Мы все с вами сейчас живем в тот период времени, когда активно развиваются подходы многоядерных многопоточных вычислений и обработки информации.
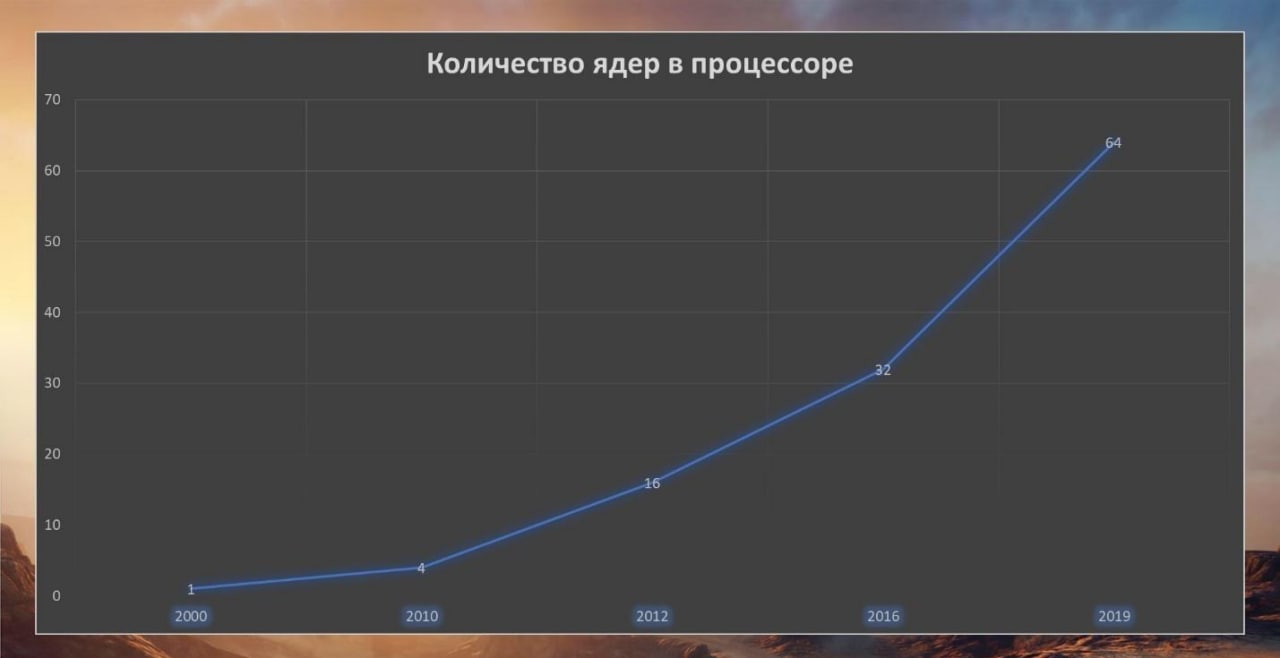
Уже давным-давно растет не частота процессоров, а увеличивается количество ядер. И пока у нас не появилось полноценного квантового компьютера, скорее всего, дальше все будет развиваться в таком же духе.
Было бы обидно не использовать все эти достижения технологического прогресса у себя в работе. А в работе мы используем платформу 1С, как ни крути.
И немного досадно, когда игрушка на твоем мобильном устройстве, например, какая-нибудь стрелялка – запускается и задействует все ядра устройства. А платформа 1С так делать не умеет.
Где в 1С можно использовать многопоточность
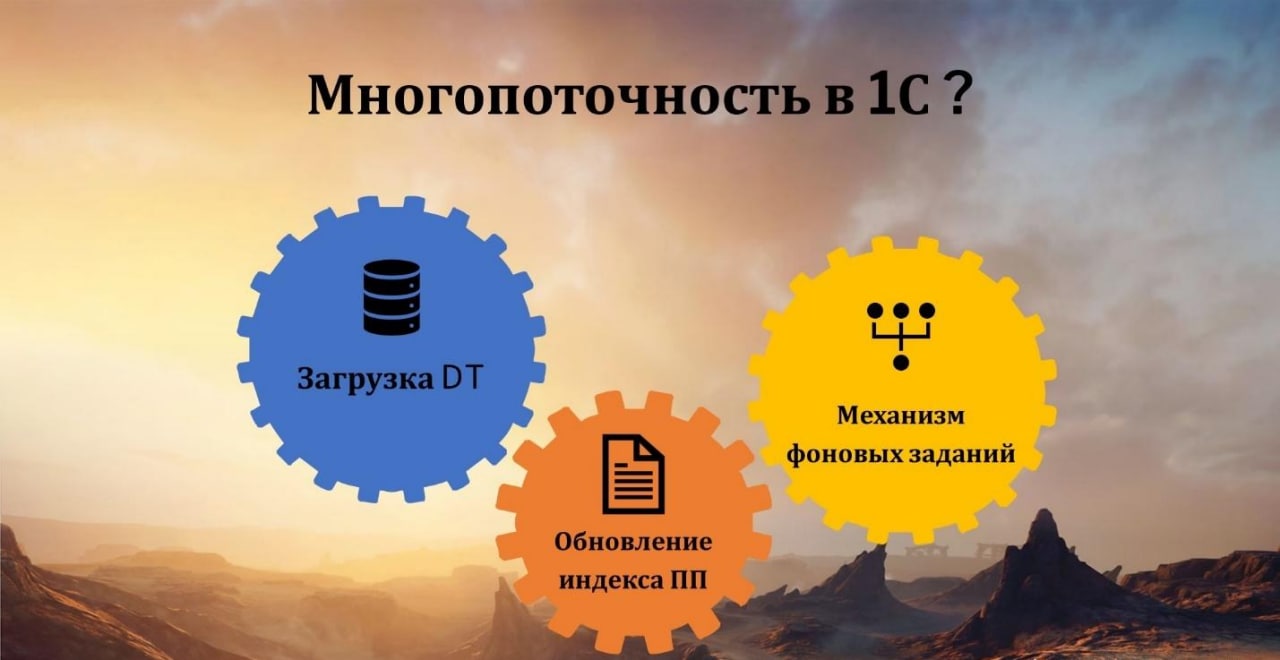
Мобильная платформа 1С пока что не умеет работать в несколько потоков эффективно, но за рамками мобильных устройств фирма «1С» все-таки некоторые фишки реализовала.
-
Например, в версии 8.3.19 появилась многопоточная загрузка в клиент-серверном варианте из DT-файла.
-
В более ранних версиях появилась возможность использовать многопоточное обновление индекса полнотекстового поиска.
-
А механизм фоновых заданий и правильные руки позволяют организовать любой алгоритм параллельной обработки данных.
Но сегодня хотелось бы поговорить про параллелизм больше в контексте СУБД, а не платформы.

От многих экспертов часто можно услышать мнение: «Отключайте параллелизм, ставьте MaxDOP=1 (max degree of parallelism – это параметр, отвечающий за параллелизм) и будет вам счастье». Та же самая рекомендация дана на сайте ИТС.
Ноги такого подхода, на мой взгляд, растут из парадигмы, что платформа 1С – это OLTP-система. Возьмите любую типовую конфигурацию и проведите в ней самый частоиспользуемый документ, к примеру «Поступление товаров и услуг» – вы увидите, сколько различных INSERT-ов делается в таблицах регистров. На мой взгляд, бессмысленно распараллеливать операцию INSERT по записи в физические таблицы в рамках атомарной транзакции.
Но любая парадигма вытекает из сомнения. С одной стороны, платформа позволяет достаточно быстро накапливать данные в транзакционном режиме. Но всегда есть потребность дальше что-то с этими данными сделать. Все мы знаем таблицы итогов, сталкивались с агрегатами или механизмом СКД. А это уже характеризует платформу со стороны OLAP-системы. И в этом контексте использование параллельных алгоритмов обработки данных, да и вообще в целом параллелизма на СУБД не является чем-то необычным или нелогичным.
Другой момент, что использовать эти подходы нужно с умом и в кейсах, где это действительно может принести положительный бизнес-эффект и дать какой-то профит.
Параллельные планы выполнения запросов – примеры из практики

К примеру, у нас в организации мы не стали отключать параллелизм. Мы пошли по другому пути – мы произвели оптимизацию самых тяжелых запросов таким образом, что параллелизм у нас запускается только на действительно тяжелых операциях в рамках технологического окна.

Что это за операции?
-
В первую очередь, это различные выполнения регламентных операций обслуживания СУБД.
-
Во вторую очередь, это сложные финансовые операции. Мы честно ничего не сможем с этим сделать, потому что тексты запросов этих алгоритмов лежат либо в закрытых модулях, либо их тексты вообще вынесены в отдельные компоненты – у нас отраслевая конфигурация.
-
И третий вид операций, который неожиданно для нас и в целом для бизнеса дал такой эффект – это выполнение отчетов по требованию. В обычной жизни, я думаю, многие из вас сталкивались с таким документом, как «Заявка на расход денежных средств». Достаточно тривиальный объект и достаточно простой бизнес-процесс – утром вы формируете заявку, что вам нужны деньги, чтобы оплатить поставщикам, подрядчикам, а далее финансовая служба это согласует и вечером деньги уходят с расчетного счета – все довольны.
Так и здесь – вечером пользователь, уходя с работы, оставляет заявку на требуемый ему отчет за какой-то период. И уже утром, придя на работу, открыв свою электронную почту, он получает этот отчет в PDF-формате. Причем, со всеми работающими расшифровками.
Какой здесь эффект? Если бы пользователь формировал этот отчет во время оперативной работы других пользователей, он бы создавал паразитную нагрузку. Этот отчет бы формировался два часа. Если бы он его делал в монопольном режиме, когда пользователи не работают, отчет бы формировался час. А при включенном параллелизме он выполняется считанные минуты – 5-7 минут. За счет этого и достигается эффект.
И в таком режиме мы прожили достаточно много времени. Но время шло и оставаться на 2014-м MS SQL Server было уже как-то некруто. Тем более, я уже в самом начале сказал, что нужно как-то следить за технологическим прогрессом, идти с ним в ногу со временем. Поэтому мы посмотрели, что есть на рынке.
Выбор СУБД для оптимального параллельного выполнения запросов
А рынок СУБД активно развивается. Сейчас хайпанули NoSQL-системы. И буквально за семь лет «пулей» выстрелил PostgreSQL.

Мы встали на распутье – переходить на MS SQL 2019 либо попробовать PostgreSQL. И начали сравнивать эти системы.
С одной стороны. MS для нас уже стал родным.
-
Он привычный, теплый, ламповый, его поведение предсказуемо.
-
Будем честны – он достаточно легко настраивается.
Что касается PostgreSQL, вокруг этой СУБД в последнее время очень много дискуссий в сообществе 1С.
-
Если брать стандартные варианты, которые идут в поставке, там в последних версиях есть возможность выбрать оптимальные параметры настройки СУБД для работы с 1С.
-
Есть поддержка со стороны отечественных коммитеров.
-
Скорость новых фич
-
Кроме этого, еще психологически давит фактор импортозамещения и курс доллара, который постоянно меняется.
Все эти факторы делают PostgreSQL таким кандидатом, который можно рассмотреть, чтобы на него перейти.
Но при переходе на ту или иную СУБД, будь то MS или PostgreSQL, мы не хотели бы потерять тот эффект, который мы достигаем за счет параллелизма. А он для нас действительно очень важен, потому что все эти операции, о которых я сказал, которые выполняются в рамках технологического окна, они спокойно укладываются в технологическое окно. Но стоит нам отключить параллелизм, жить становится уже как-то не очень комфортно.
С учетом того, что мы – быстрорастущая компания, которая активно осуществляет экспансию в новые регионы, как вы понимаете, технологическое окно с каждым разом становится все меньше, а задач от бизнеса и, соответственно, регламентированных операций – все больше. Поэтому в сегодняшнем докладе я хотел бы сравнить работу этих двух СУБД именно в контексте параллелизма, потому что сравнение во всех остальных случаях – это тема отдельного доклада. Тем более, что информации про обычное сравнение MS SQL и PostgreSQL в интернете полно, Антон Дорошкевич на площадке Инфостарта про это уже рассказывал.
Критерии оценки
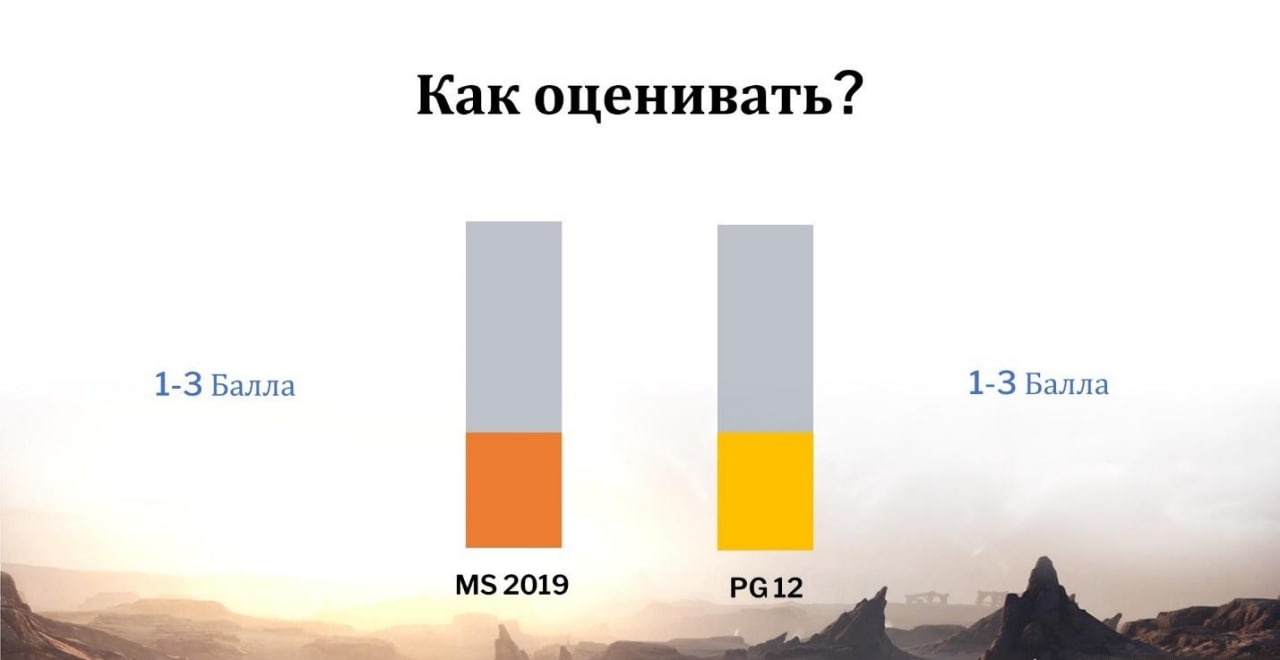
Как мы будем оценивать, сравнивать эти СУБД и определять победителя? Все достаточно просто – я выделю основные функциональные блоки, связанные с работой СУБД и буду оценивать их по трехбалльной шкале – от 1 до 3. По итогу мы все эти баллы сложим и кто больше баллов наберет, тот и победитель.

Причем критериями сравнения будут являться не только временные показатели, хотя эта метрика действительно очень важна, но и вообще возможность СУБД каким-то образом распараллелить ту или иную операцию.
Какие функциональные блоки будем брать для сравнения?
-
В первую очередь, это выполнение регламентов обслуживания СУБД – то, о чем я говорил. Выполнение в несколько потоков было бы замечательно, если бы это было возможно.
-
Возможность СУБД строить параллельные планы выполнения запросов и в многопоточном режиме производить из этих планов выборку данных непосредственно из СУБД.
-
Коснемся реструктуризации, потому что тема важная. Мы постоянно растем, у нас добавляются метаданные, производится реструктуризация.
-
И коснемся мониторинга – здесь я подразумеваю возможность многопоточного или многосеансового сбора метрик и в том же многопоточном режиме возможность их анализировать.

Немного о параметрах стенда. Мы не стали ничего придумывать, а сделали все по фен-шую. На физической машине развернули две виртуальные машины:
-
для PostgreSQL мы развернули машину на CentOS;
-
для MS SQL Server – на Windows Server 2016.
1. Регламенты обслуживания
Перейдем теперь непосредственно к блокам – начнем эту битву СУБД.
В первую очередь нас интересуют регламенты обслуживания.
Здесь по классике стандартом являются такие операции как обновление статистики, реиндексация, перестроение индекса и возможность формирования полных бэкапов.

Обновление статистики. Начиная с MS SQL Server 2016, для обновления статистики можно использовать хинт MAXDOP – именно этот хинт будет отвечать за то, сколько параллельных процессов обновления будет запущено.
У PostgreSQL есть команда vacuumdb с ключом -j. При ее вызове аналогичным образом будет запущено обновление статистики в столько потоков, сколько мы укажем. Несмотря на это, по временным показателям, а именно в это блоке мы будем рассматривать время – MS SQL превосходит PostgreSQL на 60%.

Дефрагментация и реиндексация. Я специально их выделил в один блок, потому что в PostgreSQL это – всего одна команда reindexdb. Но для PostgreSQL, на самом деле, лучше всего использовать внешние утилиты. Мир OpenSource для PostgreSQL открыт, он большой, там много всего интересного. И здесь как раз я бы выделил утилиту pg_repack – потому что у нее есть очень крутая особенность – она не блокирует таблицы, которые перестраивает. И вообще, у нее есть возможность выполнять отдельные операции, связанные только с перестроением индекса.
Разработчики утилиты рекомендуют использовать версию 1.4.5, не ниже. У себя для тестов мы использовали 1.4.5 и 1.4.6.
На 1.4.5 мы словили неприятный баг, что переиндексация регистра бухгалтерии заняла двое суток. Эта операция просто не закончилась. Мы слегка психанули, завершили ее, поставили 1.4.6, запустили, и в принципе все достаточно быстро выполнилось.
У MS SQL сервера есть нотация ALTER INDEX, для которой тоже есть возможность использовать хинт MAXDOP, но для дефрагментации я рекомендую еще использовать набор умных скриптов от ola.hallengren.
Я думаю, многие сталкивались с этими скриптами – это действительно уникальная крутая штука. Их тоже можно параметризировать, там тоже есть хинт MAXDOP, можно получить хороший эффект.
Здесь MS SQL Server тоже быстрее справляется – время приведено на слайде.

Бэкапы. Полные бэкапы в наше время все равно нужны, от них никуда не деться. Как бы мы не выкручивали параметр MAXDOP, бэкапы на MS SQL Server формироваться быстрее не будут. Единственный на мой взгляд правильный и доступный вариант – это использование следующего скрипта, который приведен на слайде.
В этом скрипте мы указываем, на сколько файлов у нас будет разбиваться исходный бэкап. И при наличии NMVE-дисков в наше время можно вообще спокойно разбить несколько файлов на один диск, потери производительности не будет.
PostgreSQL в отличие от MS SQL имеет на борту утилиту pg_dump, которая идет из коробки. Она позволяет формировать бэкап в многопоточном режиме. Но из-за специфики этой утилиты она больше подходит для dev-контура. Все-таки здесь я бы рекомендовал обратиться к миру OpenSource и использовать утилиты Pg_probackup, Pgbackrest и wal-g. Все они имеют возможность формировать бэкап в многопоточном режиме.
Я для тестов использовал именно pg_probackup. Потому что над этой утилитой в последнее время команда PostgresPro проделала действительно очень большую работу – оптимизировала ее и постоянно добавляет какие-то новые фичи. Причем, pg_probackup по синтетическим тестам среди прочих утилит занимает лидирующие позиции – одни из первых. Даже несмотря на это MS SQL все равно уделывает PostgreSQL. Даже если мы будем в один файл формировать бэкап, он все равно будет формироваться быстрее, чем несколько потоков у Pg_probackup.
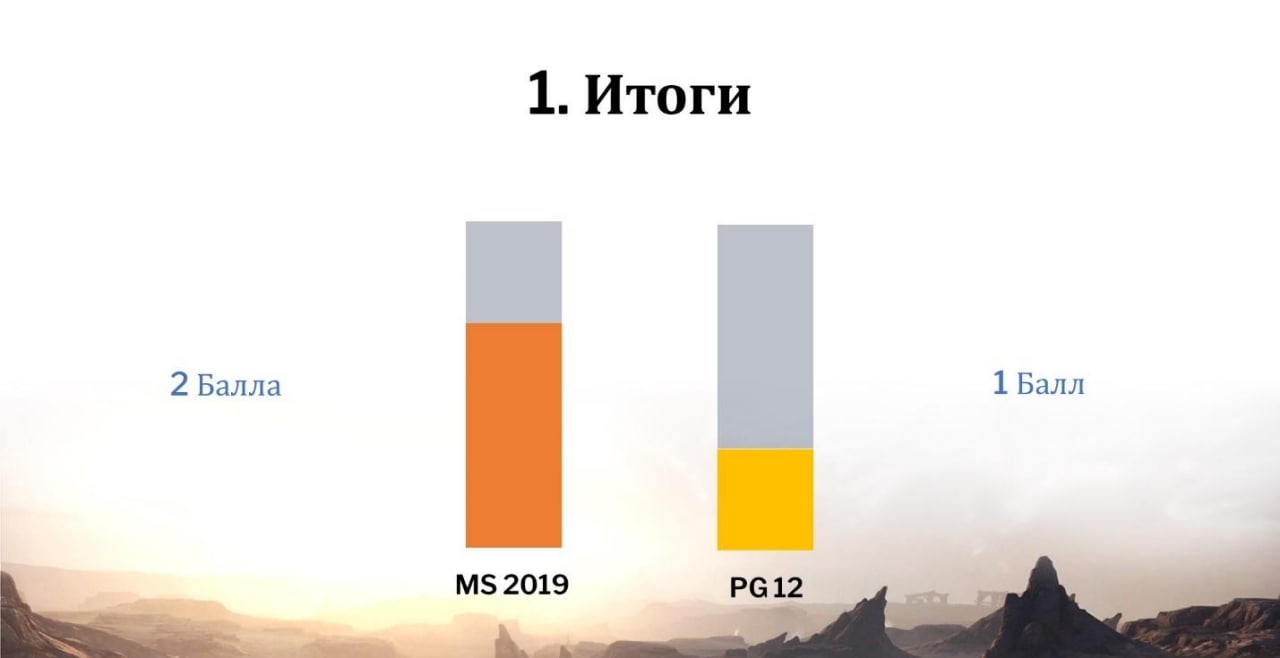
Что по итогу по регламентам выполнения обслуживания баз?
MS SQL здесь в лидерах. Один балл у PostgreSQL, потому что там есть обширный мир опенсорса и там действительно комбинацией утилит и их версией можно подобрать себе уникальную инсталляцию, которая по скорости и по качеству будет достаточно хороша, но быстрее от этого, чем MS SQL, не станет.
2. Запросы
Может быть в запросах PostgreSQL будет круче? Давайте посмотрим. Здесь я выделил отдельные атомарные конструкции запросов и буду рассматривать возможность параллельного выполнения запросов, потому что временные показатели при отключенном параллелизме можно найти и в интернете, и самим посмотреть – нас именно интересует факт распараллеливания операций.

В первую очередь рассмотрим конструкцию – сканирование индексов таблиц с последующей агрегацией. Она великолепно параллелится как в MS SQL, так и в PostgreSQL.
Тем более, если у вас обновлена статистика, все актуально на СУБД. Все просто замечательно.

Дальше идет конструкция объединения запросов. Не важно, «ОБЪЕДИНИТЬ» или «ОБЪЕДИНИТЬ ВСЕ» – тоже параллелится.

Соединение таблиц, особенно вид соединения merge join, когда у нас производится соединение двух таблиц по индексам либо покрывающий индекс используется. Самый быстрый вид соединения, прекрасно параллелится и на MS SQL и на PostgreSQL.
Немного хочу коснуться такой конструкции как ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ. Я думаю, многие из вас знают, что PostgreSQL не любит эту тему и если использовать этот вид соединения, параллелизм отключится. Если в запросе есть ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ – все, никакой параллельности не будет. Но я не буду здесь снижать баллы у PostgreSQL. Я этот вид соединения не люблю – у меня в отделе его никто не использует, и в типовых конфигурациях тоже в последнее время от него избавляются. Тем более, что оно легко заменяется объединением левых и правых соединений – поэтому в принципе, это ограничение можно обойти, я не считаю это минусом.

Строковое сравнение – когда мы используем ПОДОБНО, MS SQL спокойно это прожевывает и может строить параллельные планы на определенных узлах.
Но для PostgreSQL это – ограничение, потому что там используются типы MCHAR и MVARCHAR, которые введены искусственно и приближают эти типы данных к типам CHAR и VARCHAR, используемым в MS SQL Server.

Операция «ВЫРАЗИТЬ» – в принципе, если тоже использовать приведение к строкам, здесь похожая история, как в прошлом примере. Отключается параллелизм. Если мы используем приведение к ссылочным типам или каким-то другим, тоже отключается. В этом случае здесь MS SQL параллелит, а PostgreSQL – нет, он здесь подкачал немного.

Со всеми ограничениями PostgreSQL можно смириться и жить, но с использованием временных таблиц. Это ограничение, которое у меня вызывает определенные вопросы. До сих пор – и в 12, и в 13 версии PostgreSQL – это ограничение есть.
Если использовать в запросе помещение во временную таблицу, на весь запрос будет отключаться параллелизм. И здесь мы приходим к некоему противоречию – на официальном сайте PostgreSQL написано: «Хотите, чтобы у вас параллелилось, заменяйте временные таблицы на вложенные запросы, вам будет счастье». Но в то же время, открываем на сайте ИТС стандарты разработки, смотрим, как писать правильные запросы и видим: «Используйте временные таблицы, если использовать вложенные запросы, будут проблемы со статистикой, падение производительности и прочее». Противоречение.
Хотя есть маленький лайфхак. Если кто-то вдруг из вас до сих пор использует УТ 10.3, и использует параллелизм на MS SQL, можете спокойно переходить на PostgreSQL. На УТ10.3 большинство запросов – вложенные, вы не потеряете ничего в производительности.

Относительно новая конструкция «СГРУППИРОВАТЬ ПО ГРУППИРУЮЩИМ НАБОРАМ». В MS SQL распараллеливание работает, в PostgreSQL – не работает.
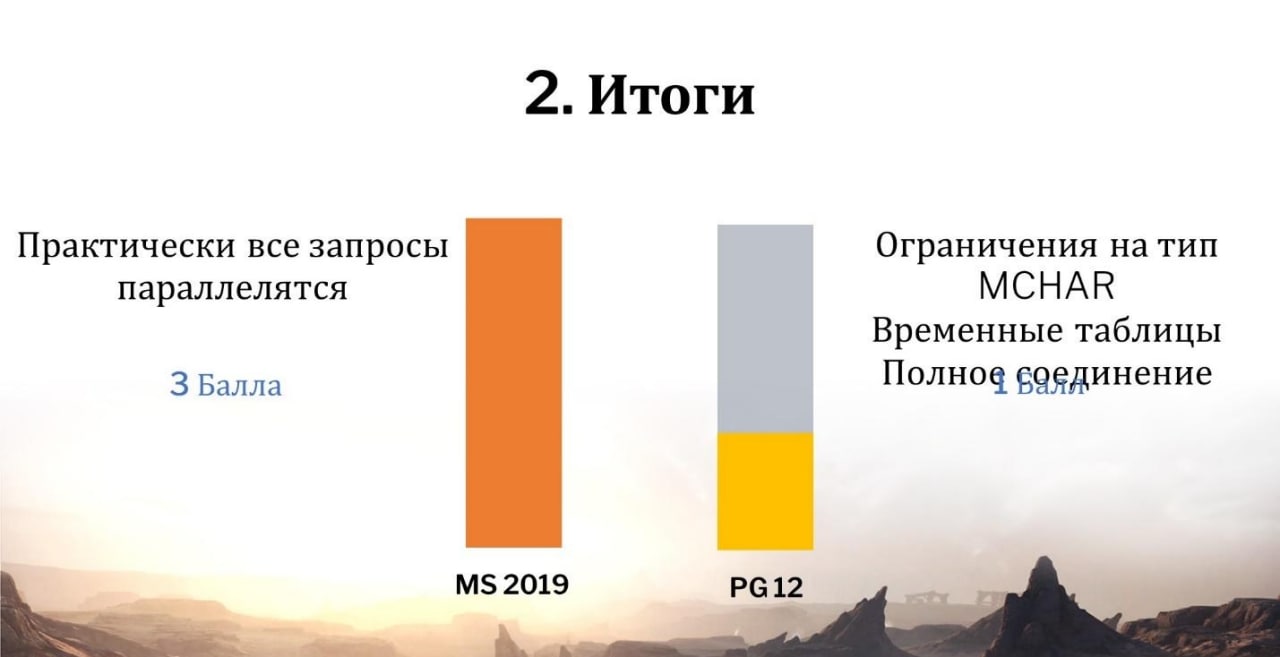
Какие итоги по запросам?
Ходил слух, что если мы для MS SQL будем использовать конструкцию SELECT TOP вначале запроса, это будет отключать параллелизм для всего запроса. Оказалось, что это байка – в MS SQL 2019 все спокойно распараллеливается, практически все запросы распараллеливаются.
Если мы берем PostgreSQL, есть очень грубые моменты – временные таблицы, ВЫРАЗИТЬ, группировка наборами. Мы в последнее время для себя эту конструкцию используем, получаем профит с нее. Печально.
3. Реструктуризация
Давайте посмотрим на еще один такой момент как реструктуризация.
Их существует два вида – первая версия включена у большинства из вас, она идет по умолчанию. Здесь параллелизм не дает особого эффекта.
Есть вторая версия реструктуризации – она появилась в 8.3.11. Здесь даже при отключенном параллелизме будет положительный эффект и ускорение за счет использования конструкций ALTER TABLE, CREATE INDEX и ALTER.
Стоит там включить параллелизм, выигрыш будет еще значительно выше.

В MS SQL есть уникальная возможность включать параллелизм не только в целом на инстанс, можно включать на базу и также на конкретный индекс.
Но в нашем случае установка параллелизма на индекс нам не поможет, потому что индекс у нас только создается – мы будем рассматривать конструкцию CREATE INDEX.
В PostgreSQL есть возможность установить степень параллелизма через параметр max_parallel_maintenance_workers, он будет отвечать, сколько рабочих процессов будет запущено для служебной команды CREATE INDEX. Но мир PostgreSQL хитрый, у него нельзя установить только один параметр, чтобы все это чудесным образом заработало. На мой взгляд, это всегда комбинация каких-то параметров.
В нашем случае здесь стоит обратить внимание на параметр max_parallel_workers, который сверху ограничивает, сколько параллельных воркеров, рабочих процессов у нас вообще может использоваться в узлах запросов.
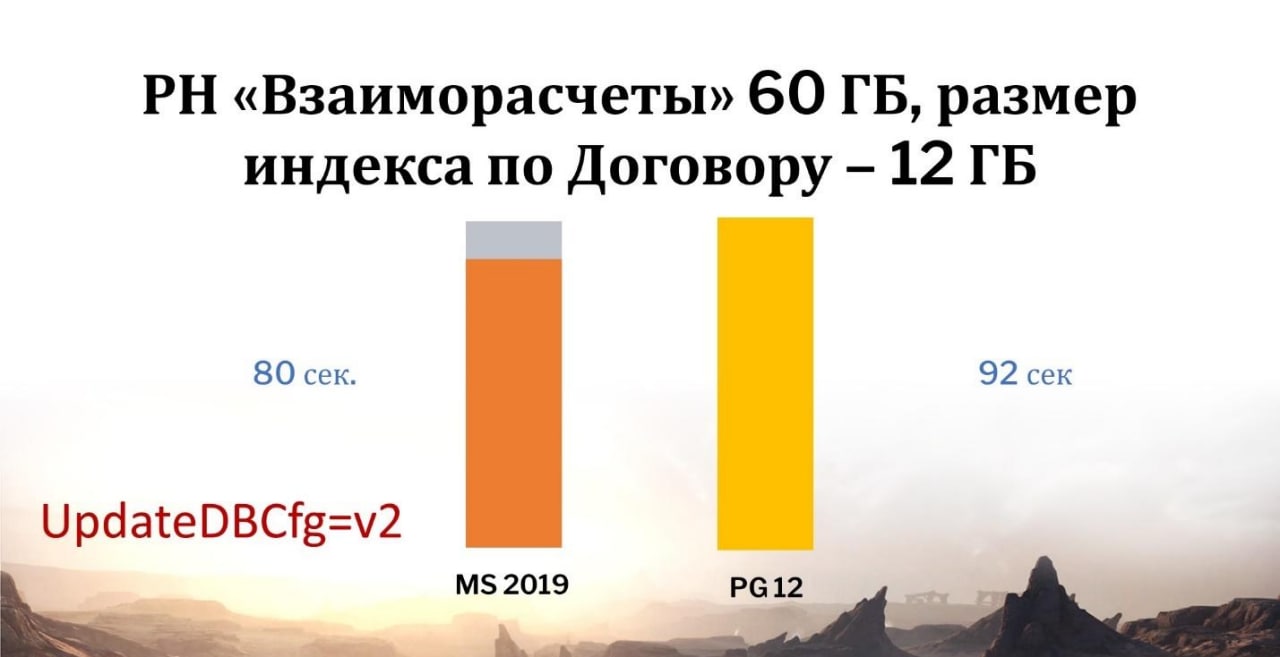
Давайте сравним. У нас есть таблица регистра накопления «Взаиморасчеты», она весит 60 Гб, 12 Гб будет занимать индекс по Договору. Мы будем использовать создание индекса CREATE INDEX – что получим по итогу?
Здесь разница у MS SQL и у PostgreSQL незначительна – 12 секунд.

Это круто, поэтому я не буду здесь занижать баллы у PostgreSQL, здесь и MS SQL, и PostgreSQL молодцы.
4. Инструментарий анализа
Давайте теперь посмотрим на инструментарий анализа. Это как раз мониторинг, о котором я вначале говорил, потому что хотелось бы в параллельном режиме собирать метрики. И в таком же режиме их анализировать.
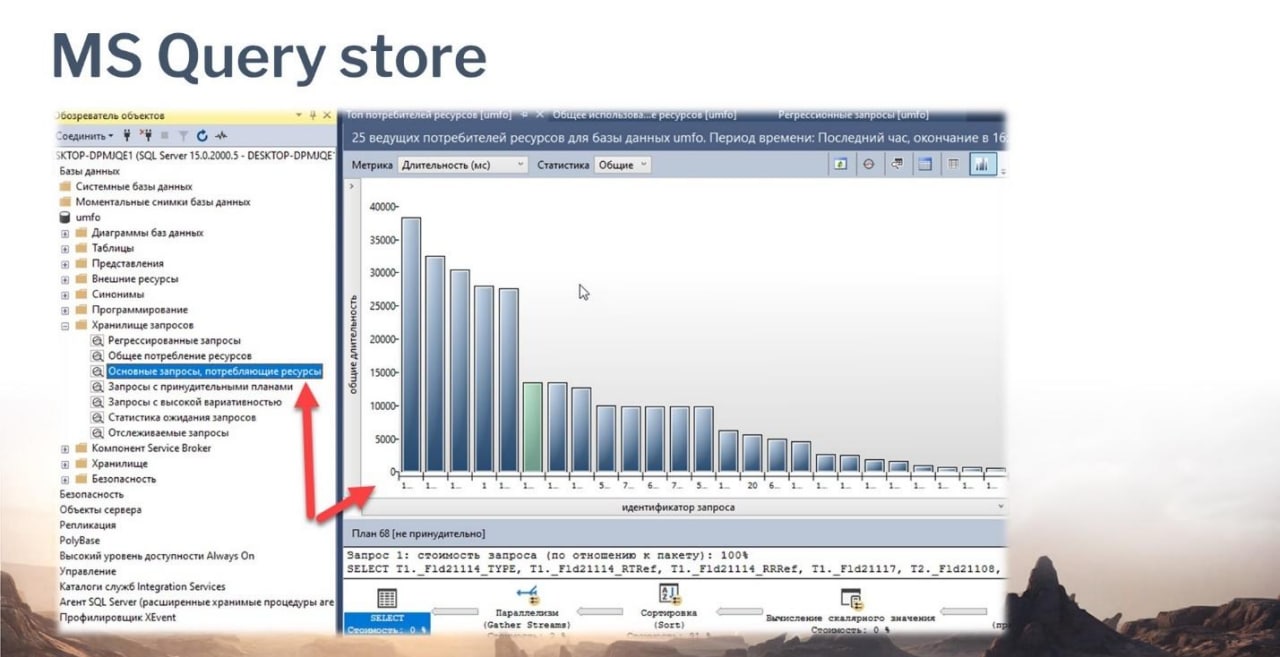
У MS начиная с 2016-й версии появился очень крутой инструмент – Query store – хранилище запросов. Он идет из коробки, включается одной галочкой и конфигурируется несколькими параметрами. Здесь в рамках каждого сеанса метрики собираются. Параллельность достигается за счет нескольких сеансов. В каждом работающем сеансе производится сбор метрик. Все это собирается в оперативную память и потом с какой-то определенной периодичностью сбрасывается непосредственно в служебные таблицы базы. Инструмент крутой, у него крутая визуализация, есть определенный набор пресетов, это такая входная точка в анализ проблем производительности.
Если у вас более ранняя версия MS SQL Server, не 2016-я, то вы можете использовать динамические административные представления DMV. Там есть хинт MAXDOP – пожалуйста, применяйте, будет распараллеливаться запрос.

У PostgreSQL есть статические представления. Это – pg_stat_statements и pg_stat_activity.
В принципе, как начальная точка старта для поиска проблем производительности, тоже крутая штука. Объединением этих двух запросов можно раскусить большинство кейсов.
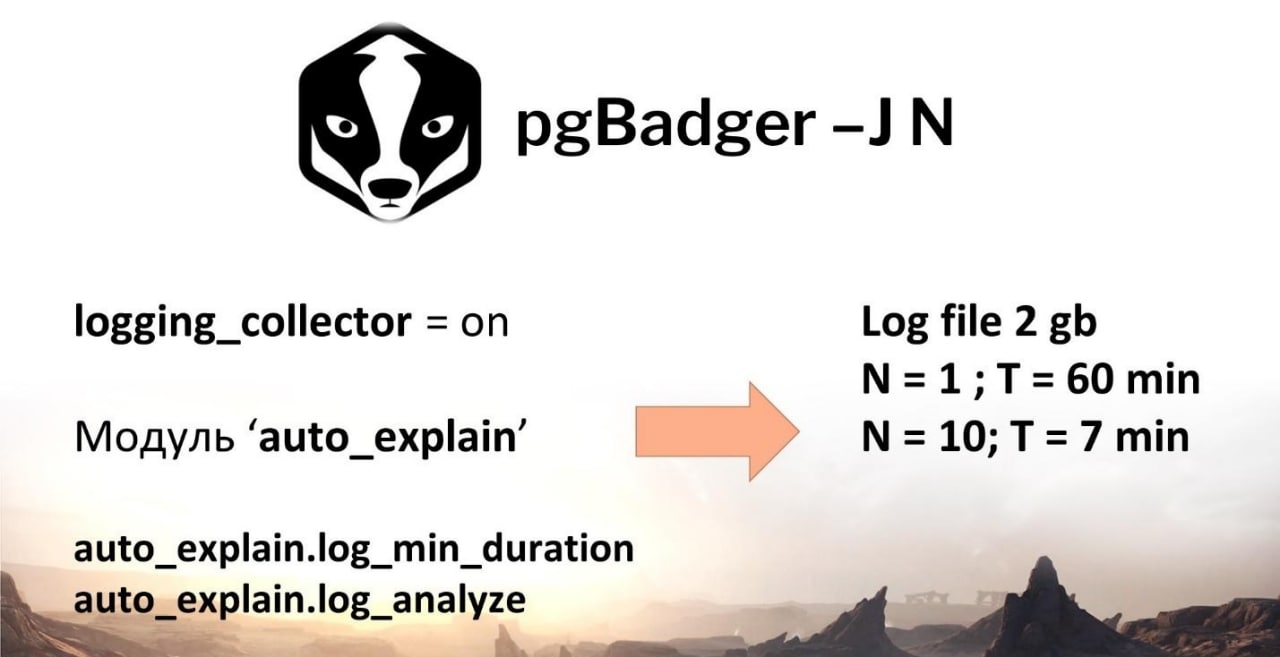
Но для того, чтобы сильнее углубиться в анализ проблем производительности, стоит обратиться к логам. Логи в PostgreSQL – это основа для поиска проблем. И здесь из мира OpenSource есть крутая утилита pgBadger. В чем его особенность? Она визуализирует логи, в многопоточном режиме позволяет логи разбирать. Чтобы эта вещь заработала, нужно непосредственно на инстансе PostgreSQL включить возможность сбора логов, активировать модуль auto_explain, который позволит собирать фактические планы выполнения запросов со статистикой. И ограничить сбор статистики для таких запросов значением duration, чтобы у вас не захламлялся лог и не рос объем, потому что в один прекрасный момент он может разрастись так, что места на вашем жестком диске кончится, инстанс PostgreSQL стопорнется, да и вообще операционка может стопорнутся.
И еще один момент – если вы все-таки включили на PostgreSQL параллелизм, логи будут расти еще быстрее, потому что каждая параллельная ветка запроса попадает в лог. Если запрос выполняется в четыре потока, у вас четыре текста запроса будут идти в логах. На это тоже стоит обратить внимание.
За счет утилиты pgBadger, запущенной с ключом -J, можно распараллеливать даже анализ логов. К примеру, разбор логфайла 2 Гб при параметре N=1 (один поток) будет занимать порядка часа. А если мы применим 10 потоков, то разберем уже за 6-7 минут.
Такой эффект достигается за счет использования параллелизма.
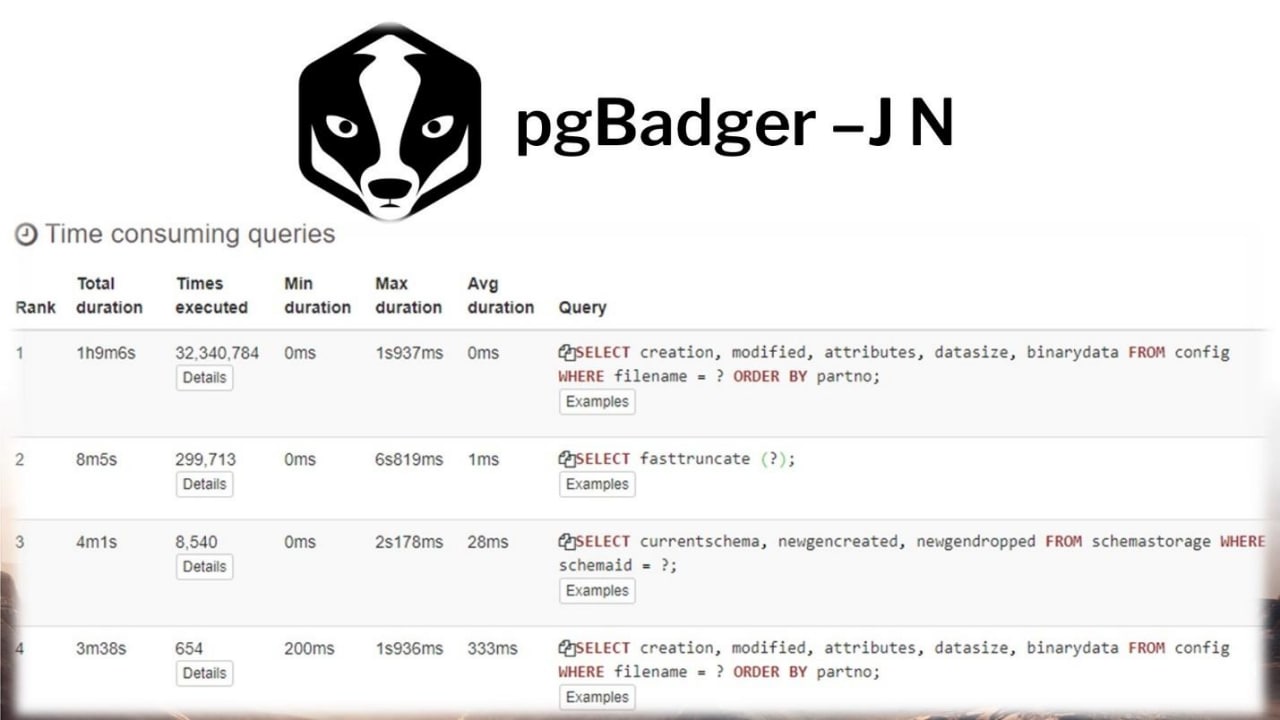
По сути, небольшой пример. Я не стал приводить логи PostgreSQL, они неструктурированы, могут напугать. Но кто сталкивался, тот знает. По сути, эта утилита преобразует логи с такой красивый вид. И дальше уже можно предпринимать какие-то действия для поиска определенных проблем производительности, разбирать определенные кейсы.

Итоги:
-
С одной стороны, в MS SQL Server есть хранилище запросов и динамические административные представления sys_dmv – это круто. Но параллельности в хранилище запросов нет.
-
У PostgreSQL тоже есть pg_stat_activity, pg_stat_statements, но там тоже нет какой-либо параллельности – при выполнении этих запросов, они выполняются в один поток. Зато у PostgreSQL есть поддержка со стороны OpenSource в виде утилит. И здесь pgBadger накидывает определенные баллы.
По итогу, мне кажется, что и MS SQL, и PostgreSQL – молодцы, и там, и там есть крутые инструменты. Любой кейс можно разобрать.
Итоги «битвы»

Подведем итог по всем нашим четырем блокам. Сложим баллы и посмотрим, что получилось.
MS SQL все-таки красавчик, пока что он в лидерах. Это лидерство обеспечивается за счет того, что есть параллелизм при выполнении служебных операций обслуживания баз, и есть возможность параллелить абсолютно любые конструкции запросов.
Что касается нашего перехода – мы пока остались на 2014-м MS SQL Server.
Но мы мониторим, что происходит на рынке, смотрим, как развивается PostgreSQL, какие новые фишки в нем появляются, нам интересно попробовать 13-ю версию.
И вообще в целом, у PostgreSQL хорошая динамика. Если в MS SQL вообще возможность параллелизма появилась 12 лет назад, то в PostgreSQL – всего 4 года назад. Со скоростью наращивания фич, которые там появляются, PostgreSQL может в один прекрасный момент не только догнать, но и перегнать MS SQL.
Не бойтесь включать параллелизм, но делайте это с умом.
Выбирайте стоимостной порог, чтобы он срабатывал определенным образом. По ссылке https://github.com/dbamaster/DBA-Mastery/blob/master/MAXDOP%20Calculator вы можете найти калькулятор для MS SQL Server, который позволяет выбрать оптимальный параметр стоимостного порога и вообще параметр MAXDOP
Смотрите, как ведет себя та или иная СУБД, тестируйте и проверяйте.
Параллелизм используется уже не первый десяток лет. С этого есть определенный эффект. Поэтому не бойтесь применять параллелизм в ваших кейсах, и вы получите положительный эффект.
Ссылки на полезные ресурсы
1. Подбор MAXDOP https://github.com/dbamaster/DBA-Mastery/blob/master/MAXDOP%20Calculator.
2. pg_repack https://pgxn.org/dist/pg_repack/
3. Умные скрипты для MS SQL Server https://ola.hallengren.com/downloads.html
4. Документация по параллелизму в PostgreSQL https://postgrespro.ru/docs/postgresql/11/runtime-config-resource#RUNTIME-CONFIG-RESOURCE-ASYNC-BEHAVIOR
*************
Данная статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Post-Apocalypse.
Вступайте в нашу телеграмм-группу Инфостарт