Мой доклад называется «Регулярная интеграция 1С с использованием RabbitMQ». Отсюда первый вопрос – почему же RabbitMQ?
-
RabbitMQ бесплатный, у него открытый исходный код, при необходимости мы можем его даже сами переписать.
-
Кроссплатформенность: мы можем использовать RabbitMQ на Windows, на Linux, и на других экзотичных системах.
-
RabbitMQ нетребовательный к ресурсам, он прост в установке и эксплуатации – поставили, настроили очереди и забыли. Периодически добавляем и удаляем – администрирование по минимуму.
-
Для RabbitMQ уже разработаны клиентские библиотеки для большинства современных языков программирования. Если вам потребуется сынтегрировать не только 1С, но и какую-то еще систему, вы легко сможете это сделать.
-
Для RabbitMQ можно использовать разные форматы сообщений. Тело сообщения RabbitMQ может быть каким угодно: оно может быть представлено как просто строка или как двоичные данные, представленные в виде строки. Можно самим определить необходимый нам формат, причем этот формат может отличаться для разных очередей, разных систем. Мы чуть позже эту возможность посмотрим.
-
К RabbitMQ можно подключать дополнительные модули. Есть много модулей от известных разработчиков, и можно экспериментировать – подключить модуль от кого-нибудь неизвестного.
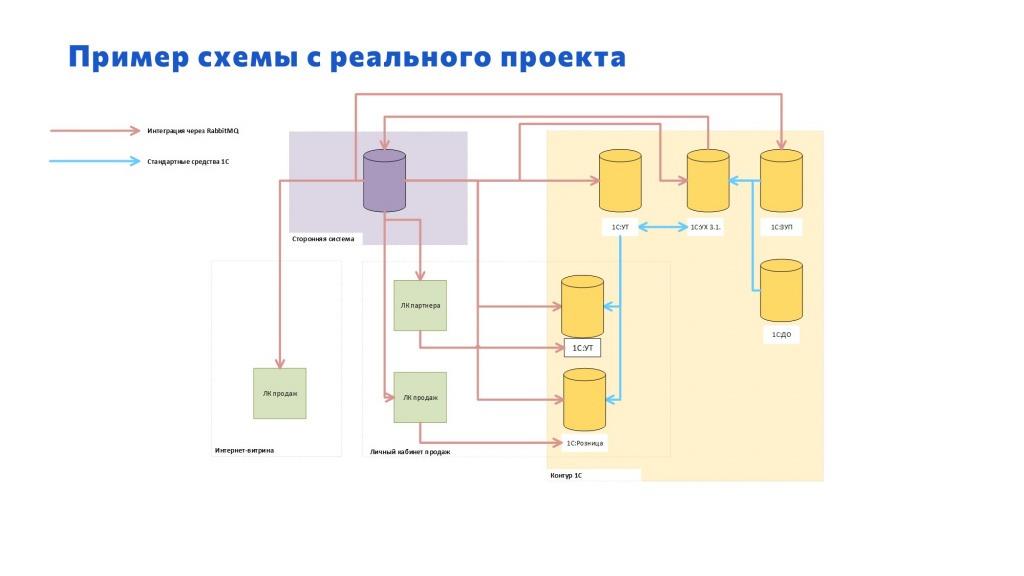
Немного о проекте, на котором я являюсь техническим архитектором – расскажу, почему именно на нем мы решили использовать RabbitMQ.
Слева у нас есть некоторая система – она написана с нуля на некотором языке программирования. Это не фреймворк, не SAP, не Oracle и т.д. – это чисто с нуля написанная система.
У этой системы есть некоторые витрины и личные кабинеты, которые изначально взаимодействовали между собой на RabbitMQ. И к ней потребовалось подключить учетные системы на базе 1С, потому что у нас 1С – это стандарт для бухгалтерского учета. А бухгалтерский учет нужен везде.
Помимо того, чтобы подключить бухгалтерский учет, потребовалось подключить еще несколько учетных систем:
-
1С:ЗУП, чтобы считать зарплату;
-
1С:Управление торговлей для складского учета;
-
параллельно подключить 1С:Управление торговлей именно для торговых операций;
-
и некоторые маленькие магазинчики, которые будут работать на 1С:Розница.
На схеме:
-
голубыми стрелками показаны потоки интеграции, которые идут стандартными средствами;
-
а красным цветом помечено то, что работает через RabbitMQ.
Поскольку большинство обменов уже работало на RabbitMQ, он был уже настроен и проверен по нагрузке – вполне логично, что мы захотели использовать его и в интеграции с нашими учетными системами.
Применимость технологии RabbitMQ в 1С

На слайде представлена некоторая табличка, это мое личное мнение, когда стоит использовать технологию RabbitMQ для интеграции, а когда – не стоит.
-
Если у вас есть типовой обмен – лучше допилить его.
-
Если у вас есть небольшой обмен до пяти объектов – тоже не стоит использовать RabbitMQ, проще сделать интеграцию через веб-сервис, HTTP-сервис или другую известную вам технологию. В этом случае вы сможете реализовать и поддерживать этот обмен в одиночку.
-
Но если у вас одна система на 1С, другая не на 1С, третья на SAP, на Oracle и так далее, и при этом нет полноценной шины данных – тогда уже имеет смысл использовать RabbitMQ.
Опять же, повторюсь, это исключительно мое мнение. Если у вас есть большое желание переписать типовой обмен полностью на RabbitMQ, это ваше полноценное право.
Договоренности перед разработкой интеграции

Чтобы при использовании RabbitMQ в 1С пользователю все было удобно и понятно, нам потребуется целая подсистема для интеграции. Но перед тем, как начать ее разрабатывать, нам нужно договориться о следующих сущностях:
-
Потоки интеграции и объекты интеграции.
-
Определение мастер-систем для объектов.
-
Спецификации объектов интеграции.
-
Формат сообщения – мы должны договориться:
-
Как обозначаем типы объектов;
-
Как представлены данные в сообщении;
-
Какие служебные поля потребуются в нашем сообщении.
-
Сейчас речь именно о формате тела сообщения, которое мы непосредственно будем обрабатывать.
Расскажу подробнее, что имеется в виду под каждой из этих сущностей.

Мы по порядку определяем:
-
Какие системы участвуют в интеграции: 1С эта система или не 1С; будет она с нами обмениваться или нет.
-
Потоки и направления взаимодействия между системами: это будет однонаправленный поток; либо двунаправленный; либо иногда однонаправленный, иногда двунаправленный.
-
Какие объекты подлежат интеграции: по какому потоку какие объекты у нас идут. Например, контрагенты у нас ходят из системы А в систему Б и параллельно в систему В, Г, Д и Е и так далее.
-
Мастер-системы для НСИ и регламентированных документов, если они есть. Если мы не определим мастер-системы, в конечном итоге идентификаторы объектов у нас разойдутся, и нам придется эти объекты сопоставлять между собой. Когда системы две – это просто, когда три – возможно, когда четыре, пять, шесть, семь, восемь – уже нереально сложно, долго и проще заново все сделать;
-
Состав полей, которые мы будем передавать. Здесь же мы определяем, какие именно поля у нас будут обязательными, какие желательными, какие просто необходимыми. Например, идентификатор объекта необходим по умолчанию – он должен присутствовать во всех наших объектах.
После того как мы все это определили, переходим к определению формата сообщения.
Так как мы уже знаем, какими объектами будем обмениваться, нам нужно согласовать, как мы будем обозначать тип нашего объекта. Мы можем представить тип объекта:
-
Строковой константой – например, «Контрагент» либо, как мы привыкли в 1С, «СправочникСсылка.Контрагент».
-
В виде Идентификатора – числового либо Guid.
-
Либо придумать что-то свое экстравагантное.
Представление типа объекта в виде строковой константы неудобно – кто-то написал с большой буквы, кто-то с маленькой, кто-то ошибся в букве, написал «Кантрагент» через «а» и так далее.
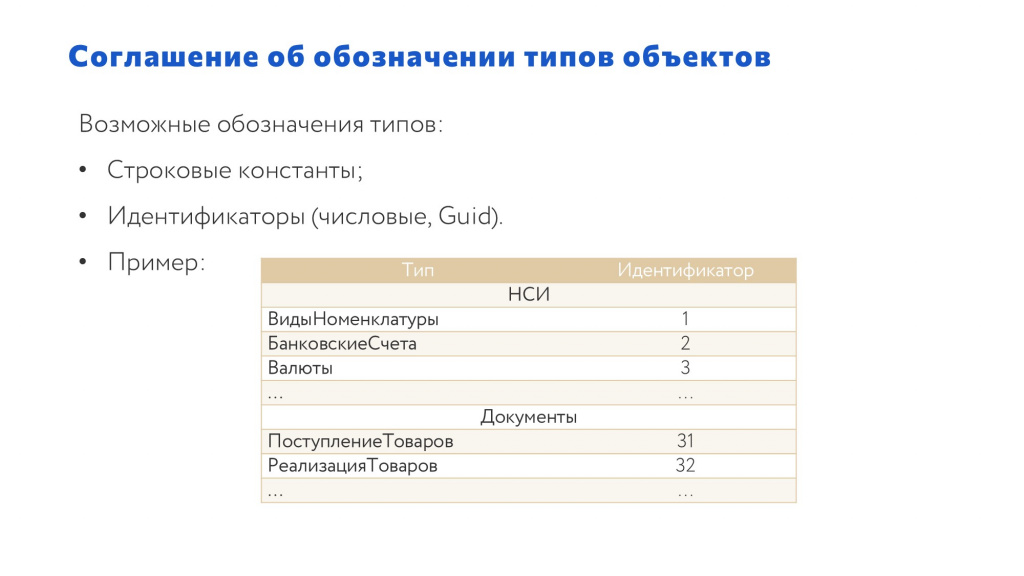
Лучше всего, на мой взгляд, использовать идентификаторы и проще всего, если идентификаторы будут числовыми. Например, мы определяем идентификаторы для справочников:
-
«ВидыНоменклатуры» – «1»;
-
«БанковскиеСчета» – «2»;
-
«Валюты» – «3».
Для документов:
-
«ПоступлениеТоваров» – «31»;
-
«РеализацияТоваров» – «32».
И в результате можем сгруппировать эти объекты так, как нам нужно. Например:
-
для централизованной НСИ у нас будут идентификаторы – до 10;
-
для просто НСИ, которая ходит между системами – от 10 до 30;
-
а после 30 – у нас идут документы.
В этом случае при анализе сообщений мы, глядя на наш тип объекта, будем сразу понимать, что к нам пришло.
Пример сообщения обмена

Что мы можем использовать в качестве формата самого сообщения:
-
Можем использовать строку, но это неудобно.
-
Я предпочитаю XML, потому что это человекочитаемо. При необходимости можно показать сообщение исполнителю или даже заказчику. И некоторые заказчики, которые понимают английский, здесь даже что-то поймут: что есть источник, есть объект и тип объекта.
-
Можно использовать тот же JSON – он более компактный и позволяет уменьшить само сообщение. Например, если вы знаете, что в вашем объекте всегда будет много полей, либо это будет документ с большим количеством строк в табличной части, лучше использовать JSON.
После того как мы определили формат, можно сразу же определить те вспомогательные поля, которые нам потребуются. Обратите внимание, здесь есть:
-
id – идентификатор сообщения;
-
Source – источник;
-
ObjectType – это как раз тот тип объекта, про который мы говорили;
-
CreationTime – время создания этого пакета.
Для чего нужны эти служебные поля:
-
Идентификатор позволяет упростить взаимодействие между системами для служб поддержки этих систем. Чтобы одна служба поддержки сказала: «Мы отправили сообщение с идентификатором таким-то», а вторая служба поддержки сказала: «Мы его не приняли, вы его где-то потеряли».
-
Источник не обязателен, но если у вас много систем, такое поле лучше иметь – чтобы было понятно, откуда такое сообщение пришло, кому адресно направить претензии.
-
Время создания – я считаю, что это необходимое поле. С его помощью можно увидеть, что один объект был выгружен, например, несколько раз. Упорядочив сообщения по этому полю, мы обработаем их в правильном порядке. Например, если в массиве сообщений два сообщения по одному объекту, мы можем по дате создания сориентироваться – либо по порядку их выстроить, либо сразу обработать только последнее сообщение.
Пример представления данных
Когда мы определили служебные поля, можно переходить к представлению самого объекта в нашем сообщении.

Наш объект удобнее всего представить в виде XML – это готовая структура со списком полей, который мы уже заранее согласовали: определили, какие поля должны быть, как они называются, какие обязательные, какие необязательные.
Судя по идентификатору типа объекта из предыдущей таблички, здесь у нас пример выгрузки объекта типа «Банковский счет». У нас есть:
-
ID – идентификатор, наша ссылка, представленная в виде guid;
-
ПометкаУдаления;
-
Владелец;
-
Наименование;
-
НомерСчета;
-
Банк.
По такому сообщению мы можем легко и непринужденно создать банковский счет – конечно, если у нас есть контрагент с идентификатором как у владельца счета.
Я считаю, что при передаче объекта не нужно пихать его поля в само сообщение, чтобы поля объекта шли сразу после полей сообщения. Лучше этот XML сериализовать и представить в виде строки, предварительно договорившись о поле, в которое мы будем класть эту строку.

Пример хранения сериализованного объекта в теге Object сообщения – на слайде. Мы добавили сюда сам сериализованный объект, который мы преобразовали в строку, просто заэкранировав символы «<» и «>».
Тем самым мы можем разделить обработку самого сообщения и обработку объекта – сериализовать их обратно, представить в виде объектных сущностей и с ними работать. Довольно удобно.
При этом у вас не возникнет ситуации, что какой-нибудь разработчик ошибся, вынес пометку удаления в теги самого сообщения, а на обратной стороне у вас из-за этого возникнут ошибки.
Когда мы полностью договорились о том, как будем взаимодействовать, можно постепенно переходить к самой разработке.
Кратко об API RabbitMQ

Подробно рассказывать про RabbitMQ я не буду, думаю, многие из вас уже пробовали с ним работать. Кратко перечислю способы взаимодействия, которые для него могут быть.
-
Rest API – отправили запрос, получили ответ;
-
Клиентская библиотека, которая поставляется самим RabbitMQ;
-
Либо одна из внешних компонент, которые написаны для 1С – о компонентах расскажу чуть позже.

Теперь о настройках, которые нам необходимы – это:
-
адрес сервера, порт;
-
логин, пароль;
-
для получения сообщений нам нужно знать имя очереди, из которой мы будем это читать;
-
и нужны настройки отправки сообщения.
Где хранить эти настройки – это уже на ваше усмотрение.

Минимальный набор событий, которые потребуется реализовать в нашей подсистеме. Я все-таки считаю, что нужно делать именно подсистему, а не просто одну обработку, которая читает сообщения, тут же их записывает и обрабатывает.
-
Самое главное – это метод для установки соединения с самим RabbitMQ.
-
Метод для определения очереди, с которой мы работаем в данный момент – куда мы отправляем либо откуда читаем.
-
Методы для чтения сообщений – либо чтение одиночного сообщения, либо чтение пакетом.
-
Метод отправки подтверждения о получении сообщения вынесен отдельно. В RabbitMQ есть гарантированная доставка. Мало того, что вы прочитали сообщение, вы должны подтвердить, что его прочитали. Поэтому этот метод обычно реализуется отдельно – вы прочитали, записали, обработали, неважно, что сделали, потом отправили, что сообщение можно удалять;
-
Метод для отправки сообщения.
-
И самое последнее, но не самое ненужное – это метод для получения ошибки обработки: «ПолучитьПоследнююОшибку» или «ПолучитьПоследниеОшибки».

Внешние компоненты, которые на данный момент есть, и общеизвестны, и общедоступны:
-
PinkRabbitMQ от «Первый БИТ»;
-
и YellowRabbit от «Серебряной пули».
Будете гуглить – будьте аккуратнее, особенно на работе: PinkRabbitMQ надо писать полностью, иначе он ссылается не туда.

Посмотрим реализованность необходимых нам методов на примере компоненты PinkRabbitMQ: в ней есть методы для соединения, отправки и получения – можно брать и использовать. Но сначала давайте посмотрим, что нам нужно реализовать в нашей подсистеме, чтобы у нас заработала полноценная интеграция.
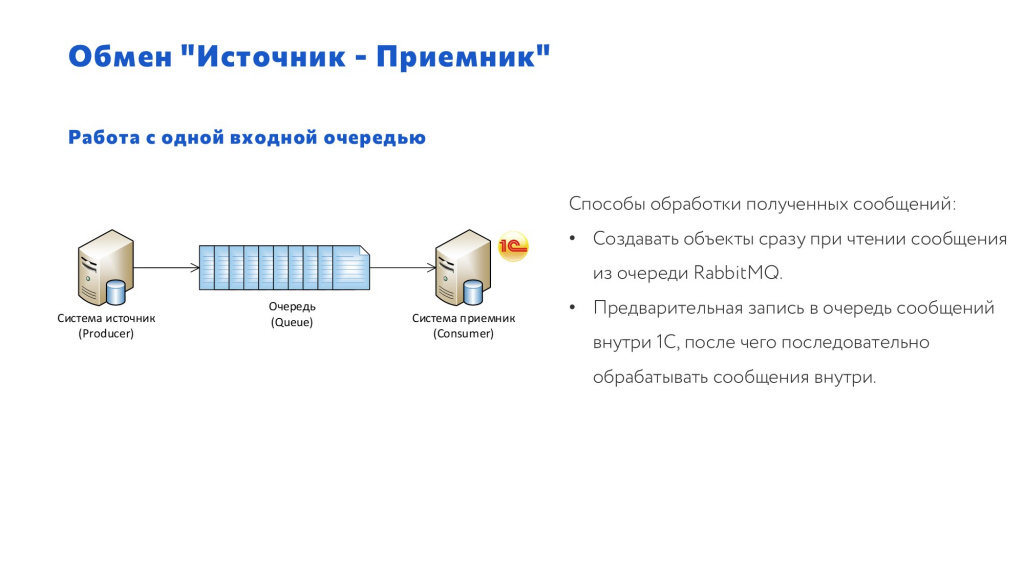
Обмен «Источник – Приемник»
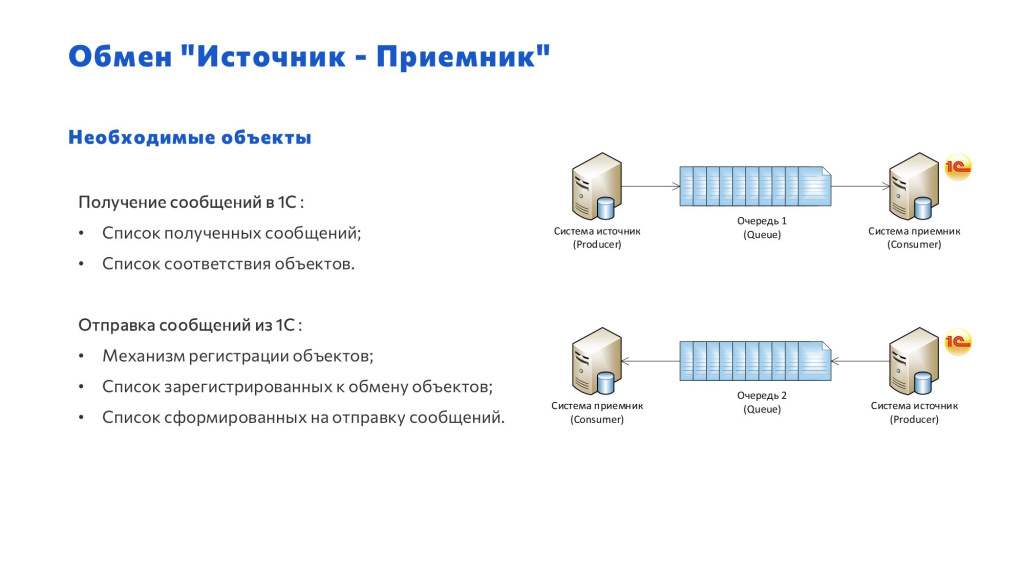
Я все-таки считаю, что нам важно не просто получить сообщение и обработать, но и сохранить его в нашей системе. Для этого нам потребуется:
-
Список полученных сообщений;
-
Список соответствия объектов – мы такой список назвали «КлючиЭлементов», но это уже на ваше усмотрение.
Для отправки нам потребуется:
-
Механизм регистрации объектов;
-
Список зарегистрированных к обмену объектов;
-
Список сформированных на отправку сообщений – пока сообщение не обработалось, мы должны его видеть; если ошибка – мы тем более должны его видеть.

Вариант реализации всего того, что я рассказал.
-
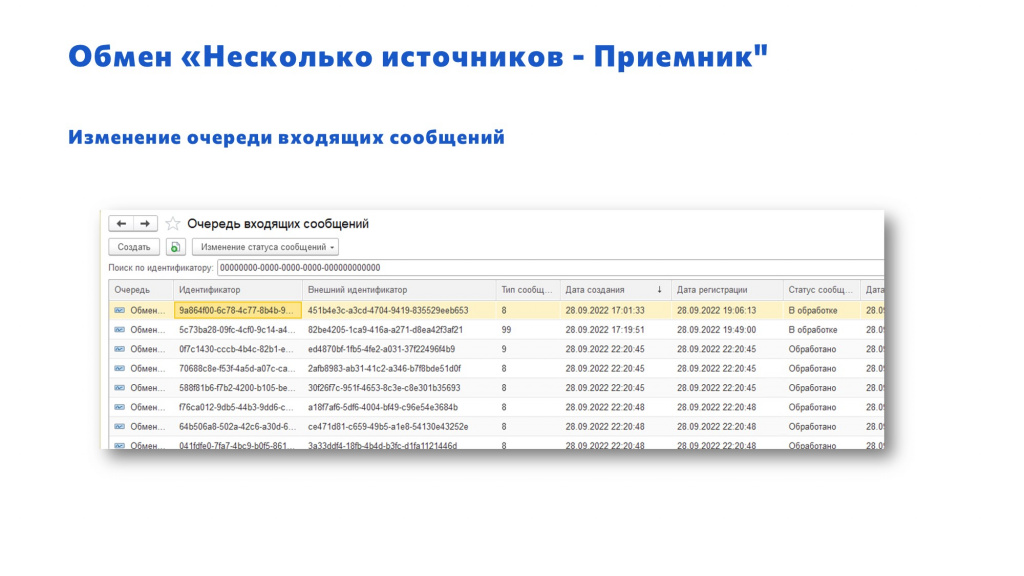
Для получения сообщений – регистр сведений «ОчередьВходящихСообщений».
-
Для соответствия – регистр сведений «КлючиЭлементов».
Структура РС «ОчередьВходящихСообщений» довольно простая:
-
Измерение – ИдентификаторСообщения»
-
Ресурс – «Хранилище», где хранится XML, JSON либо другой формат, которым вы обмениваетесь.
-
И некоторые служебные реквизиты
Обратите внимание, что служебных реквизитов гораздо больше, чем тех, которые мы обсудили в формате сообщения. Эти поля уже нужны нам, как разработчикам – на нашей стороне и для удобства работы. У нас есть:
-
ДатаСоздания – когда мы создали сообщение на той стороне,
-
ДатаРегистрации – когда мы приняли сообщение на нашей стороне. По разнице этих двух дат можно понять, что у нас по какой-то причине был разрыв два дня – сеть не работала либо что-то еще.
-
ИДОбъекта – сюда мы сохраняем идентификатор объекта из сообщения, чтобы после его обработки нам было проще его найти. Мы не храним здесь сразу ссылку на объект, потому что типов объектов у нас может быть много, и такие запросы будут работать медленно.
Для РС «КлючиЭлементов» все просто:
-
ID – идентификатор источника;
-
СсылкаНаЭлемент – ссылка на объект в нашей системе.
Дополнительно обращу внимание на ресурс «ДатаИзменения» – помимо того, что мы можем ориентироваться на поле сообщения CreationTime (время создания пакета), ресурс «ДатаИзменения» позволит нам понять, не обрабатываем ли мы старое сообщение. А то, возможно, у нас уже идет ситуация, когда пришла какая-то старая версия сообщения, и мы пытаемся затереть уже существующий правильный объект.
Для отправки я использовал:
-
Подписку на события «ОбменСправочникиДокументы» – для механизма регистрации объектов.
-
РС «ОчередьЗарегистрированныхОбъектов», в которую складываются все эти объекты.
-
И РС «ОчередьОтправляемыхСообщений».
Здесь нет ничего про правила конвертации и прочее, потому что они у меня в коде. Так сделано на мое усмотрение – на ваше усмотрение может быть по-другому.
Зачем все так сложно – зачем тратить место, что-то хранить? Почему бы просто не считывать сообщения от системы-источника из очереди напрямую?

Но в хранении сообщений все-таки есть некоторые плюсы.
-
Если мы обрабатываем сообщение на лету, в RabbitMQ оно не остается – его RabbitMQ не залогирует. Если нам потребуется повторно обработать сообщение, нам нужно будет запрашивать его на стороне источника.
-
Когда сообщение хранится на стороне 1С, мы можем его посмотреть. Даже если это не человекочитаемый вид, разработчики могут его получить, посмотреть и понять состав полей. А если у нас XML человекочитаемый, мы его вывели на экран, показали, какие у нас обязательные поля не заполнены и так далее.
Конечно, есть минус – эти данные приходится хранить и периодически чистить, т.к. если не следить, они забьют все место.

Теперь случаи, когда мы не доверяем источнику. Не всегда мы можем верить той стороне – тем более, когда не просто несколько команд разработки, а кто-то хочет сорвать интеграцию.
Что может быть самым плохим?
-
Когда у нас уникальные идентификаторы не уникальны. Идентификаторы могут быть как у самого сообщения, так и у объекта.
-
Если с уникальностью идентификатора сообщений мы что-то можем сделать – просто на своей стороне ввести дополнительное поле идентификатора в нашей системе и фиксировать: сообщение пришло, мы ему присвоили свой идентификатор.
-
Если же идентификатор объекта не уникальный на стороне источника – здесь мы ничего сделать не можем. Нужно настаивать, требовать, шантажировать и так далее, чтобы коллеги на своей стороне исправили идентификаторы. Ни в коем случае не ведитесь на объяснения: «вы привяжитесь к этим трем полям, они в связке дают уникальный идентификатор». Не нужно им верить. Если вы договаривались, что это поле будет идентификатором, оно должно быть уникальным.
-
-
Утверждение, что объект на стороне приемника не соответствует отправленным данным. Такое тоже встречалось в моей практике – коллеги утверждают, что они отправили все по формату, проблемы на нашей стороне. У нас есть РС «ОчередьВходящихСообщений» – мы просто демонстрируем, что к нам пришло от них.
-
Если коллеги на той стороне не попадают в формат сообщения – здесь повод просто обратиться к нашим изначальным договоренностям о составе обязательных полей. Просто настаиваем на том, чтобы коллеги придерживались договоренностей.
Правила преобразования объектов

Кратко о том, как обрабатываются исходящие сообщения, простенький алгоритм.
-
Мы получаем объект из очереди.
-
Дальше определяем, требуется ли его выгружать. Повторюсь, у меня эта логика описана в коде – у вас может быть реализовано любым другим способом, в том числе, через подключение правил регистрации в виде XML.
-
Далее заполняем структуру в соответствии с полями согласованных спецификаций.
-
Если мы договорились, что выгружаем сообщения в XML либо в JSON, сериализуем получившуюся структуру в нужный формат и отправляем сообщение.
Почему на моей схеме используются регистры сведений, а не планы обмена? Просто потому, что планы обмена на больших объемах начинают подвисать.

Алгоритм формирования входящего сообщения немного сложнее, потому что у нас есть некоторая бизнес-логика:
-
Нам нужно проверить, что объект не создан. Если создан, то получить.
-
И самый главный пункт – создать или обновить зависимые объекты.
Алгоритм со звездочкой, потому что при этом требуется учесть даты запрета изменения и так далее.
Обмен «Несколько источников – Приемник»
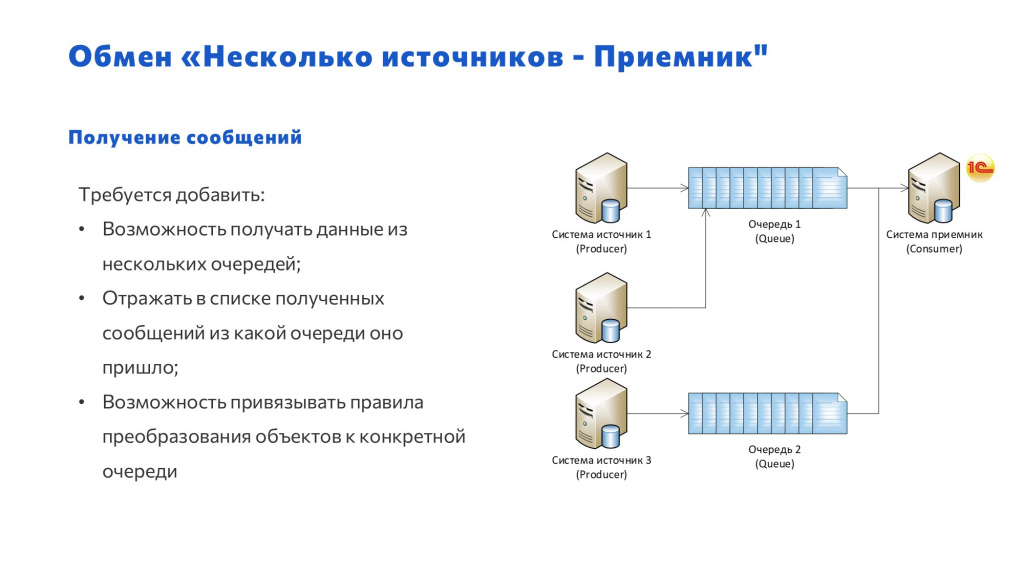
Когда мы реализовали простой обмен через одну очередь с одним источником и с одним приемником, стоит перейти к тому, что у нас будет несколько источников, несколько приемников и несколько очередей.
Для этого в нашу схему требуется добавить:
-
настройки для RabbitMQ – предусмотреть сразу, что и Rabbit у нас будут разные;
-
настройки очередей;
-
и возможность привязки правил к этим очередям.
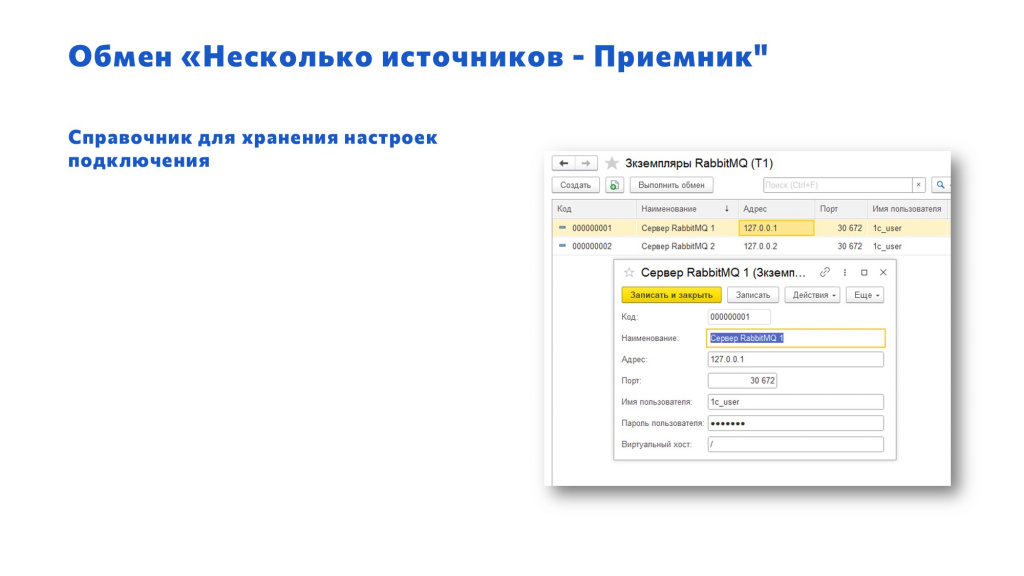
Для хранения настроек подключения к RabbitMQ используем справочник.
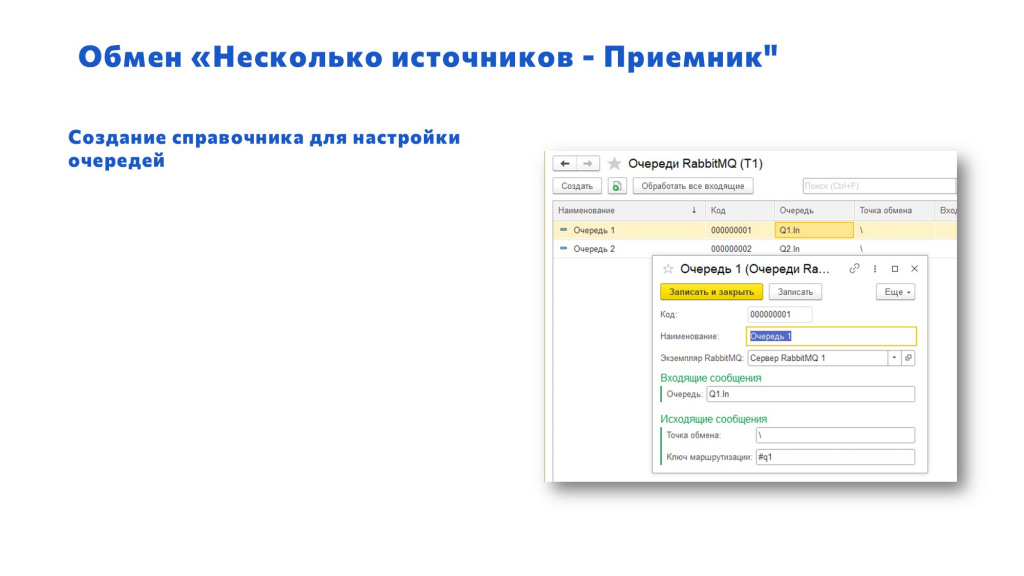
Аналогичный справочник – для хранения настроек очередей.
В РС «ОчередьЗарегистрированныхОбъектов» у нас уже первым полем встает Очередь.
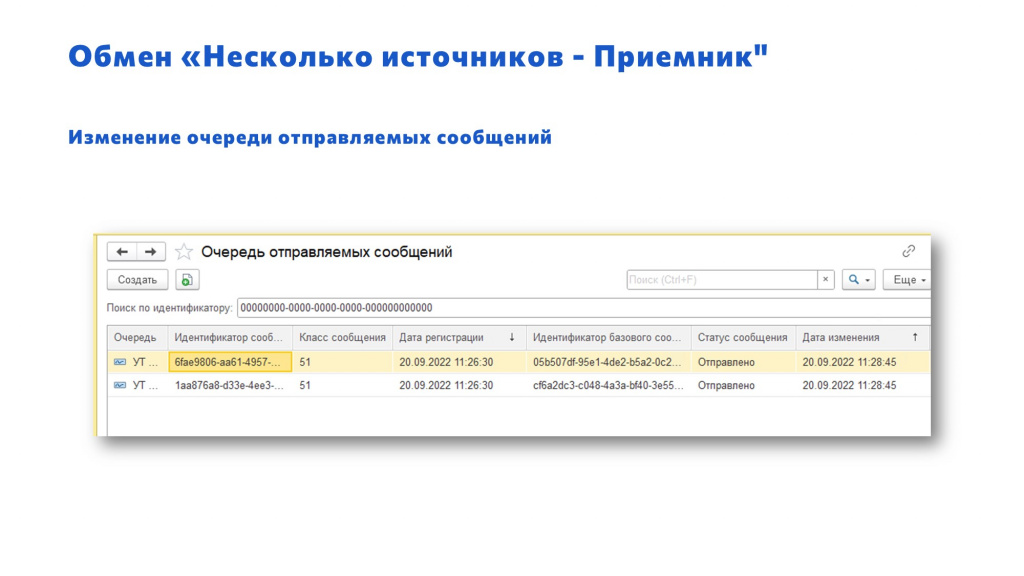
То же самое – для РС «ОчередьОтправляемыхСообщений».
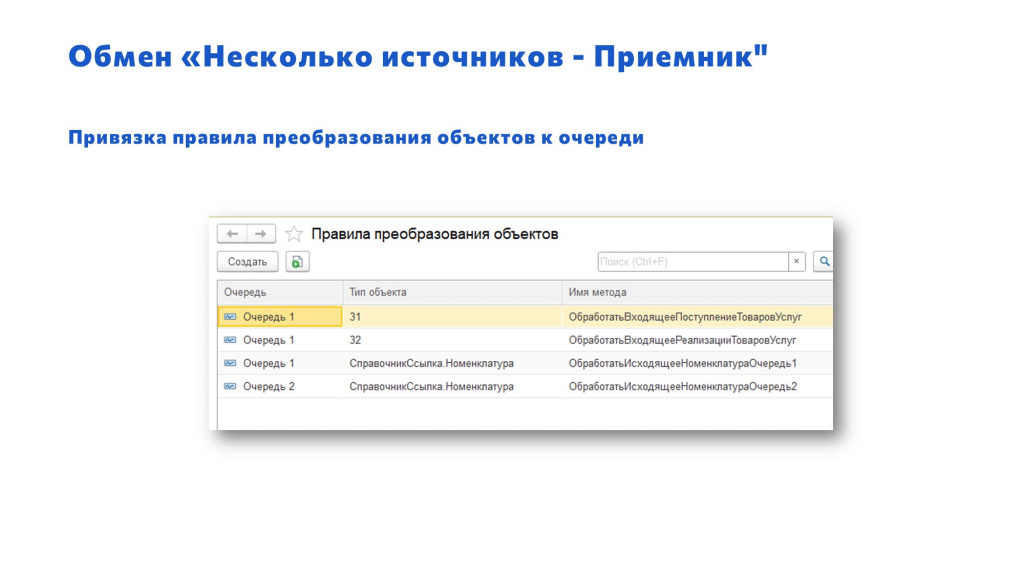
Дополнительно привязываем к очередям наши правила преобразования объектов.
Обратите внимание, что привязка идет:
-
как к типам, которые мы получаем – на слайде «31» и «32»;
-
так и к типам объектов внутри нашей 1С – когда у нас есть СправочникСсылка, мы можем хранить отдельные правила преобразования для Очереди1 и для Очереди2.
Доработки, которые нужны для RabbitMQ
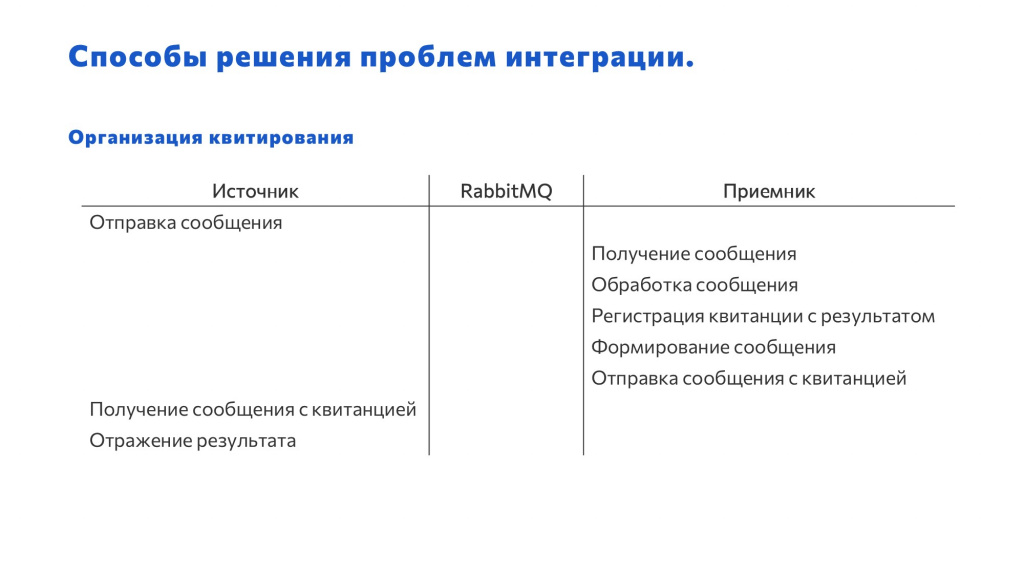
Расскажу о некоторых проблемах, которые могут возникнуть:.
Организация квитирования. Квитирование в RabbitMQ есть: после получения и обработки сообщения мы ставим галку, что его приняли, и тогда источнику может улететь квитанция, но она стандартная.
Возможно, потребуется добавить несколько полей в это сообщение. Для этого можно использовать такую схему:
-
получили сообщение;
-
обработали;
-
зарегистрировали квитанцию (объект квитанции – это либо справочник, либо структура, либо что-то еще);
-
сформировали сообщение;
-
и отправили на сторону бывшего источника – а коллеги уже обработали и поняли, что не так.
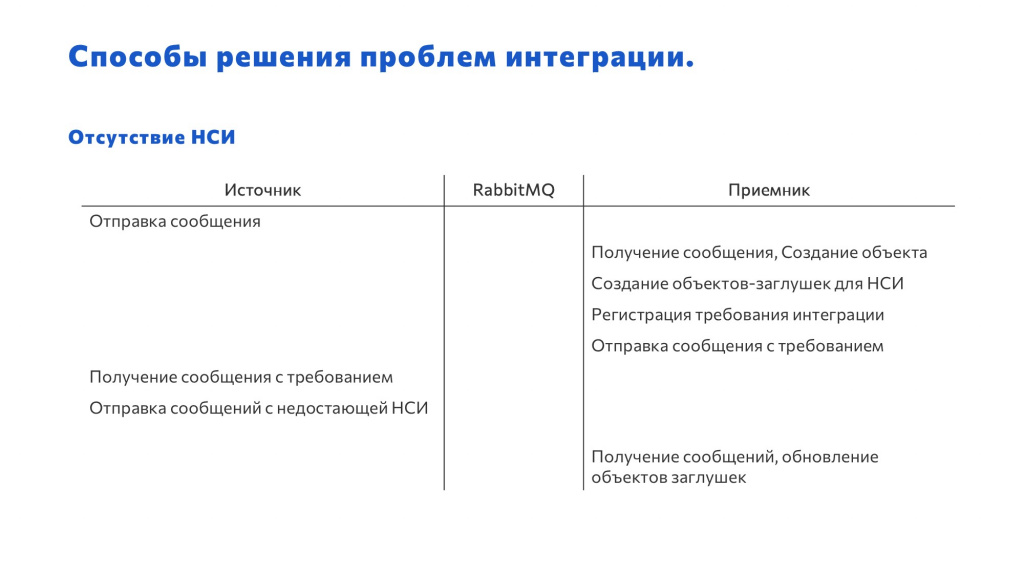
Еще одна проблема, с которой вы наверняка сталкивались – к вам пришел документ с отсутствующей у вас НСИ. Вместо того чтобы просто не грузить этот объект, можно поступить по-другому:
-
Получили сообщение.
-
На месте недостающих объектов НСИ создали объекты-заглушки.
-
Зарегистрировали некоторый объект «Требование интеграции» – вы можете создать такой РС или справочник.
-
И отправили это сообщение на сторону источника.
-
На другой стороне обмена нам потребуется реализовать обработку такого типа сообщений – когда к ним придет такое «Требование интеграции», нужно зарегистрировать к обмену недостающие объекты и их выгрузить.
-
Так как мы договорились о типах, мы для НСИ, которую мы не нашли, указываем уже не просто идентификатор, но и еще тип объекта.
-
И когда коллеги нам отправляют сообщение с этой недостающей информацией, наши объекты-заглушки обновляются, и наш документ выглядит полноценно.
Третья проблема, которая здесь не обозначена, но я с ней буквально недавно столкнулся – это проблема с зависанием фоновых заданий. Так как это подсистема 1С, обмены c RabbitMQ и обработку наших очередей стартуют фоновые задания. А они могут зависать.
Здесь я, к сожалению, не знаю другого способа этого избежать, кроме как написать внешнее приложение, которое будет дергать RabbitMQ и через HTTP либо через COM класть сообщения в наш РС «Очередь» в 1С. Но это уже опять же на ваше усмотрение.
Вопросы и ответы
Был ли у вас опыт встраивания в типовой обмен 1С обработку транспорта для RabbitMQ?
Нет, такой задачи у меня не было, но это вполне реализуемо.
Как бороться с копиями баз?
Достаточно просто. Чаще всего в системе заводят некоторую константу – путь к базе. Когда путь к базе сменился, мы считаем, что это копия.
А что делать с админами, которые любят путь к базе через айпишник прописывать?
Обидеть админов… Возможно, здесь Service Discovery поможет.
Решений миллион. Самое простое – прописать путь базе. Если админы переместили базу, обмен встал, значит что-то не так – пошли разбираться, выяснили, что база переехала.
Если создали копию, путь поменялся, обмен встал – там он и должен встать.
На стороне RabbitMQ какой-нибудь плагин для валидации входящих форматов данных не пробовали?
Нет, не пробовали, потому что даже если мы напишем схемы для валидации, они будут работать до первой ошибки.
Если вы хотите генерировать полноценное сообщение об ошибке, вам придется реализовывать эту проверку либо полностью на стороне 1С, либо писать этот валидатор отдельно – предварительно отправлять данные на него, получать список ошибок, отправлять дальше сообщения.
У меня вопрос про инфраструктуру под RabbitMQ. Если у нас сотни источников и потребителей, вы рекомендуете использовать выделенный хост под RabbitMQ? Или все-таки можно с чем-то его установить? Например, СУБД. Я сейчас утрирую, конечно. Может быть есть рекомендации по операционной системе и так далее?
Нужно смотреть, какая нагрузка вас нагрузка пойдет на RabbitMQ. Я админ ненастоящий, я только некоторые вещи знаю.
Если мы знаем, что у нас при обмене за минуту будет выгружаться 10 сообщений, то, в принципе, можете разместить его вместе со своим сервером MS SQL, PostgreSQL – это неважно.
Но если у вас обмен высокоинтенсивный, он не должен падать и не должен зависеть ни от чего, тогда стоит выделить под RabbitMQ отдельный сервер.
В этом проекте RabbitMQ был просто помещен в контейнер Kubernetes. Если нам нужно увеличить масштабируемость обмена, добавляется дополнительный контейнер, и все становится лучше.
Для хранения очереди сообщений RabbitMQ использует какую-то свою небольшую встроенную СУБД или ему нужно все-таки что-то еще отдельно ставить – PostgreSQL, например?
RabbitMQ имеет встроенные механизмы хранения данных на диске, ему не нужна отдельная СУБД.
Есть ли для RabbitMQ какие-нибудь плагины, чтобы мониторить длину очереди или что-нибудь такое? Чтобы мы смотрели и понимали, не происходит ли что-то уже внутри RabbitMQ.
Сам сервис RabbitMQ контролирует длину очереди и может передавать данные – в том числе, в Zabbix.
Когда вы говорили про структуру сообщений, вы говорили, что служебную информацию записываете в тело сообщения. При этом сам протокол AMQP поддерживает заголовки и свойства сообщений. Компонента PinkRabbitMQ запись в заголовки и свойства сообщений поддерживает. Почему вы их не используете? Это как раз позволяет вытащить из тела эту служебную информацию, быстро искать по ней, не заглядывая в тело и так далее.
Я понимаю, что такая возможность есть. Но здесь кому как удобнее.
В нашей подсистеме служебные поля выделены прямо в само сообщение, потому что само сообщение у нас хранится в базе. Мы получили это тело сообщения, сохранили его, при необходимости открыли и увидели, что там внутри.
А при подходе, когда часть хранится в заголовках сообщения RabbitMQ, а часть в теле нашего сообщения, которое попадает в 1С, при получении сообщения нам это сообщение придется склеивать.
Это не баг, это фича. Нам не нужно парсить большой XML, чтобы узнать, от кого это сообщение или его дату. Нам достаточно просто прочитать реквизит – для этого и задумывалось.
Действительно, так сделать можно, но в нашем случае это было не нужно.
Когда вы показывали скриншоты, я там увидел подписку на событие – видимо, при записи документа происходит его регистрация в очереди. А как вы ставите регистры на регистрацию к механизму обмена?
В моем текущем проекте нет обмена данными регистров – есть только документы и справочники.
Для регистров можно в поле Object класть не ссылку на объект, а непосредственно данные в виде хранилища значений.
Вы подписались на изменение записи регистра и в регистр ОчередьЗарегистрированныхОбъектов кладете в поле Object уже непосредственно сами данные, которые хотите конвертировать в дальнейшем.
Но тогда же нам по два сообщения будет вылетать, если мы это подключим к подписке? Когда мы записываем набор записей, у нас сначала пустой набор записывается, потом уже какой-то набор записей.
Нужно прописать, что если набор записей пустой, не регистрировать сообщение.
У меня вопрос по метрикам вашего проекта. Сколько сообщений проходит в час, минуту, сутки? Какое количество сущностей вы передаете? Смотрели ли вы в сторону EnterpriseData – почему вы разрабатывали свой стандарт под XML, а не использовали уже готовый от 1С?
EnterpriseData не используется, потому что у нас система не только 1С, и для коллег проще обрабатывать XML в том виде, как я показывал на экране.
По сущностям, которые используются:
-
НСИ – порядка 15 видов;
-
документы – порядка 20 видов.
По количеству сообщений: в час порядка 10 тысяч RabbitMQ обрабатывает.
Даже когда на начальном этапе проекта у нас были сложности – то 1С подвиснет, то еще что-то произойдет – скапливалось по 90-100 тысяч сообщений. RabbitMQ их за 3-5 минут выкачивает, перекладывает в очереди внутри 1С, и постепенно начинается обработка.
Естественно, внутри вы можете определить приоритет – для обработки сообщений либо для работы пользователей.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.


Вступайте в нашу телеграмм-группу Инфостарт