Меня зовут Юлия Даскаль, я работаю ведущим разработчиком в Центре экспертизы 1С компании Magnit Tech.
Хочу рассказать о том, как нам удалось победить нашу боль и наладить работу с огромнейшими журналами регистрации.

Немного о ситуации в «Магните»:
-
У нас более 50 баз 1С, некоторые из которых имеют очень большие журналы регистрации.
-
Суммарно в месяц накапливается около 2 ТБ логов. Это просто огромнейший объем информации, в котором часто бывает сложно найти то, что нужно.
-
При таких объемах поиск одного события в стандартном журнале регистрации 1С может занимать больше часа. А нам такие скорости не подходят – для нас важно получать информацию максимально оперативно.
-
Кроме этого, регулярно возникают задачи, когда нужно сагрегировать данные – например, по событиям или по действиям пользователей – а стандартный журнал регистрации такой возможности не предоставляет.
Поэтому мы стали искать решение: анализировали рынок, изучали опыт других компаний, сравнивали инструменты – и в итоге остановились на ClickHouse.

ClickHouse – это колоночная СУБД, которая изначально была разработана в Яндексе для Яндекс.Метрики, а позже выделилась в отдельный проект, став доступной для всех.
-
ClickHouse распространяется с открытым исходным кодом под лицензией Apache License 2.0, что подразумевает бесплатное коммерческое использование.
-
Одна из ключевых особенностей ClickHouse – это колоночное хранение данных. В отличие от классических СУБД, где данные хранятся построчно, ClickHouse хранит информацию в колонках. Это существенно ускоряет выполнение запросов, поскольку система считывает только необходимые столбцы и отбрасывает ненужные данные.
-
ClickHouse поддерживает различные кодеки сжатия данных.
-
Индексы в нем построены так, что позволяют при выполнении запросов исключать из обработки ненужные блоки данных.
-
Еще одно преимущество – поддержка распределенных запросов «из коробки». Мы можем развернуть ClickHouse в кластере и выполнять запросы к данным различных серверов параллельно.
-
Кроме того, ClickHouse позволяет работать с данными практически в реальном времени – они доступны сразу после загрузки, не нужно ничего ждать и дополнительно обрабатывать.
-
И у ClickHouse более 30 видов движков хранения с различными особенностями записи, хранения и обработки данных. Поэтому критически важно правильно выбрать движок на этапе проектирования, поскольку это напрямую влияет на производительность при выполнении запросов.
-
Сфера применения у ClickHouse довольно широкая: это и хранение логов (как в нашем случае), и бизнес-аналитика, и мониторинг, и работа с Big Data.

У многих может возникнуть вопрос: почему ClickHouse, а не ElasticSearch? Мы тоже задавались этим вопросом, и окончательно определились после сравнения производительности этих двух систем, которое приводится в статье на Инфостарте – большое спасибо автору за подробный анализ.
Если коротко:
-
ElasticSearch отлично подходит для полнотекстового поиска.
-
Но в задачах агрегации ClickHouse значительно превосходит по скорости.
-
Кроме того, ClickHouse эффективнее сжимает данные, что обеспечивает более компактное хранение.
-
А еще ElasticSearch более ресурсоемкий, потому что вынужден дополнительно расходовать оперативную память для поддержания индекса полнотекстового поиска в актуальном состоянии.

ClickHouse идеально подходит для журнала регистрации 1С:
-
Колоночная структура ClickHouse не приспособлена к частым изменениям данных – стандартные операции UPDATE приводят к пересборке затронутых данных, а это ресурсозатратно и неэффективно. Но в случае с логами 1С нам и не нужно ничего менять – мы производим только сбор и хранение событий.
-
У журнала регистрации фиксированная структура полей, которую легко переложить на табличное хранение.
-
За счет того, что в журнале регистрации большинство полей содержат неуникальные и часто повторяющиеся данные, мы можем их эффективно сжимать в ClickHouse.
-
К тому же, журнал регистрации редко используется для полнотекстового поиска – нам, в основном, нужны отборы по конкретным полям. Даже если требуется отбор по полю комментария, достаточно поиска по подстроке.

Существует несколько способов выгрузки данных из 1С в ClickHouse.
-
Использование REST-интерфейса ClickHouse. Это базовый способ взаимодействия, но у него есть существенный недостаток – в этом случае нагрузка ложится непосредственно на сервер приложений 1С, а мы такие риски себе позволить не можем, так как логи у нас достаточно большие.
-
Подключение через ADODB – этот вариант, к сожалению, тоже не подходит, поскольку не поддерживает кроссплатформенность.
-
Различные готовые решения из репозиториев на GitHub – с ними тоже, к сожалению, часто случаются проблемы:
-
Такие инструменты сложно поддерживать и изменять, потому что они написаны на различных языках, для которых у нас не всегда есть необходимые компетенции.
-
Часто нет документации, или она недостаточно информативная.
-
Нет возможности настраивать и распараллеливать нагрузку на разбор.
-
И, к сожалению, часто бывает низкая производительность.
-
-
Специализированное ПО, которое забирает логи из одного источника, преобразует в нужный формат и отправляет в целевую систему – к таким инструментам относятся, в частности, Vector и Fluent Bit.
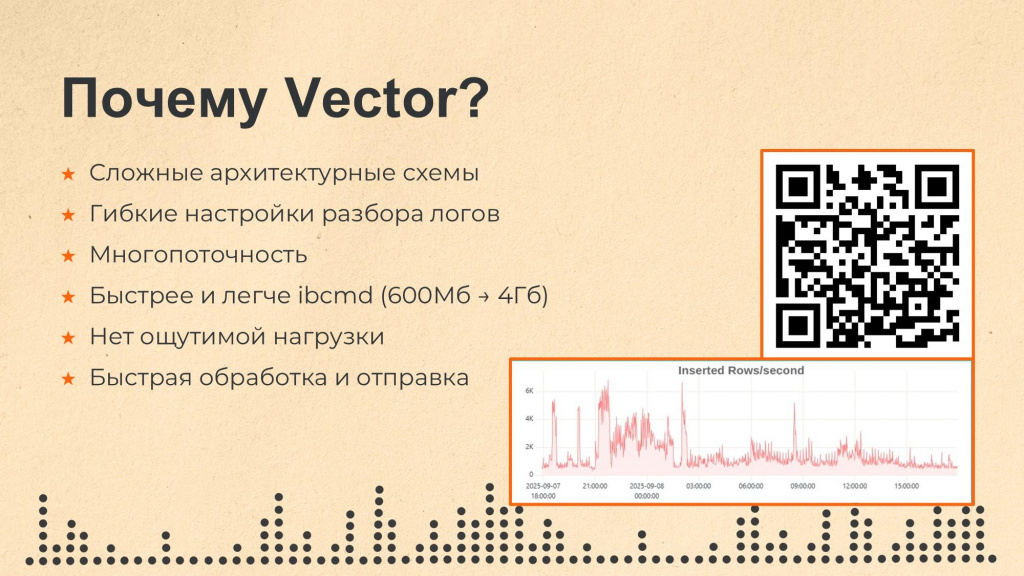
В итоге мы выбрали Vector, потому что у него есть ряд серьезных преимуществ:
-
Поддержка сложных архитектурных схем – возможность подключать различные очереди и дополнительные инстансы, переносить нагрузку с сервера приложений 1С на отдельный сервер.
-
Широкие возможности по разбору и трансформации логов – для Vector можно написать собственные правила для парсинга и преобразования полей в нужный формат, управлять логикой обработки и структурой итоговых данных.
-
Многопоточность – Vector способен отправлять данные в разные системы одновременно. Например, мы одним и тем же процессом Vector на одном сервере отправляем данные журнала регистрации в ClickHouse, а данные технологического журнала – в OpenSearch.
-
По сравнению с ibcmd (утилитой администрирования автономного сервера) Vector работает быстрее, и итоговый файл логов получается значительно меньше по весу – например, исходный файл логов весом 600 МБ после трансформирования через ibcmd начинает весить 4 ГБ. Это связано с тем, что ibcmd заменяет в итоговом файле логов все идентификаторы на представления – за счет этого файл пухнет и становится очень большим. Подробнее об этих особенностях и сравнении ibcmd с Vector можно прочитать в статье на Инфостарте.
-
Нет ощутимой нагрузки. Например, у нас Vector развернут на сервере приложений 1С и несмотря на огромные объемы разбираемых логов – до 6000 записей в секунду (в среднем около 1500) – заметного влияния на производительность не наблюдается.
-
Быстрая обработка и отправка данных. Среднее время обработки логов – от появления события в журнале регистрации до его попадания в ClickHouse – максимум 3 минуты, а часто и меньше.
Подробнее о нашем опыте работы с Vector рассказал Александр Леонов.
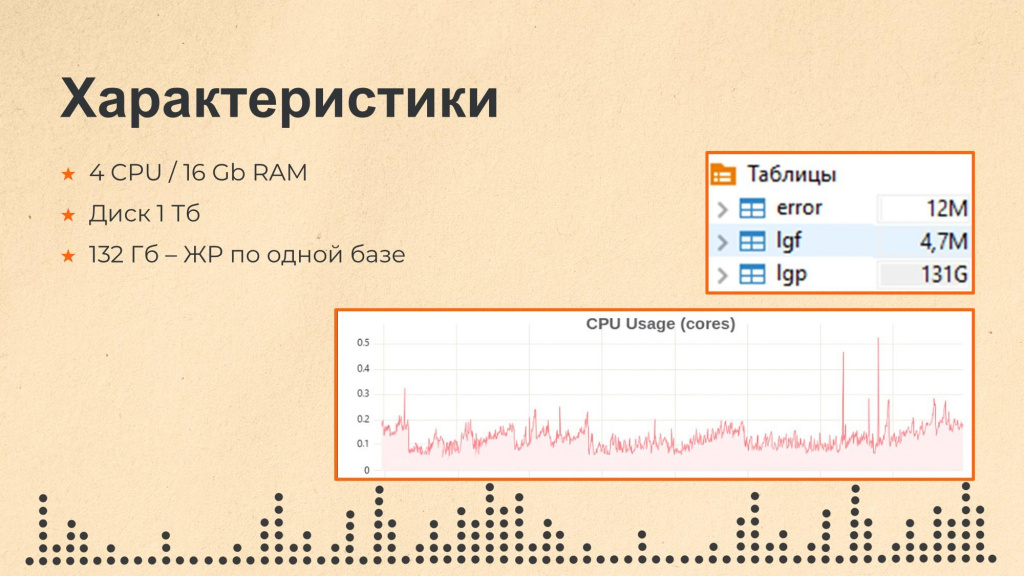
Сервер для ClickHouse у нас имеет следующие характеристики:
-
4 ядра CPU.
-
16 ГБ оперативной памяти.
-
Диск объемом 1 ТБ.
Справа показана структура таблиц журнала регистрации по одной из баз. В ClickHouse у нас хранятся данные журнала за год, всего они занимают 132 ГБ, из них больше всего – в таблице lgp. При этом сама исходная база данных, из которой собирается этот журнал регистрации, занимает около 80 ТБ.

Расскажу подробнее про структуру таблиц.
-
В таблице error хранятся ошибки парсинга файла логов – например, если при парсинге Vector не смог корректно обработать и загрузить запись журнала в основную таблицу, информация об ошибке попадает сюда.
-
В таблице lgf хранятся идентификаторы ссылок, используемые в основной таблице логов, и их текстовые представления. Благодаря тому, что в основной таблице логов используются именно идентификаторы, удалось сократить ее объем примерно на 30%. При этом за получение журнала регистрации в человекочитаемом виде приходится «платить» – соединяться с этой таблицей и получать все представления.

-
Таблица lgp – основная, в ней хранятся абсолютно все события журнала регистрации, поэтому она и занимает больше всего места в базе. На слайде показаны топ-5 наиболее частых событий – видно, что на первом месте событие _$Data$_Update, апдейты данных.

Кроме этого, у нас есть две таблицы материализированных представлений (MatView), в которые сохраняются результаты запросов для ускорения доступа к данным.
-
mv_lgp_minute – содержит уже сагрегированные данные в разрезе минут. Далее я расскажу подробнее, для чего мы так сделали.
-
mv_session – хранит информацию о пользовательских сессиях с датой начала и датой окончания.
Теперь о том, какими способами можно получить обработанные данные из ClickHouse обратно в 1С.
-
Через внешние источники данных – но это требует настройки сервера приложения 1С.
-
Через COM или ADODB – у нас в компании этот способ запрещен, в частности, из-за отсутствия кроссплатформенности и из-за того, что различные базы используют различные версии платформы, и это тоже накладывает свои сложности.
-
Напрямую через REST API ClickHouse – это наиболее удобный и гибкий способ, и именно его мы и использовали.
Для получения через REST API обработанных данных из ClickHouse мы написали обработку, которая может использоваться в любой конфигурации. В ней можно формировать отчеты, настраивая для них различные отборы; сохранять и выбирать варианты; заменять GUID на человекочитаемые представления.
Основная цель этой обработки – это работа с журналом регистрации в 1С таким же образом, как и со стандартным журналом регистрации.

Но если нам нужно получить из ClickHouse более сложные агрегации, мы обращаемся к другим инструментам:
-
Например, у ClickHouse есть веб-интерфейс в браузере – там можно выполнять любые SQL-запросы.
-
Можно подключить базу ClickHouse к DBeaver – он также позволяет просмотреть структуру таблиц, узнать их размер и выполнить любые сложные запросы с агрегациями.
-
Можно читать данные из 1С через REST API – для этого мы, в частности, используем нашу обработку.
-
Или подключиться к ClickHouse напрямую из Grafana, чтобы тоже выполнять там запросы или анализировать данные на дашбордах.

Теперь о том, как мы используем наш журнал регистрации в ClickHouse.
-
Мы разбираем инциденты ИБ – смотрим, кто изменил тот или иной элемент справочника, зашел под админскими правами или что-то удалил, в общем, сделал что-то не так. Раньше это было очень сложно: приходилось восстанавливать журналы регистрации из архива, подключать их к 1С, настраивать отборы, долго ждать (около часа). А если сразу разобраться не получалось или требовалось проверить еще какие-то гипотезы, приходилось делать все это заново. Сейчас сотрудники сопровождения используют готовый запрос к ClickHouse, меняют параметры на нужные и за 30 секунд получают результат. Они очень рады.
-
Статистика работы пользователей – мы можем анализировать производительность сотрудников: кто сколько создал документов, сколько создал элементов справочников.
-
Дашборды в Grafana – дальше я покажу их и расскажу, как мы их используем.
-
И анализ демографии данных – при запуске новых интеграционных потоков часто требуется оценить: какие данные чаще всего изменяются, как часто, в каком объеме и сколько среди них уникальных значений. На слайде как раз показано, что когда мы собирали демографию данных из журнала регистрации стандартными средствами – без детализации до объектов, без сбора уникальных записей – это занимало около часа. Сейчас же демография данных у нас считается по уникальным записям и занимает примерно 15 секунд.
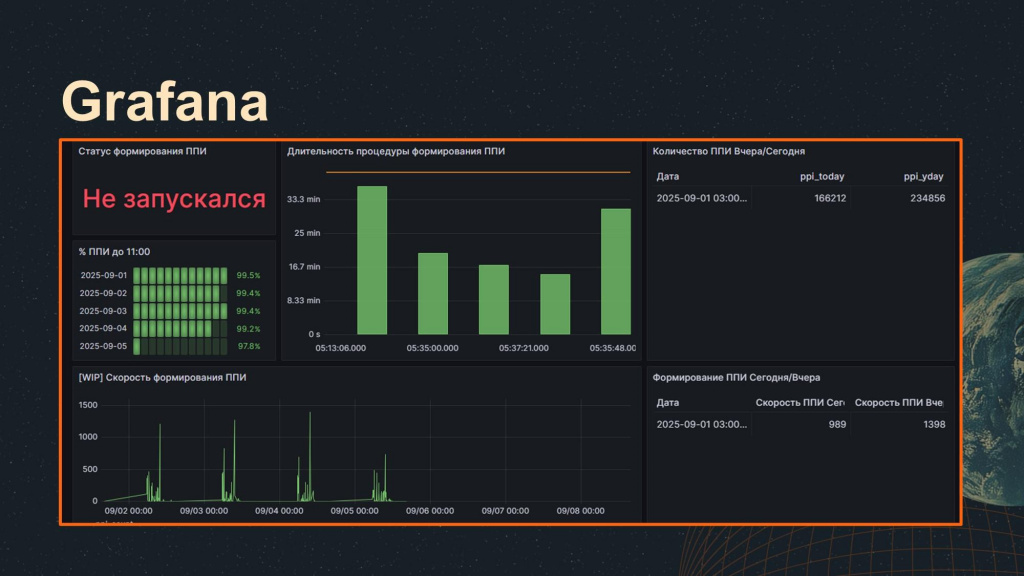
Вот так выглядят наши дашборды в Grafana.
Удобно, что Grafana интегрируется с ClickHouse напрямую – ей не нужны никакие прослойки. Заходим в интерфейс, пишем запрос, получаем данные и можем их визуализировать.
Анализируя данные журнала регистрации, мы можем отслеживать наличие или отсутствие определенных событий, видеть их длительность и интенсивность, оценивая число новых документов в час или в минуту, контролировать различные показатели системы.
Однако при построении некоторых дашбордов мы столкнулись с проблемой производительности: часть визуализаций не успевала выполняться и завершалась по таймауту.
Для решения этой проблемы мы добавили материализованное представление mv_lgp_minute, которое содержит уже сагрегированные данные в разрезе минут. Теперь запросы выполняются не к «сырым» данным, а к предварительно агрегированным, что позволяет ускорить формирование визуализаций и стабилизировать работу дашбордов.

А материализованное представление mv_session мы используем для отслеживания критически важных событий – например, чтобы знать о входе пользователя под админскими правами или о возникновении ошибки в одном из ключевых процессов.
Дело в том, что ClickHouse не поддерживает триггеры в классическом понимании. Однако есть альтернативные решения:
-
Использовать материализованное представление и через него передавать данные в классическую СУБД – PostgreSQL, MySQL, MS SQL – а там уже можно использовать триггеры.
-
Настроить отправку из материализованного представления в Kafka и подключить внешний скрипт для обработки очереди. На GitHub вы можете скачать пример реализации такого триггера: при появлении определенных событий через Materialized View данные отправляются в Kafka, после чего внешний скрипт считывает сообщения из очереди и выполняет необходимые действия – например, отправляет информацию в Sentry и уведомляет о событии через Telegram или email.
-
Настроить триггеры на стороне Grafana – задать критические значения показателей и реагировать на их превышение.
Таким образом ClickHouse позволил нам превратить журнал регистрации из проблемы в источник новых возможностей.
Вопросы и ответы
Что такое демография данных и для чего она используется?
Анализ демографии данных требуется при проектировании новых интеграционных потоков. У нас большие базы, и при запуске интеграции важно понимать реальный объем изменений, чтобы правильно выбрать инструмент.
Например, мы знаем, что за день у нас было 80 000 изменений документов. Но при анализе выясняется, что уникальных объектов – всего 10 000. Это означает, что фактически нужно передавать не 80 000 записей, а 10 000. Соответственно, можно выбрать более экономичный сценарий выгрузки – например, выполнять ее пакетно в конце дня.
Из стандартного журнала регистрации на наших объемах запросов было невозможно получить количество уникальных записей – запрос просто падал. Сейчас такой расчет занимает около 15 секунд вместо часа.
Что такое материализованное представление?
Материализованное представление задает запрос с правилами обработки данных, поступающих в исходную таблицу. При добавлении новых записей ClickHouse автоматически применяет этот запрос и сохраняет результат в отдельной таблице.
В нашем случае при вставке данных в исходную таблицу они автоматически агрегируются и сохраняются в таблице материализованного представления. В дальнейшем эти заранее подготовленные данные можно переиспользовать.
Вы сказали, что в ClickHouse более 30 движков хранения для таблиц. Какой движок вы в итоге используете?
Для основных таблиц у нас в ClickHouse используется движок MergeTree – он самый распространенный и универсальный, покрывает большую часть задач.
Насколько оправдано вынесение представлений в отдельную таблицу и использование соединений, вместо того чтобы обогащать основную таблицу?
Это осознанное решение, за счет которого мы смогли сократить основную таблицу примерно на 30%, потому что ClickHouse эффективнее сжимает короткие идентификаторы, чем текстовые представления.
Да, для получения человекочитаемого вида приходится выполнять соединения, но экономия объема это оправдывает.
Вы сказали, что в качестве движка, который загружает логи в ClickHouse, выбрали Vector. Чем вас не устроили Fluent Bit или Fluentd?
По сравнению с Fluent Bit Vector требует меньше ресурсов и значительно производительнее. К тому же Vector позволяет реализовывать сложные архитектурные схемы, описывать правила преобразования. В нашем случае это критично, поскольку у нас большие объемы логов.
Мы для выгрузки в ClickHouse используем экспортер от Евгения Акпаева, и у него есть проблема: если в журнале регистрации возникает событие «журнал регистрации поврежден», он перестает его читать и экспортировать. У Vector нет таких проблем? Или у вас журнал никогда не повреждается?
Vector корректно обрабатывает ошибки. Если при разборе возникает проблема, запись попадает в таблицу errors, откуда ее можно дополнительно проанализировать и обработать.
У вас Vector крутится как сервис на каждом сервере приложений 1С? Или где он вообще находится?
Да, Vector запущен на той же машине, что и один из серверов приложений 1С. И несмотря на наши большие объемы данных, он не оказывает существенной нагрузки на систему. Поэтому пока нам достаточно. А вообще у Vector есть возможности для масштабирования, и в дальнейшем мы можем его вынести отдельно или развернуть на несколько серверов.
Вы на каждую базу 1С создаете отдельную базу в ClickHouse?
Да, для каждой базы 1С у нас отдельная база в ClickHouse.
Как вы подключаете новые базы ко всему этому конвейеру?
Мы создаем базы и их таблички в ClickHouse вручную. Никакой автоматизации в этом плане пока нет. Но да, в дальнейшем мы планируем перейти на подход Infrastructure as Code и использовать шаблонные конфигурации с переменными окружения.
Что происходит с исходными файлами журнала регистрации 1С после того, как вы их экспортируете в ClickHouse?
У нас есть отдельные регламенты, которые по прошествии определенного периода времени уже чистят этот журнал. Но в момент, когда событие отправляется в ClickHouse, с данными журнала регистрации ничего не происходит
А чистите как, кодом? Или через команду Сократить для журнала регистрации в конфигураторе?
Нет, просто удаляем файлы.
Но для удаления файлов журнала нужно же останавливать службу в 1С. Останавливаете? Или можно на лету как-то удалить?
Останавливаем. И удаляем, используя пакетный режим конфигуратора с параметром запуска ReduceEventLogSize.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт