Как часто у вас получается сразу начать тестировать свой код? Обычно сначала тратишь полчаса на подготовку тестовых данных, проверяешь их, потом понимаешь, что чего-то не хватает, нужно допилить и подготовить еще, и в итоге уходит гораздо больше времени, чем на написание самого кода. Ситуация знакомая? Мне – да. Постараемся с ней разобраться и найти решение.
В этой статье я расскажу про подходы к тестовым данным, инструменты для работы с ними и дам советы разработчикам.
Я работаю с 1С более 13 лет. Пару лет назад я погрузился в юнит-тестирование подробно и плотно: изучил тему, написал регламенты, документацию, обучил свою команду и сейчас делюсь экспертизой с соседними командами нашего департамента. За это время я понял, что самый большой и проблемный пласт в юнит-тестировании – подготовка тестовых данных. Оказалось, что написать тест – не проблема. Одна из самых больших сложностей на данный момент – подготовить нормальные и качественные тестовые данные.
Я расскажу о своих наблюдениях и опыте, а также покажу инструмент, который позволяет удобно генерировать код создания тестовых данных.
Контекст системы и архитектура тестирования
Немного контекста о нашей системе. Это одна из самых высоконагруженных баз компании. Ее размер более 10 терабайт. Команда разработки, которая занимается доработкой, состоит из 15 человек. Конфигурация на обычных формах, основана на управлении корпоративными финансами (УКФ).
У нас много интеграций: Kafka, HTTP, используем хранимые процедуры, деплоим и тестируем все с помощью GitLab CI.

Приложения состоят из нескольких слоев по заветам чистой архитектуры Роберта Мартина:
-
Пользовательский интерфейс,
-
Бизнес-логика,
-
Слой доступа к данным,
-
База данных.
В 1С-тестировании нам помогает Vanessa Automation для проверки пользовательского интерфейса; для бизнес-логики используется YaxUnit; слой доступа к данным и саму базу данных тестирует вендор, и эту часть мы не проверяем.
Если говорить конкретно о юнит-тестировании, то главное – понимать, что мы не тестируем работу с базой данных, работу с ролями и пользовательский интерфейс. Мы тестируем только написанную нами бизнес-логику. Из базы мы получаем структуры и коллекции, обрабатываем и перекладываем их, и именно эту логику мы проверяем юнит-тестами. Мы должны убедиться, что преобразование данных и логика их обработки сохраняются. Упрощая: как говорят в других языках, важно убедиться, что перекладка из одного JSON в другой работает корректно.
Три подхода по работе с тестовыми данными
Подходы к юнит-тесту – тема не такая простая, как может показаться на первый взгляд. Можно взять копию прода и подумать, что все будет хорошо, но на самом деле это не так.
Подход 1: Специальный стенд с эталонными данными
Первый подход – это работа со специальным стендом. Создаем пустую базу, настраиваем в ней какие-то основные процессы, готовим тестовые данные руками и при появлении новых процессов или каких-то версий данных мы их вносим туда и получаем эталонную систему для того, что можно тестировать.
При необходимости тиражируем базу. Это маленький легкий продукт, который позволяет нам проводить какие-то дополнительные манипуляции с ней.
Давайте рассмотрим плюсы и минусы данного подхода.
Из плюсов:
-
Все актуальные процессы всегда в одном месте. Это документация, это система, на которую можно гонять тесты, это демостенд, который можно использовать по назначениям, названным ранее.
-
Это легкая база, которую можно запускать как локально, так и на сервере.
-
Это полностью контролируемая среда команды разработки, либо команды аналитиков, которая занимается внесением.
Но есть и минусы:
-
Скорость актуализации данных. У вас появляется новый процесс, аналитик бежит внедрять его, рассказывает про него пользователям, пишет документацию, и до этой базы дело может не дойти. Плюс размазывается ответственность. Кто должен вносить эти данные? Разработчик? Он не отвечает за процессы. Аналитик? Когда? Тестировщик? Тоже непонятно по времени, когда и сколько нужно дополнять данных.
-
А также это дорого. Это время на актуализацию, на удаление старых данных, на подготовку этих данных.
Если мы говорим про учетную систему такую, как наша, для того, чтобы внести туда огромное количество данных, нужно изрядно попотеть.
Если же мы говорим про какую-то маленькую библиотеку, которая использует небольшой объем данных (например, тот же YaxUnit), то там есть небольшая база, в которой содержится необходимая информация для тестирования продукта. В этом случае этот подход может быть оправдан.
Для разработчика работа со специальным стендом – это идеальный вариант. Потому что актуализацией данных скорее всего будет заниматься не он. Он ничего не делает, получает готовый продукт, на котором пишет юнит-тест и не тратит время на подготовку этих данных.
Подход 2: Копия продуктовой базы
Второй вариант – копия продуктовой базы, про которую я уже рассказывал. Бэкапим прод, разворачиваем на тестовом контуре нужное количество баз и запускаем тесты.
У нас этот подход используется для части тестов: берутся не полноценные актуальные копии, а diff-копии или copy-on-write, чтобы запускать, например, дымовые тесты.
У копии продуктовой базы есть и плюсы, и минусы.
Плюсы:
-
Это самая простая реализация. Каждый может это сделать. Если у вас файловая база – скопировали DT и развернули. Если у вас SQL-база – скопировали средствами SQL и развернули. Все знают и умеют с этим работать.
-
В такой копии есть все необходимые данные, которые нужны для юнит-тестов. За актуализацией данных следит пользователь: не разработчики, а аналитики. Там хранятся все данные по актуальным процессам и немного исторических.
Из минусов:
-
Этот подход подходит только для небольших баз. Что я подразумеваю под небольшими базами? Наша база – 10 терабайт, и она не самая большая. У коллег база – 92 терабайта, и развернуть ее достаточно быстро для тестирования не получается. Есть нюансы и ограничения.
-
Учетным данным нельзя доверять. Учетные данные – это данные, которые вводят пользователи и сопровождает support, то есть команда сопровождения может вносить нужные для бизнеса данные руками. Это ручные операции и обработки, которые не предусматривают работу с бизнес-логикой. Не самое плохое, что может произойти, – ваши тесты упадут с такими данными. Хуже, если тесты пройдут и покажут положительный результат. Это ложноположительный результат, который пропустит ошибку в прод, а на новых данных, введенных корректно, будет допущена ошибка, которая может стать критичной.
-
Неконтролируемая среда, которая не поддерживается разработкой и командой аналитики. Данные вносятся со всех сторон, support и пользователи могут внести туда чуть больше или чуть меньше, и ваши тесты будут падать, что создает дополнительные проблемы. С точки зрения разработчика этот вариант самый простой: он ничего не делает, он просто получает готовые данные, которые можно переиспользовать.
Подход 3: Создание тестовых данных под каждый тест
Третий подход по работе с тестовыми данными – это создание тестовых данных под каждый тест. Я считаю его самым предпочтительным, потому что он позволяет запускать тесты самостоятельно, без каких-либо дополнительных приседаний, будь то специальный стенд или копия продуктовой базы. Данные можно создавать кодом, загрузкой из макетов или другими удобными для вас способами. Самое главное, чтобы данные были созданы в полном объеме, чтобы тест работал самостоятельно и в вакууме.
Плюсы:
-
Полностью контролируемая среда, которая позволяет разработчику имитировать любую ситуацию на любой базе, не тратя время на придумывание дополнительных манипуляций.
-
Независимость от базы: вы можете запустить тесты на специальном стенде, на копии прода, на пустой базе, потому что все данные создаете во время работы.
-
Версионируемость тестовых данных. Если это макет, если это код, вы можете версионировать их в GitLab либо в хранилище, если макеты прикладываете непосредственно в свою конфигурацию.
Но у этого подхода есть и минусы:
-
Долгая подготовка тестовых данных: нужно создать достаточно большое количество кода, либо выгрузить достаточно большое количество данных, чтобы работать с ними.
-
Код создания нужно поддерживать: это может быть миграция, загрузка из макетов и другие операции. Это трудоемкая и долгая работа.
В этом подходе больше всего страдает разработчик. Вся подготовка и вся работа с тестовыми данными ложится на него. Он должен это делать, он должен все готовить, поддерживать и актуализировать эти данные.
Рекомендации по выбору подхода
Нет идеального варианта, нет серебряной пули, которая решит все задачи. Я рекомендую использовать разные подходы для разных задач. Например, для дымовых тестов подойдет вариант с копией прода. Для юнитов, для маленькой конфигурации по типу библиотеки, можно подготовить специальный стенд и использовать его. Для большой учетной системы подойдет вариант с подготовкой тестовых данных на копии прода и генерации этих тестовых данных с помощью кода.
Для дымовых тестов подойдет копия: там есть все данные, можно прогонять дымовые тесты по открытию форм и проведению документов. Данные уже имеются. Если произойдет ошибка из-за большого количества данных и случайности выборки, вероятность этого мала и не особо аффектит результат тестов.
Для юнит-тестов библиотек – эталонная база.
Для юнит-тестов учетных систем – сочетание подходов: backup и создание тестовых данных с помощью кода.
Инструменты для упрощения работы с тестовыми данными
Выгрузка данных (XML/JSON и др.)
Как упростить работу с тестовыми данными для разработчика? Первый вариант – использование выгрузок данных. Самый простой инструмент – универсальный обмен данными в формате XML. Он простой и понятный, все умеют с ним работать, но есть нюансы. Можно выгрузить тестовые данные и вместе с ними полбазы, забыв снять настройки. Если без шуток, подойдет любой механизм сериализации и десериализации, который используется у вас в компании и который вы написали не специально для тестов.
Вы выгружаете тестовые данные в XML, JSON, прикладываете их к тестам, можете настроить зависимости, сложить их в GitLab и там хранить либо использовать тестовое расширение. Выгружается необходимый минимум информации, нужный для теста. Это могут быть НСИ, настройки, документы или состояние системы на нужный момент.
Но нужно решить несколько вопросов:
-
Где хранить выгруженные данные? GitLab, хранилище, расширение – этот вариант вы выбираете сами.
-
Какой механизм использовать? Чем выгружать и чем загружать данные.
-
Как проводить актуализацию и миграции данных? Если поменялась структура метаданных, как заполнить новые реквизиты актуальными данными, как изменить состояние данных в выгруженных макетах.
Плюсы использования выгрузок данных:
-
Простой и понятный инструмент. Он есть у всех, у кого есть интеграция, можно использовать уже существующий инструментарий.
-
Данные можно версионировать, если хранить макеты или данные в системе версионирования.
Минусы:
-
Сложность в актуализации и миграции данных: нужно постоянно поддерживать данные при активной разработке, на это тратится много времени.
-
Можно ошибиться и выгрузить половину базы – это отсылка к универсальному обмену в формате XML, который есть у всех.
-
Сложная структура данных при выгрузке в XML: нельзя просто зайти в GitLab и вручную поправить макет, чтобы он заработал и тесты прошли, нужно знать структуру и тратить на это время.
-
Если говорить про подготовку тестовых данных, тесты должны быть быстрыми, но при загрузке из макетов можно потратить много времени на десериализацию. Если при каждом тесте вы загружаете данные из макета, может потребоваться большой объем времени.
-
После тестов база становится «грязной», нужно очищать данные либо перевосстанавливать базу. Для маленькой базы это приемлемо. Для большой базы тратится много времени – от нескольких часов до целых дней.
Хранение данных в коде (через YaxUnit)
Второй вариант, который я предлагаю – хранение данных в коде метаданных. Этот вариант самый предпочтительный. Он использует механизмы фреймворка YaxUnit и позволяет создавать тестовые данные во время тестов или перед ними, а также удалять эти данные после выполнения тестов. Все это фреймворк делает из коробки.
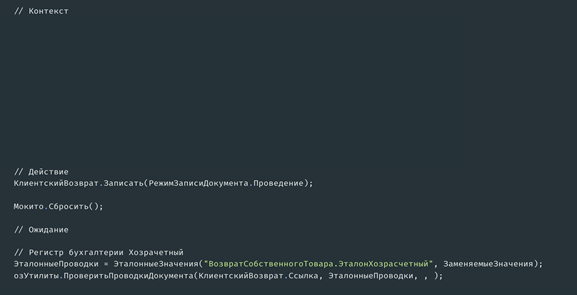
Здесь используется паттерн AAA: подготовка, действие и проверка. Сначала мы описываем общий алгоритм написания теста: пишем «рыбу», затем часть с проверкой, затем часть с подготовкой и проверкой ожиданий.
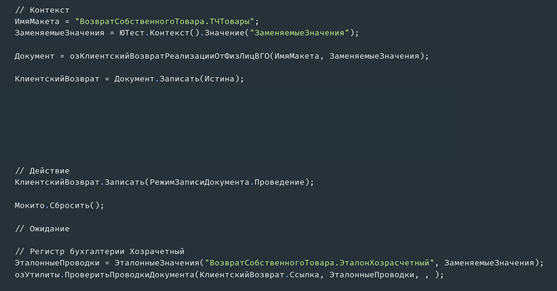
Дальше пишем подготовку тестовых данных, запускаем тест, тест падает. Не понимаем причину, начинаем разбираться.
Код подготовки тестовых данных, который мы написали, выглядит большим, мы потратили время.
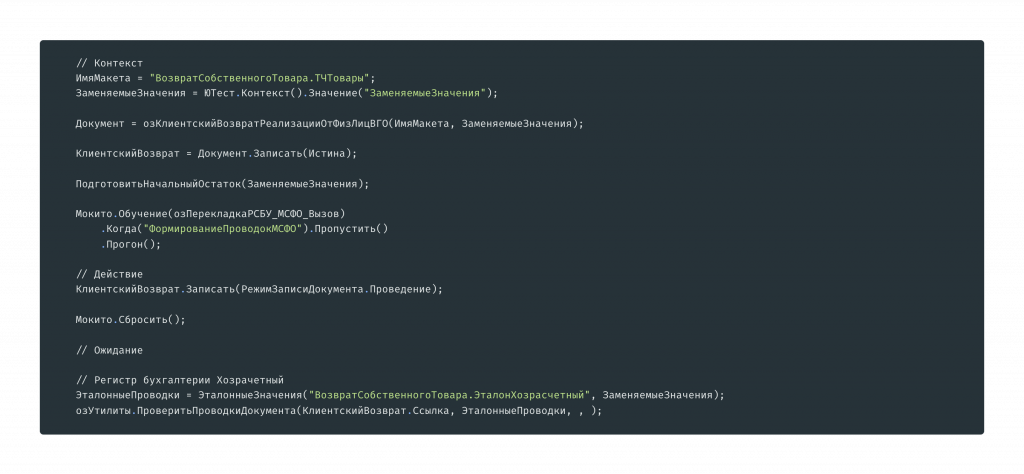
Дальше пытаемся разобраться, что происходит, пишем еще один код подготовки тестовых данных, понимаем, что не подготовили начальные остатки.
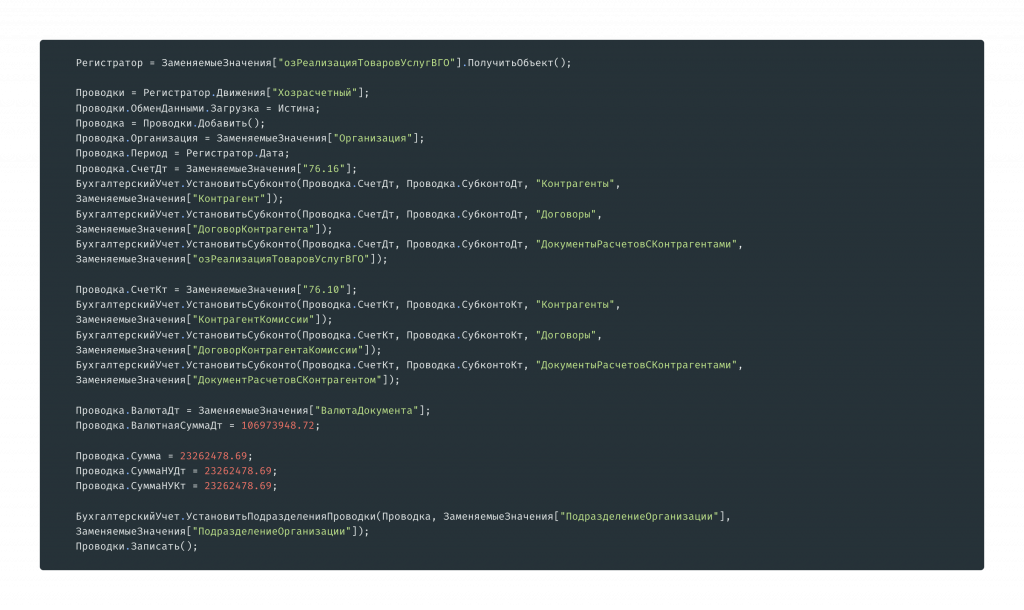
Код подготовки остатков выглядит следующим образом.
Снова запускаем тест, снова он падает, тратим время, пишем mock, и в итоге тест перестает падать. Если разбирать по времени написания, это долго, хотя на словах звучит просто и быстро.
Если у вас много легаси, где не соблюдались стандарты разработки и здравый смысл, а разработчики приходили из разных компаний с разными подходами, то как итог всего этого - код может быть запутанным и сложным. На расследование, откуда берутся тестовые данные и какие настройки нужны, уходит много времени.
Разберем плюсы и минусы хранения данных в коде, помимо подготовки самого кода теста.
Плюсы:
-
Хранение в коде позволяет версионировать тестовые данные в привычном для разработчика виде. Это код, который читается, понятен и который можно исправить хоть в блокноте.
-
Можно использовать наглядное хранение в макетах табличных документов. Можно использовать макеты с форматами вашей компании. Табличный документ можно раскрасить, выделить ячейки, которые необходимо использовать разработчику.
-
Также не обязательно создавать все данные. YaxUnit позволяет создавать фикции объектов. С помощью настроек или руками вы указываете, какие реквизиты создаются фикционно, и их не нужно предзаполнять. Для конкретной тестируемой операции вы пишете код создания тестовых данных, помечаете необязательные реквизиты как фикционные, и все. Фреймворк сам создаст ссылки, заполнит их, и от вас ничего не потребуется.
-
Самый большой плюс – очистка базы после выполнения тестов. База остается чистой, даже если она большая. После прогона тестов вы можете запустить их еще раз и не тратить много времени на подготовку базы.
Минусы:
-
Длительная подготовка данных: нужно потратить много времени, если мы берем проведение документа, на подготовку остатков, на подготовку кода создания документа, на создание эталонов для сверки результата проведения.
-
Нужно уметь пользоваться фреймворком: изучить документацию, посмотреть примеры, попробовать и после этого начинать использовать.
Сделаем выводы:
-
Нет идеального инструмента, который изначально подойдет вашей команде. Нужно выбирать под существующие потребности. Нужно учитывать возможности команды и возможности сопровождения выбранного подхода.
-
Инструменты, как и подходы, можно сочетать. Идеального решения нет: вы выбираете, используете, комбинируете и находите то, что подходит вашей команде в конкретный момент времени.
Советы разработчикам и идеи по упрощению работы
Мои советы по подготовке тестовых данных направлены на подготовку данных с помощью кода, так как это вариант, который я предпочитаю и использую.
Модули-помощники
Один из удобных вариантов работы с тестовыми данными – модули-помощники, как они называются в документации. По сути это общие модули, в которых лежат атомарные методы по работе и созданию тестовых данных. Это общие модули с нужным функционалом для разработчиков, который можно переиспользовать при создании тестовых данных.
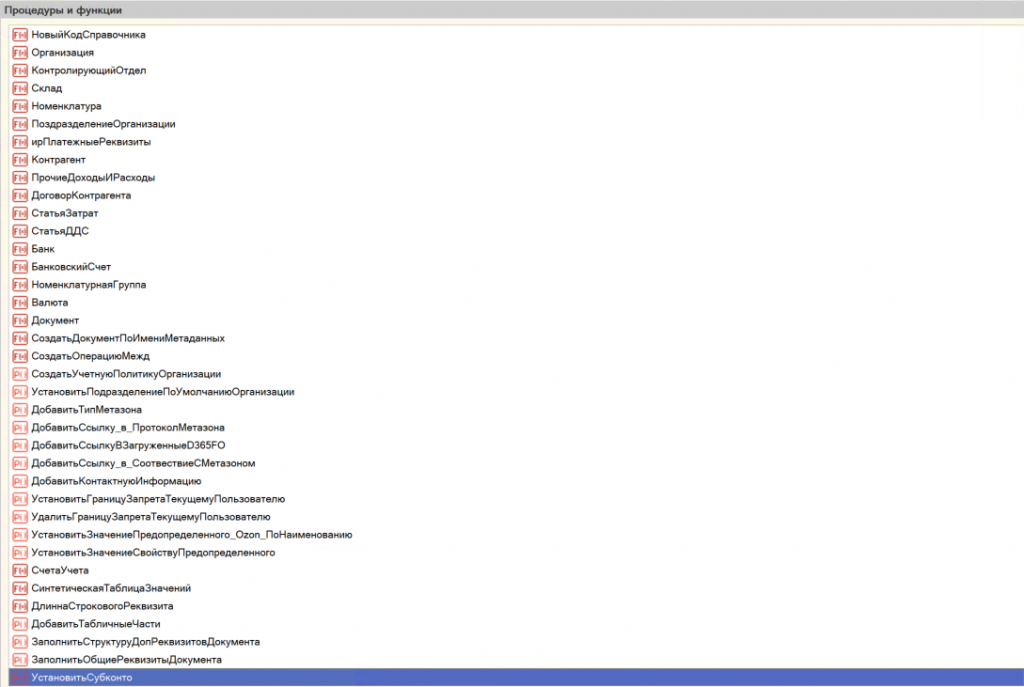
Это пример нашего модуля-помощника. Здесь видно большой объем процедур и функций. Они в основном направлены на специфику блока учета, который мы автоматизируем – финансовый учет.
Какие принципы мы используем при работе с модулями-помощниками:
-
Методы должны быть универсальными, а не узкоспециализированными. Все методы должны быть атомарными или такими, чтобы их можно было переиспользовать как детали конструктора. Смысл – создать важные и нужные инструменты для разработчика, а не складывать туда все подряд, что может когда-то пригодиться.
-
Методы должны возвращать готовые объекты или конструкторы, которые можно переиспользовать. Примеры таких методов: метод создает готовый объект и возвращает сам объект или ссылку по параметру. Либо создает предзаполненный конструктор объекта и возвращает его для дальнейшего заполнения. Можно заполнять настройки: например, создавать учетную политику для организации с возможностью кастомизации по параметрам.
-
Методы должны быть хорошо документированы. Разработчик не должен тратить время на погружение в детали метода, чтения документации должно быть достаточно.
Приведу несколько примеров.
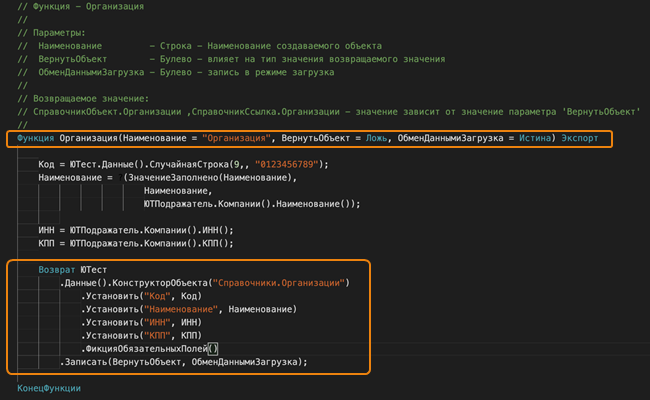
Создание элемента справочника «Организации». Метод параметризован, и от значений параметров зависит заполнение элемента справочника. Параметры необязательны, что позволяет вызывать метод как ТестовыеДанные.СоздатьОрганизацию() без лишних размышлений о работе метода и получать нужные данные в нужном виде.
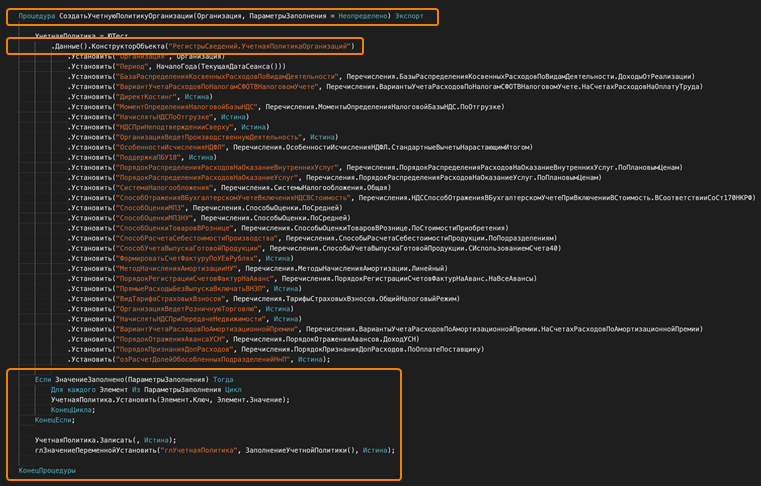
Пример функции для регистра – учетная политика. Сам функционал большой, по сути это копия учетной политики по нашей основной организации с возможностью заполнить или кастомизировать ее из параметров, которые передает разработчик при вызове.
Генераторы кода
Второй инструмент, который я хотел бы посоветовать – это генераторы кода. Вариант самый предпочтительный для разработчика, потому что он пишет за него код.
На данный момент во фреймворке есть генератор кода на основе обработки по созданию данных.
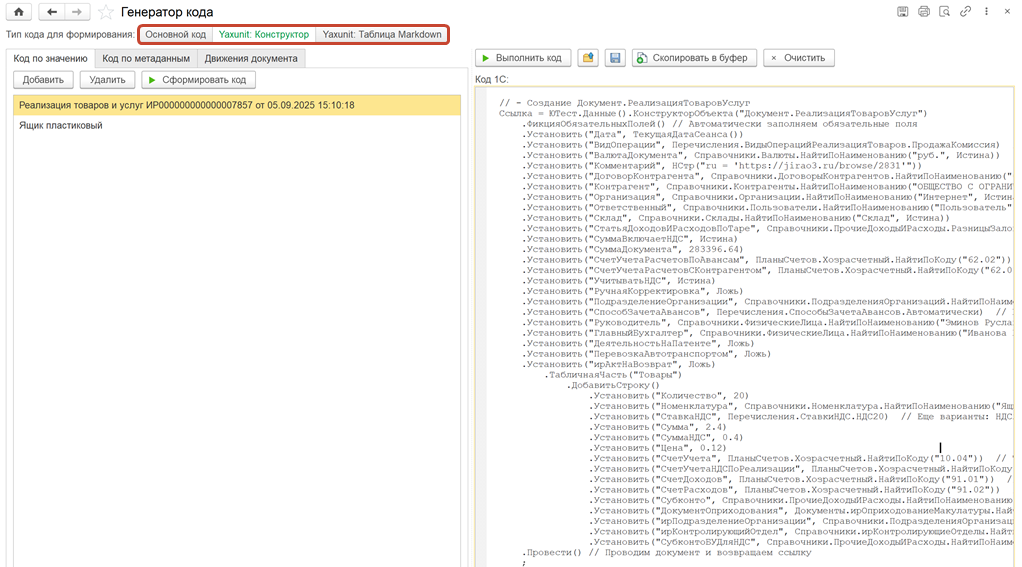
Это обработка, которая создает не только тестовые данные, но и данные для работы обработчиков обновления или для других целей.
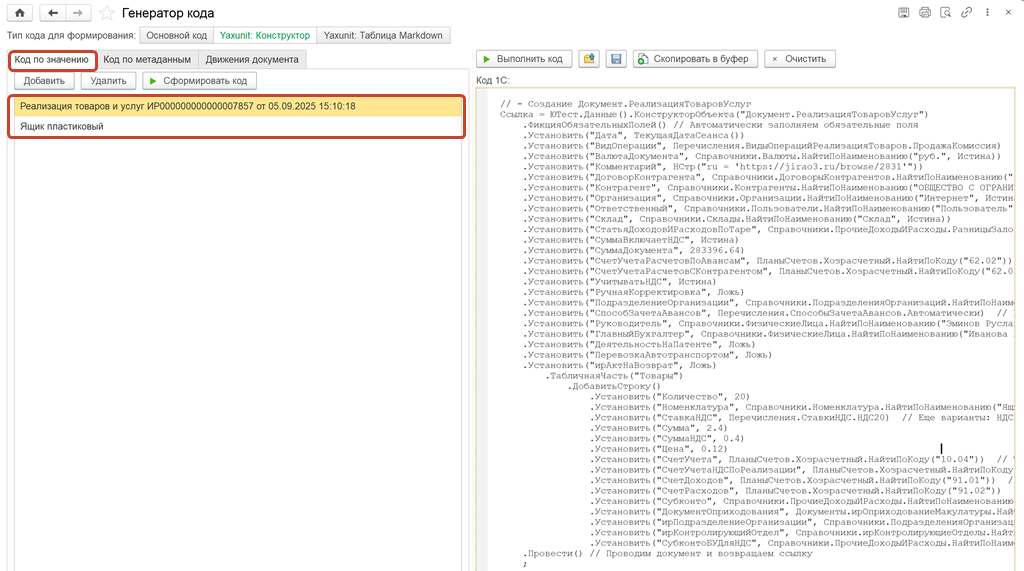
Обработка имеет две области: область выбора элементов и область со сгенерированным кодом. В первой области выбираются элементы, которые необходимы. На вкладке «Код по значению» нажимается кнопка «Сформировать код», и разработчик получает готовый код.
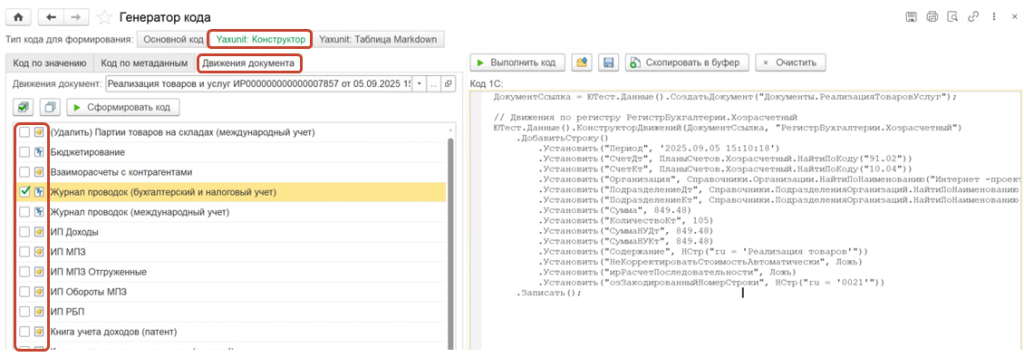
Также поддерживается второй вариант работы – работа с конструктором движений. Здесь выбирается элемент справочника, документ, движение, которое нужно сгенерировать в код, и результат выводится разработчику.
Из минусов, которые я отметил для себя: мы стараемся создавать фиктивные объекты, а не переиспользовать существующие в конфигурации, а здесь такого функционала нет. Генерируется код, который использует существующие объекты конфигурации: поиск по наименованию, по коду или по предопределенным элементам. Поэтому для нас это не самый удобный инструмент.
Помощник для создания тестовых данных
В своей работе мы используем помощник для создания тестовых данных. Этот инструмент написал я. Он разрабатывался параллельно с тем генератором, который сейчас используется во фреймворке. Его основная цель – создание движений документа, то есть создание кода генерации движений документа и кода генерации самого документа.
Кейсы, которые мы старались автоматизировать – проверка проведения документа. Результатом работы этой обработки является код по созданию документа, код по загрузке движений и макет этих движений.
Логика, которую я закладывал – это помощник, результат работы которого нужно доработать. Нужно потратить время, это не готовый код, его можно кастомизировать, что-то поменять, но он помогает разработчику, потому что большая часть кода уже написана, и ее нужно изменить, а не писать с нуля.
Необходимые для создания тестового объекта данные должны генерироваться, а не искаться в базе данных. Этот подход немного изменился, ниже я расскажу, каким образом и что из этого получилось.
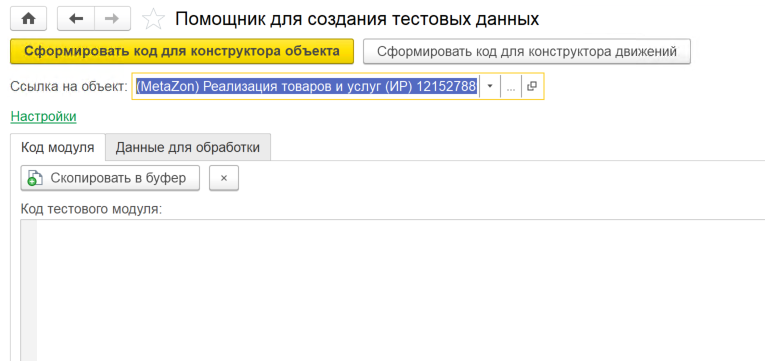
Интерфейс похож на интерфейс генератора. Есть два режима. Первый режим – формирование кода для конструктора объекта. Второй – формирование кода для конструктора движений.
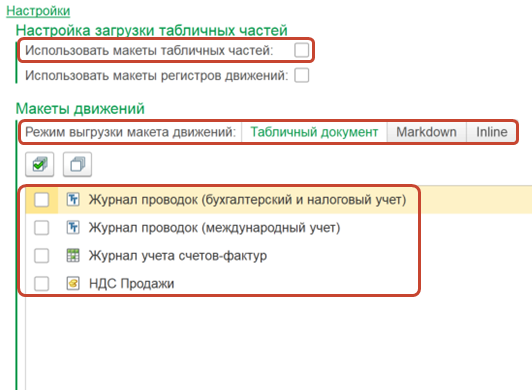
Начнем с кода для конструктора объекта. Указывается ссылка, дополнительные настройки, в том числе – использовать макеты табличных частей или нет. Это inline-макеты, ниже я покажу, как они работают.
Есть несколько режимов выгрузки макетов движений: хранение в табличных частях, в текстовом макете в формате Markdown и в inline-макете непосредственно в коде. Также выбираются движения, которые есть у конкретного объекта. Заполняются не все данные по регистрам, которые есть у документа, а только те, которые заполнены у выбранного экземпляра.
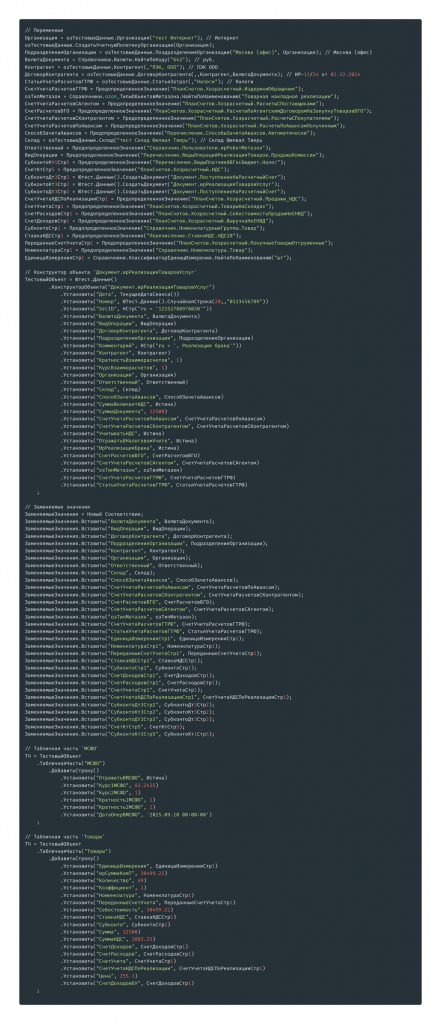
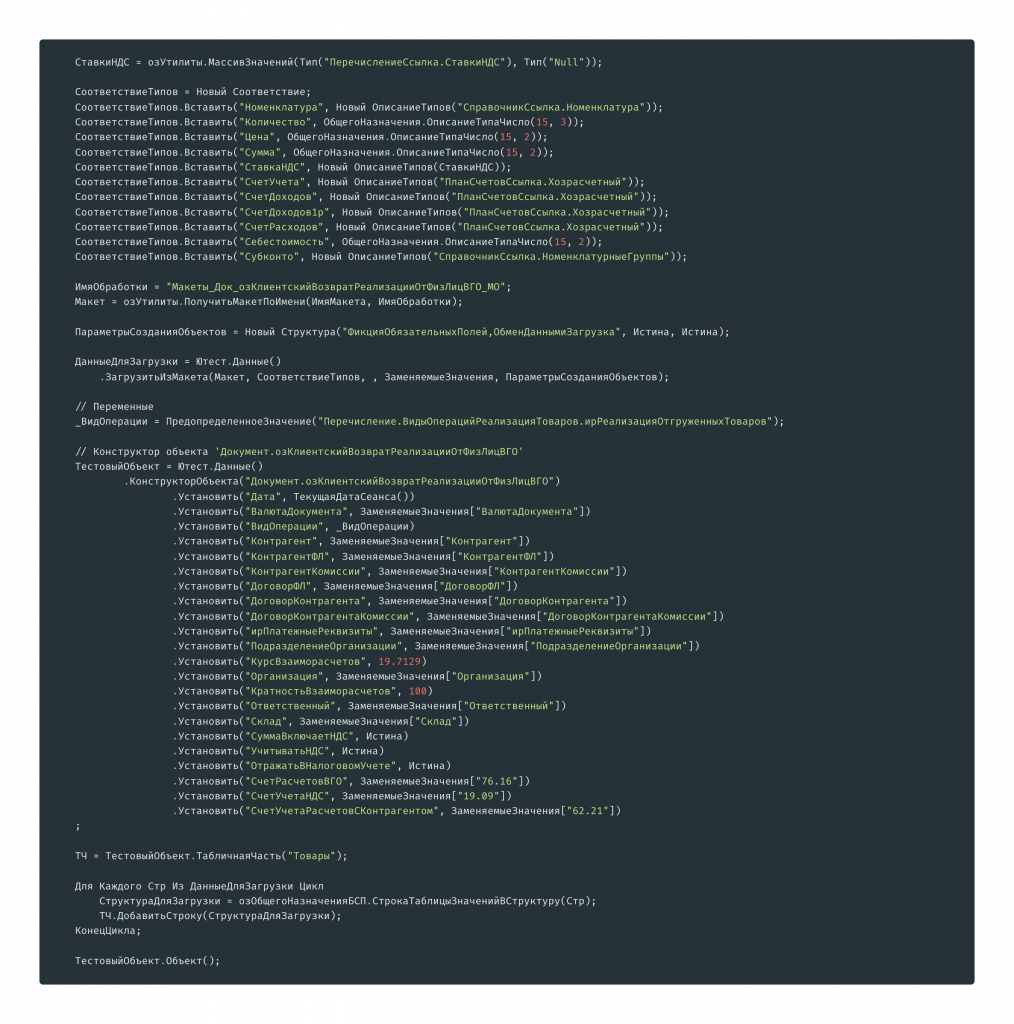
Результатом работы будет код. Создаваемый код начинается с области переменных. Код формируется так: читаются тестовые данные, из них генерируются переменные, которые потом переиспользуются в создаваемом объекте.
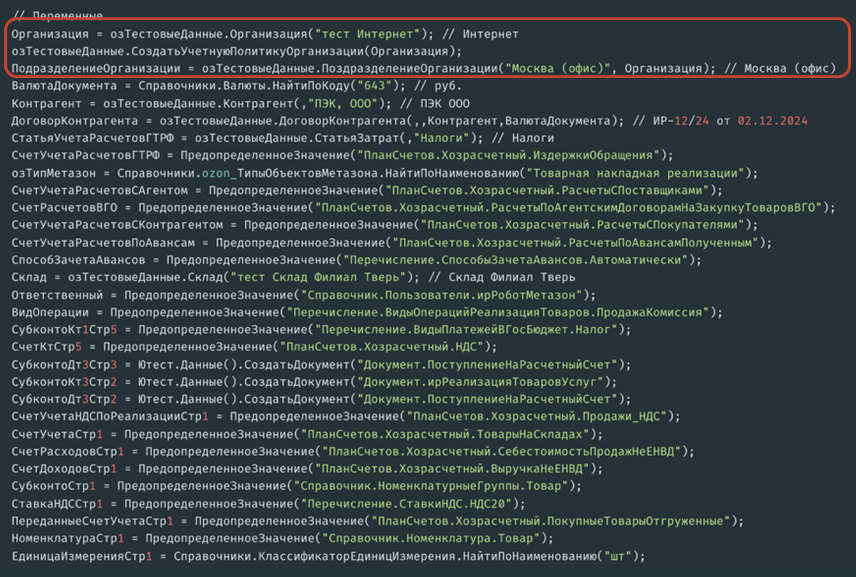
Переменные я бы разделил на несколько категорий. Первая категория – переменные, которые создаются с помощью модулей-помощников. Есть переопределяемый модуль, в котором для каждого типа, для которого вы хотите переопределить код создания, указывается, что для типа «Организация» используется определенный код создания. Ничего сложного: там четыре процедуры, которые используются для переопределения.
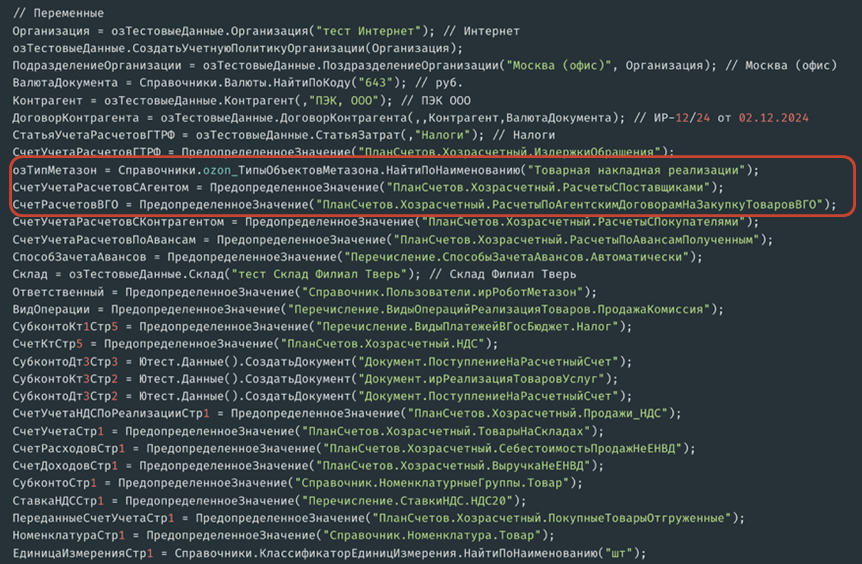
Второй вариант работы с тестовыми данными – поиск по классификаторам. Раньше я говорил, что в приоритете нужно создавать все тестовые данные, но для себя мы решили, что удобнее использовать копию прода с готовыми классификаторами и настройками, не тратить на это время и искать объекты в базе, а не создавать их.
Еще один вариант – использование предопределенных значений, когда используется функция ПредопределенноеЗначение с текстовым представлением элемента.
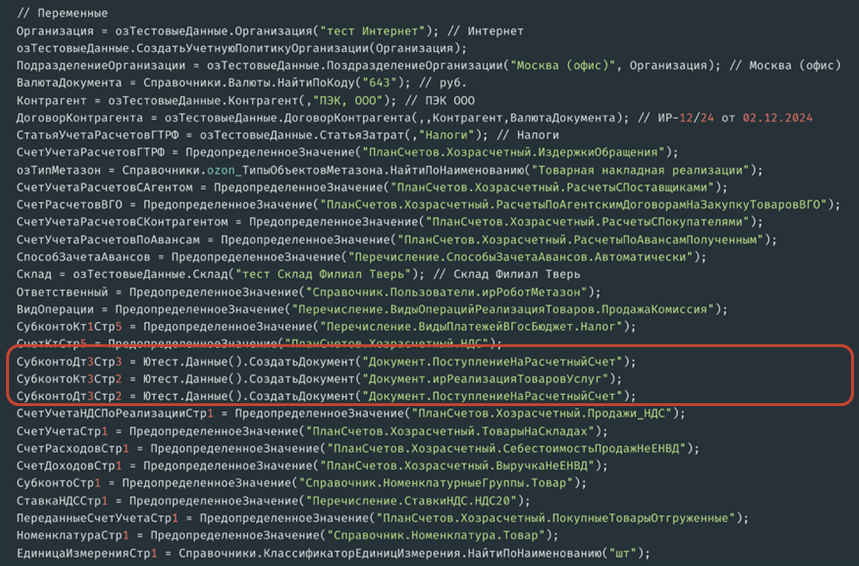
Третий основной вариант работы с тестовыми данными – создание элементов с помощью механизма фреймворка. Генерируется код, который создает элемент по типу данных и подставляет его значение в переменную.
Зачем нужны переменные, видно на следующем этапе – при заполнении линейных реквизитов объекта.
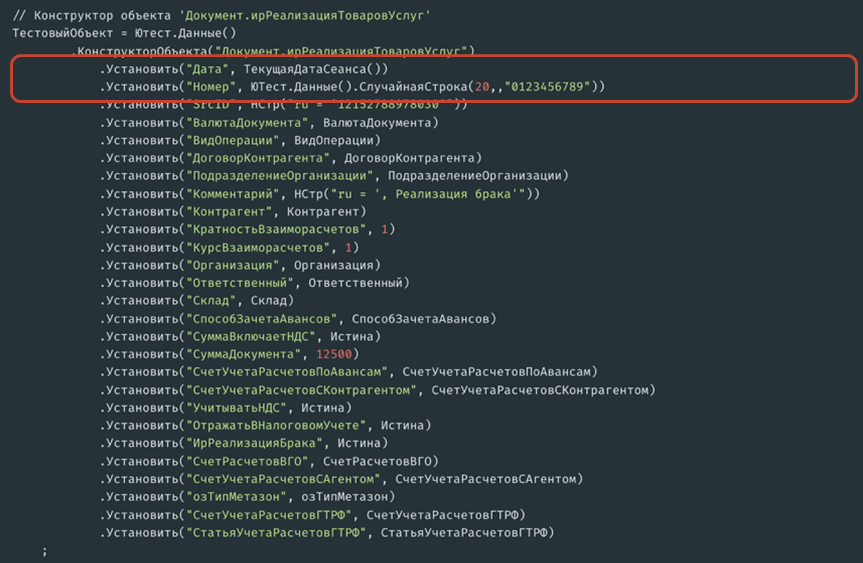
Здесь показан вариант заполнения реквизитов с помощью кода, который используется в переопределяемом модуле тестовых данных.
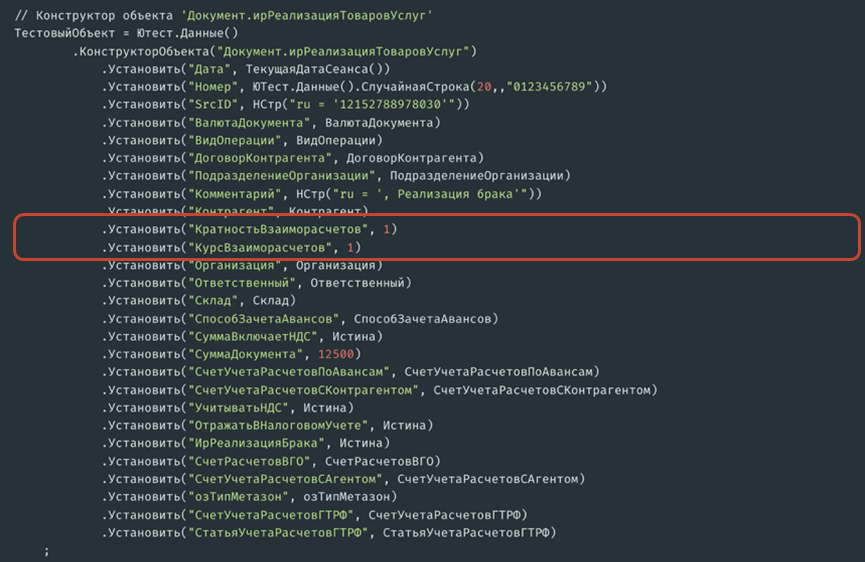
Также заполнение реквизитов значениями примитивных типов...
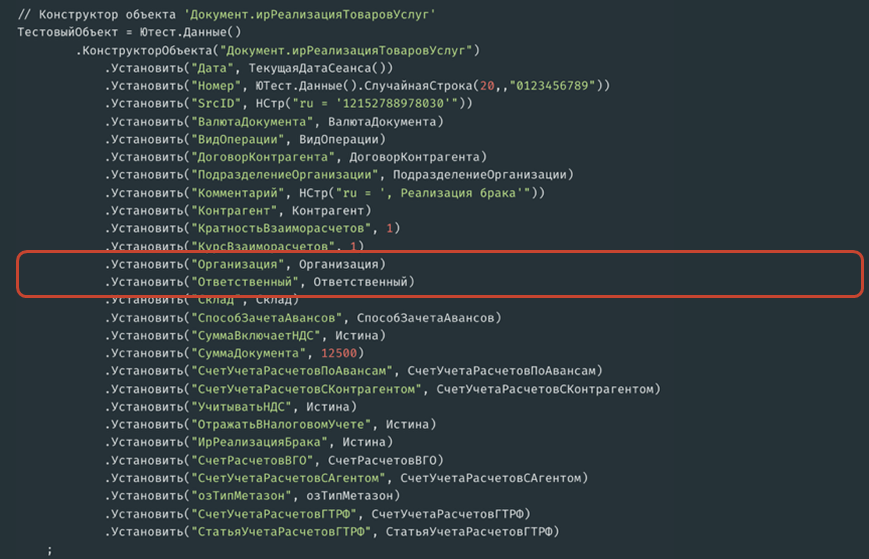
...и теми самыми переменными, которые были определены ранее.
Третья часть, которая генерируется – заменяемые значения. Это соответствие, необходимое для загрузки данных из макетов. Если используется режим работы с табличными частями в виде inline-макетов, эти заменяемые значения подставляются туда, и данные из макета загружаются согласно указанным настройкам.
В ключе соответствия указывается имя переменной строкового типа, которая используется в макете, а в значении – ссылка на переменную.
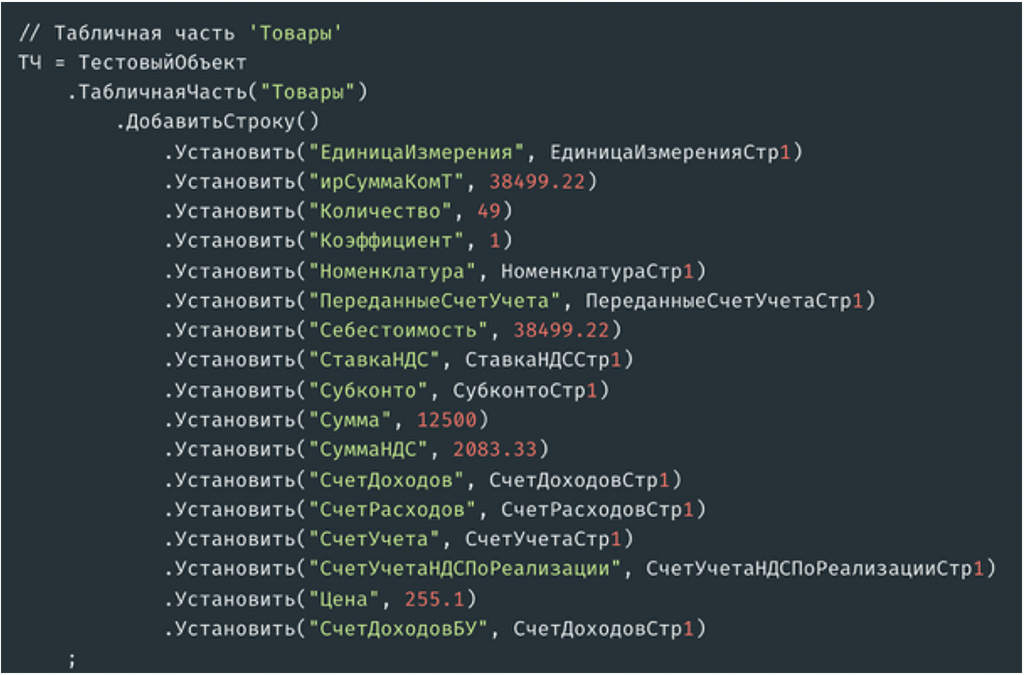
Заполнение табличных частей выглядит так. Если у вас небольшое количество строк в табличных частях, их можно загрузить с помощью кода. Это наглядно и понятно.
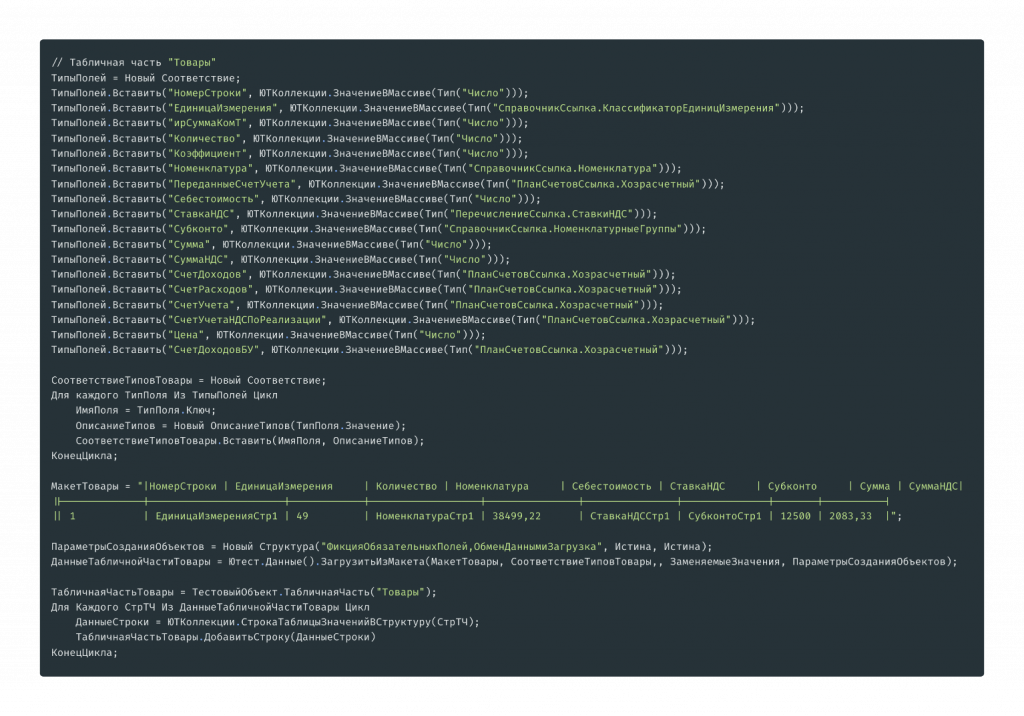
Если строк много, я рекомендую заполнять табличную часть из макета. В простом случае на одной строке это выглядит так: вот эта часть – это макет табличной части. При большом количестве строк этот вариант гораздо нагляднее и удобнее, чем заполнение кодом: у вас не будет дублирующихся блоков кода по заполнению строк табличной части, будет одна таблица, которая автоматически загрузится с помощью такого же фрагмента кода.
Мы загрузили документ, заполнили реквизиты, заполнили табличные части и переходим к проверке движений по тому кейсу, который я изначально подсвечивал, – по назначению этого инструмента.
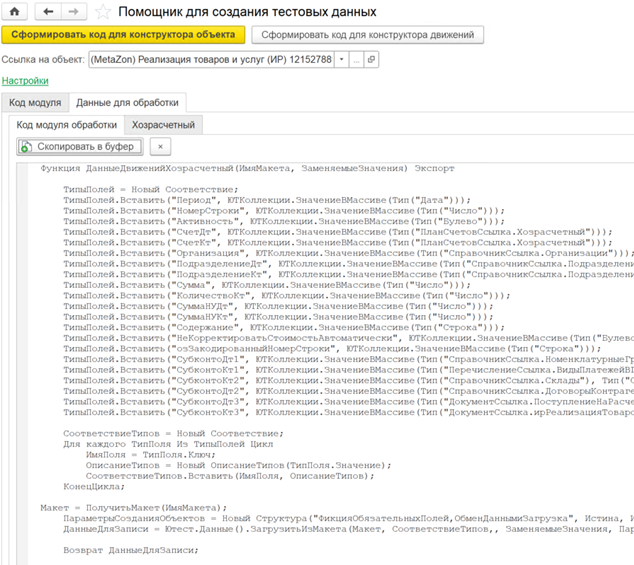
Код по генерации самих макетов лежит на вкладке «Данные для обработки». Там находится код модуля обработки, листинг которого выглядит так же, как загрузка табличных частей.
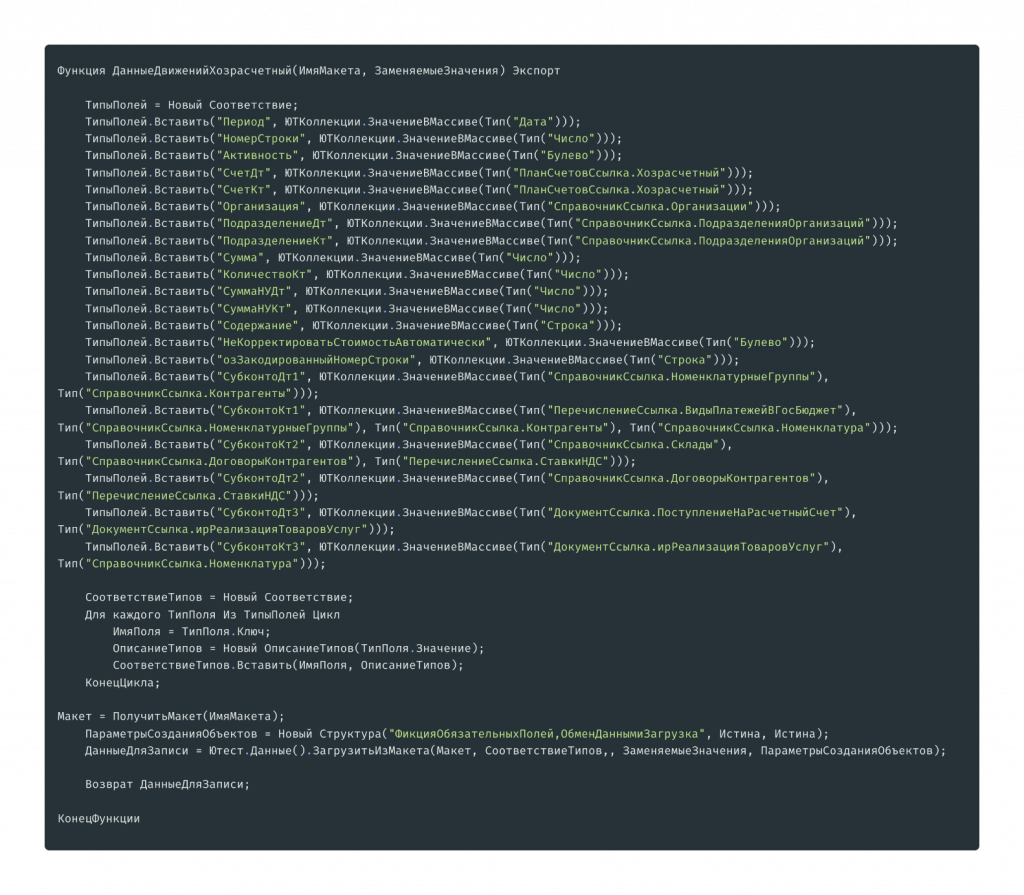
В первой части определяется тип полей макетов, дальше создается соответствие типов, используемых для загрузки из макетов. Здесь же определяется макет, который загружается. В это имя нужно передать имя макета из параметра либо прописать его непосредственно в коде.
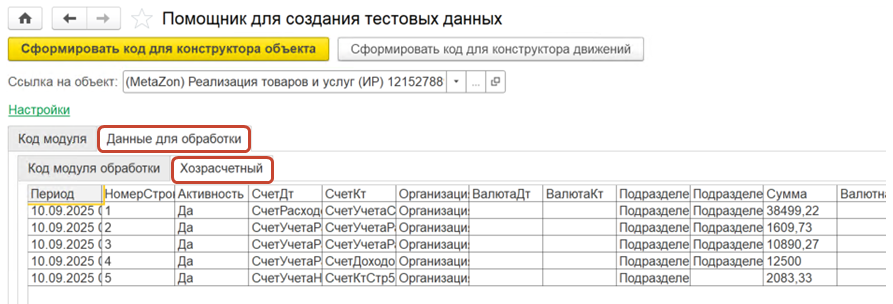
Сами макеты выглядят следующим образом. Данные в них немного обфусцируются: они превращаются в имена переменных, которые передаются из области переменных. Это не реальные данные – номер счета или что-то еще, а переменные, которые были установлены ранее и будут заменены при загрузке из макета.
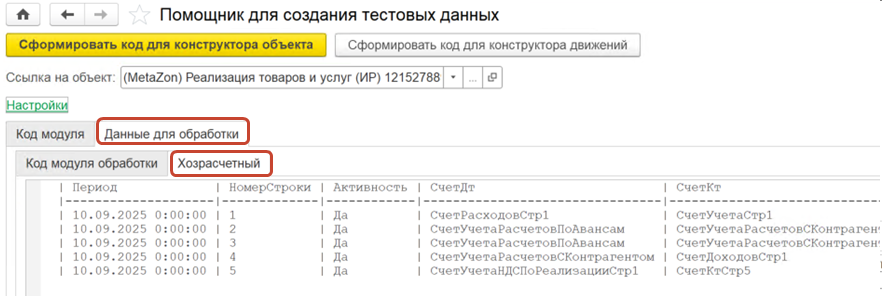
Вот так выглядит второй вариант работы – текстовый макет.
В третьем варианте, как и при загрузке из inline-макетов, вместо ссылки на макет появляется строковый inline-макет в виде таблицы, и этот же код так же корректно работает с такими макетами.
Конструктор движений
Еще один вариант работы – конструктор движений.
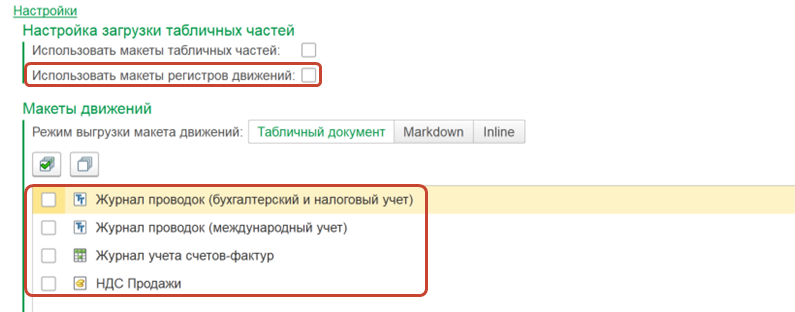
Конструктор движений использует те же области настроек, которые я показывал выше, но работает с макетами регистров движений (либо без них, если используется режим inline-макетов) и самими движениями, которые выбираются.
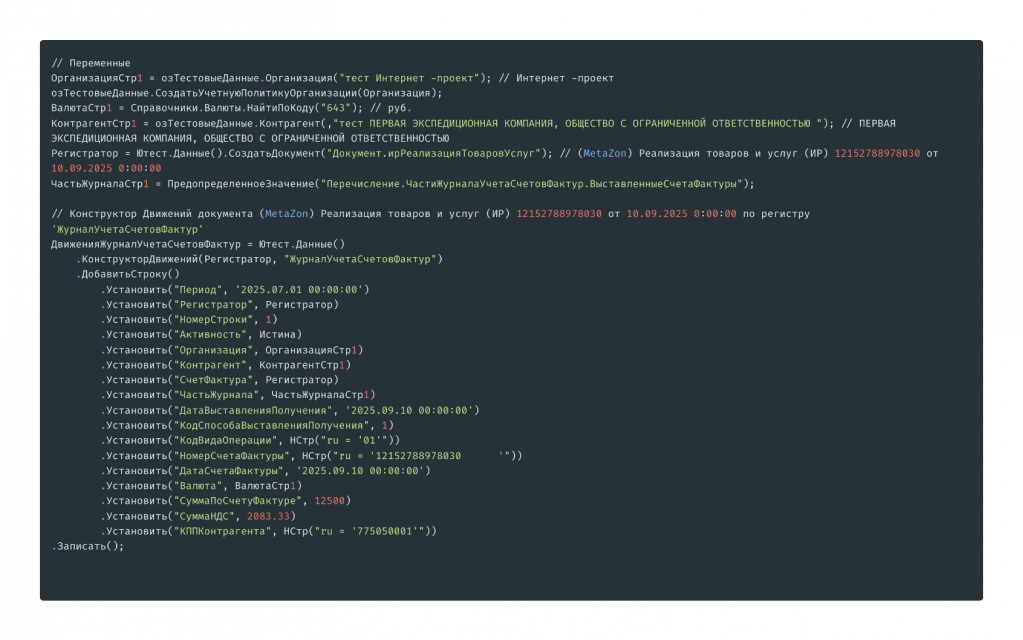
Сгенерированный код выглядит более лаконично, и это весь код.
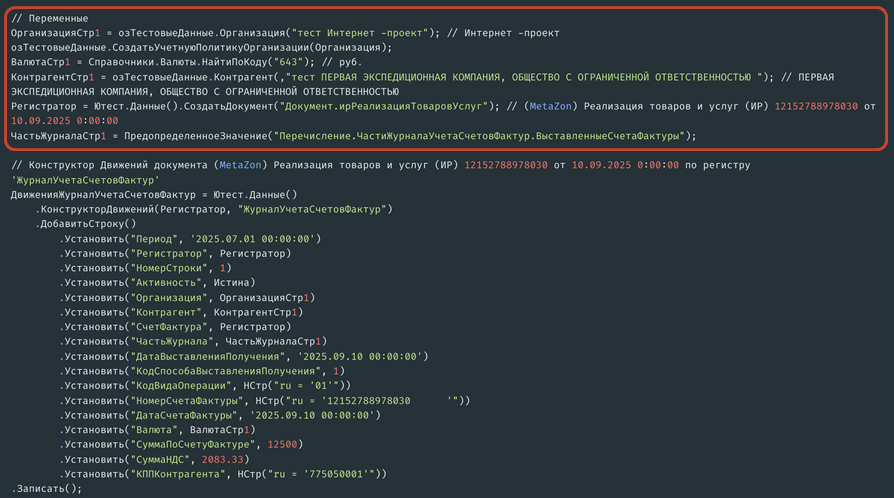
В первой части определяются переменные.
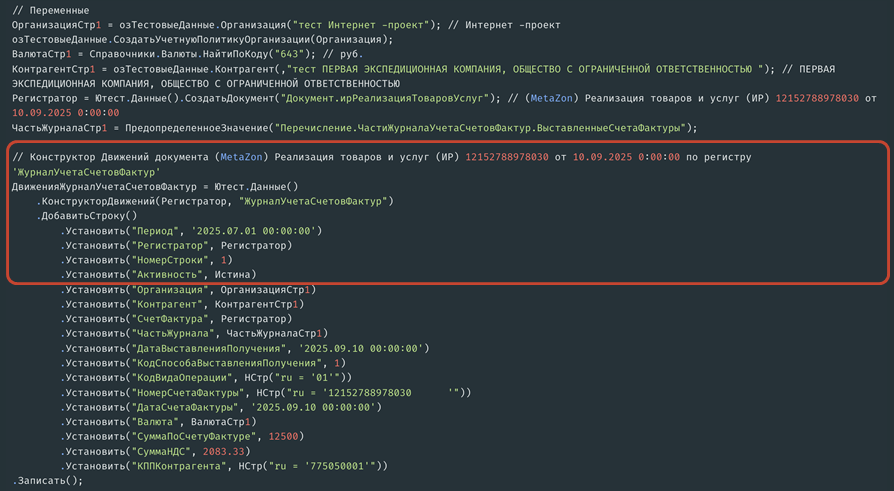
Во второй заполняется строка регистра, в данном случае – «Реализация товаров и услуг» и регистр «Журнал учета счетов-фактур».
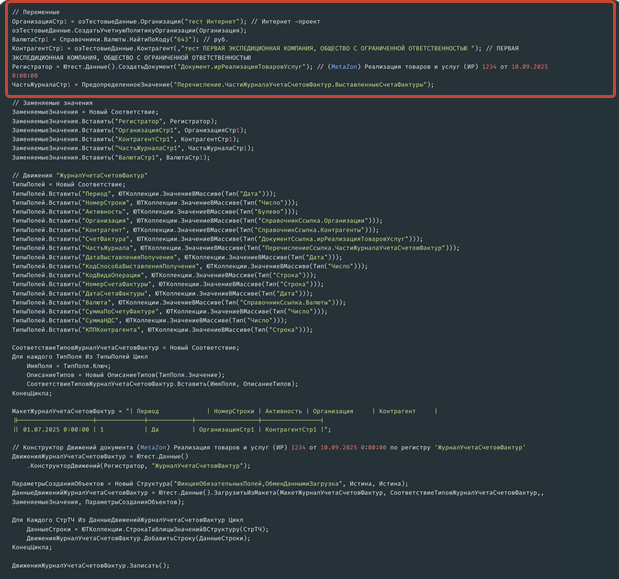
Код по работе с inline-макетами выглядит примерно так же: область переменных...
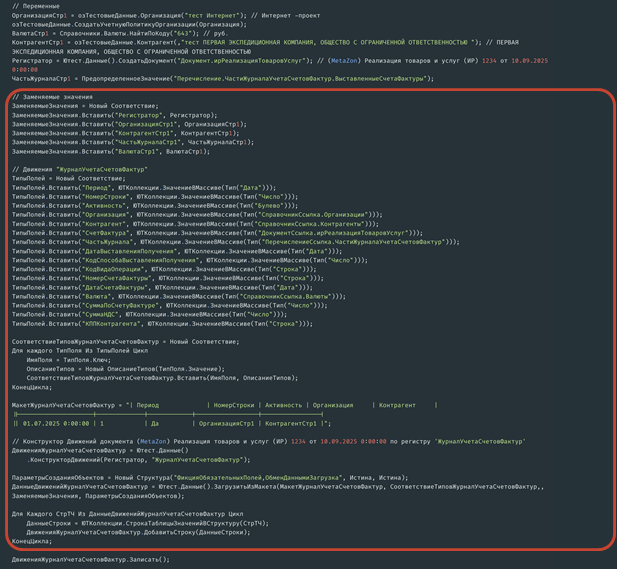
...и область загрузки из макета. Здесь задаются заменяемые значения, выполняется определение типов, указывается сам макет и код загрузки, а запись выполняется уже ниже. Этот код предполагается использовать для загрузки больших таблиц: он занимает меньше места, чем предыдущий вариант.
Итоги
Какой способ работы с тестовыми данными я порекомендую? Никакой.
Выбирайте самый подходящий и нужный для вас под конкретные цели. Сначала определяете цели, затем – инструменты. Я могу только посоветовать и рассказать то, что было в моем опыте.
Лучший вариант для создания тестовых данных – тот, который подходит вам под ситуацию.
Инструменты по генерации, при необходимости, можно написать самостоятельно. Если есть желание, призываю контрибьютить в существующие инструменты и помогать себе и другим разработчикам, участвуя в развитии такого инструмента, как YaxUnit.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.


Вступайте в нашу телеграмм-группу Инфостарт