Контекст импортозамещения и вызовы миграции
Сейчас у нас много проектов, связанных с импортозамещением. За этим словом скрывается большой объем задач: нужно понять, как историческая система поведет себя на новой инфраструктуре, особенно при переходе со стека Microsoft SQL Server и Windows на Linux и PostgreSQL.
Чтобы оценить работу системы на новой инфраструктуре, выделяют несколько критериев производительности. Их много, но для нас особенно важны два:
-
Время отклика – время, которое пользователь ждет при выполнении действия в системе.
-
Пропускная способность – количество операций, которые пользователь может выполнить за единицу времени.
Если обобщить, цель состоит в том, чтобы обеспечить комфортную и стабильную работу пользователя. Для получения численных показателей и оценки будущего поведения системы проводят нагрузочное тестирование.
Суть и цель нагрузочного тестирования

Нагрузочное тестирование – это проверка системы с использованием сценариев бизнес–пользователей, приближенных к реальной работе. В классических проектах по импортозамещению часто возникает вопрос: что может пойти не так?
Есть историческая система, которую переносят с одной СУБД, например с SQL Server, на PostgreSQL. Количество пользователей не меняется, скорость их работы не меняется, бизнес–процессы остаются прежними. Кажется, что риски минимальны, а если что–то пойдет не так, проблему можно будет исправить уже в продуктивной эксплуатации: подкрутить настройки, и все заработает.
На практике такие решения приводят к тому, что через некоторое время – например, через месяц работы на новой инфраструктуре – приходится экстренно откатываться обратно. Это требует ресурсов, времени и денег.

Если заранее провести нагрузочный тест, подобных критических сбоев можно избежать: проблемы будут обнаружены до запуска, и у команды останется время на оптимизацию.
Пример критической проблемы после миграции
Рассмотрим критическое увеличение времени выполнения пользовательских операций на примере проведения документа.
На исторической системе документ проводился за 5–7 секунд. После перехода на PostgreSQL, где используется собственный оптимизатор и собственные планы выполнения запросов, длительность изменилась: в новой системе документ стал проводиться около 20 секунд.
Такое замедление приводит к ожиданию на блокировках и, как следствие, к конфликтам блокировок при работе пользователей. С системой становится невозможно работать.
Нагрузочное тестирование позволяет заранее отследить подобные проблемы производительности и не переносить их в продуктивную эксплуатацию.
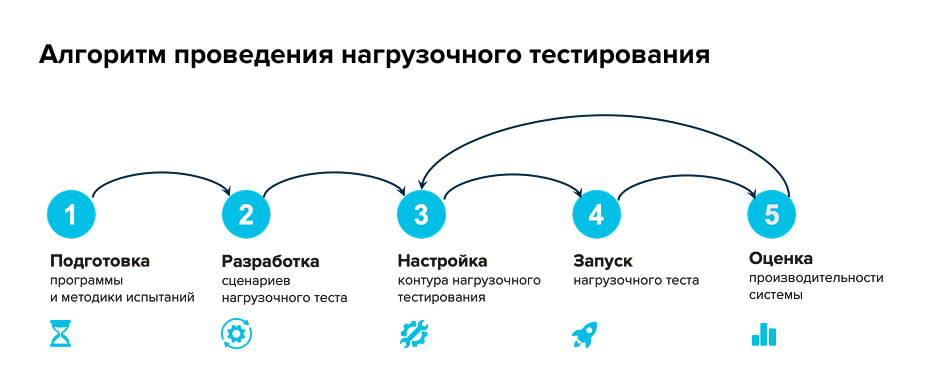
Дальше рассмотрим алгоритм проведения нагрузочного тестирования. В нем пять шагов. Без них невозможно получить полезные результаты, которые можно оценить и применить.
Шаг 1. Подготовка программы и методики испытаний
Первый шаг – подготовка программы и методики испытаний. Обычно это документ, который комплексно описывает пошаговый план и стратегию проведения нагрузочного тестирования. Это один из самых важных этапов, и выполняется он до начала основных работ.
Документ состоит из нескольких разделов.
Описание контура нагрузочного тестирования. Важно понимать, что проводить нагрузочный тест на инфраструктуре, не идентичной продуктивной, не имеет смысла: результаты будут отличаться от продуктивных.
Например, если в продуктиве ожидается кластер 1С из трех серверов, а для нагрузочного теста используется один сервер, команда может выявить и даже оптимизировать часть проблем производительности. Но такая оптимизация окажется бесполезной, если в продуктивной архитектуре эти проблемы не возникли бы.
То же самое относится к СУБД. Если в продуктиве кластер состоит из одного мастера и нескольких реплик, то в нагрузочном тестировании в идеале должен использоваться аналогичный кластер. Это дорого, но важно для корректной оценки системы.
Согласование бизнес–сценариев и ключевых операций – второй раздел программы и методики испытаний. На этом этапе мы тесно взаимодействуем с заказчиком, функциональным архитектором или командой и обсуждаем перечень сценариев, которые должны войти в нагрузочный тест.
Главный вопрос простой: какие сценарии действительно важны? Часто пользователи отвечают, что важны все сценарии. На практике часть операций выполняется редко или вообще не используется. Если это ERP–система, список может включать около 300 сценариев. Разработать их все и провести нагрузочный тест заняло бы примерно год, и никто на это не согласится.
Поэтому перечень нужно пропустить через фильтр:
1. Критичные для бизнеса сценарии. Это сценарии, без которых бизнес не функционирует или в которых критическое замедление существенно влияет на процессы. Примеры – расчет себестоимости в ERP или получение заказов клиента в системах, работающих с маркетплейсами, а затем вся цепочка обработки заказа.
2. Сценарии с высокой массовостью. Это операции, которые выполняет большое количество пользователей или которые часто выполняются за единицу времени.
3. Сценарии, которые уже вызывали жалобы на производительность. Их важно проверить в нагрузочном тестировании на новой инфраструктуре.
В общем случае можно придерживаться правила: берем 20% сценариев, которые формируют 80% нагрузки на систему.
Описание ролей для выполнения сценариев – третий раздел программы и методики. Все сценарии должны выполняться с теми же ограничениями прав, которые предусмотрены в продуктивной среде. Выполнять сценарии под полными правами не имеет смысла, потому что работа в таком режиме обычно быстрее. Это связано, например, с RLS: платформа добавляет к стандартному запросу дополнительные подзапросы, и это влияет на реальную производительность.
Определение профиля нагрузки – следующий раздел. Здесь описываются:
-
количество виртуальных пользователей, которые будут участвовать в нагрузочном тесте;
-
количество повторений каждого сценария одним пользователем за единицу времени;
-
количество операций в час и за весь период теста;
-
длительность нагрузочного теста;
-
количество тестовых данных и объем базы.
Чаще всего тест длится от 3 до 8 часов. Этого обычно достаточно, чтобы проявились основные проблемы производительности. Иногда длительность может быть меньше: например, стресс–тест проводится за один час. В таком тесте профиль нагрузки увеличивается в пять раз: растут количество пользователей и частота выполнения сценариев, а за короткий промежуток времени проверяется, выдержит ли система такой уровень нагрузки.
Цель по объему данных – обеспечить тот объем базы, который ожидается в продуктиве, будет достигнут в ближайшее время или прогнозируется как целевой через год или два.
Описание шагов бизнес–сценария. Пятый раздел, по сути, это техническое задание для разработчика, который будет разрабатывать обработки выполнения сценариев.
Шаг 2. Разработка сценариев нагрузочного теста
Рассмотрим разработку сценариев на примере 1С:Тест–центра.

На изображении показан пример кода обработки. В обработке на языке 1С есть два важных метода.
Первый – ПриОткрытии. В нем описывается перечень шагов и операций, которые будут выполняться в сценарии: открыть форму списка, открыть форму документа, заполнить реквизиты, провести и закрыть документ.
Второй – ВыполнитьОперацию. В этой процедуре каждая операция детально описывается кодом: какие реквизиты заполняются и какими значениями.
При разработке сценария важно имитировать все пользовательские и системные действия. Нужно вызывать обработчики элементов форм при открытии, обработчики реквизитов при изменении, например КонтрагентПриИзменении, потому что в этих обработчиках может быть завязана значительная логика и могут выполняться тяжелые запросы.

Провести нагрузочный тест можно на двух типах данных: синтетических и продуктивных. Продуктивные данные предпочтительнее, потому что они реалистичнее. Не всегда удается сгенерировать синтетические данные так, чтобы они точно отражали реальную картину.
В ERP объекты метаданных обычно объемные: у них много реквизитов и табличных частей, а логика сильно завязана на код. Часто возникает такая ситуация: мы программно заполнили объекты синтетическими данными, запустили нагрузочный тест, а он падает из–за того, что какая–то табличная часть недозаполнена, хотя формально она не обязательна. Приходится возвращаться к разработке, дорабатывать генерацию и снова запускать нагрузочный тест. В продуктивных данных такой проблемы нет.
Из этого следует еще одно преимущество продуктивных данных – упрощение подготовки базы для нагрузочного тестирования. Если мы берем продуктивную базу, она уже наполнена, а целевой объем практически достигнут. Обычно нужно только догенерировать некоторое количество документов для использования в сценариях.
При работе с синтетическими данными база изначально пустая. Чтобы ее наполнить, создаются обработки генерации данных. В ERP много объектов метаданных, для которых нужно разрабатывать такую генерацию.

На изображении представлен пример обработки генерации данных на одном из наших проектов. Обработка написана с нуля, потому что готовых решений нет: под каждый проект создается своя генерация данных.
Первая колонка содержит описание и перечень объектов метаданных. Последняя колонка показывает текущее количество объектов в базе и количество, которое нужно сгенерировать. Дальше используется кнопка "Запустить генерацию".
Обратите внимание на выбор количества потоков. В ERP или в Управлении холдингом часто нужно сгенерировать несколько сотен тысяч документов и других объектов. Сделать это в один поток за приемлемое время практически невозможно, поэтому одна из сложностей работы с синтетическими данными – необходимость разрабатывать многопоточную генерацию.

После генерации данные нужно распределить между сценариями нагрузочного тестирования. Важно, как именно это делается. В общем случае данные можно распределить пропорционально, но всегда нужно придерживаться принципа максимального приближения к реальной работе системы.
Например, если выделить одного контрагента и одну номенклатуру и распределить их по всем 500 пользователям, результатом нагрузочного тестирования станут искусственные конфликты блокировок. В реальной жизни все пользователи не работают с одним и тем же контрагентом.
Шаг 3. Настройка контура нагрузочного тестирования
Чтобы получить численные показатели, необходимо настроить мониторинг на всех уровнях:
– серверное оборудование;
– приложение 1С;
– СУБД.
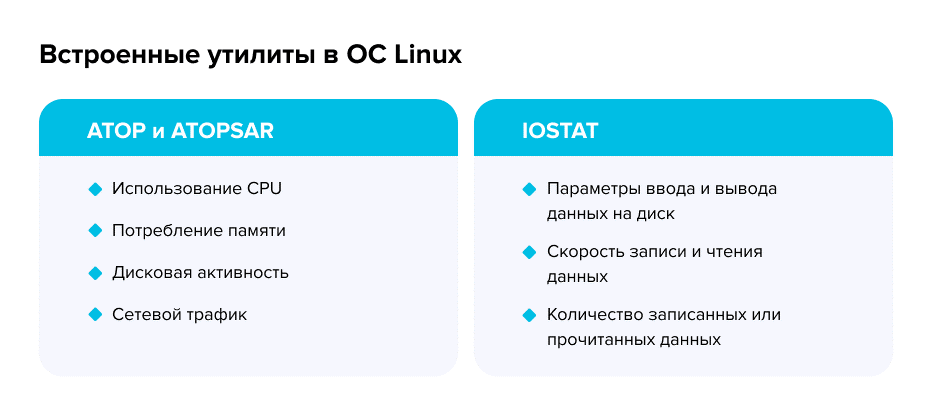
На уровне операционной системы для мониторинга серверного оборудования мы используем встроенные утилиты: ATOP, ATOPSAR, IOSTAT. Сторонние инструменты сложнее согласовать, потому что для их установки нужно подтверждение информационной безопасности. Поэтому встроенные утилиты предпочтительнее.
Они позволяют собирать данные о загрузке оборудования и конвертировать их в JSON или текстовый файл, который затем можно загрузить в систему визуализации.

На уровне приложения 1С обязательно включаем подсистему оценки производительности, входящую в БСП. Если конфигурация нетиповая и не содержит БСП, подсистему встраивают вручную. Здесь мы собираем профиль ключевых операций, определенных на этапе подготовки программы и методики испытаний.
Также включаем технологический журнал по основным событиям:
– исключения уровня кода;
– ошибки уровня кластера;
– блокировки;
– таймауты;
– дедлоки;
– длительное ожидание блокировок;
– длительные запросы (например, от одной секунды);
– клиент–серверные вызовы.
На уровне СУБД часть данных уже собирается системой. В PostgreSQL это:
– статистика буферного кэша;
– журнал предзаписи WAL;
– фоновые процессы.
Дополнительно можно включить протоколирование:
– таймаутов на ожиданиях блокировки;
– взаимоблокировок;
– автоочистки и контрольных точек;
– ошибок;
– планов запросов на этапе оптимизации.
Эти данные нужны для оценки работы СУБД после нагрузочного тестирования и для дальнейшей настройки параметров, чтобы добиться более эффективной работы.
Планы запросов во время самого нагрузочного тестирования лучше не включать, потому что они создают дополнительную нагрузку. В продуктивной системе планы тоже не собираются постоянно. Сбор планов запросов включается уже на этапе оптимизации, когда нужно понять причину проблемы в конкретной ключевой операции.
Шаг 4. Запуск нагрузочного теста
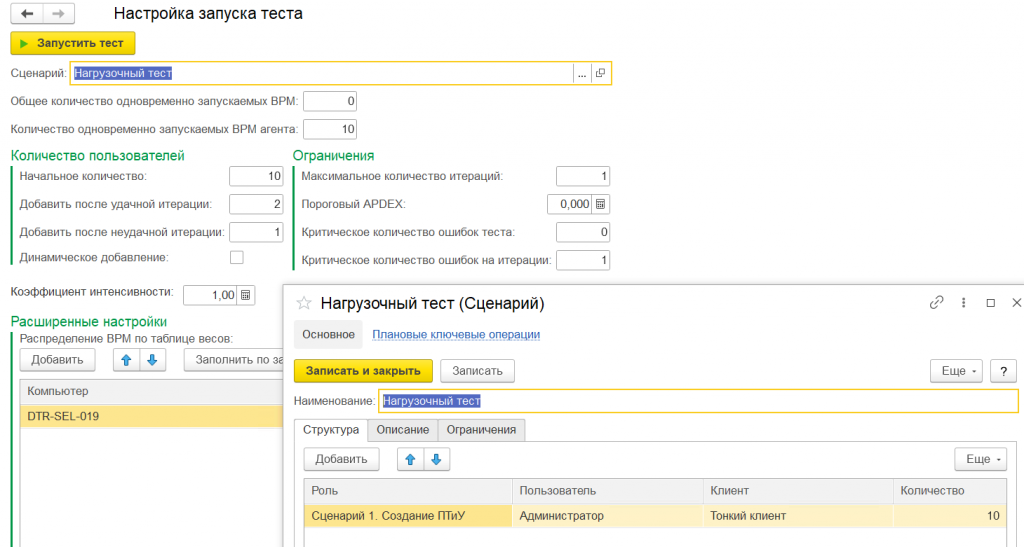
На изображении показан интерфейс 1С:Тест–центра. В этом окне собираются все разработанные сценарии, указывается количество пользователей для каждого сценария и запускается тест.

Пример запущенных клиентских сессий 1С
После запуска отображается общий прогресс. 1С:Тест–центр запускает клиентские сессии в количестве, указанном в настройках нагрузочного теста. Если задано 1000 пользователей, откроется 1000 окон 1С. Для каждого виртуального рабочего места назначается своя обработка сценария, и оно начинает выполнять действия, прописанные в этой обработке.
Шаг 5. Оценка производительности системы
После проведения нагрузочного теста и получения численных результатов их нужно оценить и сформировать рекомендации по оптимизации или перейти к самой оптимизации.
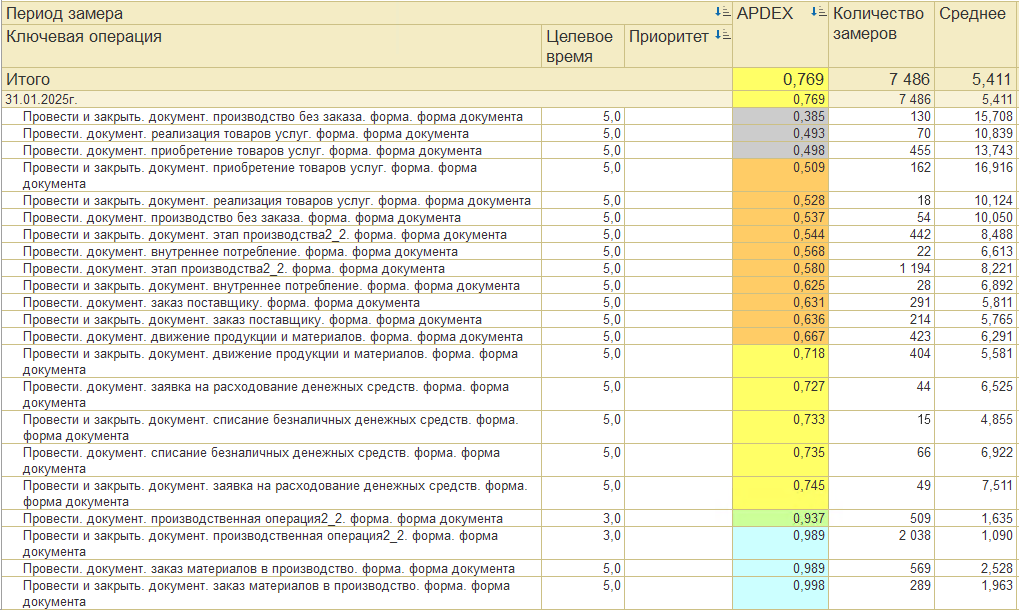
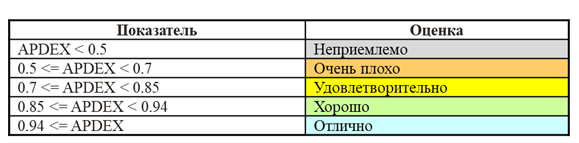
Отчет оценки производительности и общий APDEX
В первую очередь смотрим отчет оценки производительности: общий APDEX системы и детализацию по ключевым операциям.
В примере общий APDEX равен 0.769, оценка – удовлетворительно. Требуется анализ и оптимизация операций проведения документов.
Детализация ключевых операций для анализа
Далее определяем, какая ключевая операция требует расследования, в чем проблема и что нужно оптимизировать.
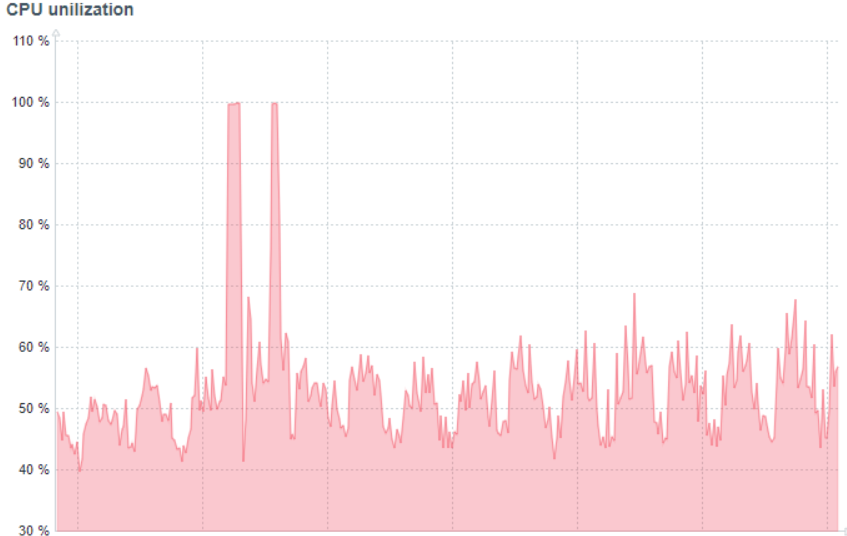
График загрузки процессора
Следующий шаг – анализ загруженности оборудования. В примере процент загрузки процессора в норме и не превышает 80%, но есть две кратковременные пиковые нагрузки до 100%, которые требуют анализа.
Обычно для анализа ищут корреляцию между пиковой нагрузкой и сценариями, которые выполнялись в этот момент. Для этого используется протокол нагрузочного тестирования.
В данном случае причиной повышенной нагрузки на процессор стало формирование отчетов. В этот период выполнялись сценарии, которые формировали большие отчеты с отбором по периоду за год без дополнительных фильтров.
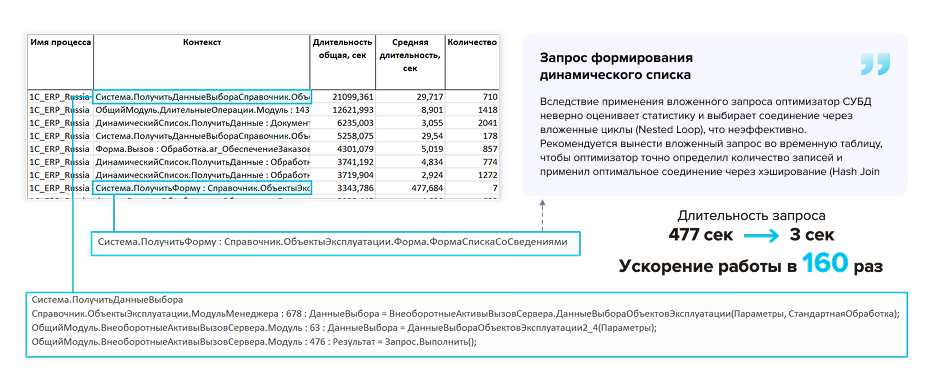
Пример анализа технологического журнала
Дальше анализируем технологический журнал. Для анализа используются скрипты: их можно написать на любом языке, а примеров в интернете достаточно. Один из вариантов – группировка длительных запросов с выделением топ–50 по суммарной длительности.
На одном из проектов был показательный пример: открытие формы динамического списка объектов эксплуатации выполнялось 500 секунд. После получения плана запроса и анализа причины выяснилось, что в запросе динамического списка находился вложенный запрос.
Оптимизатор PostgreSQL, на который мы перешли с Microsoft SQL Server, не мог рассчитать актуальную статистику для этого вложенного подзапроса и выбирал соединение вложенными циклами. Это и приводило к такой длительности.
После рекомендации перенести вложенный запрос во временную таблицу оптимизатор смог быстро посчитать статистику этой таблицы и выбрать хеш–соединение. В результате запрос вместо 500 секунд стал выполняться 3 секунды.
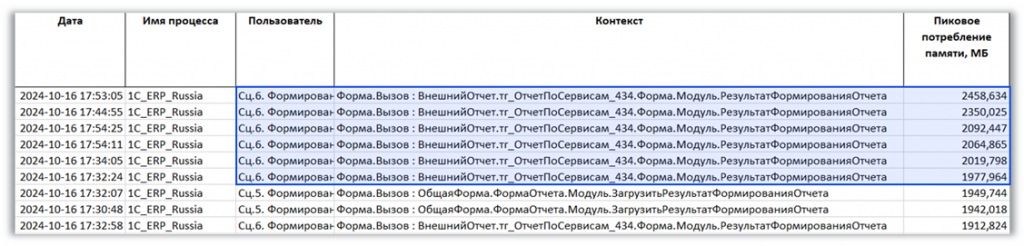
Следующее, что анализируется в технологическом журнале, – пиковое потребление памяти. После группировки отчетов по пользователям и по пиковому потреблению памяти выделяются сценарии, которые массово начинают формировать отчеты.
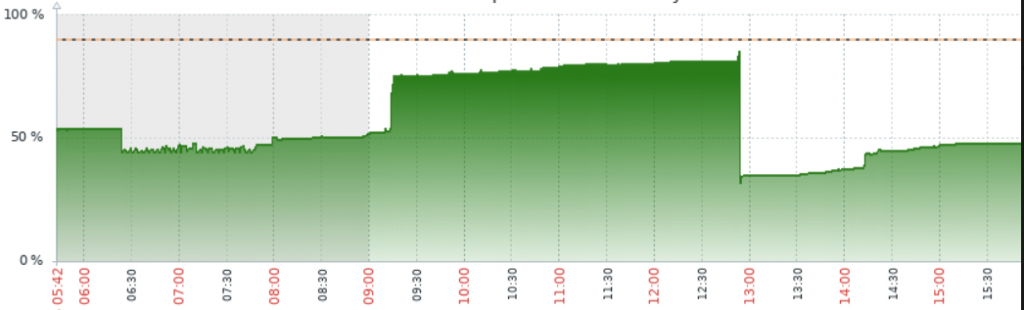
График доступной оперативной памяти
По графику доступной оперативной памяти видно, как она резко снижается: утилизация растет, свободной памяти почти нет, а затем она резко появляется снова. Это пример сценариев, которые формировали большие отчеты с отбором за целый год и получали миллионы записей. После завершения формирования отчеты закрылись, и память освободилась.
Оценка сроков проведения нагрузочного тестирования

Слайд с оценкой сроков нагрузочного тестирования
Теперь посмотрим, сколько времени занимает проведение нагрузочного тестирования.
Часто на проектах внедрения и запуска крупных систем уровня ERP в бюджет и план проекта закладывают примерно одну неделю. В нашей практике был проект внедрения ERP за полтора года, при этом на нагрузочный тест в плане стояла всего одна неделя.
Минимальный нагрузочный тест на пять сценариев будет разрабатываться примерно 30 дней. А дальше все зависит от количества сценариев: сроки могут составлять и три месяца, и больше.
Самый длительный этап – разработка сценариев и генерация тестовых данных. Этот этап хорошо параллелится между разработчиками. Если есть команда, которая может писать сценарии для нагрузочного тестирования, то условные 60 дней можно уменьшить почти в 10 раз, если над задачей работают 10 разработчиков.
Этап описания технических заданий для разработчиков также хорошо параллелится между аналитиками, потому что они описывают пошаговый план пользовательских действий.
Все остальные этапы практически не параллелятся. Подготовку программы и методики испытаний, проведение нагрузочного теста, сбор результатов, оценку и формирование рекомендаций по оптимизации может выполнить только технический эксперт, и он делает это в одиночку.
Дополнительная ценность нагрузочного тестирования: отказоустойчивость
Помимо классической ценности нагрузочного тестирования есть дополнительная, с которой мы столкнулись на практике и которую сами применили.

На одном из проектов у нас был запланирован нагрузочный тест для проверки пользовательских сценариев. Дополнительно мы использовали его для проверки отказоустойчивости.
Был кластер из трех серверов 1С: два центральных с уровнем отказоустойчивости 1 и один рабочий, а также кластер СУБД с одним главным сервером и двумя репликами.

В один момент проведения нагрузочного теста мы выключили один центральный сервер 1С и главный сервер СУБД, чтобы посмотреть, как система отреагирует на аварийное переключение.
Мы проверяли:
-
как быстро пользователи переключатся на второй центральный сервер;
-
как быстро одна из реплик в кластере СУБД станет мастером;
-
каким будет замедление ключевых операций у пользователей в момент переключения.
Как пример, на этом кейсе мы обнаружили инфраструктурную проблему: после выключения главного сервера СУБД все запросы на запись пошли на реплику, которая еще не успела стать мастером. Часть пользователей получила ошибку о попытке записи на сервер СУБД, доступный только для чтения.
Повторное использование нагрузочного теста

Еще одна ценность – повторное использование нагрузочного теста.
На одном из проектов мы проводили нагрузочный тест ERP на релизе определенной версии. Пока мы разрабатывали сценарии, проводили тестирование, получали результаты, оценивали их и выполняли оптимизацию, вышел новый релиз.
Заказчик принял решение, что изменения в новом релизе важны и запуск опытно–промышленной эксплуатации без них невозможен. У нас уже был нагрузочный тест, с помощью которого можно проверить новый релиз. Мы обновили конфигурацию, взяли ранее сделанный нагрузочный тест, актуализировали сценарии, снова провели тестирование, получили результаты, сформировали рекомендации по оптимизации, оптимизировали систему и запустили ее в опытно–промышленную эксплуатацию.
Через некоторое время вышла новая версия платформы, которую тоже хотелось бы ввести в продуктив, но сразу запускать ее рискованно. Мы снова взяли наш нагрузочный тест, обновили платформу в контуре нагрузочного тестирования, запустили тест и посмотрели, как система работает на новой версии.
Так можно делать постоянно: при выходе новых релизов типовой конфигурации, собственных нетиповых релизов и обновлений платформы.
Итоги
Проект нагрузочного тестирования не стоит воспринимать как одноразовую активность перед запуском. В результате команда получает инструмент, которым можно проверять работу системы сейчас и использовать его в будущем.
Для проектов импортозамещения это особенно важно: новая инфраструктура может изменить поведение запросов, блокировок, памяти и отказоустойчивости даже при прежних пользователях и прежних бизнес–процессах. Нагрузочный тест позволяет увидеть эти изменения до продуктивного запуска, оценить их численно и заранее подготовить рекомендации по оптимизации.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAMLEAD & CIO EVENT.


Вступайте в нашу телеграмм-группу Инфостарт