
{kind=link}
Предисловие автора
Методика сложилась при разборе утечек на рабочем сервере. Как оказалось, поиск утечек памяти — нетривиальная операция. Гигабайты логов, события LEAKS c тысячами строк стека вызовов.
Уточню, что в скриптах нет академической строгости. Скрипты написаны под конкретную задачу — получить результат здесь и сейчас. Где-то можно было бы добавить проверок, где-то обернуть переменные в кавычки по всем канонам. Кто-то заметит, что код можно упаковать в два-три раза компактнее. Можно. Но зачем? Развёрнутые скрипты проще понять, адаптировать и, если что, починить. Все имена модулей, серверов и пользователей в примерах изменены. Совпадения случайны. Платформа 8.3.27, окружение Git Bash с GNU утилитами.
Шаг 0. Предварительная диагностика: есть ли утечка?
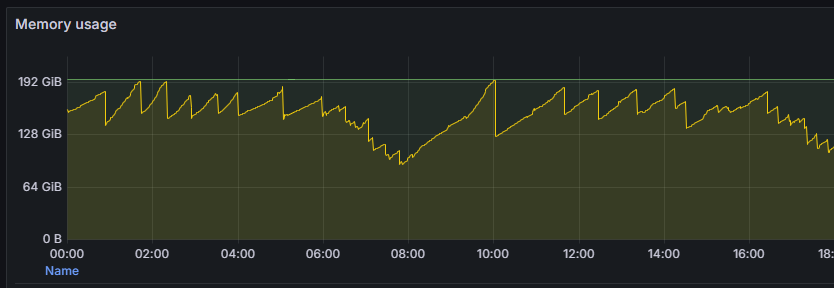
Первый этап анализа — понять, действительно ли мы имеем дело с утечкой, а не со штатным поведением платформы.
Как устроены утечки памяти в 1С
Платформа 1С использует автоматическое управление памятью со сборщиком мусора. В большинстве случаев объекты, созданные в серверном коде, освобождаются автоматически после завершения вызова. Однако существуют ситуации, когда объекты не могут быть освобождены:
Циклические ссылки — два или более объекта ссылаются друг на друга. Сборщик мусора 1С исторически не умел разрывать циклические ссылки. В современных версиях платформы механизм улучшен, но полностью полагаться на него не стоит — циклические ссылки остаются частой причиной утечек.
Накопление данных в долгоживущих переменных — когда в цикле обработки (например, по документам или организациям) на каждой итерации создаются объекты, которые добавляются в общую коллекцию или присваиваются переменной модуля, но не очищаются между итерациями. Формально это не утечка в классическом смысле, но эффект тот же — линейный рост потребления памяти.
Удержание ссылок на тяжёлые объекты — двоичные данные, COM-объекты, HTTP-соединения, которые не обнуляются явно после использования.
Как платформа фиксирует утечки в технологическом журнале
Платформа 1С предоставляет два связанных события в технологическом журнале (ТЖ):
Событие CALL — записывается при завершении каждого серверного вызова (обращение клиента к серверу, выполнение фонового задания и т.д.). Содержит итоговые показатели: Memory (потребление на момент завершения), MemoryPeak (максимум за время вызова), Module и Method (точка входа в коде), t:clientID (идентификатор соединения).
Событие LEAKS — записывается после CALL, если платформа обнаружила объекты, которые не были освобождены после завершения вызова. Содержит t:clientID (тот же, что в CALL — это ключ связи) и Descr — подробное описание каждого неосвобождённого объекта: его тип (KeyAndValue, Structure, Array, BinaryData и др.) и полный стек вызовов, показывающий, в какой строке какого модуля объект был создан.
Связка CALL → LEAKS по t:clientID позволяет ответить на три вопроса: какой вызов потребляет много памяти, что именно не освобождается и где в коде это происходит.
Для сбора LEAKS необходимо явно включить параметр <leaks collect="1"/> в logcfg.xml. Без него платформа не выполняет анализ неосвобождённых объектов и событие LEAKS не записывается.
Утечка vs. норма
Не каждое высокое потребление памяти — утечка. Важно различать три ситуации:
| Ситуация | Поведение памяти | Утечка? |
|---|---|---|
|
Тяжёлый отчёт / обработка |
Выросла → вызов завершился → освободилась |
Нет |
|
Кэш платформы (метаданные, сеансовые данные, ПовтИсп - повторное использование возвращаемых значений) |
Выросла до фиксированного уровня → стабилизировалась |
Нет |
|
Регламентное задание / фоновая обработка |
Растёт линейно с каждым вызовом, не возвращается |
Да |
| Избыточное потребление в цикле | Стабильно высокая на каждый вызов, но не растёт между вызовами | Нет, но требует оптимизации |
Методика работает для всех четырёх случаев. Даже если анализ покажет, что монотонного роста нет — вы получите ответ на вопрос «что именно потребляет память и где в коде это происходит». Это позволяет принять обоснованное решение: чинить срочно, оптимизировать планово или оставить как есть.
Признаки, подтверждающие утечку
Если вы наблюдаете совокупность следующих признаков — это с высокой вероятностью утечка:
Монотонный рост без возврата — на графике мониторинга память рабочего процесса (rphost) только растёт и никогда не снижается до прежнего уровня. Это главный и самый надёжный признак.
Один rphost потребляет значительно больше остальных — если в кластере несколько рабочих процессов и один из них выделяется по памяти, значит утечка привязана к конкретному сеансу или фоновому заданию.
Проблема воспроизводится после перезапуска — если перезапустить rphost, память возвращается к норме, но через некоторое время снова начинает расти по тому же сценарию.
Рост происходит в предсказуемое время — например, ночью, когда работают только регламентные задания. Это сужает круг подозреваемых.
Что должно быть готово перед Шагом 1
Данная методика предполагает, что:
- Технологический журнал настроен и собирает данные.В xml включены события CALL, LEAKS и параметр <leaks collect="1"/>. Подробная настройка описана в Приложении А.
- В логах присутствуют нужные события.Убедитесь, что в каталогах rphost_*/ есть файлы .log, в них встречаются события ,CALL, с полем MemoryPeak= и события ,LEAKS,. Если LEAKS отсутствуют — проверьте xml.
- Вы находитесь в каталоге с логами ТЖ(или знаете путь к ним). Все скрипты методики ожидают структуру rphost_*/*.log в текущем каталоге.
Шаг 1. Найти самые большие вызовы (CALL), у которых есть пара LEAKS
Получить список «кандидатов» — вызовов с большим MemoryPeak, для которых в логах реально встречается LEAKS с тем же t:clientID. Это отсекает «просто тяжёлые» вызовы от тех, где платформа зафиксировала утечку.
Почему именно так
- Событие CALL фиксирует завершение серверного вызова и содержит итоговые Memory/MemoryPeak — это «чек» по расходу памяти.
- Событие LEAKS пишется после CALL для того же t:clientID и содержит Descr — описание неосвобождённых объектов.
- Связка CALL → LEAKS по t:clientID — основной способ сказать: «этот вызов и тяжёлый, и течёт».
Шаг 1.1 — Общая картина по потребляемой памяти
Когда на сервере несколько баз или десятки фоновых заданий, начинать с поиска конкретных CID неудобно — результат будет слишком объёмным. Сначала группируем по Module.Method, чтобы понять: какие методы текут, сколько баз затронуто, каков масштаб.
# [STEP1_1_GROUP_BY_MODULE_METHOD]
PEAKMB=500
grep -hE ",CALL,|,LEAKS," rphost_*/*.log 2>/dev/null | \
awk -v PEAKMB="$PEAKMB" '
function cid(s, m) { return (match(s,/t:clientID=([0-9]+)/,m) ? m[1] : "") }
function pkMB(s, m) { return (match(s,/MemoryPeak=([0-9]+)/,m) ? int(m[1]/1048576) : -1) }
function getf(s,f, m) { return (match(s,f"=([^,]+)",m) ? m[1] : "N/A") }
{
c = cid($0); if (c == "") next
if ($0 ~ /,CALL,/) {
if (pkMB($0) >= PEAKMB) lastCall[c] = $0; else lastCall[c] = ""
next
}
if ($0 ~ /,LEAKS,/ && lastCall[c] != "") {
if (!seen[c]) {
seen[c] = 1
s = lastCall[c]
mod = getf(s, "Module")
meth = getf(s, "Method")
db = getf(s, "p:processName")
match(s, /Memory=([0-9]+)/, a); mem = int(a[1]/1048576)
match(s, /MemoryPeak=([0-9]+)/, a); peak = int(a[1]/1048576)
match(s, /CpuTime=([0-9]+)/, a); cpu = int(a[1]/1000)
key = mod "|" meth
cnt[key]++
sumMem[key] += mem
sumPeak[key] += peak
sumCpu[key] += cpu
if (peak > maxPeak[key]) maxPeak[key] = peak
dbkey = key "|" db
if (!seenDB[dbkey]) {
seenDB[dbkey] = 1
dbCnt[key]++
if (dbCnt[key] <= 3) dbs[key] = dbs[key] (dbs[key] ? ", " : "") db
}
}
}
}
END {
# заголовок в stderr — он не попадёт в sort
printf "%-50s %5s %10s %10s %10s %10s %s\n", \
"Module.Method", "Count", "AvgMem", "AvgPeak", "MaxPeak", "AvgCPU_s", "Databases" > "/dev/stderr"
printf "%-50s %5s %10s %10s %10s %10s %s\n", \
"--------------------------------------------------","-----","----------","----------","----------","----------", \
"-------------------" > "/dev/stderr"
# данные в stdout — пойдут в sort
for (k in cnt) {
split(k, parts, "|")
dbInfo = dbs[k]
if (dbCnt[k] > 3) dbInfo = dbInfo ", ... (+" (dbCnt[k]-3) " ещё)"
printf "%-50s %5d %8d МБ %8d МБ %8d МБ %8d с %s\n", \
parts[1] "." parts[2], \
cnt[k], \
int(sumMem[k]/cnt[k]), \
int(sumPeak[k]/cnt[k]), \
maxPeak[k], \
int(sumCpu[k]/cnt[k]), \
dbInfo
}
}' | sort -k2 -rn | head -20
Пример вывода результата
Module.Method Count AvgMem AvgPeak MaxPeak AvgCPU_s Databases
-------------------------------------------------------- ----- ---------- ---------- ---------- ---------- -------------------
ИнтеграцияЭДО.ОбработкаОчередиДокументовЭДО 6 1885 МБ 1950 МБ 9124 МБ 114046 с buh_org0, buh_org1
ЭДОФоновыеЗадания.ВыполнитьРегламентныеДействияЭДО 58 473 МБ 582 МБ 631 МБ 19227 с buh_org1, buh_org2, buh_org3, ... (+10 ещё)
ЛицензированиеСервер.РегламентноеЗаданиеМенеджерСеансов 41 840 МБ 874 МБ 948 МБ 15629 с buh_org4, buh_org0
Как читать результат
| Поле | Что показывает | На что обращать внимание |
|---|---|---|
|
Count |
Сколько раз метод попал в CALL+LEAKS |
Чем больше — тем системнее проблема |
|
AvgMem |
Среднее потребление на момент завершения |
Сколько «оседает» после вызова |
|
AvgPeak |
Средний пик за вызов |
Типичная нагрузка на память |
|
MaxPeak |
Максимальный пик среди всех вызовов |
Худший случай |
|
AvgCPU_s |
Среднее процессорное время (секунды) |
Косвенный признак объёма работы |
|
Databases |
Список затронутых баз |
Проблема в одной базе или во всех? |
Если один и тот же Module.Method встречается в 13 базах с Count=58 — это системная проблема, чинить в первую очередь. Если метод с MaxPeak=9124 МБ встретился 6 раз, но в 2 базах — это тяжёлая локальная проблема, приоритет по критичности ещё выше. Если метод встретился 1 раз с Peak=787 МБ — возможно, разовый инцидент.
Примечание: Каждый CID учитывается только один раз (по первой паре CALL+LEAKS). Если одно долгоживущее фоновое задание генерирует несколько пар CALL+LEAKS за длительный период, в Count попадёт только первая. Для первичного обзора это корректно — на следующих шагах мы увидим полную картину для конкретного CID.
Шаг 1.2 — Проверка динамики Memory для выбранного метода
После выбора метода из таблицы Шага 1.1 необходимо проверить, действительно ли память не освобождается между вызовами. Это самая быстрая и дешёвая проверка, которая отсекает ложноположительные срабатывания до начала тяжёлого анализа LEAKS.
Почему это нужно
Событие LEAKS фиксируется платформой при наличии неосвобождённых объектов после завершения вызова. Но «неосвобождённые объекты» — это не всегда утечка. Платформа может фиксировать:
- Кэш менеджеров метаданных (CatalogManager, EnumManager) — создаётся один раз, живёт до конца вызова
- Объекты ПовтИсп — штатный механизм повторного использования
- Сеансовые данные БСП — инициализация при старте фонового задания
Все эти объекты попадают в LEAKS, но не приводят к росту памяти между вызовами. Единственный надёжный способ отличить утечку от штатного поведения — посмотреть, возвращается ли Memory к исходному уровню после завершения вызова.
# [STEP1_2_MEMORY_DYNAMICS]
MODULE_FILTER="ОбработкаОчередиДокументовЭДО"
grep "$MODULE_FILTER" rphost_*/*.log | grep ",CALL," | \
awk '{
match($0,/Memory=([0-9]+)/,m); mem=int(m[1]/1048576)
match($0,/MemoryPeak=([0-9]+)/,p); peak=int(p[1]/1048576)
printf "%6d МБ / %6d МБ %s\n", mem, peak, $0
}' | head -30
Как читать результат
Левая колонка — Memory (сколько памяти «осело» после завершения вызова). Правая — MemoryPeak (максимум во время работы). Важна именно левая колонка — её динамика от строки к строке.
Пример: утечки нет
0 МБ / 4 МБ ...ОбработкаОчередиДокументовЭДО...
0 МБ / 4 МБ ...ОбработкаОчередиДокументовЭДО...
0 МБ / 4 МБ ...ОбработкаОчередиДокументовЭДО...
0 МБ / 4 МБ ...ОбработкаОчередиДокументовЭДО...
0 МБ / 30 МБ ...ОбработкаОчередиДокументовЭДО...
0 МБ / 30 МБ ...ОбработкаОчередиДокументовЭДО...
Memory возвращается к 0 после каждого вызова. MemoryPeak=682 МБ встречается у отдельных вызовов, но это пиковое потребление во время обработки большого объёма данных. После завершения вызова память освобождается. Это не утечка. Переходить к следующему методу из таблицы Шага 1.1.
Пример: утечка есть
200 МБ / 250 МБ ...ОбработкаОчередиДокументовЭДО...
350 МБ / 400 МБ ...ОбработкаОчередиДокументовЭДО...
474 МБ / 579 МБ ...ОбработкаОчередиДокументовЭДО...
510 МБ / 614 МБ ...ОбработкаОчередиДокументовЭДО...
Memory монотонно растёт от вызова к вызову и не возвращается к исходному уровню. Каждый следующий вызов начинает с того уровня, на котором закончился предыдущий. Это утечка. Продолжать анализ — переходить к Шагу 1.3.
Пример: стабильно высокая (кэш)
1457 МБ / 1480 МБ ...ОбработкаОчередиДокументовЭДО...
1453 МБ / 1476 МБ ...ОбработкаОчередиДокументовЭДО...
1453 МБ / 1476 МБ ...ОбработкаОчередиДокументовЭДО...
1455 МБ / 1477 МБ ...ОбработкаОчередиДокументовЭДО...
Memory стабильна на высоком уровне, но не растёт. Это фиксированный кэш (ПовтИсп, сеансовые данные). Не утечка, но может потребовать оптимизации, если объём кэша чрезмерный.
Сводная таблица решений
| Паттерн Memory | Интерпретация | Действие |
|---|---|---|
| 0 → 0 → 28 → 0 → 0 | Возвращается к норме | Не утечка. Следующий метод |
| 200 → 350 → 474 → 510 | Монотонный рост | Утечка. Шаг 1.3 |
| 500 → 500 → 500 → 500 | Стабильно высокая | Кэш. Оценить необходимость оптимизации |
| 0 → 0 → 0 → 500 → 500 | Однократный скачок, затем стабильна | Кэш, загруженный при первом вызове. Не утечка |
| 4621 → 8982 → 1457 → 1453 | Скачки, затем стабилизация | Тяжёлая обработка + кэш. Шаг 1.3 для анализа состава |
Если результат неоднозначный
Увеличьте выборку до 50–100 строк (замените head -30 на head -100) и посмотрите на более длинном интервале. Если тренд неочевиден — добавьте фильтр по конкретной базе:
grep "$MODULE_FILTER" rphost_*/*.log | grep ",CALL," | \
grep "p:processName=buh_org0" | \
awk '{
match($0,/Memory=([0-9]+)/,m); mem=int(m[1]/1048576)
match($0,/MemoryPeak=([0-9]+)/,p); peak=int(p[1]/1048576)
printf "%6d МБ / %6d МБ\n", mem, peak
}' | head -50
Это покажет динамику для одной базы, исключив «шум» от разных баз с разным объёмом данных.
Несколько баз — несколько паттернов
Один и тот же метод может вести себя по-разному в разных базах. Например, в одной базе Memory стабильно высокая (кэш), в другой — единичный всплеск до нескольких гигабайт, в третьей — память возвращается к нулю. Если картина неоднородная — фильтруйте по p:processName и анализируйте каждую базу отдельно. Для дальнейшего анализа выбирайте базу с самым тяжёлым или самым повторяемым паттерном.
Шаг 1.3 — Получить CID для выбранного метода
После выбора метода из таблицы Шага 1.1 получаем конкретные строки CALL с CID. Переменная MODULE_FILTER задаёт фильтр по имени метода. Если фильтр не нужен — закомментируйте строку с grep.
# [STEP1_3_CALLS_WITH_LEAKS]
PEAKMB=500
MODULE_FILTER="ОбработкаОчередиДокументовЭДО"
grep -HE ",CALL,|,LEAKS," rphost_*/*.log 2>/dev/null | \
grep -E ",LEAKS,|${MODULE_FILTER}" | \
awk -v PEAKMB="$PEAKMB" '
function cid(s,m){ return (match(s,/t:clientID=([0-9]+)/,m)? m[1]:"") }
function pkMB(s,m){ return (match(s,/MemoryPeak=([0-9]+)/,m)? int(m[1]/1048576) : -1) }
{
# отделяем имя файла (до первого ":")
match($0, /^([^:]+\.log):(.*)$/, parts)
fname = parts[1]
line = parts[2]
c=cid(line); if(c=="") next;
if(line ~ /,CALL,/){
if(pkMB(line) >= PEAKMB) { lastCall[c]=line; lastFile[c]=fname } else lastCall[c]="";
next;
}
if(line ~ /,LEAKS,/ && lastCall[c]!=""){
if(!printed[c]){
print "[CALL_WITH_LEAKS] FILE=" lastFile[c] "\t" lastCall[c];
printed[c]=1;
}
}
}' | tee results.txt | head -20
echo "[STEP1] Total: $(wc -l < results.txt) lines saved to results.txt"
В терминал выводятся первые 20 строк. Полный результат сохраняется в results.txt для использования в следующих шагах.
Пример результата
[CALL_WITH_LEAKS] FILE=rphost_69708/26041119.log 57:40.021001-778379997,CALL,1,
level=INFO,process=rphost,OSThread=5004,t:clientID=10857,callWait=0,first=1,
Usr=Svc_edo,SessionID=22291,p:processName=buh_org0,Func=Background job,
Module=ИнтеграцияЭДО,Method=ОбработкаОчередиДокументовЭДО,
Memory=9418812928,MemoryPeak=9567572248,InBytes=215530840,
OutBytes=156175074,CpuTime=515343750
Строка grep -E ",LEAKS,|${MODULE_FILTER}" пропускает все события LEAKS (они нужны для связки по clientID) и только те CALL, в которых встречается искомый метод. Остальные CALL отбрасываются до попадания в awk.
Как читать результат работы скрипта
| Поле | Что это | Зачем нужно |
|---|---|---|
| t:clientID=10857 | Идентификатор клиентского соединения | Ключ связи с LEAKS на следующих шагах |
| Module=ИнтеграцияЭДО | Модуль 1С | Понимаем, какой код вызвал проблему |
| Method=ОбработкаОчередиДокументовЭДО | Метод | Конкретная точка входа |
| Memory=9418812928 (~8982 МБ) | Память на момент завершения | Сколько «осело» после вызова |
| MemoryPeak=9567572248 (~9124 МБ) | Пиковое потребление | Максимум, достигнутый во время вызова |
| Usr=Svc_edo | Пользователь 1С | Для идентификации сценария |
| Func=Background job | Тип вызова | Фоновое задание — значит работает без UI |
Выбор CID для дальнейшего анализа. Если результат содержит несколько строк — выбираем CID с максимальным MemoryPeak:
grep "Module=ИнтеграцияЭДО" results.txt | \
awk '{match($0,/MemoryPeak=([0-9]+)/,m); print m[1]"\t"$0}' | \
sort -rn | head -1
Далее с этим CID переходим к Шагу 2.
Если результат пустой
- Снизить порог: PEAKMB=200 или PEAKMB=100.
- Проверить наличие логов:
ls rphost_*/*.log | head. - Проверить, включён ли сбор LEAKS в настройках ТЖ (параметр
<leaks>в logcfg.xml). - Проверить формат:
grep -c ",CALL," rphost_*/*.log | grep -v ":0$"— убедиться, что CALL-события вообще есть.
Шаг 2. Найти LEAKS и вырезать содержимое
По t:clientID из Шага 1 найти в логах строку LEAKS и вырезать фрагмент лога, содержащий полное описание утечки — список неосвобожденных объектов с их стеками вызовов.
Что мы ищем и зачем
Событие LEAKS содержит в поле Descr полное описание неосвобождённых объектов — их типы и стеки вызовов. Это многострочная запись, которая начинается сразу после заголовка события и может занимать тысячи строк. Именно это описание мы вырезаем для дальнейшего анализа.
# [STEP2_FIND_LEAKS_AND_SLICE]
CID=10857
# Ищем LEAKS по всем файлам — только строку с LEAKS для нужного CID
hit=$(grep -rHn "LEAKS.*t:clientID=${CID}[^0-9]" rphost_*/*.log 2>/dev/null | head -1)
echo "[STEP2] hit=$hit"
file=$(echo "$hit" | cut -d: -f1)
line=$(echo "$hit" | cut -d: -f2)
# Находим конец события LEAKS
end=$(tail -n +$((line+1)) "$file" | grep -n "^[0-9][0-9]:[0-9][0-9]\." | head -1 | cut -d: -f1)
end=$((line + end - 1))
start=$(( line>1 ? line-1 : 1 ))
sed -n "${start},${end}p" "$file" > "ctx_${CID}.log"
echo "[STEP2] written ctx_${CID}.log ($(wc -l < ctx_${CID}.log) lines)"
grep -rn "LEAKS.*t:clientID=${CID}[^0-9]"— ищет строку LEAKS с нужным clientID по всем rphost-логам. Суффикс[^0-9]исключает ложные совпадения (например, CID=46 не совпадёт с CID=460)..tail -n +$((line+1)) | grep -n "^[0-9][0-9]:[0-9][0-9]\."— от следующей строки после LEAKS ищет начало следующего события ТЖ (строка с временной меткой). Это конец описания утечки.sed -n "${start},${end}p"— вырезает фрагмент: 1 строку до LEAKS (CALL для этого же CID) и всё описание утечки до конца события.
Что мы увидим в результате выполнения
[STEP2] hit=rphost_69708/26041119.log:14379641:57:40.052000-0,LEAKS,1,
level=DEBUG,process=rphost,OSThread=5004,t:clientID=10857,
t:applicationName=BackgroundJob,t:computerName=app1,
t:connectID=365898,Descr='
KeyAndValue:
[STEP2] written ctx_10857.log (76929 lines)
Как читать результат
|
Поле |
Что это |
Зачем нужно |
|---|---|---|
|
:14379641: |
Номер строки |
Можем вернуться к сырому логу при необходимости |
|
t:applicationName=BackgroundJob |
Тип приложения |
Подтверждает: утечка в фоновом задании |
|
t:connectID=365898 |
ID соединения |
Дополнительный идентификатор для корреляции |
|
Descr=' … |
Начало описания утечки |
Дальше идет список объектов с типами и стеками вызовов |
Что внутри файла ctx_10857.log
- 1-2 строки до—предшествующее событие (CALL строка для этого же ClientID)
- Строка LEAKS— заголовок события с t:clientID, t:applicationName и началом Descr='
- Десятки тысяч строк описания — при тяжёлых вызовах (гигабайты памяти) файл может содержать 50 000–100 000 строк. В нашем случае 76 929 строк для вызова с пиком 9 ГБ:
KeyAndValue:
ЭДО Обработка.ЭДОЯдро.МодульОбъекта : 16801 : ...
ЭДО Обработка.МодульЕДО.МодульОбъекта : 8396 : ...
...
Если hit пустой
- Проверить, есть ли LEAKS вообще:
grep -rc "LEAKS" rphost_*/*.log | grep -v ":0$" - Проверить CID:
grep -r "t:clientID=${CID}[^0-9]" rphost_*/*.log | head -3 - Проверить, что CID правильный: номер должен совпадать с тем, что показал Шаг 1.3
Большие файлы LEAKS. При анализе вызовов с потреблением в несколько гигабайт событие LEAKS может содержать десятки тысяч строк. Команда tail -n +<номер> на файле в миллионы строк может работать медленно. Если поиск конца события занимает больше минуты — ограничьте поиск: tail -n +$((line+1)) "$file" | head -500000 | grep -n "^[0-9][0-9]:[0-9][0-9]\." | head -1.
Шаг 3. Агрегировать содержимое LEAKS: "что течёт" и "куда копать"
Из ctx_<CID>.log получить два среза:
- ТОП типов объектов— какие типы данных 1С «текут» (KeyAndValue, Array, Structure, ValueTable, BinaryData и т.п.)
- ТОП строк кода— какие конкретные строки модулей чаще всего встречаются в стеках утёкших объектов
Это даёт первичное понимание: что утекает и откуда.
3.1 - ТОП типов объектов
# [STEP3_TOP_TYPES]
CID=10857
grep -oE "^[^[:space:]][^:]+:" ctx_${CID}.log | \
sort | uniq -c | sort -rn | head -30
-
grep -oE "^[^[:space:]][^:]+:" — ищет строки, начинающиеся с непробельного символа и заканчивающиеся двоеточием. В содержимом LEAKS так записаны типы объектов: KeyAndValue:, Array:, Structure:, а также составные имена вроде EnumManager.ВидыСвойств:, InformationRegisterManager.НастройкиОтчетов:.
- sort | uniq -c | sort -rn— классический подсчёт уникальных значений с сортировкой по убыванию.
В результате выполнения скрипта мы видим
5538 KeyAndValue:
1 FixedArray:
| Ключ | Количество | Элемент коллекции | Важность |
|---|---|---|---|
| KeyAndValue: | 5538 | (Структура, Соответствие, ФиксированнаяСтруктура) — пара «ключ-значение» | Высокая — массовое создание, признак накопления в цикле |
| FixedArray: | 1 | Фиксированный массив | Низкая — единичный, скорее контейнер верхнего уровня |
| Structure: | — | Структура | Зависит от количества |
| ValueTable: | — | Таблица значений | Высокая. Если много — тяжёлые данные |
| BinaryData: | — | Двоичные данные (файлы, картинки) | Высокая. Очень тяжёлые объекты |
| COMObject: | — | Внешний COM-объект | Высокая. Часто не освобождается автоматически |
Вывод по нашему случаю: 5538 объектов KeyAndValue при 1 объекте FixedArray — это массовое создание пар «ключ-значение» в цикле обработки очереди документов. Масштаб (тысячи объектов) соответствует количеству документов в очереди. FixedArray — единичный, скорее контейнер верхнего уровня.
3.2 - ТОП строк кода
# [STEP3_TOP_CODELINES]
CID=10857
grep -oE "[^[:space:]]+ : [0-9]+ :" ctx_${CID}.log | \
sort | uniq -c | sort -rn | head -50
- grep -oE "[^[:space:]]+ : [0-9]+ :"— ищет паттерн Модуль : НомерСтроки :, который платформа 1С использует в стеках LEAKS для указания точки в коде.
- Подсчёт и сортировка — аналогично 3.1.
При выполнении мы увидим подобный результат
5491 ОбщийМодуль.ИнтеграцияЭДО.Модуль : 364 :
5251 ОбщийМодуль.ИнтеграцияЭДО.Модуль : 695 :
4691 РегистрСведений.СписокДокументовОтправкаПакетовЭДО.МодульМенеджера : 14 :
4638 ОбщийМодуль.ИнтеграцияЭДО.Модуль : 1354 :
4634 Обработка.ЭДОЯдро.МодульОбъекта : 29769 :
4634 Обработка.ЭДОВызовы.МодульОбъекта : 6246 :
4634 Обработка.ЭДОВызовы.МодульОбъекта : 5894 :
3950 Обработка.ЭДОЯдро.МодульОбъекта : 29632 :
3950 Обработка.ЭДОЯдро.МодульОбъекта : 16418 :
3950 Обработка.ЭДОХранениеДанных.МодульОбъекта : 16122 :
3950 Обработка.ЭДОХранениеДанных.МодульОбъекта : 14115 :
3950 Обработка.ЭДОХранениеДанных.МодульОбъекта : 13747 :
729 ОбщийМодуль.ИнтеграцияЭДО.Модуль : 23 :
514 Обработка.ЭДОСтандартУФ.МодульОбъекта : 165 :
496 Обработка.ЭДОЯдро.МодульОбъекта : 29673 :
...
Результат — это «тепловая карта» кода: чем больше число слева, тем чаще эта строка встречается в стеках утёкших объектов.
Структура данных (три уровня):
| Уровень | Счётчик | Строки | Интерпретация |
|---|---|---|---|
| Ядро цикла | 5491–4634 | :364, :695, :14, :1354, :29769, :6246, :5894 | Точка входа и общий путь — почти все объекты проходят здесь |
| Тело операции | 3950 | :29632, :16418, :16122, :14115, :13747 | ЭДОХранениеДанных — здесь создаются основные данные (71% объектов) |
| Ветвления | 100–729 | :23, :165, :29673 и т.д. | Разные ветки: инициализация, виды пакетов, метрика |
Правило чтения:
- Строки с близким счётчиком (5491, 5251, 4691, 4638, 4634) — это один и тот же стек вызовов на разных уровнях вложенности. Небольшие расхождения (5491 vs 4634) означают, что часть объектов создаётся до ветвления.
- Резкое падение счётчика (4634 → 3950 → 729 → 496) — точки ветвления: код расходится на разные сценарии.
- Доминирующая группа 3950 (71%) — основная зона накопления данных в ЭДОХранениеДанных.
Визуализация цепочки по нашим данным:
5491 :364 -- точка входа (ПроверитьОбновитьКэшПоДокументу)
5251 :695 -- ОбновитьСписокДокументов
|
4691 ---- :14 АвторизоватьсяПодЛогином |
4638 ---- :1354 ЭДО_Авторизоваться | основной ствол
4634 ---- :5894 > :6246 > :29769 |
|
3950 ---- :29632 > :16418 > :13747 | ЭДОХранениеДанных (71%)
|
729 ---- :23 Инициализация | ветка инициализации
496 ---- :29673 Metadata.Вставить | ветка метаданных
Что это даёт:
- Верхние строки (5491–4634) — точка входа и основной ствол, менять здесь обычно не нужно.
- Группа 3950 — зона, где создаются основные данные (ЭДОХранениеДанных). Здесь искать причину.
- Строки 100–729 — побочные ветки (инициализация, метаданные), чинить во вторую очередь.
Если типов объектов много и разных
Когда в результате работы скрипта из 3.1 видим разнородную картину:
1500 KeyAndValue:
800 Structure:
200 Array:
150 BinaryData:
50 ValueTable:
Это означает несколько разных утечек в одном вызове. Нужно повторить Шаг 6 отдельно для каждого типа (заменив KeyAndValue на Structure, BinaryData и т.д.).
Шаг 4. Классифицировать проблему
По результатам Шагов 1–3 определить тип проблемы и приоритет исправления, не заглядывая в код 1С.
Матрица классификации
|
Признак объекта |
Накопление в цикле |
Кэш/ПовтИсп |
Тяжелые объекты |
Внешние ресурсы |
|
Тип объекта |
KeyAndValue, Structure, Array |
KeyAndValue, Structure |
BinaryData, ValueTable, HTTPResponse |
COMObject, XMLWriter |
|
Счётчик в 3.2 |
Десятки–сотни одинаковых |
1–5 |
1–10, но Memory огромный |
1–10 |
|
Повторяемость строк |
Одни и те же строки ×N |
Уникальные строки |
Мало строк, но большой Memory |
Мало строк |
|
Наличие ПовтИсп |
Нет или мало |
Доминирует |
Нет |
Нет |
|
Приоритет |
Срочно — линейный рост памяти |
Низкий — фиксированный объём |
Высокий — скачкообразный рост |
Срочно — возможна утечка за пределами 1С |
Применение к нашему случаю
| Признак | Значение | Интерпретация |
|---|---|---|
| Тип объекта | KeyAndValue: (5538) | Пары ключ-значение из структур |
| Счётчик | 3950 одинаковых стеков | Массовый цикл по документам |
| ПовтИсп | Нет | Не кэш платформы |
| Memory/MemoryPeak | 1457 / 1480 МБ (стабильно) | Тяжёлый, но не растёт |
| Паттерн Memory | Стабильная между вызовами | Не классическая утечка |
Классификация: Избыточное создание объектов в цикле. Формально не утечка (память не растёт между вызовами), но каждый вызов фонового задания потребляет ~1.5 ГБ из-за повторной авторизации и загрузки справочника на каждый документ в очереди. Приоритет — высокий (оптимизация).
Что подготовить для задачи по исправлению (3 артефакта)
|
1 |
CALL-строка |
Шаг 1 |
Текст — одна строка с Module, Method, Memory, MemoryPeak |
|
2 |
Сводка анализа |
Шаги 3–4 |
Текст — TOP_TYPES (10 строк) + TOP_CODELINES (20 строк) + классификация |
|
3 |
Срез лога с описанием утечки |
Шаг 2 |
Файл ctx_<CID>.log — для просмотра содержимого LEAKS |
Скрипт для выделения top-5 точек входа
# [STEP4_TOP5_CODELINES]
CID=10857
grep -oE "[^[:space:]]+ : [0-9]+ :" ctx_${CID}.log | \
sort | uniq -c | sort -rn | head -5
Это тот же скрипт из Шага 3.2, но берём только top-5 для компактности
Пример результата работы
5491 ОбщийМодуль.ИнтеграцияЭДО.Модуль : 364 :
5251 ОбщийМодуль.ИнтеграцияЭДО.Модуль : 695 :
4691 РегистрСведений.СписокДокументовОтправкаПакетовЭДО.МодульМенеджера : 14 :
4638 ОбщийМодуль.ИнтеграцияЭДО.Модуль : 1354 :
4634 Обработка.ЭДОЯдро.МодульОбъекта : 29769 :
Как читать: это не «5 разных проблем», а один стек
Все пять строк имеют близкие счётчики (5491–4634) — значит они встречаются вместе в стеке почти каждого утёкшего объекта. Небольшие расхождения означают, что часть объектов создаётся до ветвления на разные сценарии.
Это цепочка вызовов:
[1] ИнтеграцияЭДО : 364 — точка входа (ПроверитьОбновитьКэшПоДокументу)
[2] ИнтеграцияЭДО : 695 — ОбновитьСписокДокументов
[3] СписокДокументовЭДО : 14 — авторизация перед обновлением
[4] ИнтеграцияЭДО : 1354 — ЭДО_АвторизоватьсяПодЛогином
[5] ЭДОЯдро : 29769 — проверка ТипыДокументов (после авторизации)
Для разработчика важны строки [3]–[5] — на каждой итерации цикла по документам вызывается авторизация, после которой загружается справочник типов документов. Оба действия можно выполнить один раз перед циклом.
Шаг 5. Вытащить «окрестность стека» по топ-строкам
Этот шаг опциональный. Выполняется при первом анализе незнакомого кода или когда результат Шага 3.2 неоднозначен. При повторном анализе похожих случаев — переходить сразу к Шагу 6.
Дать разработчику не просто список Модуль : строка, а контекст: какие типы объектов и какой стек вызовов окружают каждую топ-строку. Это позволяет увидеть причинно-следственную связь: «в этом месте кода создаётся вот такой объект».
Почему это нужно
Результат Шага 3 — это «плоский» список. Он не показывает:
- Какой тип объекта создаётся в конкретной строке
- Какие вызовы идут до и после
- Есть ли цикл (повторяющийся паттерн)
Шаг 5 восстанавливает эту связь из содержимого LEAKS.
# [STEP5_SHOW_CONTEXT_AROUND_TOPLINES]
CID=10857
for pat in \
"ОбщийМодуль.ИнтеграцияЭДО.Модуль : 364 :" \
"ОбщийМодуль.ИнтеграцияЭДО.Модуль : 695 :" \
"РегистрСведений.СписокДокументовОтправкаПакетовЭДО.МодульМенеджера : 14 :" \
"ОбщийМодуль.ИнтеграцияЭДО.Модуль : 1354 :" \
"Обработка.ЭДОЯдро.МодульОбъекта : 29769 :" \
; do
echo "===== $pat ====="
grep -nF "$pat" "ctx_${CID}.log" | head -3 | cut -d: -f1 | \
while read -r n; do
echo "--- hit at line $n ---"
start=$(( n>20 ? n-20 : 1 ))
end=$(( n+20 ))
sed -n "${start},${end}p" "ctx_${CID}.log"
done
done
Как работает скрипт
- Цикл for pat in ...— перебирает top-5 строк кода из Шага 4.
- grep -nF "$pat"— ищет каждую строку в ctx_<CID>.log с номером строки (-n) и точным совпадением (-F).
- head -3— берём максимум 3 вхождения (больше обычно не нужно — паттерн повторяется).
- sed -n "${start},${end}p"— вырезаем окно ±20 строк вокруг каждого вхождения.
Пример одного блока
===== ОбщийМодуль.ИнтеграцияЭДО.Модуль : 1354 : =====
--- hit at line 5 ---
KeyAndValue:
ЭДО Обработка.ЭДОХранениеДанных.МодульОбъекта : 13747 :
Результат = ДопСправочники_СписокЭлементов(ИмяСправочника, ПереченьРеквизитов);
ЭДО Обработка.ЭДОХранениеДанных.МодульОбъекта : 14115 :
ЭДО Обработка.ЭДОХранениеДанных.МодульОбъекта : 16122 :
ЭДО Обработка.ЭДОЯдро.МодульОбъекта : 16418 :
Результат = Модуль_ХранениеДанных.ДопСправочники_СписокЭлементов(...);
ЭДО Обработка.ЭДОЯдро.МодульОбъекта : 29632 :
ТипыДокументов = ХранениеДанных_СписокЭлементовДопСправочника(...);
ЭДО Обработка.ЭДОЯдро.МодульОбъекта : 29769 :
ТипыДокументов = ПредопределенныеСписки_ТипыДокументов();
ЭДО Обработка.ЭДОВызовы.МодульОбъекта : 6246 :
Ядро.ТипыДокументов_ПроверитьНаличие();
ЭДО Обработка.ЭДОВызовы.МодульОбъекта : 5894 :
ОбработатьСобытияПослеАвторизации();
ЭДО ОбщийМодуль.ИнтеграцияЭДО.Модуль : 1354 :
Токен = ЭДОВызовы.ЭДО_АвторизоватьсяПодЛогином(...);
ЭДО РегистрСведений.СписокДокументовОтправкаПакетовЭДО.МодульМенеджера : 14 :
Токен = ИнтеграцияЭДО.АвторизоватьсяПодЛогином(...);
ЭДО ОбщийМодуль.ИнтеграцияЭДО.Модуль : 695 :
ОбновитьСписокДокументов(ПараметрыОтправки);
ЭДО ОбщийМодуль.ИнтеграцияЭДО.Модуль : 364 :
ПроверитьОбновитьКэшПоДокументу(СтрокаОчереди.Документ1С);
KeyAndValue:
ЭДО Обработка.ЭДОХранениеДанных.МодульОбъекта : 13747 :
...
Как читать результат Шага 5, структура одного блока:
KeyAndValue: — ТИП неосвобождённого объекта
...ЭДОХранениеДанных : 13747 : — где создан объект (глубина стека)
Результат = ДопСправочники_... — код строки
...ЭДОЯдро : 16418 :
...ЭДОЯдро : 29632 : — загрузка справочника ТипыДокументов
...ЭДОЯдро : 29769 :
...ЭДОВызовы : 6246 : — проверка после авторизации
...ЭДОВызовы : 5894 : — ОбработатьСобытияПослеАвторизации
...ИнтеграцияЭДО : 1354 : — авторизация
...СписокДокументовЭДО : 14 : — вызов авторизации из обновления списка
...ИнтеграцияЭДО : 695 : — ОбновитьСписокДокументов
...ИнтеграцияЭДО : 364 : — точка входа
KeyAndValue: — СЛЕДУЮЩИЙ объект (тот же паттерн!)
На что обращать внимание:
|
Тип перед стеком |
KeyAndValue:, Array:, Structure: |
Понимаем, что именно создаётся в этой точке |
|
Повторяемость блоков |
Одинаковые блоки идут подряд |
Подтверждение цикла — каждая итерация создаёт объект |
|
Код строки (если виден) |
Токен = ...АвторизоватьсяПодЛогином(...) |
Конкретная операция, создающая объект |
|
Порядок стека |
От «глубокого» вызова к точке входа |
Восстанавливаем цепочку: кто кого вызвал |
Ключевой признак проблемы в нашем случае:
Блоки KeyAndValue: с идентичным стеком идут один за другим — это значит, что один и тот же код на каждой итерации создаёт KeyAndValue, и ни один из них не освобождается до завершения всего вызова.
Чек-лист по результатам Шага 5
По каждому «снимку» отвечаем на вопросы:
| # | Вопрос | Как определить | Наш случай |
|---|---|---|---|
| 1 | Это создание данных в цикле? | Одинаковые блоки подряд = да | Да — 3950+ одинаковых блоков |
| 2 | Что создаётся? | Тип перед стеком | KeyAndValue — пара ключ-значение |
| 3 | Где создаётся? | Верхняя строка стека | :13747 в ЭДОХранениеДанных |
| 4 | Кто вызывает? | Следующие строки стека | :1354 → ЭДО_АвторизоватьсяПодЛогином → :5894 → ТипыДокументов |
| 5 | Есть ли сброс между итерациями? | Искать в коде = Неопределено / .Очистить() | Нет — объекты накапливаются |
| 6 | Можно ли вынести из цикла? | Если результат не зависит от итерации | Авторизацию и загрузку справочника можно выполнить один раз перед циклом |
Шаг 6. Свести LEAKS к «повторяющемуся сценарию» и выделить подозрительный участок цикла
Автоматически сгруппировать утёкшие объекты по сигнатуре стека — уникальной цепочке вызовов. Это заменяет ручной просмотр содержимого LEAKS (как в опциональном Шаге 5) и даёт точный ответ: сколько разных «сценариев утечки» существует и какой из них доминирует.
Почему нельзя остановиться на Шаге 5
Шаг 5 показывает 1–3 примера для каждой топ-строки. Но:
- Одна строка кода может участвовать в разных цепочках вызовов
- Разные ветки кода могут проходить через одну и ту же строку
- Без группировки непонятно, сколько объектов создаёт каждый сценарий
Шаг 6 решает эту проблему: берёт полный стек каждого объекта, приводит к единому формату и считает повторения.
# [STEP6_STACK_SIGNATURES]
CID=10857
DEPTH=8
awk -v DEPTH="$DEPTH" '
# Ловим начало любого утёкшего объекта
/^[^[:space:]].*:$/ {
capturing = 1
k = 0
sig = ""
next
}
capturing && / : [0-9]+ :/ {
# нормализуем пробелы
gsub(/^[[:space:]]+/, "")
gsub(/[[:space:]]+$/, "")
gsub(/[[:space:]]+/, " ")
sig = sig $0 "|"
k++
if (k >= DEPTH) {
counts[sig]++
capturing = 0
}
next
}
# Любая строка, не похожая на стек, прерывает захват
capturing && !( / : [0-9]+ :/ ) {
# Если успели набрать хотя бы 1 строку — считаем укороченную сигнатуру
if (k > 0) counts[sig]++
capturing = 0
}
END {
for (s in counts) {
print counts[s] "\t" s
}
}
' "ctx_${CID}.log" | sort -rn | head -20
Как работает скрипт (пошагово)
- Триггер
/^[^[:space:]].*:$/— обнаруживает начало нового утёкшего объекта в описании утечки. Ловит любую строку, начинающуюся с непробельного символа и заканчивающуюся двоеточием — это универсальный паттерн для всех типов объектов (KeyAndValue:, Structure:, Array: и т.д.). - Захват стека— следующие строки, содержащие : число : (формат стека 1С), собираются в строку-сигнатуру через разделитель |.
- Ограничение глубины DEPTH=8— берём первые 8 уровней стека. Этого достаточно, чтобы различить сценарии, но не перегрузить группировку.
- Прерывание захвата— если встретилась строка без паттерна стека, захват останавливается (стек закончился).
- Агрегация counts[sig]++— одинаковые сигнатуры суммируются.
- Сортировка— самые частые сигнатуры наверху.
Параметр DEPTH
|
4–5 |
Грубая группировка, много разных стеков |
Может объединить разные сценарии |
|
8 |
Стандарт — различает основные ветки |
Оптимальный баланс |
|
12–15 |
Детальная группировка |
Может «разбить» один сценарий на подварианты |
Как адаптировать для других типов объектов
Если в Шаге 3.1 доминирует не KeyAndValue, а другой тип — заменяем триггер:
# Для Structure:
/^[[:space:]]*Structure:/ {
# Для BinaryData:
/^[[:space:]]*BinaryData:/ {
# Для любого типа (универсально):
/^[^[:space:]][^:]+:$/ {
Пример результата
3950 ...ИнтеграцияЭДО.Модуль : 364 : ПроверитьОбновитьКэшПоДокументу|
...ИнтеграцияЭДО.Модуль : 695 : ОбновитьСписокДокументов|
...СписокДокументовОтправкаПакетовЭДО : 14 : АвторизоватьсяПодЛогином|
...ИнтеграцияЭДО.Модуль : 1354 : ЭДО_АвторизоватьсяПодЛогином|
...ЭДОВызовы : 5894 : ОбработатьСобытияПослеАвторизации|
...ЭДОВызовы : 6246 : ТипыДокументов_ПроверитьНаличие|
...ЭДОЯдро : 29769 : ПредопределенныеСписки_ТипыДокументов|
...ЭДОЯдро : 29632 : ХранениеДанных_СписокЭлементовДопСправочника|
...ЭДОЯдро : 16418 : ДопСправочники_СписокЭлементов|
...ЭДОХранениеДанных : 13747 : ДопСправочники_СписокЭлементов|
496 ...тот же ствол до :29769...|
...ЭДОЯдро : 29673 : Metadata.Вставить|
188 ...тот же ствол до :29769...|
...ЭДОЯдро : 29668 : Metadata.Вставить|
107 ...:364|:695|:25 ОбновитьСписокДокументовКонтекст|
...:194 ОчиститьОбработанныеЗаписи|:23 Инициализация|...|
87 ...:364|:695|:25|:180 СписокДокументов|:31 ПолучитьОбработкуЭДО|:23 Инициализация|...|
73 ...:364|:681 ПолучитьОбработкуЭДО|:23 Инициализация|...СтандартУФ...|
65 ...:364|:695|:6 ПолучитьОбработкуЭДО|:23 Инициализация|...|
48 ...:364|:688 ПолучитьВидыДокументовДляОтбора|:8 МассивВидовПакетов|
...:28874 ВидыПакетов|:29154 Новый Структура(КлючиДляОписанияВида)|
46 ...:364|:695|:25|:178 СписокДокументов_Документы|
...:39536 Для Каждого ВидПакета|:28874 ВидыПакетов|:29154 Новый Структура|
27 ...:364|:695|:14|:1356 ЗаполнитьКонтекстСеанса|...Метрика...|
Как читать результат — дерево сценариев
Все сигнатуры сходятся в одну точку входа (:364 ПроверитьОбновитьКэшПоДокументу) и расходятся на три основные ветки:
Точка входа: :364 ПроверитьОбновитьКэшПоДокументу
|
+-- :695 ОбновитьСписокДокументов
| |
| +-- :14 АвторизоватьсяПодЛогином 4661 объект (84%)
| | |
| | +-- :1354 ЭДО_АвторизоватьсяПодЛогином
| | | |
| | | +-- :5894 > :6246 > :29769 > :29632 > ЭДОХранениеДанных
| | | | 3950 объектов (71%) -- ТипыДокументов
| | | |
| | | +-- :5894 > :6246 > :29769 > :29673 Metadata.Вставить
| | | | 496 объектов (9%)
| | | |
| | | `-- :5894 > :6246 > :29769 > :29668 Metadata.Вставить
| | | 188 объектов (3.4%)
| | |
| | `-- :1356 ЗаполнитьКонтекстСеанса > Метрика
| | 27 объектов (0.5%)
| |
| +-- :25 ОбновитьСписокДокументовКонтекст 240 объектов (4.3%)
| | +-- :194 ОчиститьОбработанныеЗаписи > :23 Инициализация
| | | 107 объектов
| | +-- :180 СписокДокументов > :23 Инициализация
| | | 87 объектов
| | `-- :178 СписокДокументов_Документы > ВидыПакетов
| | 46 объектов
| |
| `-- :6 ПолучитьОбработкуЭДО > :23 Инициализация
| 65 объектов (1.2%)
|
+-- :681 ПолучитьОбработкуЭДО > :23 Инициализация > ЭДОСтандартУФ
| 73 объекта (1.3%)
|
`-- :688 ПолучитьВидыДокументовДляОтбора > ВидыПакетов
48 объектов (0.9%)
Сводная таблица сценариев
| Сценарий | Объектов | % | Точка в коде | Суть |
|---|---|---|---|---|
| Авторизация → ТипыДокументов → ЭДОХранениеДанных | 3950 | 71.3% | ДопСправочники_СписокЭлементов | Загрузка справочника после авторизации в цикле |
| Авторизация → Metadata.Вставить | 684 | 12.4% | ПредопределенныеСписки_ТипыДокументов | Заполнение метаданных при авторизации |
| Инициализация контекста (разные точки входа) | 332 | 6.0% | ИнициализироватьОбщийКонтекст | ПолучитьОбработкуЭДО → инициализация в цикле |
| ВидыПакетов (ПредопределенныеСписки) | 94 | 1.7% | ПредопределенныеСписки_ВидыПакетов | Новый Структура в цикле по видам |
| КонтекстСеанса → Метрика | 27 | 0.5% | ЗаполнитьКонтекстСеанса | Статистика при заполнении контекста |
| Прочие | 451 | 8.1% | Разные | Мелкие ветвления |
| Итого | 5538 | 100% |
Главный вывод Шага 6
4634 из 5538 объектов (83.7%) создаются в цепочке АвторизоватьсяПодЛогином → ЭДО_АвторизоватьсяПодЛогином → ОбработатьСобытияПослеАвторизации → ТипыДокументов.
На каждой итерации цикла по документам очереди происходит:
- Авторизация в сервисе ЭДО (:14 → :1354)
- После авторизации — проверка и загрузка справочника ТипыДокументов (:5894 → :6246 → :29769)
- Загрузка справочника из хранилища данных (:29632 → :16418 → :13747)
Результат не освобождается между итерациями. При очереди в тысячи документов это даёт гигабайты неосвобождённых объектов за один вызов фонового задания.
Это не классическая утечка с монотонным ростом между вызовами — память стабилизируется на ~1.5 ГБ и не растёт дальше. Но это избыточное потребление: авторизацию и загрузку справочника можно выполнить один раз перед циклом.
Шаг 7. Фиксируем результат
Собрать из результатов Шагов 1–6 готовую задачу, которую разработчик может взять в работу без дополнительных вопросов.
Упаковка артефактов для передачи разработчику
После завершения анализа (Шаги 1–6) у нас накопилось несколько файлов, разбросанных по текущему каталогу. Чтобы передать разработчику готовый комплект — собираем всё в одну папку. Это удобно: можно приложить к задаче в трекере, отправить архивом или положить на общий диск.
Файлы для передачи разработчику
| # | Файл | Содержимое | Источник |
|---|---|---|---|
| 1 | call.txt | CALL-строка | Шаг 1 |
| 2 | ctx_10857.log | Срез лога с описанием (~76 000 строк) | Шаг 2 |
| 3 | top_types.txt | ТОП типов объектов | Шаг 3.1 |
| 4 | top_codelines.txt | ТОП строк кода | Шаг 3.2 |
| 5 | stack_signatures.txt | Сигнатуры стеков | Шаг 6 |
Скрипт для автоматической упаковки
# [STEP7_PACKAGE]
CID=10857
DIR="case_${CID}"
FILE="rphost_69708/26041119.log" # файл из hit на Шаге 2
mkdir -p "$DIR"
# CALL-строка — из конкретного файла, найденного на Шаге 2
grep ",CALL,.*t:clientID=${CID}[^0-9]" "$FILE" | \
tail -1 > "${DIR}/call.txt"
# Содержимое
cp "ctx_${CID}.log" "${DIR}/"
# Типы объектов
grep -oE "^[^[:space:]][^:]+:" "ctx_${CID}.log" | \
sort | uniq -c | sort -rn > "${DIR}/top_types.txt"
# Строки кода
grep -oE "[^[:space:]]+ : [0-9]+ :" "ctx_${CID}.log" | \
sort | uniq -c | sort -rn > "${DIR}/top_codelines.txt"
# Сигнатуры стеков
AWK_TMP=$(mktemp /tmp/step7_XXXXXX.awk)
cat > "$AWK_TMP" << 'AWKEOF'
/^[^[:space:]].*:$/ {
capturing = 1; k = 0; sig = ""; next
}
capturing && / : [0-9]+ :/ {
gsub(/^[[:space:]]+/, ""); gsub(/[[:space:]]+$/, ""); gsub(/[[:space:]]+/, " ")
sig = sig $0 "|"; k++
if (k >= DEPTH) { counts[sig]++; capturing = 0 }
next
}
capturing { if (k > 0) counts[sig]++; capturing = 0 }
END {
for (s in counts) print counts[s] "\t" s
}
AWKEOF
awk -v DEPTH=8 -f "$AWK_TMP" "ctx_${CID}.log" | \
sort -rn > "${DIR}/stack_signatures.txt"
rm -f "$AWK_TMP"
echo "[STEP7] Packaged into ${DIR}/:"
ls -la "${DIR}/"
Результат упаковки данных по расследованию
[STEP7] Packaged into case_10857/:
-rw-r--r-- 1 user user 450 Jun 12 10:00 call.txt
-rw-r--r-- 1 user user 3845000 Jun 12 10:00 ctx_10857.log
-rw-r--r-- 1 user user 52 Jun 12 10:00 top_types.txt
-rw-r--r-- 1 user user 4200 Jun 12 10:00 top_codelines.txt
-rw-r--r-- 1 user user 3800 Jun 12 10:00 stack_signatures.txt
Проверка после исправления
После исправления и переноса доработок на боевой сервер повторите Шаги 1–3 на новых логах:
- Шаг 1— если метод исчез из результатов или MemoryPeak значительно снизился — исправление сработало
- Шаг 3— если количество объектов в LEAKS уменьшилось — утечка устранена частично или полностью
- График мониторинга— если память рабочего процесса rphost перестала расти монотонно — проблема решена
| Результат проверки | Действие |
|---|---|
| Метод отсутствует в Шаге 1.1, Memory на вызов снизилась | Закрыть задачу |
| MemoryPeak снизился (например, с 9 ГБ до 500 МБ), LEAKS остались | Частичное исправление — повторить Шаги 3–6 для остатка |
| Memory на вызов не изменилась | Исправление не попало или не затронуло основной сценарий |
| Memory между вызовами перестала расти (если была утечка) | Утечка устранена, даже если LEAKS ещё есть |
Сводная карта методики
|
Предварительная диагностика |
Подтверждение утечки или избыточного потребления |
|---|---|
|
Найти CALL + LEAKS по порогу MemoryPeak |
CID, Module, Method, Peak |
|
Найти LEAKS, вырезать содержимое |
ctx_<CID>.log |
|
Агрегировать: типы + строки кода |
TOP_TYPES, TOP_CODELINES |
|
Классифицировать проблему |
Тип: цикл / кэш / тяжёлый |
|
Контекст вокруг топ-строк (опционально) |
Снимки стека с типами |
|
Сигнатуры стеков → дерево сценариев |
Сценарии утечки |
|
Задача разработчику + упаковка + верификация |
case_<CID>/ |
Приложение А. Пример настройки технологического журнала
<?xml version="1.0"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log location="E:\1c_logs\log_memory_leaks" history="12">
<event>
<eq property="Name" value="CALL"/>
</event>
<event>
<eq property="Name" value="LEAKS"/>
</event>
<property name="all"/>
</log>
<leaks collect = "1">
<point call = "server"/>
</leaks>
</config>
<?xml version="1.0"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<log location="E:\1c_logs\log_memory_leaks" history="12">
<event>
<eq property="Name" value="CALL"/>
</event>
<event>
<eq property="Name" value="LEAKS"/>
</event>
<property name="all"/>
</log>
<leaks collect = "1">
<point call = "server"/>
</leaks>
</config>Влияние на производительность
Параметр <leaks collect="1"> включает анализ неосвобождённых объектов после каждого серверного вызова. Это создаёт дополнительную нагрузку:
- CPU— платформа выполняет обход графа объектов после каждого CALL
- Диск— события LEAKS содержат полные стеки, логи растут значительно быстрее
- Память— незначительно, но на нагруженных серверах может быть заметно
Рекомендация: включать на ограниченное время (часы, не дни), в период воспроизведения проблемы. На высоконагруженном продуктиве — согласовать окно сбора. После получения логов — отключить, убрав блок <leaks> из logcfg.xml.
Приложение Б. Типичные паттерны утечек в 1С
|
Сценарий |
Типы объектов в LEAKS |
Характерные вызовы в стеке |
Способ исправления |
|---|---|---|---|
|
Авторизация в цикле |
KeyAndValue, Structure |
Авторизоваться, ПолучитьТокен |
Кэшировать токен |
| Загрузка справочника в цикле | KeyAndValue | СписокЭлементов, ПредопределенныеСписки | Загрузить один раз перед циклом |
|
Создание обработки в цикле |
KeyAndValue, Structure |
Создать(), Инициализировать |
Вынести перед циклом |
|
Накопление результатов |
Array, ValueTable |
Добавить, ЗагрузитьКолонку |
Порционная обработка |
|
Двоичные данные без очистки |
BinaryData |
ПолучитьИзВременногоХранилища |
УдалитьИзВременногоХранилища |
|
COM-объекты |
COMObject |
Новый COMОбъект |
Явный = Неопределено |
|
HTTP-соединения |
HTTPConnection |
Новый HTTPСоединение |
Переиспользовать соединение |
|
Подписки на события |
Structure, KeyAndValue |
ДобавитьОбработчик |
УдалитьОбработчик после использования |
Когда анализ показал, что утечки нет
Не каждое расследование заканчивается найденной утечкой. В нашем реальном примере анализ показал, что монотонного роста памяти между вызовами нет — Memory стабильна на уровне ~1.5 ГБ. Формально это не утечка. Но методика дала конкретный ответ: 83.7% неосвобождённых объектов создаются из-за повторной авторизации и загрузки справочника на каждый документ в очереди. Это избыточное потребление, которое можно оптимизировать.
Что он даёт:
- Точный диагноз вместо догадок. Даже без утечки вы знаете: что потребляет память, где в коде, и можно ли оптимизировать.
- Обоснование приоритета. «1.5 ГБ на вызов из-за авторизации в цикле по 5000 документов» — это конкретная задача с понятным эффектом, а не абстрактное «память течёт».
- Исключение подозреваемых. Если метод проверен и Memory не растёт — он вычеркнут из списка. Можно не возвращаться.
- Сужение круга поиска. Если память всё ещё растёт на графике мониторинга — возвращайтесь к Шагу 1.1 и берите следующий метод.
Методика работает в трёх случаях: когда находит утечку, когда находит избыточное потребление без утечки, и когда достоверно исключает проблему. Во всех трёх случаях результат — обоснованное решение, а не догадка.
Вступайте в нашу телеграмм-группу Инфостарт