Как возникла идея проекта
Моя статья посвящена ИИ на чистом 1С. Хочу поделиться с вами своим опытом: как это у меня получилось. Я люблю вызовы, и вызов у меня был такой: MVP своими руками за 30 минут.
У меня для вас две новости – хорошая и плохая. Начну, традиционно, с плохой.
За 30 минут у меня не получилось – это плохая новость. Хорошая новость в том, что у вас получится. Постарался сделать так, чтобы у вас получилось. Сейчас расскажу, как это сделать.
У меня профильное образование – программно-аппаратное обеспечение вычислительной техники и сетей. Во время обучения я проходил разные языки программирования, низкоуровневые и высокоуровневые. Но в дальнейшем вся моя трудовая деятельность была связана с 1С.
Когда я начал разбираться в работе с ИИ, то понимал: когда изучаешь что-то новое, у тебя есть порог входа. Какие-то вещи ты знаешь, какие-то не знаешь, а про какие-то еще не знаешь, что ты их не знаешь. И они будут всплывать уже в момент реализации.
Поэтому я не хотел повышать себе порог входа тем, что нужно изучать еще и язык программирования, например Python. Хотел остаться в рамках родной 1С и хлебнуть только вопросов по ИИ, а не вопросов по другим языкам программирования. Отсюда у меня и появился такой вызов.
Итак, какую бизнес-задачу я себе поставил? ИИ-помощник.
Например, у нас есть линия поддержки и есть какая-то база знаний, к которой обращаются сотрудники, если они не знают ответа на вопрос. Они находят информацию и формируют ответ пользователю. Хотелось бы, чтобы это делал не человек, а ИИ-помощник.
Почему ИИ-помощник? Потому что он понимает смыслы и может сформулировать шаблон ответа, а не просто выполнить контекстный поиск по словам. Контекстный поиск нам что-то найдет, но если это, допустим, новый консультант, он может не знать, как у нас это называется, и просто не сможет найти нужную информацию.
Чистый GPT или другая LLM здесь не подойдут, потому что у нас может быть какая-то специфика, регламенты и т.д., с которыми не знакомы публичные модели.
В такой ситуации лучше использовать RAG-систему, когда мы подбираем контекст по смыслу и задаем вопрос GPT уже с этим контекстом, чтобы он нашел ответ и сформулировал его.
Первая архитектурная проблема
Какие архитектурные проблемы я получил? Во-первых, 1С все-таки работает на реляционных базах данных. Они не предназначены для того, чтобы хранить смыслы. Они больше предназначены для хранения структур данных, их соответствий и сбора аналитики.
Поэтому мне нужен был другой тип базы данных – векторная база данных. Векторные базы данных как раз могут хранить семантику текста и с помощью векторов понимать, близкие тексты по смыслу или далекие.
Я не большой специалист в векторных базах данных, они бывают разные, поэтому выбирал по своим параметрам. Мне нужно было, чтобы база работала локально, чтобы я мог экспериментировать на компьютере независимо от интернета. Нужно было, чтобы ее можно было легко развернуть и свернуть, и чтобы я мог с ней общаться без других языков программирования.
Я выбрал Qdrant. С ним можно общаться через REST API, можно развернуть его локально в Docker, и все будет работать. Он бесплатный, ничего платить не надо – тоже классно.
Вторая архитектурная проблема
Хорошо, я нашел векторную базу данных, развернул ее, поставил. Теперь мне нужно было как-то из вопросов и ответов получить векторы.
Как это хранится в векторной базе данных? Данные переводятся в вектор и потом векторы записываются в базу данных. Близкие по смыслу векторы находятся «рядом». А те, что далеки по смыслу, хранятся в «разных углах» базы данных. И по расстоянию между векторами мы понимаем, это про одно и то же или про разные вещи.
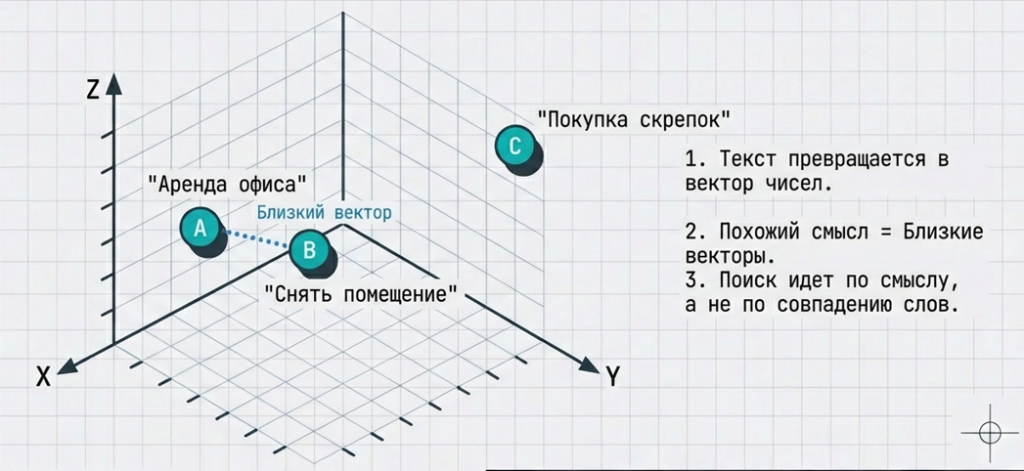
Операция перевода текста в вектор называется эмбеддинг (embedding). Просто так ее тоже не сделать: в 1С нет методов, которые позволяют превратить текст в вектор, состоящий из чисел.
Я выбрал локальную модель для эмбеддинга – nomic-embed-text. Для нее у меня были простые условия: чтобы все работало локально, потому что мне нужно было делать эксперименты, и чтобы вектор получался достаточно большим. От размера вектора зависит точность, с которой модель будет переводить текст в вектор.

Здесь размерность 768 точек. У GPT, по-моему, около 1300. То есть в два раза больше, но для того, чтобы попробовать, этого более чем достаточно.
К тому же эта модель бесплатная. Отличное решение, я считаю.
Но сама по себе она не работает: для нее нужен локальный сервер моделей. Выбор пал на Ollama. Она тоже разворачивается в Docker очень легко, в нее ставится наша модель для эмбеддинга и можно работать. Также все работает через REST, то есть через HTTP-запросы. Легко, удобно и бесплатно.
Финальная архитектура проекта
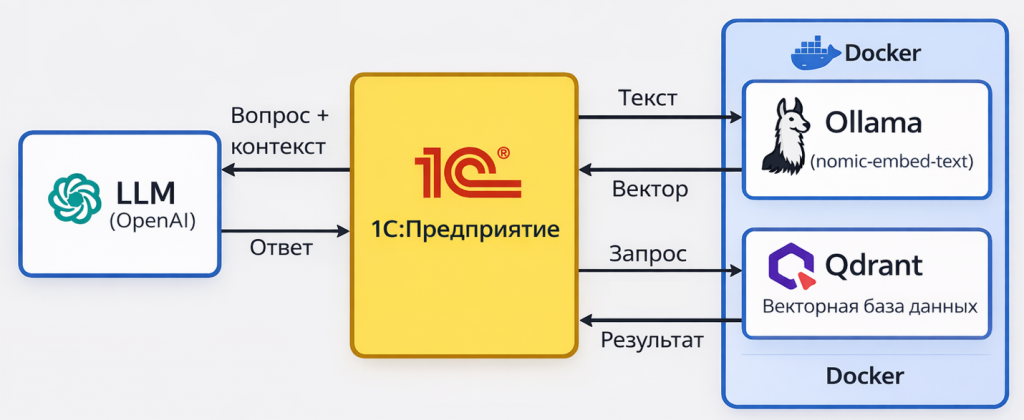
У нас есть 1С, есть Docker, на котором размещены сервер моделей и векторная база данных Qdrant. Мы обращаемся к Docker через HTTP-запросы и отправляем туда данные.
Допустим, если нам нужно перевести текст в вектор, мы обращаемся к модели, отправляем текст и получаем обратно вектор. Если нам нужно записать вектор в базу данных, мы обращаемся к Qdrant, записываем его и получаем результат.
И дальше из 1С работаем с LLM-моделью. Я работал с GPT, мне она нравится. Но можно использовать и любую другую модель. Так же через HTTP-запросы мы можем передавать ей вопрос с нашим контекстом и получать ответ.
Почему я решил, что эмбеддинг у меня будет локально, а модель для ответов на вопросы – не локальная, а сетевая? Размышлял так: эмбеддинг – все-таки более простая задача. Для нее нужна модель, но сама задача проще для вычисления, и ее можно локально делать с достаточным качеством.
А вот работа со смыслами – это более сложная штука. Здесь лучше использовать самые последние модели, которые есть. Естественно, локальная модель не будет самой крутой. Самая крутая, скорее всего, будет либо немного платной и облачной, либо бесплатной, но с условиями. Например, у GPT можно поставить галочку, разрешить делиться своими данными, и тогда она дает работать с ней бесплатно.
Сложность появилась там, где ее не ждал
Вроде все было готово к работе: архитектура есть, модели есть, все сейчас полетит, все заработает. Но сложность появилась там, где я, честно говоря, не ожидал. Она возникла на этапе перевода текста в векторы.
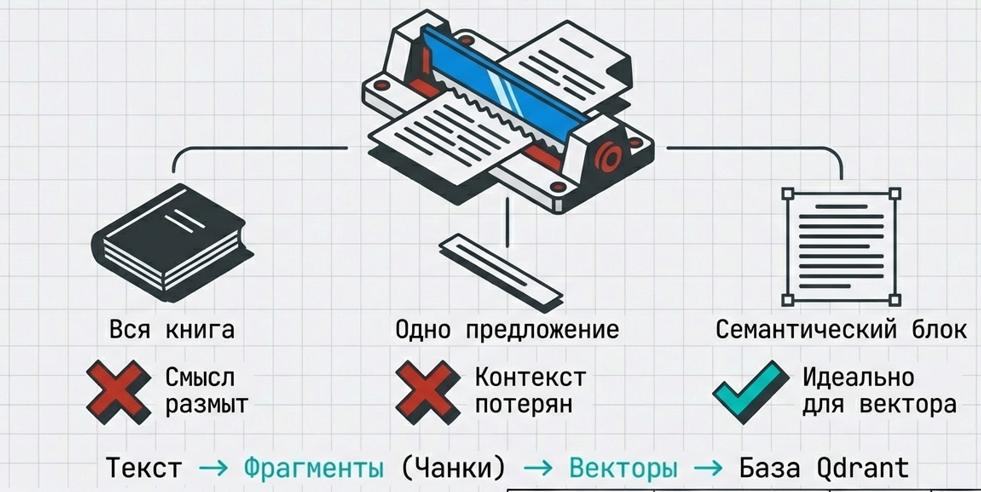
Этот процесс называется чанкинг – искусство нарезки данных. Реальное искусство, и сейчас объясню почему.

Допустим, у нас есть какой-то регламент, образно представленный на изображении. Мы можем весь этот регламент перевести в вектор, сделать его одним чанком. Плюсы – легко и быстро. Но есть и минусы: в нем может быть несколько смыслов, каждый абзац будет немного про свое, и вектор получится немного усредненным.
Пример про управление автотранспортом. Если в первом абзаце будет про бензин, во втором – про автотранспорт, а в третьем – про какие-нибудь настройки, то этот вектор будет и не про бензин, и не про автотранспорт, и не про настройки. Он будет усредненным, и найти его будет сложнее. Он может просто не попасть в нужную нам выборку.
Тогда я подумал: «Целиком не пойдет, давайте поделим его на абзацы». В тексте есть абзацы, значит, возьмем по абзацам.
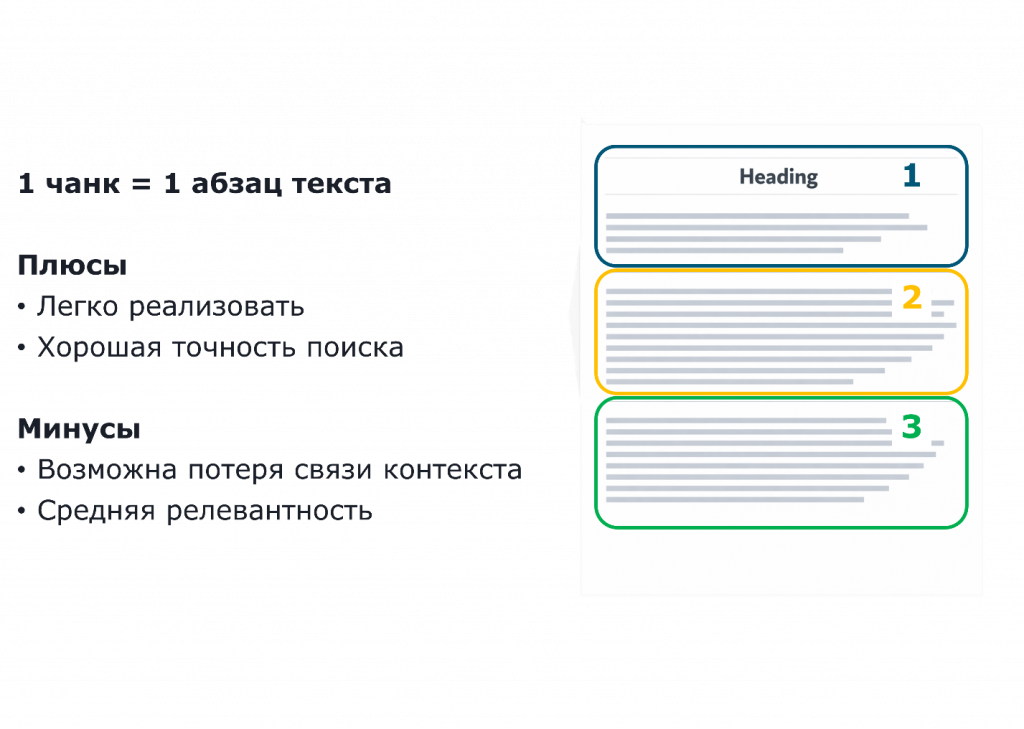
Но появляется следующая проблема. У нас даже есть выражение «вырванное из контекста». Второй абзац, вырванный из контекста, может читаться вообще про другое, окажется в «другом углу» векторной базы данных, и мы никогда его не найдем по целевому запросу.
С другой стороны, абзацы уже меньше, чем текст целиком, и они точнее будут размещены в векторной базе данных. Но нам нужно их сгруппировать, потому что все-таки они про одно.
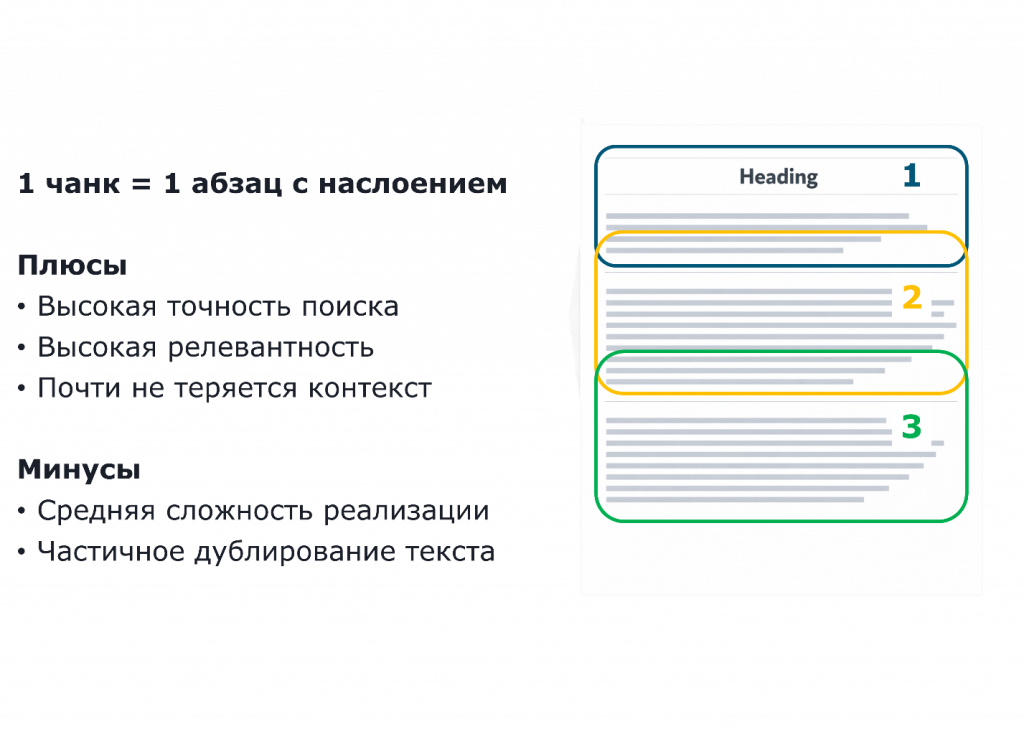
Есть метод наслоения, когда в следующий чанк мы берем немного текста из предыдущего чанка. Так они будут по смыслу чуть ближе. Мы как бы сближаем их в этой векторной базе данных, и они с большей вероятностью будут находиться.
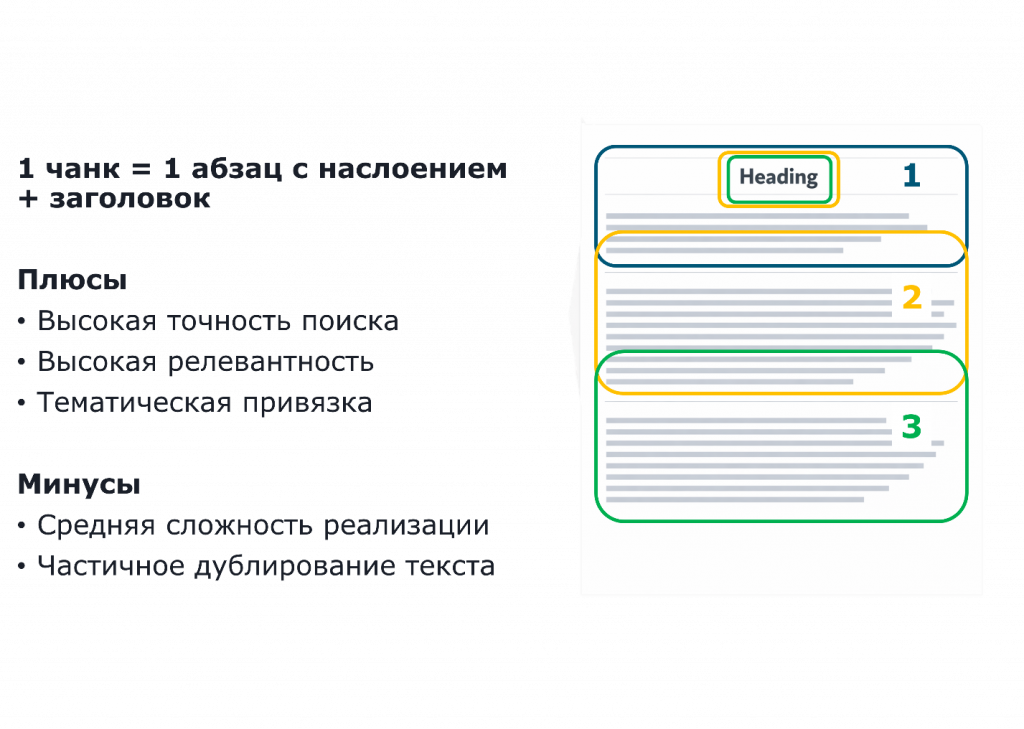
И последний шаг, который я придумал, – взять еще заголовок. То есть в каждый чанк дополнительно поместить заголовок, чтобы еще точнее определить местоположение этих векторов в базе данных.
И знаете, мне это напомнило задачу про поиск кратчайшего пути в графе. В принципе, у нас есть готовые алгоритмы, но когда мы смотрим на конкретный граф, там обычно есть какие-то нюансы, и все время нужно придумывать, как именно в этой ситуации рациональнее сделать алгоритм.
В чанкинге история такая же. Вроде все понятно: есть текст. Но если, допустим, текст будет с картинками, что делать с этими картинками? Описывать их через LLM? Убирать? Где-то хранить? Вопросы здесь на самом деле еще не закончены.
Реализация
Дальше – реализация.
Задача реализована в виде расширения. Сначала сделал обработку, когда хотел успеть за 30 минут, но потом понял, что это будет неинтересно. Поэтому пожертвовал своей целью и сделал расширение чуть лучше, чтобы с ним можно было поиграть.
По сути, у него две функции: заполнение векторной базы данных и режим работы с ответами на вопросы. В принципе, его можно запустить на любой конфигурации – на пустой или встроить в существующую. Но я работал на пустой.
Заполнение векторной базы данных

Как уже говорил, работа с векторной базой данных происходит через HTTP-запросы. Мы делаем запрос по адресу. Это PUT-запрос Collections.
Векторная база данных – это как СУБД, и в ней есть коллекции. Каждая коллекция – это как реляционная база данных внутри СУБД. Обращаемся к коллекции MVP_30 – это название моей коллекции, которую я сделал для проекта. Points означает, добавляю или изменяю точки. Параметр wait=true – это значит мы дожидаемся ответа. Когда запись будет выполнена, СУБД вернет результат. Это синхронный режим работы. Если будет false, режим будет асинхронным.
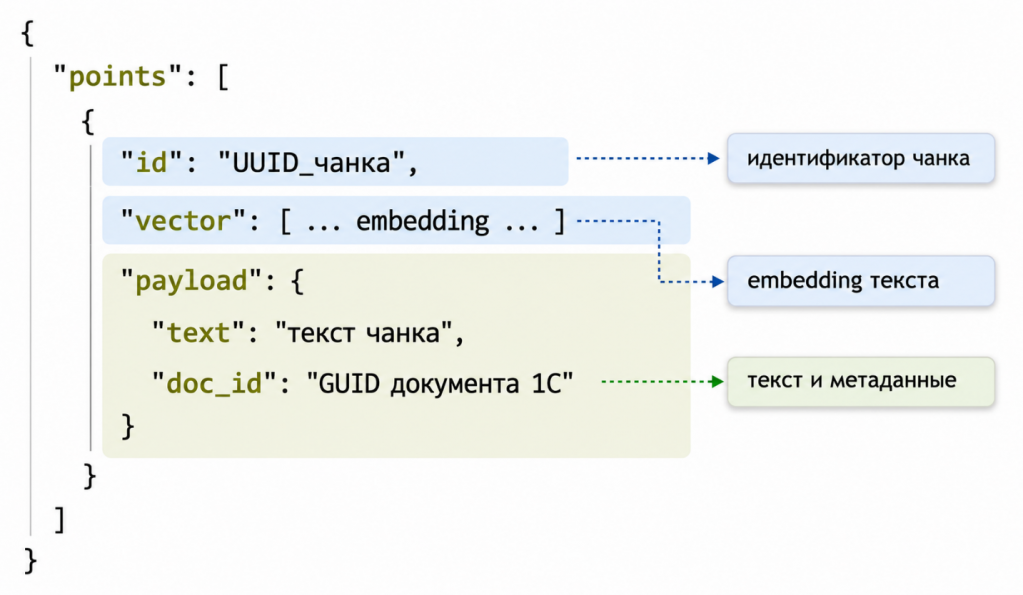
Делается такой запрос, и в теле запроса передается JSON. Структура достаточно простая.
-
ID чанка – это уникальный идентификатор чанка, по которому мы потом будем искать его, если нам нужно будет удалить, изменить или сделать с ним что-то еще.
-
Vector – это тоже обязательная часть структуры JSON, сам вектор, который мы получили после эмбеддинга.
-
Payload – тоже обязательная структура, но внутри мы можем сделать ее любой. Что хотим туда записать, то и записываем. Я записывал туда текст чанка, чтобы потом собрать контекст. То есть тот текст, который я перевел в вектор, я записывал в поле text.
Еще записываю doc_id – «ссылка» на документ 1С, чтобы было понятно, откуда возник каждый вектор.
И в Qdrant классно то, что можно делать поиск по payload, по этой структуре, если вдруг возникнет такая необходимость.
Похожим способом выполняются и остальные операции.

Поиск векторов – это POST, также collections, имя коллекции, points, search. Передается JSON соответствующей структуры. Мы передаем туда вектор, и Qdrant возвращает нам векторы, близкие к этому вектору по смыслу.
Удаление вектора – POST, collections, имя коллекции, points, delete. Передаем ID точки, которую хотим удалить. И, естественно, обратно нам тоже возвращается JSON.
Переходим к механике. Что же я сделал?

Документ «Документ знаний» делает чанкинг, записывает данные в регистр сведений, делает эмбеддинг чанков и записывает все это еще в Qdrant.
Вы спросите: «Костя, зачем регистр сведений?» Я сначала тоже не знал, зачем он, а потом понял.
Допустим, мы записываем данные в Qdrant. Например, есть регламент, который мы используем для ИИ-Помощника. Но со временем регламент изменился, и нам нужно обновить эти данные в Qdrant, перезаписать их. Например, изменилось количество дней, сумма или НДС – мало ли что может измениться.
Возникает вопрос – а как нам найти не просто что-то по смыслу, а конкретные чанки, которые изменились? Для этого нужно знать их ID, а ID нужно где-то хранить.
Поэтому я завел регистр сведений, в который дополнительно записываю то, что поместил в Qdrant. Получается, что вся картинка полностью есть в 1С: вот документы, вот исходник, вот чанки, вот их ID. Можно перезаписывать, обновлять данные в QDrant, в общем, делать все что угодно.
Документ имеет два режима работы:
-
Первый – загрузка в виде «вопрос – ответ». Когда у нас есть текст в виде вопрос-ответ. Это работа линий поддержки.
-
Второй режим – работа с абзацами. Если у нас есть регламент или статья, мы можем загрузить его, и система будет бить текст на чанки по абзацам и записывать в базу данных.
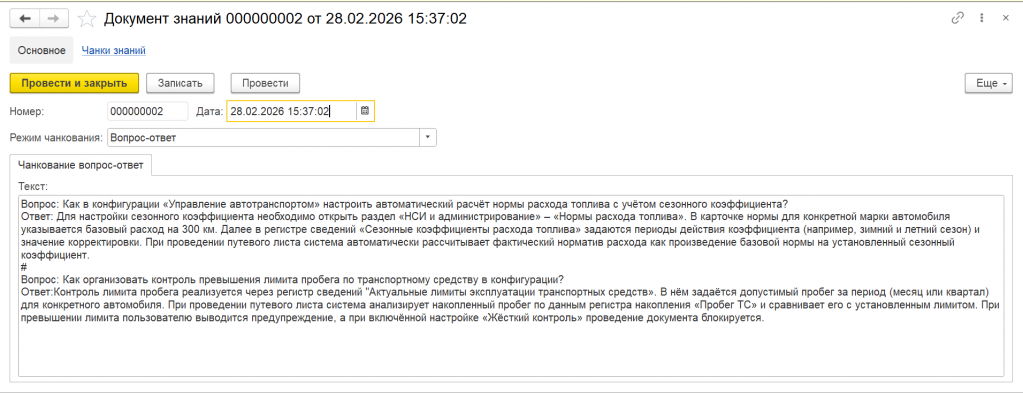
Вот пример документа. Для создания примера попросил GPT придумать вопросы пользователей и ответы на них по конфигурации Управления Автотранспортом.
Для MVP я сделал следующую структуру текста: идет слово «вопрос:», затем сам вопрос, далее слово «ответ:» и, собственно, ответ. Секции с вопросами и ответами разделяются решеткой.
И смотрите, что еще интересно. Ответ на самом деле может быть большим. Если это ответ пользователю, он не может быть просто «да, возможно» или «нет, невозможно». Скорее всего, это будет какое-то описание.
И мы снова сталкиваемся с тем, что если описание будет очень большим, у нас опять получится усредненный чанк, и его будет сложно найти. Поэтому здесь дополнительно реализовано разделение абзаца по количеству символов. Если текст большой, он тоже будет резаться.
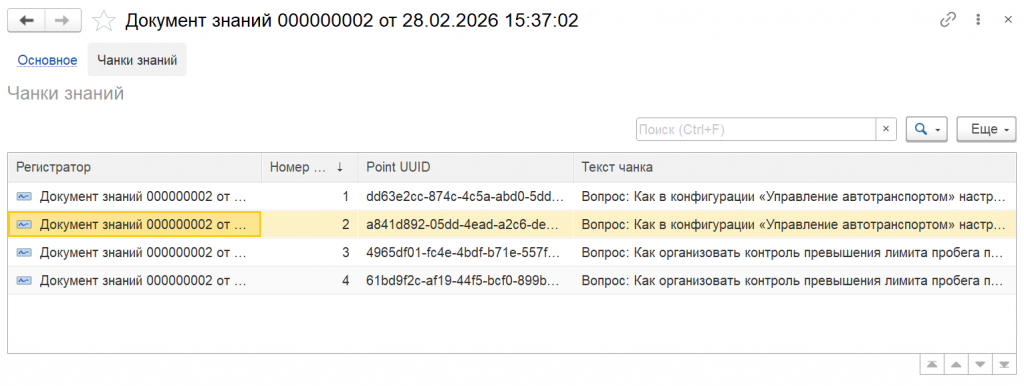
У меня было два вопроса: вопрос-ответ. Система разбила их на четыре чанка. Каждый вопрос – на два чанка, потому что ответы выходили за границу размера текста, который я определил.
В чанки помещается вся информация – чтобы у нас оставался контекст. Но еще раз обращаю внимание: это искусство. Здесь нужно пробовать и смотреть, как будет работать лучше.
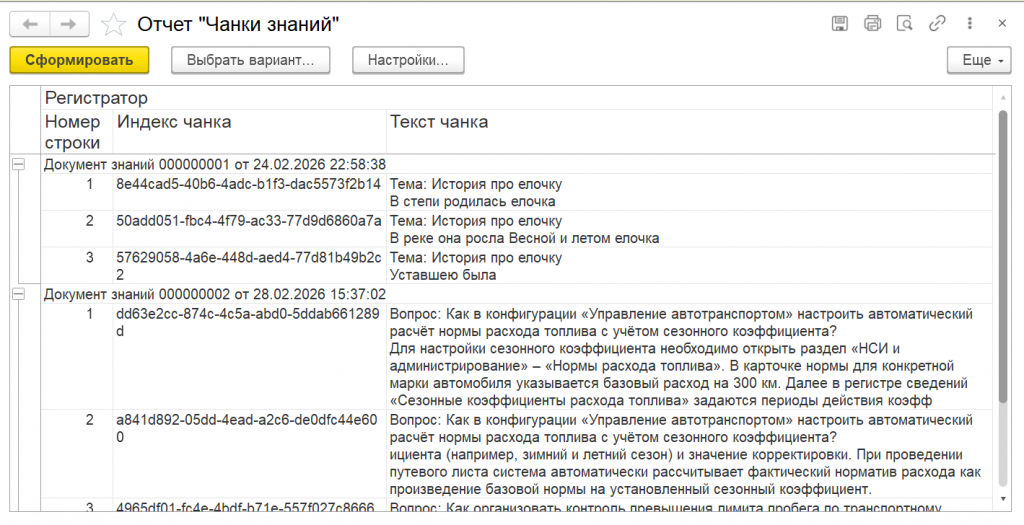
Для анализа информации в базе реализован отчет «Чанки знаний», он показывает все данные, которые мы внесли в QDrant.
«Вопрос – ответ»
Итак, как работает вся эта система?
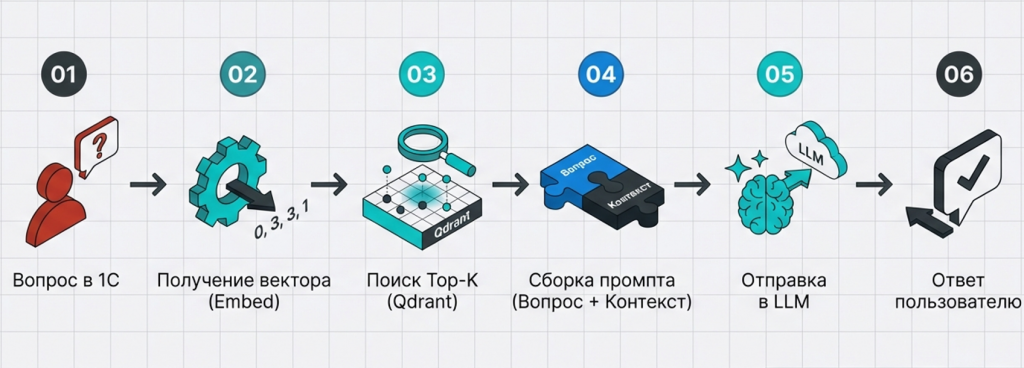
Мы получаем вопрос от пользователя, оператор вводит его в 1С. Дальше 1С берет этот вопрос, переводит его в вектор (делает эмбеддинг) и отправляет в векторную базу данных с запросом: «Найди мне похожие по смыслу векторы».
Векторная база данных ищет векторы, близкие по расстоянию к этому вектору, и возвращает список векторов.
Здесь тоже нужно быть внимательным и смотреть на объем этих векторов: сколько их вернется. Если контекст будет очень большим, система тоже может запутаться. Поэтому я беру топ-3 вектора (в обработке можно задать, сколько векторов мы берем для контекста).
Мы берем эти векторы, получаем из них текст чанков и собираем промпт для GPT: «Ответь на такой-то вопрос», вставляем вопрос, пишем «используя следующий контекст» и добавляем весь найденный контекст. Еще добавляем инструкцию: «не придумывай, если ответа нет – скажи, что нет» для уменьшения вероятности галлюцинаций.
Передаем все это в LLM. Она это переваривает и возвращает нам сформированный ответ. Или возвращает: «Я не знаю, этой информации в контексте нет».

Обработка состоит из двух закладок.
На первой закладке размещены основные элементы:
-
Вопрос – поле, в которое мы вписываем вопрос пользователя.
-
Ответ – поле, в котором мы получаем ответ.
-
Число контекстов – сколько векторов мы будем использовать для контекста.
-
Найденные фрагменты – найденные в QDrant векторы, чтобы смотреть не в отладчике, а прямо в обработке. Таблица позволяет увидеть что система нашла: на основании чего формировался ответ, что мы передали в GPT.
На закладке «Промпт» размещено текстовое поле, которое можно вписать дополнение к основному промту, вшитому в обработку.
Здесь есть промпт. Это не тот промпт, который заложен внутрь. В это поле можно дописать что-нибудь дополнительно к промпту, который я зашил в обработку. Потом идет вопрос пользователя.
Демонстрация
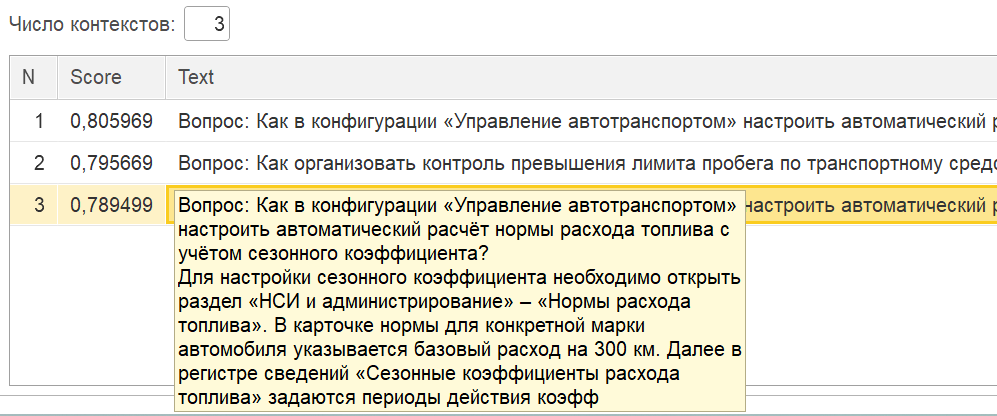
Запросы для тестового примера были сгенерированы с помощью GPT, темой для базы знаний была выбрана конфигурация Управление Автотранспортом.
В стандартах учета автотранспорта расход топлива принято считать на 100 километров. Для того, чтобы проверить, используется ли контекст нашей базы знаний, в загруженном фрагменте расход топлива считался на 300 км.
Далее при запросе пользователя «На сколько километров рассчитывается норма топлива?» система отвечает «На 300 километров».
То есть, если наши регламенты отличаются от общепринятых, система смотрит именно на наши регламенты.
Как понять, что действительно использовались загруженные данные? Смотрим на текст чанка, и в нем видим информацию, что в карточке нормы базовый расход задается на 300 километров. Теперь мы понимаем: да, действительно использовался наш контекст, и система дала правильный ответ.
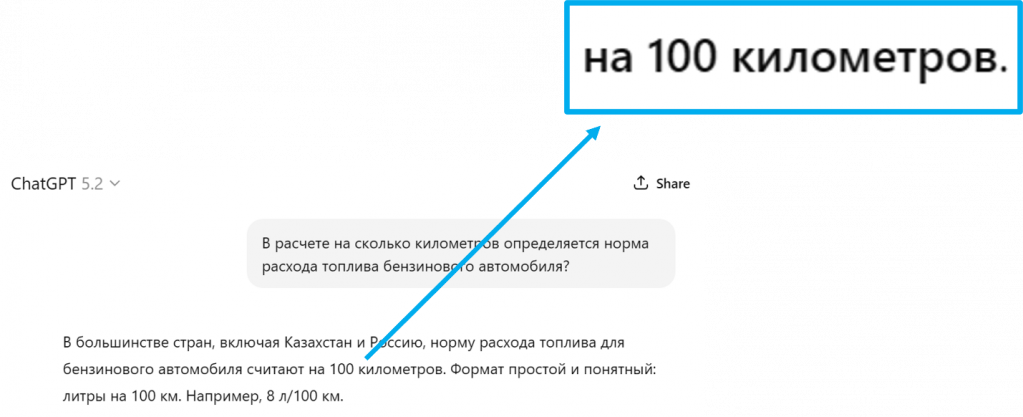
Для контроля зададим вопрос GPT, система отвечает «100 километров». Так мы понимаем, что RAG работает: при ответе используется наш контекст из нашей базы данных.
Сферы применения и готовый стенд для тестирования
Где это можно использовать?
Там, где есть поддержка, вопросы и ответы. Можно использовать инструкции, если они есть. Можно сделать какого-то помощника. Можно прикрутить к этому всему бот – не знаю, какой теперь, правда, – и попробовать все это покрутить.
Самое главное: почему у вас получится?
Я весь этот стенд приложил к статье. Также есть dt-файл моей конфигурации и Docker-стенд, в котором развернуты Qdrant, Ollama и модель nomic-embed-text.
Есть инструкция по работе в конфигурации и инструкция по тому, как все это развернуть. Если кратко: вам нужно поставить Docker, а потом запустить bat-файл. Если вы не доверяете bat-файлу, в инструкции описаны команды консоли, которые вы можете запустить самостоятельно.
После запуска команд у вас в Docker развернется стенд с данными, которые я показывал.
Выводы
Цель достигнута: на базе 1С, без знания и использования дополнительных языков программирования, реализован ИИ-помощник. Используется только 1С как основная система, HTTP-запросы и инфраструктура, без которой невозможно.
И очень важным оказалось даже не знание архитектуры и не знание языков программирования, а качество данных, которые мы используем для работы помощника. Чанкинг оказался самым сложным процессом. И, что интересно, самым сложным оказалось то, что напрямую меньше всего относится к искусственному интеллекту.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.


Вступайте в нашу телеграмм-группу Инфостарт