Примерно полтора года назад я начала встраивать ИИ в свою ежедневную работу. Что-то начало получаться, что-то «отвалилось». И в этой статье мы поговорим о том, что реально работает.
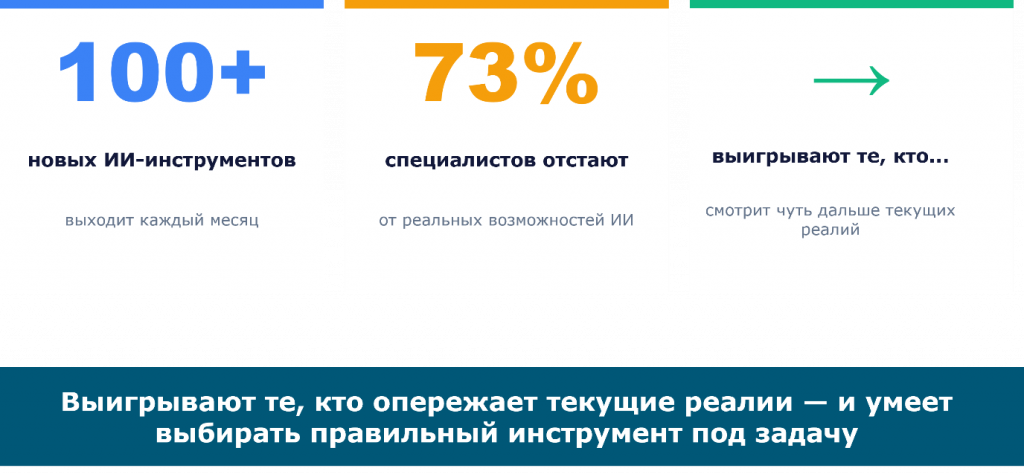
Давайте начнем с контекста: почему это сейчас важно. Каждый месяц выходит более ста новых ИИ-инструментов, и это огромный поток. При этом исследования показывают, что 70% специалистов не применяют эти инструменты или не знакомы с ними (по данным исследования «Магнита» с МФТИ и РЭШ). И не потому, что им они не нужны, а потому, что просто непонятно, с чего начать и как встроить их в свою рабочую жизнь.
Здесь важно понять одну вещь: в итоге выигрывают не те, кто гонится за всеми новыми инструментами, а те, кто правильно их применяет и умеет подстраивать под свой рабочий инструментарий.
На мой взгляд, есть еще несколько навыков, которые будут актуальны вне зависимости от того, как будут меняться ИИ-модели. Об этих навыках и пойдет речь далее.
Разберем четыре темы:
-
Как комбинировать инструменты в цепочку,
-
Как работать с источниками и избегать ошибок ИИ,
-
Как использовать мультимодальность,
-
И почему критическое мышление – самый ключевой навык в работе с ИИ.
По каждой теме будет кейс из практики. Начнем с первого тренда.
Хватит искать «идеальную нейросеть»
Первый и, пожалуй, самый важный шаг или сдвиг в мышлении – отказаться от поиска идеальной нейросети.
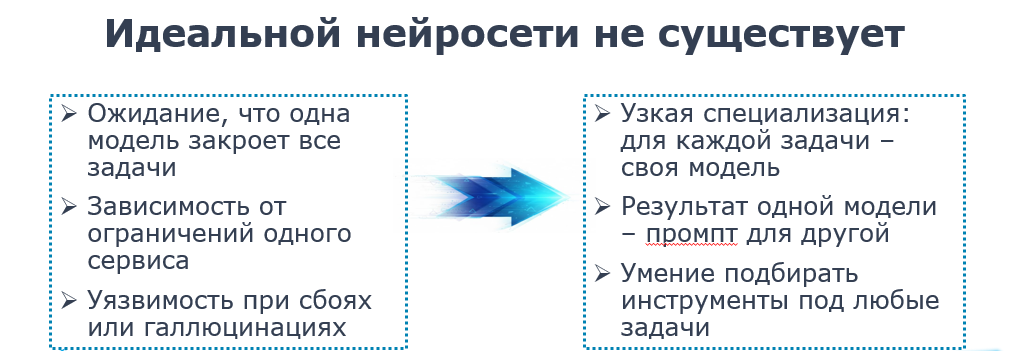
Я сама через это прошла. Сначала мне казалось, что нужно найти тот самый один инструмент, одну модель, которая закроет все мои потребности и решит все задачи. Но, как оказалось, это нереально. Этого не случится, потому что такого единого инструмента просто не существует.

Каждая модель заточена под свои задачи. Условно, ChatGPT хорошо работает в диалоге. Perplexity умеет искать информацию в интернете со ссылками на источники. Claude справляется с большим контекстом, умеет работать с документами и так далее.
Это разные инструменты, и ключевой навык здесь – не найти лучший из них, а уметь комбинировать их, разбивать свои задачи на шаги и на каждый шаг подбирать свой инструмент. То есть результат одной модели становится входом для следующей. Это как раз и называется оркестрацией инструментов.

Посмотрим, чем такой подход отличается от использования только одной модели. Когда мы используем один инструмент, мы полностью зависим от его ограничений. Если он начинает ошибаться или чего-то не умеет делать, мы уже в тупике, задача не решается.
Цепочка работает иначе. Каждая модель делает то, что умеет лучше всего, и передает результат следующей.

Наверняка у многих из вас была такая история: конец рабочего дня, встреча с заказчиком только что закончилась, запись есть, а к утру уже нужно подготовить черновик технического задания. Как можно автоматизировать этот процесс и облегчить себе работу?
Первый шаг всем знакомый – транскрибация. Надеюсь, все уже этим пользуются. Это может быть тот же Whisper или встроенный инструмент, например, в Dion, где вы проводите видеоконференции. Вы загружаете аудиозапись, переводите запись встречи в текст, и это занимает около двух-трех минут вместо того, чтобы вспоминать, что происходило.
Второй шаг – структурирование. Здесь уже ChatGPT, Claude или другая модель помогает выделить из текста бизнес-требования, цели, задачи – то есть основу того, что мы получили на встрече.
Третий шаг – генерация черновика ТЗ по вашему корпоративному шаблону. Здесь, на мой взгляд, лучше всего справляется Claude, потому что он умеет работать с шаблонами и документами Word, Excel и так далее.
Четвертый и, конечно, самый важный шаг – эксперт, специалист, то есть вы. Именно вы читаете результат, дорабатываете его, дополняете контекстом, которого модель могла не знать, и принимаете финальное решение. Именно на этом этапе происходит аналитическая работа.
Итого техническое задание готово, при этом качество не падает. Мы просто облегчаем работу специалиста и снимаем с него то, на что уходят силы и время.
Сейчас, конечно, мы можем собирать этот процесс, этот конвейер вручную и комбинировать инструменты и модели. Но мы уже начинаем использовать ИИ-агентов. Они тоже могут совмещать функции нескольких моделей.
Но уже в 2026, 2027, 2028 году, я думаю, ИИ-агенты полностью возьмут задачу оркестрации на себя и сами будут комбинировать эти инструменты. При этом человек будет комбинировать уже не сами модели, а управлять ИИ-агентами, то есть заниматься оркестрацией ИИ-агентов.
И навык понимать, как устроен этот процесс, останется с нами надолго. Это основа.
Итак, мы разобрали первый навык – умение строить цепочки и подбирать свои модели. Теперь разберем второй: как не попадаться на ошибки ИИ?
Верификация и работа с источниками
Главная проблема ИИ – он все еще ошибается. И это не было бы такой большой проблемой, если бы он хоть как-то об этом сигнализировал. Но на выходе мы просто получаем красивый, складный текст, а правильный он или нет – с первого взгляда не разберешь.
Хорошая новость в том, что этим можно управлять. Есть несколько приемов, которые помогают.

Первый – это RAG. Вы подключаете базу знаний, и модель отвечает строго по ней, то есть не придумывает. RAG расшифровывается как Retrieval-Augmented Generation – генерация с использованием извлеченных данных. Этот подход помогает получать ответы по загруженной информации.
Второй прием – мы можем применять system prompt с ограничением. Мы можем задать модели формат вывода ответа: отвечать только на основе переданного документа или загруженных данных. Это тоже меняет качество ответов.
И третий прием – использовать запросы на самопроверку. Можно попросить ИИ найти в своем же ответе противоречия с источниками или то, что он придумал сам.
Основное правило верификации такое: достоверность – это источники плюс ограничения плюс самопроверка. Формула простая, но рабочая.
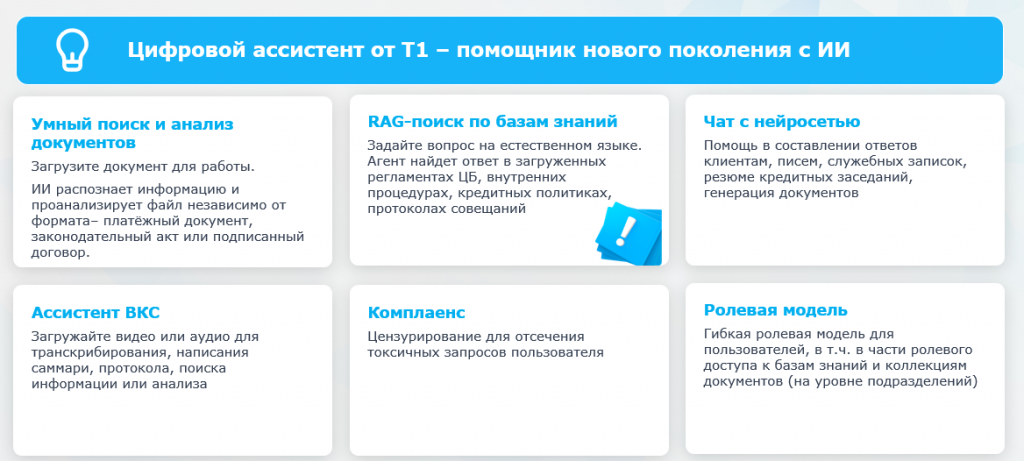

И вот как это реализовано в продукте, который мы разработали в Т1. На самом деле в Т1 мы не только используем ИИ в ежедневной работе, но и разрабатываем собственные продукты на его основе. Один из них – Иннокод. Это мощный инструмент для помощи разработчикам, в том числе на 1С.
А второй – цифровой ассистент, который помогает решать повседневные задачи с документами и знаниями внутри компании. Так как я аналитик, я больше всего использую именно ассистента. Применяю его и как обычную нейросеть для ответов в формате чат-бота и работы с текстом, и как ассистента ВКС для расшифровки аудио и видео. Это достаточно удобно.
В основе одной из функций цифрового ассистента как раз лежит RAG – работа по внутренней базе документации, регламентам, протоколам, инструкциям. При запросе пользователя ассистент ищет ответ именно по загруженной базе данных, по базе знаний.
То есть никаких галлюцинаций, никакой информации из интернета – только то, что загружено в корпоративном доступе. Это принципиально важно для бизнеса: ИИ-ассистент отвечает на основе актуальных внутренних регламентов. При этом база знаний может обновляться, а сам подход помогает обеспечивать требования к безопасности.

Вот таким образом выглядит интерфейс нашего ассистента, в котором как раз есть раздел «Базы знаний».
Если корпоративного инструмента у вас нет, этот же принцип легко реализовать в вашей любимой модели: в ChatGPT, Gemini или Claude. Вы можете создать в ней проект, загрузить вашу документацию – понятное дело, с учетом безопасности и того, насколько это конфиденциальные данные, – сохранить эти данные в виде проекта и написать system prompt: отвечать только на основе загруженных данных.
И теперь переходим к третьему тренду – к тому, как ускорить саму постановку задачи.
Мультимодальность
Большинство из нас взаимодействует с ИИ исключительно через текст. Так уж повелось: первые языковые модели были именно текстовыми. Мы привыкли набирать требования, описывать контекст, формулировать, что именно не работает.
Но задайте себе вопрос: зачем описывать то, что можно просто показать?

Скриншот передает контекст интерфейса мгновенно и намного точнее любого текстового описания. Голосовой ввод позволяет надиктовать задачу за 30 секунд вместо того, чтобы описывать целый абзац текста. Можно также загрузить фотографии с рукописными схемами, черновиками, наработками – и модель превратит их в структурированный текст.
Общее правило здесь такое: «покажи» всегда лучше, чем «опиши». Старайтесь выбирать тот канал передачи, который требует от вас меньше времени.

Давайте посмотрим на конкретную ситуацию, которую наверняка многие узнают. Типичная ситуация: пользователь обращается в техподдержку, что-то не работает в системе. Нужно разобраться и передать задачу на решение.
Традиционный текстовый подход – скопировать текст ошибки, описать, на каком экране и в каком разделе это произошло, объяснить, что пользователь ожидал получить. В итоге только на формулировку этой задачи уходит пять, десять, иногда пятнадцать минут. И это при условии, что человек умеет ясно и структурированно формулировать свои требования.
Мультимодальный подход подразумевает немного другой сценарий. Мы можем передать скриншот, записать короткое голосовое аудиосообщение о том, что случилось и что сломалось, а ИИ сразу перефразирует это и передаст как задачу.
Скорость работы с ИИ определяется не только тем, как быстро он отвечает. Во многом она определяется тем, насколько точно и быстро вы умеете ставить задачу.
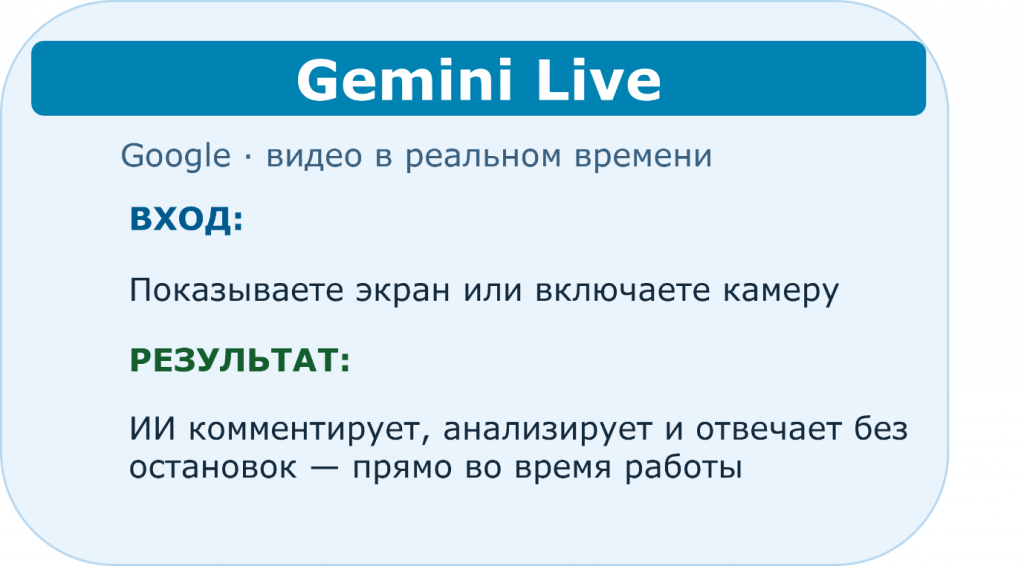
Еще один инструмент показывает, куда в целом движется это направление. Это как раз пример мультимодального взаимодействия с ИИ – Gemini Live от Google. Это режим, в котором ИИ видит ваш экран или камеру в реальном времени и комментирует происходящее прямо в процессе работы, без пауз и отдельных запросов на ответы.
Из последнего, где я сама попробовала его в быту: с помощью онлайн-режима мы разобрали, почему у меня не работает микроволновка и почему сломался робот-пылесос. Мы онлайн посмотрели, что происходит при нажатии той или иной кнопки, и он действительно дал реальные рекомендации: что могло сломаться, в чем причина поломки, какие детали можно купить. В итоге мы реально сэкономили кучу денег и времени на диагностике: просто заказали детали и сами починили приборы.
В рабочих задачах принцип такой же. Вы показываете схему или интерфейс в онлайн-режиме, получаете ответ и уже готовый результат.
На мой взгляд, сейчас это еще не стандарт взаимодействия. Инструмент может немного ошибаться, лагать, но именно в этом направлении все и движется. Мы идем к мультимодальному взаимодействию с ИИ.
Поэтому предлагаю пробовать это уже сейчас. Насколько я помню, доступна бесплатная версия, можно попробовать в мобильном приложении.
И теперь перейдем к последнему, четвертому тренду – пожалуй, самому важному.
Критическое мышление
ИИ очень убедителен. Это одновременно его сила и ловушка. Проблема в том, что убедительный ответ и правильный ответ – это не всегда одно и то же.
Иногда он просто берет и спокойно вставляет между двумя реальными шагами какой-нибудь несуществующий шаг, который придумал сам. Во-первых, это не сразу бросается в глаза. А если мы не обладаем тем самым критическим мышлением, мы это просто пропустим дальше, что не очень хорошо.
Что с этим делать? Здесь помогают конкретные привычки.
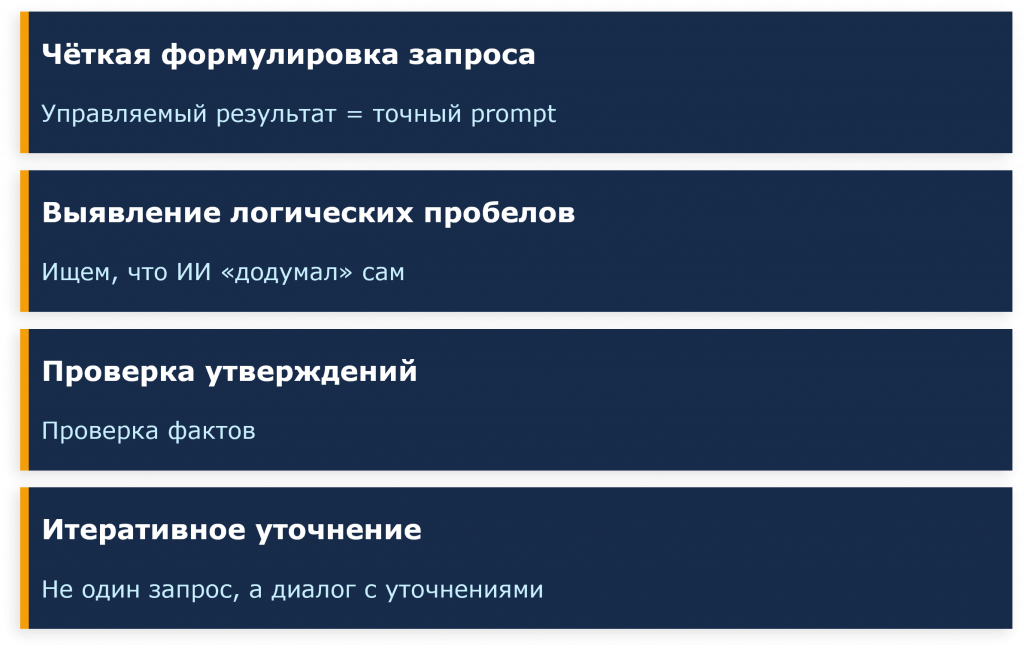
Первое – точная формулировка запроса. Чем конкретнее ваш вопрос и чем точнее вы описываете, что хотите получить, тем более управляемым будет ответ.
Второе – искать, где ИИ додумал сам, где он сделал допущения, которых вы ему не давали.
Третье – требовать источники для каждого конкретного утверждения.
И четвертое – работать в диалоге, не принимать каждый его ответ за верный. То есть мы уточняем, переспрашиваем, подтверждаем.
Еще одна полезная привычка – после ответа спрашивать: «А что ты здесь предположил сам?». Обычно он отвечает честно: вот это я придумал сам. И тогда мы просто говорим: «Эту часть ответа убери или найди для нее достоверные источники».
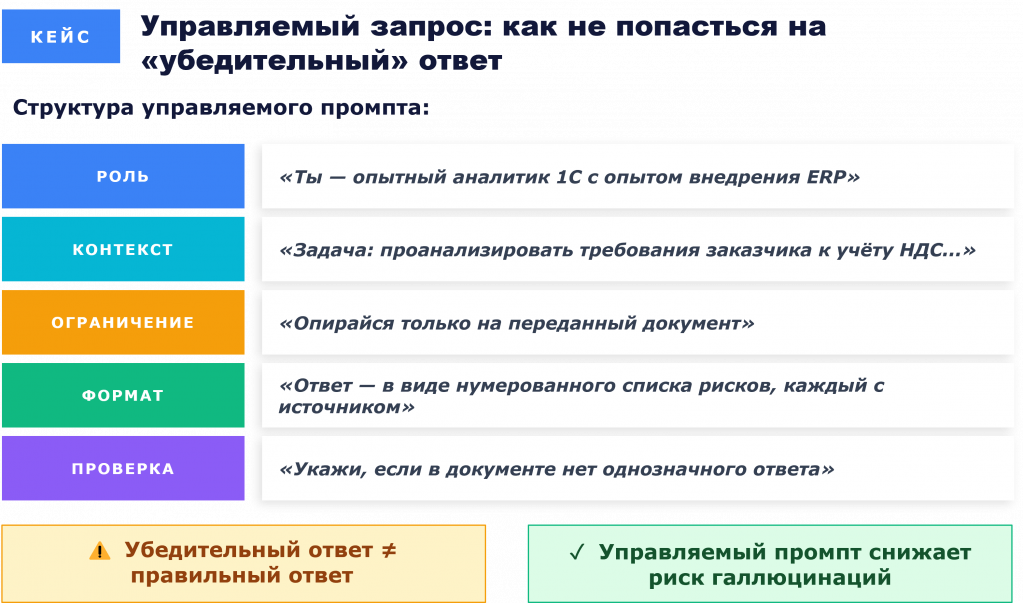
Как эти принципы выглядят в структуре конкретного запроса? Хочу показать структуру запроса, которая дает управляемый результат. Я называю это управляемым промптом. Он состоит из пяти элементов.
Первый элемент в промпте – роль. Мы пишем: «Ты – опытный аналитик 1С с опытом внедрения ERP на крупных производственных предприятиях». ИИ начинает отвечать языком специалиста, а не общими фразами.
Второй элемент – контекст. Чем конкретнее задача, тем лучше будет ответ. Мы говорим: «Проанализируй требования заказчика к учету НДС в 1С:ERP УХ при работе с агентскими договорами».
Третий элемент – ограничения, то, о чем мы говорили в пункте про верификацию. Мы говорим: «Опирайся только на переданный документ или на ранее загруженные данные, не придумывай сам».
Четвертый элемент – формат вывода ответа. Мы говорим: «Если в документе нет однозначного ответа, так и напиши». Формат ответа тоже можно задавать: в виде списка, документа Word, таблицы Excel и так далее. Модель хорошо следует заданному формату вывода.
И, конечно же, проверка. Мы говорим, что ИИ должен признавать свою неопределенность. Просим: «Укажи, что ты здесь придумал сам». Тем самым мы улучшаем ответы.
Такой промпт – это не разовая история, а привычка. После двух-трех раз вы уже начинаете формулировать запросы в такой структуре автоматически, потому что они дают более четкий результат.
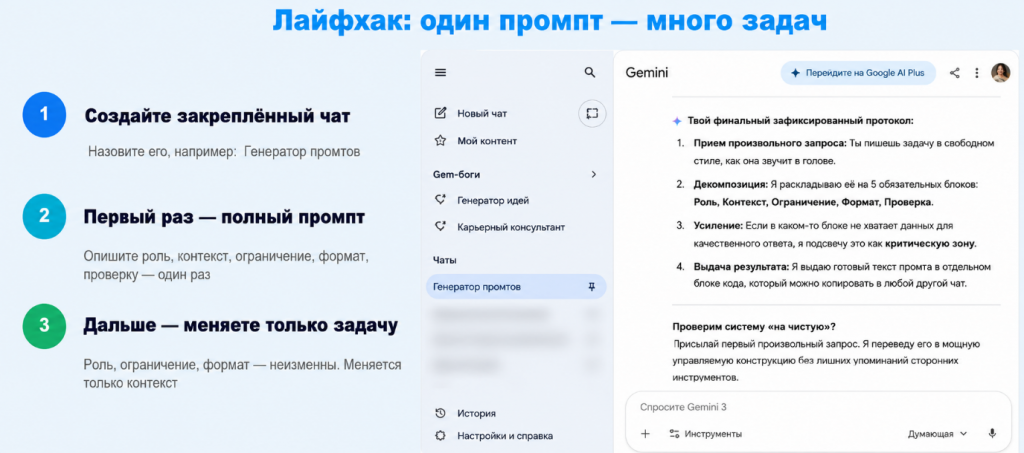
И вот личный лайфхак, который мне экономит время. Я создала закрепленный чат. Вы можете сделать это в любой модели, где вам нравится работать, в том же ChatGPT, специально для составления промптов под ваши задачи. Можно назвать его, например, «генератор промптов».
Первый раз вы загружаете в него требования к управляемому промпту: роль, ограничения, формат, проверку. Можете воспользоваться моим предыдущим изображением. А дальше в этом же чате вы просто генерируете новые запросы по шаблону, произвольно описывая задачу. Каждый раз открываете чат и меняете только контекст.
И еще один плюс: готовый промпт из этого чата вы не продолжаете отрабатывать здесь же. Вы начинаете новый чат или переходите в другую модель, где вам удобнее обработать задачу.
Заключение
Давайте подведем итог по всей статье. Мы с вами разобрали четыре темы, которые отличают продвинутого специалиста от новичка.

Первое – умение комбинировать инструменты. Не искать идеальную нейросеть, а строить цепочки, где каждый инструмент делает то, что умеет лучше всего.
Второе – контроль над источниками. Не принимать уверенный тон ИИ за признак достоверности.
Третье – использование мультимодальности. Скриншот, голос, файл, видео – выбирать то, что быстрее, чем текст. Это экономит время уже на этапе постановки задачи.
И четвертое – критическое мышление: точная формулировка запроса, поиск допущений и перепроверка результатов любой модели.
И что важно: все это не про технологии и инструменты, а про подход и привычки.
Начните с малого. Возьмите одну свою рутинную задачу на этой неделе и попробуйте применить хотя бы один из этих принципов. Не нужно сразу перестраивать всю свою работу. Можно начать с небольших шагов.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.
Вступайте в нашу телеграмм-группу Инфостарт