Тема моей статьи – цепочки промптов, которые превращают ИИ в надежного агента. Я являюсь 1С-разработчиком, поэтому постараюсь перевести все ИИ-термины на язык, понятный 1С-разработчику.
Для начала обозначу проблему, которую я автоматизирую с помощью ИИ-агента. Все мы хотели бы, чтобы хирург, который нас оперирует, работал по инструкции. Так же и пилот, который ведет наш самолет. Поэтому бизнес всегда хочет, чтобы сотрудники работали по инструкции.
Инструкция позволяет предотвратить ошибки на раннем этапе, когда их еще можно исправить. Инструкция помогает новичкам и ускоряет профессионалов. Поэтому инструкция повышает эффективность бизнеса.
Проблема в том, что даже идеально написанная инструкция может оказаться бесполезной, потому что люди просто не любят читать инструкции. И с текстовой инструкцией действительно работать неудобно. Прежде чем приступить к работе по инструкции, ее нужно найти. И часто инструкция, закопанная в корпоративной базе знаний, просто перестает работать: ее либо сложно найти, либо мы не хотим тратить время на поиск.
Второй момент: когда мы уже что-то сделали, допустим, в программе 1С, найдя инструкцию, мы должны правильно определить точку входа в эту инструкцию, то есть понять, на каком шаге мы сейчас находимся. И при этом, даже работая по инструкции, мы все равно можем допускать ошибки, поэтому нам тут не помешает второй пилот.
Раз уж люди не хотят это делать, я предлагаю заставить ИИ-агента работать. То есть мы не будем создавать на ИИ-агенте функционал, который уже делают сотрудники. Мы автоматизируем тот функционал, который сотрудники делать не хотят. Инструкцию за нас будет читать ИИ-агент. Он найдет инструкцию, определит, какие шаги мы уже выполнили в программе 1С, и подскажет нам следующий шаг. А если мы допустили ошибку, он подскажет, как ее исправить.
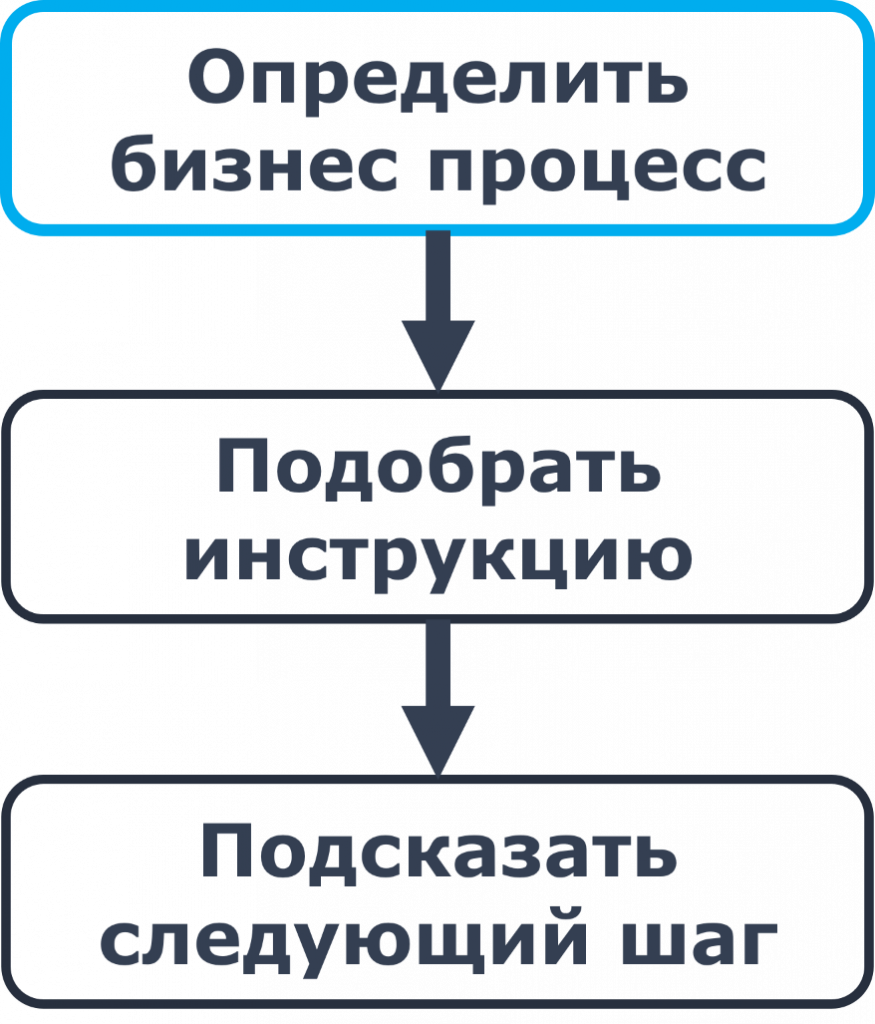
Поэтому наш агент должен уметь прочитать действия пользователя в 1С, понять по этим действиям, какую инструкцию нужно найти, и подсказать, какой следующий шаг нужно выполнить. А если пользователь допустил ошибку, то, проанализировав действия пользователя, агент должен вывести подсказку, как исправить эту ошибку.
Поговорим о терминологии
Теперь поговорим о терминологии, чтобы вам было понятно, что такое ИИ-агент и из чего он состоит. И поговорим именно на языке 1С-разработчиков.
В принципе, ИИ-агент отличается от чат-бота тем, что он использует инструменты. И если мы посмотрим схему ИИ-агента, то вам это напомнит схему бизнес-процессов в 1С. Только в 1С алгоритмы мы пишем кодом, а в ИИ-агенте алгоритмы мы пишем промптами.
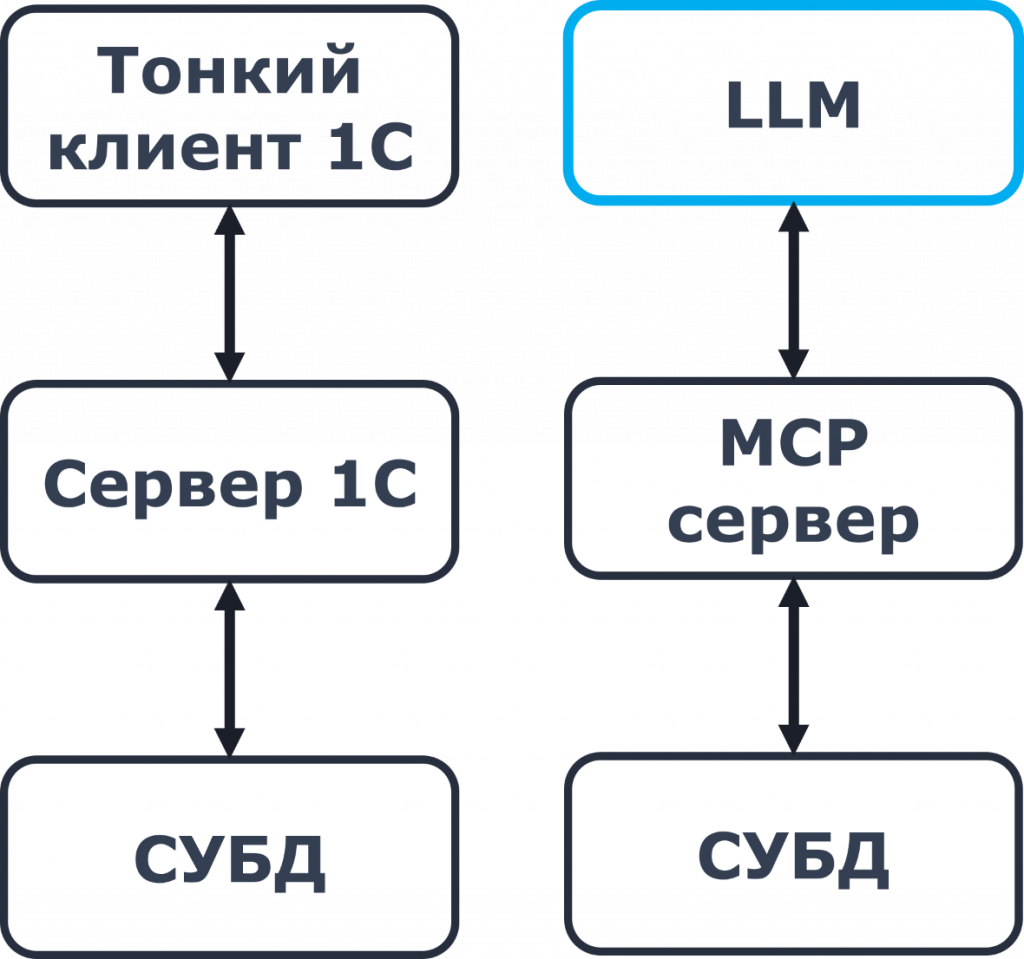
Ключевой элемент в ИИ-агенте – это LLM. По сути, LLM – это компилятор промптов. А если сравнивать с 1С, то это компилятор, который работает как тонкий клиент. Потому что тонкий клиент не имеет доступа к базе данных. Так же и LLM не имеет доступа к базе данных, не имеет доступа к вашему компьютеру, не имеет доступа ни к чему. Она умеет только генерировать текст.
И важное отличие LLM от 1С в том, что в 1С мы пишем четкий код, а в LLM мы пишем инструкцию. Например, мы хотим получить остаток по складу. Мы буквально уговариваем LLM получить этот остаток по складу. LLM уже сама принимает решение, какой инструмент из доступных ей нужно использовать. И нет стопроцентной гарантии, что она использует именно нужный инструмент, если у нас неправильный промпт.
Что такое MCP-инструмент? Это функция, которая выполняется на сервере. Буквально это экспортная функция на сервере. То есть MCP-сервер – это серверный модуль, который состоит из нескольких функций. Каждая функция, так же как и в 1С, имеет свое имя, входные параметры, описание и результат, то есть возвращаемое значение.
На изображении вы видите описание одного MCP-инструмента из программы Cursor. И тут не столько важен текст описания, сколько важен объем этого описания. Каждая функция имеет свое текстовое описание: именно по этому описанию LLM понимает, какую функцию, то есть какой MCP-инструмент, нужно использовать для поставленной задачи.
И вот этот объем текста, который указан в описании, – это только один инструмент. На MCP-сервере может быть 20 инструментов. То есть будет 20 таких описаний. Поэтому важно ограничивать количество инструментов, которые мы даем в LLM, потому что описание каждого инструмента добавляется в контекст.
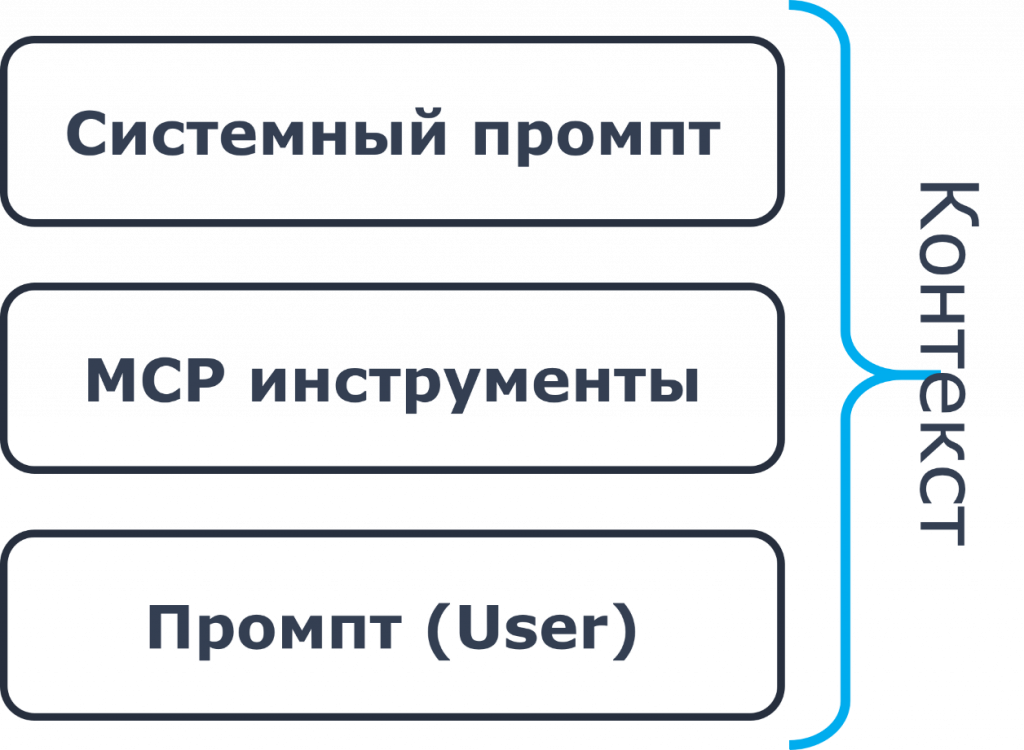
Вы можете посмотреть на схеме, из чего строится контекст. Это системный промпт, потом добавляется описание всех MCP-инструментов, и только потом добавляется наш промпт – то, что мы хотим выполнить. И если вы подключите большое количество MCP-инструментов, может получиться так, что под ваш промпт просто не останется места в контексте, если контекст ограничен.
Следующий момент: когда мы добавляем много MCP-инструментов, модель может среди них запутаться. Могут оказаться инструменты, которые выполняют похожие функции, но с определенной спецификой. Представьте, что вы хотите забить гвоздь, открываете ящик с инструментами, а там 10 молотков и микроскоп. Легко ли вам будет определиться, какой инструмент выбрать?

Промпт – это аналог функции в 1С. Причем функции на клиенте. Если в 1С вы пишете: «Если условие выполнено, тогда получить остатки по складу», то в промпте мы не указываем, какую функцию нужно вызвать. В промпте мы пишем: «Проверь, выполнено ли условие. Если условие выполнено, получи остатки по складу». То есть мы опять же уговариваем LLM выполнить функцию.
При этом нам даже не обязательно говорить, какую именно. LLM сама найдет на сервере подходящую функцию, определит, какие входные параметры нужно передать, вызовет эту функцию и вернет нам остатки по складу. Опять же, если эта функция есть.
Если этой функции нет, то хорошая LLM выведет ответ: «У меня нет такой возможности». А плохая LLM выведет какие-то остатки по какому-то складу. У меня были такие ситуации: она может сказать, что остаток – 20 штук, хотя она даже не проверяла.
Поэтому поговорим про особенности работы с промптами, чтобы не попадать в такие ситуации, когда мы получаем непредсказуемый результат.
Особенности работы с промптами
Во время отладки любой промпт всегда обрастает инструкциями. Изначально мы пишем промпт под известные нам условия, под предполагаемое поведение. Затем запускаем отладку, ловим ошибки или непредусмотренное поведение и добавляем уточняющие инструкции.

Причем даже на простое действие, такое как «получи остаток по складу», можно добавить значительное количество уточняющих инструкций. Например: если склад не существует – верни ошибку, если товара нет – верни пустой массив. И так далее. Таких инструкций может быть очень много.
А если наш промпт выполняет сразу несколько действий, то при отладке мы ловим ошибки на каждое действие, добавляем инструкции на каждое действие и в итоге получаем минусы большого суперпромпта.
Во-первых, это когнитивная перегрузка: чем больше правил, тем ниже вероятность соблюдения каждого из них. Во-вторых, мы получаем конфликт инструкций.

Вот пример уточняющих инструкций, которые я указал. Две из них могут конфликтовать. Когда мы пишем: «Если количество товаров равно нулю, выведи их количество равным нулю», а второй инструкцией добавляем: «Игнорируй удаленные товары», LLM может подумать, что если количество товаров равно нулю, значит, это удаленный товар. И она уже не поймет, что ей делать: игнорировать эти товары или выводить их. Здесь и возникает непредсказуемое поведение.
Поэтому появляется сложность отладки: изменение одной части промпта может непредсказуемо сломать другую часть промпта.
Какие промпты мы используем в жизни
Теперь я хочу показать, что вы сами прекрасно знаете, как правильно разрабатывать промпты, и используете это в жизни.
Представьте ситуацию. Программист работает удаленно, вышел в магазин, и тут ему звонит коллега: «Ты не закрыл конфигуратор, мне срочно нужен доступ, мне нужно что-то подправить». И вот наш программист звонит своей жене и должен объяснить ей, что она должна взять его ноутбук и закрыть конфигуратор.
В данной ситуации один большой промпт – это если он позвонит жене, все на одном дыхании скажет, что нужно сделать, и будет ждать, пока она сделает. Но мы так не делаем, потому что прекрасно понимаем: если мы хотим, чтобы наша задача была выполнена, это не сработает. Как минимум жена ему скажет: «Наверное, ты сам вернешься и все сделаешь, потому что это сложно».

Поэтому обычно мы разбиваем задачу на шаги. Мы говорим: «Найди ноутбук» – и ждем, пока она его найдет, потому что она может его не найти. Дальше говорим: «Авторизуйся в системе, введи пароль ЛУВР». Опять же ждем, что она авторизовалась, ждем подтверждения, что действие выполнено. Дальше говорим: «Найди окно конфигуратора. Сохрани изменения. Закрой окно конфигуратора. Оповести о выполнении».
То есть мы делим задачу на шаги, ждем, пока каждый шаг выполнится, и не переходим к следующему шагу, пока не выполнен предыдущий.
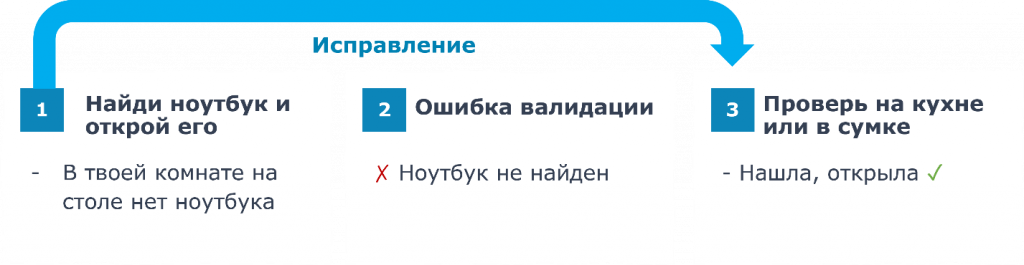
Если у нас возникла ошибка, например мы говорим: «Найди ноутбук», а она отвечает, что в комнате нет ноутбука на столе, мы понимаем, что ноутбук не найден. То есть у нас произошла ошибка валидации. И только в этот момент мы подключаем еще один промпт, который выполнит исправление либо выведет подсказку. Например: «Проверь на кухне».
Если бы мы использовали один большой промпт, мы бы все эти исправления добавили в него изначально. Мы бы написали: «Найди ноутбук. Если его нет в комнате, значит, он на кухне». То есть мы бы забили лишний контекст этими исправлениями. Причем в идеальном случае, когда все выполнялось бы сразу, а чаще всего у нас все будет выполняться именно так, эти исправления всегда жгли бы токены бесполезно. Поэтому мы делим промпт на цепочку промптов.
Делим промпт на цепочку промптов
Когда мы делим задачу, каждый шаг задачи может состоять из трех промптов.
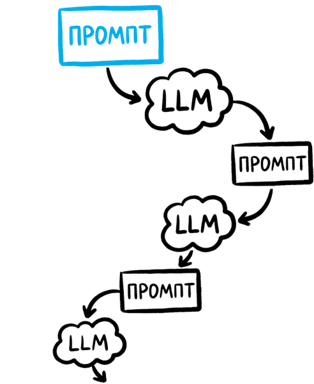
Первый – промпт текущего шага. Это действие, которое нужно выполнить сейчас, плюс результат прошлого шага. Чуть позже я скажу, почему нам придется всегда добавлять результат прошлого шага в промпт.
Второй – промпт проверки результата. Например, если вы хотите получить остаток по складу, вам нужно проверить, что это хотя бы число. То есть если мы ожидаем число, а нам вывелась какая-то текстовая ошибка, мы должны понимать, что это ошибка, и не продолжать выполнять нашу автоматизацию.
И третий – промпт исправления ошибок. Если у нас вышла какая-то ошибка, например мы закрывали окно конфигуратора, а выскочило сообщение: «Изменения не сохранены. Сохранить или нет?», мы можем запустить промпт исправления ошибок. Либо, если мы получали остаток по складу, ожидали число, а вышел какой-то текст, мы этим промптом исправления ошибок можем вообще выйти из автоматизации. То есть мы останавливаем дальнейшую работу, чтобы не сжечь бесполезно токены на всех остальных действиях.
Почему приходится передавать результат прошлого шага? Когда мы работаем по API, мы привыкли по чат-ботам, что можем с ним переписываться, и он всегда помнит, что мы у него спрашивали на прошлом шаге. При работе по API бот никогда ничего не помнит. Он даже не знает, что было раньше.
Представьте, что вы позвонили в службу поддержки мобильного оператора, решили свою проблему, оператор вам все подсказал, вы положили трубку и через секунду вспомнили, что еще кое-что забыли спросить. Если вы перезвоните, с вероятностью 99% трубку возьмет совершенно другой оператор. И если вы просто продолжите говорить, он скажет: «Я не понимаю, о чем ты».
То есть нам приходится передавать контекст: о чем был прошлый разговор. Точно так же на каждом шаге, в каждый следующий промпт, мы должны передать: «Вот только что мы сделали это, результат такой-то, теперь сделай следующее».
Как вы понимаете, раз мы добавляем в каждый промпт какой-то текст, то у нас увеличивается количество сжигаемых токенов.
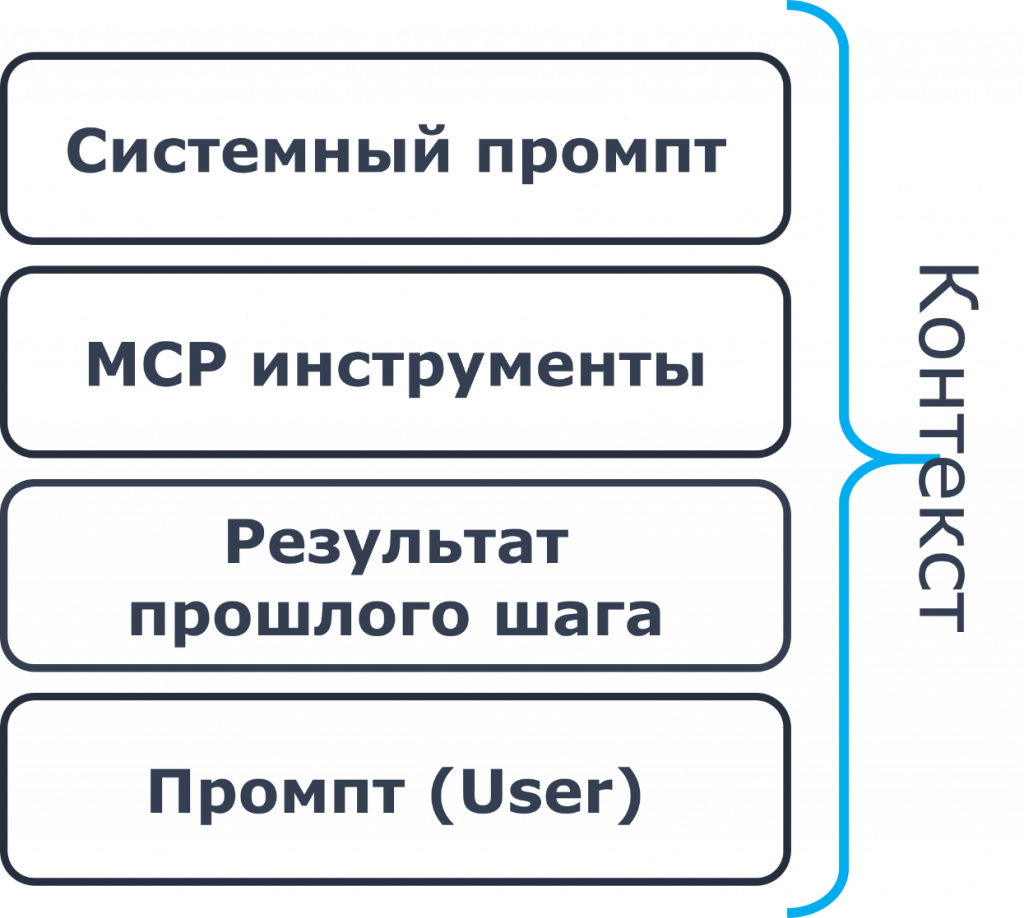
Если мы один большой промпт разделим на 10 последовательных промптов, суммарное потребление токенов увеличится в четыре-шесть раз. Потому что на каждом шаге у нас в контекст добавляется системный промпт, добавляется описание MCP-инструментов, мы добавляем результат прошлого шага и указываем наш промпт: что сделать в текущем шаге.
И тут есть некоторые моменты, которые нас спасают. Например, большинство современных API используют кэширование префикса промпта. Префикс промпта – это текст от начала до первого измененного символа. То есть если вы следующий промпт в цепочке отправляете ровно таким же, как предыдущий, он будет считан из кэша. И за считывание из кэша вы не заплатите. Точнее, заплатите со скидкой – практически 90%. Даже если мы используем локальную LLM, второй промпт читается из кэша, и это выполняется гораздо быстрее.
Если мы поменяем промпт, поменяем результат прошлого шага, может быть, поменяем MCP-инструменты, системный промпт во всей цепочке у нас все равно остается одинаковым. Он каждый раз отправляется, и на каждом шаге будет считан из кэша. Поэтому рекомендую действия и описания инструкции, которые относятся ко всей цепочке сразу, выносить в системный промпт и не бояться, что он повторяется на каждом шаге.
Но, тратя больше токенов, мы на самом деле получаем надежность ответов. Потому что на каждом шаге выполняется какая-то одна подзадача, снижается вероятность ошибки и упрощается проверка результата.
Мы сознательно идем на дополнительный расход – так же, как, когда мы позвонили жене, мы сознательно дольше и подробнее объясняем ей, что нужно выполнить. Потому что у нас задача – выполнить действие, а не сократить промпт и сделать все как-то ускоренно.
То есть лучше заплатить за большее количество токенов, но получить результат, чем заплатить за меньшее количество токенов и не получить результата.
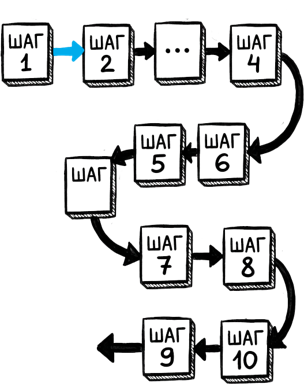
Теперь определимся, на сколько шагов делить задачу. Здесь работают те же стандарты программирования, что и в 1С.
Когда вы создаете функцию, а мы уже сказали, что промпт – это функция, функция должна выполнять одно действие. Это принцип единственной ответственности. Если функция выполняет два действия, скорее всего, вы должны создать две функции.
Так же и в промпте. Один промпт должен выполнять одно действие.
Второй момент: должна быть понятна валидация шага. Если вам хочется пропустить проверку, потому что кажется, что этот шаг незачем проверять, либо вам непонятно, как его проверить, значит, вы неправильно разбили задачу на шаги. Каждый шаг должен быть проверяемым, и каждый шаг должна быть возможность повторить, не затрагивая все остальные шаги.
Приступим к автоматизации
Теперь поговорим про автоматизацию в реальной базе 1С. Покажу, что вы наверняка будете делать неправильно, если начнете первый раз автоматизировать действия в 1С с помощью ИИ-агента.
Во-первых, как мы подключим ИИ-агента к нашей базе 1С? Есть возможность на базе 1С развернуть MCP-сервер. Но в данной задаче, а я напомню, наша задача – подсказывать пользователю следующий шаг по инструкции, у нас есть гораздо более удобный интерфейс, к которому можно подключиться. Это журнал регистрации.
В журнале регистрации мы видим все шаги пользователя. И мы видим даже объекты 1С. То есть мы можем спокойно с этим работать.
У нас в компании для записи журнала регистрации используется сервис Graylog. И также настроен MCP-сервер, который из этого Graylog позволяет с помощью LLM получать данные.
Это очень крутая функция, потому что мы можем на естественном языке делать запросы к Graylog. Например, обычным промптом можем сказать: «Посмотри, какие ошибки происходили за последние два часа». LLM сама сформирует запрос к Graylog, получит эти данные и вернет нам ответ.
Либо мы можем сказать: «Нам сейчас нужно для нашей задачи посмотреть, какие действия Иванов Иван Иванович выполнял в 1С за последние 10 минут». Тогда мы сможем подсказать ему, какой следующий шаг нужно сделать, и вообще проанализировать, не допустил ли он какие-то ошибки. Возможно, он что-то пытается сделать, получает ошибки и сам не понимает, что с этим дальше делать. Мы можем даже без его запроса подсказать ему, что нужно исправить какую-то ошибку.
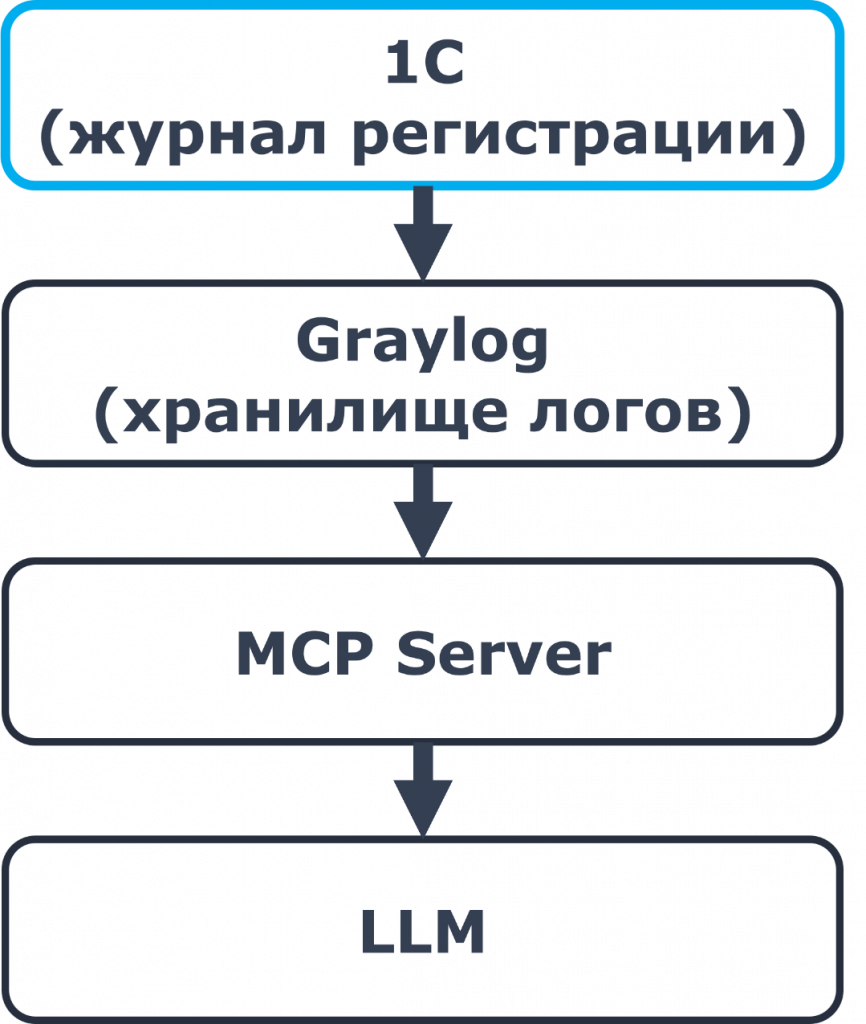
То есть схема такая: 1С, дальше идет Graylog, к Graylog подключен MCP-сервер, и мы этот MCP-сервер подключаем к LLM.
Если нам не хватает каких-то записей в журнале регистрации, мы легко можем добавить логирование с помощью подписок на события. Например, подписка «Обработка получения формы» позволяет записывать в лог, какую форму какого справочника или документа открыл пользователь, с точной ссылкой на этот объект.
Самого агента мы добавим в интерфейс 1С с помощью системы взаимодействия. Пример такого бота на системе взаимодействия вы можете увидеть в «Документообороте». Это бот Ася.
Но бот Ася подсказывает не то, что нужно сделать следующим шагом. Он просто ищет инструкцию и выводит вам ссылку на эту инструкцию, которую вы можете открыть и самостоятельно прочитать.
А мы делаем бота, который будет подсказывать следующий шаг. Либо пользователь сможет спросить у него, почему возникает ошибка. Тогда бот найдет его ошибку, проанализирует ее и подскажет, почему она возникла.
https://vkvideo.ru/video-169774330_456239103 – ссылка на видео, которое помогло мне разобраться с системой взаимодействия. Рекомендую посмотреть, если вы хотите начать с ней работать.
Алгоритм анализа действий и важность группировки на сервере
Разделим нашу задачу на шаги для анализа последних действий пользователя.

Сначала мы отбираем записи по пользователю в журнале регистрации, например за последние 10 минут. Дальше группируем их, потому что журнал регистрации содержит очень много шумной информации, бесполезной для нашей задачи. Нам нужно сгруппировать записи по объектам 1С в хронологическом порядке и определить бизнес-процесс, которым сейчас занимается пользователь.
Дальше нам нужно найти инструкцию для этого бизнес-процесса, проверить шаги по инструкции и шаги, которые пользователь уже выполнил в программе 1С, и определить следующий шаг либо вывести текст ошибки.

И вот тут возникают нюансы. Например, на шаге «сгруппировать по объектам» мы можем получить с помощью MCP-инструмента из Graylog все записи за 10 минут и попросить LLM сгруппировать эти записи. Тогда получается, что мы засовываем в LLM огромный контекст, который она должна обработать сама, и сжигаем токены.
Это равнозначно тому, что вы выполните запрос на сервере без условий, а на клиенте будете обходить и группировать эти данные либо определять по условиям, подходят они вам или нет.
Чтобы этого избежать, нужно группировать эти записи на уровне MCP-сервера. Если у вас нет возможности добавить в тот MCP-сервер, которым вы пользуетесь, такой MCP-инструмент, который вернет сразу сгруппированные записи, можно создать свой прокси MCP-сервер. Он вызовет MCP-инструмент, обработает полученные данные и вернет в LLM уже свернутые данные.
То есть MCP-инструмент можно вызывать не только из LLM. Его можно вызвать из обычного Python-модуля и обработать эти данные.
Определение бизнес-процесса
Еще один момент, на котором вы, скорее всего, допустите ошибку, – это определение бизнес-процесса.

Мы можем сделать это так: пишем промпт: вот последнее действие пользователя, задача – определить бизнес-процесс.

И ИИ-агент нам ответит: «Я проанализировал действия пользователя, там был приказ, учет времени, отчетность. В действиях пользователя четко прослеживается процедура оформления увольнения сотрудника».
Когда этот бизнес-процесс достаточно распространенный, ничего страшного. LLM вам его определит и даже скажет, что это за бизнес-процесс. Но если это какой-то специфический бизнес-процесс, который используется только у вас в компании, LLM никогда в жизни не определит, что это за бизнес-процесс. Она вас всегда обманет. То есть для автоматизации нам нельзя использовать знания LLM.
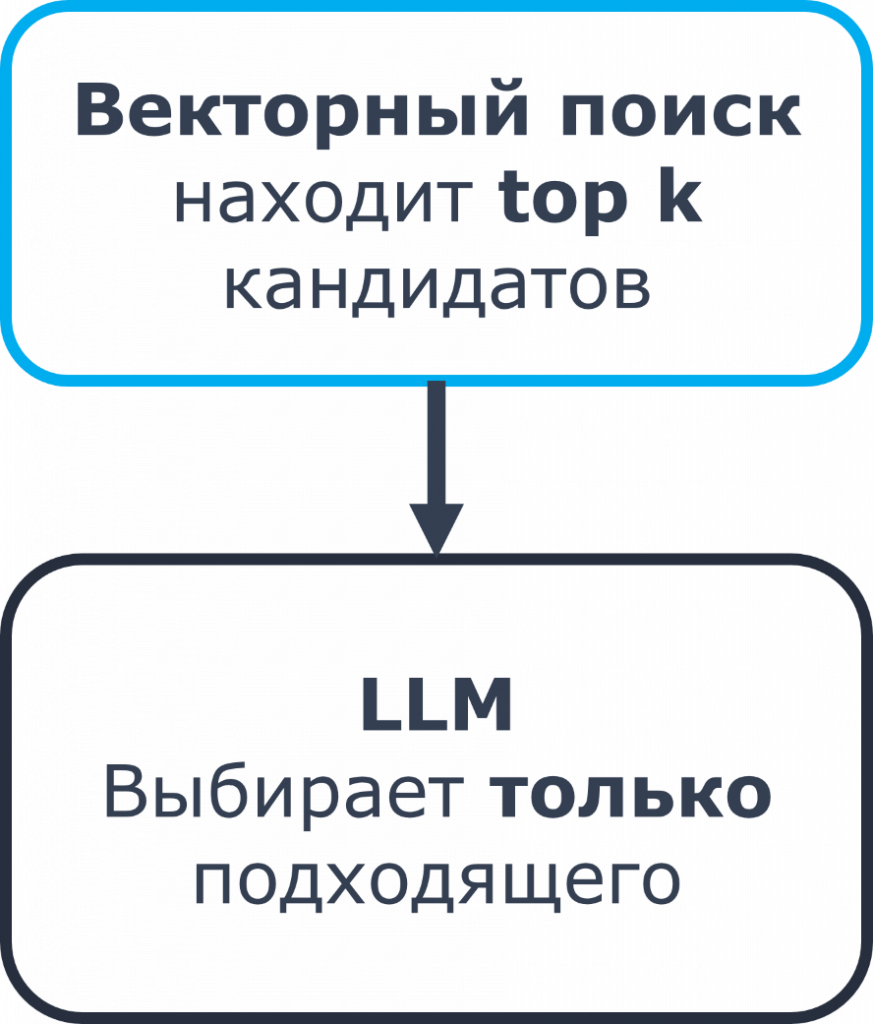
Мы всегда должны добавлять в контекст то, что хотим спросить. Если мы хотим что-то спросить, сначала должны предоставить ей всю эту информацию, а потом уже по этой информации спрашивать.
Для этого используется RAG, то есть векторный поиск.
Чтобы вы понимали, что такое векторный поиск в 1С, представьте, что мы все наши инструкции разделили по абзацам и записали в регистр сведений. Векторный поиск – это поиск в этом регистре сведений по подобию.
Допустим, мы написали: найти, выбрать все записи, где текст подобен каким-то словам. Но в отличие от поиска в 1С, где мы ищем достаточно строго, даже когда пишем «подобно» с процентами, векторный поиск умеет искать по синонимам и похожим фразам.
Почему мы выбираем топ-5? Представьте, что мы из этого регистра сведений с абзацами инструкций выбрали топ-5 инструкций, в которых есть эти слова. Можем ли мы гарантировать, что в этом списке есть подходящая инструкция? Скорее всего, она может там быть, но ее там может и не быть.
Поэтому нельзя выбрать топ-1: топ-1 не всегда будет подходящей инструкцией. Мы на всякий случай выбираем топ-5, отдаем эти пять инструкций LLM следующим шагом и просим определить, есть ли в этих пяти найденных инструкциях подходящая.
То есть мы передаем: вот действия пользователя, вот пять инструкций, которые мы нашли. Определи, подходит ли какая-нибудь из них под действия пользователя.
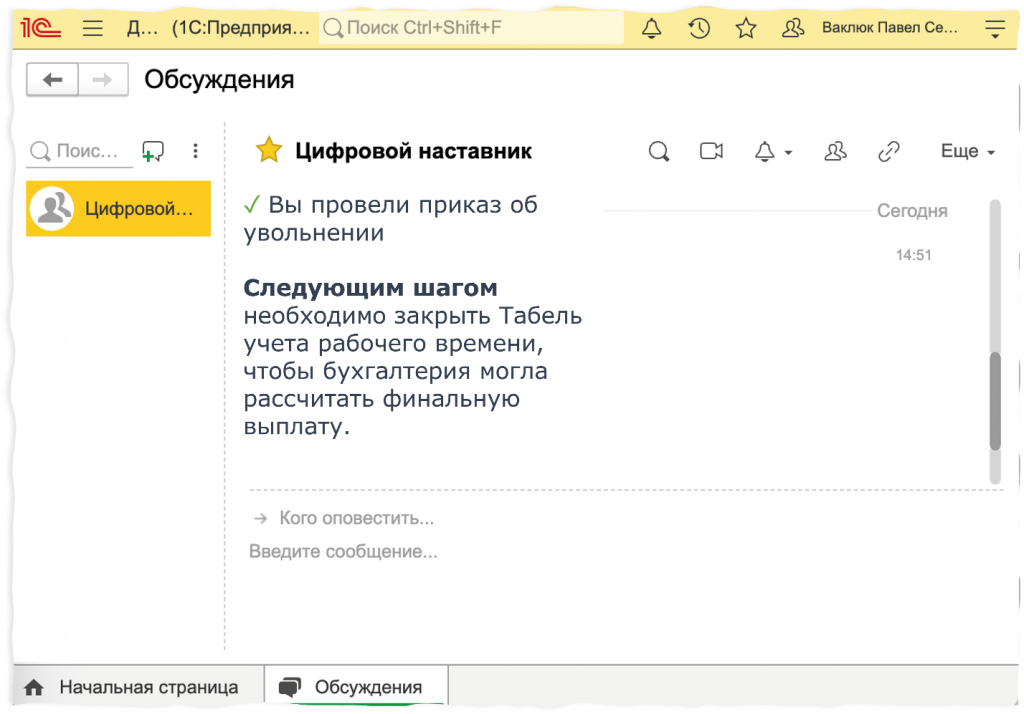
Дальше мы возвращаем ответ в 1С, в ту же систему взаимодействия, в тот же диалог, в котором пользователь сделал запрос. И возвращаем либо успех: «Вы провели приказ об увольнении. Следующим шагом необходимо закрыть табель учета рабочего времени».
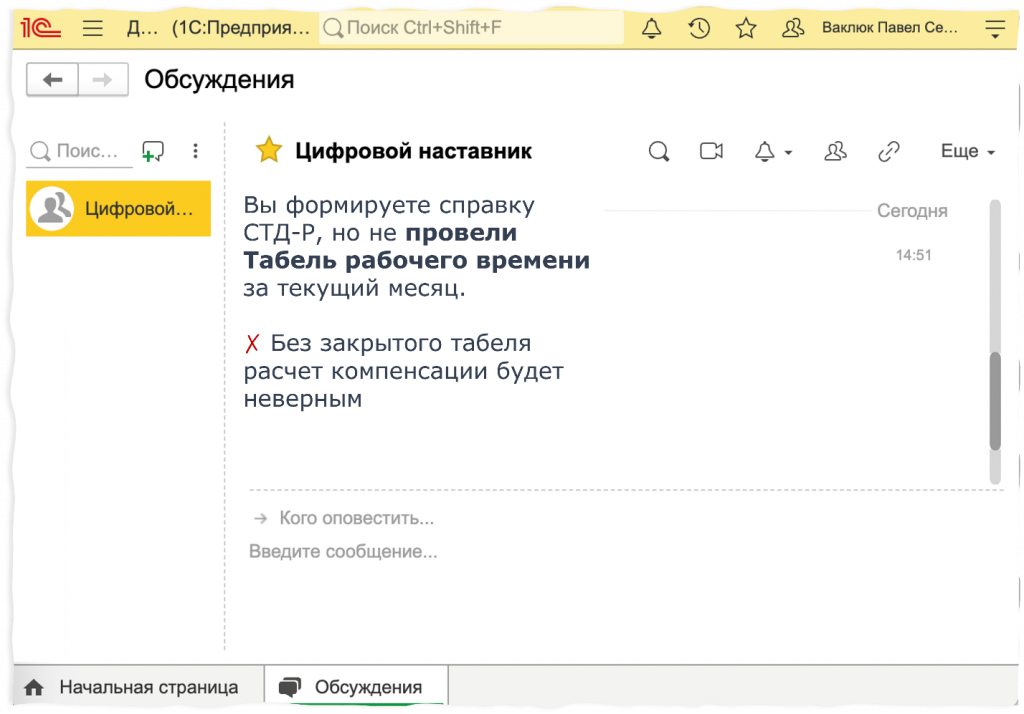
Либо возвращаем ошибку: «Табель не был проведен. Без закрытого табеля расчет компенсации будет неверным».
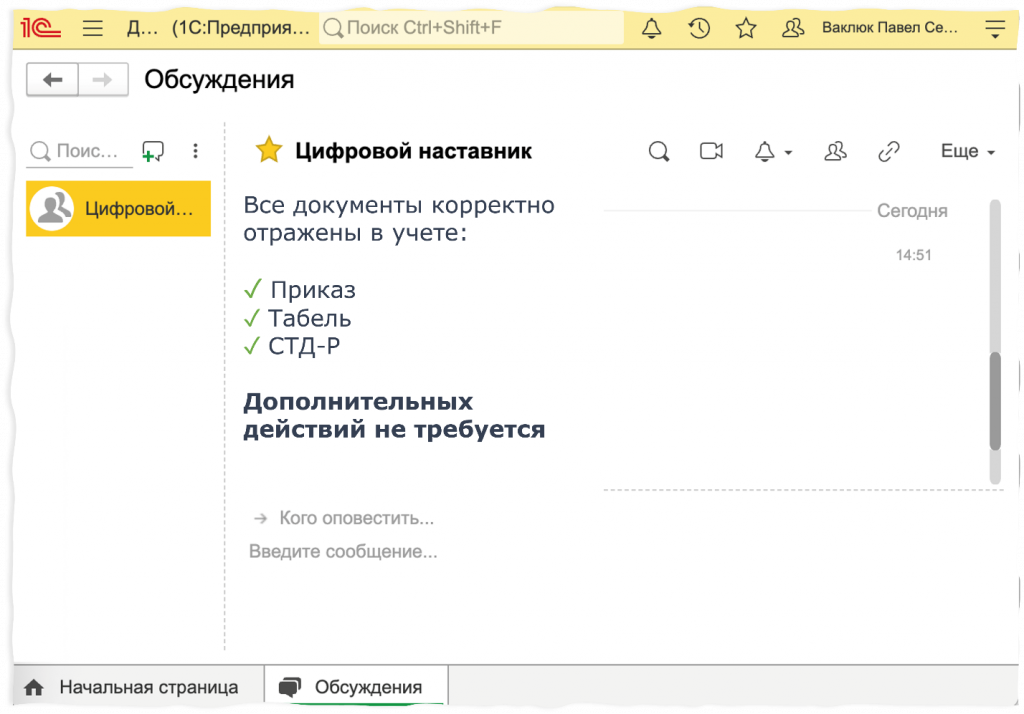
Либо наш агент скажет: «Вы все правильно сделали, дальше делать ничего не нужно».
Безопасность и конфиденциальность
Теперь поговорим про безопасность.

Когда вы работаете с бизнесом, вы не можете использовать LLM на каком-нибудь внешнем сервере, потому что мы работаем с персональными данными, которые нельзя отправлять на чужие сервера. Нам придется создавать и настраивать локальную LLM на своем железе. Либо нужно очищать персональные данные из журнала регистрации на лету. Но это не очень удобно.
Если мы разворачиваем локальную LLM, нам нужно соответствующее железо. Если железо слабое, то мы будем использовать слабые модели. И тут как раз нам на помощь приходят цепочки промптов, потому что они позволяют даже на слабой модели последовательно выполнить нашу задачу. Пусть это будет дольше, но это будет точно работать.
Сами инструкции, которые мы используем в бизнесе, тоже придется хранить в локальной векторной базе, потому что векторная база может быть в облаке. И если нам нужно делить инструкции по правам пользователя, например, чтобы отдел закупок не видел инструкции бухгалтерии, лучше хранить инструкции в разных базах: для отдела закупок – одну базу, для бухгалтерии – отдельную. Тогда, даже если поиск запутается, он не выведет неподходящую инструкцию другому отделу.
Всегда ли цепочка является решением
Теперь я скажу вам, что все это время рассказывал про цепочки промптов, но на самом деле это не всегда была цепочка.
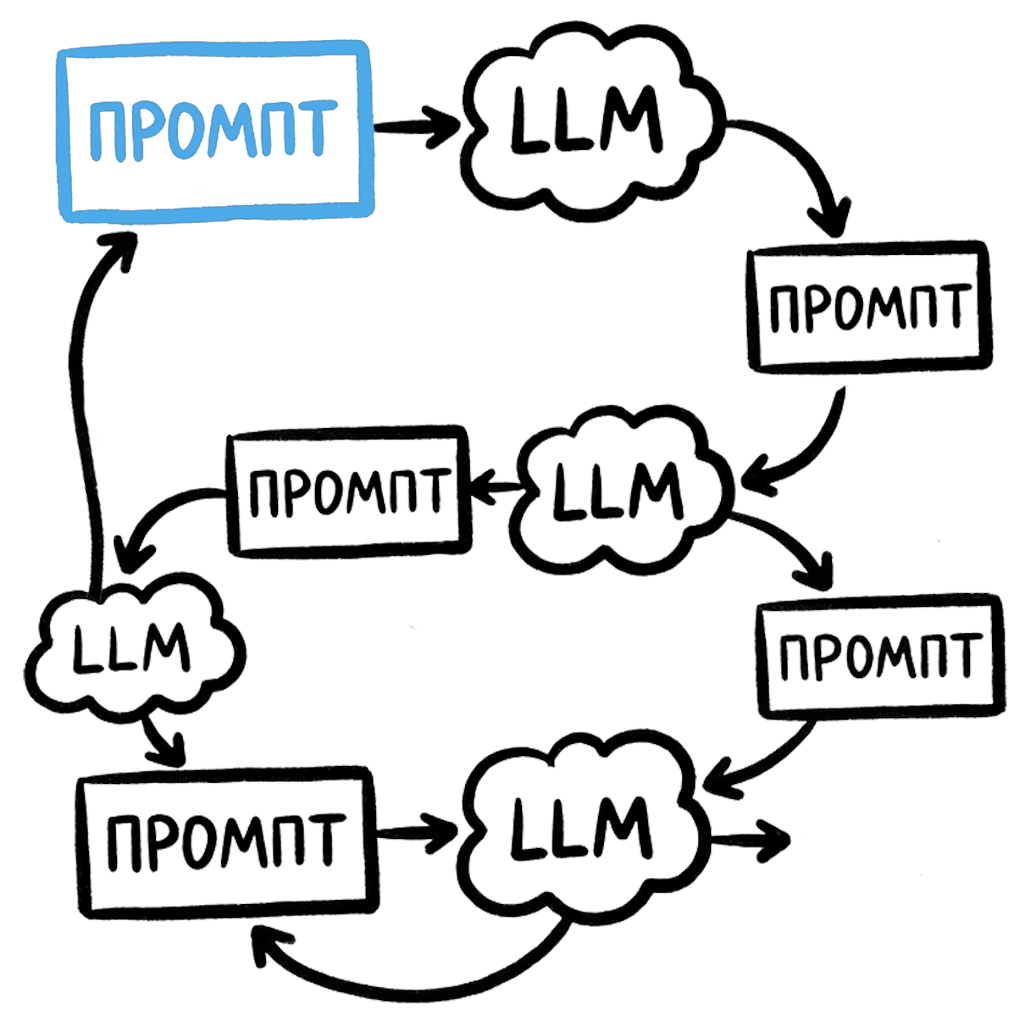
Когда я говорю, что у нас есть промпт исправления ошибок и промпт валидации, в этот момент наша цепочка на самом деле превращается в граф. Граф – это такая запутавшаяся цепочка, где каждый промпт может выполняться непоследовательно, а может вернуться назад. Здесь могут быть условные переходы, например по условию, и циклы с повтором.
Цикл с повтором – это как раз проверка, когда мы говорим: выполнить валидацию. Если валидация не выполнена – запустить промпт исправления ошибок. А если ошибку исправить не удалось, мы вообще выходим из нашей цепочки. То есть у нас может быть несколько точек входа или выхода.
Если вы работаете в Python-среде, то есть разрабатываете агента на Python, для этого есть фреймворки с открытым исходным кодом – LangChain и LangGraph (docs.langchain.com).
LangChain – это как раз для разработки линейных цепочек. Он более простой для понимания, и я рекомендую начать именно с него.
А LangGraph – как раз для разработки циклических сложных задач с валидацией, исправлением ошибок и возвратом назад.
Если вы не хотите программировать, для этого есть low-code-среда разработки n8n (n8n.io), которая позволяет, как конструктор, буквально мышкой собирать ИИ-агентов, просто двигая блоки.
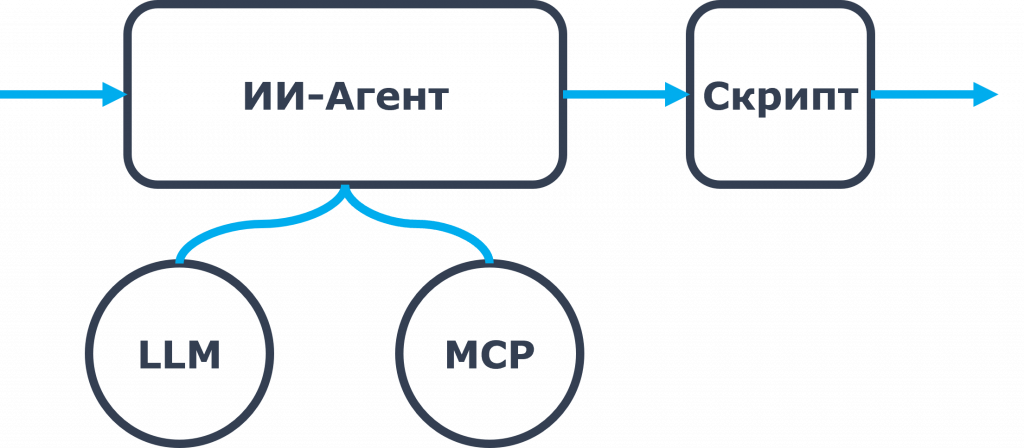
Посмотрите на изображении: у меня ИИ-агент, а дальше идет скрипт. Это ошибка, которую все допускают, когда разрабатывают на n8n.
Когда вы выносите какую-то логику в скрипт, вы на самом деле очень сильно хардкодите. Потому что если вы после этого измените промпт, ваш скрипт, скорее всего, сломается.
Все, что выносится в скрипты, лучше выносить в MCP-инструмент, подключать это как MCP-инструмент, и LLM уже сама разберется, как с этим работать.
То есть для надежного ИИ-агента в вашей схеме вообще не должно быть скриптов. Всю автоматизацию нужно выносить в MCP. А все, что нужно для работы с этой автоматизацией, все инструкции должны быть в промпте.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.


Вступайте в нашу телеграмм-группу Инфостарт