Документ долго записывается, форма не отвечает, отчет крутится. Человек видит ожидание и называет его привычным словом — “зависло”.
Для разработчика это только начало. Иногда операция действительно ждет ресурс, который держит другой процесс. Иногда запрос сам по себе тяжелый. Иногда после релиза в запись документа попала логика, которая на тестовой базе выглядела безобидно, а в рабочей базе начала мешать людям.
В моей практике такие жалобы чаще всего всплывали на массовых обработках и проведении документов. Пользователь обычно не говорит: “У нас длинная транзакция и кто-то держит ресурс”. Он говорит проще: “1С виснет”, “документ очень долго записывается”, “что-то опять тормозит”.
И вот тут начинается работа разработчика: что выполнялось, сколько длилось, кто пострадал и что изменилось перед проблемой.
Эта статья не про глубокий DBA-разбор и не про настройку всех возможных логов. Я смотрю на тему глазами 1С-разработчика. Мне важно понять две вещи: когда ситуация похожа на блокировку и какой код лучше не писать, чтобы самому не создавать ожидания.
Сначала сценарий, потом инструменты
Когда прилетает жалоба “1С зависла”, хочется сразу открыть всё подряд: журнал регистрации, активные сеансы, технологический журнал. Иногда это нужно, особенно если проблема прямо сейчас мешает работе. Но без сценария инструменты быстро превращаются в гадание.
Я начинаю с простого вопроса: что именно стало долгим?
- запись документа;
- проведение документа;
- формирование отчета;
Это разные маршруты расследования. Если долго формируется отчет, я смотрю запросы, отборы и период. Если после релиза долго записывается документ, иду в обработчики записи, подписки и расширения. Если тормозит сразу у многих, проверяю фоновые задания и массовые операции.
Живой пример: после релиза документ стал “иногда долго записываться”
Один из самых неприятных вариантов — проблема после релиза. Не такая, где всё сразу упало с понятной ошибкой. А тихая: пользователи периодически начинают жаловаться, что документ очень долго записывается.
Проблема проявляется не всегда. Один документ записался быстро, другой заставил пользователя ждать. У одного сотрудника всё прошло нормально, у другого форма висит. Ошибки может не быть. Есть только жалоба и ощущение, что раньше было быстрее.
Такие ситуации сложнее выявляются именно потому, что снаружи они выглядят как обычное “1С виснет”. Нет красивого текста исключения, по которому сразу понятно, куда идти. Есть время, сценарий и недавний релиз.
В подобных случаях я сначала не бегу обвинять сервер. Если проблема появилась после релиза, первая рабочая гипотеза — изменилось поведение кода. Подозрительными часто оказываются не большие доработки, а маленькие правки рядом с записью: добавили проверку, обновили связанный объект, подтянули данные из соседнего документа.
На тестовой базе такая мелочь почти незаметна. В рабочей базе она может пройти по большому объему данных или начать писать объекты там, где раньше записи не было.
Самый неприятный вариант — когда доработка выглядит как обычная проверка при записи, а внутри начинает читать связанные документы шире, чем нужно. На ревью такой участок лучше сразу проверять на объем данных и отборы.
В первую очередь я проверяю всё, что добавили рядом с записью и проведением:
- новый запрос без жесткого отбора;
- чтение связанных документов шире, чем нужно;
- запись объектов в цикле;
- новую подписку на событие;
- логику из расширения;
- повторную запись объекта без реального изменения данных.
Для меня это важная мысль: после релиза долгую запись документа нужно проверять как след новой логики. Документ редко становится медленным сам по себе. Обычно в сценарий добавили действие, которое держит операцию дольше обычного.
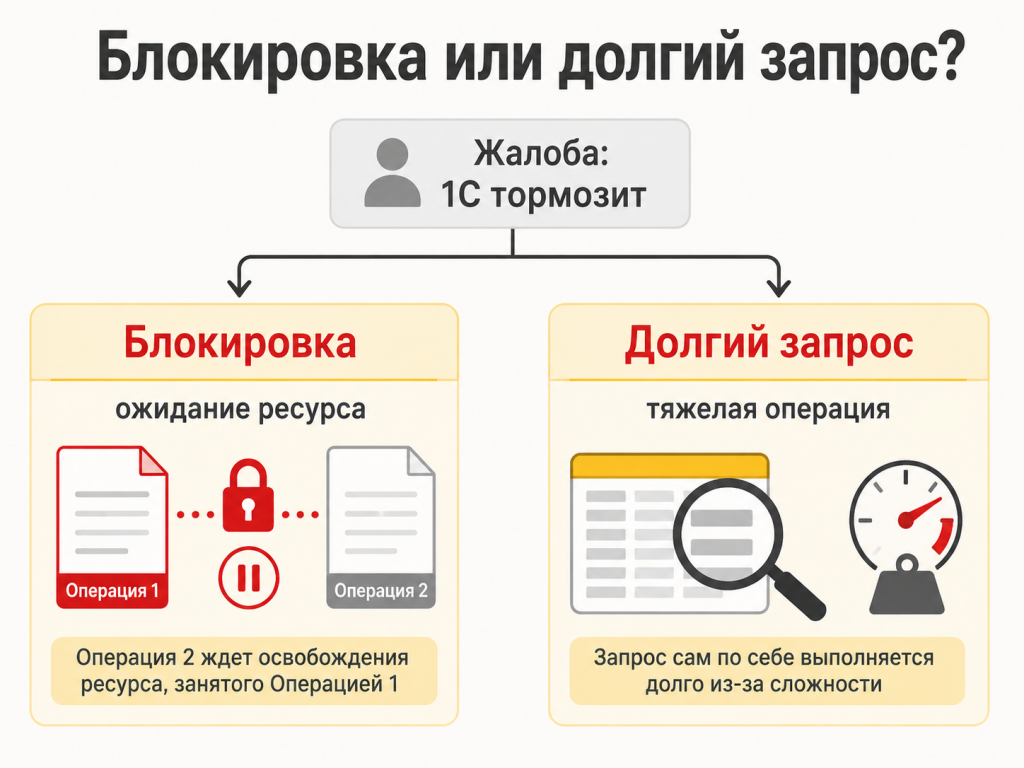
Блокировка, долгий запрос и нагрузка — разные причины с похожим лицом
Для пользователя почти все выглядит одинаково: “жду”. Для разработчика разница принципиальная.
| Причина | Как выглядит для пользователя | Что происходит внутри | Первый рабочий ход |
| Блокировка | Документ долго записывается или проводится | Один процесс держит ресурс, другой ждет | Найти сценарий, время, ожидающую операцию и источник ожидания |
| Долгий запрос | Отчет крутится, форма долго открывается | Запрос сам по себе долго получает данные | Смотреть текст запроса, отборы, период и замер производительности |
| Нагрузка сервера | Медленно почти всем и в разных местах | Ресурсов не хватает или параллельно идет тяжелая операция | Проверить активные сеансы, задания и мониторинг |
| Фоновое задание | Пользователи жалуются в одно и то же время | Задание конкурирует с пользователями за данные или ресурсы | Смотреть расписание, длительность и объем обработки |
| Внешний сервис | Операция “висит” при обмене | 1С ждет ответ другой системы | Проверить логи обмена, время ответа и таймауты |
Блокировка — это не любое долгое выполнение. Блокировка появляется там, где одна операция ждет ресурс, занятый другой операцией. Долгий запрос может никого не ждать: он просто тяжелый. Нагрузка сервера может замедлить всех без одной явной блокировки.
От причины зависит действие. Долгий запрос не лечится завершением сеанса “подозрительного” пользователя. Лишняя запись объекта в цикле не лечится только ресурсами сервера, если код продолжает делать лишнюю работу на каждом документе.
Что уточнить до расследования
Хорошая заявка экономит половину расследования. Плохая заявка выглядит так:
“1С висит. Срочно посмотрите”.
С этим тоже приходится работать, но сначала нужно собрать фактуру. Не для бюрократии, а чтобы не искать “что-то где-то вчера”.
Минимально я уточняю:
- в какой базе и во сколько началось ожидание;
- что пользователь делал в этот момент;
- какой документ, отчет или обработка были в работе;
- сколько длилось ожидание;
- пострадал один пользователь или несколько;
- был ли рядом релиз, обмен или регламентное задание.
Нормальная заявка звучит примерно так:
“Сегодня около 11:40 в базе такой-то при записи документа такого-то вида форма висела около пяти минут. Повторилось два раза. Рядом был недавний релиз”.
Здесь есть время, база, сценарий, объект, длительность и связь с изменениями. С таким описанием разработчик быстрее переходит от “кажется” к проверке.
Где искать подтверждение разработчику
Я не предлагаю разработчику сразу становиться DBA и разбирать все блокировки на уровне СУБД. В большинстве рабочих ситуаций сначала нужно понять, не создал ли проблему наш сценарий или код.
Мой маршрут обычно такой:
- сначала код и замеры;
- затем сеансы и задания;
- потом журналы;
- при необходимости — более глубокий анализ вместе с администратором.
Код и замеры производительности
Если жалоба появилась после релиза или привязана к конкретному документу, я начинаю с кода. Не потому что “разработчики всегда виноваты”, а потому что это самая конкретная зацепка.
Первый подозрительный участок для меня — всё, что добавили в обработчики записи, проведение, подписки и расширения. Особенно если там есть выборка связанных документов или запись объектов.
Отдельно смотрю запросы. Если новый запрос не ограничен периодом, организацией или конкретным объектом, он быстро становится кандидатом на замер.
Замер производительности хорошо отрезвляет. Иногда кажется, что тормозит проведение, а время уходит в запрос перед проведением. Иногда подозревают запрос, а проблема в записи объектов в цикле. Иногда медленной оказывается небольшая проверка, которую добавили “на всякий случай”.
Сеансы, журнал регистрации и технологический журнал
В активных сеансах меня интересуют длительность и ожидание. Один долгий сеанс сам по себе еще не доказательство. Но если пользователь жалуется на запись документа, а в это время идет массовое проведение, гипотеза становится сильнее.
Журнал регистрации помогает восстановить картину рядом по времени. Он не всегда покажет блокировку напрямую, но покажет события, ошибки и действия пользователей. Ошибки может не быть, поэтому журнал регистрации — это источник контекста, а не финальный судья.
Технологический журнал нужен, когда требуется подтверждение по длительным операциям, ожиданиям, запросам и контексту вызова. Я не буду делать вид, что каждый день глубоко разбираю технологический журнал на уровне эксперта эксплуатации. В моей практике старт чаще идет от кода и замеров. Но разработчик должен понимать, когда без технологического журнала уже не обойтись.
Здесь я сознательно не разбираю настройку технологического журнала и конкретные события по шагам. Это отдельная большая тема. В этой статье важнее маршрут: в какой момент становится понятно, что простого просмотра кода, замера и журнала регистрации уже мало.
Регламентные задания, обмены и мониторинг
Если жалуются несколько пользователей или проблема повторяется в определенное время, я проверяю задания и обмены. Часто причина находится в фоне: обработка пошла по большому объему, обмен начал массово писать данные, регламентное задание стартовало в рабочее время.
Мониторинг сервера нужен, когда тормозит “везде и всем”. Тут разработчик не обязан делать глубокий инфраструктурный разбор один. Но он должен понять, не запустил ли нагрузку его код или регламентная операция.
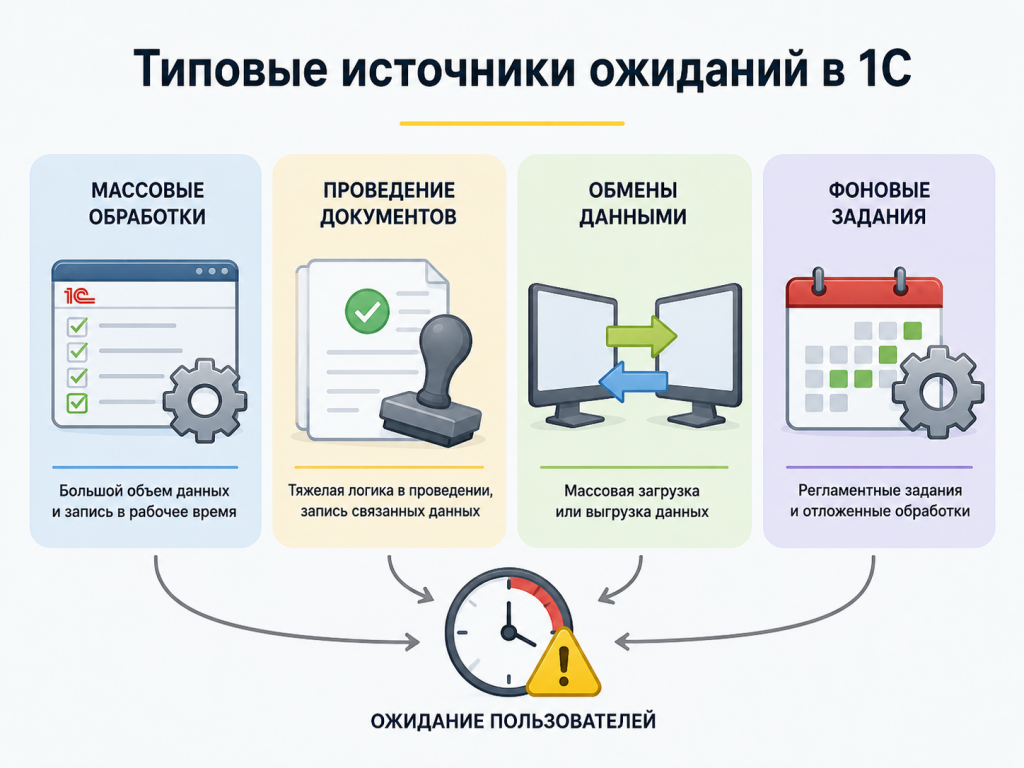
Где чаще всего появляются ожидания
Массовые обработки
Массовая обработка — один из самых частых источников неприятных ожиданий. Особенно если она пишет данные в рабочее время.
Опасный сценарий выглядит просто:
- выбрали много документов;
- в цикле получили объект;
- изменили реквизиты;
- записали документ;
- повторили это сотни или тысячи раз.
На маленьком наборе всё хорошо. На рабочей базе обработка начинает жить долго. Она запускает связанную логику и держит ресурсы дольше, чем ожидает разработчик. Пользователь в соседнем окне пытается записать документ и получает “1С висит”.
Перед массовой обработкой я проверяю три вещи: объем, время запуска и способ обработки. Если объем большой, запуск днем и всё идет одним куском, это кандидат на будущую проблему.
Проведение документов
Проведение — удобное место для бизнес-логики. Поэтому туда легко попадает лишнее: дополнительные проверки, пересчеты и обновление связанных данных.
Проблема начинается, когда обычное проведение превращается в маленькую массовую обработку. Пользователь нажал “Провести”, а внутри система пошла читать большой объем данных и записывать соседние объекты.
На ревью я особенно внимательно смотрю на такие места:
- запросы внутри проведения без отбора по конкретному объекту;
- запись связанных документов;
- пересчет большого набора данных;
- запрос внутри цикла;
- повторная запись объекта без изменений;
- дополнительная логика из расширения.
Фоновые операции
Отдельно проверяю регламентные задания и обмены. Если они массово пишут данные днем, пользователи могут видеть это как зависание обычной операции.
Здесь исправление не всегда в переписывании алгоритма. Иногда достаточно перенести запуск, ограничить объем или запретить повторный параллельный старт.
Что в коде чаще всего усиливает проблему
Блокировки и ожидания редко появляются просто потому, что “1С такая”. Часто им помогает код: длинная операция, лишняя запись или запрос без нормального отбора.
| Что проверить | Почему это риск | Как писать осторожнее |
| Запись объектов в цикле | Каждая запись запускает связанную логику | Писать только измененные объекты, дробить обработку |
| Проведение документов в цикле | Проведение может быть тяжелым | Ограничивать объем и запускать вне пикового времени |
| Широкий запрос без отборов | Операция читает лишние данные | Добавлять отборы по периоду, объекту и статусу |
| Запрос внутри цикла | Один запрос превращается в сотни обращений | Получать данные пакетом |
| Длинная транзакция | Операция дольше держит ресурсы | Сокращать критичный участок |
| Большой объем без порций | Операция становится длинной и плохо управляемой | Делить на пакеты и фиксировать прогресс |
| Лишняя повторная запись | Объект записывается без изменений | Сравнивать значения перед записью |
| Тяжелая логика в пользовательском ожидании | Пользователь ждет то, что можно выполнить отдельно | Выносить длительные действия из записи документа |
Запись объектов в цикле
Запись объектов в цикле — один из тех участков, которые на ревью нужно смотреть особенно внимательно. Строка “Объект.Записать()” выглядит маленькой. Но за ней может стоять много работы.
На ревью такой код для меня сразу красный флажок. Особенно если запись идет по выборке без ограничения объема.
Если объект не изменился, не нужно писать его “для надежности”. Такая надежность потом превращается в лишнюю нагрузку и странные ожидания. Перед массовой записью я задаю себе простой вопрос: сколько объектов реально изменится и что сработает на каждую запись?
Широкие запросы без отборов
Широкий запрос часто проходит незамеченным на тесте. Там мало данных, поэтому он выполняется быстро. В рабочей базе тот же запрос внезапно идет по большому периоду и нескольким организациям.
Плохой признак — когда запрос выбирает “всё”, а потом код фильтрует результат вручную. Еще хуже, если такой запрос стоит внутри проведения или записи документа. Пользователь ждет не только запись, но и весь этот лишний обход данных.
Запрос внутри цикла и длинная транзакция
Запрос внутри цикла — классическая ловушка. На десяти строках незаметно. На тысяче строк уже больно. Чаще безопаснее заранее собрать нужные данные одним запросом, подготовить соответствия или временные таблицы, а потом работать с готовым результатом.
С длинной транзакцией похожая история. Транзакция нужна, когда набор действий должен выполниться как единое целое. Но если внутри нее читать большой объем и писать много объектов, операция начинает держать ресурсы дольше, чем нужно.
Рабочий принцип простой: внутри транзакции оставлять только то, что действительно должно быть внутри. Подготовку данных, чтение и расчеты по возможности выполнять до критичного участка.

Как понять, что это похоже на блокировку
Подозрение на блокировку появляется не из одного признака, а из набора совпадений.
Я начинаю серьезно думать про блокировку, если:
- операция выглядит как ожидание, а не как расчет;
- проблема возникает при записи или проведении;
- рядом выполняется массовая обработка с записью данных;
- несколько пользователей работают с похожими объектами;
- после релиза новая логика стала дольше держать запись;
- проблема исчезает после завершения конкретной обработки;
- в сеансах видны длительные операции и ожидания;
- технологический журнал подтверждает ожидания.
Но здесь легко ошибиться. Долгий отчет без отборов — не обязательно блокировка. Перегруженный сервер — тоже не обязательно блокировка. Поэтому блокировка — это гипотеза, а не удобная универсальная причина для всего медленного.
Если всё назвать блокировкой, диагностика закончится раньше, чем начнется. Нужно понять, кто ждет, чего ждет, кто держит ресурс и какой сценарий к этому привел.
Как не сделать хуже во время расследования
Когда пользователи нервничают, появляется соблазн сделать что-то большое и заметное: завершить сеансы, перезапустить сервер, остановить задания. Иногда такие действия нужны. Но если сделать их раньше фиксации фактов, причина может уйти вместе со следами.
Типовые ошибки расследования:
- сразу обвинять пользователя;
- считать любое ожидание блокировкой;
- смотреть только журнал регистрации;
- не фиксировать точное время;
- не проверять фоновые задания и обмены;
- не сопоставлять проблему с релизом;
- завершать сеансы без понимания, что они делают;
- исправлять код без замера.
Пользователей винить бесполезно. Пользователь может выбрать широкий период или запустить тяжелый отчет. Но если один пользовательский сценарий способен создать серьезные ожидания для других, разработчику нужно смотреть не на характер пользователя, а на устройство сценария.
Чек-лист первичной диагностики
Я не держу такой список в голове идеально каждый раз. Но когда ситуация нервная, он помогает не прыгнуть сразу к любимой гипотезе и не пропустить простые вещи: время, сценарий, релиз, фоновые задания.
- Зафиксировать точное время проблемы.
- Понять, кто пострадал: один пользователь, отдел или все.
- Определить сценарий: запись, проведение, отчет, обработка, обмен.
- Уточнить объект: документ, отчет, обработка, период.
- Проверить, был ли рядом релиз или изменение расширения.
- Проверить фоновые задания, обмены и массовые обработки рядом по времени.
- Посмотреть активные сеансы: длительность и ожидания.
- Проверить журнал регистрации рядом по времени.
- При необходимости поднять технологический журнал.
- Сделать замер производительности проблемного сценария.
- Проверить код записи, проведения, запросы и циклы.
- Сформулировать гипотезу и следующий шаг.
Как писать код, чтобы не создавать такие проблемы
Самое полезное в теме блокировок — не расследование само по себе. Гораздо ценнее писать код так, чтобы расследований было меньше.
Перед изменением записи, проведения или массовой обработки я проверяю себя такими вопросами:
- не запускаю ли я тяжелую операцию, пока пользователь ждет ответ формы;
- не пишу ли объект повторно без изменений;
- не прохожу ли циклом по документам без ограничения объема;
- не делаю ли запрос внутри цикла;
- не выбираю ли слишком много данных без отбора;
- не держу ли транзакцию дольше, чем нужно;
- не создаю ли массовую запись в рабочее время;
- есть ли логирование длительной операции;
- есть ли безопасный повтор после ошибки.
Разработчик не предсказывает все проблемы рабочей базы заранее. Но он может не закладывать очевидные риски. Запись в цикле, широкий запрос, длинная транзакция и массовая обработка без порций — это не всегда ошибка. Но это всегда повод остановиться и проверить решение до релиза.
Финальный вывод
Когда пользователи говорят “1С тормозит”, не нужно сразу искать виноватого и перезапускать всё подряд. Сначала нужно понять сценарий, время, пользователя, длительность и то, что изменилось перед проблемой.
Блокировка — не главный злодей на все случаи. Иногда виноват обычный тяжелый запрос. Иногда мешает регламентное задание. Иногда стреляет наша же доработка после релиза.
Для 1С-разработчика эта тема важна не как страшная теория про СУБД, а как практический навык. Нужно уметь заметить, что операция не просто “медленная”, а потенциально создает ожидания для других.
Самый неприятный вариант — когда разработчик сам написал код, который на тесте прошел незаметно, а в рабочей базе начал создавать ожидания. Поэтому про блокировки стоит думать не только во время аварии, но и в момент, когда пишешь очередную запись объекта в цикле.
Хорошая диагностика начинается с вопроса: “Что именно сейчас ждет или работает слишком долго?” Хорошая разработка начинается с другого вопроса: “Что будет, если этот код выполнится на рабочем объеме данных и параллельно с пользователями?”
Если задавать эти вопросы до релиза, жалоб “1С висит” становится меньше. А если они всё же появляются, расследование идет не по панике, а по понятному маршруту.
Вступайте в нашу телеграмм-группу Инфостарт
