Почему именно Oracle?
Находясь здесь, я для себя извлек один небольшой урок – такое сочетание, как Oracle и 1С, встречается нечасто. Это – действительно редкость. И первое, что я хотел бы объяснить, – почему именно Oracle, и как так получилось, что такая достаточно редкая СУБД используется на нашем предприятии.
Во-первых, наше предприятие достаточно давно использует в своей практике Oracle.
- Начиная с 2000 года, у нас стартовал проект по внедрению ERP-системы на базе системы BAAN версии 4.
- В рамках этого проекта у нас появились люди с особыми компетенциями, которые хорошо знают, как администрировать эту систему.
Кроме того, Oracle у нас себя хорошо зарекомендовала:
- Она позволяет обеспечивать бесперебойную работу сервиса высокой доступности в режиме 24*7.
- А также она обеспечивает высокое быстродействие обработки больших массивов данных.
Характеристика нашей системы
Первоначальные характеристики нашей системы:
Конфигурация сервера для 1С:
- Сервер 1С у нас располагается на виртуальном сервере под управлением операционной системы Windows;
- Оперативная память порядка 192 Gb.
Версия конфигурации – УПП, релиз 1.3;
Версия платформы 8.3.6 с поддержкой 8.2;
Что касается конфигурации сервера СУБД:
- Сервер физический, состоит из двух узлов;
- Работает под операционной системой Oracle Linux 6.7;
- Оперативная память на каждом узле 1Тб. Как видите, ресурсов под сервер СУБД выделено гораздо больше, чем под сервер 1С.
Версия СУБД Oracle 12c;
Объем данных информационной базы более 1Тб.
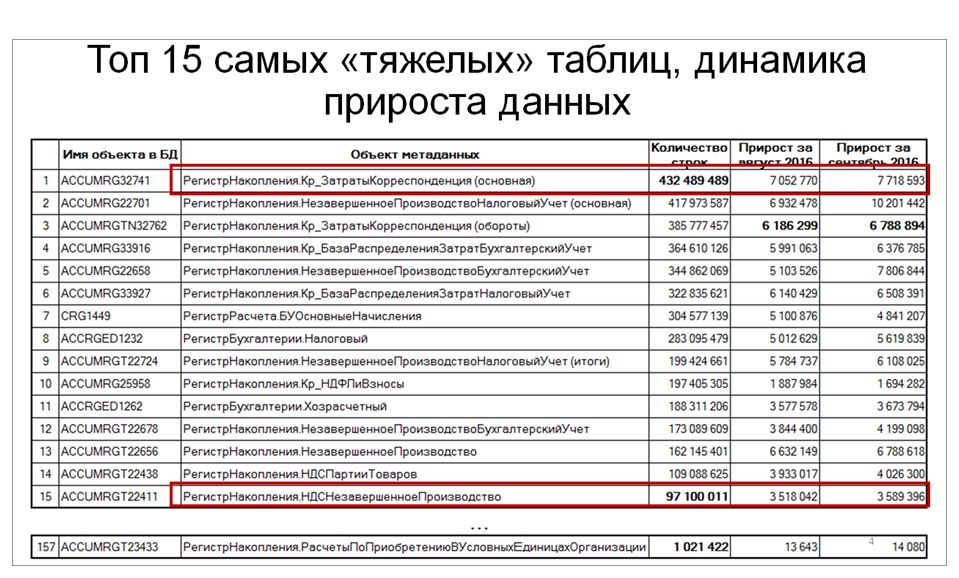
Итак, следующая достаточно важная характеристика – это размер физических таблиц в нашей базе данных. Здесь на слайде я представил ТОП-15 самых тяжелых таблиц.
- Верхняя строчка – это основная таблица регистра накопления, содержит более 400 миллионов записей;
- Последняя строка этого топа содержит чуть менее 100 миллионов записей. Система достаточно тяжелая, в нашей базе присутствует большой массив данных.
Можно также обратить внимание на прирост данных.
Основные проблемы, связанные с обеспечением быстродействия и масштабируемости в системах 1С в связке с Oracle
Итак, что с этим делать? Послушав своих коллег, которые рассказывали про проблемы, связанные с SQL-сервером, я порадовался, потому что большая часть этих проблем оказывается вне поля моего зрения:
- То, что связано с блокировками, нас не касается, потому что Oracle – это СУБД версионная.
- С планировщиком запроса, конечно, тоже возникают проблемы, но они не настолько критические, чтобы им было необходимо уделять большое внимание. Мы выполняем пересчет итогов, собираем статистику и эти моменты позволяют нам обеспечивать достаточное быстродействие и стабильно получать актуальные планы.
- Ситуации, когда план запроса ведет себя как-то неадекватно, конечно, встречаются, но они достаточно редки.
Так что же остается актуальным в нашей ситуации?
- Первое – это анализ и оптимизация быстродействия. Данных много, любой неаккуратно написанный запрос приводит к проблемам.
- Второй момент – это так называемое «противодействие» замедлению в связи с приростом данных. Прирост большой, и с этим что-то нужно делать.
Давайте поочередно посмотрим, как мы решаем эти проблемы.
Наш подход к разработке с учетом ориентации на Oracle

Что делать, когда возникают какие-то проблемные ситуации, которые необходимо исследовать или анализировать? За те два года, что я работаю с системой 1С, у нас в коллективе выработалась определенная методика проведения анализа и оптимизации быстродействия. Из чего она состоит?
На первом этапе проводится, так называемый, первичный или визуальный анализ кода, который необходимо оптимизировать. Выявляются какие-то проблемные участки кода, запросы к БД. Все это проводится посредством конфигуратора.
Следующий этап – более детальный анализ выявленных запросов в консоли запросов. На этом этапе запросы анализируются на языке 1С.
Третий шаг – это получение текста запросов SQL, его разбор и первичный анализ:
- Поиск узких мест;
- Оценка производительности;
- Замеры производительности;
- Включение технологического журнала;
- Извлечение «оракловых» запросов, которые генерирует 1С.
Все это производится посредством:
- Технологического журнала;
- А также с помощью средств администрирования Oracle – таких программ, как:
- SQL*plus – это консольная утилита, которая позволяет администратору базы данных выполнять все свои обязанности. Это достаточно удобная система, ей регулярно пользуются;
- Отдельная бесплатная утилита SQL developer, которую распространяет Oracle;
- Платная PL/SQL Developer.
На четвертом шаге производится непосредственно анализ SQL:
- Получение плана;
- Разбор этого плана;
- Оценка его стоимости.
На этом шаге уже обычно становится понятно, какие проблемы с производительностью имеются в данной функциональности.
И последний шаг – это уже оптимизация. Мы пришли к каким-то выводам, нашли способ решения на стороне языка 1С и переписали запрос.
Использование методики проведения анализа и оптимизации запросов с использованием технологического журнала 1С и средств администрирования СУБД на примере отчета «Матрица грейдов»
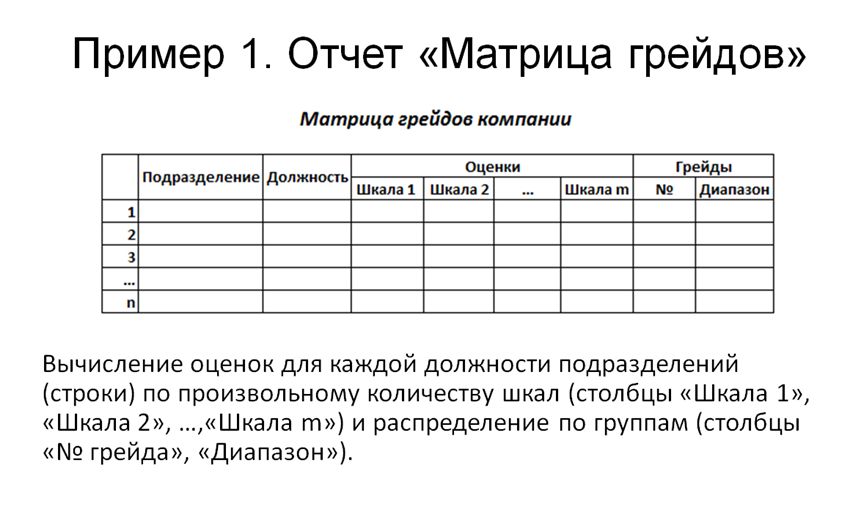
Давайте теперь на примере рассмотрим, как это все может работать.
В качестве примера я взял абстрактную ситуацию – это отчет «Матрица грейдов». Он находится в одной из отраслевых конфигураций, которую мы недавно приобрели. Сам отчет мы в своей работе не задействовали. Этим он и был хорош, потому что с ним можно было «играться», как угодно.
Итак, что делает отчет «Матрица грейдов»? Он выбирает некие оценки в разрезе подразделений и должностей по произвольному количеству шкал. Сложность в том, что эти шкалы могут быть разными. Отчет строится динамически, количество его полей меняется в зависимости от данных.
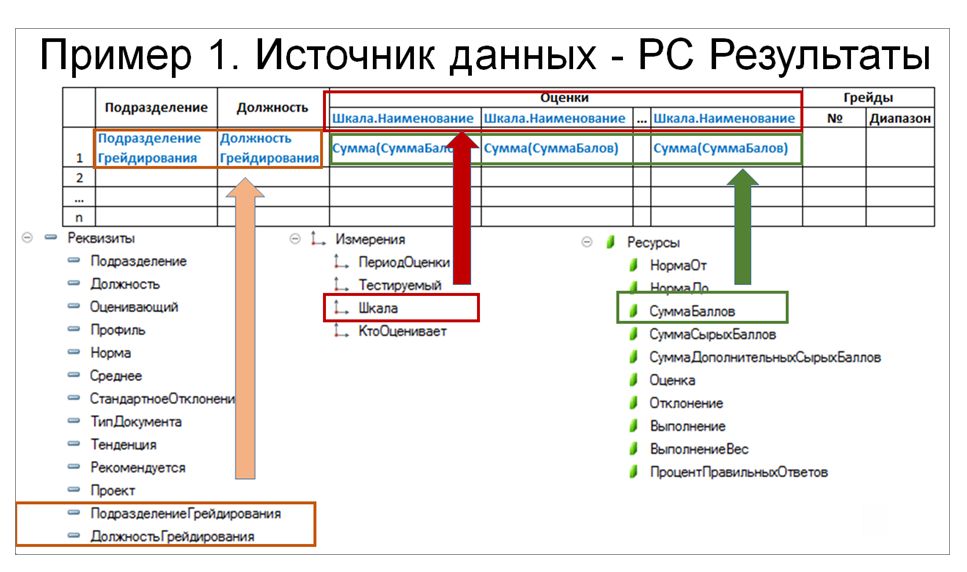
Этот отчет должен строиться таким образом:
Источником для него является регистр сведений «Результаты»:
- Подразделения и должности выбираются из реквизитов;
- Шкалы являются измерением;
- А оценки – это один из ресурсов.

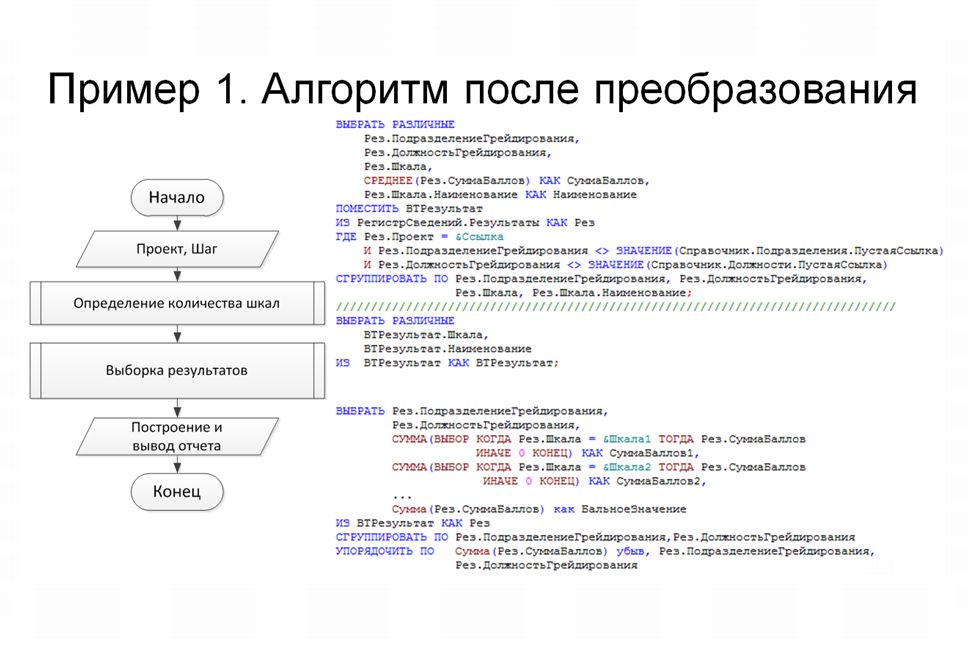
Теперь давайте посмотрим пошаговый алгоритм исполнения этого отчета.
В целом он состоит из пяти запросов, которые обращаются к базе данных и выбирают последовательно какие-то данные.
После этого все выбранные данные обрабатываются посредством алгоритма с вложенными циклами, и строится сам отчет, который выводится на экран.
Давайте последовательно рассмотрим каждый из этих запросов.
Первый запрос – это поиск документов по проекту оценки.
- Пользователь вводит в качестве условия некий проект, в рамках которого он хочет построить отчет.
- И запрос, обращаясь к документу «ПланированиеИКонтроль», выбирает перечень ссылок на документы, относящихся к выбранному проекту (все документы, которые участвовали в этой оценке).
На втором шаге уже на основании этих ссылок идет обращение к их табличной части «Грейдирование», где выбираются уникальные подразделения – это будет необходимо потом, для формирования самого отчета.
На третьем шаге выполняется еще один практически точно такой же запрос. Единственное его отличие в том, что в нем выбирается уже не только подразделение, но и должность. Лично меня это здесь насторожило – зачем два раза производить одни и те же действия при обращении к базе данных? Чуть позже мы про это поговорим еще раз.
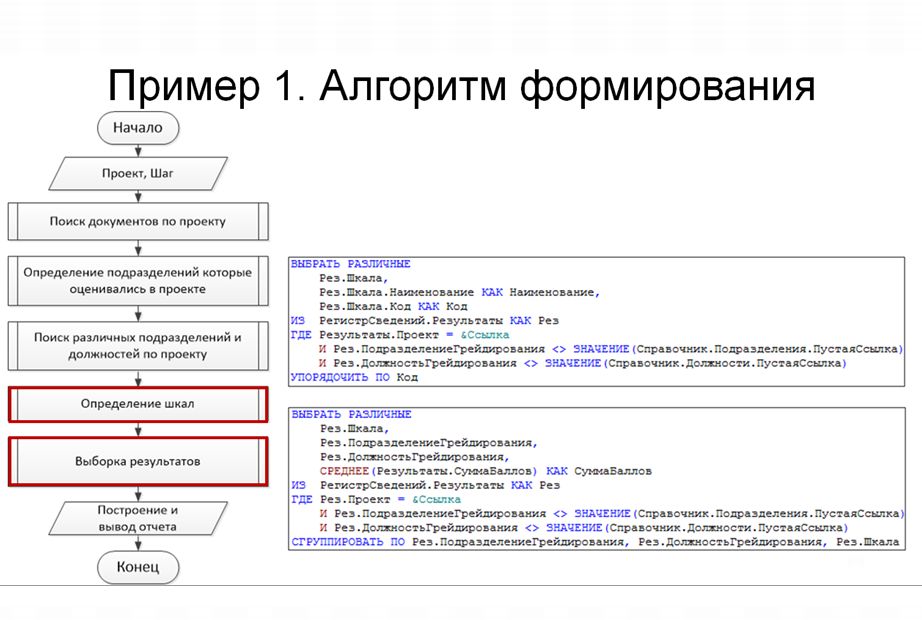
Четвертый шаг – это определение шкал. Отчет еще раз делает запрос в базу данных, при этом обращение идет уже непосредственно к регистру сведений. Оттуда в разрезе оцениваемого проекта выбираются все уникальные шкалы – на этом шаге получается как раз количество этих колонок, которые будут в отчете.
Пятый шаг – это выборка самих результатов. Идет обращение к регистру сведений с результатами, опять выбираются шкалы, подразделения, должности и уже дополнительно сами оценки.
Итак, все данные подготовлены, все, что необходимо, выбрали, пять раз обратились к базе данных и на последнем шаге произвели алгоритм построения самого отчета посредством вложенных циклов.
Вот, собственно, то, как работает этот отчет в своем первозданном виде.

Какие «узкие места», по моему мнению, присутствуют в этом отчете?
Во-первых, многократная выборка данных. Мы с вами это видели:
- Несколько раз выбираются должности;
- Несколько раз выбираются подразделения;
- Два раза производится обращение к регистру, в котором содержится информация.
Это – первое «узкое» место.
И второе – объединение баллов в одну строчку, которое происходит в момент построения и вывода отчета. Оно производится посредством большого количества вложенных циклов. Этот алгоритм – излишне запутанный. Он и обусловливает необходимость многократного обращения к базе данных посредством нескольких запросов.
Итак, что можно сделать с этим отчетом?
Вариантов немного, они все на поверхности.
Мы можем в одном запросе сразу выбрать все нужные нам поля:
- Должности;
- Подразделения;
- Шкалы;
- Оценки по этим шкалам.
И дальше уже на стороне 1С выполнять обработку и построение самого отчета. Единственный нюанс, который следует предусмотреть, заключается в том, что этот отчет – динамический (количество его полей изменяется в зависимости от данных). Из-за этого мы не можем его сформировать сразу в одном запросе.
Что можно сделать в такой ситуации?
Количество шкал можно определить сразу на первом шаге. Как видно на слайде:
- Сначала выбираются данные, которые помещаются в некую временную таблицу;
- И уже из этой временной таблицы выбираются уникальные наименования шкал, которые передаются на сторону 1С, чтобы мы, уже имея их количество, могли выстроить структуру самого отчета.
На втором шаге из временной таблицы формируется запрос. Причем его текст не просто написан руками, а на основе этого количества шкал в цикле производится так называемая склейка посредством конструкции «ВЫБОР» – мы объединяем несколько шкал и склеиваем эту строчку.
Получается, что за два прохода мы смогли сформировать то, что ранее делалось за пять шагов. По сути дела, теперь мы имеем только одно обращение в базу данных.
На слайде вы видите алгоритм после преобразования.
Итак, теперь наша задача сравнить, какой же из вариантов лучше – первый или второй. Может быть, то, что я здесь рассказываю, на самом деле, глубоко неоптимально. Как это проверить?
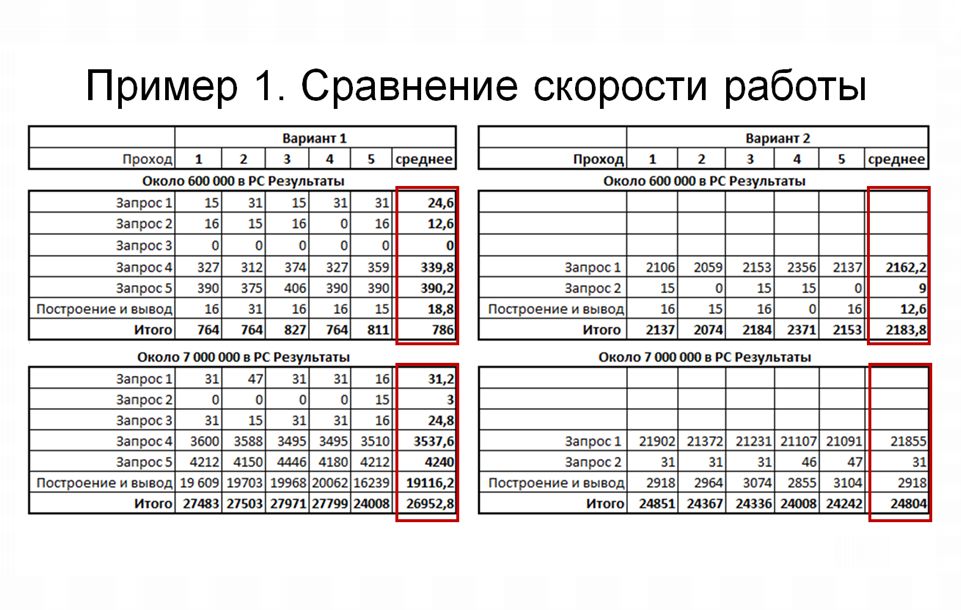
Самым простым критерием того, какая из реализаций алгоритмов лучше, это – замерить скорость выполнения. Это я и сделал. Всего замеров было пять. Последняя колонка по каждому из вариантов отображает среднее время. Ну и вверху вы видите, на каком количестве записей в итоговом регистре сведений были получены эти результаты.
На количестве записей в регистре 600 тысяч результаты оказались не очень хорошие. Мы видим, что тот самый алгоритм, который вроде бы должен был что-то оптимизировать, что-то ускорить – не сработал. Почему не сработал? Время выполнения запроса №1, который обращается к регистру сведений, получилось гораздо больше, чем время выполнения любого из запросов в первом варианте отчета. Почему так получилось, мы посмотрим чуть позже.
Но теперь я проведу еще один замер, уже на большем объеме данных – 7 миллионов записей в том же самом регистре. На этом количестве данных эти два варианта почти сравнялись по скорости – второй вариант даже стал чуть-чуть более быстрым. За счет чего получилась такая ситуация?
Мы видим, что для первого варианта самая большая и тяжелая операция – это этап «Построение и вывод», который зависит от количества выводимых строк. Если в первом варианте у нас выводилось всего три строчки, то при большем объеме данных выводится уже порядка 900, что существенно сказывается на быстродействии.
А во втором варианте отчета мы можем отметить, что быстродействие этапа «Построение и вывод» от возрастания количества обрабатываемых данных изменилось незначительно.

Итак. Почему второй вариант не сработал, почему он проигрывает в плане производительности?
Давайте рассмотрим два практически одинаковых запроса.
- Это запрос №5 из первого варианта, который выбирает данные из регистра;
- И запрос №1, который выбирает те же самые данные.
Итак, два запроса, которые друг от друга практически ничем не отличаются, за исключением того, что во втором запросе появились:
Обращение через точку – Рез.Шкала.Наименование;
И создание временной таблицы – ПОМЕСТИТЬ ВТРезультат.

Как понять, почему, казалось бы, такие небольшие отличия запроса приводят к настолько неоптимальному результату?
Для этого можно проанализировать SQL-запросы, которые генерирует 1С и отправляет в Oracle. Тексты этих запросов были получены путем включения технологического журнала.
В чем существенное различие этих двух вариантов практически одинакового запроса?
Во втором варианте у нас появляется левое соединение к таблице справочника.
Причем, это не просто левое соединение, мы потом в процессе группировки ищем по полю «Наименование» максимум;
И еще здесь в группировке используется какая-то непонятная конструкция: то, что вы видите через точку, – это обращение к так называемой «хранимой процедуре» (в MS SQL – это хранимая процедура, а в Oracle – это просто процедура).
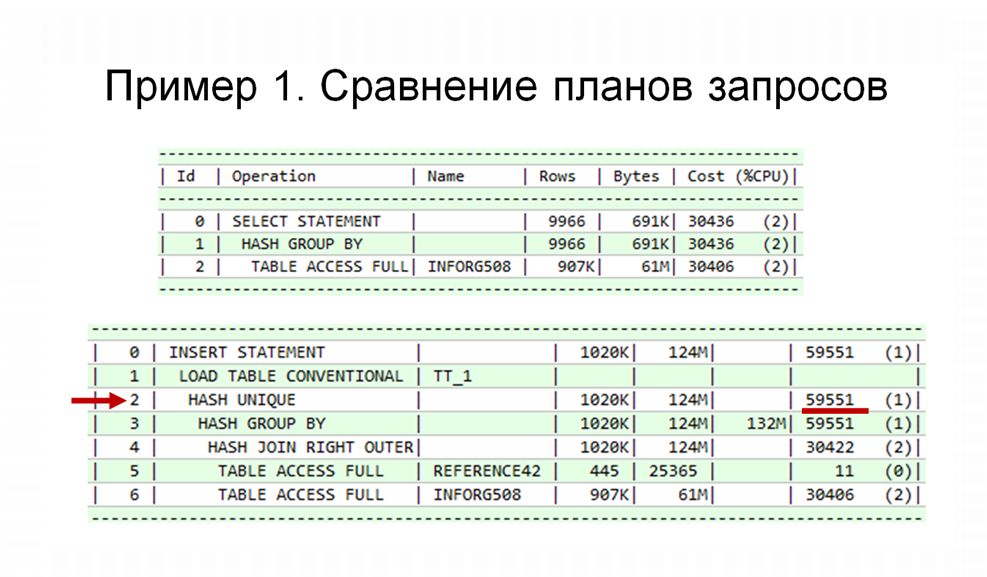
Чтобы понять, как эти действия влияют на сам запрос, обратимся к плану запроса. Вот он перед вами. Этот план запроса был сгенерирован в среде PL/SQL Developer. Он состоит из колонок:
- Операция (Operation);
- Имя объекта, к которому происходит обращение (Name);
- Количество данных, которые выбираются – прогнозируемое количество строк (Rows);
- Прогнозируемое количество данных (Bytes);
- И так называемая стоимость (Cost). Стоимость – это такая универсальная прогнозная величина, которая позволяет оценить запрос в условных единицах времени одноблочного чтения.
Итак, ориентируемся на эту стоимость.
Смотрим план первого запроса:
- На первом шаге производится полное сканирование таблицы регистра;
- На втором шаге происходит группировка;
- И суммарная стоимость самого запроса – мы видим 30436.
План второго запроса существенно больше. В нем мы видим гораздо больше операций, и стоимость этого запроса тоже больше. Почему стоимость второго запроса больше?
Во-первых, у нас уже два полных сканирования:
- Таблица индекса;
- Таблица справочника. Здесь можно отметить, что полное сканирование справочника дает несущественную нагрузку – всего 11, справочник очень маленький.
Но операция группировки в этом запросе дает нам в затратах гораздо более существенный прирост – из порядка 30 тысяч делает около 60.

Итак, какой мы можем сделать из всего этого вывод – необходимо исключить из запроса конструкцию Шкала.Наименование.
Мы это сделали.
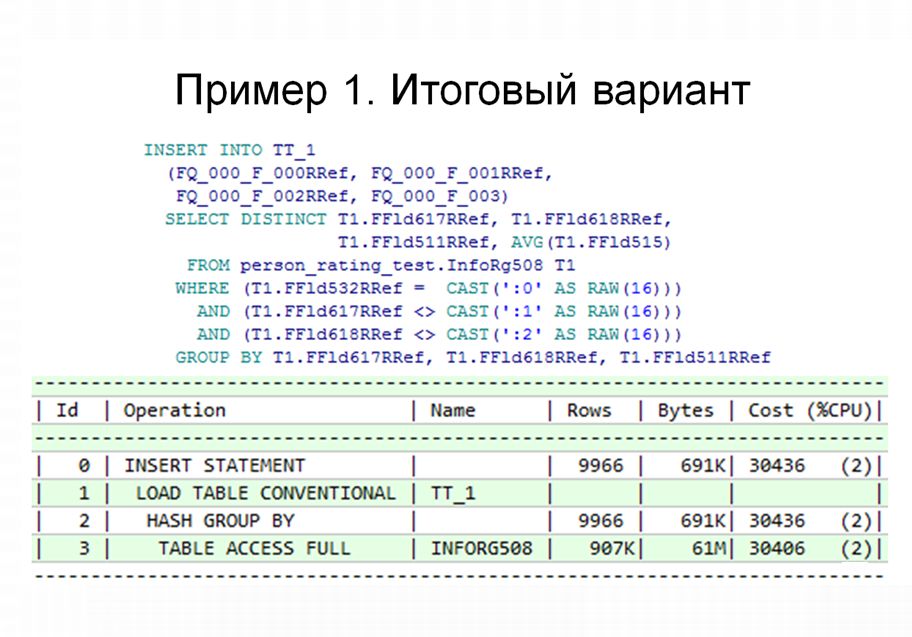
На слайде показано, какой план запроса получился в результате этого изменения. Как видите, он у нас получился примерно такой же, как и при первом шаге.
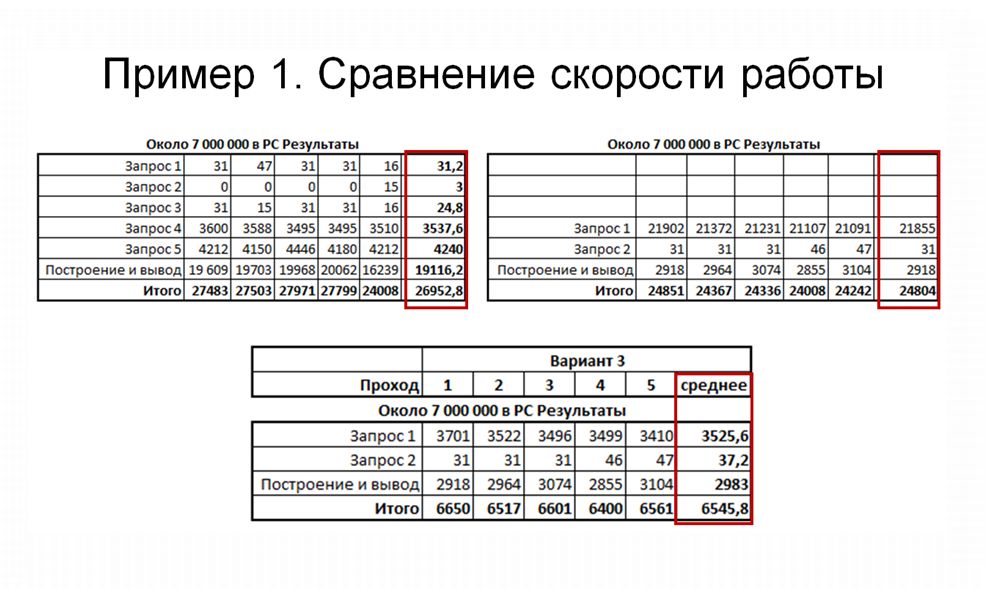
Теперь, сравнивая производительность, мы получаем для третьего варианта уже достаточно хороший результат – он работает гораздо эффективнее по сравнению с первым. Это происходит за счет того, что:
Его «Запрос 1» работает практически так же, как и «Запрос 5» из первого варианта
При этом этап «Построение и вывод» для третьего варианта работает очень быстро.
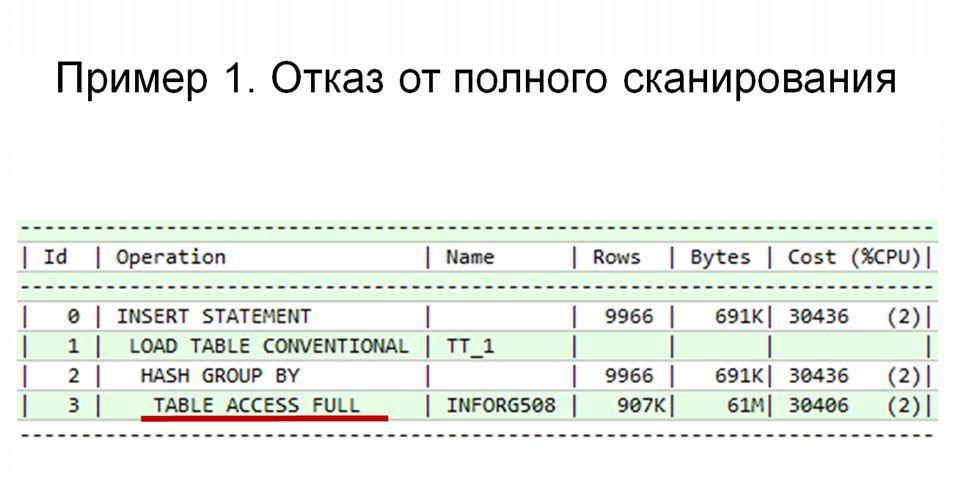
Вроде бы уже все хорошо, но пока еще есть резервы для оптимизации. В чем заключаются эти резервы? В операции полного сканирования, которая составляет основную стоимость запроса.
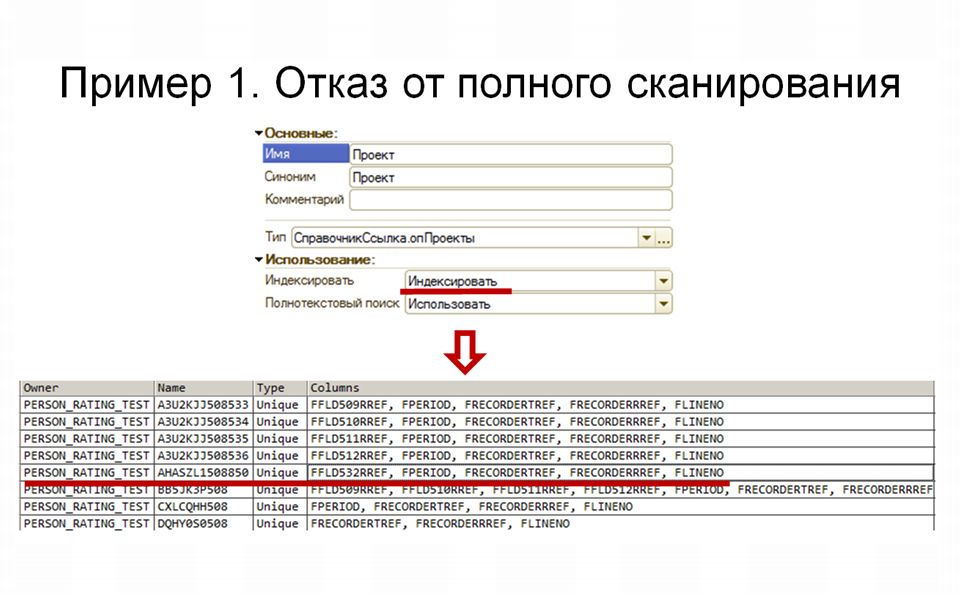
Попытаемся поменять полное сканирование на что-то другое – например, на доступ по индексу.
Для этого мы можем поставить в свойствах реквизита «Проект» значение использования «Индексировать».
Как видите, в структуре нашего регистра появился новый индекс.
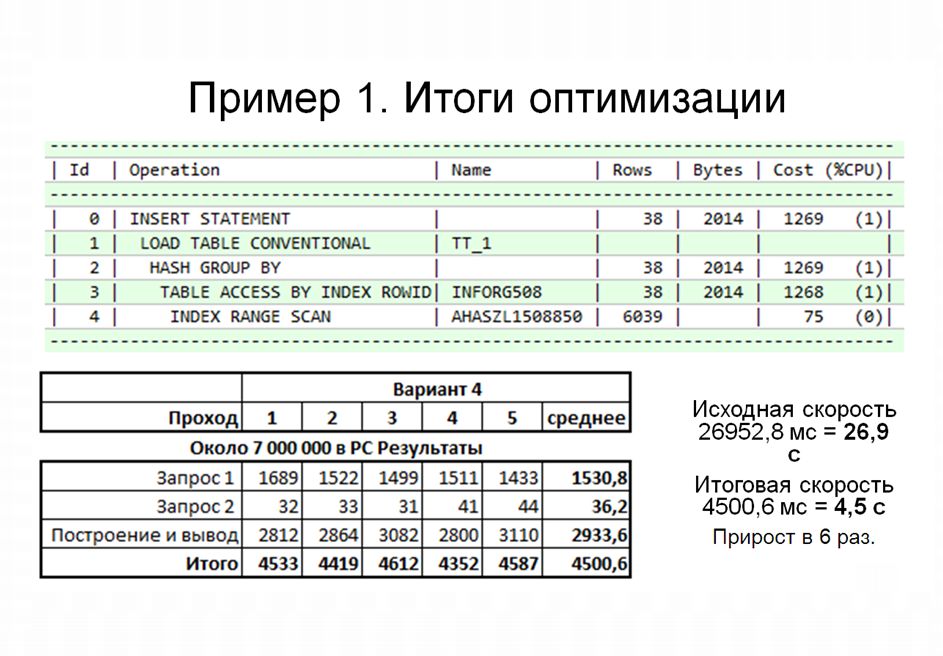
Наличие этого индекса позволяет нам значительно оптимизировать наш запрос. Теперь вместо полного сканирования у нас уже идет обращение по индексу, и мы видим, что стоимость этой операции составляет всего 75.
В результате мы получили довольно существенный прирост скорости нашего запроса, и в целом, по замерам времени, наш отчет стал работать примерно в 6 раз быстрее.
Принципы разработки программного обеспечения базы данных с учетом особенностей 1С

Что следует сказать про те результаты, которых мы добились.
Скорее всего, при эксплуатации этого отчета на реальных данных его оптимизация нам не понадобится, потому что используемый в нем объем данных – это оценки должностей. Много ли должностей на предприятии? Немного. И оценивать их будут тоже небольшое количество раз, поэтому 7 миллионов записей в регистре «Результаты» мы на этом отчете наверняка никогда не получим.
Однако в процессе анализа запроса для этого отчета были сформулированы принципы оптимизации работы базы данных с учетом особенностей 1С. Эти принципы приведены на слайде.
Нужно стараться при выявлении каких-то «узких мест» анализировать планы запросов, потому что очень часто не очевидно, почему запрос может работать медленно. Или, например, что лучше выбрать – вложенный запрос или временную таблицу? Однозначного ответа на этот вопрос нет – это можно выяснить только для локальной ситуации и именно посредством анализа запросов.
Противодействие замедлению в связи с приростом данных. Применение секционирования
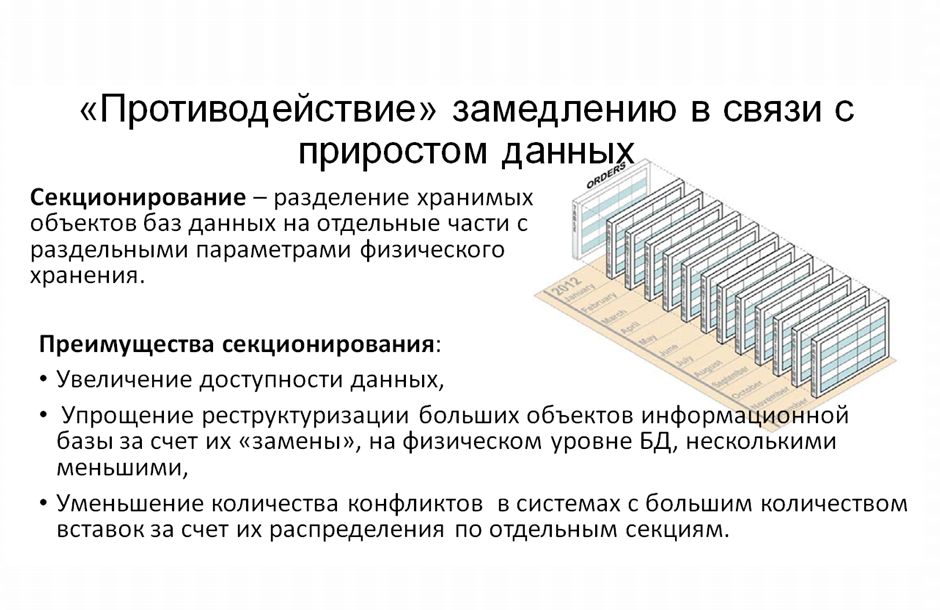
Еще один момент, про который я хотел сказать, – это «противодействие» замедлению.
В самом начале я показывал ситуацию, с которой мы работаем, – постоянный и очень быстрый прирост данных. Причем эту ситуацию не изменишь, такие требования у наших заказчиков.
Мы на этот счет долго думали и решили, что помочь нам в этом может такая вещь, заложенная в Oracle, как секционирование.
Что это такое? Секционирование – это изменение параметров хранения данных в таблицах на физическом уровне базы данных таким образом, что таблицы или индексы делятся на какие-то отдельные физические части, и СУБД уже при анализе запросов (при предоставлении данных) оперирует только какой-то одной маленькой частью, нежели всей таблицей.
У секционирования есть свои преимущества – они описаны на слайде.

Также есть разные виды секционирования.
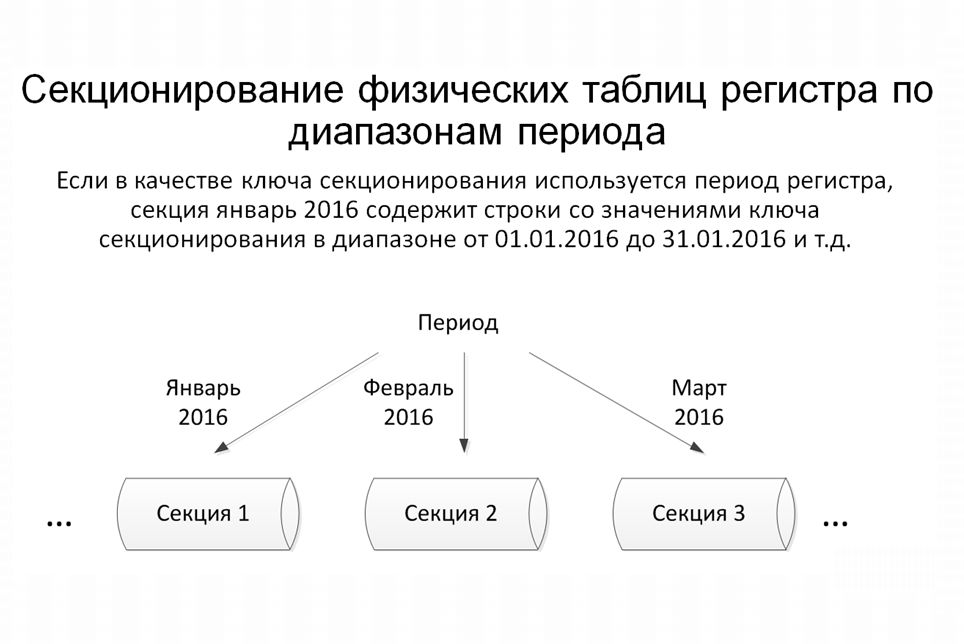
Для нас идеальным вариантом секционирования является разбиение таблиц по диапазонам периода.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2016 DEVELOPER.


Вступайте в нашу телеграмм-группу Инфостарт