











Сразу предупрежу, что никаких трепанаций программ не делал. Только лишь наблюдал извне. В распоряжении имелись 1С версии 8.3.12.1469 и MS SQL 10.50.1600.1 с его профайлером, куда ж без него.
При старте 1С:Предприятие семь раз обращается к таблице v8users, а если запустить из конфигуратора в режиме отладки, то все 11. Все бы ничего, но мною для экспериментов было сгенерировано 300 тысяч пользователей. Так сказать для наглядности. Само количество не имеет никакого значения, просто взято "с потолка" (так сказать, за время на обеденного перерыва).
Назначение каждого запроса мне, конечно же, неизвестно, но то, что они не столь очевидны, думаю, оценят многие. Назначение одного точно не то, что не знаю, не имею представления. Он второй по списку. Синтаксис остальных можно поставить под сомнение. Например, поиск текущего пользователя операционной системы. Саму обработку не прилагаю, придется ставить ценник, а лишь немного процитирую:
Вооружимся профайлером и начнем.
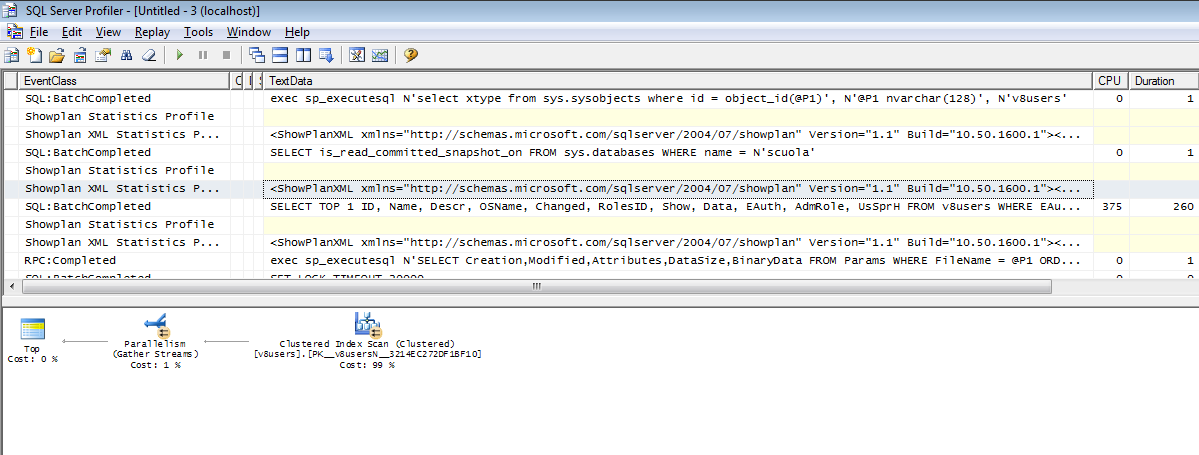
Первый запрос выглядит так:
SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE EAuth IS NULL OR AdmRole IS NULL OR UsSprH IS NULL
Данный запрос никак не оптимизируется, тем более, что таблице не хватает нужных индексов. Есть только один, да и тот не очень-то и подходит:
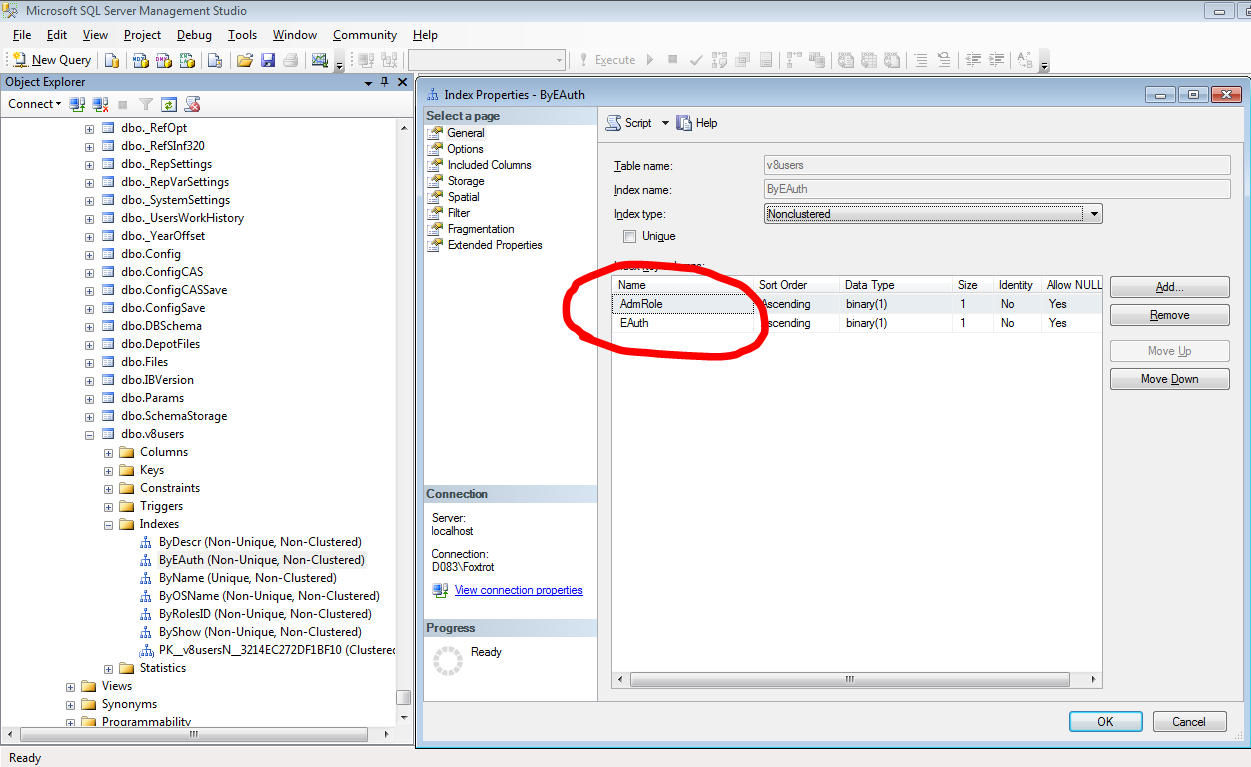
Второй запрос имеет вид:
SELECT MAX(Changed) FROM v8users
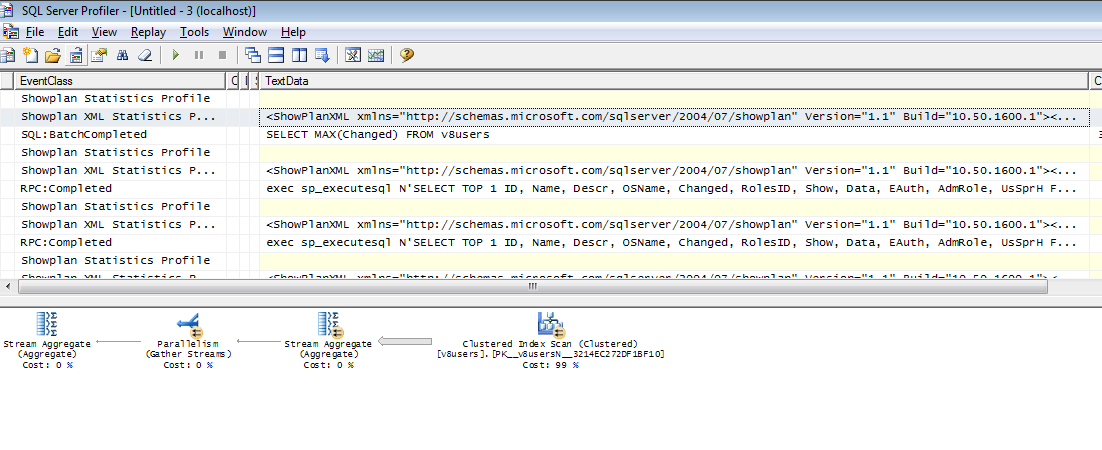 Данный запрос выполняется медленно потому, что нет индекса по полю Changed. Что мешало разработчикам создать его, остается для меня загадкой. Надо понимать, что данный запрос выполняется каждый раз при запуске 1С, и сколько времени можно было бы сэкономить пользователям, британским ученым пока неизвестно. Так же неизвестно для чего потребовался этот запрос. Да узнаем мы, когда последний раз изменяли параметры пользователя, а дальше что? Что делать с этой информацией? Буду признателен тому, кто приоткроет тайну.
Данный запрос выполняется медленно потому, что нет индекса по полю Changed. Что мешало разработчикам создать его, остается для меня загадкой. Надо понимать, что данный запрос выполняется каждый раз при запуске 1С, и сколько времени можно было бы сэкономить пользователям, британским ученым пока неизвестно. Так же неизвестно для чего потребовался этот запрос. Да узнаем мы, когда последний раз изменяли параметры пользователя, а дальше что? Что делать с этой информацией? Буду признателен тому, кто приоткроет тайну.
Последующие запросы на первый взгляд похожи друг на друга и различаются лишь параметрами. Радует, что все выражения оптимизируемы планировщиком, так как имеют все необходимые индексы.
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x00000000000000000000000000000000,0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE OSName = @P1 AND ID <> @P2
ORDER BY OSName',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'\\localhost\Foxtrot',0x952A5019EAE6A1F74023E7966E3EE1DE
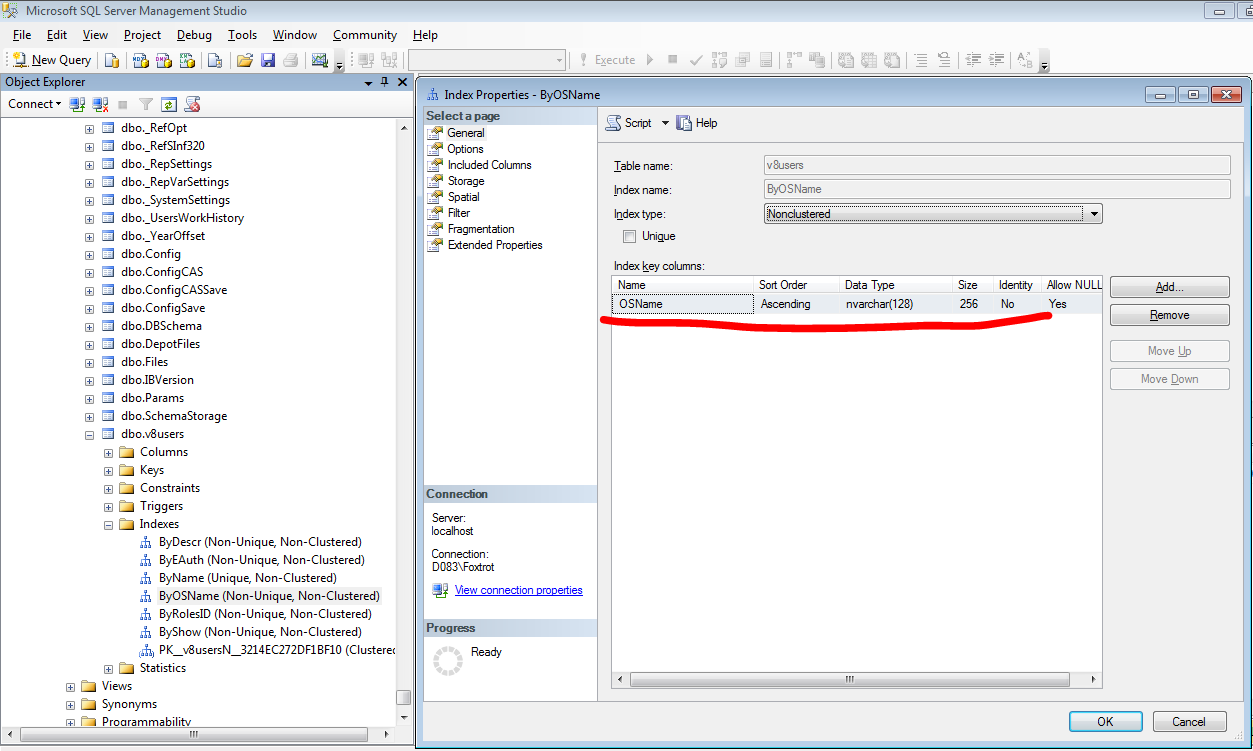
Видимо из-за размера поля OSName такой план запроса.
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x00000000000000000000000000000000,0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users
WHERE OSName = @P1 AND ID <> @P2
ORDER BY OSName',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'\\ localhost \Foxtrot',0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 2147483647 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE Name = @P1 AND ID <> @P2
ORDER BY Name',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'Admin',0x952A5019EAE6A1F74023E7966E3EE1DE
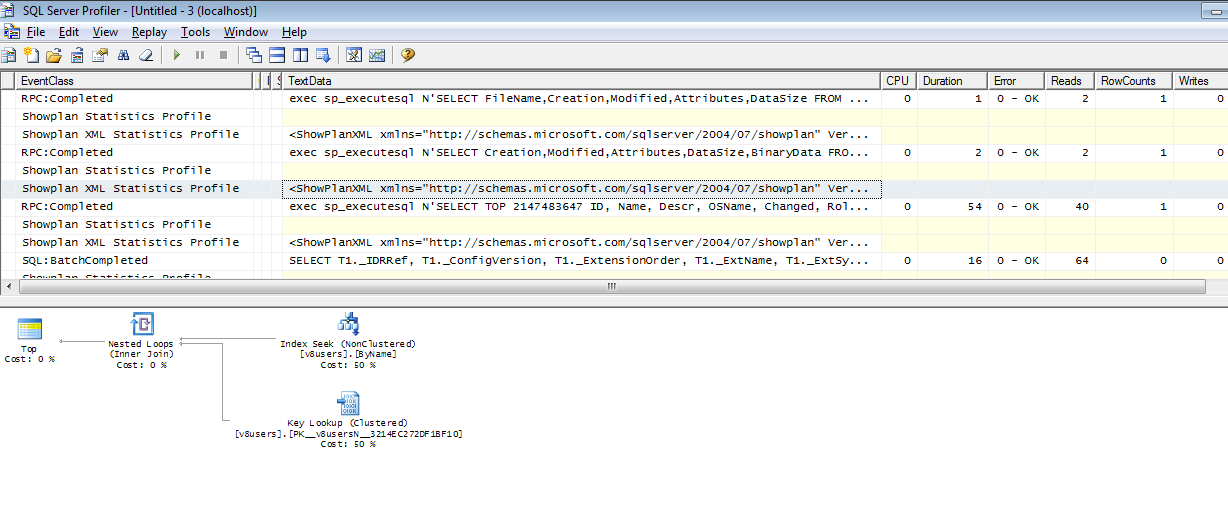
Поле Name меньшего размера, чем предыдущее – и план проще. Если кого-то заинтересовало мистическое число 2147483647, то есть статья в Википедии.
Последующие запросы дополнительно выполняются при запуске 1С:Предприятия из конфигуратора в режиме отладки. Все они лишь вариации предыдущих запросов, так что вопросов, думаю, быть не должно. О назначение каждого можно без труда догадаться, хотя конечно есть и вопросы.
Например, 0x952A5019EAE6A1F74023E7966E3EE1DE – это уникальный идентификатор пустой записи. Так вот не совсем понятно, для чего в каждом запросе писать:
ID <> 0x952A5019EAE6A1F74023E7966E3EE1DE
Ведь это только тормозит выполнение запроса. Тем более, что результат первой части запроса почти во всех случаях уникален.
exec sp_executesql N'SELECT TOP 2147483647 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE Name >= @P1 AND ID <> @P2
ORDER BY Name',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'',0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x9615C386AE786E744E60B9E4F7DD290A,0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x9615C386AE786E744E60B9E4F7DD290A,0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 2147483647 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE Name >= @P1 AND ID <> @P2
ORDER BY Name',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'',0x952A5019EAE6A1F74023E7966E3EE1DE
exec sp_executesql N'SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE ID >= @P1 AND ID <> @P2
ORDER BY ID',N'@P1 varbinary(16),@P2 varbinary(16)',0x9615C386AE786E744E60B9E4F7DD290A,0x952A5019EAE6A1F74023E7966E3EE1DE
Все эти запросы 1С выполняет при запуске, и как решение проблемы медленного запуска можно запускать программу только один раз после каждого обновления конфигурации. Но как оказалось этого недостаточно. Дело в том, что еще есть регламентные задания. Так вот при каждом выполнении каждого регламентного задания выполняется дважды еще один запрос:
SELECT TOP 1 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(NOLOCK)
WHERE EAuth IS NULL OR AdmRole IS NULL OR UsSprH IS NULL
Хорошая новость в том, что SQL-сервер при повторном выполнении использует результаты первого, то есть выполняет мгновенно.
При внешнем подключении выполняются все три запроса.
Чтобы управлять таким количеством пользователей был создан справочник «Пользователи» с реквизитом УИД, который синхронизировался с таким же полем таблицы v8users.

Ниже код синхронизации. Текст приведен не полностью, без вызываемых функций, но думаю, что их названия не вызовут затруднений в понимании назначений.
В качестве эпилога
При большом количестве пользователей не рекомендую лишний раз пользоваться методом ПолучитьПользователей() объекта ПользователиИнформационнойБазы потому, что он возвращает массив. Так что придется обождать пока не получите его целиком. Здесь впору кричать «массив, Карл!» Почему так было сделано, остается еще одной загадкой. Почему нельзя было сделать выборку, например как у справочников или документов:
Выборка = Документы.РасходнаяНакладная.Выбрать(ДатаНач, ДатаКон);
Время ожидания сразу же бы сократилось в разы. Метод ПолучитьПользователей() на стороне сервера выглядит следующим образом:
exec sp_executesql N'SELECT TOP 2147483647 ID, Name, Descr, OSName, Changed, RolesID, Show, Data, EAuth, AdmRole, UsSprH
FROM v8users WITH(READCOMMITTED)
WHERE Name >= @P1 AND ID <> @P2
ORDER BY Name',N'@P1 nvarchar(4000),@P2 varbinary(16)',N'',0x952A5019EAE6A1F74023E7966E3EE1DE
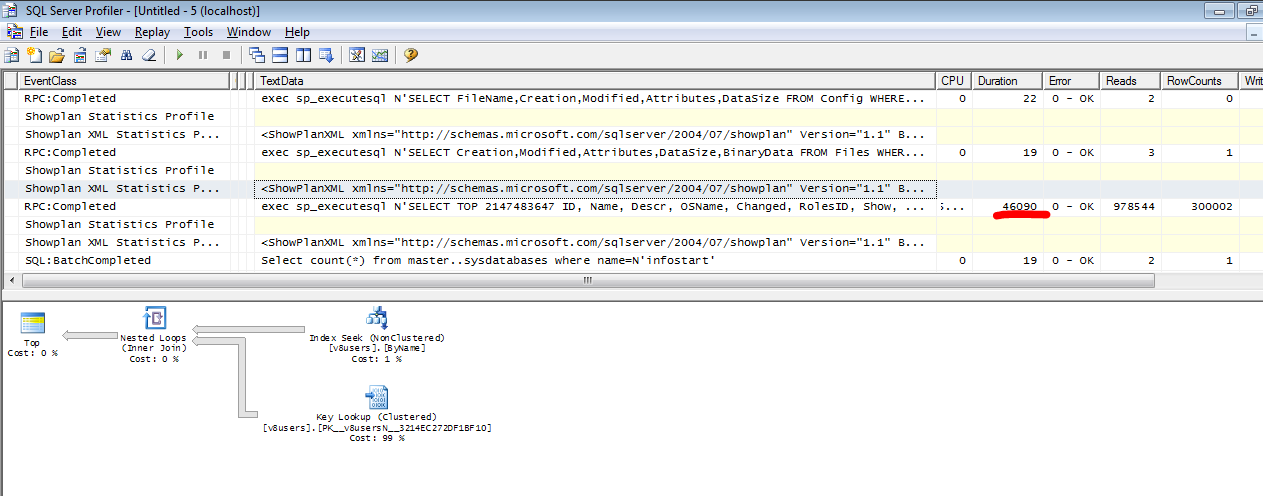
И план так себе, за то на выходе имеем массив. В моем случае из 300 тысяч элементов.
Вступайте в нашу телеграмм-группу Инфостарт