📌 О чём это вообще
Если вы хоть раз пытались искать «вода без газа 1.5 л» в справочнике номенклатуры на 50 000 позиций — вы знаете, что обычный поиск по подстроке не найдёт Aqua Minerale негаз. 1,5л ПЭТ. Потому что подстрока не совпадает.
Векторный (семантический) поиск решает это так: каждый элемент справочника превращается в массив чисел (вектор), который описывает смысл наименования. Запрос пользователя превращается в такой же вектор. Дальше ищем ближайшие — и они оказываются осмысленно близкими, даже если буквально не совпадают.
Расширение «Эмбид»:
- работает с любым справочником базы (выбираете в выпадающем списке — не нужно дописывать код под каждый);
- хранит векторы во внешнем контейнере ChromaDB;
- считает векторы локальной моделью через LM Studio (или любой OpenAI-совместимый сервер);
- умеет полную пакетную переиндексацию в фоновом задании, поиск с порогом релевантности, версионирование коллекций по модели;
- ставится одной кнопкой в любую конфигурацию 1С (режим
Customization, совместимость8.3.27).
Под капотом: 1 подсистема, 1 справочник, 2 регистра сведений, 2 перечисления, 11 констант, 3 общих модуля, 2 общих формы, 20 страниц встроенной справки (
Help/ru.htmlу подсистемы, перечислений, регистров, справочника и формы его списка, обеих общих форм и всех констант).
🧪 На чём проверял
1С: Управление торговлей, редакция 11 (11.5.22.174) (учебная) но будет работать и на других
Сервер (домашний ПК — здесь крутятся ChromaDB и модель эмбеддингов):
Компонент Значение ОС Windows 11 Pro Процессор AMD Ryzen 9 5950X ОЗУ 64 ГБ (2×16 + 2×16) Видеокарта NVIDIA GeForce RTX 5060 Ti 16 ГБ Docker Docker Desktop (актуальная версия) LM Studio актуальная версия с моделью text-embedding-multilingual-e5-large.ggufКлиент (ноутбук с файловой 1С):
- Платформа 1С 8.3.27+
- Тестовая база с подключённым расширением
Emb- Справочник «Номенклатура» — около 5–7 тыс. позиций без иерархии
💡 Если NVIDIA-видеокарты нет — берите
multilingual-e5-smallилиmultilingual-e5-base. Будет считаться на CPU, чуть медленнее, но рабоче. На Ryzen 5950X без GPU полная переиндексация ~6500 позиций укладывается в 5–7 минут.
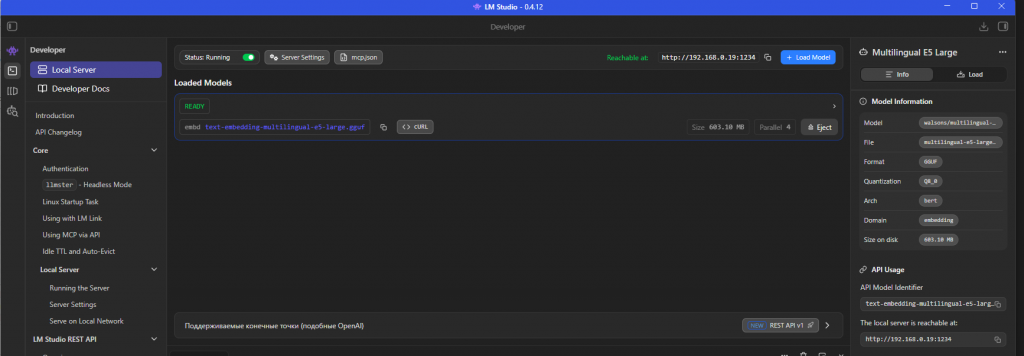
🚀 Шаг 1. Ставим LM Studio (модель эмбеддингов)
- Скачиваем LM Studio с официального сайта, ставим как обычное приложение.
- Внутри LM Studio открываем вкладку «Discover» (поиск моделей) и качаем
text-embedding-multilingual-e5-largeв формате GGUF.
- Если хочется поэкспериментировать —
Qwen3-Embedding-4BилиQwen3-Embedding-8B. Расширение «из коробки» поддерживает создание карточек под обе.- Переходим в раздел «Local Server»:
- Загружаем модель эмбеддингов (кнопка Load Model → выбираем e5-large).
- Порт по умолчанию —
1234(рекомендую оставить).- Включаем Serve on Local Network, если 1С запускается с другого компьютера.
- Жмём Start Server.
- Проверяем, что сервер живой. В PowerShell:
curl http://localhost:1234/v1/models
В ответе должен быть JSON с массивом
data, где будет наша модель.
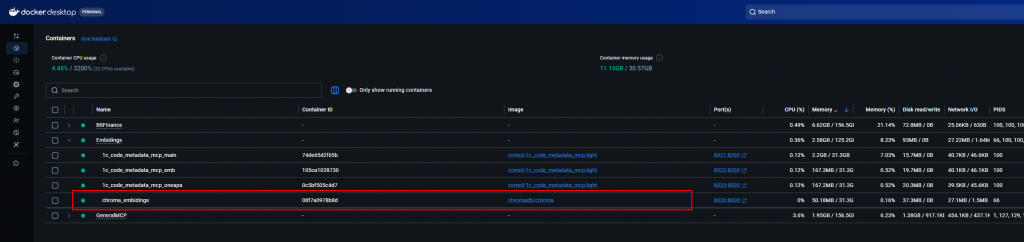
🐳 Шаг 2. Поднимаем ChromaDB в Docker
- Если Docker Desktop не установлен — ставим с официального сайта и запускаем.
- Создаём папку под данные ChromaDB (она переживёт перезапуски контейнера):
New-Item -ItemType Directory -Path "G:\Эмбидинги\base\chroma" -Force- Запускаем контейнер (PowerShell, бэктик в конце строк — это перенос команды):
docker rm -f chroma_embidings 2>$null; docker run -d ` --name chroma_embidings ` --label com.docker.compose.project=Embidings ` -p 8020:8000 ` -v G:\Эмбидинги\base\chroma:/data ` -e IS_PERSISTENT=TRUE ` -e PERSIST_DIRECTORY=/data ` --restart unless-stopped ` chromadb/chromaЧто важно:
8020— порт на хосте, к нему обращается 1С;
8000— порт внутри контейнера (это стандарт ChromaDB, его не трогаем);
G:\Эмбидинги\base\chroma— место хранения векторов; послеdocker rmколлекции не пропадут;
том нужно монтировать именно в/data(как в команде выше). Если смонтировать, например, в/chroma/chroma, папка на диске останется пустой, хотя по API коллекции будут создаваться — данные окажутся в файловой системе контейнера, минуя примонтированный каталог;
лейблcom.docker.compose.project=Embidings— чисто для удобства: в Docker Desktop контейнер ляжет в свою сворачиваемую группу.
- Проверяем, что ChromaDB ответит:
curl http://localhost:8020/api/v2/heartbeatОжидаем JSON
{"nanosecond heartbeat": <число>}.
🔥 Шаг 3. Открываем порты в брандмауэре (если 1С на другом ПК)
Если вы запускаете 1С на том же компьютере, где LM Studio и Docker — этот шаг можно пропустить.
Если же 1С на ноутбуке/другом сервере — на «сервере моделей» в PowerShell от администратора:
New-NetFirewallRule -DisplayName "LM Studio API" -Direction Inbound -Action Allow -Protocol TCP -LocalPort 1234 New-NetFirewallRule -DisplayName "Chroma DB API" -Direction Inbound -Action Allow -Protocol TCP -LocalPort 8020И в карточке провайдера / в адресе хранилища 1С указываем не
localhost, а реальный IP/DNS-имя сервера.
🧩 Шаг 4. Подключаем расширение к базе
Тут, думаю, для вас сложности не составит
Шаг 5. Настраиваем хранилище и провайдера
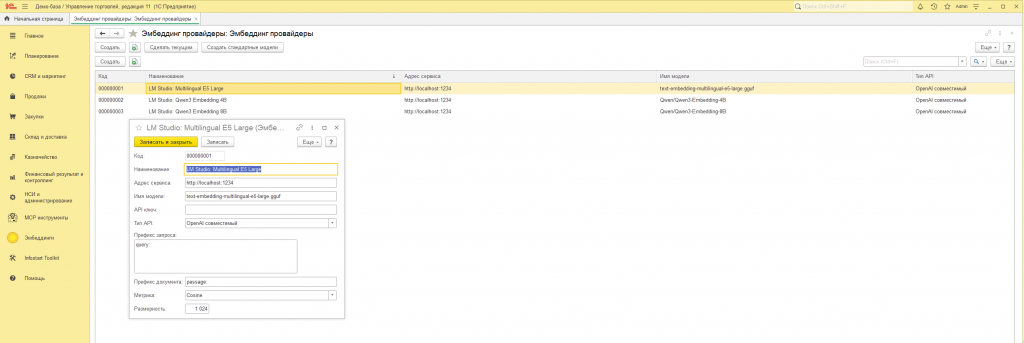
5.1. Создаём провайдера эмбеддингов
Провайдер — это карточка с координатами вашего сервера моделей. Без неё ничего не работает.
- Раздел «Эмбеддинги» → «Эмбеддинг провайдеры».
- В открывшейся форме списка жмём «Создать стандартные модели» — это самый быстрый путь: расширение само заведёт три карточки с правильными настройками:
LM Studio · multilingual-e5-large(1024-мерный, метрика cosine, префиксыquery:/passage:);LM Studio · Qwen3-Embedding-4B;LM Studio · Qwen3-Embedding-8B.
- Если хочется завести вручную — кнопка «Создать» и заполнить поля:
| Поле | Что писать |
|---|---|
| Наименование | Любое осмысленное, например LM Studio · multilingual-e5-large |
| Адрес сервиса | http://localhost:1234 (для удалённого сервера — IP/DNS-имя) |
| Имя модели | Точное имя модели, которое LM Studio показывает в Local Server. Обычно это text-embedding-multilingual-e5-large |
| API ключ | Для LM Studio / Ollama — пусто. Для OpenAI — обязательный Bearer-токен |
| Тип API | OpenAI совместимый |
| Метрика | Cosine для e5/Qwen3, L2 для классических OpenAI |
| Размерность | 1024 для e5-large; 0, если хотите оставить «как модель отдаст» |
| Префикс запроса | query: (с пробелом!) для e5; пусто для Qwen3 |
| Префикс документа | passage: для e5; пусто для Qwen3 |
Нюанс e5 и колонка «Соответствие, %». Процент в результатах поиска — это пересчёт расстояния между векторами , а не «насколько совпал текст». У multilingual-e5 поиск шлёт в модель строку с префиксом query:, индексация — с passage:; даже если вы ввели то же выражение, что в наименовании номенклатуры, в модель уходят разные входы → векторы не совпадают → для визуально полного совпадения процент часто ниже 100 (часто ~90–97%) — это ожидаемо.
У Qwen3 в типовых карточках префиксы пустые, там для идентичного текста процент обычно ближе к 100%. Убрать асимметрию у e5 можно, очистив оба поля префикса у провайдера (тогда запрос и документ кодируются одинаково), но для e5 это обычно ухудшает качество обычного семантического поиска; после смены префиксов обязательна полная переиндексация.
5.2. Назначаем провайдера текущим
В форме списка провайдеров выделяем нужного → кнопка «Сделать текущим». Строка подсветится — это наш активный провайдер. В системе всегда ровно один.
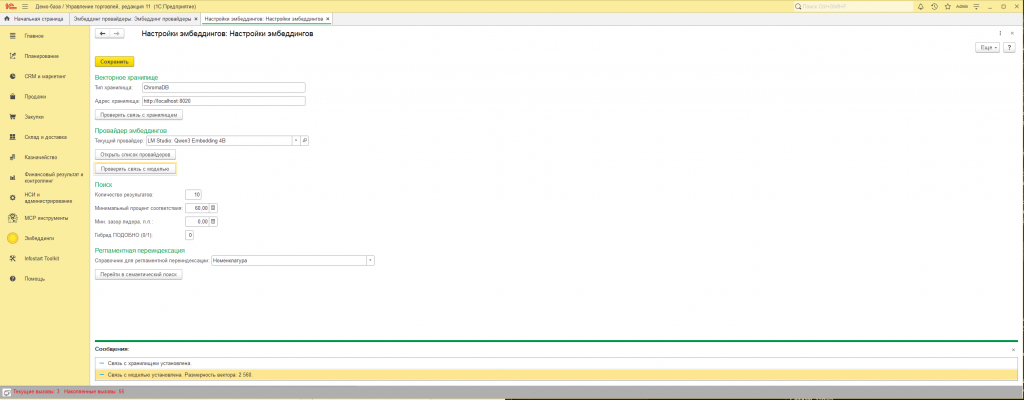
5.3. Заполняем «Настройки эмбеддингов»
-
Раздел «Эмбеддинги» → «Настройки эмбеддингов».
-
Группа «Векторное хранилище»:
- Тип хранилища:
ChromaDB(другие пока не поддерживаются). - Адрес хранилища:
http://localhost:8020(или IP сервера). - Жмём «Проверить связь с хранилищем» — внизу должно появиться сообщение об успехе. Если ошибка — проверьте, что Docker запущен и контейнер живой (
docker ps).
- Тип хранилища:
-
Группа «Провайдер эмбеддингов»:
- Текущий провайдер уже подставлен из п. 5.2 (либо выбираем здесь).
- Жмём «Проверить связь с моделью» — сообщение должно показать размерность вектора (для e5-large —
1024).
-
Группа «Поиск»:
-
Количество результатов: сколько строк показывать в форме поиска. Рекомендую
10. -
Минимальный процент соответствия: порог отсечки. Рекомендую начать с
60для e5; для Qwen3 — с50. -
Мин. зазор лидера, п.п. (
ЭмбеддингМинЗазорЛидераПроцентов): защита от «ровного» топа. Перед эмбеддингом запрос нормализуется (СокрЛП, схлопывание пробелов,Ё→Е). Если после отбора по минимальному проценту в выдаче три и больше строк, должны выполняться оба условия: зазор (1 − 2) и зазор (2 − 3) по проценту не меньше порога; иначе таблица очищается и показывается пояснение. Если строк ровно две — проверяется только зазор (1 − 2).0— правило выключено.С чего начать (подбор порога):
Значение, п.п. Смысл 0Правило выключено. 1,5…2,5Разумный старт: «ровные» топы часто отсекаются; запросы с явным лидером обычно проходят. Практично начать с 2,0.> 3Жёстче: меньше мусора, но выше риск скрыть выдачу, когда два реально близких по смыслу товара честно делят 1–2 место. Если после включения пусто слишком часто на нормальных фразах — снизьте зазор (например до
1,2…1,5). Если мусор всё ещё проходит — поднимите (например2,5…3,0). Имеет смысл не завышать без нужды минимальный процент соответствия: от него зависит состав первых строк и фактический зазор между ними.Важно: при одной строке после порога зазор не проверяется. При двух — только пара 1–2.
-
Гибрид ПОДОБНО (0/1) (
ЭмбеддингГибридПОДОБНО): при1после векторного поиска выполняется запрос к справочнику поНаименование ПОДОБНО(до 100 ссылок; фрагмент запроса до 100 символов). Строки, попавшие в эту выборку, поднимаются вверх в таблице результатов; порядок внутри «поднятых» и «остальных» сохраняет векторное ранжирование.0— только вектор, без подъёма. Если нормализованный запрос короче 2 символов, шаг ПОДОБНО пропускается.
-
-
Группа «Регламентная переиндексация»:
- Если планируете запускать ночное обновление по расписанию — выберите справочник в поле «Справочник для регламентной переиндексации».
-
Жмём «Сохранить». В одной транзакции записываются восемь констант, которые отображаются на форме (хранилище, провайдер, блок «Поиск» и регламентный справочник). Константы
ЭмбеддингТаймаутМодели,ЭмбеддингТаймаутХранилищаиЭмбеддингРазмерПакетана этой форме не выводятся — их меняют в Конфигураторе (узел Константы) или оставляют значения по умолчанию; код расширения читает их при пакетной переиндексации и HTTP-вызовах. Ориентиры: размер пакета64на GPU и16на CPU; таймаут модели120с; таймаут хранилища60с.
🧠 Шаг 6. Настраиваем, что именно индексировать
По умолчанию для каждого справочника в качестве текста для вектора берётся только Наименование. Этого часто мало: например, у номенклатуры важны ещё артикул, базовая единица, описание.
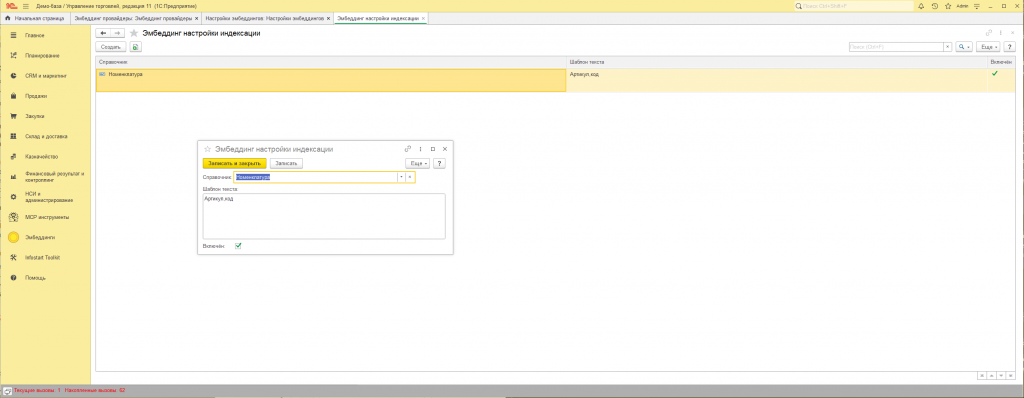
Расширение позволяет задать шаблон текста на каждый справочник через регистр сведений ЭмбеддингНастройкиИндексации.
- Открываем регистр (через «Все функции» → «Регистры сведений» → «Эмбеддинг настройки индексации» — либо из формы поиска, если добавили там команду).
- Создать запись.
- Поля:
- Имя справочника:
Номенклатура - Включён: если снят — в строку для эмбеддинга и при полной переиндексации попадает только наименование (поле «Шаблон текста» не используется). Если включён — наименование плюс непустые реквизиты из шаблона, как ниже.
- Шаблон текста: (имеет смысл при Включён = да) перечисление имён реквизитов шапки через запятую (как в конфигураторе), которые дополнительно попадут в строку для эмбеддинга после наименования, только непустые значения, между частями один пробел. Пример:
Артикул, Кодили без пробела после запятой:Артикул,Код— оба варианта корректны. Пустое поле при включённом флаге — в вектор уходит только наименование. - Имена реквизитов проверяются при разборе списка и при добавлении полей в запрос; недопустимые фрагменты отбрасываются (защита от подстановки в текст запроса).
- Имя справочника:
Пример (холодильник Indezit 1330). В регистре для справочника Номенклатура: измерение Справочник = номенклатура, Шаблон текста = Артикул,Код, Включён = да. У элемента номенклатуры: наименование Indezit 1330, артикул 0167899, код УТ-0000123 (если код пустой — см. ниже). Тогда строка для вектора до нормализации регистра и префикса модели будет:
- код заполнен:
Indezit 1330 0167899 УТ-0000123; - код пустой:
Indezit 1330 0167899.
- Записываем. После следующей переиндексации тексты будут собираться по этому списку.
Важно: если меняете шаблон или модель — сделайте полную переиндексацию заново. Старые векторы посчитаны по старому тексту/модели, смешивать их нельзя.
📦 Шаг 7. Полная индексация справочника
- Раздел «Эмбеддинги» → «Семантический поиск».
- Поле «Справочник» — выпадающий список со всеми справочниками базы, у которых есть реквизит
Наименование(для прочих индексация невозможна — текст брать неоткуда).- По умолчанию подставляется «Номенклатура», если она есть.
- Видим строку «Состояние индексации»: имя коллекции в ChromaDB, количество документов, дата последней переиндексации.
- Жмём «Переиндексировать».
- Запускается фоновое задание:
- под капотом —
ЭмбеддингПоиск.ЗапуститьПолнуюПереиндексациюВФоне; - можно спокойно работать в других окнах 1С;
- под капотом —
Длительность ориентировочно:
Размер справочника LM Studio + e5-large на GPU LM Studio + e5-large на CPU 1 000 элементов ~30 секунд ~1.5 минуты 5 000 элементов ~2 минуты ~6 минут 50 000 элементов ~20 минут ~1 час 💡 Имя коллекции в ChromaDB —
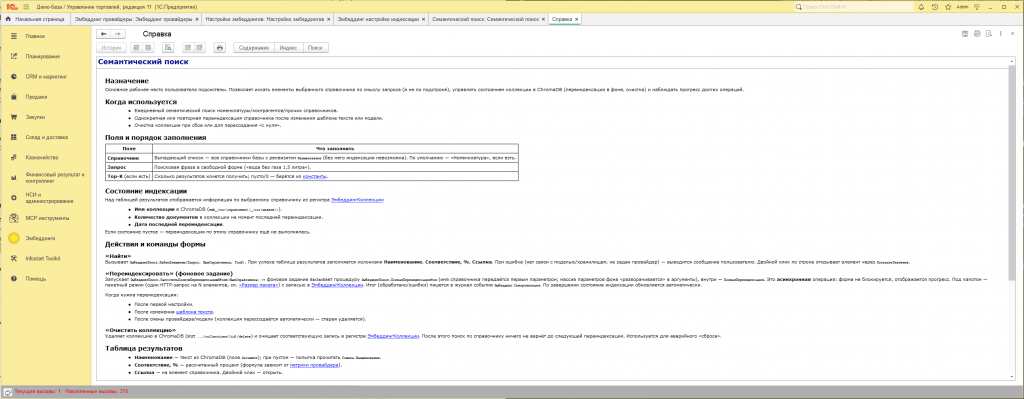
emb_<crc32(имя_справочника)>_<crc32(имя_модели)>. При смене модели у текущего провайдера расширение создаст новую коллекцию автоматически — старые «битые» векторы не помешают. Маппинг хранится в регистреЭмбеддингКоллекции(только чтение).🔍 Шаг 8. Семантический поиск
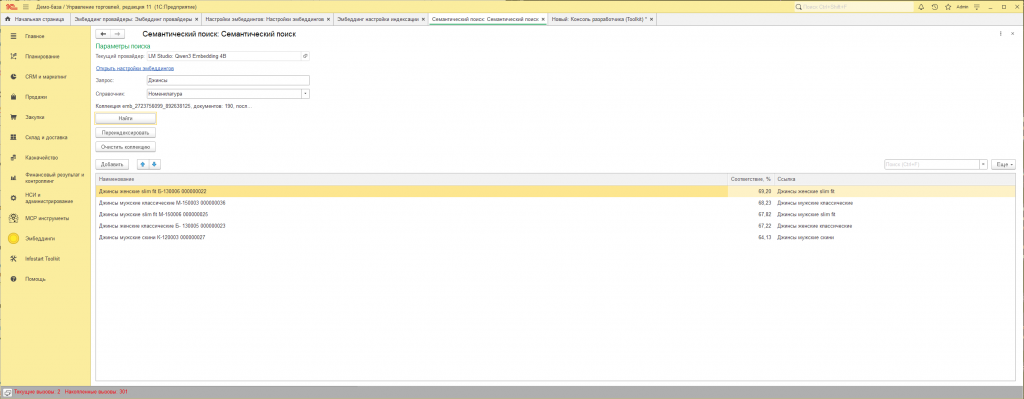
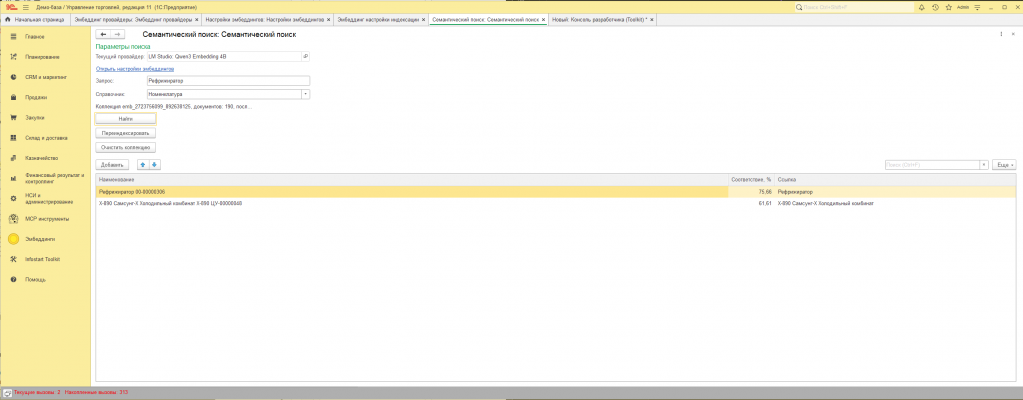
- Раздел «Эмбеддинги» → «Семантический поиск».
- Выбираем справочник.
- В поле «Запрос» пишем человеческим языком: «
вода без газа 1.5 литра», «клавиатура механическая русская», «шуруп для гипсокартона 35 мм» — что угодно.- Жмём «Найти».
- В таблице снизу — результаты:
Наименование/Соответствие, %/Ссылка. Сортировка — по убыванию релевантности (после нормализации запроса и, при включённом гибриде ПОДОБНО, с подъёмом строк, у которыхНаименованиесодержит подстроку запроса — см. п. 5.3).- Двойной клик по строке — открывает элемент справочника как обычно.
Если ничего не нашлось — это либо настоящий ноль (в коллекции нет похожего по смыслу), либо минимальный процент соответствия слишком высокий, либо сработало правило «мин. зазор лидера» (при двух строках — близкие 1–2 места; при трёх и больше — «ровный» блок 1–2–3 — см. п. 5.3): тогда таблица пустая, но появится пояснение, а не техническая ошибка. В отличие от старых версий, расширение явно сообщит об ошибке поиска (например, ChromaDB недоступен или вектор не посчитался) — в нижней части формы появится текст ошибки. Молча возвращать пустой массив больше нельзя.
Если результаты странные:
- Проверьте, что метрика провайдера соответствует модели (
Cosineдля e5/Qwen3,L2для классических).- Для e5: по умолчанию задайте префиксы
query:/passage:(см. таблицу выше). Если смущает не 100% при полном совпадении текста запроса и наименования — это следствие асимметрии префиксов; см. абзац «Нюанс e5 и колонка „Соответствие, %“» выше в шаге 5. Обнулять оба префикса имеет смысл только осознанно (см. тот же абзац).- Для Qwen3 в типовых карточках префиксы оставляют пустыми.
- Сделайте полную переиндексацию заново, если меняли шаблон текста или реквизиты в
ЭмбеддингНастройкиИндексации.
🛠 Шаг 9. Обслуживание
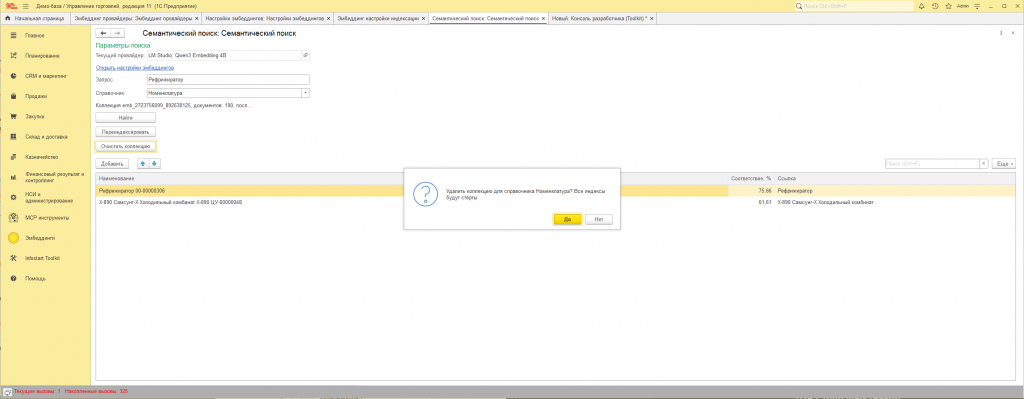
Очистить коллекцию
В форме «Семантический поиск» → кнопка «Очистить коллекцию». Удаляет все векторы текущего справочника в ChromaDB. После этого нужно сделать полную переиндексацию.
Логи
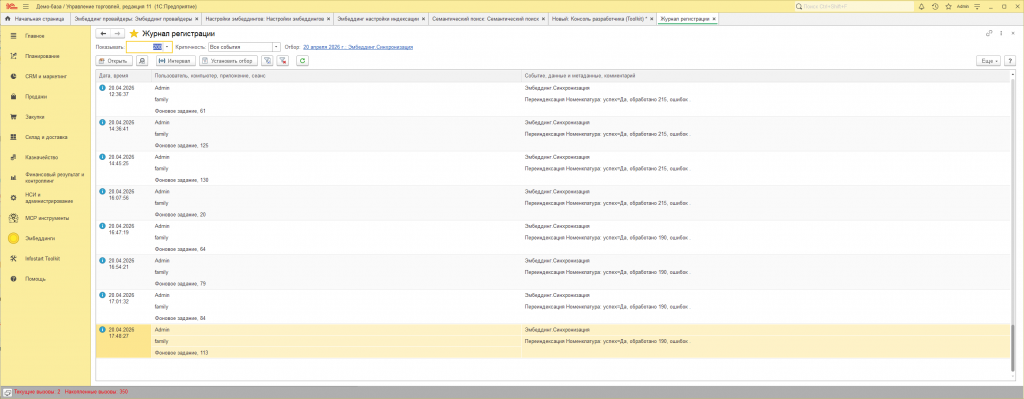
Все ошибки HTTP (модели и хранилища) пишутся в журнал регистрации:
- Событие:
Эмбеддинг.Синхронизация - Уровень:
Предупреждение
Открывается через «Все функции» → «Стандартные» → «Журнал регистрации», фильтр по событию.
Регламентная переиндексация (опционально)
Расширение содержит готовую процедуру ЭмбеддингПоиск.ПолнаяПереиндексацияРегламентноеЗадание, которая берёт имя справочника из константы ЭмбеддингИмяСправочникаРегламент.
В составе расширения регламентное задание не зарегистрировано — это сделано намеренно, чтобы не нагружать вашу базу без явного согласия. Запустить можно одним из способов:
- Завести
ScheduledJobв самом расширении (или в основной конфигурации) с вызовом этой процедуры. - Запускать вручную из обработчика регламентной задачи БСП.
- Настроить внешнее планирование (например,
schtasksс запуском пакетного режима 1С).
FAQ / типичные грабли
Q: «Проверить связь с моделью» возвращает «Превышен таймаут».
A: Скорее всего, в карточке провайдера указан адрес http://localhost:1234, а 1С работает на другом ПК. Замените на реальный IP/DNS-имя сервера с LM Studio. И не забудьте про правило брандмауэра (Шаг 3).
Q: ChromaDB отвечает 410 Gone / 404 на /api/v1/....
A: Расширение работает с API v2 (/api/v2/tenants/default_tenant/databases/default_database). Старые версии ChromaDB (до v0.5.x) не поддерживаются. Обновите образ: docker pull chromadb/chroma.
Q: Размерность вектора у разных моделей разная — что делать с уже посчитанными?
A: Ничего не делать. Имя коллекции включает CRC хэша модели, поэтому при смене модели старая коллекция остаётся, а под новую создаётся свежая. Запускайте полную переиндексацию — и работайте.
Q: Можно ли использовать OpenAI напрямую вместо LM Studio?
A: Да. В карточке провайдера: Адрес сервиса: https://api.openai.com, Имя модели: text-embedding-3-small (или -large), API ключ: ваш sk-… , Метрика: Cosine. Префиксы — пустые. После этого «Проверить связь с моделью» должна вернуть размерность 1536.
Q: Можно ли индексировать документы / регистры?
A: Сейчас — только справочники (это сделано через Метаданные.Справочники).
Q: Поиск по 50 тыс. позиций тормозит.
A: Сам поиск в ChromaDB — миллисекунды. Тормозит обычно одно из двух: (а) dimensions модели огромный и вектор считается долго, (б) включён большой Минимальный процент соответствия и расширение запрашивает у ChromaDB до ТопК * 20 кандидатов. Для больших коллекций уменьшайте порог или ТопК.
Q: Где встроенная справка?
A: Везде. Любая форма / справочник / константа / регистр расширения отвечает на F1 — открывается страница с описанием полей, действий и типичных ошибок. Всего 20 страниц справки в нативном формате 1С (см. блок «Под капотом» выше).
🗺 Карта объектов расширения
| Что | Где |
|---|---|
| Подсистема | Подсистема.ДОЭмбеддинги (раздел «Эмбеддинги» в командном интерфейсе) |
| Справочник провайдеров | Справочник.ЭмбеддингПровайдеры |
| Регистры | РегистрСведений.ЭмбеддингНастройкиИндексации, РегистрСведений.ЭмбеддингКоллекции |
| Перечисления | Перечисление.ЭмбеддингТипAPI, Перечисление.ЭмбеддингМетрика |
| Константы (11 шт.) | ЭмбеддингАдресХранилища, ЭмбеддингТипХранилища, ЭмбеддингКоличествоРезультатов, ЭмбеддингТекущийПровайдер, ЭмбеддингТаймаутМодели, ЭмбеддингТаймаутХранилища, ЭмбеддингРазмерПакета, ЭмбеддингИмяСправочникаРегламент, ЭмбеддингМинимальныйПроцентСоответствия, ЭмбеддингМинЗазорЛидераПроцентов, ЭмбеддингГибридПОДОБНО |
| Общие модули | ЭмбеддингПровайдер (HTTP к модели), ВекторноеХранилище (HTTP к ChromaDB), ЭмбеддингПоиск (оркестрация) |
| Общие формы | НастройкиЭмбеддингов, ФормаСемантическогоПоиска |
| Роль | ДООсновнаяРоль |
🎯 Что в итоге получаете
- Магический поиск «по смыслу» по любому справочнику базы.
- Универсальность: новый справочник — без единой строки кода.
- Полностью локальная инфраструктура (никакие данные не уходят наружу, если используете LM Studio + ChromaDB).
- Пакетная индексация в фоне с прогрессом, версионированием коллекций и настраиваемым текстом для вектора (регистр
ЭмбеддингНастройкиИндексации: «Шаблон текста» при флаге «Включён», иначе только наименование). - Встроенная справка по F1 на каждый объект.
- Открытый исходный код, легко расширяется (
Customization-расширение, режим совместимости 8.3.27).
🙏 Вместо заключения
Расширение — попытка сделать векторный поиск в 1С «промышленно пригодным», а не просто демонстрацией. Поэтому: фоновые задания, регистры настроек, версионирование коллекций, валидация имён реквизитов, единая форма настроек, кнопки проверки связи и встроенная справка.
Что намеренно не сделано :
- автоматическая подписка
ПриЗаписисправочников (чтобы не нагружать запись элементов лишними HTTP-запросами без согласия владельца базы); - регламентное задание (точка запуска — на ваше усмотрение);
Если найдёте баги или захочется фичу — пишите, разберёмся. Удачи! 🎉

Infostart MagicInput
Улучшенный поиск по строке в 1С: находит объекты по любой части названия и нескольким ключевым фрагментам, распознаёт ввод в другой раскладке и показывает статусы прямо в списке подбора. Помогает быстрее находить нужные элементы, сокращает ошибки при вводе и подключается как готовое расширение для 1С 8.3/8.5 — без доработок.
Проверено на следующих конфигурациях и релизах:
- Управление торговлей, редакция 11, релизы 11.5.22.174
Вступайте в нашу телеграмм-группу Инфостарт