

{kind=link}
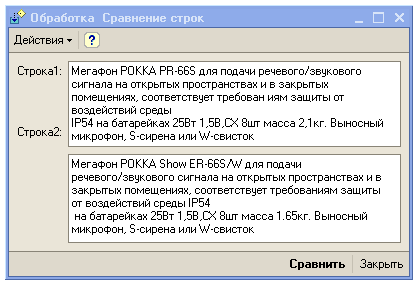
Работая над обработкой сравнения документа с присланной версией печатной формы заказа в xls, столкнулся с необходимостью сообщать не только сам факт отличия в названиях товаров, но и информации о том, что конкретно отличается. Беглое знакомство с материалами Инфостарта не помогло - не нашел подходящего решения. Пришлось самому придумывать алгоритм. Получившийся инструмент показался мне полезным - потому решил поделиться ним.
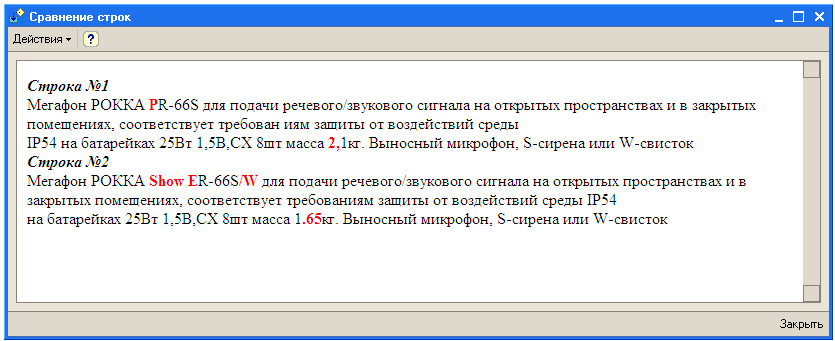
Алгоритм: находим наибольшую общую подстроку двух строк (с помощью суффиксных автоматов http://e-maxx.ru/algo/suffix_automata) - получается что каждая строка разбита на 3 части: левая (еще не обработанная), средняя (это наибольшая общая подстрока) и правая (не обработанная). Левую и правую части обрабатываем таким же образом до тех пор, пока не сможем получить общую подстроку - в таком случае подстроки различны. В итоге получаем чередование совпадающих и не совпадающих подстрок.
Алгоритм выполнен без рекурсии - т.е. подходит для обработки больших строк.
Дополнительно для увеличения наглядности добавил вывод в html.
PS: если снова изобрел велосипед - прошу прощения за невнимательность.
Вступайте в нашу телеграмм-группу Инфостарт