
Когда работа 1С останавливается, это не просто ИТ-сбой, а риск для бизнеса. Разбираем, как организована поддержка РКЛ на практике: уровни критичности, SLA и что действительно влияет на скорость решения проблем.
Техническая поддержка по 1С:Расширенной корпоративной лицензии – это тот уровень сервиса, который обычно начинают ценить не в момент покупки, а когда случается первый серьезный сбой. Когда 1С становится ядром бизнеса, любая нестабильность системы перестает быть ИТ-проблемой и превращается в операционный риск. Именно в таких ситуациях становится понятно, как на самом деле работает РКЛ.
В Инфостарт мы регулярно подключаемся к таким кейсам. Если исходить из практического опыта, основная ценность РКЛ – не в формальных SLA, а в том, что за ними стоит: понятная модель реагирования, доступ к экспертизе и возможность разбирать проблемы на уровне платформы, а не симптомов.

Расширенная корпоративная лицензия (1С:РКЛ)
Как устроена поддержка РКЛ на практике
Поддержка по РКЛ – это не «расширенный ИТС». Это отдельный контур сопровождения, ориентированный на технологический слой: платформа, кластер, СУБД, инфраструктура.
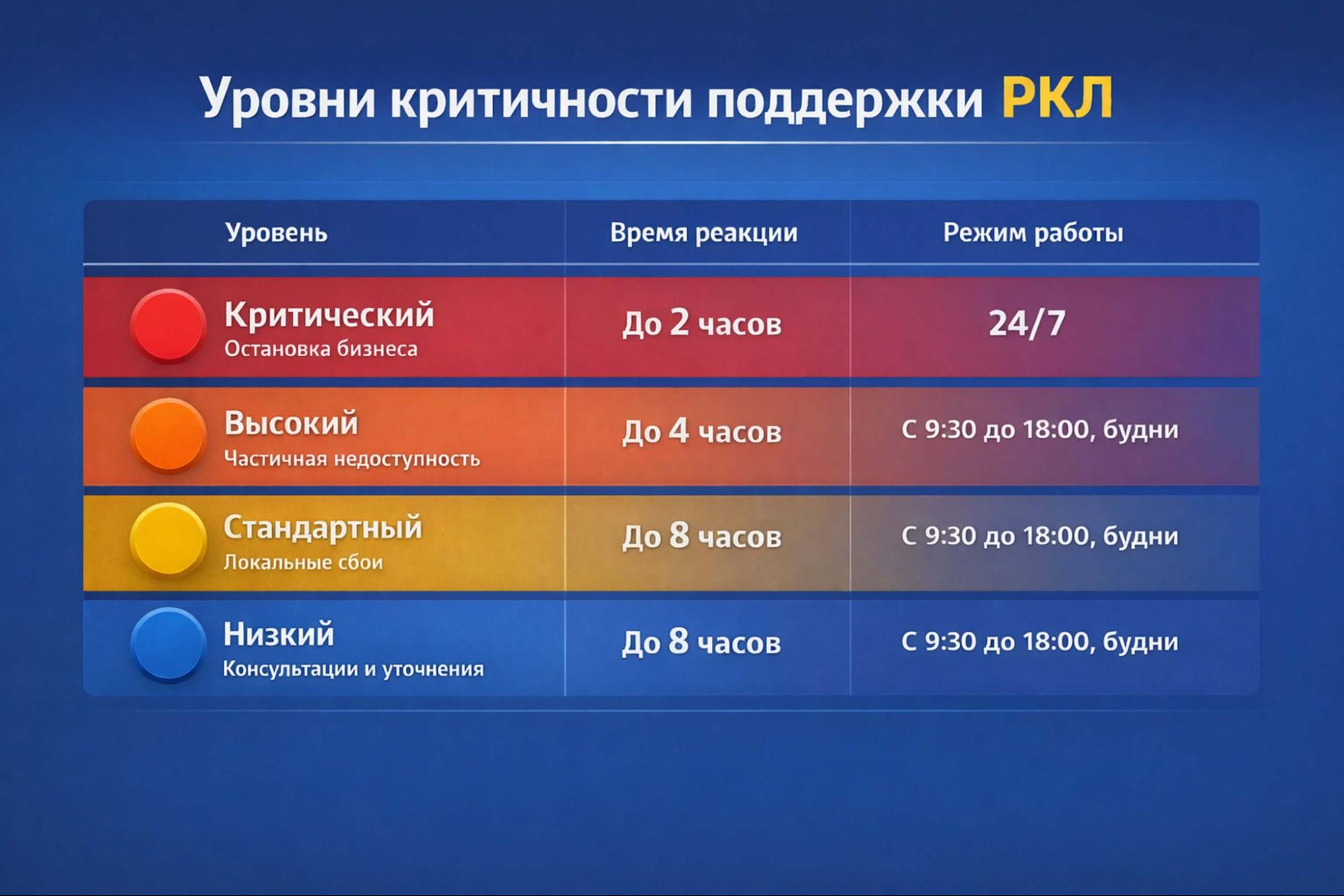
Когда приходит обращение, ключевую роль играет не только сама проблема, но и ее влияние на бизнес. Именно поэтому вся работа строится вокруг уровней критичности. Именно по ним определяется скорость реакции, режим работы и глубина вовлечения экспертов.
Есть четкие критерии, которые помогают отнести инцидент к тому или иному уровню. Они завязаны на три вещи: доступность системы, наличие обходных решений и влияние на бизнес-процессы.
Критический уровень: остановка бизнеса
К первому уровню критичности относится ситуация, когда система фактически недоступна или ее использование невозможно. Критерии здесь жесткие:
- недоступен ключевой функционал и нет обходных путей;
- пользователи не могут выполнять операции;
- невозможно восстановиться из резервной копии или перейти на другую версию.
Важно: этот уровень применяется только к продуктивным системам, находящимся в промышленной эксплуатации.
По SLA такие обращения обрабатываются с максимальным приоритетом. Время реакции составляет до 2 часов. Поддержка работает в режиме 24/7. Статус обновляется не реже одного раза в 12 часов, на практике чаще.
Есть и требования к заказчику: специалист должен быть на связи постоянно, а время ответа не должно превышать час. Если эти условия не соблюдаются, критичность автоматически снижается.
Судя по практике Инфостарт, такие кейсы почти всегда связаны с платформой или инфраструктурой. Например, аварийное завершение процессов rphost. Внешне это выглядит как «периодически выкидывает пользователей», но по факту это деградация всего кластера.
В другом случае сервер ras начинал падать с определенной периодичностью, и администраторы теряли управление системой. Бывали ситуации, когда рабочие процессы зависали и не принимали новые соединения: сервис формально запущен, но подключиться невозможно.
Во всех этих сценариях система либо полностью недоступна, либо ее использование непредсказуемо. Это прямое влияние на бизнес, и именно такие инциденты попадают в уровень 1.
Высокий уровень: частичная недоступность
Уровень 2 – это ситуации, когда система продолжает работать, но часть функционала недоступна или существенно деградирует.
Критерии здесь такие:
- бизнес-процесс можно выполнить, но с серьезными ограничениями;
- приходится использовать обходные решения;
- время выполнения операций увеличивается более чем в два раза.
Также сюда относятся ситуации, когда проблема блокирует развитие системы: например, невозможность обновления платформы или конфигурации.
По SLA время реакции составляет до 4 часов. Работа ведется в рабочее время. Статус обновляется примерно раз в 5 рабочих дней.
На практике это один из самых частых уровней для сложных технологических проблем. Например, ошибка платформы при удалении записей из регистра сведений. Система работает, но важные операции не выполняются. Или некорректное поведение управляемых блокировок, из-за которого возникают зависания при записи данных.
Отдельно стоит отметить сценарии, когда система формально доступна, но ее использование сопровождается нестабильным поведением. Например, ошибки платформы в механизмах авторизации (в том числе OpenID Connect) или некорректная работа отдельных функций после обновления. В таких случаях пользователи могут входить в систему и выполнять операции, но часть процессов работает с перебоями или дает непредсказуемый результат.
Стандартный уровень: локальные сбои и деградация
Уровень 3 – это ситуации, когда система в целом работает, но есть проблемы, влияющие на отдельных пользователей или отдельные сценарии.
Критерии:
- сбои носят единичный характер;
- ухудшение производительности не превышает критических значений;
- система остается работоспособной без серьезного влияния на бизнес.
Время реакции по SLA – до 8 часов. Работа ведется в рабочее время. Обновление статуса происходит примерно раз в 10 рабочих дней.
Именно здесь сосредоточена большая часть инженерной работы. Например, длительные обращения к менеджеру управляемых блокировок. Пользователь видит ограничения, но система продолжает работать. Или задачи по анализу производительности: расчет себестоимости начинает выполняться дольше обычного, но не блокирует работу полностью.
Часто встречаются кейсы с технологическим журналом: дублирование ключей, некорректные события, влияние настроек ТЖ на производительность. Это не аварии, но такие проблемы усложняют диагностику и могут накапливаться. Сюда же относятся взаимоблокировки: система работает, но периодически возникают зависания отдельных операций.
Низкий уровень: консультации и уточнения
Уровень 4 – это обращения, не влияющие на текущую работу системы.
Критерии простые:
- система полностью работоспособна;
- нет влияния на бизнес-процессы;
- речь идет о консультациях или предложениях.
По SLA он обрабатывается так же, как и стандартный: реакция до 8 часов, работа в рабочее время.
На практике это вопросы по лицензированию, настройке серверов, особенностям работы платформы. Например, как распределяются лицензии в кластере, как корректно настроить сервер лицензирования или разбор механизма истории данных.
Такие задачи часто воспринимаются как второстепенные, но именно они помогают избежать серьезных инцидентов в будущем.
Почему качество обращения напрямую влияет на скорость решения
Даже при наличии РКЛ скорость решения проблемы зависит от того, насколько хорошо подготовлено обращение. Если есть описание сценария, технологический журнал, информация об окружении – работа начинается сразу. Если нет, значительная часть времени уходит на уточнения.
Мы регулярно это видим. В задачах по производительности наличие корректных замеров «до и после» позволяет быстро локализовать проблему. В критических инцидентах подробные данные помогают сократить время диагностики.
РКЛ дает бизнесу управляемость
Если смотреть на сложившуюся практику, РКЛ – это не просто качественная поддержка, а фактор, напрямую влияющий на управляемость бизнеса. Когда возникает проблема, компания понимает, какой это уровень критичности, как быстро будет реакция и кто будет этим заниматься. В результате снижается время простоя и появляется возможность работать с проблемами системно.
Именно поэтому для крупных систем РКЛ становится частью базовой инфраструктуры и необходимым элементом устойчивой работы бизнеса.











