

Работа с данными в 1С ориентирована на объектный подход и реализована при помощи принципов объектно ориентированного программирования. Для ссылочных типов данных используются объекты, а для значимых типов данных используются наборы записей. Все операции изменения данных выполняются при помощи этих объектов.
Ссылка = Справочник.Номенлатура.НайтиПоКоду("1234");
Объект = Ссылка.ПолучитьОбъект();
Набор = РегистрСведений.КурсыВалют.СоздатьНаборЗаписей();
Одновременно с этим, в качестве хранилища данных 1С опирается на использование реляционных баз данных, которые реализуют иной подход, а именно оперируют наборами данных. В литературе западных авторов, например Itzik Ben-Gan, эти два образа мышления противопоставляются как "iterative thinking" (итеративное мышление) и "thinking in sets" (мышление наборами). Принципиальная разница заключается в том, что 1C оперирует объектами, входящими в наборы, а SQL оперирует наборами объектов как единым целым.
В конечном итоге это порождает так называемую проблему объектно-реляционного рассогласования интерфейсов (не нашёл лучшего перевода для object-relational impedance mismatch). В ООП её принято решать при помощи технологии объектно-реляционного преобразования (object-relational mapping - ORM). Часто реализация ORM API налагает свои требования и ограничения по работе с данными. Набор этих ограничений и особенностей использования API зависит от целей и задач, преследуемых разработчиками, но, как правило, тех или иных потерь функциональности при работе с РСУБД не избежать.
Реализация ORM 1С имеет существенные ограничения. В первую очередь это касается использования табличных операторов, а во вторую — возможностей определения и использования различных стратегий блокирования ресурсов (записей таблиц). Многим компаниям эти ограничения кажутся неприемлемыми и они не стесняются работать с СУБД напрямую. Если несколько лет назад это казалось чем-то из ряда вон выходящим, то в последнее время я наблюдаю повышенный интерес к этой теме. Похоже, что это становится трендом.
Табличные операции (в отличие от построчных).
Для выполнения табличных операций в 1С имеется только одна возможность — наборы записей. Для ссылочных данных эта возможность недоступна. При этом наборы записей ограничены своим отбором, за рамки которого выйти нельзя. Например, если мы хотим изменить данные регистра сведений подчинённого регистратору, то мы просто обязаны сделать это для каждого документа по отдельности, задав значение свойства отбора "Регистратор". Кроме этого, обновление (update) значений записей набора реализовано таким образом, что сначала 1С выполняет удаление (delete) записей по заданному отбору, а затем делает вставку (insert). Таким образом, если нам нужно изменить только несколько записей в наборе, то необходимо будет выполнить операции удаления и вставки для остальных записей набора в любом случае.
Разумеется такая работа с данными избыточна. Поэтому в некоторых особо важных с точки зрения 1С случаях платформа работает с таблицами как с единым набором данных. Например это происходит при обновлении номера сообщения в таблицах регистрации изменений или при пересчёте итогов.
В моей практике табличные операции в основном были необходимы в следующих случаях:
- свёртка или архивирование данных за прошлые периоды;
- массовая замена ссылок или значений (исправление или пересчёт данных);
- нестандартный пересчёт итогов;
- перенос данных из одной базы в другую;
- сверка документов двух баз данных.
На Инфостарте есть достаточно много статей по этим темам. Я не хочу повторяться. Могу лишь только сказать, что в некоторых случаях средствами 1С некоторые задачи было просто невозможно выполнить (от слова "совсем"). В остальных случаях это было неприемлемо для бизнеса с точки зрения времени выполнения. Не редко при работе с СУБД напрямую удавалось получать прирост производительности в десятки раз при этом часто без остановки работы пользователей в рабочей базе. То, что раньше выполнялось часами, начинало выполняться за считанные минуты.
В последнее время в сети, на YouTube например, можно встретить выступления на тему "Твой ORM обманывает тебя" (your ORM is lying you) или "Почему ORM это анти-паттерн" (why ORM is anti-pattern). Я хочу сказать, что для каждой задачи — свой инструмент. Для ввода данных и оперативной работы пользователей технология ORM вполне пригодна, но для интенсивных вычислений и обработки данных нет.
Стратегии блокирования.
Реализация ORM 1С диктует свою стратегию блокирования. Текущим стандартом является режим управляемых блокировок, что на уровне MS SQL Server означает изменение поведения, принятого по умолчанию, уровня изоляции транзакции READ COMMITTED на READ COMMITTED SNAPSHOT или "версионник". По сути для управления блокировками платформа 1С предлагает использовать только объект "БлокировкаДанных".
Другими словами из всего многообразия вариантов блокировок, которые есть в MS SQL Server было оставлено всего две. Одна на чтение — READ COMMITTED SNAPSHOT, а вторая для обновления данных (UPDLOCK), которая соответствует уровню изоляции REPEATABLE READ.
MS SQL Server даёт возможность определять стратегию блокирования записей на уровне таблицы при помощи так называемых табличных подсказок (hints). Эти возможности покрывают все сценарии, которые только могут прийти в голову.
Я уже писал о таком хинте, как ROWLOCK, в своей статье на Инфостарт "T-SQL + 1С: как правильно удалять очень много записей".
Сегодня я расскажу о хинте READPAST.
Изначально этот хинт был нужен для того, чтобы на базе таблиц можно было организовать работу с очередями произвольного доступа. Работает этот хинт так, что когда мы выполняем операцию чтения, обновления или удаления, используя READPAST, мы пропускаем все заблокированные записи. Их как-будто бы нет для нас. При этом наша транзакция не блокируется другими транзакциями.
Рассмотрим пример: допустим нам необходимо пересчитать и изменить значения какого-нибудь реквизита во всех документах. Пусть это будет его статус оплаты, например. При этом пользователи интенсивно работают с документами и периодически блокируют документы. Наша задача обновить те документы, которые доступны в данный момент времени, без ожидания на блокировках. Нам не принципиально обновить статус прямо сейчас, мы можем запустить обработку несколько позже ещё раз. При этом, избегая блокировок ожидания, мы всё-таки делаем полезное дело, обновляя оперативную информацию, и в какой-то степени экономим ресурсы СУБД по управлению блокировками.
Демонстрационная таблица "docs" состоит из трёх колонок "id" (идентификатор документа), "sum" (сумма документа) и "status" (0 — ждём оплату, 1 — оплачено).
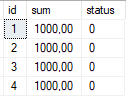

Создадим новый запрос в SQL Server Management Studio, который будет пользователем, который меняет сумму документа c id = 1. Обратите внимание, что транзакцию я начинаю явно, но не завершаю её. Мы завершим её потом вручную.
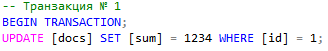
Теперь в новом окне Management Studio создадим второй запрос, в котором попробуем обновить статус документов с id > 0.

Выполнение этого запроса "зависнет", ожидая завершения транзакции № 1. Таймаут установлен на 10 секунд. Посмотрим в каком состоянии находятся данные в текущий момент времени:

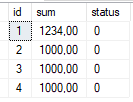
Как мы видим транзакиця № 1 обновила сумму документа с id = 1, но статус этого документа не был обновлён. Более того статус ни одного документа не был обновлён, так как транзакция № 2 "зависла" на первой строке. Если подождать истечения 10 секунд в окне транзакции № 2, то в результате мы увидим ошибку.

Вернёмся в первое окно и откатим транзакцию № 1, выполнив в этом окне следующую инструкцию.
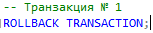
Теперь используем хинт READPAST.
Снова выполним запрос транзакции № 1, не завершая транзакцию.
Перейдём в окно транзакции № 2, но перед выполнением запроса добавим хинт READPAST.

Выполним этот код и обнаружим, что команда выполнилась без "зависания". Проверим результат работы.
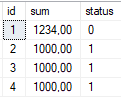
Все значения статуса обновлены, кроме записи, которая до сих пор заблокирована транзакцией № 1.
Наша задача выполнена =)
Это был очень простой пример. Однако мне вспоминается такая задача: менеджеры по продажам интенсивно оформляют заказы с обязательным резервированием товара на складах компании. Постоянные блокировки, вылеты по таймауту, ну и конечно же если весь документ не провёлся, то по заказу вообще ничего не зарезервировалось — нужно начинать всё сначала. Жалобы менеджеров на программистов, куча потерянного времени самих менеджеров на решение вопросов блокировок между собой в частном порядке, возможно упущенные продажи и даже клиенты.
Проблему было решено решить путём построчного резервирования при помощи наборов записей 1С — каждая запись табличной части заказа резервировалась в цикле по отдельности. Допускалось частичное резервирование. Количество фактически зарезервированного товара визуально отображалось в документе. Менеджер мог через какое-то время вернуться к заказу и повторить попытку зарезервировать товар по тем строкам, по которым это не удалось сделать сразу. Это конечно же не исключало ожидания на блокировках, но жизнь стала лучше. Хотя, честно говоря, не намного.
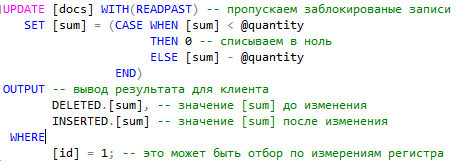
Эту проблему можно решить, используя хинт READPAST. При этом одним запросом мы можем обновить записи регистра, выполнить контроль отрицательных остатков и, если остатка не хватает, то зарезервировать товар под ноль, и всё так же одним запросом вернуть результат его работы. Для этого нужно использовать свою какую-нибудь таблицу для хранения оперативных остатков и резервов по товарам, но я думаю, что можно "прикрутиться" и к таблице итогов регистра. Для хранения оперативных итогов там есть запись с периодом равным "5999-11-01 00:00:00". Предлагаю для самостоятельного изучения следующий запрос:
Написание запросов SQL для 1С это достаточно сложная работа. Чтобы облегчить этот труд я занимаюсь разработкой инструмента, который решает большинство вопросов, возникающих при этом:
- получение метаданных 1С и их сопоставление с именами SQL;
- получение метаданных SQL по типам данных полей таблиц и их индексам;
- создание и редактирование запроса SQL в терминах 1C визуальными средствами (дизайнер запросов);
- генерация SQL кода для выполнения по результатам работы дизайнера запросов.
Рабочее название проекта 1C#. Адрес проекта на GitHub: https://github.com/zhichkin/Z
Мне будет очень приятно, если кто-то заинтересуется проектом и составит мне компанию =)
Вступайте в нашу телеграмм-группу Инфостарт