Здравствуйте! Речь пойдет в основном про PostgreSQL – я являюсь одним из ведущих экспертов в стране по эксплуатации 1С на PostgreSQL. Поэтому то, что я расскажу, взято не из книжек, а из практики реальной эксплуатации систем от одного до нескольких тысяч пользователей на базу.
В названии доклада у меня немного стилизованная поговорка: «Держи данные в тепле, транзакции в холоде, а VACUUM в голоде». И мы с вами пойдем по этим трем этапам, чтобы навести порядок в базе.
Чтобы база работала быстро, в ней нужен порядок
Все, конечно, знают, что 80% проблем в 1С – это программисты, они пишут неправильный код. Но остальные 20% – это все равно базы и железо.

Хотя все – и программисты, и пользователи, и даже системные администраторы, у которых аллергия на 1С, хотят, чтобы база работала очень быстро - в бардаке скорости не бывает.
Представьте ячеистый склад. Изначально туда, в пустое помещение склада, завезли ячейки, пронумеровали.
Но потом – кладовщики, которые заносят товар (наши INSERT и UPDATE) туда кладут, как попало – куда хотят, туда закинули. А кладовщики, которые хотят взять товар – наши SELECT, надеясь, что склад ячеистый (а он по факту не ячеистый – там бардак полнейший), долго мучаются, ищут, выносят целыми стеллажами ваш склад на улицу, на солнечный свет, там его разбирают, находят наконец-то нужное, это нужное отдают вам, заносят обратно.
И такой бардак продолжается очень долго.
В отличие от MS SQL, PostgreSQL – это версионная база данных. Там никто изначально не заботится о том, чтобы данные лежали в каком-то порядке. Они лежат так, как их туда положили.
В MS SQL у нас все данные лежат согласно кластеризованному индексу – там порядка чуть больше.
Я в докладе постараюсь рассказать, как ухаживать за данными 1С в различных СУБД, чтобы в итоге все работало быстро. Основными базами данных для 1С на данный момент являются MS SQL и PostgreSQL, поэтому я буду делать ссылки на обе базы данных. И если с MS SQL почти все уже научились дружить, то PostgreSQL еще побаиваются, поэтому упор будет сделан именно на работу 1С с PostgreSQL, при этом давая сравнение с MS SQL.
Стандартные операции для наведения порядка в базе

Начнем с наведения этого порядка хотя бы чуть-чуть.
Одним из главных залогов здоровья базы является знание планировщика запросов о том, что, где и как лежит во вверенной ему базе. В MS SQL за порядок отвечает ребилдиндекс, а за знание «что, где и как» – обновление статистик. Все знают эти процедуры в MS SQL:
-
INDEX REBUILD;
-
UPDATE STATISTICS.
Они впитаны с молоком матери в каждого 1С-ника, в каждого админа, у которого нет аллергии на 1С и на 1С-ников. Достаточно запускать их каждую ночь, и будет почти счастье. Про «почти» – чуть позже.
Что же в PostgreSQL? PostgreSQL – версионная база данных. Это значит, что при каждом перепроведении прошлого периода в 1С база засоряется старыми версиями. Там нужно периодически наводить порядок.
Чтобы не «насиловать мозг» админам, не заставлять их писать какие-то скрипты, в PostgreSQL давным-давно есть специальный служебный «пылесос», который как раз «вакуумит» таблицу – называется AutoVacuum. На заре использования PostgreSQL в мире 1С был прямо тренд – отключите AutoVacuum, и будет счастье. И почти все админы так и делали и счастливо наблюдали, как наконец-то их железки ничего не делают, и вроде бы даже кажется, что база заработала побыстрее. Это происходило примерно две недели, потом база вставала полностью «колом» – все железо вставало в топ нагрузки, и вообще ничего не помогало. Вывод: «PostgreSQL не подходит, переходим на MS SQL, и там счастье, потому что там делать почти ничего не нужно». Все мольбы разработчиков PostgreSQL включить AutoVacuum оставались неуслышанными, админы считали себя умнее документации: «Мы лучше знаем. Раз я отключил, и железу помогло – значит, это хорошо». Только недавно до всех начало доходить, что, если ты заходишь на сервер, а он ничего не делает, у тебя беда. А не наоборот.
Еще в PostgreSQL есть AutoAnalyze (если кто не знает, AutoAnalyze в PostgreSQL – это апдейт статистик). Его аналог есть и в MS SQL. Называется AUTO_UPDATE_STATISTICS. На каждой базе автоапдейт статистик (параметр AUTO_UPDATE_STATISTICS) по умолчанию стоит включенным, можно еще ставить асинхронный апдейт статистик AUTO_UPDATE_STATISTICS_ASYNC. Но если вы помните, в первый день Инфостарта был доклад от ребят, которые раскопали, что автоапдейт статистик на MS SQL им заблокировал всю базу.
К сожалению, на MS SQL AUTO_UPDATE_STATISTICS можно только отключить. А вот на PostgreSQL это можно «научиться готовить». Как это готовить – сейчас мы с вами немного разберем.
Держи VACUUM в голоде. Настройка AutoVacuum в PostgreSQL

Первое дело – VACUUM надо держать в голоде.
Что значит «в голоде»?
Он должен быть всегда готов начинать обрабатывать ваши данные, но, желательно, чтобы он не делал этого постоянно – его надо кормить маленькими порциями.

Как это сделать? В PostgreSQL для этого есть куча настроек. СУБД PostgreSQL вообще построена таким образом, что там нет «черных коробок». Все, что делает система, вы можете настроить – поднастроить, перенастроить. Это, с одной стороны, плюс, с другой – огромный минус. Понастраивают такого, что там вообще потом ничего не шевелится.
Как настроить AutoVacuum хорошо?
autovacuum = on
Первым делом, как бы ни казалось это смешно, не забудьте раскомментировать эту строчку (убрать впереди знак решетки «#»). Потому что очень много ко мне прилетает конфигов – все включено, но ничего не работает. Спрашиваю: «AutoVacuum включен?» – «Да-да-да, включен». И первую же строчку смотрю – AutoVacuum включен, но закомментирован. Не надо так делать, раскомментируйте. Это – раз.
autovacuum_max_workers
Второе – сколько фоновых процессов будет вакуумить («пылесосить» вашу базу от “мёртвых” записей)? Причем, надо помнить, что пылесосятся не только таблицы, но и индексы. Индекс в PostgreSQL – это совершенно отдельный файл.
Для PostgreSQL база 1С – это ненормальная база данных. Почему? Потому что даже элементарная БП3.0 содержит почти 40 тысяч файликов. Даже пустая, просто демка. Она содержит около 6 тысяч таблиц, и на каждую таблицу приходится еще примерно по 3-5 индексов.
Предположим, вы задаете количество фоновых процессов autovacuum_max_workers равным трем. Соответственно, этим трем ребятам нужно обработать 40 тысяч файлов. Теперь представьте, с какой скоростью они их будут обрабатывать. Даже если они просто заглянут в каждый файл, проанализируют, и у каждого на это уйдет хотя бы секунда, вам понадобится 13 с лишним тысяч секунд. Если представить, что база – это помещение с 40 тысячью комнатами. И даже если ни в одной комнате нет ни единой соринки, а надо пройтись по ним, заглянуть: «А, чисто» и закрыть дверь. И так втроем им надо обойти 40 тысяч комнат. Они будут обходить три с лишним часа.
Но, с другой стороны, если мы в базу запустим кучу процессов автовакуума (поставим количество фоновых процессов равным 300) – вы работать не сможете. Поэтому хорошая практика настройки AutoVacuum – это устанавливать количество равным половине всех ядер сервера СУБД.
Бояться не надо. Не будет у вас постоянно половина занята. Дальше все расскажу. Но в качестве значения autovacuum_max_workers нужно указывать примерно половину имеющегося количества ядер.
Что в PostgreSQL плохо и, наверное, когда-то исправят?
То, что невозможно настроить отдельно количество воркеров на AutoVacuum и отдельно количество воркеров на AutoAnalyze. Эти процессы нельзя разделить. Один и тот же процесс занимается и «пылесосом», и тут же, когда пропылесосил, еще и смотрит: «Что там в комнате осталось?» – статистику собрал.
Аргументы разработчиков PostgreSQL: «Зачем обходить одну и ту же таблицу двумя процессами, лучше обойду одним».
Аргументы эксплуататоров БД: «Дайте возможность гибко настроить процессы AutoVacuum и AutoAnalyze. Например, мне нужно часто обновлять статистику, потому что я постоянно добавляю записи в таблицу. Я из нее ничего не удаляю, ничего не обновляю – не надо мне ее пылесосить».
Но пока такой возможности настроить фоновые процессы нет, довольствуемся тем, что есть, и делаем запуск по крону скрипта с analyze необходимых таблиц.
Кстати говоря, на больших инсталляциях MS SQL тоже похожая ситуация, так же отдельно стоит регламент по обновлению статистики определённых таблиц БД - каждый час или раз в несколько часов.
autovacuum_vacuum_cost_limit
Но просто так взять и увеличить количество воркеров – не даст никакого эффекта. Почему? Потому что PostgreSQL считает суммарную стоимость работы каждого воркера – autovacuum_vacuum_cost_limit (по умолчанию равна 400). Например, он прочитал страницу – это стоит один балл. Он удалил запись с этой странички, это стоит 5 баллов. И эта стоимость указана в настройках.
autovacuum_vacuum_cost_delay
Когда ВСЕ воркеры наберут в сумме своей работы 400 баллов, они встанут в паузу, которая указана в настройке autovacuum_vacuum_cost_delay. Они все остановятся, подождут 20 миллисекунд и опять начнут дальше убираться. Зачем это сделано? Это сделано для того, чтобы система «продышалась».
Воркеров по умолчанию – 3. Соответственно, если мы увеличиваем количество воркеров autovacuum_max_workers в 2 раза, то нам нужно увеличить и стоимость autovacuum_vacuum_cost_limit в два раза. Это многие забывают и, увеличивая количество воркеров, говорят: «Ничего не помогает». Ничего и не поможет. Вы просто уменьшили порцию каждого воркера – скорость обработки не увеличится.
autovacuum_vacuum_scale_factor
Поехали дальше. Я уже сказал, что 1С – это “ненормальная” база данных среди баз данных вообще, поэтому для нее нужны “ненормальные” настройки агрессивности AutoVacuum. По умолчанию, настройка autovacuum_vacuum_scale_factor, при которой AutoVacuum сработает на таблице, равна 10% (т.е. с последнего AutoVacuum в этой таблице должно поменяться 10% строк).
Надо ее поменять хотя бы до одного процента. Почему? Мы все храним в 1С данные за 15 лет, а работаем в последнем квартале. Но чтобы статистика обновилась, и мы могли знать точное распределение данных за этот квартал, нам нужно в 15-летней базе накопить изменения в 10% – это надо прямо долго поработать. Примерно 4 квартала. И через год AutoVacuum туда при настройке по умолчанию заглянет. Где грань агрессивности? Грань агрессивности на грани производительности ваших дисков. Можете просто побаловаться, поменять эту цифру – все меняется «на лету», никакой перезагрузки не надо, надо просто перечитать настройки, и PostgreSQL будет уже относиться к этому делу по-другому. Если диски быстрые (SSD) – такой настройки, чтобы успевало пересчитаться, хватает. Это всего 1% данных, это нормально для фоновой обработки.
autovacuum_analyze_scale_factor
А autovacuum_analyze_scale_factor по умолчанию вообще равен 20%.
То есть, PostgreSQL по умолчанию пропылесосит данные только когда в таблице поменяется 10%, а статистику по умолчанию посчитает только после изменения 20%.
Потому что в нормальных приложениях и в нормальных базах данных люди практически всегда пользуются всей таблицей – там считается, что архивные данные, которые никому не нужны, должны лежать в соседнем месте. В 1С такого нет, у нас скажешь бухгалтерам: «Я сейчас удалю отсюда данные старше, чем 3 года» – будет паника вплоть до инфаркта: «Как же так, как я дальше буду жить?» Поэтому, куда деваться – будем настраивать.
Как настраивать? Параметр autovacuum_analyze_scale_factor ужесточаем в 40 раз, до 0.5%. Полпроцента поменялось – анализируй, собирай статистику. Для нас это важно.
Тут полное перекликание с MS SQL. На ИТС есть рекомендации по обновлению статистики в MS SQL – там написано, что апдейт статистики нужно проводить с параметром FULLSCAN (сканировать всю таблицу базы данных независимо от их изменения).
При этом автоапдейт статистики проводит инкрементальный апдейт. Этого недостаточно. Причем, это тот самый автоапдейт, который нужно отключить при возникновении проблем – вообще просто так не отключайте, это хорошая штука, просто иногда возникают проблемы, и надо знать, как их анализировать, и тогда отключить. Почти то же самое, в MS SQL делает exec sp_updatestats – на всю базу либо на таблицу, насильно проводимый (без автоапдейта). Он тоже инкрементальный, его тоже недостаточно.
Настроили. Как теперь узнать, что мы настроили правильно?
Мониторинг процессов автовакуума

Узнать достаточно просто – делаем единственный запрос. Он вам выдаст количество процессов автовакуума, которые работают на момент этого запроса.
И все гениальное просто – результат этого запроса в среднем за рабочее время должен быть меньше вашей настройки максимального количества воркеров. Мы выполнили первое задание нашей поговорки – вакуум сидит в голоде. Вы для него настроили 6 воркеров, а в среднем у вас их, например, 5.
По-хорошему, работа воркеров должна занимать 1-2 процента рабочего времени базы данных. Не больше. Иначе у вас база в цейтноте стоит, вы не угадали с настройками. Вы либо переборщили с резкостью настроек, либо недостаточно выделили воркеров – система вакуума не успевает обработать все ваши данные.
Понятно, что это – не единственный мониторинг, но это – мониторинг самого верхнего уровня, который можно завязать на любую систему информирования (не обязательно на Zabbix, можно и на почту).
Сделайте себе алерт, пусть вам прилетит об этом уведомление, чтобы вы проверили, что происходит в базе.
Отдельно на больших базах необходимо на ночью запускать скрипт вакуум+аналайз+заморозка, например вот такой
vacuumdb -h 127.0.0.1 -p 5432 -U postgres -a -z -F -j 4
Этот скрипт провакуумит, проанализирует и заморозит всё во всех базах на сервере в 4 потока.
Перестроение индексов в PostgreSQL и MS SQL

Едем дальше. Помимо автовакуума, вакуума и аналайза, есть еще такая проблема – она есть и в MS SQL и в PostgreSQL. Проблема называется REINDEX в PostgreSQL, либо INDEX REORGANIZE (бывший DBCC INDEXDEFRAG) в MS SQL.
В MS SQL эта операция не справляется, когда фрагментация индекса больше 30%. Проводить ее бесполезно – порядок не наведет. Фрагментация так и останется.
То же самое в PostgreSQL. Команда REINDEX очень часто не справляется с индексами типа btree, и именно нам (всем 1С-никам) тут не повезло, поскольку в 1С индексы только btree. Именно с нашими индексами REINDEX от PostgreSQL не всегда справляется.
Что такое «не справляется?» Индекс «пухнет». Несмотря на то, что мы все настроили, автовакуум есть (индексы от пустых страничек чистятся). Но индекс «пухнет». Казалось бы, ну и пусть «пухнет».
А вот нет. Опять же, из-за специфичной работы 1С записей в индексах базы 1С примерно в два раза больше, чем самих данных в базе 1С. Если вы разложите вашу базу 13 Тб, вы удивитесь, потому что там будет 8-9 Тб индексов, скорее всего. И только 4Тб реальных данных. Соответственно, по 1С-никам это бьет прямо молотом. Что делать?
Олег Бартунов рассказывал про PostgreSQL 12, в котором появилась команда REINDEX INDEX CONCURRENTLY
Что она делает? Она для всех ленивых одной строкой выполняет три строчки кода:
CREATE INDEX CONCURRENTLY new_index ON …;
DROP INDEX CONCURRENTLY old_index;
ALTER INDEX new_index RENAME TO old_index;
Можно не ждать 12-го PostgreSQL, а взять и сделать самим по аналогии. Создаем индекс с параметром CONCURRENTLY (без блокировки) точно такой же индекс, как у вас есть – только называем его по-новому. Это на базе данных надо делать (придется создавать индекс, нарушая лицензионное соглашение 1С). Затем уничтожаем индекс, который у нас был от 1С, и переименовываем вновь созданный индекс, давая ему имя как было раньше.
Это аналог INDEX REBUILD с ONLINE = ON в MS SQL.
В Postgres 12 все это будет делаться одной командой.
Но опять же, вспоминаем – у нас с вами на элементарной базе около 25 тысяч индексов. Успеешь состариться, пока проанализируешь их хотя бы один раз – что там выросло, а что нет. Есть специальная утилита – pg_repack. Она за вас все пройдет, найдет, проанализирует и сделает в том числе и эту операцию. Утилита pg_repack – это замена операции VACUUM FULL, которая является блокирующей. Для 1С-ников - VACUUM FULL – то же самое, что реструктуризация таблиц. Наводит полный порядок, но работать в базе нельзя. А pg_repack – это почти реструктуризация версии 2.0. Рядом создастся табличка, туда аккуратно переедут данные, потом ваша старая таблица заблокируется, в новую таблицу переедет инкремент (то, что успело создастся с момента перепаковки), потом удалится старая таблица и будет переименована новая, чтобы уже с ней дальше работать. Офлайн все равно случится, но буквально на секунду, на две. Не больше.
Плюс – она наведет порядок в индексах. Именно пересоздав их, как написано выше.
Штука сложная, потому что ее придется собрать – ее нельзя через install поставить. Собирается буквально тремя командами.
yum install postgresql96-devel-9.6.11-1.1C.x86_64.rpm
yum install gcc make flex bison perl bzip2 zlib-devel libicu-devel patch openssl-devel readline-devel
cd pg_repack
PG_CONFIG=/usr/pgsql-9.6/bin/pg_config make
PG_CONFIG=/usr/pgsql-9.6/bin/pg_config make install
И потом на базе:
CREATE EXTENSION pg_repack;
Вообще определить нужно ли пересоздавать индекс в PostgreSQL крайне сложно, разработчики пока не дают какого-то надёжного инструмента.
К сожалению, нормальный анализ можно провести фактически только одним способом. С момента, как вы залили в PostgreSQL dt-ник, вы должны собирать ежедневно и выгружать размеры всех ваших элементов в БД. Всех таблиц и индексов. И так каждый день. И смотреть, что выросло неадекватно для Вашего профиля нагрузки (статистики за предыдущий месяц-два) это значит, что он начал «пухнуть».
Либо просто принять правило что, например все индексы более 1ГБ необходимо пересоздавать раз в неделю/месяц.
Pg_repack, как и все в PostgreSQL, имеет огромное количество параметров запуска, может перепаковать все таблицы, все базы на кластере, может конкретную таблицу. А может только индексы в этой таблице.
Крутая штука, почитайте, попробуйте.
Держи транзакции в холоде

Едем дальше. Мы все настроили – автовакуумы, репаки работают, все классно. Но, когда база большая (например, несколько ТБ), они не успеют, никто не успеет. Это нереально. Автовакуум будет там полгода ходить, наверное. Что делать? Надо замораживать (использовать параметр FREEZE)
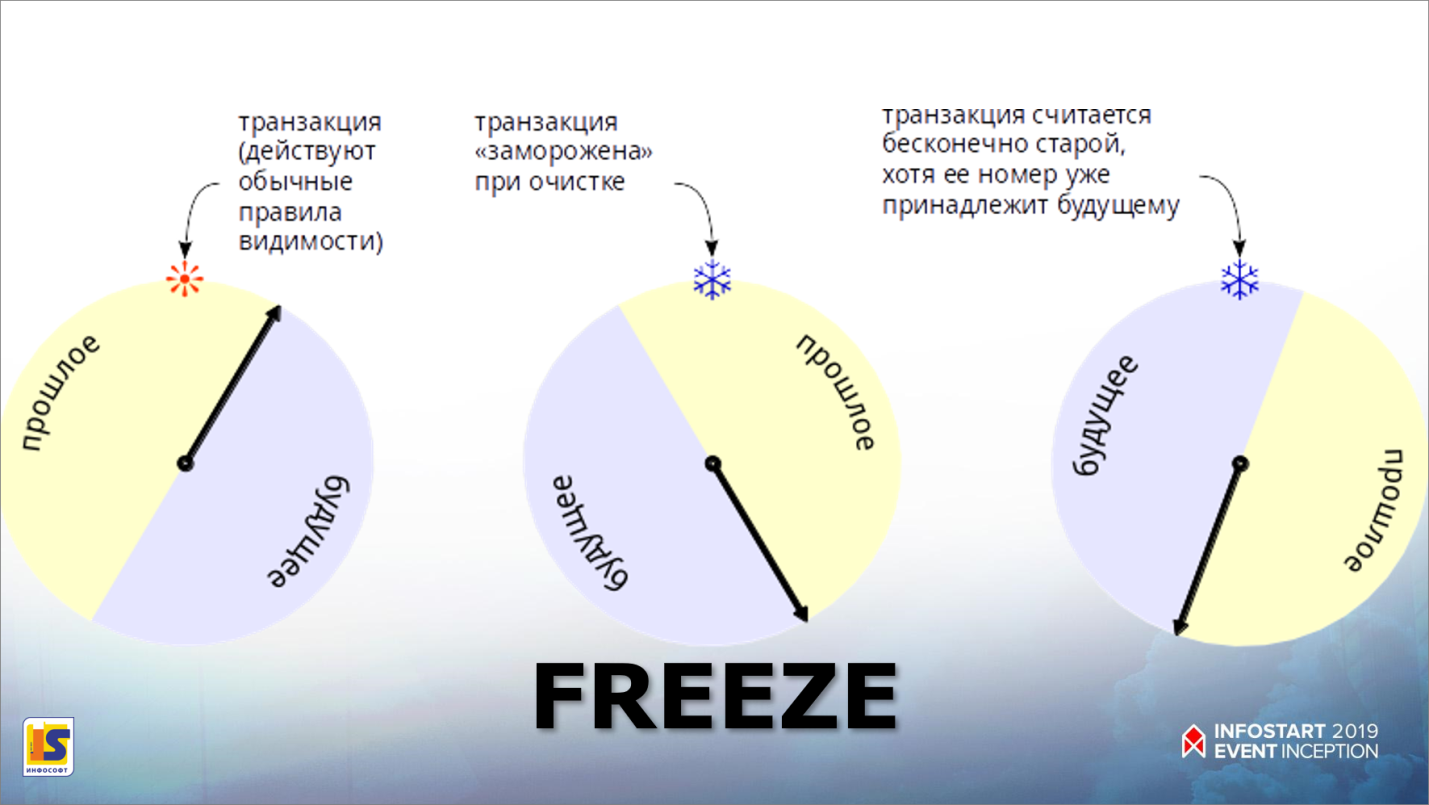
Вообще, команда обслуживания VACUUM FREEZE в PostgreSQL– очень сложная тема. Она ломает мозг, когда пытаешься прочитать, либо послушать – первые раз пять. Всем советую на хабре статьи Егора Рогова из команды PostgresPro. Статьи про «заморозку» надо читать раза три-четыре – только тогда начинаешь понимать, что это такое)))
Изначально заморозка была придумана вообще не для того, для чего мы сейчас будем ее использовать. А мы будем использовать ее побочный эффект. «Заморозка» была придумана из-за одной проблемы – поскольку PostgreSQL – версионник, он может отличать новую транзакцию от старой только по ее номеру. Больше ему не на что ориентироваться. Номеров транзакций на каждую таблицу в 32-битном счетчике PostgreSQL – 4 миллиарда. Это немного.
Для того чтобы решить эту проблему, счетчик транзакций в Postgres закольцевали так, что номеров стало по 2 миллиарда:
-
справа от текущей даты два миллиарда номеров транзакций в будущем;
-
и слева – два миллиарда номеров в прошлом.
Но может случиться так, что транзакция была в прошлом, счетчик переключился, и она вдруг оказалась в будущем. В общем, проблема есть, счетчик может кончиться. Проблема называется wrap_around. Когда счетчик кончится, база данных «встанет колом», скажет: «Не могу выделить новый номер, стоп-машина». Придумали замораживать. Что это значит? По всем страничкам ходит наш любимый вакуум (или автовакуум) и у каждой транзакции спрашивает:
– «Какой у тебя номер?»
– «100500»
– «А текущий номер в системе сейчас какой?»
–«500100500»
– «А какая настройка в PostgreSQL, что мне считать стариками?»
– «В PostgreSQL настройка – заморозить все, что старее текущей транзакции на 500 миллионов».
И вакуум ставит специальный бит «заморозка», после чего эта транзакция считается старее всех в системе (все замороженные транзакции считаются самыми старыми). Всё, счетчик пошел дальше.
В чем же побочный эффект? Побочный эффект начал проявляться с версии PostgreSQL 9.6. В PostgreSQL 9.6 придумали «Карту заморозки». Когда вакуум прошелся по транзакциям, нашел всех стариков, заморозил и так получилось, что заморожена вся страница данных целиком (все транзакции, расположенные на странице данных, заморожены), он в карте заморозки помечает – это страница заморожена. В чем побочный эффект? Вакуум не смотрит на замороженные страницы никогда. Это – раз.
Второе – как было раньше? Вакуум шел по таблице, прошел нашу террабайтную таблицу на 99%, приходит админ, говорит: «Нагрузка большая, убить все вакуумы». Затем базе становится совсем плохо, админ включает вакуум, и таблица опять начинает обрабатываться с начала. Так было раньше.
А теперь, даже если админ убил процесс вакуума на 99%, то при его включении будет обрабатываться всего один процент, и он его пройдет очень быстро.
И это все на PostgreSQL работает в фоне, вы об этом просто не знаете. На эту заморозку просто никто не обращает внимания. Она защищает вашу базу от того, чтобы она «колом» не встала. Но, возвращаясь к нашей любимой специфике 1С, что у нас данные за 15 лет, работаем мы с последним кварталом, а еще и постоянно жмем «Перепровести», и это – минимум месяц, а то и квартал, у нас появляется очень много работы для вакуума почти каждый день. Чтобы облегчить эту работу - запускайте FREEZE хотя бы раз в неделю/месяц на всей базе. Это – неблокирующая операция. Она заставит вакуум пройтись по всей вашей базе, заморозить тупо все таблицы, и все страницы в базе пометятся, как замороженные.
Следующий проход автовакуума будет просто мгновенным.
Таким образом, FREEZE как раз и поможет всем нашим фоновым процессам отрабатывать быстро. К сожалению, FREEZE – незаслуженно не узнанная функция, которой почти никто в 1С-ном мире не интересуется.
Держи данные в тепле

И на десерт. Мы все молодцы – все, что надо, заморозили. Теперь надо разогреть то, что не надо морозить – данные должны быть горячими.
Освобождаем кэш
В чем смысл? Смысл в том, что ночью у нас в базах происходит полная вакханалия. Ночью на MS SQL происходит ребилд индексов и апдейт статистик – это заставляет MS SQL поднимать в память данные, которые не факт что утром пригодятся вашим пользователям.
И когда наступает утро, и счастливые бухгалтера идут работать, нажимать кнопки в своей 1С, и на больших базах MS SQL вы увидите по загрузке железа просто ужасающую картину, которая будет сбивать вас с толку. Вы увидите 100% нагрузку на диски с базой данных при скорости чтения 10 Мб в секунду. При этом база лежит на СХД, которая в хорошую погоду выдает 2Гб в секунду. Вы начнете винить админов, что у них полка «умерла», будете долго ломать голову.
А знаете, что надо сделать?
DBCC DROPCLEANBUFFERS
Надо заставить MS SQL этой командой выгрузить из кэша все, что сейчас не нужно. А сейчас не нужно ничего, кроме активных транзакций.
Ситуация усугубляется с ростом оперативной памяти. Чем больше у вас оперативной памяти, тем больше вы туда за ночь зальете мусора. Тем дольше утром СУБД будет приходить в сознание, пытаясь лихорадочно найти, что ей в памяти не нужно. Потому что MS SQL так устроен – он на всякий случай оставляет там все, что может пригодиться, и высвобождает ровно столько мегабайт, сколько вам сейчас понадобились в кэше. Все же знают что сколько MS SQL не дай оперативной памяти - съест всё!
Ситуация плачевная. Что делать?
Первую команду я уже написал – DBCC DROPCLEANBUFFERS. Ее, по-хорошему, надо делать каждую ночь после всех ваших регламентов.
И еще одна команда DBCC FREEPROCCACHE – ее тоже уже почти все научились делать. Правда, рекомендация фирмы 1С – делать при возникновении проблем, но на всякий случай, делаем всегда. Ну и пусть делается. Подумаешь, утром чуть дольше поработает система, пока не накопит кэш.
Что касается PostgreSQL – там все чуть полегче, не нужно ничего высвобождать. Он работает с кэшем по-другому. Он высвободит все за вас, у него есть счетчик «сколько транзакций сейчас требуют данные, которые я в кэш поднял?». И если этот счетчик равен нулю, он скинет этот кэш, освободит за вас, вам делать ничего не надо. Этим управляет настройка checkpoint timeout. Она по умолчанию раз в пять минут делается. В PostgreSQL с этим ничего специально делать не надо.
Прогреваем данные
Ну что, мы из сауны вынесли всех, кто там перегрелся. Теперь туда надо занести то, что надо.
К сожалению, тут я вас расстрою. Вам придется написать нагрузочное тестирование. Или, хотя бы, сценарии работы ваших пользователей. Желательно, правда, с перепроведением чего-нибудь безопасного, что не страшно перепроводить. Вам придётся собрать всю информацию с пользователей – что они делают в 1С хотя бы первые три часа, когда приходят на работу. И, грубо говоря, в 6 утра начать это делать за них вчерашними данными – разогреть базу.
-
Если вы знаете, что вам нужно на уровне запросов SQL – напишите скрипт. Правда, это может превратиться в ад (чуть-чуть поменяли разработчики код в 1С – вам придется переписывать).
-
По-хорошему, приложение должно эмулировать ту нагрузку, которую вы собираетесь создавать. Например, у вас утром придут 100 пользователей, так вот и запустите 100 фоновых заданий, каждое из которых будет эмулировать действия пользователей, отчеты и документы, с которыми они работают.
Как это сделать? И тут к нам на помощь приходит фирма «1С». На сайте обновлений ERP уже полгода скромненько, в самом низу всех ссылок, лежит дистрибутив специальной демонстрационной базы ERP 2.4.7.151 со встроенным Тест-центром и сценарием типовой работы пользователя в ERP. За вас все написали и все сделали. Если у вас не ERP, хотя бы подсмотрите, что они там сделали и перенесите в свои базы.
Да, она потребует запуска тонких клиентов. А вы хотели все фоновыми решить? Это неправильно. У вас же будет проводить тонкий клиент – вы же будете получать формы, динамические списки – фоновым заданием вы это не прокачаете.
Конечно, этот сценарный тест создан не для разогрева. Он создан для тестирования. Или для нагрузочного тестирования – ко многим же клиенты приходят с вопросом: «На 500 пользователей ERP заработает или нет?» И тут им показываешь тест-центр, в котором можно протестировать демобазу ERP – настроить, сколько пользователей работает, и она сама распределит, сколько там кладовщиков, бухгалтеров, продавцов. Это – типовая нагрузка по мнению фирмы 1С. Не нравится – можете под себя что-то в коде или в настройках изменить.
В итоге, на прогретых ухоженных данных нам останется только написать верный функционально и оптимальный по производительности код 1С и наслаждаться своим произведением!)
****************
Данная статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT 2019.


Вступайте в нашу телеграмм-группу Инфостарт