Большинству разработчиков, кто вынужден работать в уже сформировавшемся ИТ-ландшафте, знакома проблема, что с каждым годом внедрять функциональные возможности становится все сложнее. Есть объем доработок, который вы внедрили в прошлом году: это произошло достаточно просто. В этом году чуть сложнее, а в следующем году вы поймете, что какой-то объем доработок просто не сможете осилить.
Разберемся, почему это происходит, как с этим жить, и почему с этим придется столкнуться любой компании, которая «доживет» до обретения своего зрелого ландшафта.
Концепция «Крест ИТ»
Хорошая модель, которая описывает концепцию этой идеи, называется «Крест ИТ». Она базируется на двух основных фактах:
- Бюджет, выделяемый на ИТ, либо не растет, либо растет очень медленно.
- Затраты на уже реализованные решения растут всегда, и растут достаточно быстро.

Из этой простой установки рождается печальный факт – рано или поздно любой бюджет, выделяемый на ИТ, будет «съеден» затратами на решения, которые были реализованы ранее.
Эта концепция хорошо описывается простым графиком. Посмотрите на две области: слева область с довольным человечком, справа – с грустным.
- Область со смайликом описывает ресурс, который остается на реализацию новых интересных решений, полезных для бизнеса.
- Правее человечек не такой веселый, показывает, как затраты на поддержку «съедают» весь выделенный на ИТ бюджет и продолжают расти, получая свое в виде постоянных аварий, инцидентов и тому подобное.
Что мы можем сделать как разработчики, чтобы оставаться в левой части как можно дольше? В контексте этой модели есть два глобальных решения:
- Что-то сделать с бюджетом, чтобы он рос ускоренно. Наверное, иногда это получается, но крайне редко.
- Как-то повлиять на скорость роста затрат на поддержку, чтобы красный график был как можно более пологим.
Что влияет на угол наклона графика? Очевидно, что факторов будет много, и в разных компаниях эти факторы, скорее всего, будут разными. И для них при всей несхожести будет соблюдаться принцип Парето. Это значит, что два-четыре основных фактора будут генерировать максимальный, либо большую долю объема затрат. В нашем конкретном случае найти если не факторы, то причины и место обитания этих факторов, было достаточно просто.
Тяжелые системы как основа ИТ-ландшафта
Наш ИТ-ландшафт построен вокруг одной гигантской информационной системы. Рядом с ней стоят несколько тоже больших систем, но не таких тяжелых. И есть много совсем микроскопических – с точки зрения наших главных систем – приложений, которые разбросаны по всему ИТ-ландшафту и особой роли не играют.

Из анализа объема операций и долей задач, которые реализуются в наших основных системах, без всякой калькуляции можно сделать вывод, что почти все затраты приходятся на наш ТОП-3 систем. На первую – с большим отрывом.
Отсюда возникает предположение: если мы каким-то образом сможем сделать эти системы меньше, то кардинально уменьшим затраты на поддержку и освободим ресурсы для разработки новых систем и решений, полезных для бизнеса.
Самым очевидным и одновременно сложным решением было бы придумать что-то, чтобы в один прекрасный момент сделать из нескольких очень крупных систем много-много маленьких, которые были бы сконцентрированы на какой-то определенной функции, использовали подходящий стек технологий и взаимодействовали друг с другом по какой-то корпоративной шине.
К сожалению, если и было время, когда это можно было сделать – оно упущено много лет назад. Слоник уже вырос, съесть его за раз не получилось и не получится. Придется делать это за несколько подходов.
Как появляются монструозные системы
Прежде чем рассказывать «ужасы нашего городка», и как тяжело жить с большими системами, скажу, что у них есть определенные плюсы. Сам факт существования больших систем – в нашем случае это более 10 лет – говорит, что у таких систем есть какие-то плюсы, драйверы их постоянного роста:
- Есть как минимум несколько классов задач, которые в таких системах решаются лучше, чем в менее масштабных.
- Монолитные системы удобнее разрабатывать: пользователю проще сформулировать свою задачу и понять свое пожелание относительно уже существующих объектов, возможностей и интерфейса. То же касается разработчиков с аналитиками.
- Задача реализовать что-то новое связана с повышенными сложностями. А тут, когда вы разрабатываете в уже устоявшемся монолите, вся команда разработки освобождается от мук творчества. В монолите всегда есть один – максимум два – правильно работающих способа в отличие от разработки с нуля, где всегда куча вариантов, которые подходят, и сложно выбрать единственно правильный. А когда цель ясна, средства понятны – команде разработки комфортнее работать.
Вот так, путем реализации маленьких и больших задач изначально большие системы становятся гигантскими, а потом и монструозными.
Ключевые проблемы больших систем
На каждом новом этапе встречаются один-два-три фактора, которые катастрофически влияют на производительность, стоимость сопровождения, поддержки и разработки в этих системах.
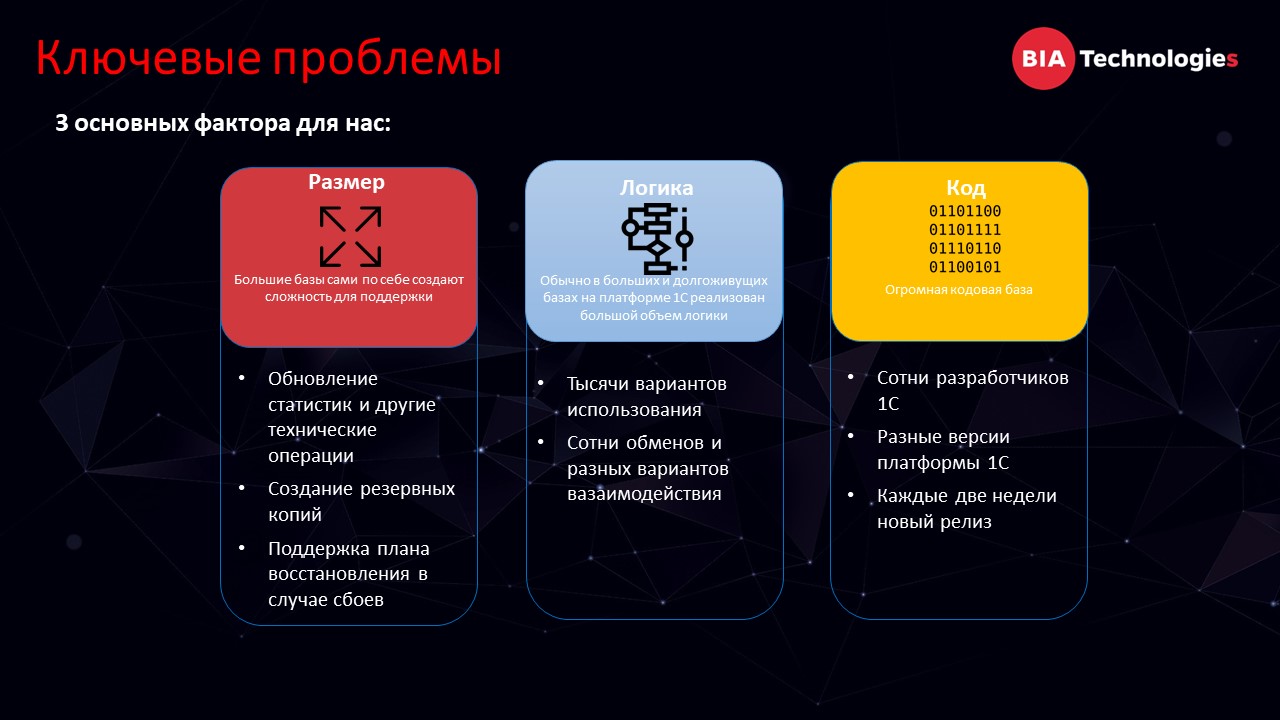
Я разделил факторы, оказывающие негативное влияние на систему, на три большие группы.
- Первая группа факторов – это растущие показатели. Это может быть объем данных, количество пользователей и операций. Начиная с какого-то момента каждый новый пункт роста обходится для компании все дороже.
- Вторая группа факторов – когнитивная сложность получившихся решений. Всегда наступает момент, когда количество реализованной функциональности превращается в такое качество, которое не позволяет дальше разрабатывать и проектировать решения так, чтобы получать прогнозируемый результат.
- Третий момент – то, что поддерживает и обеспечивает большую систему со сложной логикой – это кодовая база. То, как мы разрабатываем – тоже играет большую роль и составляет большую часть стоимости. Правильная работа с кодом позволяет как-то более-менее приемлемо работать в больших системах и даже как-то урезать эти системы.
Первая группа факторов: растущие показатели
Давайте перейдем к первой группе факторов. Эта группа факторов – самая сложная и самая простая.

Сложная, потому что если вы даже на короткий момент времени упустите контроль над ростом показателей или контроль над количеством функциональности, и база начнет расти слишком быстро, вы не сможете вовремя среагировать, – вы однажды столкнетесь с тем, что база будет просто не работоспособна. Надо жестко и постоянно контролировать эти факторы.
С другой стороны, методология работы с каждым из этих факторов более-менее ясна. Вы можете методом гугления найти решение для любых проблем, связанных с производительностью, объемом данных или для других задач.
Давайте пробежимся по способам решения для каждого из этих факторов.
- Первый фактор, о котором думаешь, когда говоришь о большой системе – это объем данных. Понятно, что с этими данными можно делать – есть механизмы, которые позволяют базу обрезать, получать уменьшенную копию этой базы, новую систему, в которой меньше данных. Но надо понимать, что такой подход и постоянная обрезка имеют пределы своей производительности. Потому что при активной доработке системы скорость наращивания объема данных растет, и вам для сохранения понятного объема придется обрезать базу раз за разом. То есть пределы работы с объемом данных все равно есть, и в какой-то момент вам придется принять это и научиться работать с большими данными – решать все эти вопросы с обеспечением производительности, отказоустойчивости и восстановлением после сбоев.
- Другое направление и фактор, который нельзя забывать – количество пользователей и те операции, которые они выполняют в системе. Начиная с какого-то момента некоторые пользователи могут создавать опасность для производительности и работоспособности системы, и надо понимать, каким образом работать с этими группами пользователей. И, по идее, желательно как-то от них избавляться. В нашем случае мы начали с достаточно наивных методов – развернуть копию базы данных для чтения и перевести туда всю работу этих пользователей. Постепенно перешли и на более хитрые механизмы формирования сложных витрин с большими данными, где пользователи спокойно работают и довольны качеством и актуальностью этих данных.
- И третий фактор, который характеризуется объемом – это тот объем функциональности, который вы реализовали в системе. Чем больше его становится, тем больше и быстрее растет база данных, тем больше становится пользователей. Этим тоже необходимо как-то управлять, бороться со слишком большой скоростью. В нашем конкретном случае мы стараемся контролировать доработки, которые реализуем, но идея как-то вынести большой кластер функциональности не получается. Тот момент, когда мы упустили, и все жизненно важные функции для системы зародились именно в ней, они так активно в ней и развиваются.
Объем функциональности рано или поздно приводит к другой сложности. Это когнитивные сложности.
Фактор второй: когнитивные сложности
В нашей системе ведется разработка больше 10 лет. За это время реализована большая функциональность: сотни и тысячи процессов так или иначе автоматизированы с помощью нашей большой системы. Эти процессы и варианты их использования, которые мы реализовали, сформировали целые комки, сложные для понимания и анализа, с которыми приходится работать.

Все это приводит к тому, что когда бизнес-заказчик приходит к нам с двумя внешне одинаковыми задачами, которые принесут ему приблизительно одинаковую пользу – одну мы сделаем легко, а другая во время разработки может привести к непрогнозируемому взрывному росту трудозатрат. Сложно объяснить бизнесу, почему в одном случае у нас все хорошо, а в другом – мы не смогли разработать экономически выгодный механизм.
И что с этим делать? Наверное, вариантов не так уж много. Если у нас достаточно сложная логика решения, нужно автоматизировать множество процессов – нам никуда не деться. Даже если мы разрежем базу и избавимся от больших систем, эта сложность никуда не денется.
Необходимо разработать «базу знаний», которая позволит нам быстро и качественно спроектировать новое решение. Вовремя увидеть, что запроектированное решение повлияет так или иначе на какие-то процессы, которые мы не хотим затронуть.
В нашем случае пришлось разработать целый аналитический фреймворк, который позволяет аккумулировать эти знания, поддерживать их в актуальном состоянии. Сейчас мы только в процессе сбора этих знаний. Не знаю, получится у нас это или нет. Но у меня есть определенная убежденность, что какой бы база ни была – в каждом конкретном случае она будет отличаться, как и методология сбора этих данных – основной частью и скелетом этой системы, скорее всего будет репозиторий юзкейсов, на которые уже будет навешиваться дополнительное описание.
Хочется надеяться, что мы сможем собрать базу знаний, и это позволит не просто разрабатывать новые решения или быстро разбираться с инцидентами. Есть понимание, что когда наступит час Х, и мы захотим вынести большой объем функциональности в кластер, во внешнюю систему, нам эта «база знаний» будет жизненно необходима. В противном случае безболезненно или хотя бы приемлемо болезненно вынести эту функциональность будет сложно.
Третий фактор: качество кодовой базы
И третий, самый важный фактор, который влияет на стоимость поддержки уже реализованных решений – качество кодовой базы.

На качество кодовой базы постоянно оказывается достаточно мощное влияние.
- В нашей системе одновременно работает множество разных команд разработчиков, у каждой свой подход, своя доменная модель, и самих разработчиков достаточно много. Даже при небольшой текучке мы постоянно сталкиваемся с такими проблемами, когда важный кусок кода разрабатывал один разработчик, перед уходом передал эту работу другому, а другой разработчик передает третьему.
- Специфика работы в монолите не позволяет правильно разделить доменные области. Очень сложно сказать, что эту часть разрабатывает одна группа разработчиков, вот эту – другая. Очень размыты границы между ответственностью команд. Есть большая куча объектов, которая разрабатывается одновременно несколькими разработчиками: это приводит к тому, что сложно разделить эти домены. Их границы размыты и малопонятны.
- Плюс ко всему у нас есть вопросы к историчности. Как я говорил, база работает больше 10 лет. Сначала она работала на платформе 8.1, затем – 8.2, затем – 8.3. Все эти артефакты так или иначе остаются, и нам приходится что-то с этим делать.
Как сделать так, что даже при большой кодовой базе и множестве факторов, которые влияют на качество разработки, как-то с этим управляться?
- Базовое решение – повысить общий уровень разработки. Обучение и адаптация, входной фильтр разработчиков. Наши разработчики понимают ряд вопросов лучше, чем в среднем по рынку, например: вопросы производительности, то, как работают индексы, как выполняются планы запросов, и как эти планы зависят от состояния статистик.
- Использование общих шаблонов и подходов, плюс код-ревью и автоматизация проверок позволят выровнять, нормализовать качество кода, сделать новые доработки и сделать приемлемым и понятным поддержание старых.
Про подход к проектированию новых решений
Остается еще один важный момент – то, как мы проектируем новые решения.
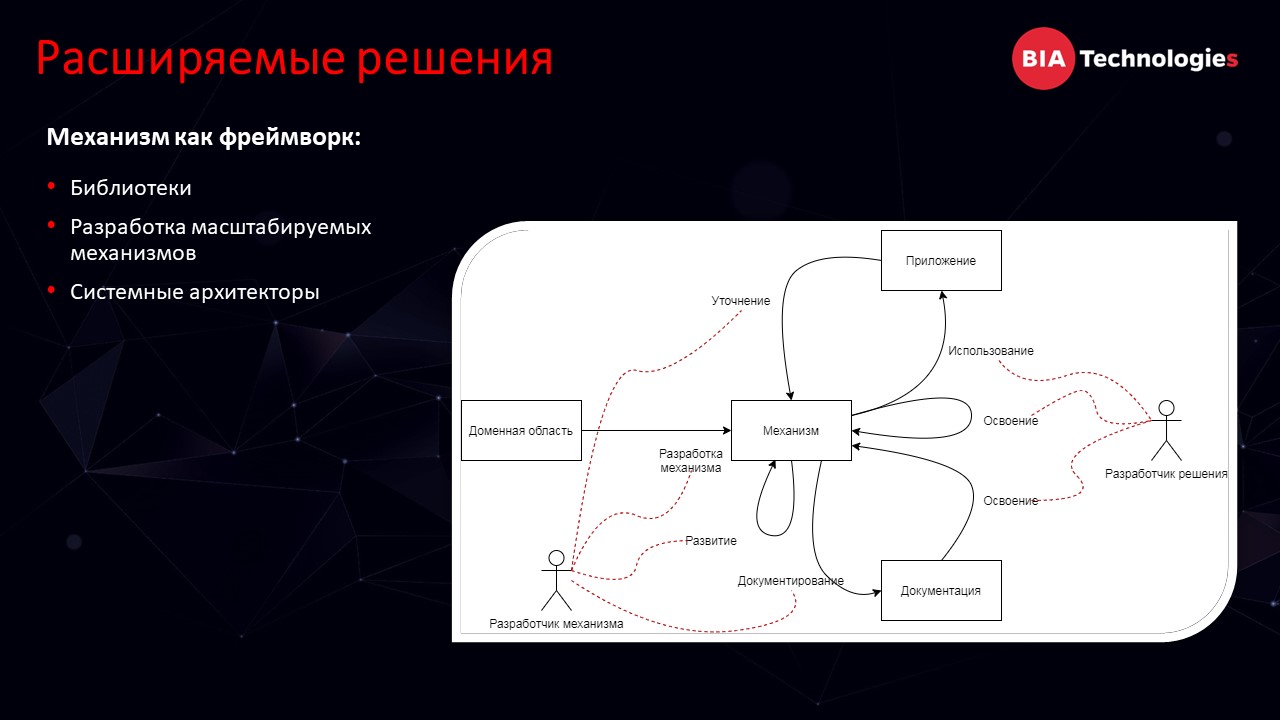
Правильный подход к задачам также является очень важным. Даже при неплохом уровне разработчиков все равно нужно хорошо погружаться в разработку некоторых задач.
Есть разовые задачи, которые, скорее всего, никогда не будут дорабатываться. В таких задачах имеет значение то, как быстро мы ее выполним, как скоро пользователь сможет работать с продуктом нашей разработки.
Но есть задачи, которые делаются с расчетом, что доработки будут постоянно модифицироваться. Как пример: реализация бизнес-процессов, выполнение производственных функций. Тут подход – сделать раз-раз и в продакшн – не совсем оправдан. Надо вовремя увидеть, что задача относится именно к этому классу и отнестись к ней по-другому. Хороший пример такого подхода у нас был реализован при разработке нашей внутренней библиотеки стандартных подсистем.
На эту задачу у нас был выделен достаточно мотивированный прокачанный разработчик, который имел возможность погрузиться в предметную область и был нацелен не просто на реализацию определенного решения, а на разработку механизма, который мог бы позволить другим разработчикам работать в сформировавшихся рамках.
После реализации этот механизм был документирован. И теперь другой разработчик, даже обладающий меньшей мотивацией, меньшим количеством времени на раскачку и, может, даже меньшей квалификацией, но при этом, работая в рамках, заданных прокачанным разработчиком, уже сможет сделать новое решение, конкретное приложение достаточно качественно без глубокого погружения.
Эту библиотеку мы у нас раскатали на много информационных систем и она широко используется нашими разработчиками. Это позволяет нам достаточно просто решать вопросы с управлением, интеграцией, доступами и другими ролевыми вопросами.
С другой стороны, как этот подход распространить на разработку внутри монолита, конкретного решения? Не совсем очевидно. Подходы к этому мы еще только ищем.
Очень большая надежда на специально выделенных разработчиков, которым мы выделяем специальную роль в разработке – эти люди называются у нас системными архитекторами. Они должны следить за тем, как у нас разрабатывается решение – правильно ли используются те механизмы, которые мы запланировали.
Системный архитектор должен следить, чтобы разрабатываемые задачи не требовали глубокого погружения, вовремя увидеть сложные задачи и найти ресурсы для их правильной проработки. Почему это важно? Потому что все равно придет момент, когда что бы мы ни делали, затраты на поддержку съедят весь имеющийся у нас ресурс. Мы придем к моменту, когда матрицу придется перезагружать. И чем больше и качественнее у нас будут проработаны эти механизмы, чем более они будут сконцентрированы, тем легче нам будет разнести систему. Растянуть расставание с большой тяжелой базой на более длительный период либо как-то минимизировать время разработки во время резкого перехода, если вдруг возникнет такая необходимость.
Итак, я рассказал вам о подходах, которые мы используем, чтобы работать со сложными факторами больших систем, чтобы они не становились слишком дороги для поддержки. Спасибо за внимание!
Вопросы
На одном из слайдов был рассказ про вынос функциональных блоков из большой системы. Расскажи про проблемы, которые были с этим связаны. Что мешает функциональность в большом монолите на сторонние, рядом стоящие решения?
Готовых 100% успешных решений для выноса этой функциональности в отдельные блоки у нас нет. К сожалению, все объемные кластеры функциональности – функциональность работы с заказами, то, как мы рассчитываем себестоимость и цены продукции – все это было реализовано в монолите и, конечно, требует выноса в отдельный функциональный блок. Но мы этого не смогли сделать? Почему? Потому что это действительно жизненно важные элементы бизнеса заказчика, они постоянно дорабатываются и вынос этой функциональности сродни операции на работающем сердце. Чтобы сделать это безопасно, с одной стороны, необходимо остановить разработку, на что не может пойти заказчик. Поэтому единственный вариант это реализовать – это либо дождаться, когда другого варианта не будет, либо второй вариант – когда бизнес скажет, что хочет что-то кардинально новое. Тогда естественно будет повод разработать новую систему и быстро перевести комплект функциональности на работу с внешней системой. Чтобы это сделать как можно более безопасно, нам и нужны хорошие разработчики и база знаний по всем кейсам, которые позволят сформировать задание на переход. Сергей Носков в одном из предыдущих докладов говорил: «У кого одна база, хочет ее разделить, у кого их несколько, хочет объединить». Это вечный цикл.
Как происходит обрезание системы? Сколько оно занимает по времени?
Мы не столько обрезаем старую базу данных – у нас есть волшебная штука, которая создает новую базу, в которой будет консистентные данные за последний период. При наших объемах – это единственный вариант. Из-за специфики хранения данных на MS SQL, альтернатив нет. По времени, так как это происходит зеркально, не останавливая процесс работы бизнеса, последний раз это заняло дня три-четыре.
Сколько человек занимается администрированием СУБД таких размеров?
DBA-шников – двое. А разработчиков у нас много.
*************
Данная статья написана по итогам доклада (видео), прочитанного на INFOSTART MEETUP Saint Petersburg.Online.
|
30 мая - 1 июня 2024 года состоится конференция Анализ & Управление в ИТ-проектах, на которой прозвучит 130+ докладов.
Темы конференции:
Конференция для аналитиков и руководителей проектов, а также других специалистов из мира 1С, которые занимаются системным и бизнес-анализом, работают с требованиями, управляют проектами и продуктами!
|





