




Источник https://www.trek10.com/blog/dynamodb-single-table-relational-modeling/ (Forrest Brazeal).
Делаю для лучшего понимания применимости связки Yandex Serverless + Yandex Database (Document API, совместим с Amazon DynamoDB) для небольших проектов, которые попадают в бесплатную тарификацию.
Из всех сессий, которые я видел в AWS re:Invent 2018, моей любимой, безусловно, является этот ошеломляющий опыт работы с NoSQL от главного технолога AWS и сертифицированного мастера космического пространства Rick Houlihan.
Рик приоткрывает крышку банки с червями, которых многие из нас, разрабатывающих таблицы DynamoDB, стараются избегать: тот факт, что DynamoDB - это не просто хранилище значений ключей для простого поиска элементов. Если вы спроектируете его правильно, одна таблица DynamoDB может обрабатывать шаблоны доступа к допустимой многотабличной реляционной базе данных, не напрягаясь.
Эта маленькая фраза "спроектирована должным образом", конечно, является предостережением. Видео Рика и соответствующая документация (ссылка), к которой, как я подозреваю, он приложил руку, плотно набиты советами о том, как создать таблицу DynamoDB, которая будет соответствовать производительности запросов вашей реляционной базы данных в произвольном горизонтальном масштабе.
Хотя не буду врать, это тяжелая штука, особенно для нас, несертифицированных космических волшебников.
Итак, в этом посте я хочу пошагово проработать некоторые соображения по проектированию однотабличной системы DynamoDB. Мы не будем рассматривать все возможные шаблоны проектирования, но, надеюсь, вы начнете понимать возможные варианты использования и неизбежные компромиссы. В заключение мы зададим главный вопрос: является ли все это хорошей идеей, когда реляционные базы данных все еще находятся прямо там?
Из RDB в DynamoDB: практический пример
Итак, какую реляционную базу данных мы должны, э-э, динамизировать? Я решил использовать самый похожий на SQL пример, который только мог придумать: Northwind, классическая реляционная база данных, используемая для обучения продукту Microsoft Access еще в 90-х годах.
Вот полный репозиторий о Нортвинде (ссылка). Он невелик, но, по крайней мере, так же сложен, как требования к данным многих современных микросервисов, которые вы, возможно, захотите использовать с помощью DynamoDB.
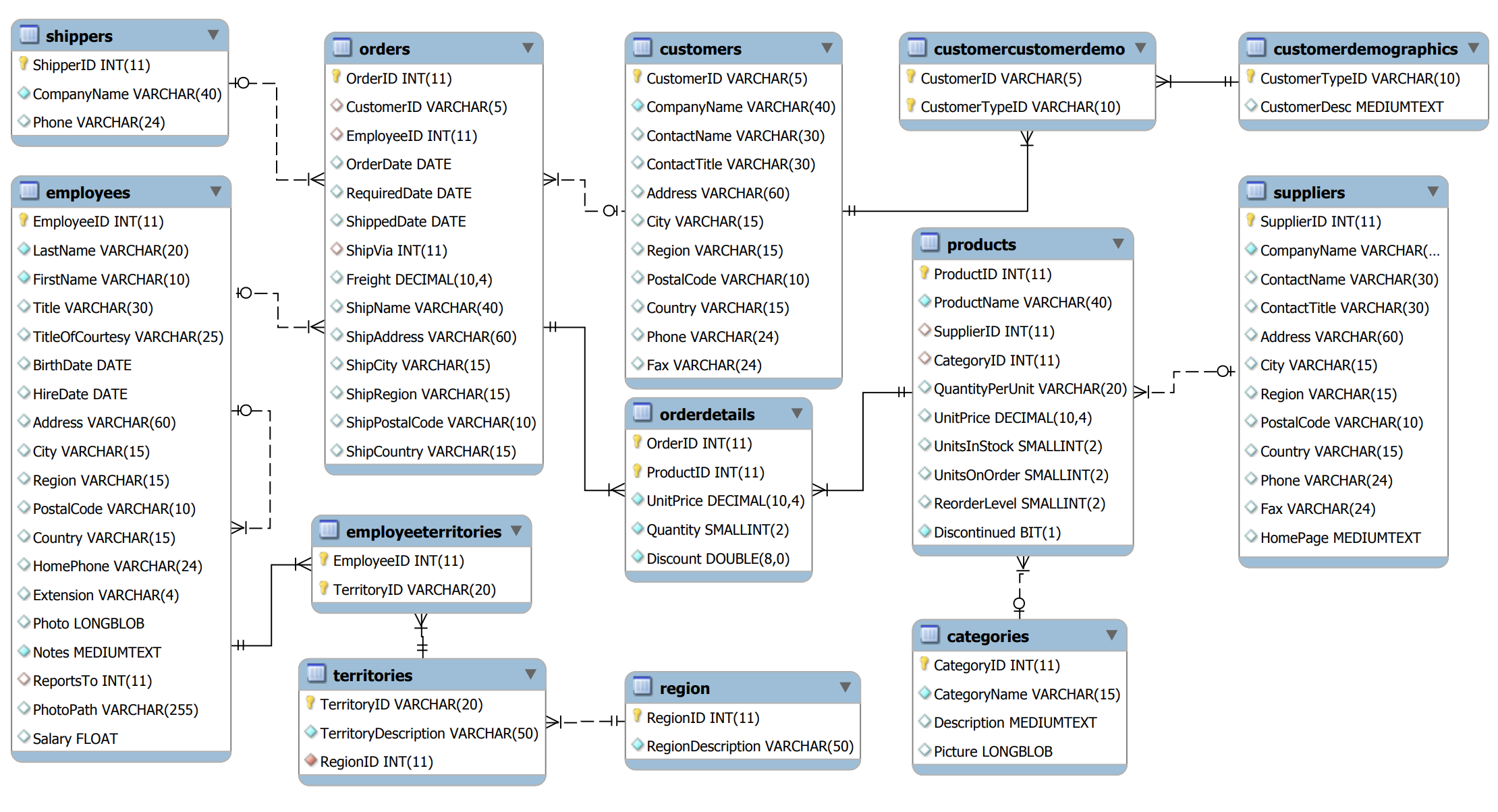
О чудо, образец данных для схемы (ссылка) Northwind доступен в очищенной CSV-форме на Github. Мы проигнорируем пару вспомогательных таблиц, чтобы сосредоточиться на “большой восьмерке”: Категории, Клиенты, Сотрудники, Заказы / Детали заказа, Продукты, Грузоотправители и Поставщики.
Я включил весь код, необходимый для создания таблицы DynamoDB и загрузки данных, как показано в этом посте, в этом репозитории Github (ссылка). Не стесняйтесь проверить и запустить самостоятельно!
Шаг за шагом
Теперь, как нам превратить наши таблицы ERD и CSV в таблицу DynamoDB?
Шаг 1: Определите шаблоны доступа, которые, по вашему мнению, вам понадобятся
Сразу же мы сталкиваемся с огромной разницей между DynamoDB и реляционной базой данных: наша модель данных будет полностью прагматичной, а не теоретически самосогласованной. Мы собираемся сформировать нашу таблицу специально вокруг того, что нам нужно делать с данными, вроде как распылять изоляционную пену на крышу.
В реальном мире мы бы собрали эти требования от команды разработчиков приложений, потенциальных пользователей и т.д. Однако это не реальный вариант использования, поэтому нам придется изобрести некоторые шаблоны доступа, посмотрев на ERD. Вот некоторые произвольные требования к запросам, которые я придумал:
- Получить сотрудника по идентификатору сотрудника
- Получать прямые отчеты для сотрудника
- Получить снятые с производства продукты
- Перечислите все заказы на данный товар
- Получите самые последние 25 заказов
- Получить грузоотправителей по именам
- Получать клиентов по контактному имени
- Перечислите все товары, включенные в заказ
- Поиск поставщиков по странам и регионам
Все это были бы простые SQL-запросы, включающие не более пары соединений. (Мы сохраним шаблоны написания для будущего поста.) Но помните, что у нас нет JOIN или GROUP BY в DynamoDB. Вместо этого мы должны структурировать наши данные таким образом, чтобы они были "предварительно объединены" прямо в таблице.
Шаг 2. Создайте таблицу DynamoDB с тремя общими атрибутами: "ключ раздела", "ключ сортировки" и "данные".
Примечание переводчика: "partition key" (PK) = "ключ раздела", "sort key" (SK) = "ключ сортировки"
Это подводит нас к одному из самых важных принципов проектирования однотабличной системы DynamoDB:
Имена атрибутов не имеют никакого отношения к значениям атрибутов.
Наше хранилище "ключ-значение" не только не имеет схемы; в некотором смысле оно также не имеет ключа. Нам нужно привыкнуть думать об именах атрибутов элемента DynamoDB как о произвольных. Наш атрибут "ключ раздела" в таблице может содержать значение другого типа в зависимости от того, является ли это Заказом, Продуктом, Сотрудником или чем-то еще:
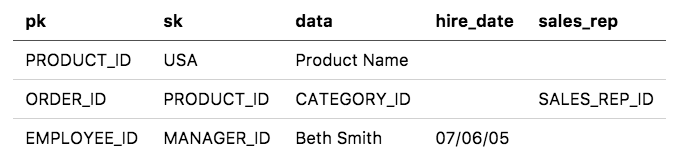
Хранение разных типов данных в одном и том же атрибуте кажется странным и неудобным, я знаю. Но на самом деле он очень мощный. Этот метод называется перегрузкой индекса (index overloading), и он позволит нам объединить тонны шаблонов доступа в очень небольшое количество индексов.
Три общих атрибута будут использоваться для поддержки двух индексов: основного табличного индекса, который использует PK в качестве раздела и SK в качестве ключа сортировки, и глобального вторичного индекса, который использует SK в качестве раздела и данных в качестве сортировки.
В любом случае, что такого особенного в индексах? В общем, ваши затраты и производительность DynamoDB будут наилучшими, если вы ограничитесь "получениями" (поиск по ключу / значению для отдельных элементов) и "запросами" (условный поиск по элементам, которые имеют один и тот же ключ раздела, но разные ключи диапазона / сортировки). Сканирование, при котором вы без разбора поглощаете все элементы из таблицы, - это медленный и дорогостоящий антипаттерн. Требуются полезные запросы и запросам требуются ... полезные индексы (useful indexes) (ссылка). Итак, мы здесь.
Эти два индекса, как мы увидим, откроют огромное количество шаблонов доступа. Другие атрибуты в таблице могут быть названы так, как вы хотите; они не обязательно должны быть согласованы между элементами. Но даже если вы дадите каждому атрибуту каждого элемента случайное имя, это никак не повлияет на поведение таблицы. (Это просто затрудняет чтение и понимание людьми макета таблицы ... как мы обсудим далее ниже.)
Шаг 3: Создайте элемент в таблице DynamoDB для каждой записи в каждой таблице entity (без объединения)
Каждый Клиент, каждый Заказ, каждая запись отправителя получает товар в нашей новой таблице. В каждом из наших случаев мы сделаем так, чтобы атрибут pk соответствовал первичному ключу реляционной записи. Однако атрибуты sk и data мы будем варьировать в зависимости от типов запросов, которые нам нужно написать. Смотрите разбивку ниже:

На данный момент мы не включили таблицу соединений “OrderDetails”; на следующем шаге она будет обработана особым образом.
Давайте отметим здесь пару трюков:
- Записи заказа, Продукта и поставщика используют статическое значение в качестве ключа раздела для GS1. Это позволяет нам просматривать все товары определенного типа (например, все заказы, соответствующие диапазону дат), не прибегая к дорогостоящей операции сканирования. Вы можете рассматривать это как обходной путь для потери наших драгоценных ключей атрибутов: вместо этого мы используем значение в качестве ключа.
- Мы использовали составное значение, называемое ключом иерархической сортировки(hierarchical sort key), в качестве поля данных для записей клиентов и поставщиков. Объединив все данные адреса в одном поле, мы можем получить информацию о стране, регионе и городе по цене одного GSI.
- Мы использовали значение “прекращено” в качестве ключа сортировки в GSI для товарных позиций. Предполагая, что мы заполняем это значение только для снятых с производства продуктов (что неверно в исходных данных Northwind), мы можем выполнять поиск снятых с производства товаров без необходимости сканирования всего раздела “ПРОДУКТ”. Этот метод называется разреженным индексом(sparse index).
На данный момент мы в основном играем в Тетрис с нашими данными, вводя и выводя различные значения из наших ограниченных слотов GSI, чтобы получить максимальную полезность. И мы еще не закончили, потому что нам все еще нужно это сделать...
Шаг 4: Представление отношений "многие ко многим" с помощью списков смежности
Лучшие практики DynamoDB заимствуют из теории графов концепцию списков смежности (adjacency lists) (ссылка), которые являются ... немного скользкой концепцией. Чтобы на мгновение зацепиться за идею графа, вы можете подумать обо всех элементах, которые мы разместили в нашей таблице до сих пор, как о записях “узла”. Они соответствуют сущностям, таким как клиенты и заказы. Теперь мы собираемся создать несколько дополнительных записей “edge”, которые представляют отношения "многие ко многим" между узлами.
В наборе данных Northwind взаимосвязь "многие ко многим", на которой мы сосредоточимся, выражена в таблице соединений OrderDetails. В заказе может быть много продуктов, один продукт может присутствовать во многих заказах, и атрибуты этой взаимосвязи выражаются в OrderDetails. Мы смоделируем эту взаимосвязь, разместив записи OrderDetails в разделе Order нашей таблицы.
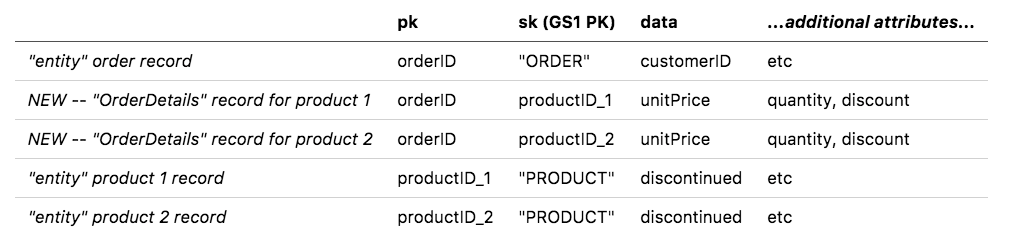
Почему мы так одержимы минимизацией глобальных вторичных индексов? Не проще ли было бы просто поместить тонну индексов в эту таблицу? Долгое время ответ был отрицательным; таблицы DynamoDB имели жесткий предел в 5 GSI. DynamoDB совсем недавно повысил это ограничение до 20, что означает, что у вас, вероятно, может быть неопределенное количество GSI в таблице.
Но многие GSI делают запись геометрически более дорогой, потребляя дополнительные единицы емкости каждый раз, когда вы обновляете элемент. Таким образом, мы выиграем по затратам и производительности, если сможем сократить наши поисковые запросы до минимально возможного размера индекса.
Что это нам дает? Теперь у нас есть возможность запрашивать раздел первичной таблицы, чтобы получить все товары в заказе. Мы можем запросить GS1 PK, чтобы выполнить обратный поиск по всем заказам данного продукта. Это шаблон списка смежности. Вы можете попробовать это самостоятельно с помощью таблицы соединений "EmployeeTerrorities" в данных Northwind, которые мы здесь не включили. Возможно, вам придется разбить этот шаблон доступа на его собственный GSI, если вы продвинетесь намного дальше.
Почему мы снова складываем все это в одну таблицу? Документация DynamoDB настоятельно рекомендует использовать как можно меньше таблиц, обычно по одной для каждого приложения / службы, если у вас нет сильно отличающихся шаблонов доступа. Расположение связанных данных близко друг к другу даст вам преимущества в производительности и масштабировании Dynamo без задержек и разочарований, связанных с запросами к нескольким таблицам через HTTP и попытками "присоединиться" к ним на стороне клиента.
Тем не менее, я вижу множество реляционных баз данных, которые следует разделить на отдельные таблицы DynamoDB, потому что одна и та же база данных используется в качестве свалки для всех видов несвязанных данных. Эта 70-гигабайтная таблица журналов доступа в вашей базе данных Postgres не обязательно должна находиться в одной таблице DynamoDB с данными о вашем продукте и заказе.
Шаг 5 (необязательно): Создайте дополнительные GSI для поддержки дополнительных шаблонов доступа.
Хотите верьте, хотите нет, но даже со всеми хитростями, которые мы использовали на шаге 2, одного GSI может быть недостаточно для поддержки всех возможных запросов! (Шокирует, я знаю.) Хорошей новостью является то, что вы можете добавить дополнительные GSI, если это необходимо, без полного разрушения вашей тщательно собранной доски для тетриса. В документах DynamoDB есть хороший пример добавления второго GSI со специально созданными ключами разделения и сортировки для обработки определенных типов запросов диапазона.
В нашем случае, однако, раздела основной таблицы плюс один GSI более чем достаточно для обработки всех вариантов использования, которые мы определили на шаге 1. Давайте разберем запросы:

Вы можете увидеть рабочие примеры всех этих запросов (ссылка) с использованием AWS Python SDK в прилагаемом репозитории. Кроме того, мы сохранили индивидуальный поиск по значению ключа для каждой сущности в таблице, поэтому мы не слишком далеко отклонились от корней DynamoDB.
Чего мы не можем сделать?
Теперь у нас есть базовый план преобразования реляционной базы данных в единую таблицу DynamoDB. Но помните, что это "вспененный подход" к данным. Подобно изоляции, затвердевшей в контурах потолка, наша модель данных с одной таблицей DynamoDB является одновременно неформальной и негибкой. Это не обязательно будет соответствовать новым шаблонам доступа.
Например, предположим, что нам нужно просмотреть все товары в данной категории. Записи “Product” имеют идентификатор категории, но на данный момент он не включен ни в один из наших индексов. Наши варианты таковы:
- Запрос все продукты, фильтрация по ID категории (не самый оптимальный запроса), или
- Размещение новые элементов в одном из наших существующих разделов, что данные продукт индекса по ID категории (создает несколько дубликатов данных, которые потенциально сложнее управлять), или
- Создать глобальный вторичный индекс с идентификатором продукта, а перегородки и идентификатор категории в качестве ключа сортировки (увеличение стоимости таблицы)
Как вы можете видеть, компромиссов предостаточно! Только вы можете решить, какой вариант имеет наибольший смысл для долгосрочной работоспособности вашего приложения и здравомыслия ваших разработчиков. Чем больше GSI с общими атрибутами вы добавите, тем сложнее будет прочитать и понять эту таблицу без дополнительной документации.
На самом деле, хорошо оптимизированный макет DynamoDB с одной таблицей больше похож на машинный код, чем на простую электронную таблицу - несмотря на все индивидуальные человеческие усилия, которые потребовались для его создания.
Что приводит к самому важному вопросу из всех:
Действительно ли моделирование моей реляционной базы данных в одной таблице DynamoDB - хорошая идея?
Около года назад я написал довольно популярную статью под названием "Почему DynamoDB не для всех". Многие из технических критических замечаний DynamoDB, которые я высказал в то время (отсутствие операционных средств управления, таких как резервное копирование / восстановление; постоянная проблема с горячими клавишами), с тех пор были частично или полностью устранены благодаря действительно впечатляющему запуску выпусков функций от команды DynamoDB.
Однако главный аргумент этой статьи остается в силе: DynamoDB - мощный инструмент при правильном использовании, но если вы не знаете, что делаете, это обманчиво удобное руководство по безумию. И чем дальше вы углубляетесь в эзотерические приложения, такие как реляционное моделирование, тем больше вы должны быть уверены, что знаете, во что ввязываетесь. Особенно с учетом того, что "бессерверные" базы данных, ориентированные на SQL, такие как Amazon Aurora (аналога у Yandex на данный момент нет), набирают обороты, у вас есть множество полностью управляемых опций с меньшей кривой обучения.
Тем не менее, помните, что оригинальная статья Amazon Dynamo основывалась на наблюдении, что большинство взаимодействий с их обширными базами данных Oracle были простыми считываниями по ключу-значению, никаких объединений или другой реляционной магии не требовалось.
Точно так же множество поверхностно реляционных наборов данных сводятся к относительно небольшому числу шаблонов использования. Если вы сможете выполнить шаги, описанные в этом посте, чтобы определить и внедрить эти шаблоны для ваших данных, масштаб, производительность и низкие операционные издержки DynamoDB могут показаться более привлекательными, чем когда-либо.
Если, конечно, вы все еще не являетесь большим поклонником Microsoft Access.
Вступайте в нашу телеграмм-группу Инфостарт