Следи за рукой
Знание - сила! А знание, подкрепленное фактами, достоверными данными и высокой актуальностью - это сила, ответственность и безграничные возможности в части анализа информации.
Не такая уж и редкая задача - получить историю изменения данных, узнать кто, что и когда изменил в том или ином объекте. Пореже нужно отправлять изменения в другие информационные системы или даже хранилища данных, для чего создаются различные способы регистрации изменений. Но хоть эти задачи и звучат просто, но чем больше система и чем сложнее архитектура потоков данных, тем больше проблем с этим возникает:
- Проблемы производительности при регистрации изменений в высоконагруженных системах
- Критичность ошибок регистрации данных, если часть изменений не будет зарегистрирована или потеряна
- Высокая детализация изменений приводит к значительному росту базы данных и таблиц регистрации, в частности, а также существенно может замедлять процессы в информационной системе
- Отправка изменений системам-подписчикам требует большой надежности и скорости работы
- И много других вопросов, с которыми придется столкнуться.
И это нормально! Не нормально - это пытаться использовать один "универсальный" инструмент для решения всех этих задач, проблем.
Так давайте пойдем дальше и посмотрим на один из путей решения. Один из множества. А именно на механизм Change Data Capture из SQL Server. И путь его использования с платформой 1С.
Обычный ход
Прежде чем начать нужно сказать пару слов о том как это обычно делается в мире 1С. Примерно это выглядит так:
- Планы обмена - объекты конфигурации 1С, задача которых предоставить инфраструктуру для регистрации изменений, формирования и обработки сообщений и возможность использования распределенной информационной базы (что не обязательно). При этом сам механизм имеет как плюсы, так и минусы. Подробно на этом останавливаться не будем, но в высоконагруженных системах использовать планы обмена дело последнее из-за узких мест в его работе. Подробнее смотрите статьи здесь, на Инфостарт.
- Собственная таблица регистрации - обычно реализуется на регистрах сведений, но бывают и более извращенные случаи. Фактически создается отдельная таблица, где разработчик может более гибким образом управлять статусами объекта. В основном так решаются задачи регистрации изменений только для обмена со сторонними системами. Истории изменений самих данных как таковых нет.
- Версионирование объектов - штатный механизм из БСП и его вариации в виде регистра сведений, в котором сохраняется сериализованная версия объекта на момент изменения. Вот его краткое описание на примере УТ 11. Относительно популярный подход хранения изменений объекта с детализацией до конкретных полей, но влияющий как на скорость записи в базу (обычно незначительно, относительно основного времени записи), так и на размер самой базы (а этот фактор уже очень сильный, иногда половину размера базы может занять история версий объектов, особенн
 о если их не чистить).
о если их не чистить).
- Сам подход хранения версий был настолько популярен, что в итоге подобный же механизм включили на уровне самой платформы 1С в виде "Истории данных", который проще в использовании, но имеет меньше контроля над своей работой. И больше ошибок, хотя с ними сталкивался достаточно давно и в новых версиях может все работает намного лучше.
- Механизм решает задачу хранения истории изменений, но работает относительно медленно при чтении данных версий, т.к. каждую из них нужно предварительно распаковать или нормализовать.
- Журнал регистрации - еще один штатных механизм для логирования изменений, но на верхнем уровне. Больше подходит для задач аудита и то не всегда. Содержит информацию кто, что и когда изменил, а также большое количество других событий для анализа. В части отслеживания изменений может помочь увидеть только сам факт изменения и его инициатора, но на вопросы кто изменил и что точный ответ дать не сможет. Хотя есть умельцы, которые версии объектов в виде текста сохраняют в журнал регистрации. Без комментариев. В целом механизм медленный и не поддающийся нормальной интеграции с другими инструментами и системами, только через различные костыли.
Это основное, что касается задач регистрации изменений и хранения истории версий объектов. Есть и другие пути, которые в мире 1С часто используют, немного выходя за границы платформы. Но об этом смысла рассказывать нет. Перейдем к теме статьи.
Берем под контроль
Отбросим штатные средства и попытаемся использовать механизм регистрации изменений Change Data Capture из SQL Server. Главная причина, почему будем использовать именно его - доступность (SQL Server до сих пор самая популярная СУБД для систем на базе 1С), высокая производительность и детализация истории изменений. Хотя и для PostgreSQL подобные возможности есть, но мы их рассматривать не будем. Поехали!
Общая архитектура
В чем суть механизма CDC? Вы включаете для базы данных поддержку использования CDC, затем включаете отслеживание изменений для конкретных таблиц базы данных. При внесении 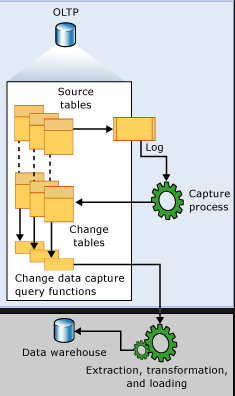 изменений в таблицы, информация об этом появляется в журнале транзакций, вне зависимости от модели восстановления базы данных (простой или полной) и вот именно эти данные из журнала транзакций и служат источником информации о вносимых изменениях.
изменений в таблицы, информация об этом появляется в журнале транзакций, вне зависимости от модели восстановления базы данных (простой или полной) и вот именно эти данные из журнала транзакций и служат источником информации о вносимых изменениях.
Фоновый процесс сканирует записи в журнале транзакций и загружает их в таблицы регистрации изменений, которые механизм CDC создает автоматически на каждую отслеживаемую таблицу. Таким образом, регистрация изменений происходит асинхронно и не влияет явно на операции в базе данных.
При включении поддержки CDC для всей базы сначала создаются служебные таблицы в схеме "cdc", информацию о которых Вы можете узнать в официальной документации (в SSMS их можно найти в списке системных таблиц):
- [cdc].[change_tables]
- [cdc].[ddl_history]
- [cdc].[lsn_time_mapping]
- [cdc].[captured_columns]
- [cdc].[index_columns]
Как только Вы включаете регистрацию изменений для конкретной таблицы, например, для таблицы [dbo].[v8users], то сразу добавляется таблица для сохранения изменений [cdc].[dbo_v8users_CT] со структурой, аналогичной исходной таблице, но при этом с дополнительными служебными полями:
- [__$start_lsn] - Регистрационный номер транзакции в журнале (LSN), связанный с фиксацией транзакции изменения.
- [__$end_lsn] - Указано только в ознакомительных целях. Не поддерживается. Совместимость с будущими версиями не гарантируется.
- [__$seqval] - Значение последовательности, используемое для упорядочивания изменений строк в пределах транзакции.
- [__$operation] - Определяет операцию языка обработки данных (DML). 1 - удаление, 2 - вставка, 3 - обновление (старые значения), 4 - обновление (новые значения).
- [__$command_id] - Отслеживает порядок операций в транзакции.
Таким образом, механизм CDC позволяет собрать историю изменения данных в таблицах на физическом уровне, что предоставляет максимальную детализацию истории изменений. Но это также создает некоторые особенности в части обработки этих данных, т.к.  некоторые операции могут формировать несколько операций в истории изменения данных. Например, операция обновления может быть представлена операцией удаления и операцией добавления, но с одним идентификатором транзакции. Это нужно учитывать.
некоторые операции могут формировать несколько операций в истории изменения данных. Например, операция обновления может быть представлена операцией удаления и операцией добавления, но с одним идентификатором транзакции. Это нужно учитывать.
Кроме служебных таблиц в базе появляются также объекты:
- Множество служебных хранимых процедур в схеме "cdc".
- И функции для удобного получения истории изменений по таблицам.
- Задания для загрузки изменений из журнала транзакций и очистки исторических данных.
- И некоторые другие объекты.
И все было бы хорошо, но просто так CDC подружить с 1С не получится, т.к. появятся следующие проблемы:
- При проведении реструктуризации базы данных механизм CDC для обновляемой таблицы будет отключен и нужно будет его вручную включить обратно.
- В момент отключения механизма CDC из-за реструктуризации может появиться потеря информации об изменениях.
- И, конечно, будет проблема в части использования информации об изменении данных из CDC, ведь официальной поддержки у платформы 1С для этого механизма нет.
Но не стоит отчаиваться, так как все эти проблемы можно решить. Этим мы и займемся дальше. В одной статье полноценно все рассказать нельзя, но направление работ определить точно можно.
Делаем настройку
Данный подход по настройке CDC подходит для любых приложений, которые используют SQL Server в качестве СУБД. Подробные шаги по настройке описаны здесь. Мы будем адаптировать подход к информационной базе 1С.
Подготовка
На первом шаге создадим в базе новую схему данных "yy", чтобы все новые объекты хранить там и не смешивать их с объектами платформы 1С.
CREATE SCHEMA [yy] AUTHORIZATION [dbo]
GO
Первым объектом в новой схеме станет таблица настроек. В ней мы будем хранить следующую информацию:
- Имя исходной таблицы в базе данных, для которой мы хотим поддерживать настройки CDC.
- Флаг использования CDC.
- Имя таблицы CDC, которая была создана системой автоматически. Вручную не заполняем (!!!).
- Текущее имя таблицы, куда переадресуется сохранение регистрируемых данных. То есть данные в основной таблице CDC мы хранить не будем, они будут переадресованы в нашу собственную таблицу. Этот параметр вручную заполнять не нужно (!!!), все будет сделано автоматически.
- И данные, по которым мы можем определить изменяли ли таблицу DDL-командами: идентификатор объекта и дата последнего изменения объекта.
CREATE TABLE [yy].[MaintenanceSettingsCDC](
[ID] [int] IDENTITY(1,1) NOT NULL,
[SchemaName] [nvarchar](255) NOT NULL,
[TableName] [nvarchar](255) NOT NULL,
[UseCDC] [bit] NOT NULL,
[SchemaNameCDC] [nvarchar](255) NULL,
[TableNameCDC] [nvarchar](255) NULL,
[TableNameCDCHistory] [nvarchar](255) NULL,
[CaptureInstanceCDC] [nvarchar](255) NULL,
[TableObjectId] [int] NULL,
[TableSchemaLastChangeDate] [datetime2](7) NULL,
CONSTRAINT [PK_MaintenanceSettingsCDC] PRIMARY KEY CLUSTERED
(
[ID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
-- Индекс для защиты уникальности настроек. На одну таблицу в схеме данных
-- может быть только одна настройка.
CREATE UNIQUE NONCLUSTERED INDEX [UX_MaintenanceSettingsCDC_BySchemaAndTableName]
ON [yy].[MaintenanceSettingsCDC]
(
[SchemaName] ASC,
[TableName] ASC
) ON [PRIMARY]
GO
Фактически, интерактивно нужно заполнять лишь поля SchemaName, TableName и UseCDC, а остлаьное будет заполнено автоматически.
Дополнительно создадим две функции, которые будут возвращать имена схем. Это просто для удобства.
Небольшие служебные функции
-- Функция возвращает имя схемы данных CDC по умолчанию.
-- Маловероятно, что Вам придется как-то эту часть изменять.
CREATE FUNCTION [yy].[GetCDCSchemeName]()
RETURNS nvarchar(255)
AS
BEGIN
RETURN N'cdc';
END
GO
-- Функция возвращает имя схемы данных, где будут находиться служебные объекты.
-- Вы можете изменить ее под свои нужды. Только не забудьте исправить имя схемы
-- в DDL-скриптах создания объектов базы данных.
CREATE FUNCTION [yy].[GetMainSchemeName]()
RETURNS nvarchar(255)
AS
BEGIN
RETURN N'yy';
END
GO
И самое главное в части настроек - это добавить процедуру для автоматического заполнения служебных полей, ведь вручную мы указываем только:
- Имя схемы исходной таблицы
- Имя исходной таблицы
- И флаг использования CDC
Вот как будет выглядеть эта процедура.
Процедура обновления служебных полей в настройке
-- Процедура для обновления служебных полей настроек CDC
CREATE PROCEDURE [yy].[UpdateServiceMaintenanceSettingsCDC]
@settingId int,
@schemaNameCDC nvarchar(255) = null output,
@tableNameCDC nvarchar(255) = null output,
@tableNameCDCHistory nvarchar(255) = null output,
@captureInstanceCDC nvarchar(255) = null output,
@tableObjectId int = null output,
@tableSchemaLastChangeDate datetime2(0) = null output
AS
BEGIN
DECLARE
@schameName nvarchar(255),
@tableName nvarchar(255);
SET NOCOUNT ON;
BEGIN TRAN;
SELECT
@schameName = SchemaName,
@tableName = TableName
FROM [yy].[MaintenanceSettingsCDC]
WHERE ID = @settingId
-- Получаем идентификатор исходной таблицы,
-- а также дату последнего изменения таблицы DDL-командами
DECLARE @currentCDCEnabled bit = 0;
SELECT
@tableObjectId = object_id,
@tableSchemaLastChangeDate =
CASE WHEN create_date > modify_date THEN create_date
ELSE modify_date
END
FROM sys.tables tb
INNER JOIN sys.schemas s
on s.schema_id = tb.schema_id
WHERE s.name = @schameName AND tb.name = @tableName
-- Сохраняем информацию о CDC:
-- * Имя схемы CDC
-- * Имя таблицы CDC
-- * Имя переопределенной таблицы CDC. Внимание! Имя формируется заново
-- при каждом вызове. Это нужно учитывать при использовании процедуры
-- * Имя экземпляра объекта сбора данных
SELECT
@schemaNameCDC = [yy].[GetCDCSchemeName](),
@tableNameCDC = OBJECT_NAME([object_id]),
@tableNameCDCHistory = OBJECT_NAME([object_id]) + '_'
+ replace(convert(varchar, getdate(),101),'/','') + '_'
+ replace(convert(varchar, getdate(),108),':',''),
@captureInstanceCDC = capture_instance
FROM [cdc].[change_tables]
WHERE source_object_id = @tableObjectId
-- Обновляем настройку
UPDATE [yy].[MaintenanceSettingsCDC]
SET
[SchemaNameCDC] = @schemaNameCDC,
[TableNameCDC] = @tableNameCDC,
[TableNameCDCHistory] = @tableNameCDCHistory,
[CaptureInstanceCDC] = @captureInstanceCDC,
[TableObjectId] = @tableObjectId,
[TableSchemaLastChangeDate] = @tableSchemaLastChangeDate
WHERE ID = @settingId
COMMIT TRAN;
RETURN 0;
END
GO
Все основные моменты описаны на листинге выше.
Теперь мы готовы перейти к следующему этапу.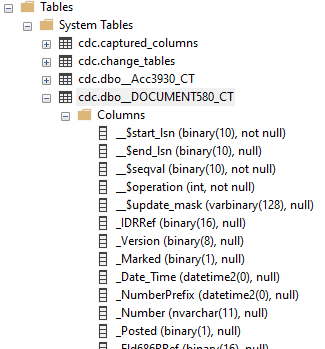
Переопределяем поведение
Платформа 1С во время реструктуризации пересоздает таблицы, что может быть большой проблемой при использовании CDC. После пересоздания таблицы механизм CDC уже по факту отключен и новые изменения не регистрируются. Пока кто-то вручную его не включит, все сделанные изменения с этот момента будут потеряны. Это самая частая проблема в таких сценариях использования.
Для решения этой проблемы предлагается такой вариант:
- Изменить поток данных об изменениях, который формируется из файла логов транзакций, таким образом, чтобы изменения записывались не в служебную таблицу CDC (которая как-раз и удаляется при реструктуризации), а в нашу собственную таблицу. Тогда при реструктуризации никаких потерянных изменений не будет.
- Ну а для включения CDC после реструктуризации сделаем некоторое задание (job), которое асинхронно обновит настройки CDC для новых таблиц максимально оперативно.
Первым пунктом и займемся. Схема будет такой:
- Есть штатная таблица CDC, куда SQL Server в реляционном формате сохраняет данные об изменениях. О них мы уже говорили выше. На скриншоте пример такой таблицы. Все они находятся в схеме "cdc".
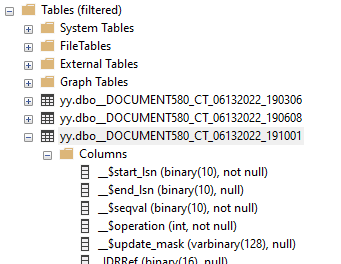
- Мы автоматически по таблице настроек CDC "MaintenanceSettingsCDC" будем создавать в схеме "yy" служебную таблицу с именем формата "<ИмяТаблицыCDC>_<ДатаСозданияСоВременем>". При каждой реструктуризации будет создаваться такая таблица, что позволит сохранить работоспособность CDC при любых изменениях структуры таблицы. Фактически у нас будет история изменений таблицы DDL-командами. На скриншоте как-раз есть история из трех реструктуризаций.
- Чтобы новая, переопределенная таблица CDC была задействована, нужно для штатной таблицы CDC создать триггер вида "INSTEAD OF INSERT", чтобы все вставки перенаправлялись в нашу собственную таблицу.
- В момент переключения также переместим все накопившиеся изменения из штатной таблицы CDC в нашу собственную таблицу. Так никакие изменения не потеряются.
Такой подход исключит потерю данных в таблицах CDC при изменении структуры основных таблиц, т.к. штатные таблицы CDC практически всегда будут пустыми. Переключение с таблицы CDC на нашу собственную таблицу будем выполнять следующей процедурой.
Процедура перенаправления потока данных CDC
-- Процедура переопределения потока данных в таблицу CDC на наши собственные
-- таблицы. Переопределение выполняется для конкретной настройки в таблице MaintenanceSettingsCDC
CREATE PROCEDURE [yy].[OverrideDataFlowForCDC]
@settingId int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @originalTableName sysname;
DECLARE @destinationTableName sysname;
-- Читаем данные переданной настройки CDC
SELECT
@destinationTableName = [TableNameCDCHistory],
@originalTableName = [TableNameCDC]
FROM [yy].[MaintenanceSettingsCDC]
WHERE ID = @settingId
DECLARE @originalSchemaName sysname = [yy].[GetCDCSchemeName]();
DECLARE @destinationSchemaName sysname = [yy].[GetMainSchemeName]();
DECLARE @destinationObjectFullName nvarchar(max) = @destinationSchemaName + '.' + @destinationTableName;
-- Формируем список таблиц для генерации скриптов создания копий таблиц и индексов,
-- триггеров и их пересоздание
DECLARE @tableName sysname;
DECLARE tables_cursor CURSOR
FOR SELECT
s.[name]
FROM SYSOBJECTS s LEFT JOIN sys.objects objs on s.id = objs.object_id
WHERE s.xtype = 'U'
and SCHEMA_NAME(objs.schema_id) = @originalSchemaName
AND s.[name] IN (
@originalTableName
);
OPEN tables_cursor;
FETCH NEXT FROM tables_cursor INTO @tableName;
WHILE @@FETCH_STATUS = 0
BEGIN
DECLARE @tableNameFull SYSNAME
SELECT @tableNameFull = @originalSchemaName + '.' + @tableName
DECLARE
@object_name SYSNAME
, @object_id INT
-- Подготовка к формированию скриптов по таблицам и индексам
SELECT
@object_name = '[' + s.name + '].[' + o.name + ']'
, @object_id = o.[object_id]
FROM sys.objects o WITH (NOWAIT)
JOIN sys.schemas s WITH (NOWAIT) ON o.[schema_id] = s.[schema_id]
WHERE s.name + '.' + o.name = @tableNameFull
AND o.[type] = 'U'
DECLARE @SQL NVARCHAR(MAX) = '';
DECLARE @SQLTRANSFER NVARCHAR(MAX) = '';
DECLARE @SQLTRANSFERTRIGGER NVARCHAR(MAX) = '';
DECLARE @SQLTRANSFERTRIGGERDROP NVARCHAR(MAX) = '';
WITH index_column AS
(
SELECT
ic.[object_id]
, ic.index_id
, ic.is_descending_key
, ic.is_included_column
, c.name
FROM sys.index_columns ic WITH (NOWAIT)
JOIN sys.columns c WITH (NOWAIT) ON ic.[object_id] = c.[object_id] AND ic.column_id = c.column_id
WHERE ic.[object_id] = @object_id
),
fk_columns AS
(
SELECT
k.constraint_object_id
, cname = c.name
, rcname = rc.name
FROM sys.foreign_key_columns k WITH (NOWAIT)
JOIN sys.columns rc WITH (NOWAIT) ON rc.[object_id] = k.referenced_object_id AND rc.column_id = k.referenced_column_id
JOIN sys.columns c WITH (NOWAIT) ON c.[object_id] = k.parent_object_id AND c.column_id = k.parent_column_id
WHERE k.parent_object_id = @object_id
)
-- Скрипт создания новой таблицы
SELECT @SQL = '
IF EXISTS (SELECT * FROM SYSOBJECTS s LEFT JOIN sys.objects objs on s.id = objs.object_id
WHERE s.name=''' + CAST(@destinationTableName as nvarchar(max)) + '''
AND xtype=''U''
AND SCHEMA_NAME(objs.schema_id) = ''' + CAST(@destinationSchemaName as nvarchar(max)) + ''')
BEGIN
DROP TABLE ' + CAST(@destinationObjectFullName as nvarchar(max)) + ';
END
CREATE TABLE ' + @destinationObjectFullName + CHAR(13) + '(' + CHAR(13) + STUFF((
SELECT CHAR(9) + ', [' + c.name + '] ' +
CASE WHEN c.is_computed = 1
THEN 'AS ' + cc.[definition]
ELSE UPPER(tp.name) +
CASE WHEN tp.name IN ('varchar', 'char', 'varbinary', 'binary', 'text')
THEN '(' + CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length AS VARCHAR(5)) END + ')'
WHEN tp.name IN ('nvarchar', 'nchar', 'ntext')
THEN '(' + CASE WHEN c.max_length = -1 THEN 'MAX' ELSE CAST(c.max_length / 2 AS VARCHAR(5)) END + ')'
WHEN tp.name IN ('datetime2', 'time2', 'datetimeoffset')
THEN '(' + CAST(c.scale AS VARCHAR(5)) + ')'
WHEN tp.name = 'decimal'
THEN '(' + CAST(c.[precision] AS VARCHAR(5)) + ',' + CAST(c.scale AS VARCHAR(5)) + ')'
ELSE ''
END +
CASE WHEN c.collation_name IS NOT NULL THEN ' COLLATE ' + c.collation_name ELSE '' END +
CASE WHEN c.is_nullable = 1 THEN ' NULL' ELSE ' NOT NULL' END +
CASE WHEN dc.[definition] IS NOT NULL THEN ' DEFAULT' + dc.[definition] ELSE '' END +
CASE WHEN ic.is_identity = 1 THEN ' IDENTITY(' + CAST(ISNULL(ic.seed_value, '0') AS CHAR(1)) + ',' + CAST(ISNULL(ic.increment_value, '1') AS CHAR(1)) + ')' ELSE '' END
END + CHAR(13)
FROM sys.columns c WITH (NOWAIT)
JOIN sys.types tp WITH (NOWAIT) ON c.user_type_id = tp.user_type_id
LEFT JOIN sys.computed_columns cc WITH (NOWAIT) ON c.[object_id] = cc.[object_id] AND c.column_id = cc.column_id
LEFT JOIN sys.default_constraints dc WITH (NOWAIT) ON c.default_object_id != 0 AND c.[object_id] = dc.parent_object_id AND c.column_id = dc.parent_column_id
LEFT JOIN sys.identity_columns ic WITH (NOWAIT) ON c.is_identity = 1 AND c.[object_id] = ic.[object_id] AND c.column_id = ic.column_id
WHERE c.[object_id] = @object_id
ORDER BY c.column_id
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, CHAR(9) + ' ')
+ ISNULL((SELECT CHAR(9) + ', CONSTRAINT [' + k.name + '] PRIMARY KEY (' +
(SELECT STUFF((
SELECT ', [' + c.name + '] ' + CASE WHEN ic.is_descending_key = 1 THEN 'DESC' ELSE 'ASC' END
FROM sys.index_columns ic WITH (NOWAIT)
JOIN sys.columns c WITH (NOWAIT) ON c.[object_id] = ic.[object_id] AND c.column_id = ic.column_id
WHERE ic.is_included_column = 0
AND ic.[object_id] = k.parent_object_id
AND ic.index_id = k.unique_index_id
FOR XML PATH(N''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, ''))
+ ')' + CHAR(13)
FROM sys.key_constraints k WITH (NOWAIT)
WHERE k.parent_object_id = @object_id
AND k.[type] = 'PK'), '') + ')' + CHAR(13)
+ ISNULL((SELECT (
SELECT CHAR(13) +
'ALTER TABLE ' + @object_name + ' WITH'
+ CASE WHEN fk.is_not_trusted = 1
THEN ' NOCHECK'
ELSE ' CHECK'
END +
' ADD CONSTRAINT [' + fk.name + '] FOREIGN KEY('
+ STUFF((
SELECT ', [' + k.cname + ']'
FROM fk_columns k
WHERE k.constraint_object_id = fk.[object_id]
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
+ ')' +
' REFERENCES [' + SCHEMA_NAME(ro.[schema_id]) + '].[' + ro.name + '] ('
+ STUFF((
SELECT ', [' + k.rcname + ']'
FROM fk_columns k
WHERE k.constraint_object_id = fk.[object_id]
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')
+ ')'
+ CASE
WHEN fk.delete_referential_action = 1 THEN ' ON DELETE CASCADE'
WHEN fk.delete_referential_action = 2 THEN ' ON DELETE SET NULL'
WHEN fk.delete_referential_action = 3 THEN ' ON DELETE SET DEFAULT'
ELSE ''
END
+ CASE
WHEN fk.update_referential_action = 1 THEN ' ON UPDATE CASCADE'
WHEN fk.update_referential_action = 2 THEN ' ON UPDATE SET NULL'
WHEN fk.update_referential_action = 3 THEN ' ON UPDATE SET DEFAULT'
ELSE ''
END
+ CHAR(13) + 'ALTER TABLE ' + @object_name + ' CHECK CONSTRAINT [' + fk.name + ']' + CHAR(13)
FROM sys.foreign_keys fk WITH (NOWAIT)
JOIN sys.objects ro WITH (NOWAIT) ON ro.[object_id] = fk.referenced_object_id
WHERE fk.parent_object_id = @object_id
FOR XML PATH(N''), TYPE).value('.', 'NVARCHAR(MAX)')), '')
+ ISNULL(((SELECT
CHAR(13) + 'CREATE' + CASE WHEN i.is_unique = 1 THEN ' UNIQUE' ELSE '' END
+ ' NONCLUSTERED INDEX [' + i.name + '] ON ' + @destinationObjectFullName + ' (' +
STUFF((
SELECT ', [' + c.name + ']' + CASE WHEN c.is_descending_key = 1 THEN ' DESC' ELSE ' ASC' END
FROM index_column c
WHERE c.is_included_column = 0
AND c.index_id = i.index_id
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + ')'
+ ISNULL(CHAR(13) + 'INCLUDE (' +
STUFF((
SELECT ', [' + c.name + ']'
FROM index_column c
WHERE c.is_included_column = 1
AND c.index_id = i.index_id
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + ')', '') + CHAR(13)
FROM sys.indexes i WITH (NOWAIT)
WHERE i.[object_id] = @object_id
--AND i.is_primary_key = 0
--AND i.[type] = 2
FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)')
), '')
-- Скрипт для переноса накопившихся данных в новую таблицу
SELECT
@SQLTRANSFER =
N'
INSERT INTO [' + CAST(@destinationSchemaName as nvarchar(max)) + '].[' + CAST(@destinationTableName as nvarchar(max)) + ']
(' +
STUFF(
(SELECT N',' + c.name
FROM
sys.columns AS c
INNER JOIN sys.types tp ON tp.system_type_id = c.system_type_id AND tp.user_type_id = c.user_type_id
WHERE
c.OBJECT_ID = OBJECT_ID(@tableNameFull)
AND NOT tp.name = 'timestamp'
ORDER BY
column_id
FOR XML PATH(''), TYPE).value('.',N'nvarchar(max)')
,1,1,N'')
+ N')
SELECT
' +
STUFF(
(SELECT N',' + c.name
FROM
sys.columns AS c
INNER JOIN sys.types tp ON tp.system_type_id = c.system_type_id AND tp.user_type_id = c.user_type_id
WHERE
c.OBJECT_ID = OBJECT_ID(@tableNameFull)
AND NOT tp.name = 'timestamp'
ORDER BY
column_id
FOR XML PATH(''), TYPE).value('.',N'nvarchar(max)')
,1,1,N'')
+ N'
FROM [' + CAST(@originalSchemaName as nvarchar(max)) + '].[' + CAST(@tablename as nvarchar(max)) + '];
';
-- Скрипт создания триггера для перенаправления потока данных в новую таблицу
SELECT
@SQLTRANSFERTRIGGER =
N'
CREATE TRIGGER [' + CAST(@originalSchemaName as nvarchar(max)) + '].[tr_AfterInsert_MoveToTable_' + CAST(@destinationTableName as nvarchar(max)) + ']
ON [' + CAST(@originalSchemaName as nvarchar(max)) + '].[' + CAST(@tablename as nvarchar(max)) + ']
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT INTO [' + CAST(@destinationSchemaName as nvarchar(max)) + '].[' + CAST(@destinationTableName as nvarchar(max)) + ']
(' +
STUFF(
(SELECT N',' + c.name
FROM
sys.columns AS c
INNER JOIN sys.types tp ON tp.system_type_id = c.system_type_id AND tp.user_type_id = c.user_type_id
WHERE
c.OBJECT_ID = OBJECT_ID(@tableNameFull)
AND NOT tp.name = 'timestamp'
ORDER BY
column_id
FOR XML PATH(''), TYPE).value('.',N'nvarchar(max)')
,1,1,N'')
+ N')
SELECT
' +
STUFF(
(SELECT N',' + c.name
FROM
sys.columns AS c
INNER JOIN sys.types tp ON tp.system_type_id = c.system_type_id AND tp.user_type_id = c.user_type_id
WHERE
c.OBJECT_ID = OBJECT_ID(@tableNameFull)
AND NOT tp.name = 'timestamp'
ORDER BY
column_id
FOR XML PATH(''), TYPE).value('.',N'nvarchar(max)')
,1,1,N'')
+ N'
FROM INSERTED;
END
';
-- Скрипт удаления триггера, если он существует перед созданием
SELECT
@SQLTRANSFERTRIGGERDROP = '
IF EXISTS (SELECT * FROM sys.objects
WHERE [name] = ''tr_AfterInsert_MoveToTable_' + CAST(@destinationTableName as nvarchar(max)) + '''
AND [type] = ''TR''
AND SCHEMA_NAME(schema_id) = ''' + CAST(@originalSchemaName as nvarchar(max)) + ''')
BEGIN
DROP TRIGGER [' + CAST(@originalSchemaName as nvarchar(max)) + '].[tr_AfterInsert_MoveToTable_' + CAST(@destinationTableName as nvarchar(max)) + '];
END;
';
-- Выполняем команды создания собственного объекта
EXECUTE sp_executesql @SQL
-- Создаем триггер для перенаправления изменений в собственную таблицу
EXECUTE sp_executesql @SQLTRANSFERTRIGGERDROP
EXECUTE sp_executesql @SQLTRANSFERTRIGGER
-- Затем переносим данные из исходной таблицы в созданную
EXECUTE sp_executesql @SQLTRANSFER
FETCH NEXT FROM tables_cursor INTO @tableName;
END
CLOSE tables_cursor;
DEALLOCATE tables_cursor;
END
GO
Процедура задокументирована в листинге. Основные шаги такие:
- Создается собственная таблица для хранения изменений.
- На штатную таблицу CDC создается триггер для перенаправления операций INSERT в нашу собственную, переопределенную таблицу.
- Из штатной таблицы переносятся накопившиеся изменения в переопределенную таблицу.
То есть на этом этапе у нас уже есть настройки и механизм переопределения потока данных об изменениях CDC. Осталось это как-то применить.
Применяем настройки
Сначала нужно определиться в какие моменты настройки CDC мы можем применять, а в какие нет. Реализуем самое простое условие - если идет обновление конфигурации информационной базы, то обновлять настройки CDC мы не должны. Почему? Потому что не хотелось бы во время рестурктуризации и "перезаливке" данных из старой таблицы в новую все эти данные в CDC зарегистрировать. Зачем?
Для проверки доступности обновления настроек сделаем процедуру.
-- Процедура позволяет определить доступность применения настроек CDC в данный момент
CREATE PROCEDURE [yy].[ApplySettingsCDCAvailable]
@availableResult int OUTPUT
AS
BEGIN
SET NOCOUNT ON;
-- Если в таблице сохраненной конфигуарции есть хоть одна запись,
-- то считаем, что идет обновление и никаких настроек CDC применять не нужно
SELECT
@availableResult = CASE WHEN COUNT(1) > 0 THEN 0 ELSE 1 END
FROM [dbo].[ConfigSave]
END
GO
Теперь при начале обновления информационной базы мы будем уверены, что CDC не будет включен для таблицы, пока реструктуризация перезаливает данные из старой версии таблицы.
Сама процедура применения настроек CDC будет выглядеть так.
-- Применение настроек CDC по настройкам из таблицы MaintenanceSettingsCDC
CREATE PROCEDURE [yy].[ApplySettingsCDC]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@settingId int,
@schemaName nvarchar(255),
@tableName nvarchar(255),
@useCDC bit,
@schemaNameCDC nvarchar(255),
@tableNameCDC nvarchar(255),
@tableNameCDCHistory nvarchar(255),
@captureInstanceCDC nvarchar(255),
@tableObjectId int,
@tableSchemaLastChangeDate datetime2(0),
@availableResult int;
-- Проверяем, доступно ли применение настроек CDC в данный момент
EXECUTE [yy].[ApplySettingsCDCAvailable]
@availableResult OUTPUT
IF(@availableResult = 0)
BEGIN
RETURN 0;
END
-- Получаем все активные настройки
DECLARE settingsCursor CURSOR
FOR SELECT
[ID]
,[SchemaName]
,[TableName]
,[UseCDC]
,[SchemaNameCDC]
,[TableNameCDC]
,[TableNameCDCHistory]
,[CaptureInstanceCDC]
,[TableObjectId]
,[TableSchemaLastChangeDate]
FROM [yy].[MaintenanceSettingsCDC]
WHERE [UseCDC] = 1;
OPEN settingsCursor;
FETCH NEXT FROM settingsCursor
INTO @settingId, @schemaName, @tableName, @useCDC,
@schemaNameCDC, @tableNameCDC, @tableNameCDCHistory,
@captureInstanceCDC, @tableObjectId, @tableSchemaLastChangeDate;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Проверяем, доступно ли применение настроек CDC в данный момент
EXECUTE [yy].[ApplySettingsCDCAvailable]
@availableResult OUTPUT
IF(@availableResult = 0)
BEGIN
RETURN 0;
END
-- Получаем текущие данные о таблице:
-- * Используется для нее CDC
-- * Идентификатор объекта
-- * Дата последнего изменения объекта
DECLARE
@currentCDCEnabled bit = 0,
@currentTableObjectId int,
@currentTableSchemaLastChangeDate datetime2(0);
SELECT
@currentCDCEnabled = tb.is_tracked_by_cdc,
@currentTableObjectId = tb.object_id,
@currentTableSchemaLastChangeDate =
CASE WHEN create_date > modify_date THEN create_date
ELSE modify_date
END
FROM sys.tables tb
INNER JOIN sys.schemas s
on s.schema_id = tb.schema_id
WHERE s.name = @schemaName AND tb.name = @tableName
-- Вариант действий если CDC для объекта уже включен
IF(@currentCDCEnabled = 1)
BEGIN
PRINT 'Для таблицы уже используется CDC: ' + @tableName
-- Есть изменения в структуре таблицы или объект был пересоздан,
-- то нужно пересоздать объекты CDC
IF(-- Структура таблицы изменилась
(NOT ISNULL(@tableSchemaLastChangeDate, CAST('2000-01-01 00:00:00' AS datetime2(0))) = @currentTableSchemaLastChangeDate)
OR
-- Идентификатор базы данных изменился
(NOT ISNULL(@tableObjectId,0) = @currentTableObjectId))
BEGIN
PRINT 'Зафиксировано изменение таблицы. Пересоздаем настройки CDC: ' + @tableName
-- Отключение CDC для таблицы
EXEC [sys].[sp_cdc_disable_table]
@source_schema = @schemaName
,@source_name = @tableName
,@capture_instance = @captureInstanceCDC
-- Включаем CDC заново
EXEC sys.sp_cdc_enable_table
-- Схема исходной таблицы
@source_schema = @schemaName,
-- Имя исходной таблицы
@source_name = @tableName,
-- Имя роли для доступа к данным изменений оставляем по умолчанию
@role_name = NULL,
-- Поддержку запросов для суммарных изменений не используем,
-- чтобы снизить размеры таблиц CDC и иметь возможность его использования,
-- даже если у таблицы нет уникального ключа
@supports_net_changes = 0;
-- Остальные параметры не используются, т.к. не нужны явно
-- Имя уникального индекса для идентификации строк (не обязателен)
--@index_name = N'<index_name,sysname,index_name>',
-- Файловая группа для хранения таблиц изменений (не обязателен)
--@filegroup_name = N'<filegroup_name,sysname,filegroup_name>'
-- Обновляем служебные поля настроек CDC
EXECUTE [yy].[UpdateServiceMaintenanceSettingsCDC]
@settingId,
@schemaNameCDC OUTPUT,
@tableNameCDC OUTPUT,
@tableNameCDCHistory OUTPUT,
@captureInstanceCDC OUTPUT;
-- Переопределяем поток изменений из стандартной таблицы CDC в собственную
EXECUTE [yy].[OverrideDataFlowForCDC]
@settingId
PRINT 'Для таблицы включен CDC: ' + @tableName
END
END ELSE -- Вариант действий, если CDC для объекта еще не был включен
BEGIN
-- Включаем CDC для таблицы, т.к. ранее он не был включен
EXEC sys.sp_cdc_enable_table
-- Схема исходной таблицы
@source_schema = @schemaName,
-- Имя исходной таблицы
@source_name = @tableName,
-- Имя роли для доступа к данным изменений оставляем по умолчанию
@role_name = NULL,
-- Поддержку запросов для суммарных изменений не используем,
-- чтобы снизить размеры таблиц CDC и иметь возможность его использования,
-- даже если у таблицы нет уникального ключа
@supports_net_changes = 0;
-- Остальные параметры не используются, т.к. не нужны явно
-- Имя уникального индекса для идентификации строк (не обязателен)
--@index_name = N'<index_name,sysname,index_name>',
-- Файловая группа для хранения таблиц изменений (не обязателен)
--@filegroup_name = N'<filegroup_name,sysname,filegroup_name>'
-- Обновляем служебные поля настроек CDC
EXECUTE [yy].[UpdateServiceMaintenanceSettingsCDC]
@settingId,
@schemaNameCDC OUTPUT,
@tableNameCDC OUTPUT,
@tableNameCDCHistory OUTPUT,
@captureInstanceCDC OUTPUT;
-- Переопределяем поток изменений из стандартной таблицы CDC в собственную
EXECUTE [yy].[OverrideDataFlowForCDC]
@settingId
PRINT 'Для таблицы включен CDC: ' + @tableName
END
FETCH NEXT FROM settingsCursor
INTO @settingId, @schemaName, @tableName, @useCDC,
@schemaNameCDC, @tableNameCDC, @tableNameCDCHistory,
@captureInstanceCDC, @tableObjectId, @tableSchemaLastChangeDate;
END
CLOSE settingsCursor;
DEALLOCATE settingsCursor;
-- Обрабатываем настройки, для которых настройка CDC выключена или отсутствует (при этом CDC включен для объекта).
-- CDC для них должен быть выключен
DECLARE
@deleteSchamaName nvarchar(255),
@deleteTableName nvarchar(255),
@deleteCaptureInstance nvarchar(255);
-- Список объектов, для которых CDC включен, но при этом
-- настройки в таблице MaintenanceSettingsCDC нет
DECLARE disableCDCObjectsCursor CURSOR
FOR
SELECT
SCHEMA_NAME(o.schema_id) AS [SchemaName]
,OBJECT_NAME(ct.[source_object_id]) AS [TableName]
,[capture_instance]
FROM [cdc].[change_tables] ct
LEFT JOIN sys.objects o
ON ct.source_object_id = o.object_id
LEFT JOIN [yy].MaintenanceSettingsCDC st
ON SCHEMA_NAME(o.schema_id) = st.SchemaName
AND OBJECT_NAME(ct.[source_object_id]) = st.TableName
AND st.UseCDC = 1
WHERE st.ID IS NULL
OPEN disableCDCObjectsCursor;
FETCH NEXT FROM disableCDCObjectsCursor
INTO @deleteSchamaName, @deleteTableName, @deleteCaptureInstance;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Проверяем, доступно ли применение настроек CDC в данный момент
-- Этот момент описан ниже
EXECUTE [yy].[ApplySettingsCDCAvailable]
@availableResult OUTPUT
IF(@availableResult = 0)
BEGIN
RETURN 0;
END
PRINT 'Отключение CDC для таблицы, т.к. настройка уже не актуальна: ' + @deleteTableName
-- Отключение CDC для таблицы
EXEC [sys].[sp_cdc_disable_table]
@source_schema = @deleteSchamaName
,@source_name = @deleteTableName
,@capture_instance = @deleteCaptureInstance
FETCH NEXT FROM disableCDCObjectsCursor
INTO @deleteSchamaName, @deleteTableName, @deleteCaptureInstance;
END
CLOSE disableCDCObjectsCursor;
DEALLOCATE disableCDCObjectsCursor;
END
GO
Общий алгоритм такой:
- Получаем настройки CDC из таблицы MaintenanceSettingsCDC и обходим каждую.
- Проверяем включен ли CDC для объекта.
- Если включен, то:
- Проверяем изменилась ли схема объекта или объект был полностью пересоздан
- Включаем CDC
- Обновляем служебные настройки
- Переопределяем поток данных
- Если выключен, то просто включаем:
- Включаем CDC
- Обновляем служебные настройки
- Переопределяем поток данных
- Отключаем настройку CDC у объектов, для которых нет активной записи в таблице MaintenanceSettingsCDC.
Для применения настроек достаточно вызвать:
EXECUTE [yy].[ApplySettingsCDC]
GO
И дело сделано!
Сопровождать и остаться в живых
Инфраструктура готова, но не запускать же это каждый раз вручную? Правильно!
Проще всего создать задание (Job) и запускать актуализацию настроек CDC раз в 15 секунд, например. Это решит большинство кейсов в части включения CDC во время изменения структуры базы данных после обновления.
Скрипт создания задания смысла приводить нет. Главное сделайте расписание раз в 15 секунд и вызывайте процедуру:
EXECUTE [yy].[ApplySettingsCDC]
GO
Вот и все сопровождение. Или не все?
Для мониторинга работы CDC можно использовать стандартный журнал логов SQL Server и историю работы заданий в SQL Server Agent. В остальном ничего особого не нужно.
Используем в своих целях
Мы все настроили, все работает. Но что это нам дает и как это использовать?
Шаг за шагом
Проведем небольшой тест. Например, у нас есть документ "Реализация товаров" из демобазы БСП. На стороне базы данных он представлен таблицами:
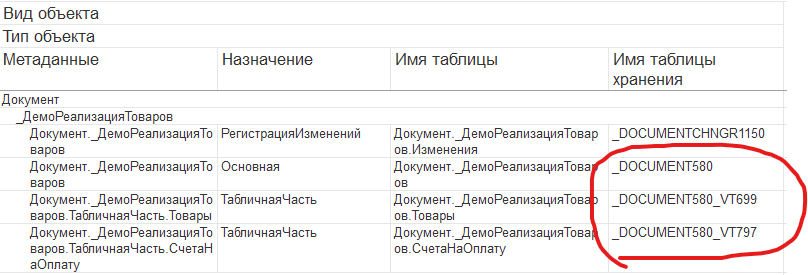
Включим для этих таблиц CDC через настройки.

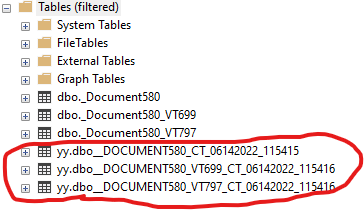
Как видно, заполнили только 3 поля. Как только задание применения настроек CDC отработает, то картина изменится на следующую.

При этом в схеме "yy" добавлены переопределенные таблицы.
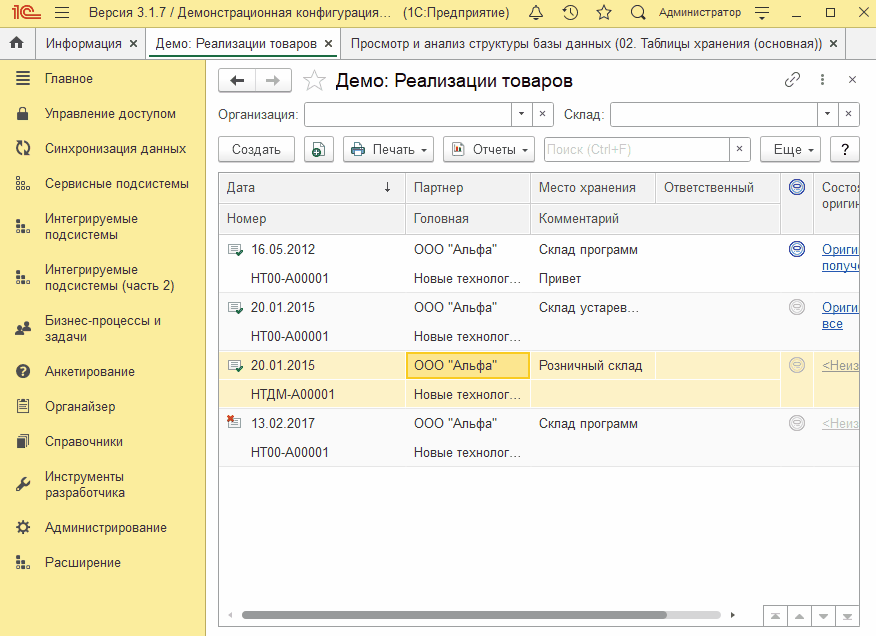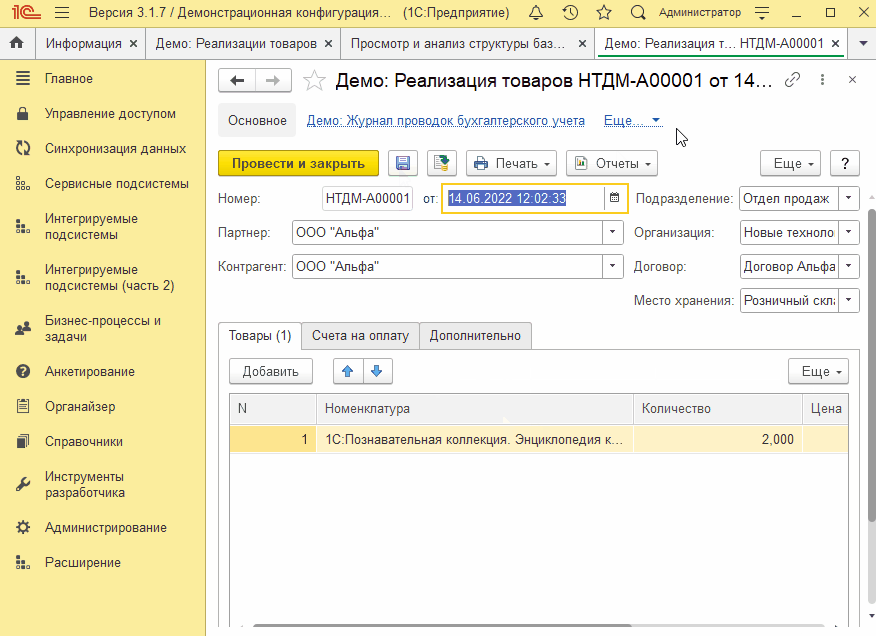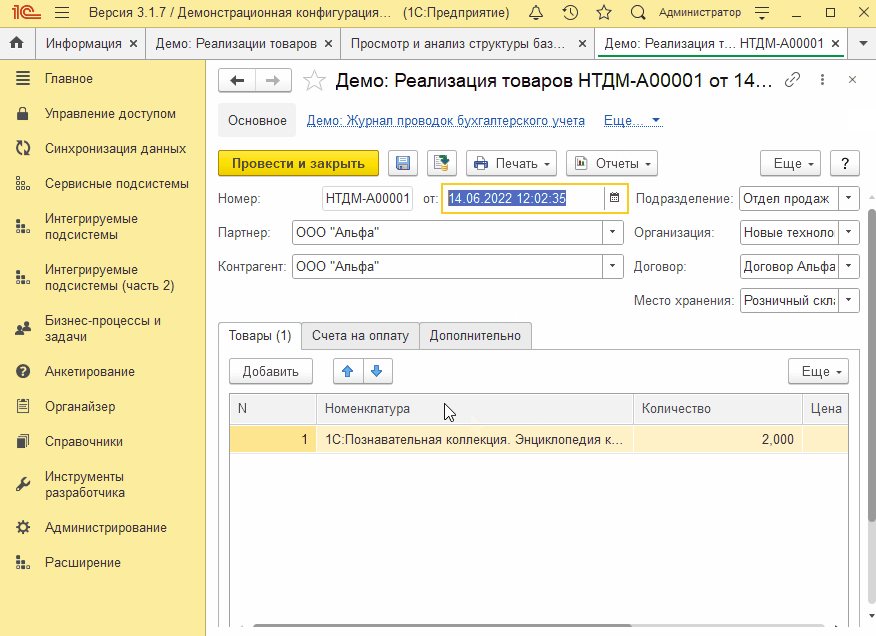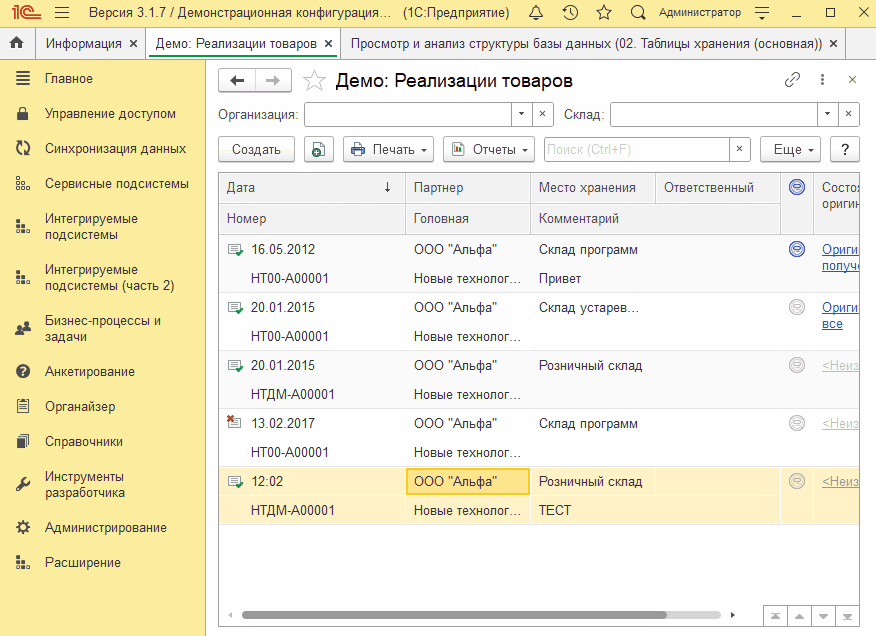
Теперь зайдем на сторону клиента 1С и добавим новый документ через копирование, а после сразу же внесем в него небольшое изменение.
Как Вы думаете, сколько транзакций базы данных мы увидим? Ответ простой: 3:
- Первая транзакция (идентификатор 0x000000AF0000AAA80008) - это добавление новых записей в таблицы. Документ в этот момент был записан без проведения. Данные в документе были только в шапке и в таб. части "Товары", поэтому таблица для счетов на оплату пустая. Вот такие записи в таблице логов изменений.
Изменения в первой транзакции
Сверху таблица шапки, снизу таб. часть товаров.

- Вторая транзакция (идентификатор 0x000000AF0000AB38000A) - это проведение документа. Фактически было изменено только поле "Проведен" (_Posted).
Изменения во второй транзакции
- Третья транзакция (идентификатор 0x000000AF0000AD500074) - обновление поля "Комментарий". В таблице изменений представлена также двумя записями UPDATE и с единственным измененным полем.
Изменение в третьей транзакции
Таким образом, мы имеем детальную информацию об изменениях документа на каждом шаге, по каждому полю.
Кратко: где используется
В самом начале статьи мы уже говорили, где это может пригодиться. После наглядного примера регистрации изменений должно было стать понятней:
- Версионирование - у нас хранятся версии всех изменений в базе и при этом в разрезе транзакций. Если одна транзакция изменяет множество документов или других объектов, то связь между этими изменениями не трудно найти.
- Аудит - информация об изменениях у нас есть, но кто их изменил. Т.к. история изменений сохраняется на уровне базы данных, то у нас нет контекста приложения. То есть нет пользователя приложения. Тут есть два варианта:
- По времени изменения легко найти записи о действиях пользователя в журнале регистрации.
- Или можно в объектах 1С сохранять поля "Создал", "Дату создания", "Изменил" и "Дату изменения", где у нас будет дата события и ссылка на пользователя. Тогда контекст приложения будет доступен и на стороне базы данных.
- Или другие подобные варианты.
- Отправка изменений при интеграции. Если в базе у нас есть таблицы с историей изменений, то можно эту информацию использовать для отправки измененных объектов в другие системы. Сценариев много, один из низ - это присоединить Kafka, которая будет забирать себе данные об изменениях и отправлять подписчикам. Надежный и понятный способ интеграции. Но это только один небольшой пример.
Статья слишком маленький формат, чтобы сразу здесь описать как присоединять Kafka или как удобно из 1С читать таблицы изменений CDC. Но основной посыл должен быть ясен.
Зачем, если можно не использовать
Незачем! Если Вы не видите плюсов в применении механизма регистрации данных, то скорее всего вам это и не нужно. Аналогичный подход можно использовать и для баз PostgreSQL, но со своими нюансами. По этому поводу можно прочитать интересную статью.
Если же штатные инструменты регистрации и обмена Вас не устраивают, а построить DWH в связке с 1С - для Вас большая боль, то CDC может стать отличным стартом. Далее можно развивать использование этого механизма, добавить новые инструменты очередей и аналитики и вот появится новый уровень развития информационных систем.
P.S. Спасибо, что дочитали! Всем добра!
Другие ссылки
Авторские разработки
Другие разработки (бесплатные и за $m)
















