Я сегодня расскажу не обо всем, что нового появилось в Postgres, но о том, что в последних версиях, по моим представлениям, может быть полезным и интересным для 1С-ников.
Приблизительно 14 лет назад фирма «1С» начала поддерживать Postgres, и это – очень хорошо. Можно порадоваться провидческой мудрости руководства фирмы и лично Бориса Нуралиева, который обратился в свое время к моим коллегам, разработчикам Postgres, чтобы сдружить эти две могучие экосистемы. Благодаря этому из 1С сейчас можно прекрасно работать на Postgres.
Платформа 1С сейчас развивается навстречу Postgres – все лучше и лучше работает на нем. И Postgres тоже развивается – всем нам от этого хорошо.

Лично я с Postgres знаком очень давно, с 1999 г., при этом сам являюсь скорее не разработчиком (написал только несколько патчей), а прикладным пользователем – в течение большого количества лет разрабатывал на PostgreSQL очень много разных систем. И когда в 2015-м году мы создали компанию Postgres Professional, я стал одним из ее соучредителей.
PostgreSQL и Postgres Pro: как правильно называются

Любой доклад по Postgres правильнее всего начать с разъяснения, почему он так называется.
Существует заблуждение, что PostgreSQL – это Postgre и SQL. Очень многие люди, которые много используют Postgres, хорошо в нем разбираются, называют его Postgre. Но такого слова нет.
У этого продукта есть два общепринятых названия – PostgreSQL или просто Postgres (он так назывался изначально, до 1996 года).
Когда придумывали название PostgreSQL, народ уже тогда сомневался, что его будет удобно произносить – и там произошло слияние букв, свойственное для английского языка.
А наша компания называется Postgres Pro, а не PostgreSQL Pro, потому что это по-русски было бы вообще не произнести.
PostgreSQL 14

Теперь к сути.
PostgreSQL 14 вышел в конце 2021 года, и все мы им уже активно пользуемся. Он оказался заметно быстрее, чем предыдущие версии, хотя, возможно, вы и не видите этой разницы. PostgreSQL и так уже достаточно быстр, и те оптимизации и ускорения, которые в нем появляются, проявляются не всегда, а в каких-то конкретных случаях – их у вас может не быть.
Или, если у вас маленькая база, вы можете не заметить этих проблем. Но дальний конец (Hi End) всегда упирается в определенные проблемы производительности – и их разработчики решают в первую очередь.
На слайде приведен грубый список того, что было реализовано для PostgreSQL 14 и, вероятно, относится к 1С. Сейчас я хочу чуть детальнее рассказать про все эти вещи.
И потом еще расскажу про 15-й PostgreSQL, потому что там тоже появились интересные штуки, которые 1С-никам могут пригодиться.
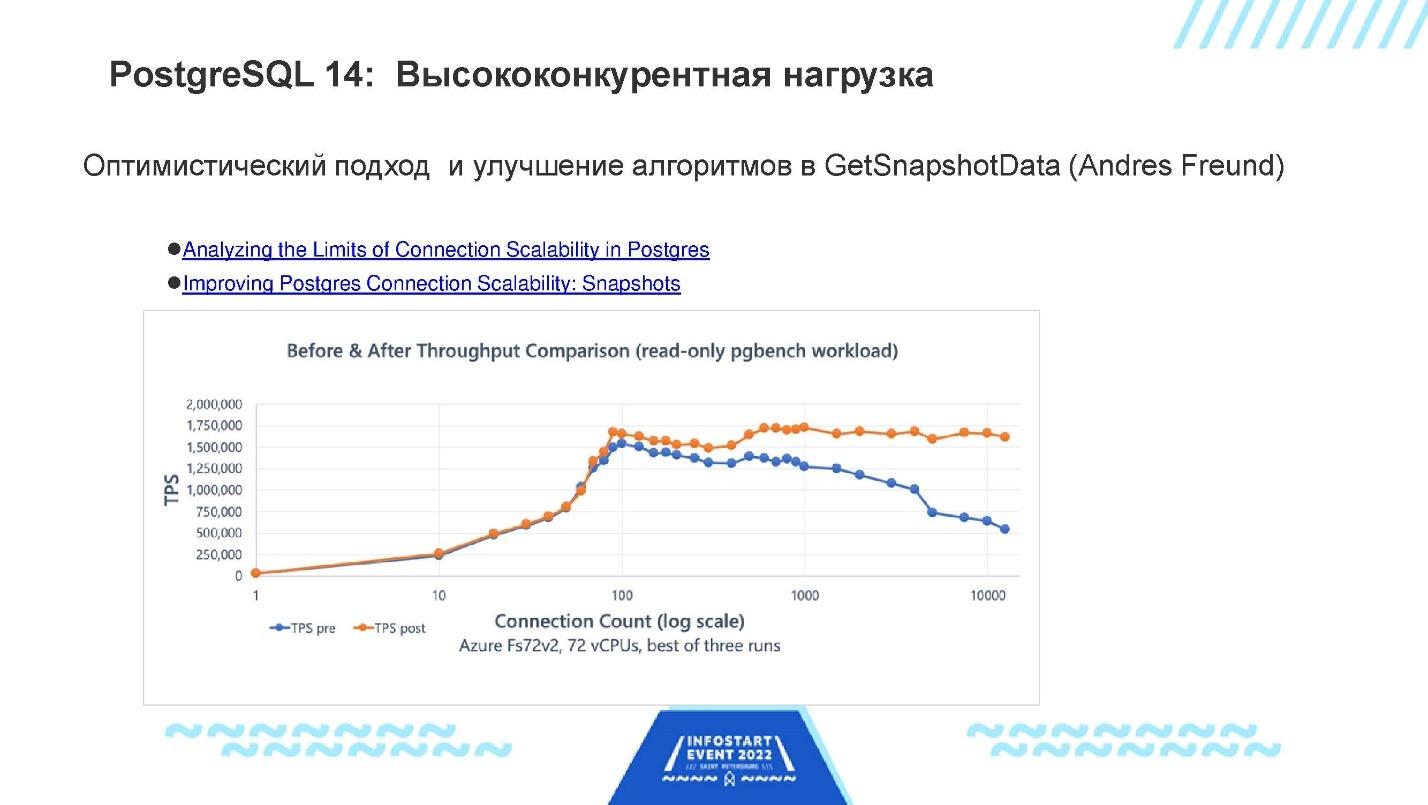
Высококонкурентная нагрузка. Первый и, с моей точки зрения, самый важный патч, который вошел в состав PostgreSQL 14 – это патч Андерса Фройнда для того, чтобы ускорить получение снапшота в базе.
Снапшотом в PostgreSQL называют описание текущего состояния базы. Снапшот – это текущее состояние базы с точки зрения взаимной видимости транзакций, т.е.информация о том наборе (м.б. большом) транзакций, которые одновременно исполняются в настоящий момент. Чтобы понять, какие версии записей одна данная транзакция должна видеть, нужно иметь представление о том, какие транзакции вообще в это время существуют, в каком они состоянии – какие уже закоммичены, а какие – нет.
Совокупно все это называется снапшот. И вычисление снапшота – это довольно трудная операция, когда действует параллельно много транзакций, много сессий. Разработчики постгреса всё время пытаются оптимизировать эту операцию.
И Андерс Фройнд в данном случае очень глубоко проанализировал все эти алгоритмы и описал свои выводы в статьях:
Там можно почитать, как он к этому шел.
На слайде приведен график результата. По горизонтальной оси – количество соединений, а по вертикальной оси – количество транзакций в секунду в простом read-only-тесте, который фактически ничего не ищет в базе, а только получает снапшот.
Видно, что PostgreSQL 14 стал лучше работать с большим количеством соединений. А с маленьким – ничего не поменялось.
Это очень большое достижение, и оно некоторым нашим заказчикам сильно помогло на 50%-100% поднять скорость работы PostgreSQL при большом количестве соединений.
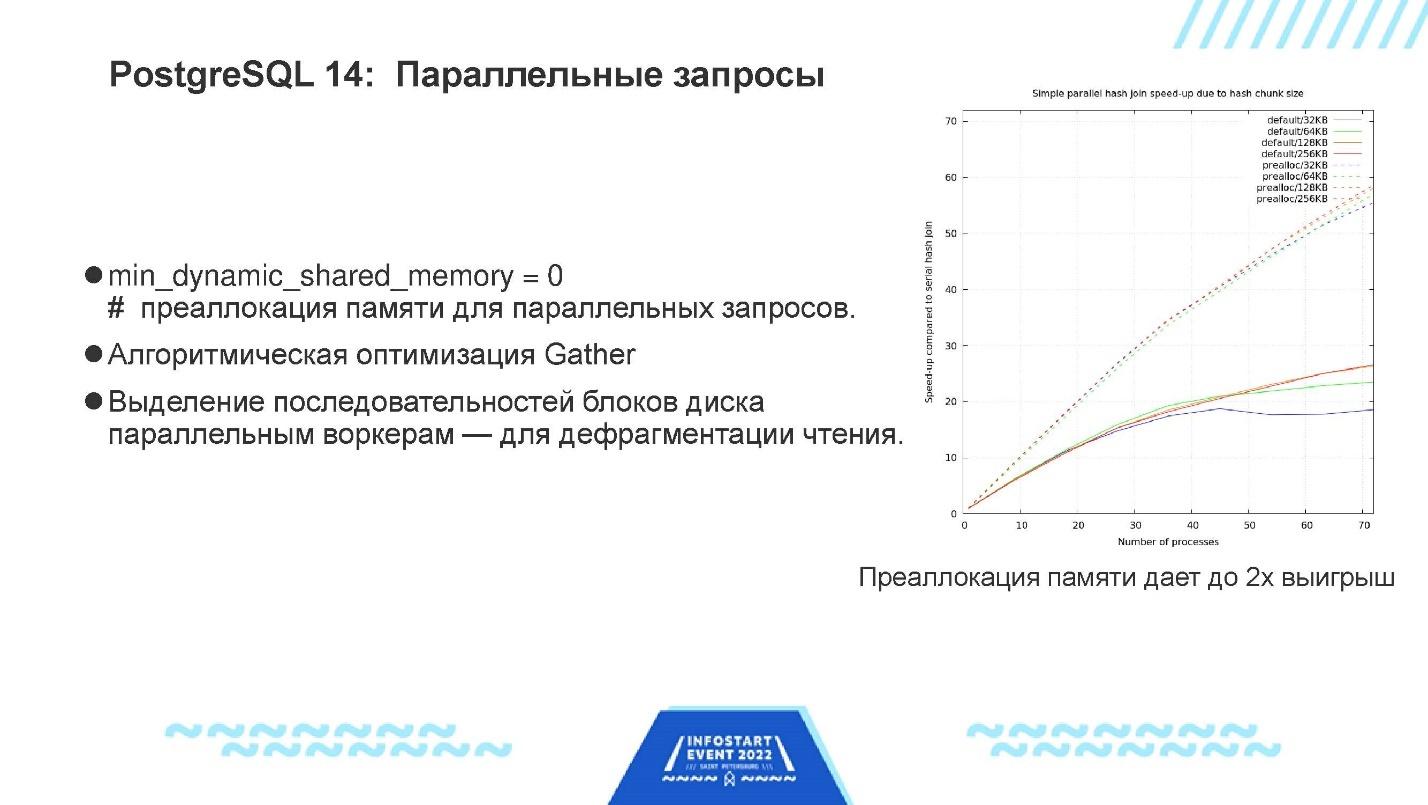
Параллельные запросы.
-
Появилась возможность предварительно выделять память для использования в параллельных запросах. Это – память, через которую отдельные воркеры обмениваются между собой данными. Никто не ожидал от этой возможности заметного эффекта, но оказалось, что здесь очень легко получить выигрыш примерно в два раза.
-
В 14-м PostgreSQL есть и другие оптимизации, связанные с параллельными запросами. Например, раньше, когда несколько воркеров читали одну и ту же таблицу, им выделялись отдельные несвязанные куски этой таблицы, что заставляло их читать ее хаотическим образом, не подряд. А когда из памяти читаешь не подряд, это всегда медленнее, чем подряд. Поэтому сейчас им выделяются большие куски, каждый из которых читается подряд, чтобы чтение было менее фрагментированным.
Все это в совокупности дает достаточно большой выигрыш для параллельного исполнения запросов.
Напомню, что параллельное исполнение запросов помогает для больших аналитических долго идущих запросов. Для них есть смысл распараллелить вычисления, потому что в этом случае обмен данными между отдельными воркерами не является большим оверхедом, который сильно замедлит запрос.
Т.е. понятно, что маленькие запросы, которые достают из базы одну-две записи, параллелить не стоит. А вот большие запросы от параллелизима хорошо выигрывают.
График на слайде – аналогичный. Здесь по горизонтали – количество процессов, которые исполняют данный конкретный запрос. А по вертикали – производительность. Те кривули, которые идут выше всего – это новая 14-я версия с преаллокацией памяти и всеми остальными фичами.
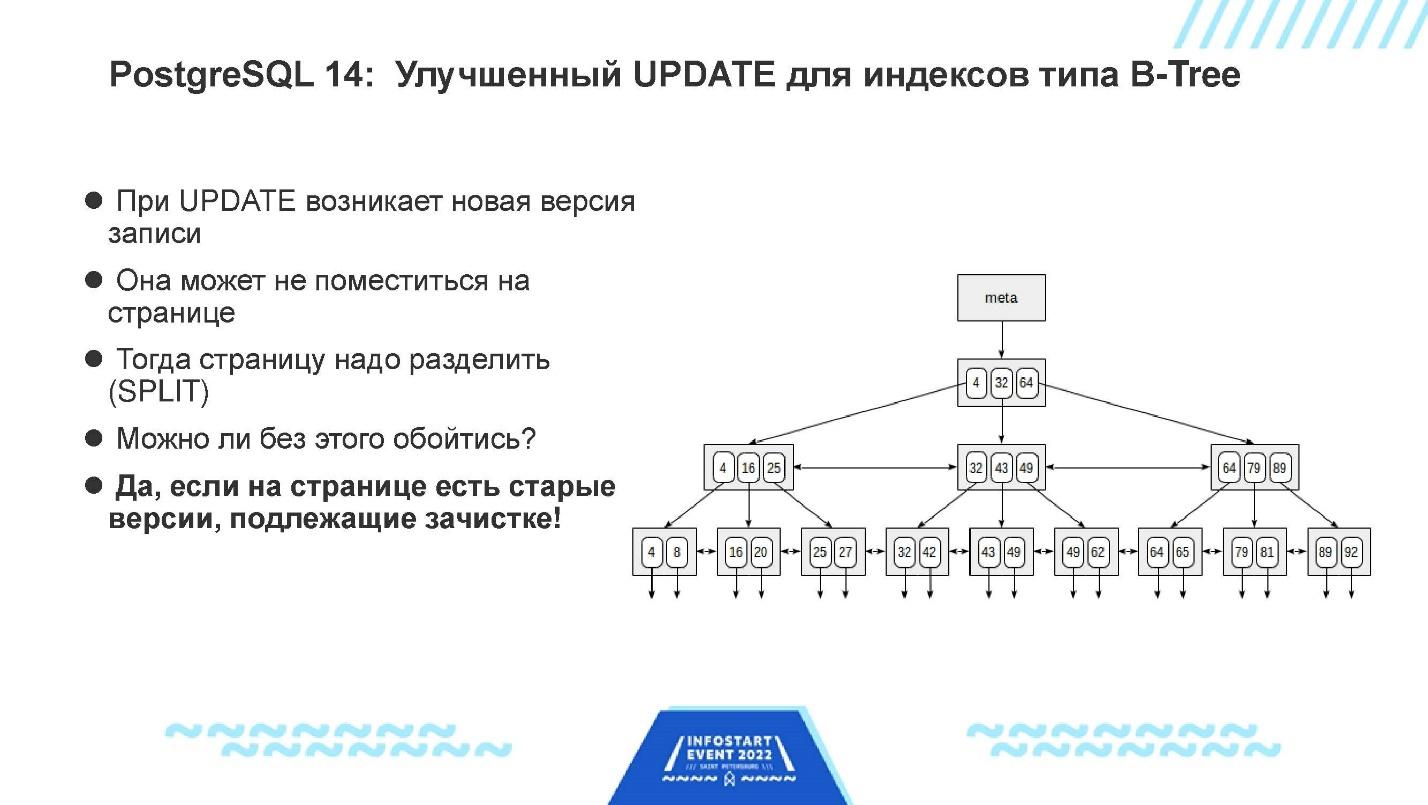
Оптимизация UPDATE – это еще одна важная вещь, которая появилась в 14-м PostgreSQL.
На картинке – схематическое изображение B-дерева (основной тип индекса, который используется в PostgreSQL чаще всего).
Когда мы апдейтим запись, для нее возникает новая версия, которая с большой долей вероятности где-то попадает в индекс.
Для PostgreSQL существует HOT (Heap only tuples) оптимизация, когда при апдейте записи новой вставки в индекс не происходит. Но предположим, что эта оптимизация не сработала – новая версия возникает и вставляется в индекс.
Индекс состоит из отдельных страниц – как и все в PostgreSQL. И если, например, мы не уместились на страницу, происходит операция SPLIT, когда страница индекса раздвигается на две – в ней становится больше узлов.
Понятно, что индекс при этом распухает – в нем добавляется целая страница. Причем, может быть, он распухает зря, потому что старую неактуальную версию записи через некоторое время удалят, но лишняя страница в индексе уже есть. И получается, что размер индекса все время чуть больше, чем нужно. Это не очень хорошо.
Поэтому появилась новая интересная оптимизация, которая прежде, чем раздвинуть индекс, выполняет конкретно для этой страницы операцию вакуума. Она смотрит – есть ли на текущей странице записи, которые уже подлежат удалению. Если они есть, она их удаляет, после чего на странице появляется место, и, если его хватает, SPLIT не происходит.
Благодаря этого индекс не растет, дисковых операций меньше, и индекс меньше. Поэтому и поиск по нему производится быстрее.
Эта штука очень помогает, если у вас большая апдейтовая нагрузка – много раз апдейтятся одни и те же записи.

Кеширование Nested Loop в памяти. Эта возможность – более туманная, потому что она срабатывает только для некоторых типов запросов. В реальной жизни мы крайне редко попадаем в ситуацию, когда это срабатывает.
Но это – еще одна новая операция, которая совершается исполнителем запросов, когда он обрабатывает узлы (ноды) в дереве запроса. Напоминаю - для исполнения SQL-запроса он компилируется в дерево, узлы которого – это отдельные операции.
В 14-й версии появилась новая операция, которую назвали ResultCache, потом поняли, что это название слишком общее, поэтому в 15-й версии ее переименовали в Memoize. Так называется операция, когда при выполнении в запросе Nested Loop (вложенного цикла) мы кешируем результаты промежуточных вычислений.
На слайде приведен пример простого запроса с SELECT из таблиц customer и issue, в котором JOIN делается с помощью Nested Loop (вложенного цикла). Запрос обходит в цикле все записи внешней таблицы customer, и для каждого элемента таблицы customer ищется подходящий ему issue.
Этот запрос может выполняться двумя способами – либо мы сканируем вначале customer, а потом для него ищем issue, либо наоборот – вначале issue, а потом для него находим customer. Планировщик выбирает, что из этого эффективнее.
В данном примере планировщик нам подобрал, что эффективнее вначале идти по issue, для него по ID искать customer и результат запоминать в кэш памяти с помощью операции Memoize.
Важно, что Memoize работает в памяти, в отличие от варианта Hash Join, когда вначале строится хэш таблицы, а потом из нее уже по ключу все выбирается. Здесь кэш строится по ходу исполнения запроса – только в том случае, если известно, что результат поместится в память. Если результат в память не помещается, смысла в этом алгоритме уже никакого нет, это не быстро – то же самое, что и просто достать по индексу.
Иногда помогает. Есть специальный параметр, которым такое кеширование можно отключить. По умолчанию оно включено. Есть встретится в плане запроса слово Memoize – не пугайтесь, это сработала новая фишка. Возможно, она вам поможет.

Возможность бесшовно перенести индекс в другое табличное пространство – еще одна полезная вещь для админов баз.
В PostgreSQL есть ключевое слово CONCURRENTLY, которое означает, что операция совершается без блокировок, легко и незаметно, на фоне всего остального. С 14-го PostgreSQL вы можете в таком режиме произвести реиндексацию так, что новый индекс будет в другом табличном пространстве.
Т.е. если у вас кончается место на диске, вы можете сразу строить индекс на другом диске, который вы принесли и подключили – построить индекс в нем. И это можно делать в режиме CONCURRENTLY – без каких-либо дополнительных блокировок.
Раньше вы могли переносить индекс с помощью команд:
ALTER INDEX SET TABLESPACE
или даже ALTER TABLE SET TABLESPACE (перенести вместе с таблицей)
Но эти варианты плохие, потому что они блокируют вам этот индекс (или эту таблицу, что практически то же самое). И эти блокировки длятся все время, пока у вас происходит операция. Это может быть долго.
Начиная с PostgreSQL 14 вы это можете делать совершенно незаметно, прозрачно и бесшовно, в режиме CONCURRENTLY.
Для предыдущих версий PostgreSQL есть расширение pg_squeeze – кто не боится, может с его помощью те же операции проделывать.

Другие новые бесшовные операции, которые появились в PostgreSQL 14 – это:
Возможность отцеплять партицию от партицированной таблицы. Фактически, таблица отцепляется, когда она уже никому не нужна. Просто она дожидается, пока завершатся все транзакции, которые использовали находящиеся в этой партиции записи или версии записей.
Кроме этого, теперь вы можете запускать одновременно несколько конкурентных операций по разным таблицам. Раньше в режиме CONCURRENTLY можно было делать только одну операцию одновременно – например, только один конкурентный реиндекс.
Wraparound: решение проблемы выхода за пределы кольца времени
Теперь я должен напомнить вам о Wraparound – это одна из больших проблем PostgreSQL, которая связана с тем, что у тех, кто реализовывал PostgreSQL, были другие приоритеты. Очень многое из того, что есть в PostgreSQL сейчас, связано с теми или иными решениями, которые были приняты еще 30 лет назад. Может быть, с точки зрения современности они кажутся нам неправильными – знай мы тогда то, что будет сейчас, мы бы сделали по-другому, были бы мудрее Стоунбрейкера и его последователей. Но они жили тогда и знали то, что тогда было известно.
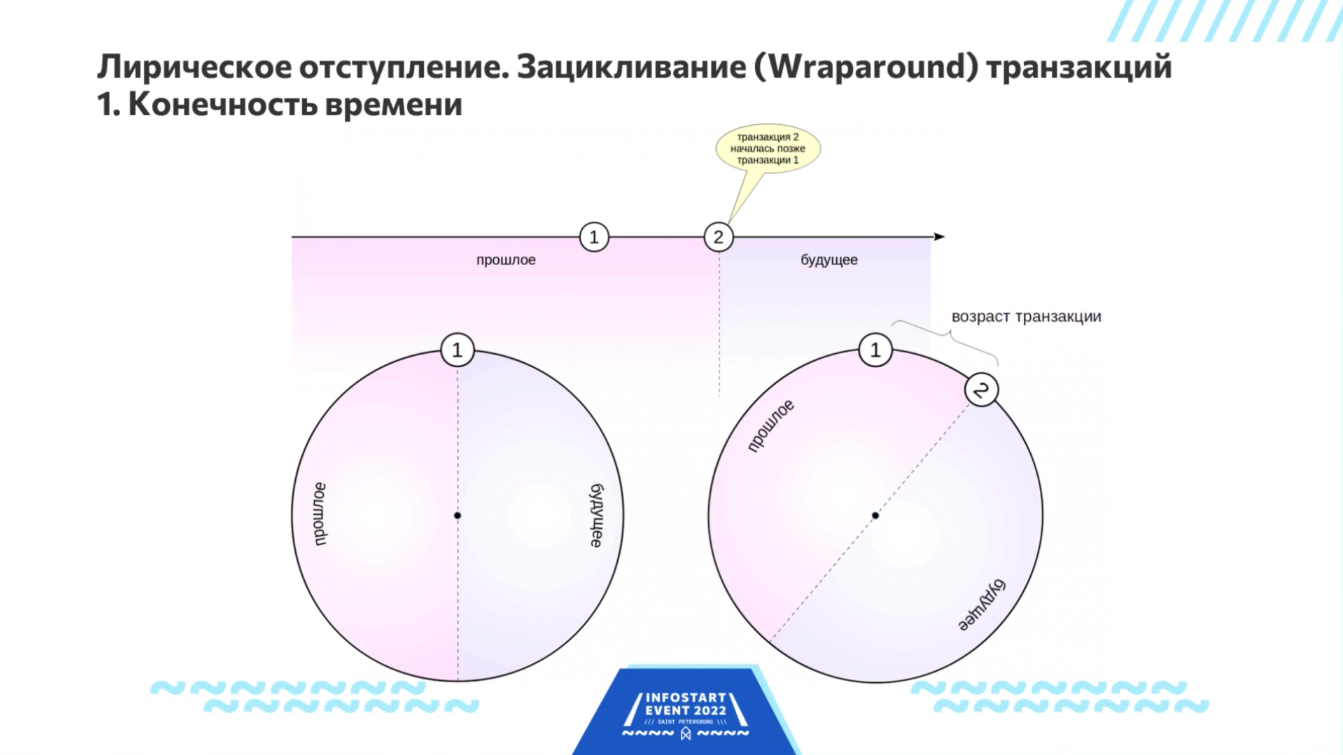
Итак, в PostgreSQL есть проблема зацикливания транзакций. Она связана с тем, что есть прошлое и будущее. Транзакции идут, завершаются, у каждой версии записи есть область видимости, которая прописана во времени.
В реальности, время бесконечное, но в PostgreSQL для обозначения времени и нумерации транзакций используются 32-битные числа, которые, конечно, небесконечны – образуют так называемую циклическую группу, когда вы прибавляете к самому большому числу единицу и получаете самое маленькое число. Так нужно делать, потому что иначе через миллиард транзакций у вас все встанет колом - упрётся в стену недостижимого будущего. Чтобы оно колом не становилось, время пришлось зациклить.
Стрелка этого времени крутится по кругу. И считается, что половина этого круга, где находятся номера транзакций справа от текущего момента – это будущее, а та половина, которая находится слева от текущего момента – это прошлое. И так постепенно это все крутится.
С другой стороны, если какая-то транзакция существует очень давно, она может из прошлого переползти в будущее. И это нехорошо.
Этот эффект называется Wraparound или зацикливание – когда транзакция из прошлого, которая уже завершилась, вдруг оказывается в будущем. В этой ситуации PostgreSQL говорит – я больше не могу работать.
Подобная ситуация возникает, когда у вас транзакция открылась, и ждет, пока два миллиарда транзакций пройдет, чтобы попасть из прошлого в будущее. Такое редко, но бывает, если есть еще какие-то причины, по которым прошлое у нас не может быть забыто. Точнее - заморожено.
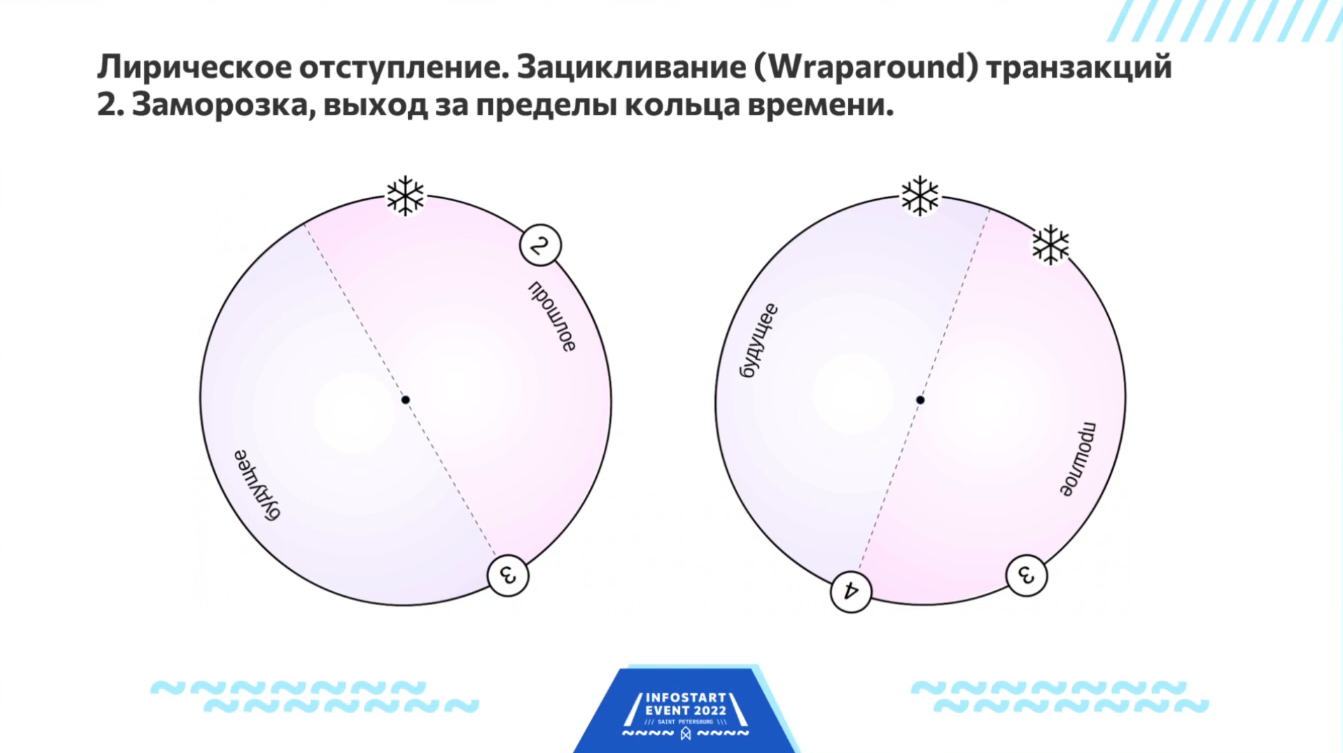
Чтобы при выходе за пределы кольца времени прошлое не исчезало совсем, происходит так называемый FREEZE (заморозка).
Помимо прошлого, которое отображается на нашем циферблате, есть еще абсолютное прошлое. FREEZE – это перенос относительного прошлого, которое умещается на циферблате, в абсолютное прошлое, которое «заморожено».
Какие-то версии записей помечаются как замороженные, это значит, что они всегда в прошлом, какой бы номер транзакций у них ни был. Это – одна из функций Vacuum, процесса непрерывного обслуживания базы – он удаляет старые версии записей, ставшие ненужными после завершения транзакций, работавших с ними,, а нужные версии, остающиеся в прошлом – замораживает, т.е. объявляет, что они в прошлом всегда и для них уже не страшно, что циферблат прокрутится.
Чтобы Wraparound не было, вам нужно, чтобы Vacuum всегда успевал подходить и делать этот FREEZE – замораживать старые записи.

В PostgreSQL 14, чтобы Wraparound не наступал так скоро, с такой неотвратимостью, на помощь приходит некоторые дополнительные настройки, которые подсказывают серверу, что если Wraparound близко, т.е. если этот циферблат подкручивается, т.е. прошлое уже подступает к будущему, нужно проводить autovacuum активнее. Он перестает делать какие-то менее срочные задачи и сосредотачивается на том, чтобы замораживать все больше и больше записей.
Он должен успеть «зафризить» (заморозить) нужные записи, пока вы не достигли «предела будущего» – есть специальные параметры vacuum_failsafe_age и vacuum_multixact_failsafe_age, которые управляют тем, насколько активно он это делает.

Статистика по выражениям на таблицах – не знаю, используются ли в 1С хранимые функции, но для того, чтобы планировщик Постгреса лучше оптимизировал запросы по ним, можно создавать специальную статистику.

Новое в статистических представлениях.
-
Если вы используете pg_stat_activity и pg_stat_statements, между ними теперь можно делать JOIN, потому что у этих таблиц появился общий идентификатор queryid. Это бывает очень удобно.
-
Кроме того, появилась вьюха (системное представление) pg_backend_memory_contexts, которая позволяет смотреть, какой бекэнд у вас сколько памяти съел и для чего.
-
И в таблице pg_locks появилось поле waitstart – оно показывает, когда был получен лок. Т.е. вы теперь можете узнать, сколько времени эта блокировка висит.
PostgreSQL 15

Кое-что полезное появилось и в 15-м PostgreSQL.
-
Самая громкая вещь, которая там появилась – это SQL-операция MERGE, но она в 1С не используется.
-
Появился вариант компрессии Zstd, наряду со старой lz4-компрессией. Она чуть побыстрее, чуть получше – возможно, даст небольшой эффект.
-
Есть некие оптимизации по сортировкам, по статистике. Здесь идет речь о статистике, которая считает, сколько было апдейтов, сколько чтений, записи и т.д.
-
Появились новые возможности, связанные с pg_basebackup
-
С архивацией WAL-ов.
-
И, как всегда, ряд оптимизаций в планировщике.

Как изменилась работа со статистикой в PostgreSQL 15. Раньше:
-
каждый бекэнд копил в себе статистику, считал, сколько было апдейтов, сколько инсертов и т.д.;
-
время от времени StatsCollector (отдельный процесс) это сбрасывал на диск в директорию PGDATA/pg_stat_tmp/;
-
из этой директории вы эту статистику зачитывали, когда делали запрос SELECT from pg_stat_tables и смотрели, сколько раз использовался тот или иной индекс, таблица и т.д.
Сейчас по-другому.
-
Сейчас бекэнды пишут прямо в shared-память.
-
На диск это сбрасывается только при остановке сервера.
Если сервер остановили неаккуратно, часть данных по статистике пропадет – но это не столь важно, зато меньше издержек и меньше лишних шевелений с диском.

Оптимизация планировщика.
-
Если в базе много вложенных view, планировщик расходует время по количеству view. Сначала мы думали, что количество времени расходуется в экспоненциальной зависимости от количества. Потом Том Лейн аккуратно посчитал – оказалось, что зависимость кубическая. В PostgreSQL 15 удалось сделать эту зависимость квадратичной – т.е. большое количество вложенных вьюшек теперь не так страшно.
-
При создании в SQL-запросе функции появилась возможность указать для нее SUPPORT-функцию, которая будет подсказывать планировщику, как эту функцию планировать – как у нее статистические параметры. Такие вспомогательные функции пока можно написать только на C, но в будущем возможности их создания будут расширены.
-
Для рекурсивных запросов появился параметр recursive_worktable_factor – можно указать, сколько итераций будет в рекурсивном SQL-запросе. Неправильно, потому что в одном рекурсивном запросе может быть несколько рекурсивных частей, и у них может быть разный фактор рекурсии. Пока что этот параметр общий, поэтому нужно задавать что-то среднее.
-
Про оптимизацию планирования group by я расскажу далее.

Архивация WAL. Известно, что логи транзакций WAL сбрасываются на диск, их можно архивировать и куда-то переносить.
-
Раньше для этого запускалась команда, которая задавалась в параметре конфигураций archive_command.
-
Теперь это может быть не только внешняя утилита, но и какая-то библиотечка, которая в каком-то расширении определяется. Понятно, что функцию из библиотеки быстрее вызывать, чем запускать внешнюю команду. Особенно, под большой нагрузкой, когда это делается часто. У нас есть такие клиенты, у которых WAL-трафик сотни мегабайт в секунду.
В качестве примера такого модуля сейчас есть расширение basic_archive, которое реализует перенос этих WAL-ов.
Также для WAL появилась интересная утилита pg_walinspect, которая позволяет смотреть, что записывается в WAL. Тоже довольно интересно, когда WAL-трафик большой.

Логическая репликация. Я знаю, что некоторые 1С-ники используют логическую репликацию. В ней появилась важнейшая вещь.
Теперь можно публиковать не всю таблицу, а только часть этой таблицы – определенные колонки или определенную выборку WHERE. Это позволяет вам частично реплицировать таблицы. Очень удобно, когда речь идет об аналитике, и вам нужно куда-то копировать часть данных.
Раньше при логической репликации могли происходить ошибки – в процессе репликации вы можете локально что-то поменять в этой базе, из-за этого происходил конфликт. Раньше она долбилась до тех пор, пока этот конфликт кто-нибудь не решит. Сейчас появилась установка disable_on_error, которая отключала подписку при ошибке. О том, что произошла ошибка, вы узнаете из лога. Появились специальные системные вьюшки, вы можете сказать потом, что какую-то транзакцию нужно пропустить, а потом дать команду ALTER SUBSCRIPTION enable, и она пойдет дальше.
У вас есть время, не напрягая сервер, спокойно решить ситуацию.

Оптимизация GROUP BY. Раньше планирование запроса с GROUP BY по двум или нескольким колонкам зависело от порядка полей в группировке, что, в принципе, неправильно.
Но Федор Сигаев нашел эту штуку – как раз при работе с 1С. И исправил. Теперь, в каком бы порядке ни был GROUP BY, оптимизатор будет исследовать все варианты, в каком порядке по этим полям можно группировать.

Несколько оптимизаций для SELECT DISTINCT – для него теперь доступно больше вариантов:
-
может использоваться HashAggregate,
-
может использоваться сортировка
-
или не использоваться сортировка
В разных случаях разные способы оказываются быстрее.

Оптимизация сортировки для выборки – когда вам нужно одну колонку достать и по ней же отсортировать. Тогда будут сортироваться не записи, содержащие эту колонку, а сами значения колонки – понятно, что это – гораздо быстрее.
Также нашли в третьем томе Кнута алгоритм сбалансированного многопоточного слияния и применили его для случая, когда сортировка не умещается в памяти, и промежуточные результаты сбрасываются на диск.

Оптимизация IN в большом списке кажется мне очень важной для 1С. Ее применительно к 1С и реализовали. Запрос IN или NOT IN – если список большой, стал работать намного быстрее. Нужно будет это проверить на реальных 1С-ных случаях и посмотреть, какой будет результат.

Результат pg_basebackup теперь можно направлять в пайп (не только на диск) и делать с ним там, что угодно.

Кроме этого, появился еще ряд оптимизаций по VACUUM (по той же заморозке). И другие вещи.
Что нового в Postgres Pro

А что интересного в последних версиях Postgres Pro, насколько он отличается от обычного PostgreSQL?
Напоминаю, что сборка PostgreSQL от Postgres Pro:
-
поддерживает 1С без дополнительных патчей и настроек;
-
в нем вообще нет Wraparound, потому что счетчик транзакций 64-битный – как, кстати, изначально и хотел сделать Стоунбрейкер в 1986 году;
-
в нем поддерживается блочная компрессия, о которой рассказывал Антон Дорошкевич;
-
есть инкрементальный бэкап, который позволяет вам легко бэкапить большие таблицы;
-
и, внимание, в 15-й версии Postgres Pro Enterprise блочная компрессия будет совместима с инкрементальным бэкапом – это то, чего давно народ ждал.
Подробности
Приведу ссылки:
-
В серии статей Павла Лузанова на Habr.com все изменения 14-й и 15-й версии описаны детальнейшим образом:
-
PostgreSQL 15 https://habr.com/ru/company/postgrespro/blog/679264/
-
PostgreSQL 14 https://habr.com/ru/company/postgrespro/blog/550632/
-
-
Демонстрационную базу для СУБД PostgreSQL можно скачать на странице https://postgrespro.ru/education/demodb – данные из нее использовались у меня на слайдах.
-
Статья Егора Рогова с подробностями о заморозке и вакууме – https://habr.com/ru/company/postgrespro/blog/455590/
-
И очень рекомендую книгу https://postgrespro.ru/education/books/internals. Это новая совершенно уникальная книга, которая очень глубоко рассказывает о том, что у PostgreSQL внутри, какие там алгоритмы используются, как работает Vacuum, как работают индексы. На сайте она выложена в бесплатной электронной версии. И если кто-то любит бумажный вариант, ее можно купить в магазине.
В заключение хочу сказать, что с 3 по 4 апреля пройдет большая всероссийская конференция PGConf.Russia 2023 – присоединяйтесь!
Вопросы:
Все изменения, о которых говорилось в докладе, касаются «ванильной» версии PostgreSQL?
Да, все эти изменения есть в ванильной версии. В Postgres Pro большого количества сейчас нет, кроме того, что я уже говорил. Все изменения связаны с тем, что все работает еще быстрее, еще надежнее. Для 1С есть специальная новая фича – это совместимость дисковой компрессии с инкрементальным бэкапом. Есть еще ряд фич по безопасности, но они больше касаются банков, чем 1С.
Мы сейчас переводим базы с MS SQL. Берем PostgreSQL с сайта 1С. Нас волнуют планы обслуживания и автоматический бэкап. Там это просто отсутствует. Как там делать бэкапы и как обслуживать базы?
В PostgreSQL так устроено, что бэкап – это внешняя задача, которую не сам PostgreSQL делает, а вы с ним делаете. Способов для бэкапа много, они описаны в документации.
Стандартный полный бэкап базы делается с помощью утилиты pg_basebackup – его можно делать непосредственно по ходу работы без каких-то блокировок по расписанию, которое вы сами определите.
Чтобы можно было восстановиться на любую точку времени, параллельно используйте архивирование WAL-ов. Это – простейший способ.
Если вы хотите чего-то продвинутого, вы можете использовать утилиты, которые не входят в состав PostgreSQL, а присутствуют где-то на GitHub, или, если речь идет о Postgres Pro, то в репозитории Postgres Pro.
В частности, мы разрабатываем утилиту pg_probackup – она распространяется свободно и разрабатывается в опенсорсе. Утилита pg_probackup дает вам дополнительные возможности по управлению бэкапами, по тому, чтобы делать инкрементальный бэкап. Но расписание бэкапа – это все равно вопрос к вам. Вы должны настроить его внешними средствами – кроном или чем-то еще.
Но в планы обслуживания входят не только бэкапы, но еще и другие вещи, связанные со статистикой, вакуум и прочее. Хотелось бы, чтобы было такое средство – прямо встроенное.
Вакуум встроенный. Он работает сам из коробки. Настраивает его не нужно, если вы вдруг не чувствуете, что он плохо справляется с этим. Как определить, что он плохо справляется, написано в статье Егора, про которую я говорил в докладе. Если вы видите, что база распухает, происходит ее рост – это связано с тем, что вакуум не успевает зачистить лишние записи. Нужно сделать его более агрессивным, чтобы он чаще и активнее зачищал старые версии. Тогда вы смотрите в статье Егора или в документации PostgreSQL, что за параметры за это отвечают, и их меняете. Примерно так.
В ближайшее время появится графическое средство для администрирования PostgreSQL, которое разрабатываем мы. Там вам станет легче диагностировать эти ситуации. Но пока мы его еще никому не показывали. Надеюсь, на следующей конференции Инфостарта, я расскажу уже про него.
В большинстве Enterprise-решений в самой базе хранится информация о том, когда для нее делали бэкап. Планируется ли когда-нибудь в PostgreSQL добавить строчку о том, когда был сделан последний бэкап?
Мы обсуждали, что такую штуку нужно сделать. Только запись о том, что есть бэкап, не означает, что есть бэкап. Да и что вам самим мешает добавить табличку, и средством, которым вы делаете бэкап, писать туда, когда был последний бэкап.
Вопрос про расширение pg_stat_statements. Практика разработки на 1С подразумевает очень большое использование временных таблиц. И один и тот же запрос, когда у вас большое количество пользователей, он в статистике pg_stat_statements будет выглядеть очень большим количеством разных запросов. Планируется ли нормализация какая-либо?
Нет, такого пока никто от нас не просил. Вы – первые. У нас в Enterprise-версии есть такая фишка как глобальная временная таблица – она всегда одна, но разные сеансы видят из нее свою часть. В Oracle такое тоже есть.
Если перейти на ее использование, тогда автоматически это будет одна и та же таблица, и вашей проблемы не будет.
Но расширение pg_stat_statements все равно это не поймет – все равно на GitHub нужно будет записать это пожелание.
На одном из прошлых мероприятий Инфостарта было обещано, что в pg_hint_plan скоро появится вылавливание параметров GUC в любом месте запроса, включая текстовые литералы – по-моему, это будет называться hints_anywhere. Потому что по-другому никак не повлиять на план запроса из кода 1С – у нас платформа почти всегда генерит уникальный запрос, и стандартное использование расширения не работает. Есть ли информация, когда это появится?
Патч готов, его можно использовать как расширение. Но в релиз эта возможность пока не вошла. Может быть, мы сможем ее встроить в Postgres Pro в ближайшее время – нужно посмотреть.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022.


Вступайте в нашу телеграмм-группу Инфостарт