
















.png")











{kind=link}
В первой части рассказали, как ускорить подготовку теста и настроить шаблон для 180 виртуальных машин (ВМ) с помощью Ansible. Во второй рассмотрели запуск теста и сбор артефактов, поговорили про архитектуру кластера 1С и настройку свойств СУБД. В заключительной части расскажем о том, что нас ждало при запусках теста, и какие доработки СУБД Tantor Postgres были сделаны, чтобы его пройти с высоким результатом.
- Немного о тесте
- Первые результаты и проблемы
- Профилирование. Проблема инвалидационных сообщений
- Профилирование. Проблема долгого удаления индексов
- Оптимизация дизъюнктивных подзапросов
- Настройки Tantor Postgres
- Итоговый результат APDEX
- Сервер СУБД
- Точки развития
- Спойлер
- Детали теста
Немного о тесте
Данный нагрузочный тест разработан фирмой 1С на конфигурации ERP 2.5.17.117, размер базы 1250 Гб. Сценарий нагрузочного тестирования эмулирует полноценный рабочий день 30 тысяч пользователей и длится 11 часов. Немного больше информации о характеристиках базы можно посмотреть на сайте 1С по ссылке.
Тест рассчитан на 30 тысяч пользователей, но мы с коллегами никогда не запускали такой тест, поэтому нашей первичной задачей было пройти этот тест, а уже потом думать над тюнингом и как мы можем улучшить результат. Решить мы начали с 20 тысяч пользователей, затем 25 и 30 тысяч, чтобы если будут проблемы, то решать их постепенно по мере возникновения.
Первые результаты и проблемы
Запустили 20 тысяч, полный прогон занимает около 14 часов. Первый час уходил у Алены на подготовку запуска, затем после запуска почти 2 часа уходило на запуск пользователей и инициализацию и сам тест идет 11 часов.
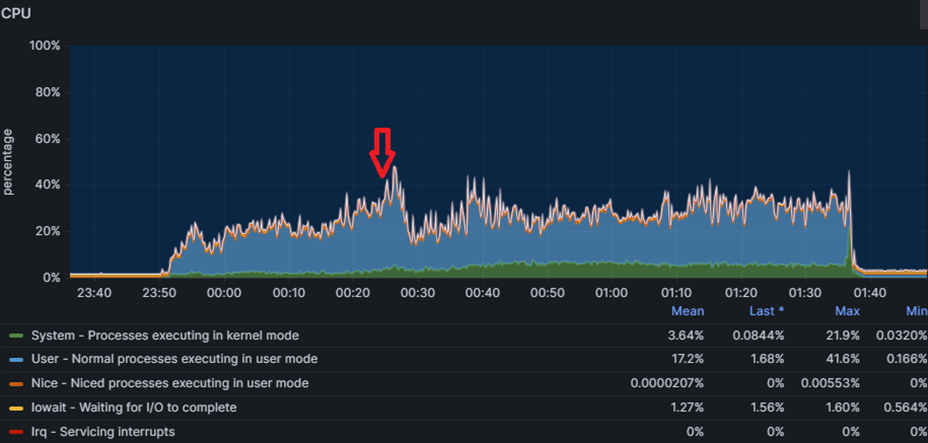
И первый наш запуск закончился успешно, т.е. отработал 11 часов без ошибок и мы получили отчет APDEX по его результатам. Мы подумали, хм, как просто, но при следующем запуске на 25 тысяч у нас начались проблемы - сервер СУБД уходил в себя спустя примерно 40 минут после начала нагрузки. Мы делали запуск на 25 тысяч несколько раз и проблема стабильно повторялась.
На графиках отображено, как выглядит проблема: процессор не уходил в утилизацию на 100%, но количество активных сессий на СУБД резко росло до нескольких тысяч пока не упиралось в max_connections. Запросы вместо миллисекунд начинались выполняться секунды, конечно с таким поведением тест успешно не завершишь.

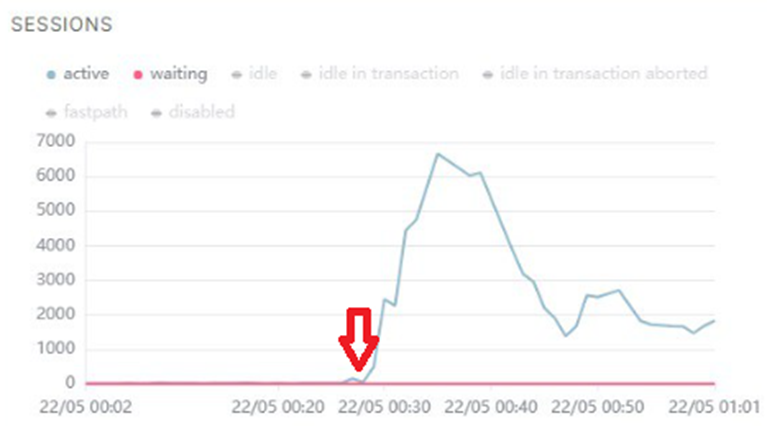
Мы экспериментировали с настройками Tantor Postgres, но это не помогало.
Давайте чуть углубимся в проблему. На видео ниже показан результат вывода простого скрипта к pg_stat_activity, с помощью которого можно без установки дополнительных расширений диагностировать некоторые проблемы при больших нагрузках:
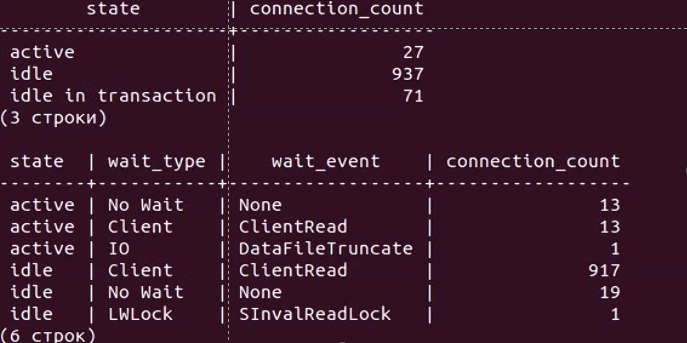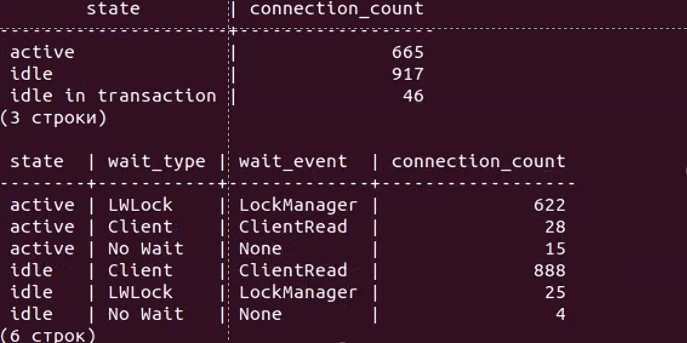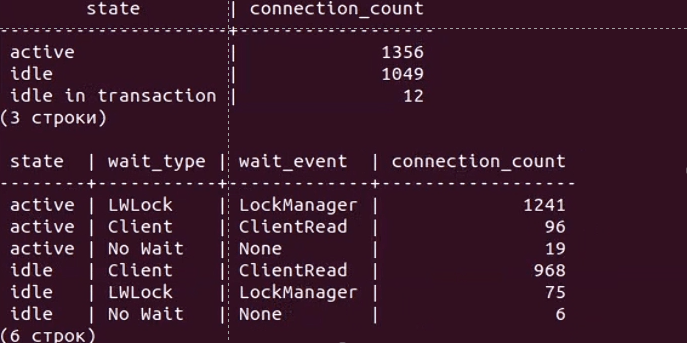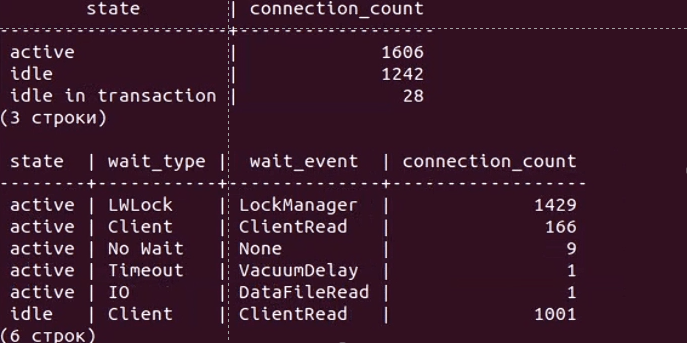
Верхняя таблица отображает количество соединений в разрезе состояний (active, idle, idle in transaction), а нижняя дополнительно в разрезе типа и события ожиданий.
Сначала мы видим что у нас около тысячи соединений большая часть из которых в режиме ожидания команды (idle), и немного активных. Но вдруг количество активных начинает резко расти, как вы видели на графике выше с количеством сессий.
И мы видим что эти активные соединения имеют тип ожидания LWLock с именем события LockManager, т.н. легковесные блокировки (lightweight locks), используемые Tantor Postgres для синхронизации доступа к разделяемым структурам данных в памяти. И через несколько секунд количество активных соединений возрастает до тысячи и более. Так начинается наша проблема (и по сути заканчивается тест).
Но эта информация не позволит нам понять причины проблем, она лишь дает направление куда копать дальше. Чтобы докопаться до сути, нам нужен анализ на уровне исходного кода. Для этого используем perf — инструмент профилирования, который точно укажет, в каких функциях Tantor Postgres происходят задержки и где образуются узкие места. И мы приходим к первой проблеме, которую нам показало профилирование.
Профилирование. Проблема инвалидационных сообщений
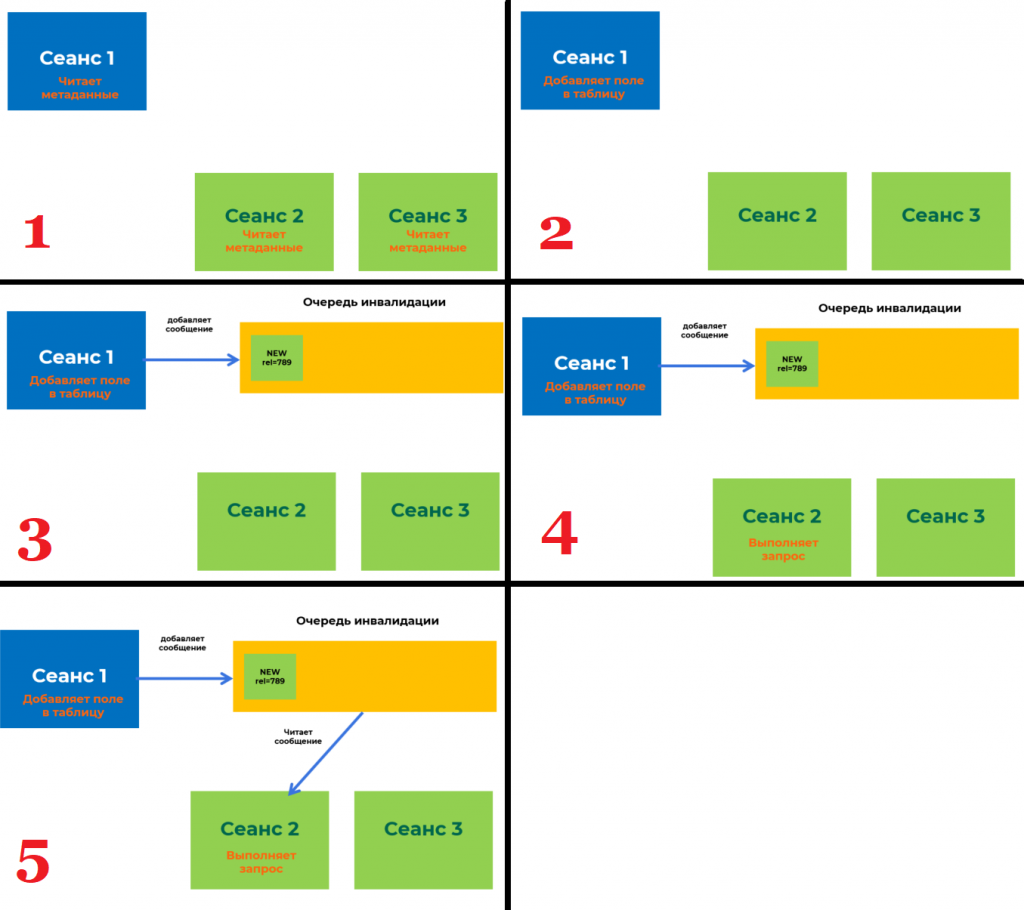
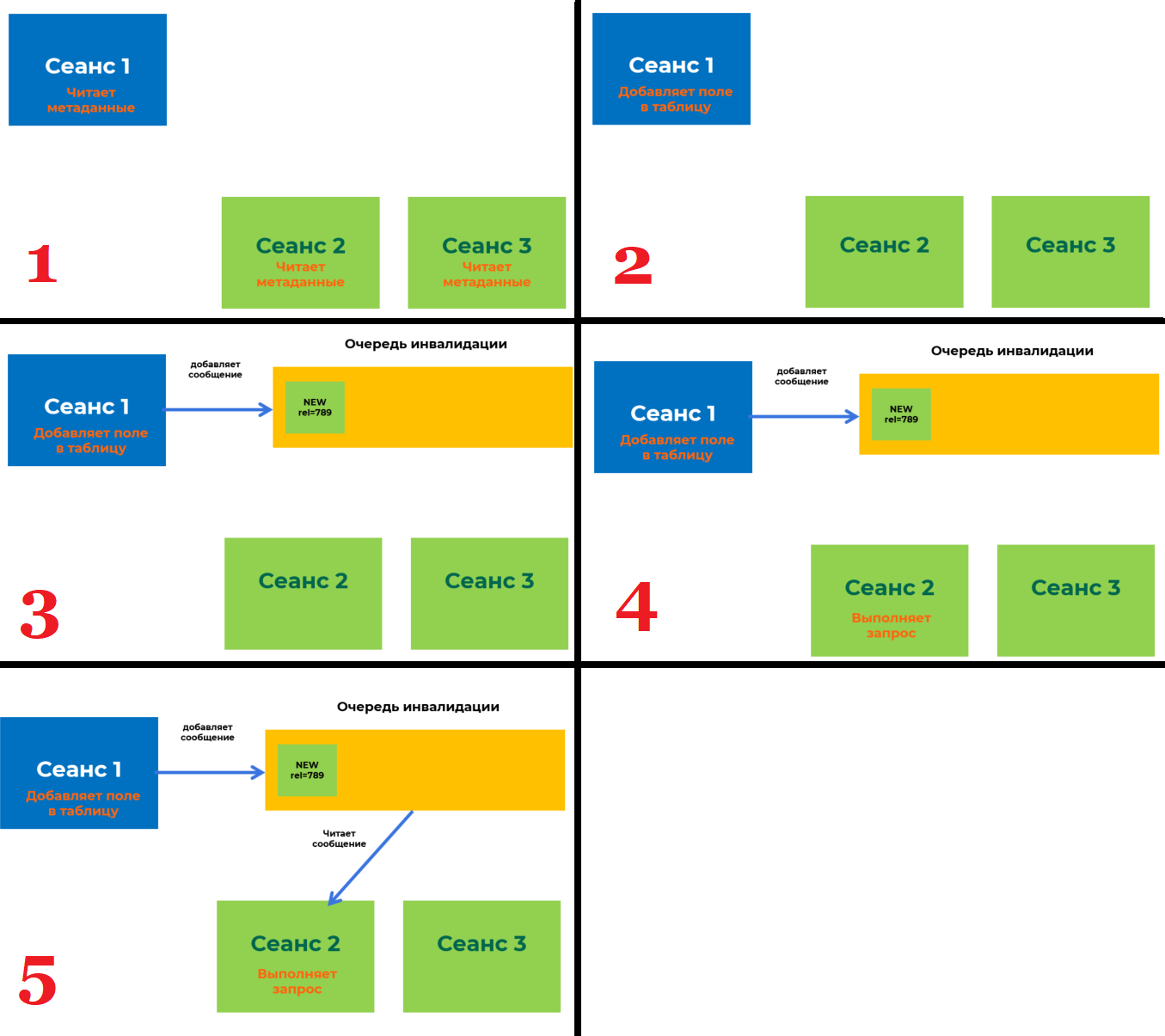
В Tantor Postgres есть общая очередь сообщений, которая нужна для того, чтобы бекенды (они же сеансы) могли обмениваться между собой важной информацией. Под важной информацией понимаются различные DDL-команды, т.е. команды, которые изменяют метаданные таблиц. Давайте рассмотрим как работает этот механизм:
- У нас есть 3 сеанса на стороне СУБД, которые начинают свою работу. При начале работы они читают метаданные таблиц из системного каталога себе в локальный кэш, чтобы понимать какие таблицы/индексы есть в базе данных и с чем они могут работать при выполнении запросов.
- В рамках сеанса 1 происходит изменение метаданных таблицы путем добавления в нее нового поля.
- Сеансы 2 и 3 не знают ничего о том, что в какую-то таблицу было добавлено новое поле. Для того, чтобы эти сеансы могли узнать о том, что изменились метаданные и существует очередь инвалидации. Сеанс 1 добавляет в эту очередь сообщение о том, что изменились метаданные таблицы, в которую он добавил новое поле.
- Сеанс 2 выполняет запрос к базе данных, в котором участвует таблица, в которую сеанс 1 добавил новое поле. Но сеанс 2 до сих пор ничего не знает об этом новом поле.
- Сеанс 2 делает запрос в очередь инвалидации по списку таблиц, которые он использует, чтобы запросить информацию по этим таблицам. И получает из этой очереди сообщение, что добавилось новое поле в таблицу, и обновляет у себя в локальном кэше данную информацию. Теперь он может выполнить запрос к базе данных и не получить ошибку, что данная колонка не существует.
Хорошо, а причем тут наш тест, ведь во время работы 30 тысяч пользователей никто не будет менять метаданные таблиц? 1С постоянно создает временные таблицы и индексы к ним, а это тоже есть изменение метаданных:
- Большое количество сеансов создают временные таблицы и отправляют информацию об этом в очередь инвалидации. Данная очередь имеет ограничение и может хранить только 16384 сообщений.
- Место в очереди начинает заканчиваться, и тут Tantor Postgres начинается процесс массовой инвалидации сообщений. Суть его состоит в том, чтобы все сеансы массово очищают локальный кэш метаданных, чтобы загрузить его заново актуальным. После этого они обращаются к очереди инвалидации, чтобы отметиться, что они "догнали" очередь. Взаимодействие с очередью инвалидации требует наложения блокировок LWLock. Это и есть причина нашей первой проблемы.
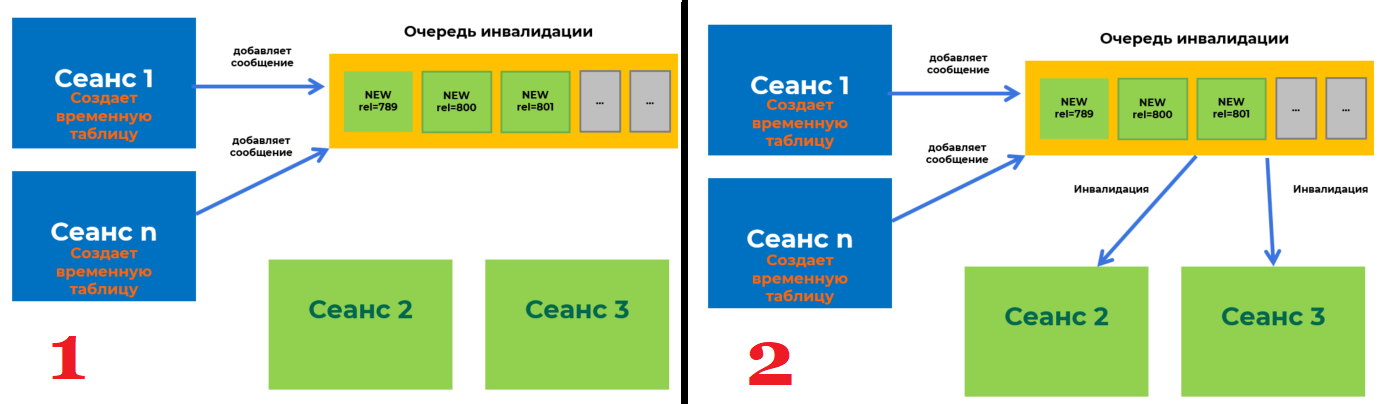
Но так как временная таблица существует только в рамках сеанса, который ее создал, и другим сеансам она не нужна, то здесь решение довольно простое: не отправлять в очередь инвалидации сообщения связанные с временными таблицами.
Мы доработали Tantor Postgres, запустили снова тест, но уже сразу на 30 тысяч пользователей. Тест завершился успешно: получили APDEX 0.635. Ну как успешно, вот вы видите графики нагрузки по CPU и активным сессиям на СУБД. Резкие всплески роста активных сессий все также были следствием LWLock'ов, которых стало меньше, но они все же были.
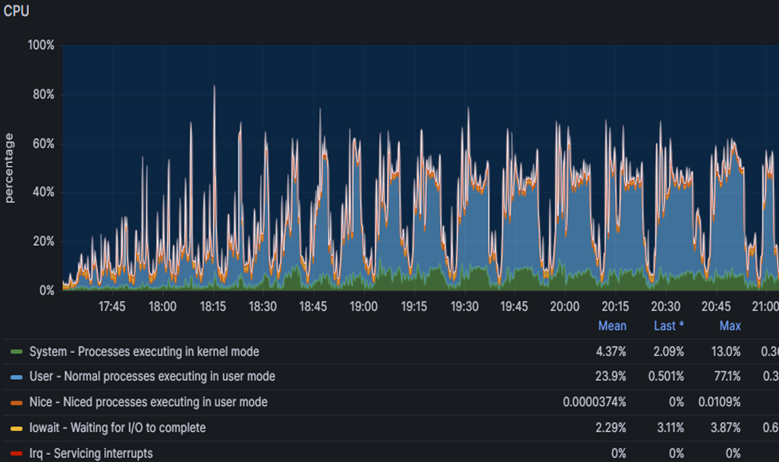

Во время этого прогона было также выполнение профилирование, которое показало нам следующую проблему.
Профилирование. Проблема долгого удаления индексов
Вторая проблема была связана с долгим удалением индексов временных таблиц. Чтобы удалить индекс, необходимо также очистить из таблиц системного каталога информацию о нем, например:
- pg_class - хранит информацию об идентификаторе индекса
- pg_type - хранит информацию о типах полей, используемых в колонках индекса
- pg_depend - хранит зависимости между объектами БД для операций CASCADE
- pg_attribute - хранит информацию о списке колонок, используемых в индексе
- и др.
Визуально схему удаления индекса можно представить следующим образом:
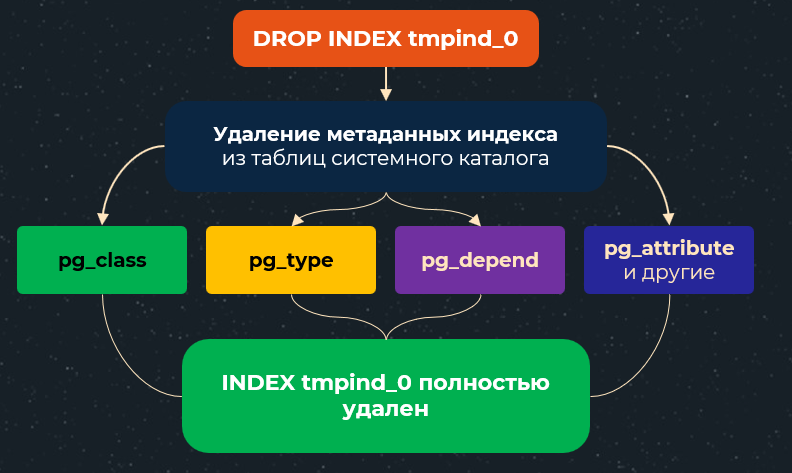
Это можно сравнить с физическим удалением ссылки в базе 1С. Допустим, мы удаляем элемент справочника "Номенклатура", и перед тем как он будет физически удален из базы данных платформа 1С должна удалить связанные записи из регистров сведений, где измерение имеет тип "Справочник.Номенклатура" и стоит галка "Ведущее". Поэтому операция физического удаления ссылок не такая быстрая, как нам бы хотелось.
То же самое и с удалением индекса в Tantor Postgres. Но любой код можно оптимизировать, в том числе исходный код нашей СУБД, что мы и сделали. После этого мы запустили нагрузочный тест на 30 тысяч пользователей и получили APDEX 0.849. Это значительно лучше, чем было раньше, но результат нас не устроил. Мы сделали еще одну доработку Tantor Postgres и изменили его настройки с учетом опыта прошлых запусков.
Оптимизация дизъюнктивных подзапросов
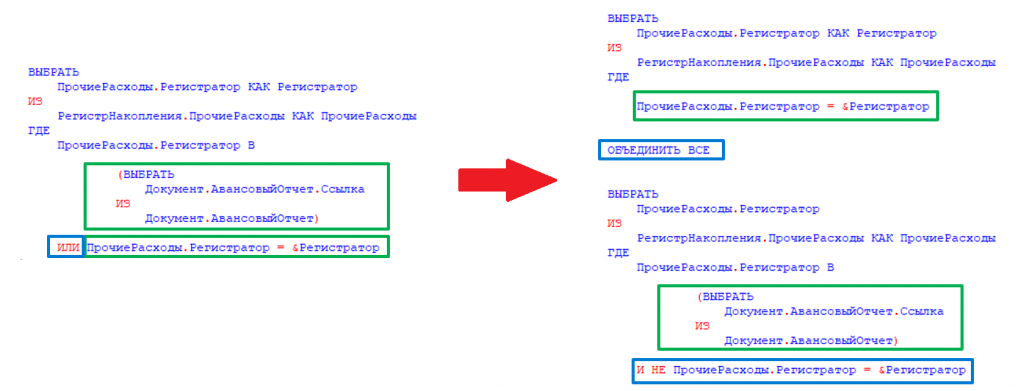
Во время теста следующий запрос выполняется около 8000 раз с длительностью 4-15 секунд в зависимости от таблицы, к которой он обращается:

Из текста запроса видно, что по одному полю накладывается отбор через условие OR. При этом индекс по этому полю есть, почему он не используется?
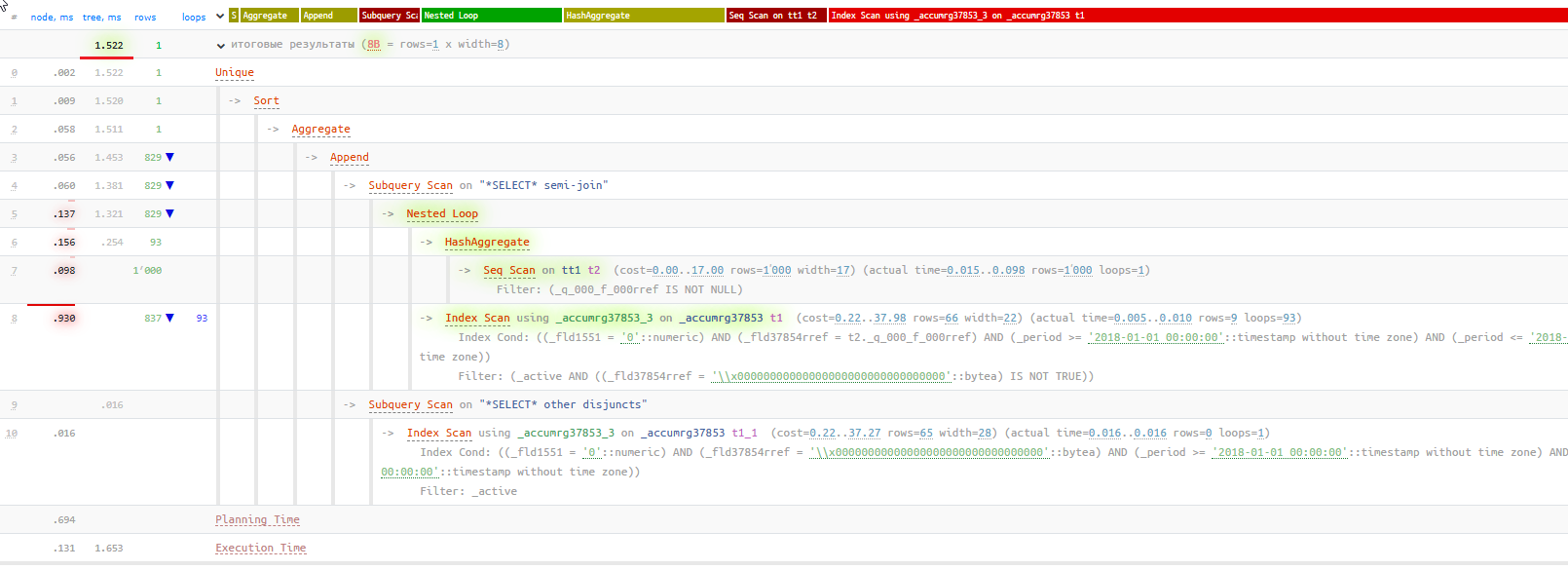
Наличие подзапроса является блокирующим фактором. Он бы мог использовать индекс, если бы это было простое условие ИЛИ в сравнении с константами - планировщик мог бы трансформировать их в ANY, но с подзапросом такое сделать нельзя и пришлось бы сканировать индекс целиком, поэтому он выбирает последовательное сканирование как более дешевый вариант с точки зрения стоимости:
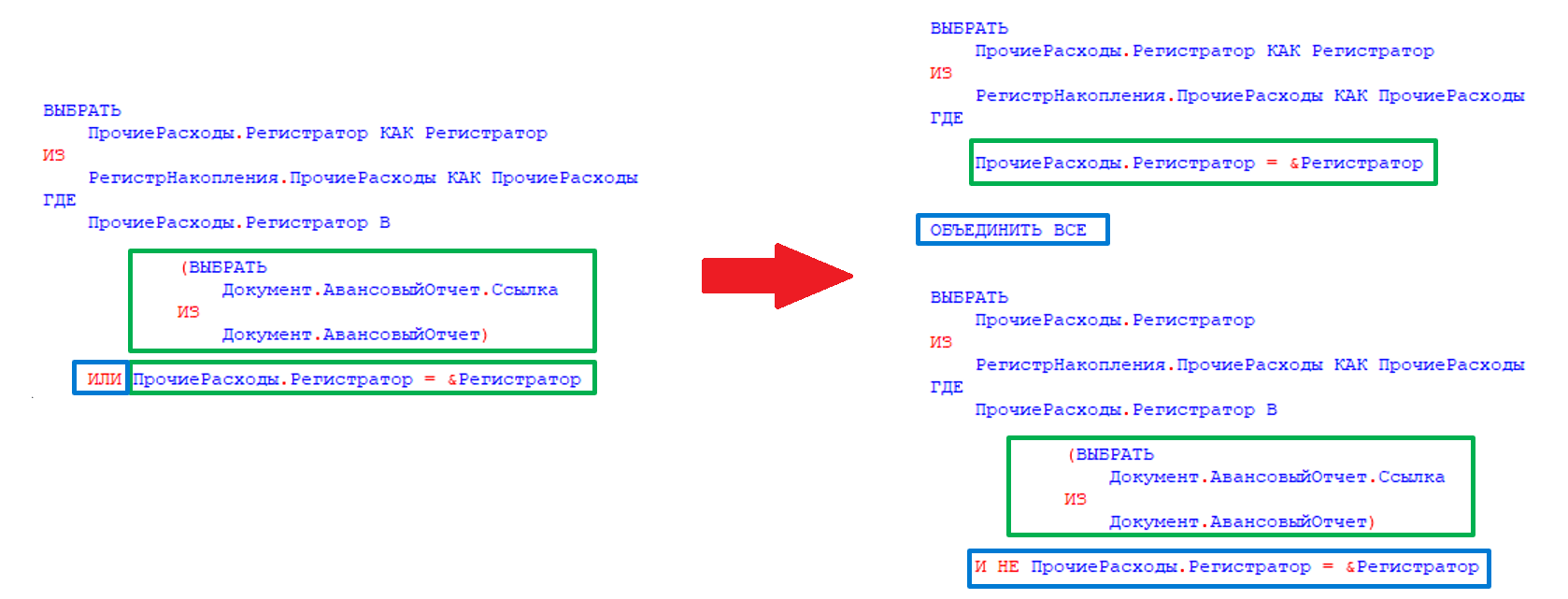
В таком случае запрос сможет использовать индекс и соответственно выполнится почти мгновенно.
По условиям теста мы не могли дорабатывать код 1С, поэтому нам нужно было научить нашу СУБД Tantor Postgres при планировании запроса автоматически переписывать текст запроса перед исполнением, если он подходит под указанный шаблон. Что мы собственно и сделали, в результате запрос вместо 5 секунд выполнился за 1 мс, т.е. ускорение в 5 тысяч раз:
Такая же технология реализована в оптимизаторе запросов MS SQL Server и Oracle Database. Теперь и в Tantor Postgres.
Настройки Tantor Postgres
Рассмотрим, как был настроен инстанс СУБД.

Общие настройки:
- Work_mem, temp_buffers, hash_mem_multiplier - мы постепенно увеличивали данные параметры, анализируя данные прошлых прогонов, чтобы уменьшить количество создаваемых временных файлов.
- Автовакуум был настроен агрессивно, т.к. нам было важно, чтобы была актуальная статистика для качественного планирования запросов.
- Huge_pages включены - с ними некоторые отчеты формировались быстрее.
- Enable_temp_memory_catalog - ключевая настройка для победы над раздутием системного каталога Tantor Postgres.
Настройки планировщика:
Все настройки тут выставлены согласно нашим рекомендациям, и включены все фичи для ускорения запросов, включая как ту, которую мы рассмотрели выше, так и другие оптимизации:
- enable_convert_exists_as_lateral_join - оптимизация запросов с 1Сными РЛС
- enable_filter_predicates_reordering - оптимизация фильтрации в узлах плана запроса index scan, sec scan, join filter.
- enable_index_path_selectivity - оптимизация, позволяющая преимущественно использовать покрывающие индексы при наличии нескольких подходящих под условия запроса.
- enable_join_pushdown - оптимизация запросов к виртуальным таблицам 1С.
Разнесение нагрузки:
Мы ничего не разносили по разным физическим дискам, у нас все было на одном логическом диске, и далее мы объясним что обеспечивает такую феноменальную производительность дисковой подсистемы.
Итоговый результат APDEX
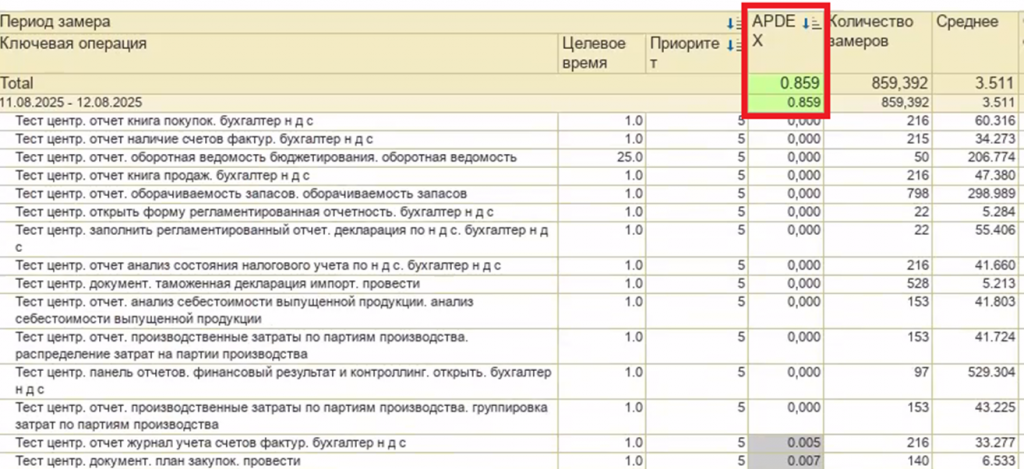
Наш самый успешный прогон показал результат APDEX 0.859:
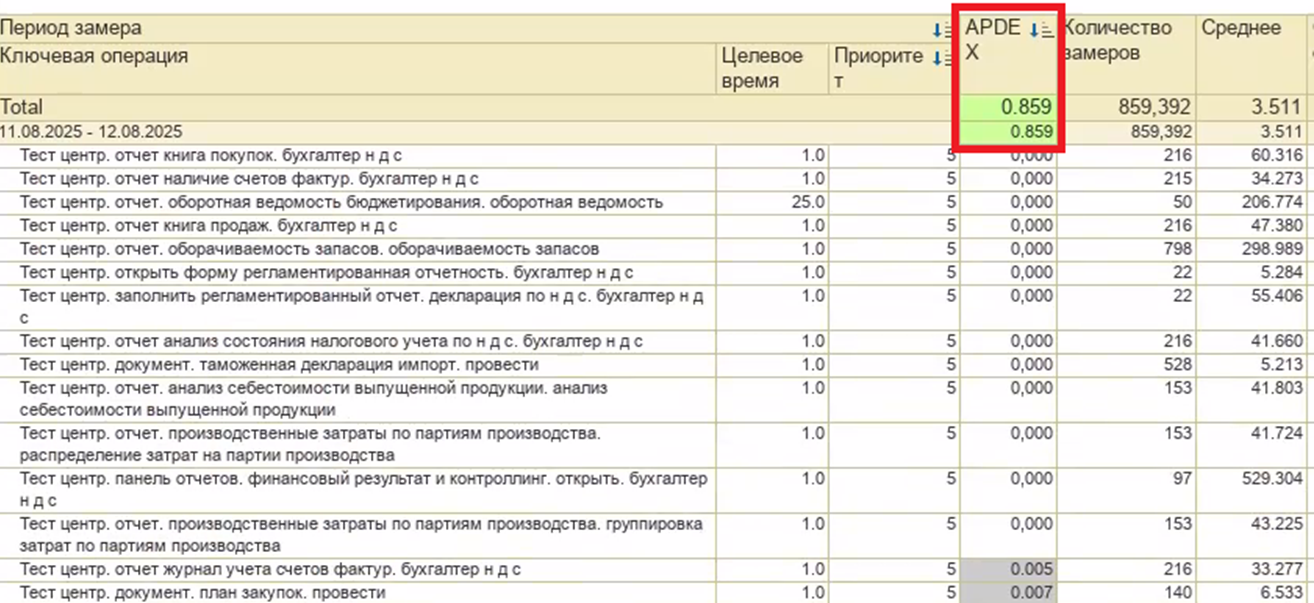
Мы были довольны результатом, т.к. проделали огромную работу в ходе проведения этого нагрузочного теста.
Давайте посмотрим на графики оборудования.
Платформа 1С хорошо справлялась с 30 тысячами пользователей и нагрузка по CPU была в среднем 30% на всех серверах приложений:
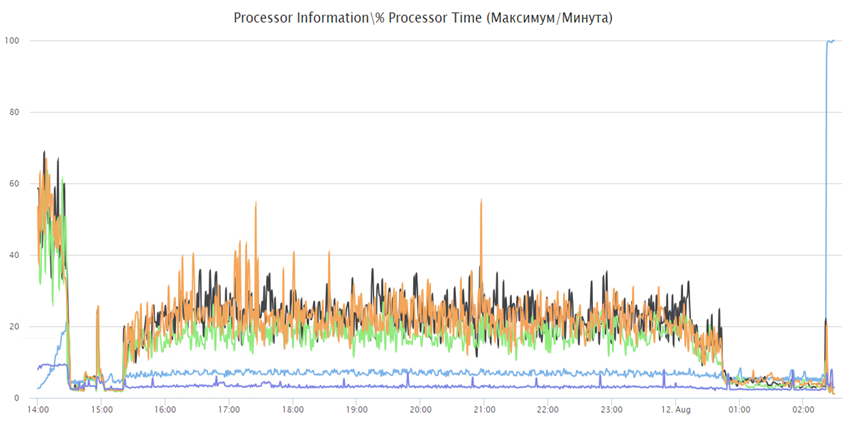
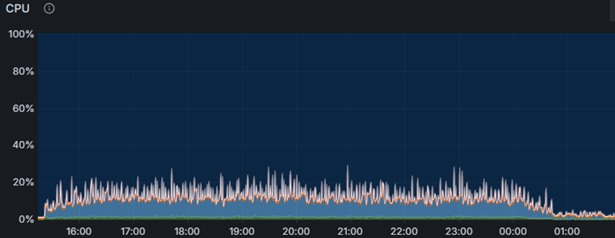
На сервере СУБД нагрузка на CPU была примерно такой же:
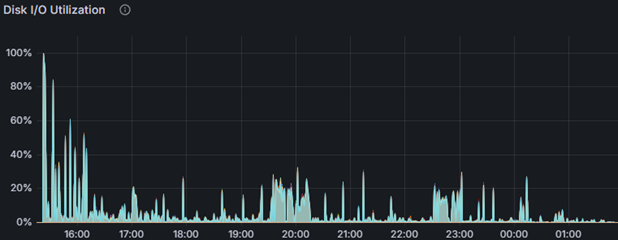
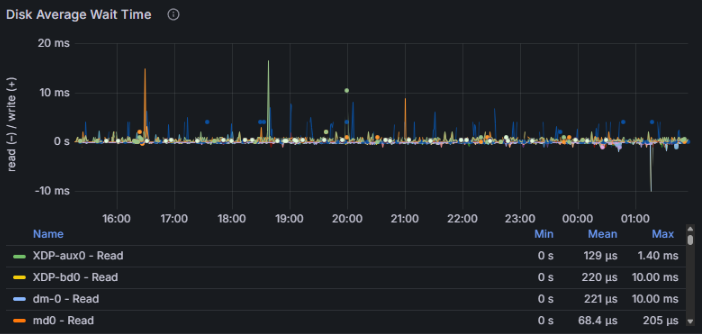
Дисковая подсистема также имела огромный запас прочности:
А вот несколько внутренних графиков Tantor Postgres:
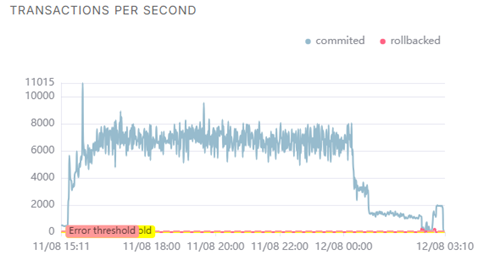
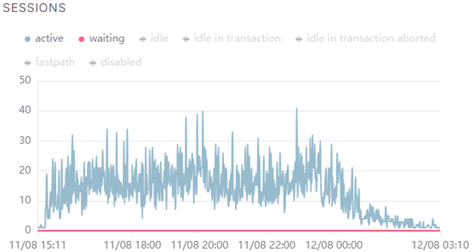

(среднее количество idle-сессий во время теста держалось в диапазоне 600-700)
Сервер СУБД
Но не только тюнинг настроек и доработка Tantor Postgres помогли нам достигнуть такого результата. Огромною роль играло и само оборудование, на котором работал сервер СУБД. В его качестве был наш собственный ПАК Tantor XData 2Y в минимальной комплектации, в которую входило 3 вычислительных сервера с характеристиками как на слайде:

Особое внимание тут заслуживает наш собственный программно-аппаратный рейд XData, который при работе с ОС AstraLinux позволяет нам держать любую нагрузку по дискам с большим запасом прочности.
Внутри одного из вычислительных серверов был развернут контейнер (по сути виртуальная машина) с 112 виртуальными CPU и 1,5 Тб RAM, внутри которого и работал инстанс СУБД Tantor Postgres.
Точки развития
Также этот нагрузочный тест выявил для нас точки роста, которые позволят еще больше улучшить производительность.
Долгое планирование запросов с большим количеством таблиц JOIN/FROM.
По итогам анализа ТЖ у нас были в топе было много запросов, которые выполнялись 300-500 мс. При этом план запроса показывал, что сам запрос выполнялся за миллисекунды, а 99% времени занимало планирование запроса, т.е. перебор различных вариантов его исполнения. Понижение *_collapse_limit'ов ускоряло планирование этих запросов, но все равно оно занимало 50 мс, и таких запросов были тысячи. Механизм перебора вариантов соединения таблиц имеет потенциал оптимизации, и мы планируем в следующих релизах ускорить время планирования таких запросов.
Тип bytea.
В базе ERP 160 тысяч полей и примерно половина из них имеют тип bytea. Он используется для ссылочных полей и хранилищ значения. При этом сам этот тип переменной длины, хотя большинство полей которые его используют фиксированной длины (тип поля, тип ссылки и сама ссылка). В MSSQL Server для этих полей используется тип binary размерностью 1, 4 и 16. Использование bytea вместо фиксированных типов данных создает дополнительные издержки, потому что база данных вынуждена хранить служебную информацию о длине каждого значения и выполнять дополнительные операции десериализации при чтении. Кроме того, переменная длина препятствует эффективному использованию прямой адресации в памяти и на диске, что замедляет как доступ к данным, так и их кэширование, а также увеличивает фрагментацию хранилища и требует больше операций при распаковке кортежей из дисковых блоков. Если написать типы bytea фиксированной длины и научить платформу 1С создавать поля с этими типами вместо bytea, то по нашим предварительным расчетам это может ускорить работу связки 1С + Tantor Postgres на 10 и более процентов.
Параллелизм и временные таблицы.
Сейчас наличие временной таблицы в запросе является блокирующим фактором для использования параллелизма, при этом в данном нагрузочном тесте было много ключевых операций по отчетам, которые выполнялись более 20 секунд и наш анализ показал, что параллелизм мог бы ускорить выполнение таких ключевых операций в несколько раз. В рамках релиза Tantor Postgres 17.6 мы уже сняли часть ограничений на использование параллелизма в таких запросах, и в 18 версии снимем оставшиеся ограничения.
Спойлер
Мы в своем импортозамещении решили пойти дальше и запускали данный нагрузочный тест на машине баз данных XData 2B на процессорах Baikal-S. Правда ядер этот процессор имеет всего 48, что позволило нам успешно пройти нагрузочный тест на 20 тысяч пользователей.
Детали теста
Специалисты АНО «Национальный центр компетенций по информационным системам управления холдингом» совместно с «ИТ-Экспертиза» успешно повторили нагрузочный тест Фирмы 1С с имитацией одновременной работы 30 тысяч пользователей системы «1С:ERP. Управление предприятием» на машине баз данных (МБД) Tantor XData 2Y, использующей СУБД Tantor Postgres. Испытания подтвердили готовность отечественного технологического стека к промышленной эксплуатации на уровне крупнейших российских предприятий.

Новый этап тестирования стал развитием проведенного ранее фирмой «1С» испытания: теперь проверялась работа не только ERP-приложения, но и всего контура отечественного аппаратного и системного обеспечения в максимально приближенных к реальности условиях.
Совместная проектная команда АНО «НЦК ИСУ», «Тантор Лабс», «ИксДата» (производителя МБД Tantor XData), YADRO и «ИТ-Экспертиза» обеспечила бесперебойную работу и устойчивость системы, исключив технологические сбои. В результате тестирования получена интегральная оценка производительности по международной методике APDEX 0,859, что соответствует уровню «Хорошо» и по отдельным параметрам превышает результат, ранее достигнутый фирмой «1С» при аналогичном тесте без использования МБД.
Кластер тестирования «1С:Предприятие» был развернут на машине баз данных Tantor XData 2Y, построенной с использованием серверов VEGMAN R220 G2. Нагрузку моделировали восемнадцать серверов VEGMAN S220 в связке с сетевыми коммутаторами KORNFELD.
Также со стороны АНО «НЦК ИСУ» было инициировано проведение тестирования по собственной разработанной методологии со сценариями работы крупного предприятия в различных часовых поясах. Нагрузочное тестирование выполнялось с помощью инструмента «1С:Тест-Центр» и имитировало процессы полноценного рабочего дня для основных ролей ERP-системы — диспетчеров производства, менеджеров по продажам и закупкам, сотрудников склада и бухгалтерии с общей численностью 15 000 одновременно работающих пользователей. APDEX составил 0,950, что соответствует уровню «Отлично».
В ходе выполнения теста средняя загрузка процессора на сервере СУБД не превышала 30–40%, на серверах приложений оставалась ниже 40%. Дисковая подсистема показала время отклика при чтении порядка одной–двух миллисекунд, при записи - около пяти миллисекунд. Длительность теста составила 11 часов непрерывной работы, и за это время не было зафиксировано падений процессов, критических ошибок или блокировок.
Технологическим партнером масштабного нагрузочного тестирования «1С:ERP» на российском стеке выступила команда интегратора «ИТ-Экспертиза», обеспечившая экспертную поддержку на всех этапах, включая анализ результатов.
Нагрузочное тестирование подтвердило: российский технологический стек готов к промышленной эксплуатации в масштабах крупнейших предприятий, обеспечивая надежность, производительность и уровень сервиса, сопоставимые с ведущими мировыми решениями.
Об условиях тестирования и оборудовании
Условия тестирования
|
Показатель |
Значение |
|
Дата проведения |
11.08.2025 |
|
Версия конфигурации |
1С:ERP Управление предприятием (версия 2.5.17.117) |
|
Версия платформы |
8.5.2, спец. сборка 8.3.27 |
|
Версия СУБД |
Tantor Special Edition 1C 17.5 |
|
Сценарий |
ERP. 30 000 одновременно активных пользователей |
|
Объем базы |
~ 1,25Тб |
|
Структура базы |
организация, имеющая в своей структуре 54 филиала, выделенных на отдельные балансы (55 позиций в справочнике организаций), 1800 подразделений, 3500 складов, 80 тыс. номенклатурных позиций, 700 тыс. сотрудников, 90 тыс. партнеров, 2.5 млн контрагентов, 25 млн договоров, 1 млн основных средств |
Технические характеристики оборудования для проведения тестирования
|
Назначение |
Кол-во серверов |
Ядер CPU |
ОЗУ (Гб) |
Диски (Тб) |
Примечание |
|
Центральный сервер |
1 |
96 |
768 |
2,4 |
Платформа 1С:Предприятие |
|
Рабочий сервер |
3 |
96 |
768 |
2,4 |
Платформа 1С:Предприятие |
|
Сервер лицензирования |
1 |
8 |
32 |
2,4 |
Платформа 1С:Предприятие |
|
Сервер баз данных |
1 |
112 |
1536 |
33,0 |
Tantor Special Edition 1C 17.5 |
|
Нагрузчики |
18 |
112 |
755 |
3 |
Каждый сервер разбит на 10 виртуальных машин, в которых запускаются около 167 сеансов, моделирующих нагрузку. |
Сервер лицензирования:
-
Intel Xeon Scalable v2 Silver 4215
-
Память 32 Гб DDR4-3200 ECC RDIMM
-
2 x Накопитель SSD NVMe Gen3 1.6 ТБ 7300MAX
Кластер тестирования «1С:Предприятие» был развернут на машине баз данных Tantor XData 2Y, построенной с использованием серверов VEGMAN R220 G2. Нагрузку моделировали восемнадцать серверов VEGMAN S220 в связке с сетевыми коммутаторами KORNFELD.
Сервер СУБД — машина баз данных Tantor XData 2Y:
-
Минимальная комплектация (3 вычислительных сервера)
-
2x Intel Xeon Platinum 8362, 3600 MHz 128 vCPU
-
RAM 2 Тб DDR4-3200
-
Программно-аппаратный рейд XData
-
Сеть 25 Гбит/с
-
Внутри вычислительного сервера поднят контейнер для инстанса СУБД Tantor Postgres: 112 vCPU, 1,5 Тб RAM
-
ОС AstraLinux 1.7.6, ядро 6.1.50-1-generic
Нагрузчик:
-
Intel Xeon Scalable v2 Gold 6230R
-
DDR4-3200 RDIMM ECC 2Rx4
-
2 x Накопитель SSD 3.84 Tb SATA 2.5" PM893
-
Сеть: 10 Гбит/с.
База наполнена данными за 2 месяца работы крупного предприятия — около 10 млн. документов. СУБД, кластер серверов и нагрузчики с тонкими клиентами платформы «1С:Предприятие» были развернуты на ОС Astra Linux 1.8. Выбранный сценарий моделировал реальную нагрузку на систему и воспроизводил повседневную работу основных пользователей ERP:
-
главный диспетчер производства;
-
локальный диспетчер производства;
-
менеджер по закупкам;
-
менеджер по продажам;
-
кладовщик;
-
внутреннее потребление товаров;
-
планирование производства;
-
бюджетирование;
-
бухгалтер по внеоборотным активам;
-
бухгалтер по взаиморасчетам;
-
бухгалтер.
Все действия пользователей выполнялись с учетом ограничений прав на уровне записей (RLS).
Результаты тестирования
|
Наименование показателя |
Значение |
|
Время работы теста |
11 часов |
|
Количество выполненных ключевых операций |
859 392 |
|
Общий APDEX по всем ключевым операциям (APDEX — стандарт для измерения производительности приложений) |
0,859 |
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT 2025

Вступайте в нашу телеграмм-группу Инфостарт