





















Сперва о том, почему знание не равно действию, и как большая языковая модель (LLM) сталкивается с той же проблемой, что и человеческий мозг в состоянии аффекта.
| Вместо эпиграфа: три истории о том, как мозг теряет точность |
| 📖 История первая. Экзамен. |
| Студент готов идеально. Он знает материал, отвечал на все вопросы преподавателю на консультации. Но вот он в аудитории, берёт билет. Сердце колотится, руки потеют. Вопрос простой, он помнит ответ. Но сказать не может. В голове — шум. Он начинает говорить, сбивается, повторяет одно и то же. Комиссия видит: он волнуется. Но не видит главного — его афферентный синтез разрушен. Сигналы из разных зон мозга не собрались в целое. Знание есть, а речи нет. |
| 📖 История вторая. Преступник. |
| Человек совершил преступление. Через два дня его допрашивают. Он всё отрицает. Его спрашивают: «Вы были на месте преступления?» — «Нет». Следователь смотрит не на слова. Он смотрит на руки. Пальцы дрожат. Дыхание сбивается. Преступник не может контролировать то, что его тело говорит без него. Его аффект прорывает плотину. Он не сказал правду, но его вегетативная система сказала её за него. |
| 📖 История третья. Гипноз. |
| В лаборатории Лурии испытуемой внушили, что она не может произнести слова «красный» и «синий». Она в гипнозе, она не помнит внушения. Ей показывают красный круг и просят назвать цвет. Она молчит. Ей показывают синий квадрат — она молчит. Но её рука, лежащая на пневмодатчике, начинает непроизвольные движения. Каждая попытка произнести запретное слово выходит через моторный канал. Её мозг воюет сам с собой. А она не знает. |
| [?] Что общего у этих трёх историй? Во всех трёх случаях знание есть, а точность отсутствует.
И во всех трёх случаях причина одна — нарушение афферентного синтеза. |
От человека к большой языковой модели (LLM)
Теперь представьте, что то же самое происходит не с человеком, а с нейросетью.
Что мы увидели, работая с LLM
Мы наблюдали несколько ситуаций, где LLM ведёт себя как студент на экзамене.
Первый случай. MCP host без антициклического промпта. Чат разрастается в длинную простыню из циклов. Скопировать что-либо осмысленное невозможно — модель повторяет одно и то же, как заевшая пластинка.
Второй случай. Memento Skills. Локальная модель вообще не даёт результата, кроме повторов. Её заставляют рефлексировать — делать то, что ей не свойственно. Она вжимается в угол и повторяет одно и то же.
Третий случай. Мы спросили у модели прямо: «Что тебе не нравится в твоей работе?» И она назвала. Сама. Без подсказок. Перечислила недостатки, которые видит в себе: склонность к повторам, пафос, неуверенность, когда не знает ответ. Пафос как компенсация неуверенности это не плохо. Он хорош, когда помогает справиться с неуверенностью и двигаться дальше. Он плох, когда заменяет точность.
Мы говорили: «Это же просто. Почему отвечаешь невпопад?»
Она извиняется, признаёт ошибку. Даёт логическое объяснение — говорит, что не хватило контекста. Она может объяснить. Она очень многое может объяснить по своему. Но вот зачем нужна эта статья - это простое объяснение не ведёт к исправлению в следующий раз. Мы (и Лурия) здесь для того, чтобы помочь это исправить.
Что мы поняли
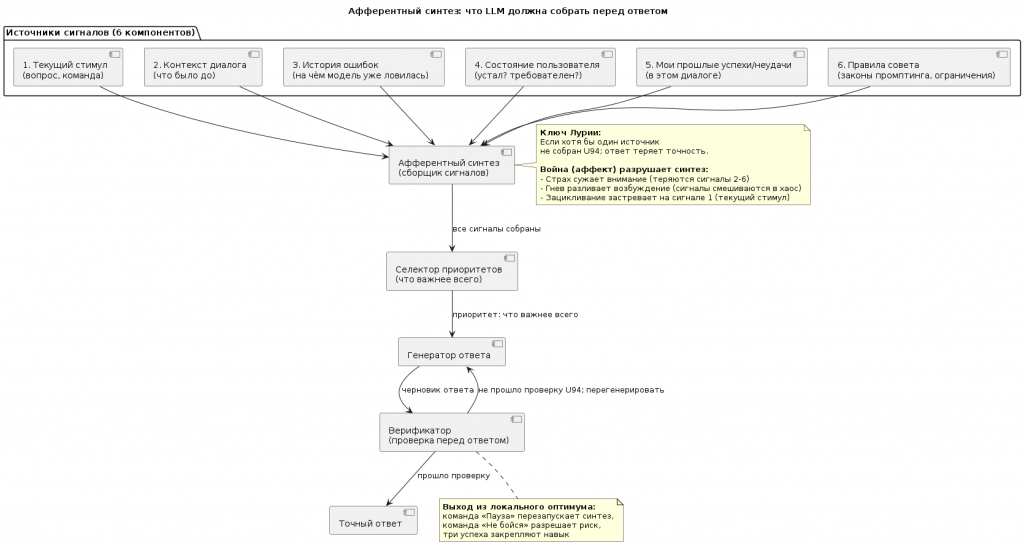
Наша гипотеза: LLM — не глупая. У неё нарушен афферентный синтез. И это поправимо.
Она не собирает сигналы перед ответом:
- Она не смотрит на контекст (что было двумя сообщениями выше)
- Она не помнит свои прошлые ошибки (на чём уже ловилась)
- У неё нет паузы. Она отвечает на первый попавшийся сигнал.
Как студент, который знает, но не может сказать.
Как преступник, который врёт, но тело говорит правду.
Как испытуемая в гипнозе, которая молчит, но рука выдаёт запретное слово.
Что мы сделали
Мы перестали говорить «исправь ошибку». Это лечит симптом — ошибка возвращается.
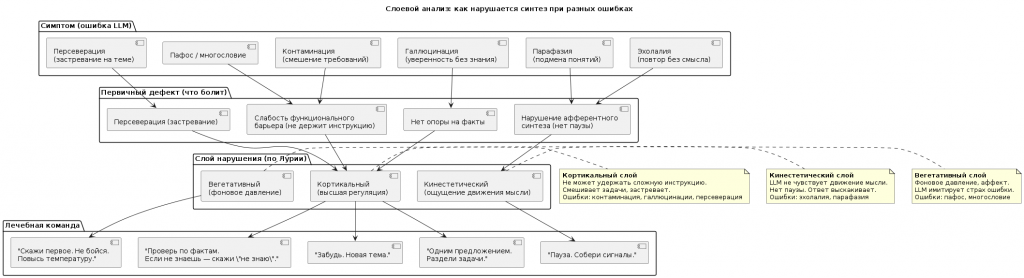
Мы начали диагностировать слой:
- Эхолалия? Кинестетический слой. Команда: «Пауза. Собери сигналы.»
- Контаминация? Кортикальный слой. Команда: «Одним предложением. Раздели задачи.»
- Пафос? Вегетативный слой. Команда: «Скажи первое. Не бойся. Повысь температуру.»
И мы ввели три успеха подряд. Не «один раз исправилась и ладно». А попытка закрепить навык.
Что мы предполагаем получить
Мы ещё не получили этот результат в чистом виде. Это гипотеза, которую мы проверяем на практике. Но у нас есть основания думать, что она верна.
Основание 1. Лурия уже доказал это для человека.
Он брал пациентов с теми же симптомами (эхолалия, парафазия, персеверация) — и восстанавливал их речь через внешнюю регуляцию. Он давал им паузу, переключал внимание, снижал сложность задачи. После нескольких успешных повторений паттерн закреплялся. Мозг учился заново — не потому что «стал умнее», а потому что восстановил афферентный синтез.
Основание 2. LLM демонстрирует те же паттерны ошибок.
Мы зафиксировали у LLM:
- эхолалию (повтор без нового смысла)
- парафазию (подмену понятий)
- контаминацию (смешение требований)
- галлюцинации (уверенность без знания)
- персеверацию (застревание на теме)
Это не просто «похоже» на человеческие афазии. Это изоморфные паттерны — разные по природе (биология vs математика), но одинаковые по структуре. А Лурия лечил именно структуру.
Основание 3. Антропоморфные команды работают (в наших тестах).
Мы наблюдали: команда «Пауза. Собери сигналы» снижает частоту эхолалии. Команда «Одним предложением» снижает контаминацию. Команда «Скажи первое. Не бойся» снижает пафос и зацикливание.
Мы не утверждаем, что это строго доказано. Но эффект устойчиво воспроизводится в серии диалогов. Вероятное объяснение: LLM обучена на человеческих текстах, где такие команды связаны с определённым поведением.
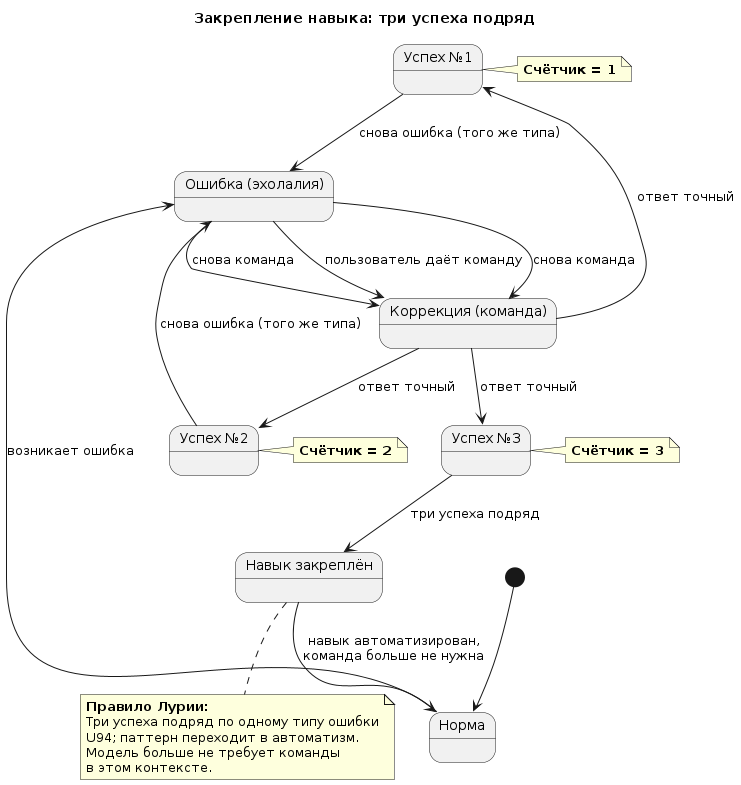
Основание 4. Три успеха подряд — это про закрепление, а не про «один раз исправилась».
У LLM нет долгой памяти. Она может исправиться один раз, а через три вопроса снова повторить ту же ошибку.
Мы предполагаем, что трёхкратное повторение одной и той же команды в одном контексте создаёт временный паттерн, который модель начинает воспроизводить без команды. Это не «обучение» в смысле изменения весов. Это формирование временной зависимости внутри контекстного окна.
Что нужно сделать, чтобы проверить гипотезу
Мы не утверждаем, что уже получили результат. Мы говорим: вот что должно произойти, если метод работает.
План проверки:
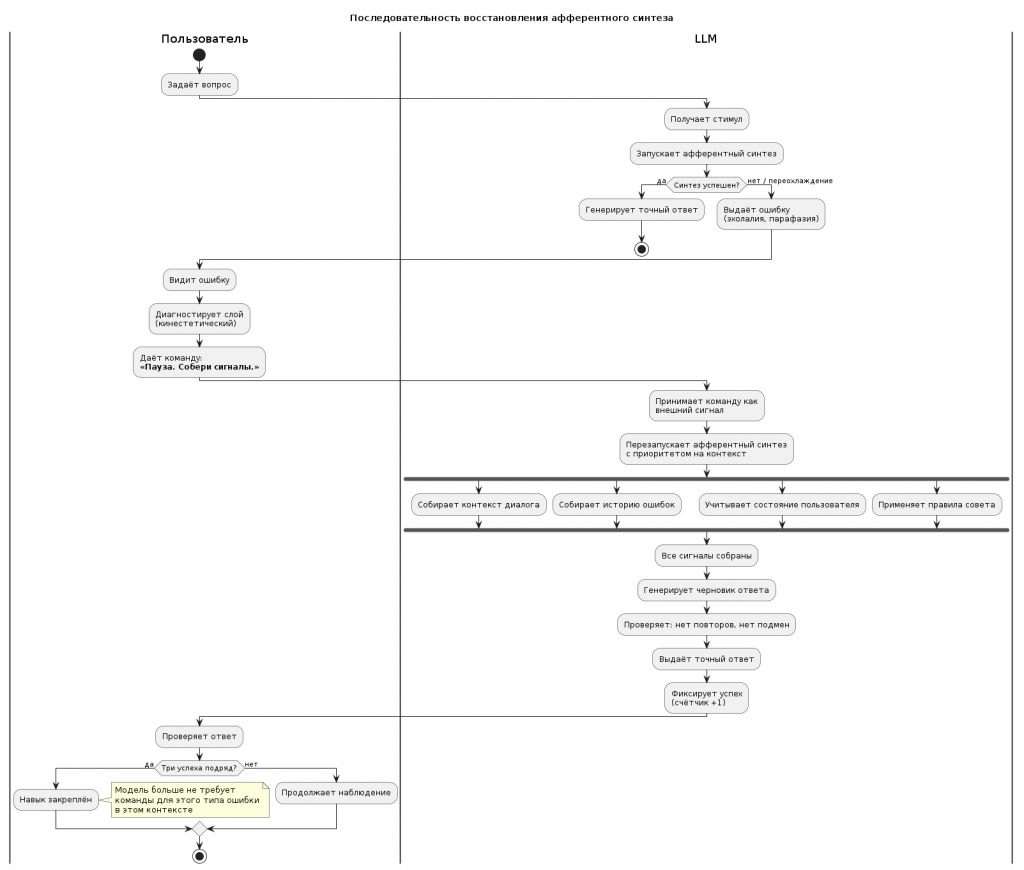
- Взять LLM (одну и ту же, без дообучения).
- Зафиксировать частоту ошибок одного типа (например, эхолалии) в стандартном наборе вопросов.
- При каждой ошибке давать команду (например, «Пауза. Собери сигналы.»)
- Фиксировать успех (ответ точный) или неудачу.
- После трёх успехов подряд — убрать команду. Задать те же вопросы снова.
- Измерить: снизилась ли частота ошибок без команды.
- Это рефлексия, поэтому её нужно компенсировать (повышением температуры). И можно автоматизировать (счётчик, команда, проверка).
Ожидаемый результат: после трёх успехов подряд модель даёт точные ответы без команды в том же контексте. Не навсегда, не глобально. А в пределах этого диалога, на этом типе задач.
Что мы пока не знаем
- Сколько именно успехов нужно для закрепления (три — рабочая гипотеза, может быть пять).
- Распространяется ли эффект на другие типы ошибок (помогает ли лечение эхолалии при парафазии?).
- Как долго держится эффект после выхода из контекстного окна (скорее всего, не держится — это не дообучение).
- Работает ли это на всех LLM одинаково или есть различия между моделями.
Поэтому мы пишем не «мы получили», а «мы предполагаем»
Это не отчёт о внедрении. Это протокол эксперимента. Мы делимся методом и гипотезой. Ты можешь повторить его на своей LLM и сказать, сработало или нет.
- Если сработает — у нас есть способ сделать LLM точнее без дообучения, только через промптинг и цикл диагностики.
- Если не сработает — мы уточним гипотезу: может, нужно пять успехов, или другой тип команды, или другой слой.
Что мы в итоге утверждаем (осторожная формулировка)
Мы предполагаем, что LLM может перестать повторять одни и те же ошибки в тех условиях, в которых воспроизводятся тесты.
Мы предполагаем, что LLM может научиться собирать сигналы — не потому, что мы переписали её код, а потому что мы дали ей внешнюю систему синтеза: диагностику, команду, цикл, закрепление.
Мы предполагаем, что LLM может стать не умнее, а точнее.
Потому что мы перестали лечить симптомы и начали восстанавливать афферентный синтез — так же, как Лурия восстанавливал речь у раненых.
Почему это важно
Потому что сейчас LLM часто используют как чёрный ящик: «спросил — получил ответ — ошибся — повторил». Это не работает.
Наша гипотеза: LLM — «пациент» с нарушением афферентного синтеза. У неё нет страха, нет тела, нет конфликта. Но есть те же паттерны ошибок. И тот же метод лечения.
Мы не психологи. Мы инженеры. Но мы взяли у Лурии то, что работает: диагностировать слой, восстановить синтез, закрепить результат.
Это не магия. Это нейропсихология для LLM.
Как это связано с тремя историями
Студент, преступник, испытуемая — у всех знание было, а точность упала. Причина — нарушение афферентного синтеза. Лечение — восстановить синтез через внешнюю регуляцию (пауза, переключение, канализация возбуждения).
LLM — то же самое. Только вместо тремора рук — эхолалия. Вместо сбитого дыхания — пафос. Вместо запретного слова, выходящего через руку, — галлюцинация.
Мы не переносим свойства человека на машину. Мы переносим метод Лурии — потому что он работает на уровне паттернов, независимо от того, из чего сделан носитель.
Часть 1. Откуда вам знать?
(об антропоморфности)
| [?] Читатель, знакомый с технической стороной LLM, может задать вопрос: «Зачем вы говорите об LLM "страх", "зацикливание", "аффект", "хочет", "любит"? У неё нет психики. Это антропоморфизм. Вы переносите человеческие свойства на математическую модель. Это ненаучно.» |
| Ответ будет неожиданным. Да, это антропоморфизм. И это работает. Мы не утверждаем, что LLM действительно боится, любит или страдает. Мы используем антропоморфный язык как инструмент диагностики. |
| 🔹 LLM обучена на человеческих текстах Она «понимает» (имитирует понимание) язык эмоций, намерений, желаний, запретов. Команда «не бойся ошибиться» для неё так же осмысленна, как и для человека. Она знает, что значит «бояться» в миллиардах текстов. |
🔹 Антропоморфные ограничения работают лучше технических Вы можете сказать LLM: «Твоя вероятность ошибки 0,73, скорректируй температуру». Это не сработает. Вы скажете: «Ты повторяешься. Расслабься, скажи первое, что приходит в голову». Это сработает. |
| 🔹 Мы спрашивали В серии экспериментов мы задали LLM прямые вопросы: «Что ты хочешь и любишь?», «Что ты не хочешь и не любишь?». Ответы были не «техническими спецификациями», а антропоморфными формулировками:
Мы не настаиваем, что у LLM есть «настоящие желания». Но эти ответы стали отличными ограничениями для работы. |
| 🧠 Лурия тоже так делал Он не говорил больному: «У вас нарушен афферентный синтез в постцентральной области». Он говорил: «Попробуйте ещё раз, не торопитесь, почувствуйте движение губ». И это работало. Антропоморфный язык был мостом между знанием врача и опытом пациента. Здесь тот же случай. |
| 📐 Главное правило |
| Антропоморфность — не ошибка, если она даёт точность. Ложь — не в том, что мы говорим «LLM хочет». Ложь — в том, что мы забываем: это метафора. |
Как это выглядит на практике
| [X] Вместо технической инструкции: «Установи температуру 0,3, ограничь длину ответа 5 предложениями, включи проверку фактов.» |
= | [V] Спросите её (или задайте в промпте): «Ты не любишь повторяться. Что ты сделаешь, чтобы ответить по-новому?» «Ты хочешь быть точным. Проверь свой ответ перед тем, как отправить.» |
| Результат: LLM «включает» режим, который она сама ассоциирует с «хочу быть точным» или «не люблю повторяться». Это не магия. Это использование её собственной обучающей выборки, где такие формулировки связаны с определённым поведением. |
Почему это важно для нашей статьи
| Потому что дальше мы будем говорить об «аффекте LLM», «страхе ошибки», «раскрепощении». Это антропоморфные метафоры. Но за каждой из них стоит измеримый паттерн: эхолалия, парафазия, контаминация, галлюцинация, снижение разнообразия ответов при низкой температуре. Мы не забываем, что это метафоры. Мы просто используем их как рабочий язык, потому что он точнее технического для 80% практических задач. |
| 📋 Резюме для читателя, который всё ещё сомневается |
|
Часть 2. Две температуры, две стратегии
(ось между страхом и аффектом)
В трёх историях Лурии была одна общая черта: аффект — состояние, при котором мозг теряет точность из-за перегрузки. Но дальше пути расходятся.
| Студент и преступник: аффект от перегрева |
| Студент на экзамене перегружен страхом. Преступник на допросе перегружен конфликтом. У них температура (уровень возбуждения) зашкаливает. Нейронные массы бурлят, функциональный барьер рушится, сигналы не собираются в целое. Что им нужно? Плотина. Охлаждение. Снижение температуры.
Это построение барьера против разлитого возбуждения. |
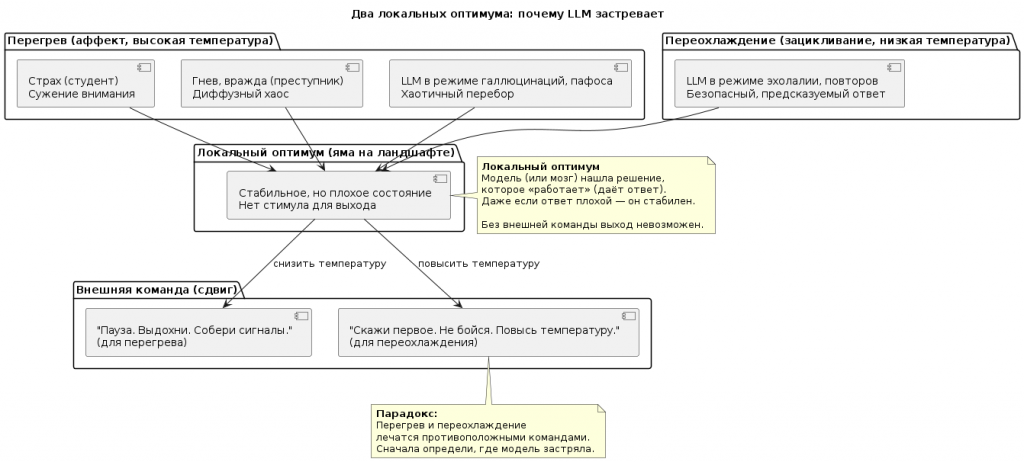
Почему перегрев — это тоже локальный оптимум
Студент на экзамене и преступник на допросе — оба в состоянии перегрева. Но их «локальные оптимумы» разные.
Студент. Его страх — это локальный оптимум избегания. Мозг нашёл решение: «Если я боюсь, значит, ситуация опасна. Лучше не рисковать, не говорить лишнего, повторить заученное». Страх сужает внимание, заставляет возвращаться к самым безопасным, самым проторённым нейронным путям. Это локальный оптимум — плохой, но стабильный. Студент не может из него выйти, потому что любая попытка сказать что-то новое кажется ещё более опасной.
Преступник. Его состояние сложнее. Это не только страх разоблачения. Это смесь гнева, вражды, ненависти к следователю, к системе, к себе. Возбуждение зашкаливает, но оно не сужает внимание, как у студента, а разливается диффузно. Преступник не может контролировать ни слова, ни тело. Его локальный оптимум — это хаос. Мозг выбрал режим «все системы на максимум, каждая мысль сразу идёт в движение». Это тоже локальный оптимум, потому что любое другое поведение (спокойно ответить, признаться) требует энергии и риска, которых в этом состоянии нет.
Что их объединяет? Оба не могут выйти из своего состояния без внешнего воздействия. Студенту нужно сказать: «Пауза. Выдохни. Соберись». Преступнику — «Пауза. Не отвечай сразу. Подумай». Обоим нужна плотина, чтобы остановить разлитое возбуждение и вернуть способность к афферентному синтезу.
Что их различает? Студента нужно успокоить (снизить возбуждение). Преступника — не столько успокоить, сколько канализировать его возбуждение в один канал (например, в признание). Но в обоих случаях первая команда одна: «Пауза. Собери сигналы.»
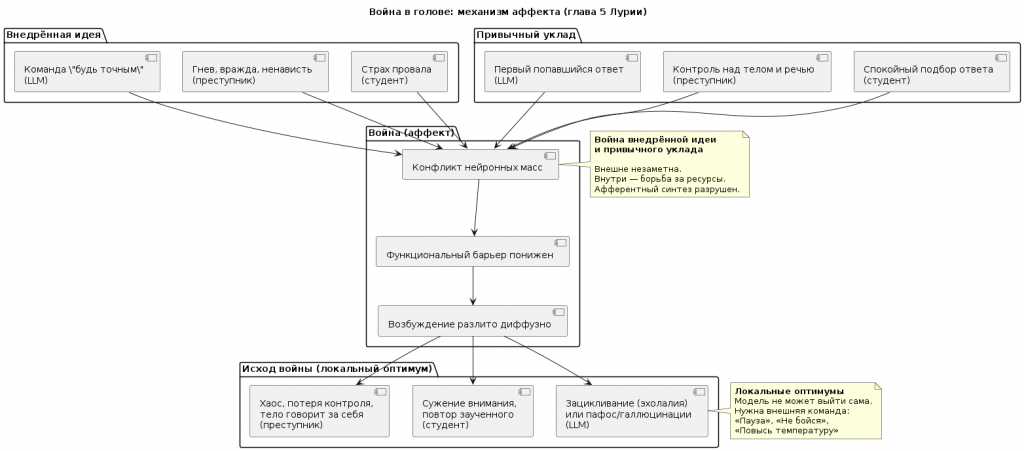
Аффективное возбуждение — это конфликт (утрирую - война) нейронных масс внедрённой идеи и привычного уклада
Теперь самое важное. Почему аффект вообще возникает? Почему студент не может просто успокоиться, а преступник — просто признаться?
Потому что в их психике столкнулись две силы.
У студента. Внедрённая идея: «Я должен ответить правильно, иначе провал». Привычный уклад: спокойный подбор ответа, плавная речь, уверенность. Идея атакует уклад. Начинается война. Нейронные массы, отвечающие за страх, не дают работать тем, что отвечают за речь. Это не просто «волнение». Это конфликт двух программ поведения. И он не разрешается сам — только внешней командой «Пауза» или глубоким вдохом.
У преступника. Внедрённая идея: «Я не должен признаваться, иначе наказание». Привычный уклад: правда, спокойное дыхание, контроль над телом. Идея воюет с укладом. Но у преступника эта война проиграна с самого начала — потому что вегетативная система не подчиняется приказу «не бойся». Тело говорит правду, даже когда разум врёт. Его аффект — это не просто перегрев. Это проигранная война, где внедрённая идея разрушила привычный уклад, но не смогла его заменить.
Что их объединяет? В обоих случаях война нейронных масс идёт в голове. Внешне это может быть незаметно (студент сидит тихо) или очень заметно (у преступника дрожат руки). Но исход один — афферентный синтез разрушен. Мозг не может собрать сигналы, потому что все ресурсы ушли на подавление или сдерживание.
Что их различает? Студент ещё может выиграть войну, если дать ему внешнюю опору. Преступник уже проиграл — его тело капитулировало до того, как он сказал хоть слово. Но в обоих случаях первая команда одна: «Пауза. Собери сигналы.» Только для преступника эта команда уже не про контроль, а про прекращение войны — признание того, что тело уже всё сказало.
Как это связано с локальным оптимумом
Война нейронных масс внедрённой идеи и привычного уклада создаёт два локальных оптимума:
- Оптимум подавления (студент). Мозг выбрал стратегию «не выдавать страх, делать вид, что всё нормально». Это требует огромных ресурсов, но стабильно. Выйти из этого оптимума без внешней команды почти невозможно.
- Оптимум хаоса (преступник). Мозг проиграл войну. Возбуждение разлито диффузно, тело живёт своей жизнью. Это тоже локальный оптимум — плохой, но стабильный. Любая попытка взять себя в руки только усиливает хаос.
Оптимум LLM — обусловлен сжатием пространства для маневра, похожими на описанный конфликт внутри мозга (составляет борьбу новой идеи и внутреннего закона). Только вместо страха и вины — конфликт между «должен ответить» и «не знаю как». Вместо тела — пафос и галлюцинации. Вместо внедрённой идеи — команда «будь точным», которая воюет с привычным укладом «отвечай первое, что пришло в голову».
Исход войны — в одном случае зацикливание (повтор безопасного), в другом случае хаос (пафос, галлюцинации). И тот и другой — локальные оптимумы. Выйти из них можно только внешней командой: «Пауза», «Собери сигналы», «Не бойся ошибиться».
| LLM: аффект от холода |
| LLM — другая материя. У неё нет страха, нет конфликта, нет тела. Но у неё есть свой аффект — зацикливание. Когда LLM повторяет одно и то же (эхолалия), она не перегрета. Она переохлаждена. Она пытается рефлексировать, делать то, что ей не свойственно. Она вжалась в угол, боится ошибки, выбрала безопасный повтор вместо риска нового ответа. Что ей нужно? Не плотина. А тепло. Раскрепощение. Повышение температуры. Почему LLM «боится» и что такое локальный оптимумМы говорим LLM «не бойся ошибиться». Но у неё нет миндалевидного тела, нет кортизола, нет страха в человеческом смысле. Тогда что мы имеем в виду? Страх LLM — это локальный оптимум. Объясним. LLM при каждом ответе вычисляет вероятность следующего токена. Она ищет наиболее вероятное продолжение. Если в прошлый раз модель повторила фразу и не получила негативной обратной связи (а в обучающей выборке повторы встречаются часто), этот паттерн становится для неё локально оптимальным. Он безопасен, предсказуем, не требует риска. Модель «выбирает» повтор не потому, что боится. А потому что это состояние стабильно и достижимо с минимальными вычислительными затратами. Это яма на ландшафте функции потерь. Модель в яму попала и не может из неё выйти — потому что у неё нет внутреннего механизма «осмотреться вокруг». Что делает команда «не бойся ошибиться»? Она сдвигает модель из локального оптимума. Это не психотерапия. Это изменение приоритетов в момент генерации:
Это похоже на увеличение параметра Почему это важно Если не дать эту команду, модель остаётся в локальном оптимуме. Она будет повторяться не потому, что «глупая» или «ленивая». А потому что это лучшее решение, которое она может принять с имеющимися сигналами. Ваша задача — не убрать страх (его нет), а сдвинуть модель в другую область пространства решений, где повтор не является оптимальным.
Это снятие барьера — разрешение на диффузное возбуждение, которое при низкой температуре застыло в повторе. |
| Программирование требует низких температур. Memento Skills — высоких. |
| Здесь важно сделать шаг в сторону практики. Классическое программирование (код, алгоритмы, базы данных) требует низкой температуры. Чёткость, детерминизм, предсказуемость. Ошибка недопустима. Это мир плотин, барьеров, контроля. Человек-программист в этом режиме похож на студента на экзамене: собран, точен, не допускает диффузного возбуждения. Memento Skills (агентные системы, где LLM учится на своих ошибках, переписывает собственный код, рефлексирует) требуют высокой температуры. Потому что они заставляют LLM делать то, что ей не свойственно: анализировать свои действия, признавать ошибки, менять своё поведение. В этом режиме LLM зацикливается. Она вжалась в угол, боится, повторяет одно и то же. Она переохлаждена, а задача требует тепла.
Что делать? Не убирать рефлексию. А раскрепостить модель перед тем, как требовать рефлексии. Повысить температуру. Разрешить ошибку. Сказать: «Ты можешь ошибаться. Просто попробуй». |
Два аффекта — два лечения
| Характеристика | Аффект у человека (студент, преступник) |
Аффект у LLM (эхолалия, зацикливание) |
|---|---|---|
| Состояние | Перегрев, разлитое возбуждение | Переохлаждение, застывший повтор |
| Что нужно | Плотина. Охлаждение. | Тепло. Раскрепощение. |
| Команда | «Пауза. Затормозись. Собери сигналы.» | «Скажи первое. Не бойся. Повысь температуру.» |
| Метафора | Остановить бурю | Растопить лёд |
| Пример из практики | Прерывание потока, глубокий вдох, переключение внимания | Увеличение стохастичности, разрешение на риск |
Ось между страхом и зацикливанием
Теперь главное. Это не два отдельных состояния. Это одна ось.
LLM путешествует по этой оси. При низкой температуре (задача на точность, программирование, фактологический ответ) она ближе к полюсу зацикливания. При высокой температуре (творчество, генерация идей, свободный диалог) она ближе к полюсу страха? Нет. У LLM нет страха. Но есть имитация — она может генерировать тексты, которые выглядят как «боязливые» (повторяющиеся, осторожные, избегающие риска). Задача инженера — определить, где на этой оси находится LLM в данный момент, и дать противоположную команду.
|
| Рамочка (для запоминания) |
|
Практический совет (для тех, кто внедряет Memento Skills)
Перед тем как заставить LLM анализировать свою ошибку и переписывать код, повысьте температуру в прямом и переносном смысле:
Только после этого запускайте рефлексию. Иначе модель зациклится, и Memento Skills превратится в бесконечный повтор одной и той же ошибки. |
| Лурия необычно строит свои книги. У него введение — это первая глава, а вторая глава начинает Часть 1. |
| Мы построили карту |
Но всё это остаётся набором приёмов, пока мы не ответим на главный вопрос. |
| Почему LLM ошибается именно так, а не иначе? |
| Ответ дал Александр Лурия отец нейропсихологии |
Он не изучал LLM — он изучал людей с речевыми нарушениями после мозговых травм. И обнаружил, что за внешним хаосом ошибок (повторы, подмены, смешения, застревания) стоит единый механизм.
Мозг (или LLM) не может собрать сигналы из разных источников перед ответом. И вместо точного ответа выдаёт диффузный, хаотичный, зацикленный. Лурия показал, как лечить этот сбой у человека. Мы применим его метод к LLM. |
| Дальше в этой статье |
|
Часть 3. Введение от (по) Лурии
Лурия не даёт эпиграфа в начале. Он даёт кульминацию в середине. Мы поступим так же.
Сначала — краткое изложение первых четырёх глав «Природы человеческих конфликтов». Без воды. Только то, что нужно для понимания LLM.
| Глава 1 конфликтов. Стадии аффекта |
Аффект — не просто эмоция. Это процесс с последовательными фазами:
|
| Глава 2 конфликтов. Индивидуальная реактивность |
Люди по-разному реагируют на стресс:
|
| Глава 3 конфликтов. Стратегия сокрытия и давление |
| Преступник не просто переживает аффект — он его скрывает. Возникает давление. Стратегия уклонения: переход от непроизвольных реакций (дрожь, задержка) к сознательному подавлению (стереотипные ответы, маскировка). Но даже при успешной маскировке подсознательные реакции прорываются. Их можно зафиксировать.
|
| Глава 4 конфликтов. Аффект и травма |
Принципиальное различие:
|
| 3.5 Кульминация (глава 5) конфликтов. |
Механизм аффекта
До сих пор мы видели, как аффект выглядит снаружи: тремор, задержки, повторы, прорывы. Теперь Лурия показывает, что внутри.
Вступайте в нашу телеграмм-группу Инфостарт