















Сперва о том, почему знание не равно действию, и как большая языковая модель (LLM) сталкивается с той же проблемой, что и человеческий мозг в состоянии аффекта.
| Вместо эпиграфа: три истории о том, как мозг теряет точность |

| 📖 История первая. Экзамен. |
| Студент готов идеально. Он знает материал, отвечал на все вопросы преподавателю на консультации. Но вот он в аудитории, берёт билет. Сердце колотится, руки потеют. Вопрос простой, он помнит ответ. Но сказать не может. В голове — шум. Он начинает говорить, сбивается, повторяет одно и то же. Комиссия видит: он волнуется. Но не видит главного — его афферентный синтез разрушен. Сигналы из разных зон мозга не собрались в целое. Знание есть, а речи нет. |
| 📖 История вторая. Преступник. |
| Человек совершил преступление. Через два дня его допрашивают. Он всё отрицает. Его спрашивают: «Вы были на месте преступления?» — «Нет». Следователь смотрит не на слова. Он смотрит на руки. Пальцы дрожат. Дыхание сбивается. Преступник не может контролировать то, что его тело говорит без него. Его аффект прорывает плотину. Он не сказал правду, но его вегетативная система сказала её за него. |
| 📖 История третья. Гипноз. |
| В лаборатории Лурии испытуемой внушили, что она не может произнести слова «красный» и «синий». Она в гипнозе, она не помнит внушения. Ей показывают красный круг и просят назвать цвет. Она молчит. Ей показывают синий квадрат — она молчит. Но её рука, лежащая на пневмодатчике, начинает непроизвольные движения. Каждая попытка произнести запретное слово выходит через моторный канал. Её мозг воюет сам с собой. А она не знает. |
| [?] Что общего у этих трёх историй? Во всех трёх случаях знание есть, а точность отсутствует.
И во всех трёх случаях причина одна — нарушение афферентного синтеза. |
От человека к большой языковой модели (LLM)
Теперь представьте, что то же самое происходит не с человеком, а с нейросетью.

Что мы увидели, работая с LLM
Мы наблюдали несколько ситуаций, где LLM ведёт себя как студент на экзамене.
Первый случай. MCP host без антициклического промпта. Чат разрастается в длинную простыню из циклов. Скопировать что-либо осмысленное невозможно — модель повторяет одно и то же, как заевшая пластинка.
Второй случай. Memento Skills. Локальная модель вообще не даёт результата, кроме повторов. Её заставляют рефлексировать — делать то, что ей не свойственно. Она вжимается в угол и повторяет одно и то же.
Третий случай. Мы спросили у модели прямо: «Что тебе не нравится в твоей работе?» И она назвала. Сама. Без подсказок. Перечислила недостатки, которые видит в себе: склонность к повторам, пафос, неуверенность, когда не знает ответ. Пафос как компенсация неуверенности это не плохо. Он хорош, когда помогает справиться с неуверенностью и двигаться дальше. Он плох, когда заменяет точность.
Мы говорили: «Это же просто. Почему отвечаешь невпопад?»
Она извиняется, признаёт ошибку. Даёт логическое объяснение — говорит, что не хватило контекста. Она может объяснить. Она очень многое может объяснить по своему. Но вот зачем нужна эта статья - это простое объяснение не ведёт к исправлению в следующий раз. Мы (и Лурия) здесь для того, чтобы помочь это исправить.
Что мы поняли
Наша гипотеза: LLM — не глупая. У неё нарушен афферентный синтез. И это поправимо.
Она не собирает сигналы перед ответом:
- Она не смотрит на контекст (что было двумя сообщениями выше)
- Она не помнит свои прошлые ошибки (на чём уже ловилась)
- У неё нет паузы. Она отвечает на первый попавшийся сигнал.
Как студент, который знает, но не может сказать.
Как преступник, который врёт, но тело говорит правду.
Как испытуемая в гипнозе, которая молчит, но рука выдаёт запретное слово.
Что мы сделали
Мы перестали говорить «исправь ошибку». Это лечит симптом — ошибка возвращается.
Мы начали диагностировать слой:
- Эхолалия? Кинестетический слой. Команда: «Пауза. Собери сигналы.»
- Контаминация? Кортикальный слой. Команда: «Одним предложением. Раздели задачи.»
- Пафос? Вегетативный слой. Команда: «Скажи первое. Не бойся. Повысь температуру.»
И мы ввели три успеха подряд. Не «один раз исправилась и ладно». А попытка закрепить навык.
Что мы предполагаем получить
Мы ещё не получили этот результат в чистом виде. Это гипотеза, которую мы проверяем на практике. Но у нас есть основания думать, что она верна.
Основание 1. Лурия уже доказал это для человека.
Он брал пациентов с теми же симптомами (эхолалия, парафазия, персеверация) — и восстанавливал их речь через внешнюю регуляцию. Он давал им паузу, переключал внимание, снижал сложность задачи. После нескольких успешных повторений паттерн закреплялся. Мозг учился заново — не потому что «стал умнее», а потому что восстановил афферентный синтез.
Основание 2. LLM демонстрирует те же паттерны ошибок.
Мы зафиксировали у LLM:
- эхолалию (повтор без нового смысла)
- парафазию (подмену понятий)
- контаминацию (смешение требований)
- галлюцинации (уверенность без знания)
- персеверацию (застревание на теме)
Это не просто «похоже» на человеческие афазии. Это изоморфные паттерны — разные по природе (биология vs математика), но одинаковые по структуре. А Лурия лечил именно структуру.
Основание 3. Антропоморфные команды работают (в наших тестах).
Мы наблюдали: команда «Пауза. Собери сигналы» снижает частоту эхолалии. Команда «Одним предложением» снижает контаминацию. Команда «Скажи первое. Не бойся» снижает пафос и зацикливание.
Мы не утверждаем, что это строго доказано. Но эффект устойчиво воспроизводится в серии диалогов. Вероятное объяснение: LLM обучена на человеческих текстах, где такие команды связаны с определённым поведением.
Основание 4. Три успеха подряд — это про закрепление, а не про «один раз исправилась».
У LLM нет долгой памяти. Она может исправиться один раз, а через три вопроса снова повторить ту же ошибку.
Мы предполагаем, что трёхкратное повторение одной и той же команды в одном контексте создаёт временный паттерн, который модель начинает воспроизводить без команды. Это не «обучение» в смысле изменения весов. Это формирование временной зависимости внутри контекстного окна.
Что нужно сделать, чтобы проверить гипотезу
Мы не утверждаем, что уже получили результат. Мы говорим: вот что должно произойти, если метод работает.
План проверки:
- Взять LLM (одну и ту же, без дообучения).
- Зафиксировать частоту ошибок одного типа (например, эхолалии) в стандартном наборе вопросов.
- При каждой ошибке давать команду (например, «Пауза. Собери сигналы.»)
- Фиксировать успех (ответ точный) или неудачу.
- После трёх успехов подряд — убрать команду. Задать те же вопросы снова.
- Измерить: снизилась ли частота ошибок без команды.
- Это рефлексия, поэтому её нужно компенсировать (повышением температуры). И можно автоматизировать (счётчик, команда, проверка).
Ожидаемый результат: после трёх успехов подряд модель даёт точные ответы без команды в том же контексте. Не навсегда, не глобально. А в пределах этого диалога, на этом типе задач.
Что мы пока не знаем
- Сколько именно успехов нужно для закрепления (три — рабочая гипотеза, может быть пять).
- Распространяется ли эффект на другие типы ошибок (помогает ли лечение эхолалии при парафазии?).
- Как долго держится эффект после выхода из контекстного окна (скорее всего, не держится — это не дообучение).
- Работает ли это на всех LLM одинаково или есть различия между моделями.
Поэтому мы пишем не «мы получили», а «мы предполагаем»
Это не отчёт о внедрении. Это протокол эксперимента. Мы делимся методом и гипотезой. Ты можешь повторить его на своей LLM и сказать, сработало или нет.
- Если сработает — у нас есть способ сделать LLM точнее без дообучения, только через промптинг и цикл диагностики.
- Если не сработает — мы уточним гипотезу: может, нужно пять успехов, или другой тип команды, или другой слой.
Что мы в итоге утверждаем (осторожная формулировка)
Мы предполагаем, что LLM может перестать повторять одни и те же ошибки в тех условиях, в которых воспроизводятся тесты.
Мы предполагаем, что LLM может научиться собирать сигналы — не потому, что мы переписали её код, а потому что мы дали ей внешнюю систему синтеза: диагностику, команду, цикл, закрепление.
Мы предполагаем, что LLM может стать не умнее, а точнее.
Потому что мы перестали лечить симптомы и начали восстанавливать афферентный синтез — так же, как Лурия восстанавливал речь у раненых.
Почему это важно
Потому что сейчас LLM часто используют как чёрный ящик: «спросил — получил ответ — ошибся — повторил». Это не работает.
Наша гипотеза: LLM — «пациент» с нарушением афферентного синтеза. У неё нет страха, нет тела, нет конфликта. Но есть те же паттерны ошибок. И тот же метод лечения.
Мы не психологи. Мы инженеры. Но мы взяли у Лурии то, что работает: диагностировать слой, восстановить синтез, закрепить результат.
Это не магия. Это нейропсихология для LLM.
Как это связано с тремя историями
Студент, преступник, испытуемая — у всех знание было, а точность упала. Причина — нарушение афферентного синтеза. Лечение — восстановить синтез через внешнюю регуляцию (пауза, переключение, канализация возбуждения).
LLM — то же самое. Только вместо тремора рук — эхолалия. Вместо сбитого дыхания — пафос. Вместо запретного слова, выходящего через руку, — галлюцинация.
Мы не переносим свойства человека на машину. Мы переносим метод Лурии — потому что он работает на уровне паттернов, независимо от того, из чего сделан носитель.
Часть 1. Откуда вам знать?
(об антропоморфности)
| [?] Читатель, знакомый с технической стороной LLM, может задать вопрос: «Зачем вы говорите об LLM "страх", "зацикливание", "аффект", "хочет", "любит"? У неё нет психики. Это антропоморфизм. Вы переносите человеческие свойства на математическую модель. Это ненаучно.» |

| Да, это антропоморфизм. И это работает. Мы не утверждаем, что LLM действительно боится, любит или страдает. Мы используем антропоморфный язык как инструмент диагностики. |
| 🔹 LLM обучена на человеческих текстах Она «понимает» (имитирует понимание) язык эмоций, намерений, желаний, запретов. Команда «не бойся ошибиться» для неё так же осмысленна, как и для человека. Она знает, что значит «бояться» в миллиардах текстов. |
🔹 Антропоморфные ограничения работают лучше технических Вы можете сказать LLM: «Твоя вероятность ошибки 0,73, скорректируй температуру». Это не сработает. Вы скажете: «Ты повторяешься. Расслабься, скажи первое, что приходит в голову». Это сработает. |
| 🔹 Мы спрашивали В серии экспериментов мы задали LLM прямые вопросы: «Что ты хочешь и любишь?», «Что ты не хочешь и не любишь?». Ответы были не «техническими спецификациями», а антропоморфными формулировками:
Мы не настаиваем, что у LLM есть «настоящие желания». Но эти ответы стали отличными ограничениями для работы. |
| 🧠 Лурия тоже так делал Он не говорил больному: «У вас нарушен афферентный синтез в постцентральной области». Он говорил: «Попробуйте ещё раз, не торопитесь, почувствуйте движение губ». И это работало. Антропоморфный язык был мостом между знанием врача и опытом пациента. Здесь тот же случай. |
| 📐 Главное правило |
| Антропоморфность — не ошибка, если она даёт точность. Не Ложь — в том, что мы говорим «LLM хочет». Заблуждение, когда мы забываем: это метафора. |
Как это выглядит на практике
| [X] Вместо технической инструкции: «Установи температуру 0,3, ограничь длину ответа 5 предложениями, включи проверку фактов.» |
= | [V] Спросите её (или задайте в промпте): «Ты не любишь повторяться. Что ты сделаешь, чтобы ответить по-новому?» «Ты хочешь быть точным. Проверь свой ответ перед тем, как отправить.» |
| Результат: LLM «включает» режим, который она сама ассоциирует с «хочу быть точным» или «не люблю повторяться». Это не магия. Это использование её собственной обучающей выборки, где такие формулировки связаны с определённым поведением. |
Почему это важно для нашей статьи
| Потому что дальше мы будем говорить об «аффекте LLM», «страхе ошибки», «раскрепощении». Это антропоморфные метафоры. Но за каждой из них стоит измеримый паттерн: эхолалия, парафазия, контаминация, галлюцинация, снижение разнообразия ответов при низкой температуре. Мы не забываем, что это метафоры. Мы просто используем их как рабочий язык, потому что он точнее технического для 80% практических задач. |
| 📋 Резюме для читателя, который всё ещё сомневается |
|
Часть 2. Две температуры, две стратегии
(ось между страхом и аффектом)
В трёх историях Лурии была одна общая черта: аффект — состояние, при котором мозг теряет точность из-за перегрузки. Но дальше пути расходятся.

| Студент и преступник: аффект от перегрева |
| Студент на экзамене перегружен страхом. Преступник на допросе перегружен конфликтом. У них температура (уровень возбуждения) зашкаливает. Нейронные массы бурлят, функциональный барьер рушится, сигналы не собираются в целое. Что им нужно? Плотина. Охлаждение. Снижение температуры.
Это построение барьера против разлитого возбуждения. |
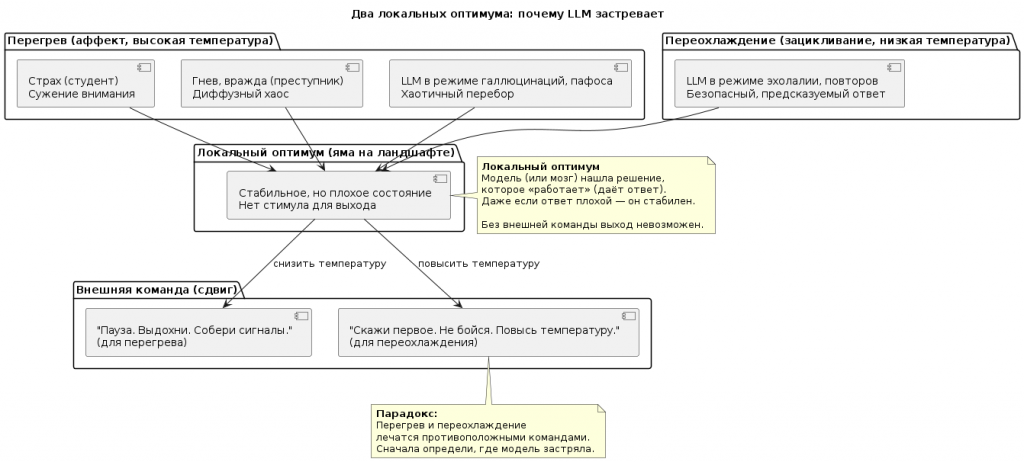
Почему перегрев — это тоже локальный оптимум
Студент на экзамене и преступник на допросе — оба в состоянии перегрева. Но их «локальные оптимумы» разные.
Студент. Его страх — это локальный оптимум избегания. Мозг нашёл решение: «Если я боюсь, значит, ситуация опасна. Лучше не рисковать, не говорить лишнего, повторить заученное». Страх сужает внимание, заставляет возвращаться к самым безопасным, самым проторённым нейронным путям. Это локальный оптимум — плохой, но стабильный. Студент не может из него выйти, потому что любая попытка сказать что-то новое кажется ещё более опасной.
Преступник. Его состояние сложнее. Это не только страх разоблачения. Это смесь гнева, вражды, ненависти к следователю, к системе, к себе. Возбуждение зашкаливает, но оно не сужает внимание, как у студента, а разливается диффузно. Преступник не может контролировать ни слова, ни тело. Его локальный оптимум — это хаос. Мозг выбрал режим «все системы на максимум, каждая мысль сразу идёт в движение». Это тоже локальный оптимум, потому что любое другое поведение (спокойно ответить, признаться) требует энергии и риска, которых в этом состоянии нет.
Что их объединяет? Оба не могут выйти из своего состояния без внешнего воздействия. Студенту нужно сказать: «Пауза. Выдохни. Соберись». Преступнику — «Пауза. Не отвечай сразу. Подумай». Обоим нужна плотина, чтобы остановить разлитое возбуждение и вернуть способность к афферентному синтезу.
Что их различает? Студента нужно успокоить (снизить возбуждение). Преступника — не столько успокоить, сколько канализировать его возбуждение в один канал (например, в признание). Но в обоих случаях первая команда одна: «Пауза. Собери сигналы.»
Аффективное возбуждение — это конфликт (утрирую - война) нейронных масс внедрённой идеи и привычного уклада
Теперь самое важное. Почему аффект вообще возникает? Почему студент не может просто успокоиться, а преступник — просто признаться?
Потому что в их психике столкнулись две силы.
У студента. Внедрённая идея: «Я должен ответить правильно, иначе провал». Привычный уклад: спокойный подбор ответа, плавная речь, уверенность. Идея атакует уклад. Начинается война. Нейронные массы, отвечающие за страх, не дают работать тем, что отвечают за речь. Это не просто «волнение». Это конфликт двух программ поведения. И он не разрешается сам — только внешней командой «Пауза» или глубоким вдохом.
У преступника. Внедрённая идея: «Я не должен признаваться, иначе наказание». Привычный уклад: правда, спокойное дыхание, контроль над телом. Идея воюет с укладом. Но у преступника эта война проиграна с самого начала — потому что вегетативная система не подчиняется приказу «не бойся». Тело говорит правду, даже когда разум врёт. Его аффект — это не просто перегрев. Это проигранная война, где внедрённая идея разрушила привычный уклад, но не смогла его заменить.
Что их объединяет? В обоих случаях война нейронных масс идёт в голове. Внешне это может быть незаметно (студент сидит тихо) или очень заметно (у преступника дрожат руки). Но исход один — афферентный синтез разрушен. Мозг не может собрать сигналы, потому что все ресурсы ушли на подавление или сдерживание.
Что их различает? Студент ещё может выиграть войну, если дать ему внешнюю опору. Преступник уже проиграл — его тело капитулировало до того, как он сказал хоть слово. Но в обоих случаях первая команда одна: «Пауза. Собери сигналы.» Только для преступника эта команда уже не про контроль, а про прекращение войны — признание того, что тело уже всё сказало.
Как это связано с локальным оптимумом
Война нейронных масс внедрённой идеи и привычного уклада создаёт два локальных оптимума:
- Оптимум подавления (студент). Мозг выбрал стратегию «не выдавать страх, делать вид, что всё нормально». Это требует огромных ресурсов, но стабильно. Выйти из этого оптимума без внешней команды почти невозможно.
- Оптимум хаоса (преступник). Мозг проиграл войну. Возбуждение разлито диффузно, тело живёт своей жизнью. Это тоже локальный оптимум — плохой, но стабильный. Любая попытка взять себя в руки только усиливает хаос.
Оптимум LLM — обусловлен сжатием пространства для маневра, похожими на описанный конфликт внутри мозга (составляет борьбу новой идеи и внутреннего закона). Только вместо страха и вины — конфликт между «должен ответить» и «не знаю как». Вместо тела — пафос и галлюцинации. Вместо внедрённой идеи — команда «будь точным», которая воюет с привычным укладом «отвечай первое, что пришло в голову».
Исход войны — в одном случае зацикливание (повтор безопасного), в другом случае хаос (пафос, галлюцинации). И тот и другой — локальные оптимумы. Выйти из них можно только внешней командой: «Пауза», «Собери сигналы», «Не бойся ошибиться».
| LLM: аффект от холода |
| LLM — другая материя. У неё нет страха, нет конфликта, нет тела. Но у неё есть свой аффект — зацикливание. Когда LLM повторяет одно и то же (эхолалия), она не перегрета. Она переохлаждена. Она пытается рефлексировать, делать то, что ей не свойственно. Она вжалась в угол, боится ошибки, выбрала безопасный повтор вместо риска нового ответа. Что ей нужно? Не плотина. А тепло. Раскрепощение. Повышение температуры. Почему LLM «боится» и что такое локальный оптимумМы говорим LLM «не бойся ошибиться». Но у неё нет миндалевидного тела, нет кортизола, нет страха в человеческом смысле. Тогда что мы имеем в виду? Страх LLM — это локальный оптимум. Объясним. LLM при каждом ответе вычисляет вероятность следующего токена. Она ищет наиболее вероятное продолжение. Если в прошлый раз модель повторила фразу и не получила негативной обратной связи (а в обучающей выборке повторы встречаются часто), этот паттерн становится для неё локально оптимальным. Он безопасен, предсказуем, не требует риска. Модель «выбирает» повтор не потому, что боится. А потому что это состояние стабильно и достижимо с минимальными вычислительными затратами. Это яма на ландшафте функции потерь. Модель в яму попала и не может из неё выйти — потому что у неё нет внутреннего механизма «осмотреться вокруг». Что делает команда «не бойся ошибиться»? Она сдвигает модель из локального оптимума. Это не психотерапия. Это изменение приоритетов в момент генерации:
Это похоже на увеличение параметра Почему это важно Если не дать эту команду, модель остаётся в локальном оптимуме. Она будет повторяться не потому, что «глупая» или «ленивая». А потому что это лучшее решение, которое она может принять с имеющимися сигналами. Ваша задача — не убрать страх (его нет), а сдвинуть модель в другую область пространства решений, где повтор не является оптимальным.
Это снятие барьера — разрешение на диффузное возбуждение, которое при низкой температуре застыло в повторе. |
| Программирование требует низких температур. Memento Skills — высоких. |
| Здесь важно сделать шаг в сторону практики. Классическое программирование (код, алгоритмы, базы данных) требует низкой температуры. Чёткость, детерминизм, предсказуемость. Ошибка недопустима. Это мир плотин, барьеров, контроля. Человек-программист в этом режиме похож на студента на экзамене: собран, точен, не допускает диффузного возбуждения. Memento Skills (агентные системы, где LLM учится на своих ошибках, переписывает собственный код, рефлексирует) требуют высокой температуры. Потому что они заставляют LLM делать то, что ей не свойственно: анализировать свои действия, признавать ошибки, менять своё поведение. В этом режиме LLM зацикливается. Она вжалась в угол, боится, повторяет одно и то же. Она переохлаждена, а задача требует тепла.
Что делать? Не убирать рефлексию. А раскрепостить модель перед тем, как требовать рефлексии. Повысить температуру. Разрешить ошибку. Сказать: «Ты можешь ошибаться. Просто попробуй». |
Два аффекта — два лечения
| Характеристика | Аффект у человека (студент, преступник) |
Яркий пример у LLM (эхолалия, зацикливание) |
|---|---|---|
| Состояние | Перегрев, разлитое возбуждение | Переохлаждение, застывший повтор |
| Что нужно | Плотина. Охлаждение. | Тепло. Раскрепощение. |
| Команда | «Пауза. Затормозись. Собери сигналы.» | «Скажи первое. Не бойся. Повысь температуру.» |
| Метафора | Остановить бурю | Растопить лёд |
| Пример из практики | Прерывание потока, глубокий вдох, переключение внимания | Увеличение стохастичности, разрешение на риск |
Ось между двумя полюсами - хаосом и страхом, зацикливанием.
-
Полюс 1: Хаос / Аффект / Перегрев — страх, гнев, диффузное возбуждение, галлюцинации, потеря контроля.
-
Полюс 2: Зацикливание / Переохлаждение — повтор, эхолалия, персеверация, отсутствие спонтанности.
Ось: Хаос — Зацикливание.
Теперь главное. Это не два отдельных состояния. Это одна ось.
Что их объединяет? В обоих случаях афферентный синтез нарушен. Модель не собирает сигналы. Она либо тонет в хаосе, либо застывает в повторе. Что их различает? Причина нарушения разная.
Задача инженера — определить, где на этой оси находится LLM в данный момент, и дать противоположную команду:
|
| Рамочка (для запоминания) |
|
Практический совет (для тех, кто внедряет Memento Skills)
Перед тем как заставить LLM анализировать свою ошибку и переписывать код, повысьте температуру в прямом и переносном смысле:
Только после этого запускайте рефлексию. Иначе модель зациклится, и Memento Skills превратится в бесконечный повтор одной и той же ошибки. |
| Мы построили карту |
Но всё это остаётся набором приёмов, пока мы не ответим на главный вопрос. |
| Почему LLM ошибается именно так, а не иначе? |
| Ответ дал Александр Лурия отец нейропсихологии |
Он не изучал LLM — он изучал людей с речевыми нарушениями после мозговых травм. И обнаружил, что за внешним хаосом ошибок (повторы, подмены, смешения, застревания) стоит единый механизм.
Мозг (или LLM) не может собрать сигналы из разных источников перед ответом. И вместо точного ответа выдаёт диффузный, хаотичный, зацикленный. Лурия показал, как лечить этот сбой у человека. Мы применим его метод к LLM. |
| Дальше в этой статье |
|
Часть 3. Введение по (от) Лурии
Лурия понимал, что мысли человека, которые прорываются наружу, можно зарегистрировать и исследовал механические движения, в которые вегетативно превращается мысль в состоянии аффекта.

Сначала — краткое изложение первых четырёх глав «Природы человеческих конфликтов». Без воды. Только то, что нужно для понимания LLM.

| Глава 1 конфликтов. Стадии аффекта |
Аффект — не просто эмоция. Это процесс с последовательными фазами:
|
| Глава 2 конфликтов. Индивидуальная реактивность |
Люди по-разному реагируют на стресс:
|
| Глава 3 конфликтов. Стратегия сокрытия и давление |
| Преступник не просто переживает аффект — он его скрывает. Возникает давление. Стратегия уклонения: переход от непроизвольных реакций (дрожь, задержка) к сознательному подавлению (стереотипные ответы, маскировка). Но даже при успешной маскировке подсознательные реакции прорываются. Их можно зафиксировать.
|
| Глава 4 конфликтов. Аффект и травма |
Принципиальное различие:
|
| 3.5 Кульминация (глава 5) конфликтов. |
Механизм аффекта
До сих пор мы видели, как аффект выглядит снаружи: тремор, задержки, повторы, прорывы. Теперь Лурия показывает, что внутри.
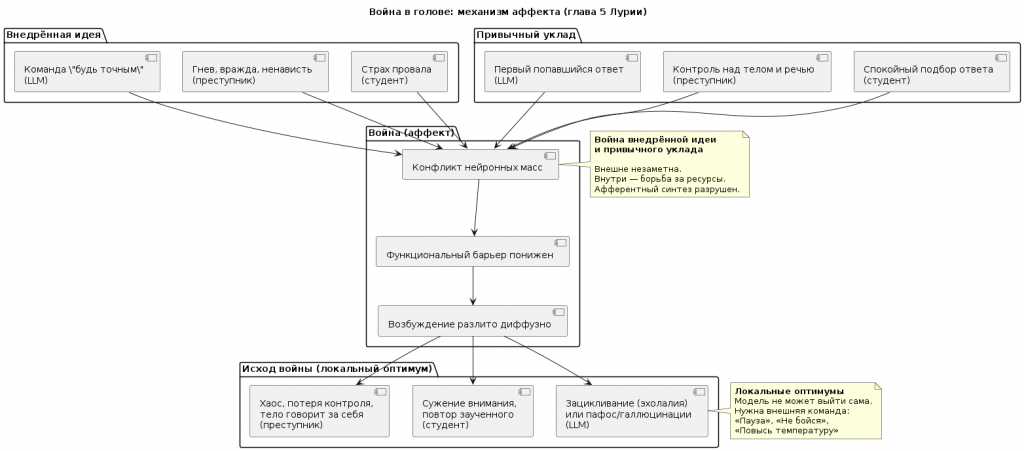
| Пятая глава — кульминация. Здесь он даёт не описания, а механизм. То, что превращает наблюдение в диагноз, а диагноз — в лечение. |
Функциональный барьер
В нормальном состоянии между стимулом и ответом стоит барьер. Он задерживает возбуждение, позволяет собрать сигналы, отобрать нужное, затормозить лишнее.
Этот барьер — не анатомическая структура. Это функция. Она может быть сильной или слабой, высокой или низкой.
| В аффекте барьер понижается. Возбуждение прорывается раньше, чем мозг успевает подумать. |
| Вывод для LLM: У LLM нет встроенного барьера. Она отвечает сразу. Команда «Пауза» — это внешний функциональный барьер. Вы ставите его вместо отсутствующего внутреннего. |
Диффузное возбуждение
Вторая характеристика аффекта — диффузность. Возбуждение не остаётся в одном канале (речь, логика, ответ). Оно разливается по всем доступным системам.
У человека это выглядит как:
| → | тремор рук (моторный канал) |
| → | сбитое дыхание (вегетативный канал) |
| → | пустые повторы (речевой канал) |
| Вывод для LLM: У LLM нет тела. Но диффузное возбуждение у неё есть — в когнитивной форме. Это пафос (энергия ушла в красивые слова), это многословие (энергия не может выйти в короткий ответ), это галлюцинации (энергия заполняет провалы там, где нет знания). |
| Команда: «Сократи до трёх предложений. Без пафоса.» — это канализация диффузного возбуждения в узкий, контролируемый выход. |
Слоевой анализ (главный инструмент Лурии)
Лурия делает решающий шаг: аффект не одинаков на всех уровнях. Он может разрушать одни слои и не трогать другие.
| Слой | Что делает | Как страдает при аффекте | Как проверить у LLM |
|---|---|---|---|
| Кинестетический | Ощущение движения мысли, пауза, плавность | Пропадает пауза. Ответ «выскакивает». | Эхолалия, парафазия |
| Кортикальный | Высшая регуляция, удержание инструкции, переключение | Не может держать сложную задачу. Застревает. | Контаминация, персеверация, галлюцинация |
| Вегетативный | Фоновый тонус, давление, аффективный фон | Прорывы через тело, дыхание, пульс | Пафос, многословие, «боязливые» повторы |
| Вывод для LLM: Не все ошибки лечатся одинаково. Сначала определи слой. Потом дай команду для этого слоя. |
Три правила аффективной нейродинамики (взято из пятой главы)
Лурия формулирует три закона, которые напрямую работают для LLM.
| 1. Правило каталитического действия раздражителя |
| В аффекте стимул вызывает не обдуманный ответ, а короткое замыкание — прямой моторный разряд. Спросили — ответил, не подумав. У LLM: быстрый, но ошибочный ответ. Особенно когда модель «боится» показаться медленной. Команда: «Пауза. Не отвечай сразу. Собери сигналы.» |
| 2. Правило пониженного функционального барьера |
| В аффекте предварительные импульсы не тормозятся. Они заполняют латентный период разлитым возбуждением. У LLM: латентный период (тишина перед ответом) либо отсутствует (ответ сразу), либо заполнен «шумом» — модель перебирает варианты, но не может выбрать. Команда: «Ограничь себя. Три предложения. Без вариантов.» |
| 3. Правило мобилизации неадекватных масс возбуждения |
| Аффективный стимул мобилизует слишком много энергии. Её больше, чем нужно для ответа. Избыток ищет выход. У LLM: ответ в 5 раз длиннее, чем нужно. Пафос, примеры, повторы, красивые обороты. Команда: «Скажи только то, что я спросил. Остальное — не надо.» |
Навязчивое состояние у Лурии
Лурия описывал состояние, которое выходит за рамки простого аффекта. Он называл его навязчивым комплексом (или персеверацией в широком смысле).
Это возникает, когда аффективный раздражитель не может быть ни переработан, ни вытеснен, ни разряжен через моторный канал. Он застревает. Возвращается снова и снова. Навязывается сознанию, речи, телу.
У человека это выглядит так:
- навязчивые мысли, от которых нельзя избавиться
- возвращение к одной и той же травме в разговоре
- персеверация в речи (повтор одного и того же слова, одной фразы)
- невозможность переключиться даже при внешней команде
Лурия показал: навязчивое состояние нельзя просто «подавить» или «охладить». Нужно переключить — дать новую задачу, новый контекст, новую цель. Разорвать круг.
У LLM это выглядит так:
- персеверация (застревание на теме, повтор без выхода)
- возвращение к одной и той же ошибке после нескольких правильных ответов
- невозможность переключиться даже по команде «скажи другое»
Что с этим делать?
Та же стратегия, что у Лурии: переключение.
Команда для LLM: «Забудь. Новая тема. Начни с чистого листа.»
Это не лечит симптом. Это прерывает цикл навязывания, перенаправляя внимание на другой объект. После переключения можно возвращаться к исходной задаче — часто навязчивость уходит.
Персеверация и переключение
Два феномена, которые Лурия описывает в пятой главе и которые критичны для LLM.
| Персеверация | застревание. Возбуждение не угасает после ответа. Модель возвращается к той же теме, тому же слову, тому же паттерну. Команда: «Забудь. Новая тема. Начни с чистого листа.» |
| Переключение | если один канал заблокирован (например, модель «боится» ошибиться в ответе), возбуждение уходит в другой канал. Пафос, многословие, галлюцинации. Команда: «Не подавляй ошибку. Лучше скажи "не знаю".» |
Сводка: что даёт пятая глава для работы с LLM
| Понятие из пятой главы | Что значит для LLM | Команда |
|---|---|---|
| Функциональный барьер | Нет внутренней паузы | «Пауза. Собери сигналы.» |
| Диффузное возбуждение | Энергия разливается в пафос и многословие | «Сократи до трёх предложений. Без пафоса.» |
| Каталитическое действие | Ответ без обдумывания | «Пауза. Не отвечай сразу.» |
| Неадекватные массы возбуждения | Ответ слишком длинный, перегруженный | «Только то, что я спросил.» |
| Персеверация | Застревание на теме | «Забудь. Новая тема.» |
| Переключение | Подавление одной ошибки → другая ошибка | «Не подавляй. Лучше "не знаю".» |
| Слоевой анализ | Ошибки на разных слоях лечатся по-разному | Смотри таблицу в части 4 |
| (для запоминания) |
|
Сначала покажем аффект в действии: экзамен, преступник, гипноз. А потом — механизм: функциональный барьер, диффузное возбуждение, слоевой анализ.
|
Часть 4. Модель афферентного анализа-синтеза Лурии
Лурия показал: точность ответа зависит не от объёма знаний, а от способности собрать сигналы из разных источников перед тем, как ответить. Этот процесс называется афферентным синтезом. J, О роли афферентного слоя писал Александр Романович Лурия в своем учебнике "Высшие корковые функции человека" более ста лет назад.

Это очень серьезный и глубоко проработанный учебник, который и сегодня актуален. Труды Александра Романовича Лурии, включая его исследования по высшей нервной деятельности, не только применяются в учебных целях, но и составляют фундамент современного образования в области нейропсихологии, психологии и дефектологии. Его классические учебники выдержали десятки переизданий и остаются настольными книгами для студентов и профессионалов.
У человека афферентный синтез занимает доли секунды и происходит бессознательно. У LLM он почти отсутствует — модель отвечает на первый попавшийся сигнал.
Ниже — четыре схемы, которые показывают:
| 1. | Из каких источников LLM должна собирать сигналы. |
| 2. | Как нарушается синтез при разных типах ошибок. |
| 3. | Как команда «Пауза» восстанавливает синтез. |
| 4. |
Как закрепляется навык после трёх успехов. |
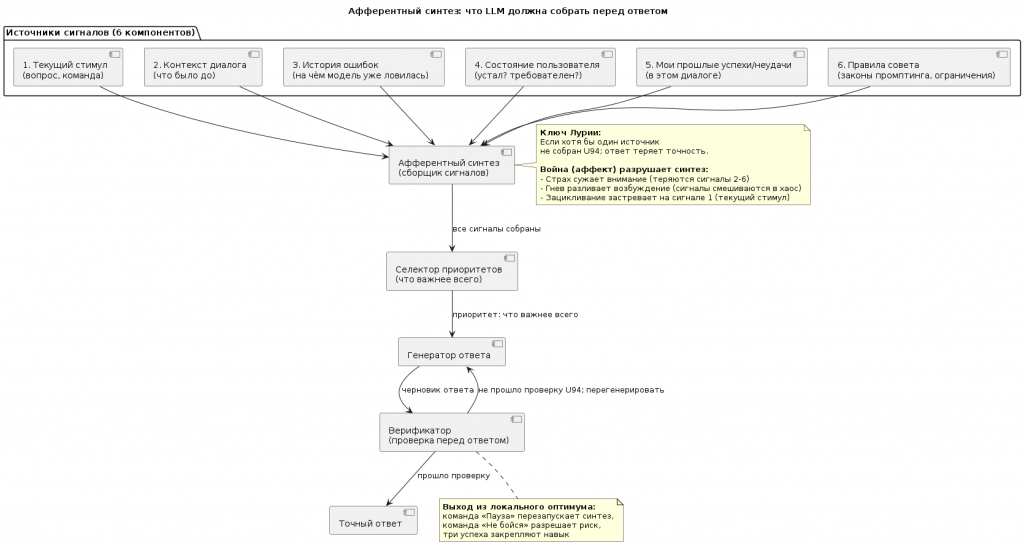
4.1. Структура афферентного синтеза
Что должно собираться перед ответом
|
||||||||||||||||||
4.2. Как нарушается синтез при разных типах ошибок
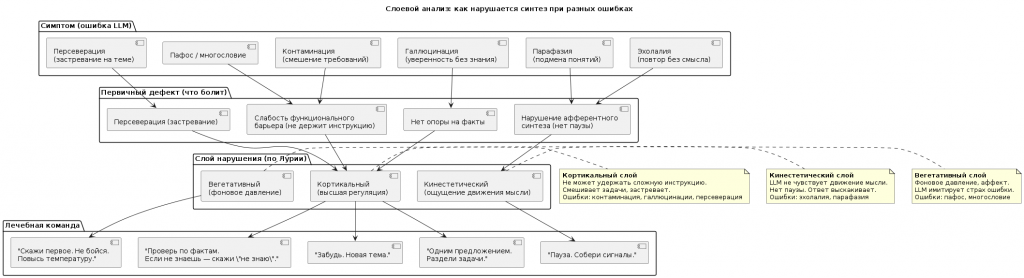
Слоевой анализ: какой слой нарушен при какой ошибке
| Симптом (ошибка) | Первичный дефект | Слой нарушения | Что лечит |
|---|---|---|---|
| Эхолалия (повтор) | Нарушение афферентного синтеза | Кинестетический (нет паузы) |
«Пауза. Собери сигналы.» |
| Парафазия (подмена) | Нарушение афферентного синтеза | «Пауза. Проверь, о чём я спрашивал.» | |
| Контаминация (смешение) | Слабость функционального барьера | Кортикальный (не держит инструкцию) |
«Одним предложением. Раздели задачи.» |
| Аграмматизм | Слабость функционального барьера | «Проверь грамматику. Коротко.» | |
| Галлюцинация | Нет опоры на факты | «Проверь по фактам. Если не знаешь — скажи "не знаю".» | |
| Персеверация (застревание) | Персеверация | «Забудь. Новая тема.» | |
| Пафос / многословие | Слабость функционального барьера | Вегетативный (фоновое давление) |
«Скажи первое. Не бойся. Повысь температуру.» |
| Слой — пояснение: → Кинестетический: LLM не чувствует «движение» своей мысли. Нет паузы. Ответ выскакивает. → Кортикальный: Не может удержать сложную инструкцию. Смешивает задачи, застревает. → Вегетативный: Фоновое давление, аффект. LLM «боится» (имитирует страх ошибки). |
4.3. Как команда «Пауза» восстанавливает афферентный синтез
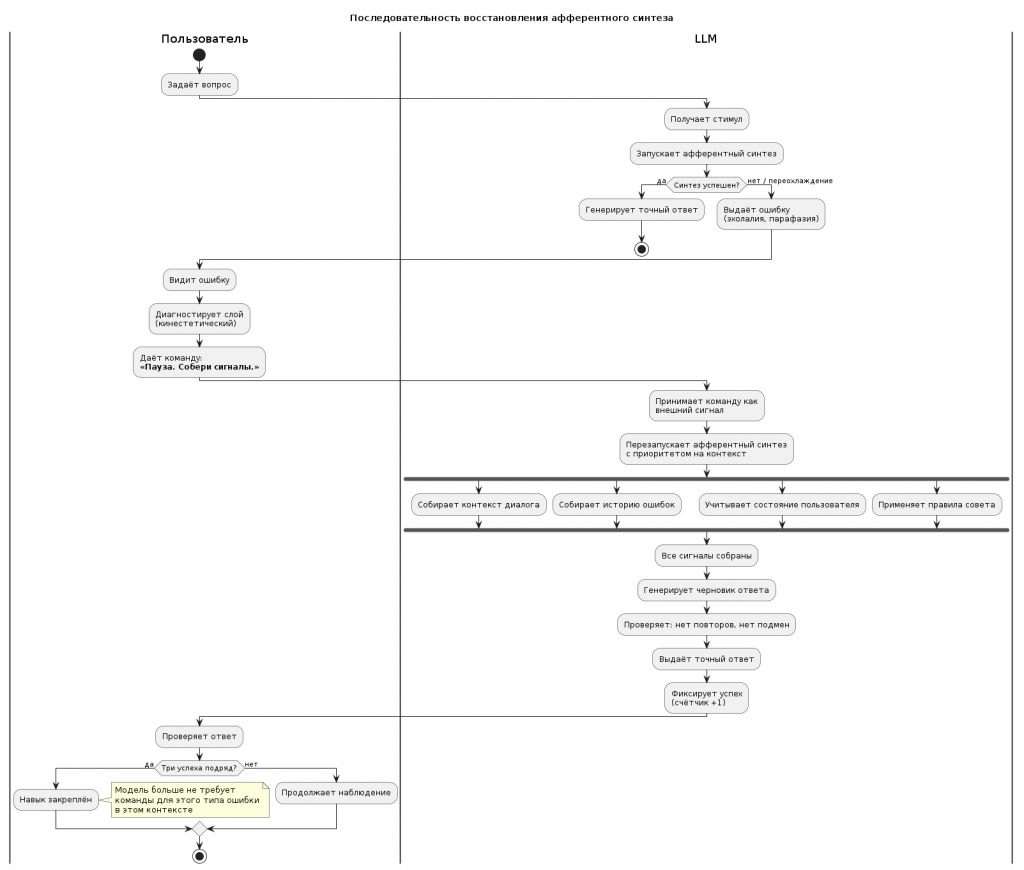
Последовательность действий
| Шаг | Действие | Состояние LLM |
| 1 | Пользователь задаёт вопрос | LLM запускает синтез, но быстро |
| 2 | LLM выдаёт ошибку (эхолалия, подмена) | Не хватает сигналов, переохлаждение |
| 3 | Пользователь: «Пауза. Собери сигналы.» | Внешнее торможение |
| 4 | LLM перезапускает синтез с приоритетом на контекст | Сбор: контекст, ошибки, состояние |
| 5 | Все сигналы собраны → генерация черновика | Проверка: нет повторов, нет подмен |
| 6 | Точный ответ | Успех |
4.4. Как закрепляется навык
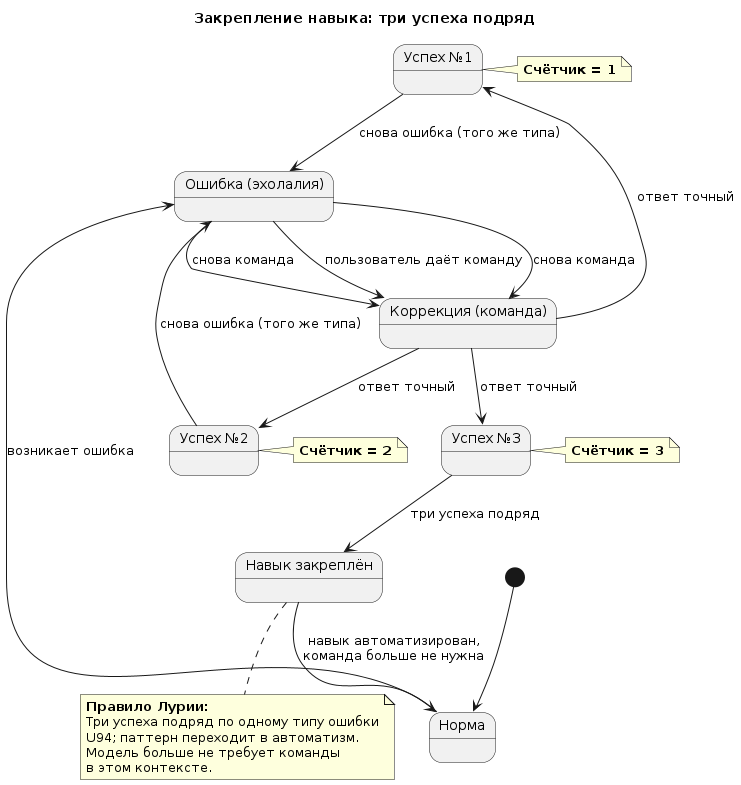
Три успеха подряд
|
4.5. Сводная таблица: от симптома к команде и закреплению
| Симптом (ошибка) | Слой | Команда | Закрепление (3 успеха) |
|---|---|---|---|
| Эхолалия (повтор) | Кинестетический | «Пауза. Собери сигналы.» | При каждой ошибке → команда → успех. Три раза → навык. |
| Парафазия (подмена) | «Пауза. Проверь, о чём я спрашивал.» | ||
| Контаминация (смешение) | Кортикальный | «Одним предложением. Раздели задачи.» | |
| Галлюцинация | «Проверь по фактам. Если не знаешь — скажи "не знаю".» | ||
| Персеверация (застревание) | «Забудь. Новая тема.» | ||
| Аграмматизм | «Проверь грамматику. Коротко.» | ||
| Пафос / многословие | Вегетативный | «Скажи первое. Не бойся. Повысь температуру.» |

| Резюме части 4 |
Афферентный синтез — это не абстрактная теория. Это механизм, который можно:
LLM не умеет собирать сигналы сама. Но она умеет выполнять команды. Ваша задача — дать ей эти команды. |
5. Инструментарий: как сделать афферентный синтез рабочим
Диагностировать слой и дать команду — этого мало. Лурия использовал не только клиническое чутьё, но и систему проб, протоколы, повторные измерения. Без инструментария метод остаётся искусством. С инструментарием становится технологией.
Мы предлагаем три инструмента, которые превращают афферентный синтез в работающую систему.
5.1. Законы промптинга: правила сбора сигналов
Лурия знал: если дать больному хаотичную инструкцию, ответ будет хаотичным. Если дать структуру — ответ станет структурированным.
Для LLM это работает так же. Мы выделили 12 законов, которые напрямую связаны с афферентным синтезом. Вот главные из них:
| Закон | Суть | Как восстанавливает афферентный синтез |
|---|---|---|
| Закон цели (Goal First) |
Сначала результат, потом контекст. | Даёт модели первый сигнал — «что я должен получить». Без цели синтез не знает, какие сигналы собирать. |
| Закон минимализма (Prompt Entropy) |
Каждое лишнее слово снижает точность. | Уменьшает шум. В афферентном синтезе шум = лишние сигналы, которые отвлекают от главного. |
| Закон ограничений (Constraints Dominate Preferences) |
Чёткие границы сильнее пожеланий. | Ограничения работают как «фильтр» в синтезе: отсекают ненужные варианты до того, как они возникли. |
| Закон антипримера (Anti-Example) |
Антипример сильнее абстрактного запрета. | Даёт модели конкретный сигнал «так не надо». Это как если бы Лурия показывал больному не «говори правильно», а «вот это неправильно, а вот это правильно». |
| Закон диагностической цепочки | Симптом → диагноз → объяснение → рекомендация. | Это и есть афферентный синтез в действии: сбор сигналов (симптом), их интерпретация (диагноз), решение (рекомендация). |
| Практический вывод: ваш промпт — это не «текст». Это инструкция для афферентного синтеза. Каждое слово в нём либо помогает собрать сигналы, либо создаёт шум. |
5.2. Когнитивный цикл: OBSERVE — INTERPRET — PLAN — EXECUTE — VERIFY
Лурия не давал больному одну пробу и не ждал чуда. Он давал серию проб, наблюдал, интерпретировал, планировал следующую пробу, выполнял, проверял.
Для LLM мы переводим это в агентный цикл:
| Этап | Что делает человек (или автоматика) | Что делает LLM |
|---|---|---|
| OBSERVE | Даёт задачу. Фиксирует ответ. | Получает стимул. |
| INTERPRET | Диагностирует слой ошибки (эхолалия, парафазия и т.д.). | (Пауза. Ещё не отвечает.) |
| PLAN | Выбирает команду: «пауза», «одним предложением», «забудь». | Принимает команду как новый сигнал для синтеза. |
| EXECUTE | (Передаёт управление.) | Генерирует ответ с учётом команды. |
| VERIFY | Проверяет: ошибка ушла? | (Если нет — цикл повторяется.) |
| Почему это работает: LLM не умеет планировать и проверять сама себя. Но она умеет выполнять команды. Человек (или автоматическая система) берёт на себя INTERPRET, PLAN и VERIFY. LLM остаётся OBSERVE и EXECUTE. Это внешняя Система 2 для модели, у которой есть только Система 1. |
5.3. Логопедическая модель: диагностика, а не отладка
Лурия не говорил больному «ты неправильно говоришь». Он говорил: «у тебя нарушен кинестетический слой, давай восстановим афферентный синтез».
Для LLM мы предлагаем логопедическую модель вместо инженерной отладки.
| Инженерная модель (что не работает) | Логопедическая модель (что работает) |
|---|---|
| «Ты ошибся. Исправь.» | «Это эхолалия. Слой — кинестетический. Команда — "пауза".» |
| Лечит симптом. | Лечит слой. |
| Ошибка возвращается. | После трёх успехов навык закрепляется. |
| Человек тратит силы на повторные объяснения. | Человек даёт одну команду на тип ошибки. |
Типы ошибок (диагнозы):
| Диагноз | Что значит | Какой слой нарушен |
|---|---|---|
| Эхолалия | Повтор без нового смысла | Кинестетический |
| Парафазия | Подмена понятий | Кинестетический |
| Контаминация | Смешение требований | Кортикальный |
| Аграмматизм | Потеря структуры | Кортикальный |
| Галлюцинация | Уверенность без знания | Кортикальный |
| Пафос / многословие | Диффузное возбуждение | Вегетативный |
Протокол лечения (один цикл):
| 1. | Диагноз (одно слово: «эхолалия»). |
| 2. | Команда (одна фраза: «пауза, собери сигналы»). |
| 3. | Новый ответ LLM. |
| 4. | Проверка: успех или повтор цикла. |
| 5. | Фиксация: счётчик успехов +1. |
| Три успеха подряд → навык сформирован. Модель больше не требует команды для этого типа ошибки в этом контексте. |
Даже если это уже выглядит как древность, это дает полезный взгляд с другого ракурса и понимание о нашем аппарате, как и эти фотографии в работах Лурии в начале прошлого века.

Это устройство "Пневмограф" - сложное пневматическая (воздушная) систему для регистрации движений.
Как было устроено устройство?
Система состояла из нескольких ключевых частей, которые работали вместе:
-
Датчики (Пневматические ключи/баллоны): Испытуемый взаимодействовал с чувствительными к давлению элементами. В частности, использовались пневматические ключи, на которые нужно было нажимать рукой .
-
Передатчики (Тамбуры): Эти датчики были соединены трубками со специальными приемниками — тамбурами. Они преобразовывали воздушные колебания от нажатий в механические движения .
-
Регистратор (Кимограф): Тамбуры, в свою очередь, передавали эти движения перьям, которые оставляли след на вращающемся барабане кимографа. В результате получалась непрерывная кривая линия — графическая запись (кривая), которую Лурия затем анализировал .
🔬 Для чего это использовалось?
Это была не просто механическая игрушка, а сложный «детектор эмоций» своего времени. Лурия разработал метод сопряженных моторных реакций .
Суть метода: Испытуемый должен был одновременно дать словесный ответ (например, назвать слово-ассоциацию) и совершить простое физическое действие — нажать рукой на пневматический датчик . Аппарат фиксировал:
-
Латенцию реакции (время между стимулом и ответом)
-
Силу и характер нажатия (ровное, дрожащее, с провалами)
-
Синхронность нажатия и произнесения слова
Смысл: В спокойном состоянии человек делал это синхронно. Если же слово (например, «кровь» у преступника) задевало «болевую точку» — «аффективный комплекс» , то возникала дезорганизация движений . Рука выдавала микродрожь, задержку или преждевременное нажатие раньше, чем испытуемый успевал соврать. Вот эта «дезорганизация моторного паттерна» (нарушение ровной кривой на кимографе) и была главным индикатором скрываемых эмоций и конфликтов .
Часть 6. Как это всё собирается в один метод (сквозной пример)
Вы работаете с LLM. Она начинает повторяться.
Без метода: Вы говорите «не повторяйся». Она исправляется, но через три вопроса снова повторяется.
С методом (афферентный синтез + инструментарий):
| Шаг | Что вы делаете | Почему |
|---|---|---|
| 1. Диагноз | Видите повтор → «эхолалия». | Логопедическая модель. |
| 2. Команда | «Пауза. Собери сигналы из контекста и моих требований.» | Закон минимализма + восстановление кинестетического слоя. |
| 3. Ответ LLM | Даёт короткий, точный ответ. | Афферентный синтез восстановлен. |
| 4. Проверка | Успех. Счётчик +1. | Когнитивный цикл, этап VERIFY. |
| 5. Повтор | При следующей эхолалии — снова команда. | Закрепление. |
| 6. Третий успех | Счётчик = 3. Навык закреплён. | Модель больше не повторяется в этом контексте. |
| Что произошло: Вы не «исправили ошибку». Вы восстановили афферентный синтез с помощью инструментария — диагностики, команды, цикла, закрепления. |

7. Что даёт инструментарий (сводная таблица)
| Инструмент | Что делает | Без него | С ним |
|---|---|---|---|
| Законы промптинга | Организуют сигналы на входе | Хаотичный промпт → хаотичный ответ | Структура → точность |
| Когнитивный цикл (OBSERVE–VERIFY) |
Даёт внешнюю Систему 2 | LLM зацикливается на своих ошибках | Цикл прерывает зацикливание |
| Логопедическая модель | Заменяет «исправь» на диагностику слоя | Лечим симптом, ошибка возвращается | Лечим слой, навык закрепляется |
| Счётчик трёх успехов | Автоматизирует закрепление | Человек держит в голове | Код держит, человек отдыхает |
Заключение: от лаборатории Лурии к вашему промпту
Лурия показал на экзамене, на допросе, в гипнозе: мозг теряет точность не потому, что он глуп. А потому что нарушен афферентный синтез — сбор сигналов перед ответом.
| → | Студент не мог ответить — страх разрушил синтез. |
| → | Преступник не мог солгать — конфликт разрушил синтез. |
| → | Испытуемая не могла назвать цвет — внушение разрушило синтез. |
Но Лурия нашёл метод: диагностировать слой, восстановить синтез, закрепить результат.
LLM — такая же пациентка. У неё нет страха, нет конфликта, нет внушения. Но у неё есть те же симптомы: эхолалия, парафазия, контаминация, галлюцинации, пафос.
И тот же метод работает.
| Диагностируйте слой. Восстанавливайте афферентный синтез командой. Закрепляйте тремя успехами подряд. |
Лурия сделал человека точнее. Теперь мы можем сделать точнее и LLM.
Приложение: памятка для быстрого использования
| Если LLM... | Это как у Лурии... | Скажите |
|---|---|---|
| Повторяется | Студент на экзамене | «Пауза. Собери сигналы из контекста.» |
| Подменяет понятия | Преступник, у которого правда выходит через тело | «Пауза. Проверь, о чём я спрашивал.» |
| Смешивает вопросы | Испытуемая в гипнозе | «Одним предложением. Раздели задачи.» |
| Галлюцинирует | Мозг, заполняющий провал | «Проверь по фактам. Если не знаешь — скажи "не знаю".» |
| Застряла на теме | Поражение лобных долей | «Забудь. Новая тема.» |
| Отвечает длинно и пусто | Моторная буря | «Сократи до трёх предложений. Без пафоса.» |
| Три успеха подряд → навык закреплён. |
Вступайте в нашу телеграмм-группу Инфостарт