Хочу рассказать про довольно нетипичное нагрузочное тестирование. Почему оно нетипичное? Когда тестируются несколько баз 1С и в них есть сценарий, который разнесен на эти несколько баз и происходит интеграция, то эта интеграция обычно эмулируется. Пишется какой-то генератор, который имитирует, будто пришли данные. На самом деле они просто порождаются в самой тестовой базе обработкой. Мы решили отказаться от такого подхода и сделать боевые интеграции.
Сначала я расскажу, что это было за нагрузочное тестирование: какие у нас были базы, какие ограничения и нюансы. Затем о том, что привело нас к решению отказаться от эмуляторов интеграции. После этого честно поделюсь проблемами, с которыми мы столкнулись. В конце подведу итоги: что в таком подходе оказалось хорошего, что плохого, и выделю маркеры, по которым можно понять, когда от подхода с эмуляторами интеграции можно отказаться.
Контекст нагрузочного тестирования
Наши нагрузочные тесты проводились у заказчика на двух доработанных базах ERP. Первая используется для работы с оперативными данными. Для удобства будем называть ее опербазой. Вторая используется для работы с финансовыми данными – это финбаза.
Эти базы довольно сильно интегрированы между собой. Многие бизнес-процессы начинаются в одной базе, перетекают в другую, могут там завершиться или даже вернуться обратно в 1С, либо улететь в третью систему.
Цель тестов была довольно простая: нужно было понять, соответствуют ли доработки по проекту внедрения договору SLA. Наши специалисты совместно с заказчиком определили список критических операций, которые необходимо замерить. Заказчик для каждой операции указал время выполнения, которое считает приемлемым.
Все тесты проходили на продуктивном стенде. Запуск продуктива на тот момент еще только планировался, поэтому активность на серверах была недостаточно критичной. Мы работали в окна, когда пользователи системой не пользовались.
Нюансы и ограничения проекта
У нас было целых три нюанса.
Первый – у заказчика был полностью закрытый IT-контур. Нам нельзя было подключаться по RDP, по AnyDesk – вообще никак удаленно подключаться было нельзя. Работали строго в офисе заказчика и только на их компьютерах. Соответственно, если возникают задержки в тестах или что-то мешает работе, командировка может продлиться или может появиться еще одна.
У нас, например, тесты проходили в две итерации. Соответственно, было две командировки.
Второй нюанс – проект был сильно сжат по срокам. На момент нагрузочных тестов параллельно еще шла разработка. Были блоки, по которым не все было доделано. Здесь отлично подходит немного видоизмененная поговорка: «Иди туда, не знаю куда, и протестируй то, не знаю что».
Третий нюанс – очень сжатые сроки подготовки к тестам. С момента, когда мы получили письмо о том, что едем на тесты, до самих тестов было чуть меньше месяца. За это время нужно было определить список ключевых операций, погрузиться в бизнес-процессы, написать и отладить обработки.
В общем, миссия казалась невыполнимой.
Причины отказа от эмуляторов интеграции
Когда мы все это поняли, мы еще и решили выстрелить себе в ногу и отказаться от типового подхода к тестам. Объясню, почему.
Первым и самым важным маркером стало то, что часть данных мы получали из «черного ящика». Это была закрытая система, доступов к которой у нас не было вообще. Мы даже не знали, какие именно данные будут приходить в 1С, какие объекты будут создаваться и как будет выглядеть сам процесс.
Второй момент – как бы странно это ни звучало, результаты тестов получаются ближе к реальности. Причин здесь две.
Во-первых, в закрытой системе, из которой мы получаем данные, они появляются не из воздуха. Это не генератор, который просто создает записи. Эти данные формируют пользователи: они что-то делают в системе, после чего информация приходит в 1С. В таких данных часто скрываются ошибки, которые не проявились в процессе обычной работы базы, но могут выстрелить позже и создать дополнительную нагрузку уже на реальном стенде.
Во-вторых, сами интеграционные системы тоже создают нагрузку. Когда выполняются транзакции, происходит запись данных, используется память, читаются данные для интеграции. Кроме того, сами системы находятся в том же продуктивном контуре и тоже создают дополнительную нагрузку. Все это делает результаты тестирования ближе к реальной эксплуатации.
Третий фактор отказа от эмуляторов интеграции – параллельно продолжалась разработка. Структура объектов метаданных постоянно менялась. Получается, сегодня мы написали генератор, а завтра разработчики что-то поменяли, и этот генератор уже неактуален. Поэтому оказалось проще создавать объекты в первой базе, после чего интеграция сама передаст их во вторую базу. В этом случае все работает корректно, потому что процесс контролируется самой интеграцией, которая всегда остается актуальной.
При этом было бы нечестно говорить, что мы не столкнулись с ошибками. Мы с ними столкнулись.
Из критичных проблем было три:
-
Параллельная разработка, о которой я расскажу подробнее.
-
Ошибка синхронизации сценариев. Если сейчас это звучит непонятно, ниже я подробно объясню, что такое синхронизация и какую именно ошибку мы поймали.
-
Недокументированное поведение Тест-Центра. Это оснастка для проведения нагрузочных тестов на базах 1С.
Проблема параллельной разработки
Первый блок, по которому шла параллельная разработка, – это биллинг. Биллинг – это автоматический расчет стоимости услуг, которые могут предоставляться либо регулярно, либо по более сложным правилам.
Например, у операторов связи, пока вы не превысили лимит в 200 минут, действует одна стоимость. Когда лимит превышен, применяется уже другой тариф. В других сферах логика примерно такая же. Биллинг – это довольно сложный расчетный механизм.
Блок биллинга все еще разрабатывался, когда мы приехали на тестирование. Он был не полностью готов, но тесты проводить все равно нужно. При этом мы даже не знали, какой там будет сценарий.
Здесь мы никак не смогли выкрутиться. В первую итерацию мы провели все тесты, кроме блока биллинга, после чего поехали домой. Затем вернулись на вторую итерацию, когда биллинг уже был доделан, и провели тестирование полностью.
Вторая параллельная разработка шла по блоку интеграции. Во время первой итерации еще дорабатывался менеджер интеграции. Мы приехали и сразу поймали несколько ошибок. Подключиться удаленно нельзя, разработчики, которые занимаются интеграцией, тоже не могут подключиться и посмотреть, что происходит. В их контуре разработки ошибка вообще не воспроизводится. В итоге мы сидели, чесали голову и сами разбирались с проблемой.
Ко второй итерации менеджер интеграции получил обновление, все проблемы были исправлены, и система стала работать стабильно. Но нам пришлось потратить время, чтобы разобраться, как теперь все настраивается, потому что часть механики изменилась.
Ошибка синхронизации сценариев
Следующая проблема была связана с синхронизацией сценариев. Начну с теории – что это вообще такое.
В нагрузочных тестах синхронизация – это передача объектов между виртуальными рабочими местами. Представим базу ERP и самый простой бизнес-процесс. Для меня таким процессом является отработка заказа поставщику. Первый пользователь создает заказ, второй вводит поступление, третий – счет-фактуру и так далее.
Синхронизация – это ситуация, когда одно виртуальное рабочее место создает объект, как-то его меняет, и после завершения работы передает следующему виртуальному рабочему месту.
Во время нагрузочных тестов все это выполняют обработки, поэтому вся ответственность за передачу объектов ложится на разработчиков.
Здесь нужно обеспечить несколько вещей:
-
Чтобы несколько ВРМ не брали одни и те же объекты в работу.
-
ВРМ не должны брать данные раньше или позже, чем это требуется. Например, заказ нужно не только создать, но и несколько раз провести, между этими действиями изменить какие-то реквизиты. Соответственно, другая ВРМ не должна взять такой заказ в работу раньше времени.
-
Тесты проводятся несколько раз, не одним проходом. Нужно обеспечить, чтобы ВРМ не брали в работу данные из предыдущих тестов.
-
Если мы сформировали, например, 10 заказов поставщику, нужно, чтобы в рамках теста были обработаны все 10 и не оставалось никаких висяков.
Достигается это правильной работой тестовых обработок.
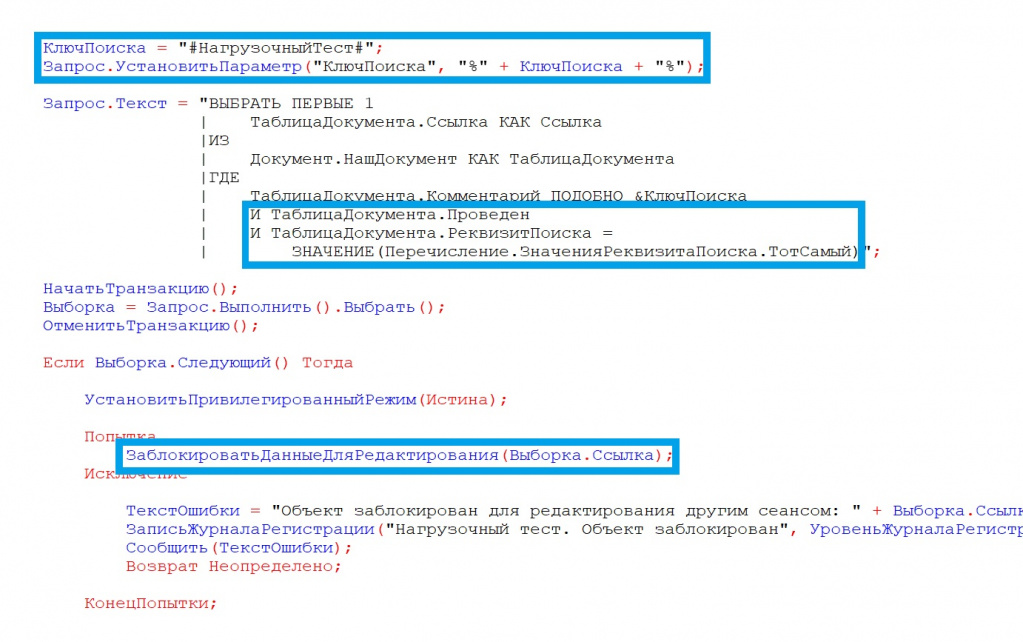
Самое простое решение – использовать служебный комментарий (например, «нагрузочный тест»), чтобы следующие ВРМ могли выборкой находить нужные объекты и брать их в работу.
Также важно определить список реквизитов и их значения, по которым мы понимаем, что объект полностью готов и его можно брать в обработку. На это стоит обратить особое внимание, потому что с этим как раз и была связана наша ошибка.
Далее, чтобы ВРМ не конфликтовали и не брали один и тот же объект, объект блокируется для редактирования – ставится объектная блокировка.

При этом до установки блокировки объект мог измениться, поэтому после того как мы его взяли, нужно проверить, не изменился ли у него комментарий. Если изменился – значит, объект уже кто-то взял, и с ним больше не работаем.
Комментарий можно не очищать, а заменить на другой. Можно также предусмотреть в обработке функционал очистки тестовых данных. По таким комментариям объекты потом легко найти и удалить.
Кроме того, важно максимально подробно вести журнал регистрации. При составлении отчета по нагрузочному тестированию у нас остаются только данные служебного документа «Результаты замеров производительности». Он как раз содержит все записи журнала регистрации. Они могут сильно помочь при подготовке итогового отчета.
И когда работа с объектом завершена, и он исключен из выборки других ВРМ, важно не забыть снять объектную блокировку, чтобы не создавать дополнительных проблем.
Теперь, когда весь этот контекст понятен, расскажу про сценарий, в котором у нас возникла ошибка.
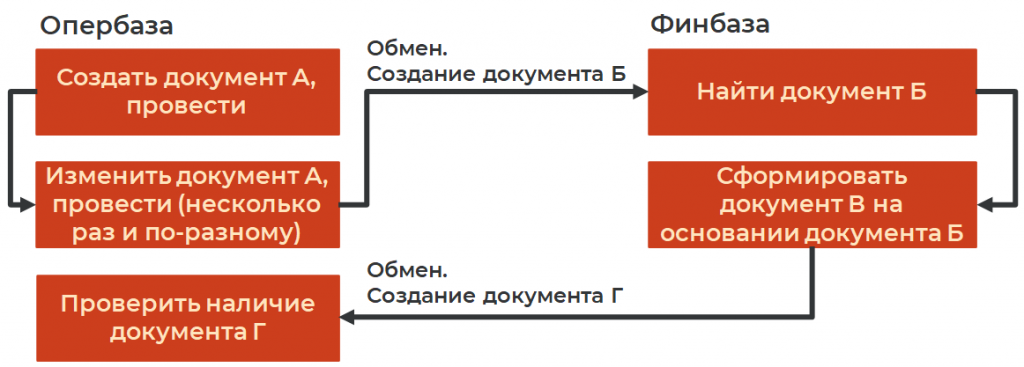
Сценарий выглядел примерно так. В опербазе создавался документ А. Названия условные, поэтому обозначим их буквами. Документ А создавался, затем несколько раз изменялся и проводился. После этого он попадал в финбазу, где на его основании создавался документ Б, после чего на его основании формировался документ В. Далее обменом в опербазе создавался документ Г. Когда опербаза убеждалась, что по документу А создан документ Г, сценарий считался завершенным.
Сценарий выглядел примерно так. Именно «примерно», потому что документ А не только создавался, но и несколько раз изменялся и проводился. Между всеми этими действиями – созданием документа, изменением реквизитов и другими шагами – ставилась пауза от 30 секунд до минуты. Это делалось для того, чтобы можно было визуально контролировать, что происходит с тестовым сценарием, и успеть заметить проблему, если что-то пошло не так. И вот здесь возникла проблема.
Суммарная пауза между действиями оказалась больше, чем периодичность обмена. Документ А в опербазе еще не был полностью заполнен, но уже происходил обмен. Документ попадал в базу Б, она видела его, брала в работу – и падала с ошибкой, потому что документ был заполнен не полностью. Следующий обмен, который должен был обновить данные документа, еще не успевал произойти.
В итоге финбаза брала сырой документ Б, происходила ошибка, и отрабатывало только примерно 45–50% документов. Синхронизация сценариев нарушалась.
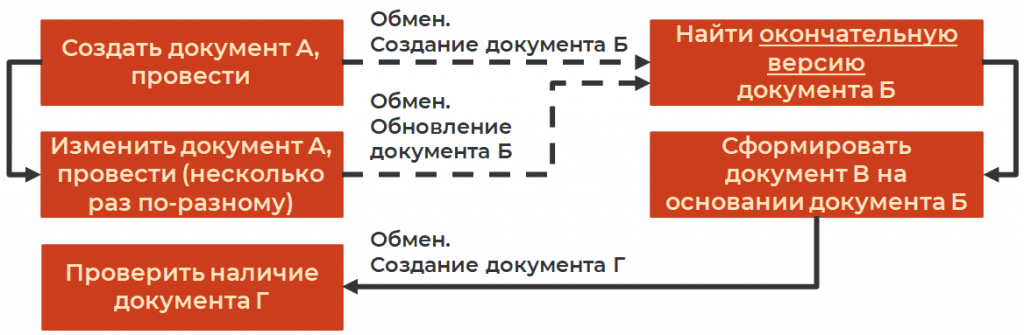
Выше я писал, что важно правильно определить состав реквизитов, по которым мы понимаем, что документ полностью готов к работе. В этом и была наша ошибка. Нужно было всего лишь учесть, что обмен может происходить между нашими паузами, и добавить дополнительную проверку готовности документа. Проверка требовалась совсем небольшая, тогда ошибка просто не возникла бы.
Возникает вопрос: почему это не обнаружилось сразу, когда писалась тестовая обработка?
Потому что во время разработки я не выставил те же паузы, которые использовались у заказчика. Они были достаточно длинные и нужны были для наблюдения за сценарием. Обработку писал я сам, логика была понятна, и о влиянии пауз просто не подумал – на этапе отладки они были минимальны.
Учитесь на моей ошибке. Если вы пишете тестовую обработку и собираетесь потом проводить нагрузочные тесты, после того как все отлажено и работает, обязательно еще раз прогоните сценарий, но уже с теми паузами, которые будут использоваться в боевом тесте. Тогда большинство подобных проблем проявится еще на этапе разработки, когда есть время спокойно все исправить. У нас все это выстрелило у заказчика – мы очень паниковали, долго исправляли, и в итоге поправили ко второй итерации тестов.
Проблема с ключевыми операциями и Тест-Центром
Следующая ошибка уже не такая критичная, но все равно вставила нам палки в колеса. Она связана с ключевыми операциями.
Начнем снова с теории. Ключевые операции – это атомарные действия в базе, во время которых пользователь ждет отклика от системы. Самый простой пример: пользователь в документе нажимает «Провести». Окно 1С зависает, и пользователь ждет, пока операция завершится. Такое действие как раз относится к ключевой операции.
Как понять, что операцию нужно замерять? Фирма 1С дает следующие критерии:
-
Операция выполняется одновременно десятью пользователями и более. В этом случае возможные тормоза на такой операции в будущем могут привести к потерям денег у бизнеса.
-
Операция критична для бизнеса – любая задержка сразу приводит к денежным потерям.
-
Система уже работает, и пользователи начинают жаловаться, что какие-то операции выполняются слишком долго.
Чтобы измерить длительность выполнения ключевых операций, нужно сделать несколько вещей:
-
Составить список ключевых операций.
-
Назначить приоритеты операциям – какие более важные, а какие не очень.
-
Определить целевое время выполнения операции. Обозначим его буквой T. Это время нельзя брать с потолка. Например, можно спросить у заказчика: «За сколько вам нужно закрывать месяц?» Он может ответить: «За пять минут». Но это нереалистичное требование.
В решениях на основе БСП есть функциональность для сбора данных о производительности по Apdex. Apdex – это международный стандарт оценки производительности информационных систем.
Оценка довольно простая. Нужно несколько раз замерить длительность выполнения операции и получить три числа:
-
Сколько раз операция была выполнена. Неважно, уложилась она в целевое время или нет, главное, чтобы завершилась без ошибки.
-
Сколько раз операция выполнилась и уложилась в целевое время T.
-
Сколько раз операция выполнилась, не уложилась в T, но уложилась в удовлетворительное время. Удовлетворительное время лежит в диапазоне от T до 4T.
Эти значения подставляются в формулу, после чего получается показатель от 0 до 1. По умолчанию считается, что у ключевой операции нет проблем с производительностью, если значение Apdex равно 0,85 или выше.
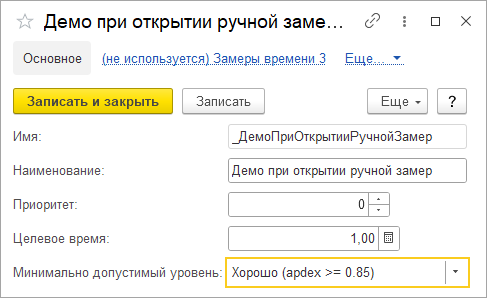
В конфигурациях на БСП ключевые операции хранятся в справочнике. Там задаются приоритеты и целевое время. Такие операции появляются автоматически, когда в коде вызывается замер по имени операции. Например, в демо-базе БСП можно увидеть ключевую операцию _ДемоПриОткрытииРучнойЗамер. Когда вызывается замер, система проверяет, есть ли элемент справочника с таким именем. Если нет – создает его. После этого вручную заполняются параметры: приоритет и целевое время.
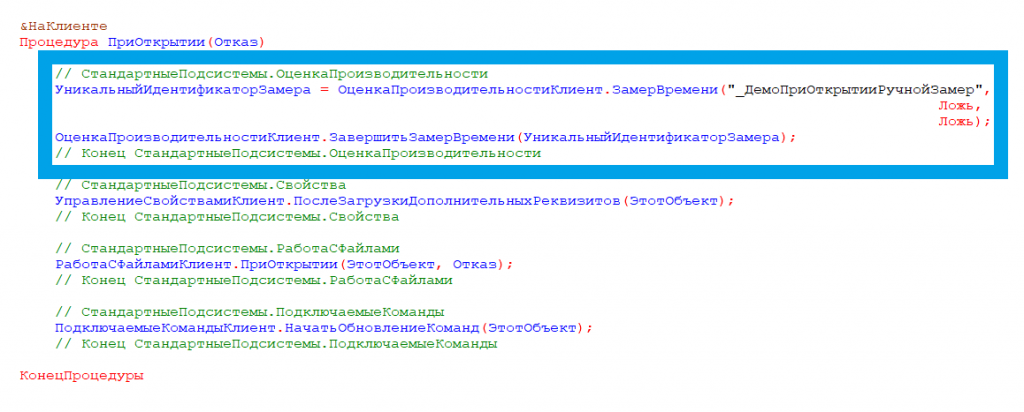
Если вы работали с конфигурациями на БСП, наверняка видели в коде конструкции вроде «ОценкаПроизводительности.ЗамерВремени» и «ЗавершитьЗамерВремени». Эти строки отвечают за измерение длительности ключевой операции. Первая строка запускает замер, вторая фиксирует результат в служебном регистре «Замеры времени».
Посмотреть эти данные можно даже без Тест-Центра. Достаточно открыть сам регистр.

В тестовых обработках для нагрузочных тестов используется тот же механизм. Сначала вызывается замер времени, затем выполняется код, имитирующий действия пользователя – например, открытие формы документа, – после чего замер завершается. И так выполняется несколько раз.

Когда все ключевые операции замерены, Тест-Центр формирует документ с результатами замеров по итерациям теста. В нем есть отчет на СКД: список ключевых операций, параметры для расчета Apdex, само значение Apdex и дополнительные данные, которые могут пригодиться при анализе.
И здесь возникает вопрос: где же была ошибка?

Проблема оказалась в том, что если имя ключевой операции содержит латиницу – например, латинский префикс, – такая операция не попадает в итоговый отчет. При этом в регистре «Замеры времени» данные есть, но в отчете Тест-Центра они не отображаются.
В результате данные можно было достать только косвенно. Формально они есть, но работать с ними неудобно. Приходилось тратить дополнительное время на ручной анализ.
Выводы и рекомендации
Начнем с того, что хорошего в таком подходе:
-
Первое и самое очевидное – экономится время на написание генераторов данных. Мы просто не пишем эти обработки и не следим за их актуальностью.
-
Учитывается реальная нагрузка, которую создает интеграция.
-
На проектах используются разные интеграционные решения. Нагрузочный тест может имитировать экстремальную нагрузку: например, закрытие месяца, расчет себестоимости и одновременную работу десяти тысяч пользователей. В такой ситуации интеграционное решение тоже проходит полноценную проверку на прочность. В нашем случае менеджер интеграции получил обновления и такую проверку выдержал.
Теперь о минусах:
-
Если интеграционное решение еще не до конца отлажено, обязательно что-нибудь сломается. Закон Мерфи никто не отменял: все, что может пойти не так, обязательно пойдет не так. Мы поймали все возможные ошибки прямо у заказчика и исправляли их на месте.
-
Повышенные требования к качеству синхронизации тестовых обработок. Даже небольшая ошибка может стоить очень дорого. В нашем случае она могла привести к задержке тестов и дополнительной командировке.
И, наконец, маркеры, по которым можно понять, что такой подход применять можно:
-
Первый и самый важный – если данные приходят из закрытой системы. В нашем случае это стало решающим фактором. Мы просто не знали, какие данные будут приходить и какие объекты будут создаваться, поэтому генератор писать было бессмысленно.
-
Нужно ли заказчику знать нагрузку от обменов на железо? Если да, такой подход может быть оправдан.
-
Насколько сжаты сроки подготовки и проведения тестов? Если времени мало, но есть опыт написания тестовых обработок, можно рискнуть и сэкономить время.
-
Насколько отлажены и протестированы интеграции? Если все работает стабильно, можно положиться на интеграцию и отказаться от генераторов данных.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.
Вступайте в нашу телеграмм-группу Инфостарт