Продукт оптимизирован для параллельного выполнения большого количества 1С запросов к базам 1С с последующей обработкой и маршрутизацией полученных данных. Поддерживается статусная модель пакетов данных, история обработки и контроль выполнения заданий обмена. (Обработка 1C в базе данных, либо API).
Продукт поставляется бесплатно. Docker-образы доступны в GitHub registry, сборка идет на GitHub Action + GitHub regestry. Решение поддерживает развертывание в Kubernetes, Docker Swarm. Например, в конфигурации Docker Swarm + Portainer можно подключиться к GitHub regestry и достаточно быстро развернуть продукт.
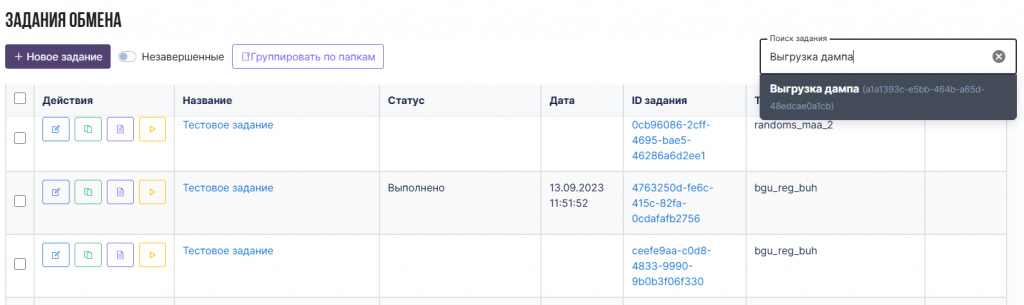
Основной сценарий работы продукта строится вокруг заданий обмена — управляемых наборов данных с настраиваемыми параметрами сбора, обработки и публикации данных. Для каждого задания доступны настройки запросов 1С, параметры обработки, статус выполнения по источникам данных, а также метрики и история обработки.
Каждое задание обмена представляет собой управляемый pipeline сбора и обработки данных с настраиваемыми параметрами выполнения. Для заданий доступны настройки запросов к 1С, режимы сбора данных, параметры хэширования и правила обработки пакетов данных.
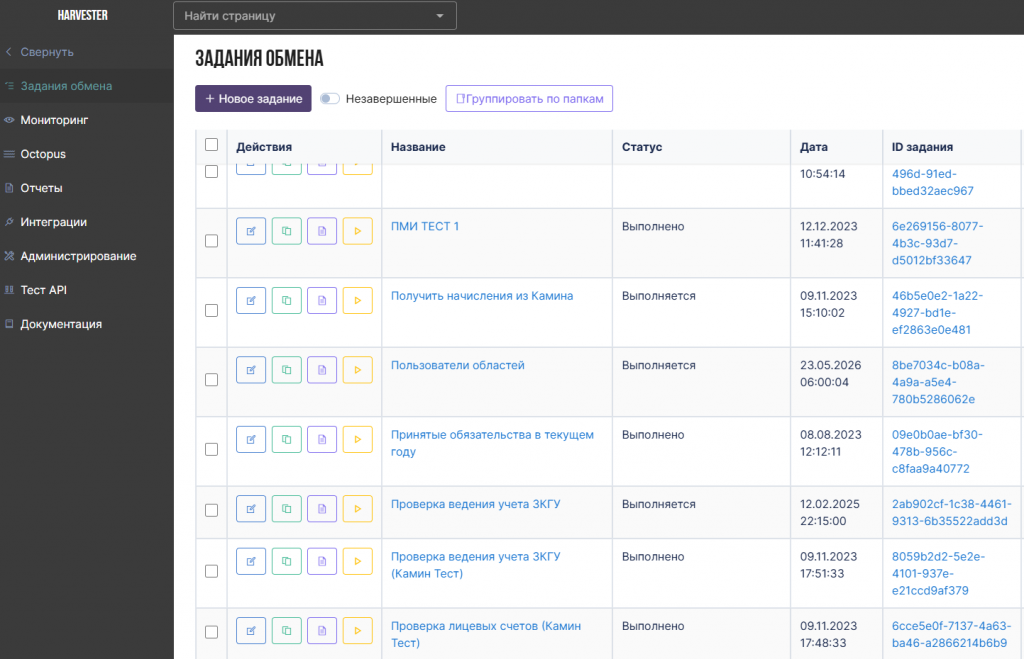
Платформа обеспечивает мониторинг выполнения заданий по всем источникам данных, включая статусы обработки, метрики производительности, историю выполнения и контроль состояния пакетов данных.
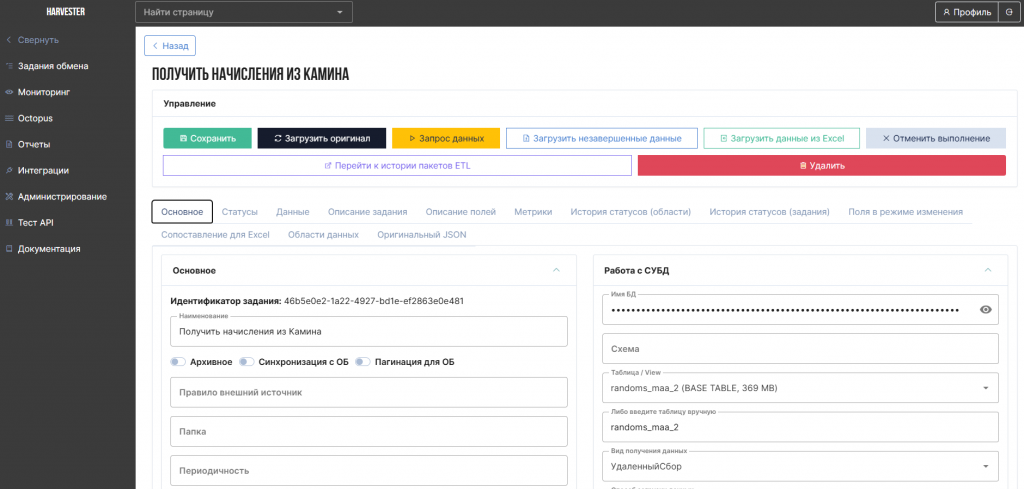
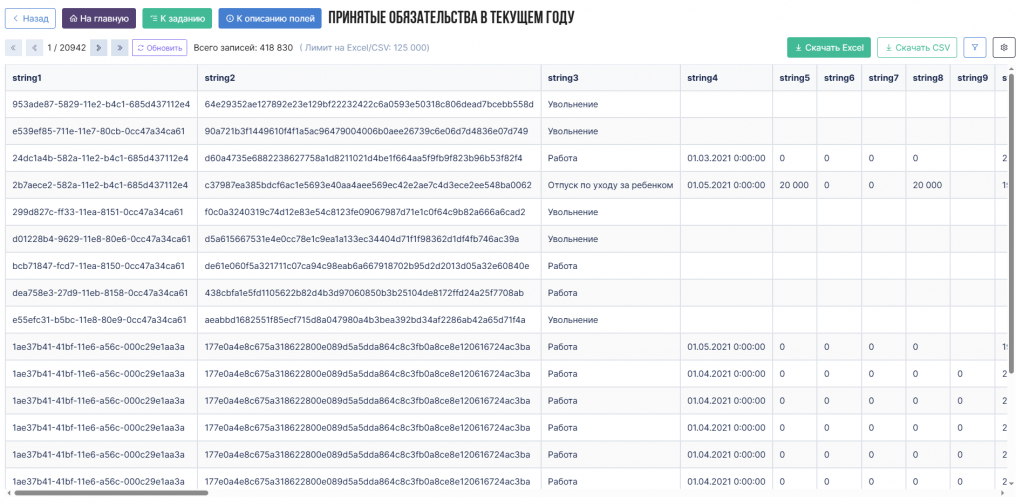
Для аналитических наборов данных реализован встроенный интерфейс просмотра и анализа информации на основе PostgreSQL и materialized view. Пользователи могут выполнять фильтрацию, поиск, группировки и экспортировать результаты в Excel или CSV без прямого доступа к исходным базам данных.
Веб-интерфейс платформы реализован на Vue.js и поддерживает деплой в Kubernetes и Docker Swarm, Интерфейс обеспечивает доступ к отчетам, настройкам обменов и аналитическим данным (+доп.сервисы)
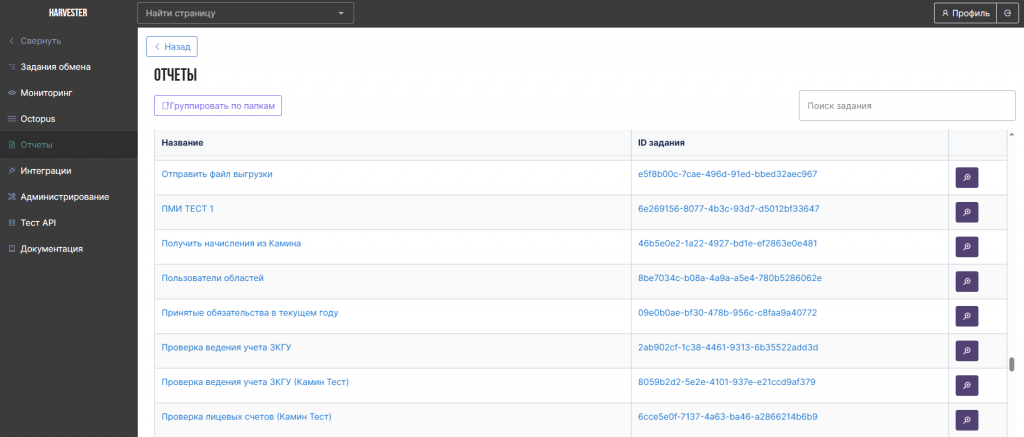
Продукт включает модуль отчетности, построенный на данных заданий обмена, обеспечивая единый слой аналитики поверх распределенных источников данных.
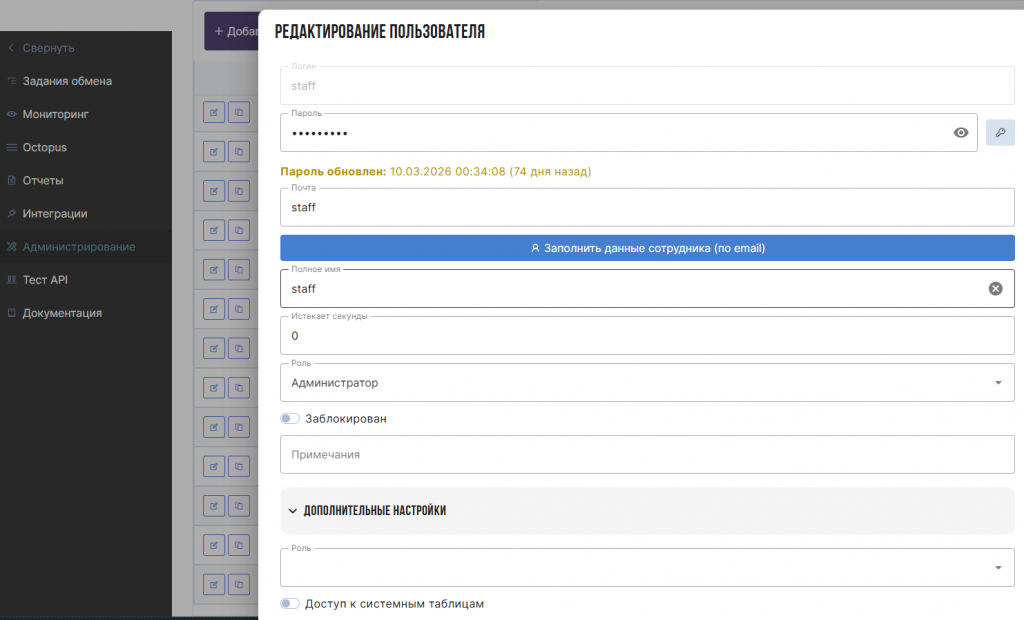
Реализована ролевая модель доступа с управлением пользователями и разграничением прав на уровне отчетов и наборов данных, что позволяет обеспечивать контролируемый доступ к информации в рамках организации.
Продукт предоставляет конструктор интеграций для быстрой публикации и сбора данных с внешних систем. Реализован механизм «Универсального API», обеспечивающий доступ к данным отчетов через единый REST-интерфейс с поддержкой фильтрации, пагинации и параметризации запросов. Пример https://harvester-demo.ru/v2/data/all/9b569ea6-37a5-11ee-911e-005056a2706b?area=4465&total=true
Система поддерживает расширяемую модель парсинга данных под требования заказчика, включая интеграцию с внешними API и последующее сохранение данных через встроенный движок обработки. Также можно подключаться к Kafka для сбора данных.
Платформа включает highload API для приема данных от источников (в основном 1С), где входящие данные представлены результатами запросов и поступают в обработку через централизованный data-processing engine. Далее данные распределяются по заданиям обмена в соответствии с заданной логикой обработки.
В продукте реализован полнотекстовый и контекстный поиск по данным с поддержкой различных поисковых движков, включая Elasticsearch, PostgreSQL (GIN-индекс) и Bleve(github.com/blevesearch/bleve/v2)
Поисковый слой интегрирован с «Универсальным API», что позволяет формировать динамические страницы-отчеты с возможностью поиска, фильтрации и агрегации данных из нескольких наборов данных одновременно. Это обеспечивает единый интерфейс для анализа распределенной информации и построения комбинированных отчетов.
Продукт ориентирован на средний и крупный бизнес и рассчитан на использование в корпоративной инфраструктуре с высокими требованиями к масштабированию и интеграциям.
Продукт продолжение моей активностью по созданию https://github.com/dmitry-msk777/Connector_1C_Enterprise и предыдущими статьями
Установка
Docker образы доступны в моем профиле https://github.com/dmitry-msk777?tab=packages
Компоненты:
- web-front (Веб, админка + сервисы) Vue.js
- api-gateway (бэк для вебки, смотрит наружу, приемщик пакетов с данными)
- etl-engine (обрабатывает пакеты с данными)
- workers (Используется для парсинга данных, а также для системных активностей)
- status-handler (Обрабатывает статусы по заданиям и пакетам данных)
- scheduler (Планировщик)
Также требуется установить PostgreSQL, Redis, RabbitMQ
Переменные окружения:
api-gateway
PORT=8094
ADDRESS_PORT_SERVICE_ETL_CORE=http://etl-core:8099
ADDRESS_PORT_SERVICE_MAIL=http://scheduler:8087
ADDRESS_PORT_gRPC=Localhost:5300
ADDRESS_RABBIT_MQ=amqp://admin:admin@10.44.4.44:5672
CCO_ORGANISATION=true
DB_CONNECTION=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable
DB_CONNECTION_MAIN_ANALYTICS=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable
LOGGER_DEFAULT=defaultStandartLog
LOG_LEVEL=7
QUEUE_Type=RabbitMQREDIS_ADDRESS_PORT=10.44.4.44:6379
SECRET_KEY_JWT=SECRET
TOKEN_BEARER=gghghghghghghghghgh
USE_REDIS=true
SENTRY_URL_DSN=https://36fc12377e434dc892e3242bfe3467f8@sentry.ru
USE_TRACING=False
service-status
DB_CONNECTION=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable
SENTRY_URL_DSN=https://36fc12377e434dc892e3242bfe3467f8@sentry.ru
SECRET_KEY_JWT=SECRET
QUEUE_Type=RabbitMQ
ADDRESS_RABBIT_MQ=amqp://rabbitadmin:admin@10.44.4.44:5672
LOGGER_DEFAULT=defaultStandartLog
sheduler
DB_CONNECTION=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable
DB_CONNECTION_MAIN_ANALYTICS=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable
PORT=8087
SECRET_KEY_JWT=SECRET
SENTRY_URL_DSN=https://36fc12377e434dc892e3242bfe3467f8@sentry.ru
ADRESS_SERVICE_API_GATE=http://api-gateway:8094
LOCALHOST_ADDRESS=http://scheduler:8087
ADDRESS_RABBIT_MQ=amqp://rabbitadmin:admin@10.44.4.44:5672
TOKEN_BEARER=fefefefefefefffefefefef
USE_REDIS=True
CCO_ORGANISATION=true
NSI_EXCHANGE=value_false
REDIS_ADDRESS_PORT=localhost:6379
GRAB_PASSWORD_FROM_MAIL=false
LOGGER_DEFAULT=defaultStandartLog
KAFKA_LIBRARY=kafkago
etl-core
PORT=8099
DB_CONNECTION=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable
USE_LIST_OF_EXCLUDED_JOBS=false
LIST_OF_EXCLUDED_JOBS=566d7547-c47a-11ec-9114-005056a2b5d5
SENTRY_URL_DSN=https://36fc12377e434dc892e3242bfe3467f8@sentry.ru
SECRET_KEY_JWT=SECRET
QUEUE_Type=RabbitMQ
ADDRESS_RABBIT_MQ=amqp://rabbitadmin:admin@10.34.4.46:5672
CCO_ORGANISATION=True
LOGGER_DEFAULT=defaultStandartLog
workers
PORT=8093
DB_CONNECTION=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable
DB_CONNECTION_MAIN_ANALYTICS=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable
SENTRY_URL_DSN=https://36fc12377e434dc892e3242bfe3467f8@sentry.ru
ADDRESS_RABBIT_MQ=amqp://rabbitadmin:admin@10.44.4.44:5672
SECRET_KEY_JWT=SECRET
ADRESS_SERVICE_API_GATE=http://api-gateway:8094
TOKEN_BEARER=fefefefefefefefeff
ADDRESS_PORT_SERVICE_MAIL=http://scheduler:8087
USE_MINIO=false
USE_EXTENDED_AUTHENTICATION=true
USE_REDIS=true
REDIS_ADDRESS_PORT=localhost:6379
LOGGER_DEFAULT=defaultStandartLog
Описание глобальный переменных (Environment variable)
PORT=8093 — Порт для REST, через который можно взаимодействовать с сервисом
DB_CONNECTION=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable — Пусть к системной базе данных продукта
DB_CONNECTION_MAIN_ANALYTICS=postgres://postgres:admin@10.44.4.44/harvester?sslmode=disable — Путь к аналитичекой базе данных продукта
LOGGER_DEFAULT=defaultStandartLog — тип логирования
SENTRY_URL_DSN=https://36fc12377e434dc892e3242bfe3467f8@sentry.ru — строка подключения Sentry (отправка ошибок)
ADDRESS_RABBIT_MQ=amqp://rabbitadmin:admin@10.44.4.44:5672 — адрес RabbitMQ
SECRET_KEY_JWT=SECRET — Ключ для JWT токена
TOKEN_BEARER=fefefefefefefefeff — JWT токена используется при взаимодействии между микросервисами
USE_REDIS=true — Использовать Redis
REDIS_ADDRESS_PORT=localhost:6379 — адрес Redis
Реализация на клиенте
Обработка 1С или прочий скрипт производит авторизацию и отправку данных через API. API находится в сервисе api-gateway ниже описание основного API для взаимодействия с серверной частью.
1. Авторизация для API
Получить токен доступа (POST)
https://localhost/auth/createSession
{
"login": "test_user",
"password": "test_password"
}
Вставлять полученный токен в каждый запрос к API в заголовок TokenBearer
Проверить валидность\годность токена (POST)
https://localhost/v2/auth/validateSession
Удалить токен доступа (POST)
https://localhost/v1/auth/removeSession
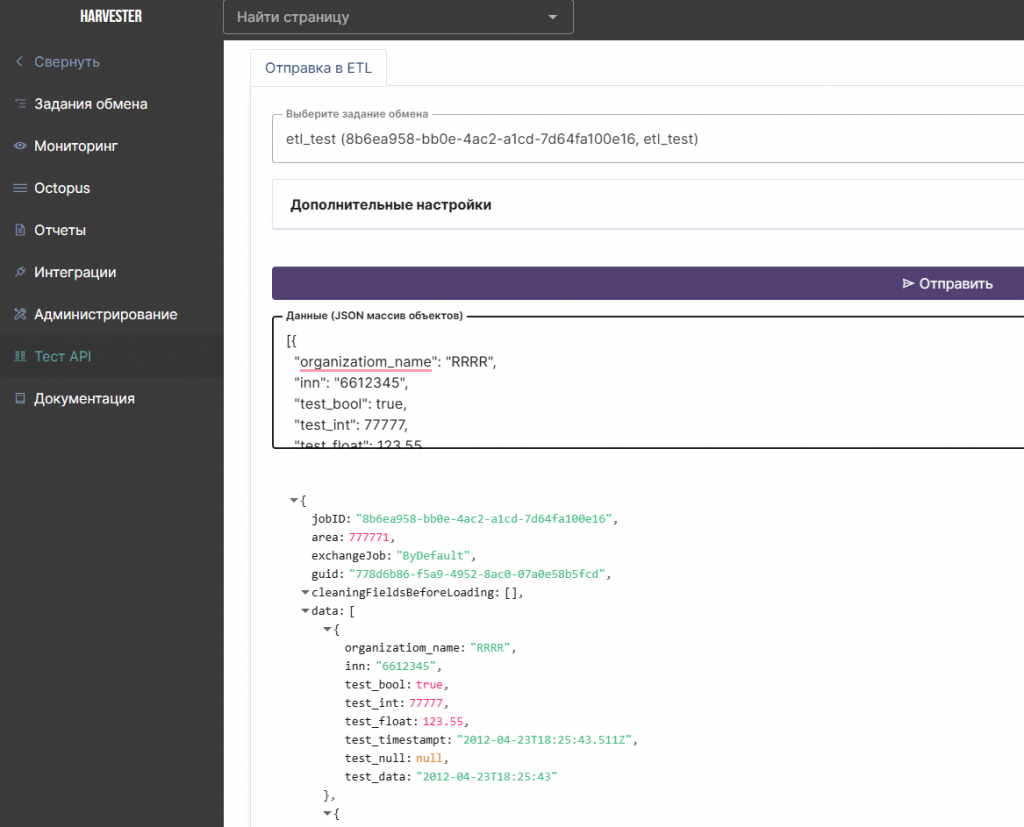
2. Отправка данных в Harvester (обработка данных через ETL процесс)
Отправка осуществляется через REST POST запросом https://localhost/v2/data/sendToETL
Тело запроса(пример):
{
"jobID": "7b916427-1c2b-43a4-ac97-e0ea312a7f41",
"data": [
{
"organizatiom_name": "RRRR",
"inn": "6612345",
"test_bool": true,
"test_int": 77777,
"test_float": 123.55,
"test_timestampt": "2012-04-23T18:25:43.511Z",
"test_null": null,
"test_data": "2012-04-23T18:25:43"
},
{
"organizatiom_name": "SSSSS",
"inn": "7712345",
"test_bool": false,
"test_int": 5555,
"test_float": 666123.55,
"test_timestampt": "2030-04-23T18:25:43.511Z",
"test_null": null,
"test_data": "2030-04-23T18:25:43"
}
]
}
Получения служебной информации по задании осуществляется у администратора (jobID служебное поле)
Более быстрый (для данных от 50 000 строк), но нужно передавать следующий заголовок: JobID https://localhost/v1/data/sendToETLfast
Для умной очистки перед загрузкой данных использовать фильтры добавлением служебного тега
"cleaningFieldsBeforeLoading": [{"Name": "area", "Value": "777"}, {"Name": "inn", "Value": "7712345"}],
Для передачи номера области(area) и номера запроса(exchangeJobID) использовать поля в шапке тела или дополнительно в заголовке для https://localhost/v1/data/sendToETLfast
"area": 777771,
"exchangeJobID": "ByDefault"
Для отслеживания корректного пакета при отправке можно указать его уникальный идентификатор: "guid": "123"
Если поля area и exchangeJobID не заданы, то они принимают следующие значения 777771 и "ByDefault" соответственно
Для отправки сжатых данные (раздел документации 1.12. Сжатие данных при отправке в ETL)
Для использования хэширования (раздел документации 1.13. Хэширование данных при отправке в ETL)
3. Универсальное API
Дает возможность без помощи разработчика сделать API для доступа к данным.
Необходимо подставлять имя своего набора данных для универсального API в url
https://localhost/v2/data/all/planovye_nachisleniya_klass_ruk где planovye_nachisleniya_klass_ruk имя набора данных
Возможно также использовать идентификатор задания обмена например https://localhost/v2/data/all/9b569ea6-37a5-11ee-911e-005056a2706b
Параметры универсального API
area=4465&total=true - отбор по колонке результата, total=true показывать суммарное количество данных в наборе.
https://localhost/v2/data/all/planovye_nachisleniya_klass_ruk?area=4465&total=true
page=1&per_page=20 паджинация
https://localhost/v2/data/all/planovye_nachisleniya_klass_ruk?page=1&per_page=20&total=true
getCountOnFieldForPagination=inn_org возвращает количество записей в разрезе значений в поле. Для паджинации на основании значений в поле результата.
https://localhost/v2/data/all/planovye_nachisleniya_klass_ruk?getCountOnFieldForPagination=inn_org
daysDeep=6&page=1&per_page=10 показывает в зависимости от daysDeep все измененные значения от текущей даты на количество дней в глубину.
https://localhost/v2/data/all/planovye_nachisleniya_klass_ruk?daysDeep=6&page=1&per_page=10
dataTimeDeep=2022-11-04T05:10:58&page=1&per_page=10 показывает все измененные начиная с dataTimeDeep
https://localhost/v2/data/all/oo_3_3_2?dataTimeDeep=2022-11-04T05:10:58&page=1&per_page=100
order=desc - обратный порядок сортировки, для отображения с конца. Для asc отсуствие параметра или order=asc
POST - метод и дополнительные опции в теле запроса.
Пример тела:
{
"filters": [
{
"field": "id",
"operation": "IN",
"value": [
519018,
762093
]
},
{
"field": "created_at",
"operation": "GtOrEq",
"value": "2024-09-01"
}
],
"typeOfFilters": "OR",
"includedFields": ["area", "kolichestvo_stavok"],
"excludedFields": ["id", "created_at", "updated_at", "deleted_at", "job_id", "exchange_job_id"],
"formatOfFileds": "CamelCase"
"orderBy": ["kolichestvo_stavok ASC", "inn DESC"]
}
filters - фильты из параметров для GET нужно помещать тут, фильры более расширенные типы фильтров
"Eq" =
"IN": В списке значений
"Like"
"NotEq" <>
"Lt" <
"LtOrEq" <=
"Gt" >
"GtOrEq" >=
typeOfFilters - Отношения фильтров, по умолчанию AND
includedFields - Включенные поля в вывод
excludedFields - Исключенные поля в вывод
formatOfFileds - Формат вывода, по умолчанию без изменений, опции (CamelCase, PascalCase)
formatOfResponse - excel, xlsx, csv, json(по умолчанию)
customLimitOfTotal - Лимит 50к, excel и csv режим устанавливается вручную этим параметром
orderBy - Сотрировка делается по нужным полям в виде списка "kolichestvo_stavok ASC", "inn DESC"
groupByFields - Поля по которым происходит группировка ("groupByFields": ["employment_type"])
groupByType - Вид группировки, агрегатных функций ("groupByType": "SUM")
groupByfieldsForSum - Поля в которым применяется агрегатные функции ("groupByfieldsForSum": ["count_position"],)
getCountOnFieldForPagination - Получить количество записей в разрезе полей ("getCountOnFieldForPagination ": ["employment_type"])
useRussianFieldsFromDictionary - Использовать заголовки (поля JSON) из словаря на русском языке (Используется для подсистемы Отчеты)
4. Swagger описание
https://localhost/swagger/index.html
5. Хэширование данных при отправке в ETL
Для включения шифрования нужно использовать настройку hashAnswer в true
Настройки устанавливаются в методе v2/system/writeSettingsJob
Хэш нужно поместить в поле hashSum (метод /v2/data/sendToETL)
6. Сжатие данных при отправке в ETL
Для включения сжатие нужно использовать настройку zipAnswer в true
По умолчанию используется алгоритм GZip (RFC 1952) также реализован алгоритм для 1C (указывать значение "zipType": "1C"). Для установки алгоритма использовать настройку ZipType
Настройки устанавливаются в методе v2/system/writeSettingsJob
Сжатые данные нужно поместить в поле dataBase64 в виде BASE64 (метод /v2/data/sendToETL)
7. Телеметрия от 1С клиентов
Отправить телеметрию (POST)
https://localhost/v1/system/telemetryClientInfo
{
"jobID":"7b916427-1c2b-43a4-ac97-e0ea312a7f41",
"remoteBaseID":"ИдентификаторУдаленнойБазы",
"dateTelemetry":"2012-04-23T18:25:43.511Z",
"versionConfig":"ВерсияКонфигурацииМетоданные",
"nameBase":"ИмяБазыМетоданные",
"stringConnection":"СтрокаСоединения",
"platformType":"ТипПлатформы",
"applicationVersion":"ВерсияПриложения",
"clientID":"ИдентификаторКлиента",
"versionOS":"ВерсияОС",
"numberVersionScript":"НомерВерсииОбработки",
"typeTelemetry":"ТипТелеметрии",
"exchangeJobID":"exchangeJobID",
"additionalInformation":"Дополнительные параметры"
}
Отправить через заголовок TelemetryClientInfo в BASE64
ew0KICAgImpvYklEIjoiN2I5MTY0MjctMWMyYi00M2E0LWFjOTctZTBlYTMxMmE3ZjQxIiwNCiAgICJyZW1vdGVCYXNlSUQiOiLQmNC00LXQvdGC0LjRhNC40LrQsNGC0L7RgNCj0LTQsNC70LXQvdC90L7QudCR0LDQt9GLIiwNCiAgICJkYXRlVGVsZW1ldHJ5IjoiMjAxMi0wNC0yM1QxODoyNTo0My41MTFaIiwNCiAgICJ2ZXJzaW9uQ29uZmlnIjoi0JLQtdGA0YHQuNGP0JrQvtC90YTQuNCz0YPRgNCw0YbQuNC40JzQtdGC0L7QtNCw0L3QvdGL0LUiLA0KICAgIm5hbWVCYXNlIjoi0JjQvNGP0JHQsNC30YvQnNC10YLQvtC00LDQvdC90YvQtSIsDQogICAic3RyaW5nQ29ubmVjdGlvbiI6ItCh0YLRgNC+0LrQsNCh0L7QtdC00LjQvdC10L3QuNGPIiwNCiAgICJwbGF0Zm9ybVR5cGUiOiLQotC40L/Qn9C70LDRgtGE0L7RgNC80YsiLA0KICAgImFwcGxpY2F0aW9uVmVyc2lvbiI6ItCS0LXRgNGB0LjRj9Cf0YDQuNC70L7QttC10L3QuNGPIiwNCiAgICJjbGllbnRJRCI6ItCY0LTQtdC90YLQuNGE0LjQutCw0YLQvtGA0JrQu9C40LXQvdGC0LAiLA0KICAgInZlcnNpb25PUyI6ItCS0LXRgNGB0LjRj9Ce0KEiLA0KICAgIm51bWJlclZlcnNpb25TY3JpcHQiOiLQndC+0LzQtdGA0JLQtdGA0YHQuNC40J7QsdGA0LDQsdC+0YLQutC4Ig0KfQ==
8. Методы по работе с служебными данными (обычно для Frontend)
Получить все статусы. (GET)
https://localhsot/v2/system/getJobStatusAll
Получить все незавершенные статусы. (GET)
https://localhost/v2/system/getJobStatusAll?method=unfinished
Получить статусы по конкретному заданию. (GET)
https://localhost/v2/system/getJobStatus/2c7c3258-b971-11ec-9114-005056a2b5d5
Отправить эксель на загрузку (POST) - кнопка "Выгрузить эксель в кипер"
https://localhost/v1/data/upLoadExcel/c030e376-8013-4fd3-825b-613bb54952ed
Примечания: Первая колонка всегда должна быть area. Заголовка первой строкой. Название листа строго TDSheet. Маппинг колонок должен быть прописан в задании
Получить описания полей таблицы по заданию (GET)
https://localhost /v1/system/getDescription/ffda2bd2-5fea-4437-a340-9add7b125cbb
Получить статусы в разрезе областей (GET)
https://localhost/v1/system/getJobStatusGroup/748264c1-2a9b-11ed-9115-005056a2b5d5
Получить состояние по области по Заданию обмена (GET)
https://localhost/v1/system/getExchangeJobStatus/ce07326d-097b-4412-bff9-b0be5a4869a8/777771/ByDefault
Получить все состояние областей по Заданию обмена (GET)
https://localhsot/v1/system/getExchangeJobStatusAll/ce07326d-097b-4412-bff9-b0be5a4869a8
Получить все состояния по области по Заданию обмена (GET)
https://localhost/v1/system/getExchangeJobStatusListAll
Вступайте в нашу телеграмм-группу Инфостарт