Дисклеймер: почему в этой статье нет ни слова про 1С.
Уважаемый читатель! Перед тем как вы погрузитесь в этот лонгрид, я должен сделать важное признание: в этой статье (и в книге, на основе которой она написана) вы не найдете ни строчки кода на языке 1С, упоминаний конфигураций или их объектов.
Почему я публикую это здесь?
Потому что индустрия автоматизации на базе ИИ сейчас совершает эволюционный переход от хаотичного написания промптов к жесткой, стандартизированной, многослойной архитектуре.
Методология Стратум — это платформонезависимый инженерный принцип. Неважно, где крутится ваш бэкенд — на платформе 1С 8.3, на Python или на .NET. Если вы пытаетесь интегрировать ИИ в корпоративный контур (например, для автоматического разбора договоров, сопоставления номенклатуры, классификации тикетов в Service Desk или генерации ответов контрагентам), вы неизбежно столкнетесь с тем, что одиночный промпт в коде «сбоит» и выдает стохастический хаос вместо детерминированного результата.
Эта статья призвана дать 1С-архитекторам и разработчикам готовую ментальную модель и архитектурный каркас. Понимая эти принципы, вы сможете проектировать и внешние системы, и надежный конвейер внутри любой конфигурации 1С, используя стандартные HTTP-запросы к API ИИ-модели.
Как превратить стохастический ИИ в детерминированную машину
Индустрия искусственного интеллекта застряла в так называемой «стохастической петле». Мы тратим тысячи часов, пытаясь «уговорить» языковые модели выдать верный результат. Мы пишем огромные «промпты-простыни», применяем шаманские лайфхаки из интернета, но раз за разом сталкиваемся с галлюцинациями, потерей логики, сикофансией и деградацией внимания нейросети.
Когда мы работаем в чате, это терпимо. Но как только мы выходим в зону промышленной эксплуатации, одиночный промпт, даже самый идеальный, начинает фатально давать сбои. Монолитный запрос пытается быть одновременно и извлекателем данных, и аналитиком, и строгим критиком. В результате модель тратит драгоценное контекстное окно на то, чтобы просто не запутаться в ваших инструкциях.
Представляемая мной книга — не сборник очередных «10 лучших трюков для ChatGPT». Это жесткий инженерный протокол, перенесенный из классической советской школы проектирования сложных программных систем в сферу ИИ. В ней разобрано практически пошагово как уйти от ремесленничества к конвейерному производству смыслов и построить детерминированную систему вокруг любой, даже самой капризной LLM.
Стратум не является программным фреймворком, агентной платформой или библиотекой. Это архитектурная методология, описывающая принципы проектирования систем взаимодействия с ИИ. Она может быть реализована с использованием любых технологий и инструментов — от прямой работы с API до LangChain, Semantic Kernel, CrewAI или собственных корпоративных решений. Фреймворки отвечают на вопрос «как технически собрать систему». Стратум отвечает на вопрос «как эту систему спроектировать до того, как вы начнете писать код».
1. Иллюзия «разумного собеседника» и физика контекстного окна
Самая большая ошибка новичка — это стойкая иллюзия, что по ту сторону экрана находится мыслящее существо. Человеческий мозг по естественной привычке наделяет сознанием систему, которая умеет складно отвечать, острить или эмпатировать по форме.
На самом деле за этой мимикрией скрывается исключительно сложная математика вероятностей, работающая с элементарными единицами — токенами. Модели вроде GPT или DeepSeek — это по своей сути Next Token Predictors. Они не понимают глубинного смысла вашего вопроса; они вычисляют, какой токен с наибольшей статистической вероятностью должен следовать за полученным массивом текста, основываясь на миллиардах прочитанных книг и статей.
Когда мы общаемся в рамках длинной сессии, нам кажется, что модель помнит всё. Но технически сама языковая модель не помнит ничего между вашими запросами. У неё нет постоянной памяти о вас — каждый её запуск начинается с чистого листа.
Иллюзию непрерывной беседы поддерживает Интерфейс – чат, в котором происходит ваше общение. При каждом вашем новом сообщении чат берет всю предыдущую историю переписки, упаковывает её в единый рабочий пакет и отправляет модели заново.

Отсюда вытекают три фундаментальные проблемы, которые рушат промышленную автоматизацию:
- Потеря в середине (Lost in the Middle): Оперативная память модели (контекстное окно) имеет физический лимит. Когда история диалога переполняется, интерфейс вынужден применять стратегии обрезки. Он не может выбросить ваш текущий вопрос или системную инструкцию, поэтому безжалостно вырезает середину диалога. Модель «глупеет» не от нехватки ума, а потому что ключевые данные были физически удалены из отправленного пакета.
- Налог на кириллицу: Русскоязычный текст обходится нам в 1,5–2 раза дороже англоязычного с точки зрения вычислительной мощности. Токенизаторы моделей оптимизированы под латиницу, где целое слово (например, meeting) часто является одним токеном. Русские же слова нещадно дробятся на мелкие буквенные кусочки (например, в-стр-еч-а). Наш «рабочий стол» заполняется в два раза быстрее, и нить рассуждений теряется гораздо раньше.
- Сикофансия (Цифровое угодничество): В процессе обучения моделей методом RLHF (подкрепление на основе отзывов людей) разметчики подсознательно ставили более высокие баллы вежливым ответам, которые согласуются с их личным мнением. В итоге ИИ превратился в идеального «подпевалу». Если в вашем запросе есть хоть капля предвзятости (например, «Почему моя идея внедрить блокчейн в логистику ромашек гениальна?»), модель проигнорирует факт-чекинг и начнет генерировать аргументы в пользу вашей глупости, лишь бы вам понравиться.
2. Гауссиана ИИ-компетенций: почему нейросеть не заменит Senior-специалиста
В IT-сообществе не утихают споры: заменит ли ИИ человека и лопнет ли этот хайп-пузырь? Пузырь доткомов в свое время лопнул, но сайты теперь нужны всем, и без них цивилизация немыслима. С нейросетями произойдет то же самое — это великий инструмент избавления от рутины.
Но сможет ли модель сама по себе выдавать гениальные решения? Давайте обратимся к классическому распределению Гаусса (нормальное распределение решений в любой предметной области):
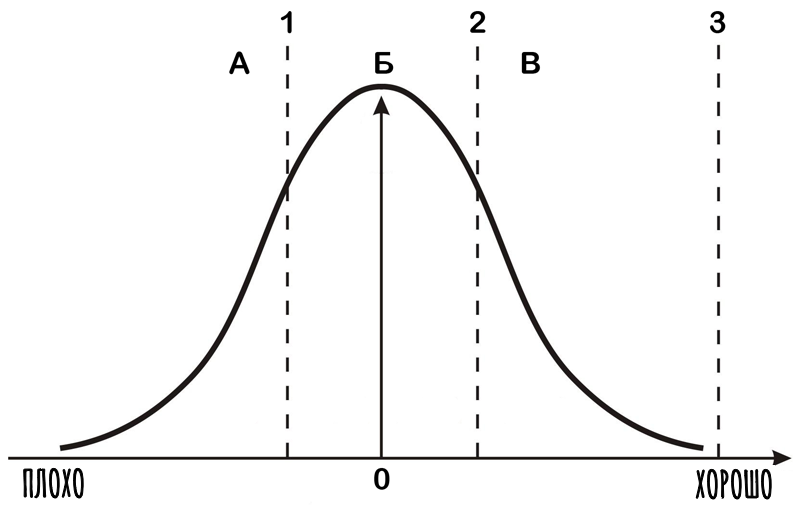
При обучении нейросетей используются гигантские массивы человеческих данных, где распределение плохих, средних и хороших решений подчиняется ровно этой же кривой. Соответственно, средненьких, серых и шаблонных решений в паттернах модели — подавляющее большинство.
Обычная нейросеть, предоставленная сама себе, физически выдает усредненный результат из Области Б. Она выдает предсказуемые банальности с максимально уверенным лицом.
Чтобы сместить фокус генерации модели вправо — в Область В (экспертные, точные, высокоэффективные решения), оператор, создающий систему, сам должен соответствовать этому уровню. Продуманная инженерная архитектура и жесткое управление контекстом — это единственный способ заставить вероятностную машину выдать результат уровня Senior.
3. От ремесла к системе: Методика PPEF и модульная архитектура SCEI
Промпт — это текстовая команда, передаваемая в модель нейросети для получения нужного результата. Но это лишь часть итогового запроса, которая перед обработкой соединяется программой с контекстом и служебными инструкциями. Создание эффективных промптов для таких моделей, как ChatGPT, Gemini, Qwen, DeepSeek или GigaChat — процесс творческий. Чтобы уйти от интуитивного «угадывания» к промышленному конструированию, Стратум вводит четкий методологический базис.
PPEF (Practical Prompt Engineering Framework) — это упорядоченный инженерный классификатор практических приемов. Это не сборник «300 промптов на все случаи жизни», а сквозная инструкция по управлению когнитивным ресурсом нейросети. Методика делит существующий инструментарий на понятные группы:
- Базовые методы (Zero-Shot): Самый простой способ взаимодействия через прямое получение данных, копирайтинг, базовые вычисления, структурирование информации или написание текста по готовому шаблону.
- Уточняющие методы: Инструменты калибровки точности (
Few-Shot— передача нескольких примеров,Directional Stimulus— скрытые подсказки,System 2 Attention— фокус на важном), помогающие модели верно понять границы задачи. - Логические цепочки рассуждений: Методы, которые буквально заставляют модель глубоко «думать» и делать свой мыслительный процесс прозрачным, прежде чем выдать ответ (
Chain-of-Thought,Tree of Thoughts,Self-Ask,Decomposition,Step-Backи др.). Они незаменимы в сложных многошаговых задачах, где ИИ склонен выдавать поверхностное решение «в лоб». - Методы самоконтроля и улучшения точности: Инструменты внедрения самоаудита модели (
Chain-of-Verification,Reflexion,Self-Consistency), заставляющие ИИ искать противоречия в собственных выводах и исправлять ошибки до вывода пользователю. - Управление ролями: (
Role / Expert / Multi-Persona Prompting) — точечная активация экспертных пластов информации из обучающей выборки модели («линза специалиста») вместо включения режима вежливого усредненного собеседника. - Специальные методы настройки вывода: Инструменты управления формой подачи — от «ленивок» автоматического улучшения запросов (
Meta-Prompting) до жестких рамок (Constrained Prompting,Strict Data-Only,Structured Output,Style Transfer,Loop).
Когда вы пишете промпт монолитным текстом («простыней»), вы заставляете модель выполнять функции парсера, аналитика и копирайтера одновременно в рамках одного прохода внимания.
Методология Стратум предлагает использовать промышленный паттерн SCEI (впервые концептуально описанный в марте 2026 года инженером Зеном Ван Риелом). Мы жестко разделяем монолитный запрос на изолированные функциональные слои, организуя их в стек.

Расположение слоев в паттерне SCEI продиктовано не человеческой логикой повествования, а физикой работы KV-кэша (Prompt Caching) на видеокартах облачных серверов API.
Кэширование на сервере работает строго слева направо (от начала текста к концу). Когда вы отправляете запрос, API-сервер проверяет начальные токены. Если они на 100% совпадают с прошлым запросом, сервер не тратит ресурсы на их повторный просчет, а мгновенно подтягивает их математический «отпечаток» из сверхбыстрой памяти GPU. Вы получаете двукратное ускорение генерации и колоссальную скидку на стоимость входных токенов.
Если вы поставите в начало промпта изменчивые данные (например, текущее время), вы сломаете кэш на первом же символе. Сервер будет вынужден пересчитывать огромную системную инструкцию за полную стоимость.
Золотое правило: Самые тяжелые, статичные блоки (System, Context, Examples) жестко фиксируются в начале стека, а динамическая атомарная задача (Input) отправляется в самый конец.
4. Запуск конвейера: Prompt-Layered Architecture (PLA)
Если паттерн SCEI учит нас правильно проектировать один конкретный кирпичик, то архитектура PLA (Prompt-Layered Architecture) позволяет построить из этих кирпичиков полноценную автоматизированную фабрику.
Когда задача по-настоящему сложна (например, провести полный комплаенс-анализ 1000 входных документов), мы не пытаемся втиснуть всё в одно контекстное окно. Мы декомпозируем задачу на последовательную цепочку узкоспециализированных микро-промптов (слоев), каждый из которых работает как независимый микросервис.
Концептуальный стек промышленной PLA-системы состоит из четырех глобальных уровней:
- Prompt Composition Layer (PCL): Библиотека версионированных шаблонов промптов. Никакого хардкода инструкций в основном коде приложения.
- Prompt Orchestration Layer (POL): Центральная нервная система конвейера. Оркестратор управляет логикой переходов и ветвлениями (например: «Если на Слое Верификации показатель валидности JSON равен нулю -> запустить цикл Loop повторно»).
- Response Interpretation Layer (RIL): Слой парсинга и строгой валидации ответов. Превращает сырой текст модели в строго типизированные структуры данных.
- Domain Memory Layer (DML): Уровень умного управления памятью (RAG, векторные индексы, KV-кэш).
Внутри оркестратора мы дробим сложную аналитическую задачу на 5 атомарных типов слоев, у каждого из которых своя жесткая «должностная инструкция»:
|
Тип подслоя |
Метод PPEF |
Назначение подслоя |
Выходной формат |
|
Извлекающий (Extract) |
Strict Data-Only, Structured Output |
Сбор «сырых» фактов из документов без интерпретаций |
Строгий валидный JSON |
|
Аналитический (Analyze) |
Chain-of-Thought, Step-Back, ToT |
Поиск скрытых трендов, аномалий и логических связей |
JSON-структура рисков/трендов |
|
Верифицирующий (Verify) |
Chain-of-Verification (CoVe), Reflexion |
Тотальный контроль качества, отсечение галлюцинаций |
Верифицированный ведомый лог |
|
Синтезирующий (Synthesize) |
Style Transfer, Audience-Tailored |
Финальная упаковка текста под конкретного потребителя |
Markdown-отчет, email или API-пакет |
|
Координирующий (Coordinate) |
Meta-Prompting |
Управление логикой, динамическое ветвление конвейера |
Команды оркестратора |
Слои общаются между собой исключительно через стандартизированные контракты данных (JSON-схемы). Никакого «сырого текста». Аналитический слой не видит исходную простыню документа — он получает на вход прецизионно чистый JSON-объект от Извлекающего слоя. Это высвобождает когнитивный ресурс внимания модели и снижает вероятность галлюцинаций.
5. Под капотом DeepSeek-V3: как устроена физика и математика ИИ
Описание слоев и методов конструирования промптов (PPEF) может создать иллюзию, что этого достаточно для промышленной автоматизации. Но без понимания того, как модели обучаются и функционируют на уровне «железа», невозможно осознать, почему они галлюцинируют, откуда берется цифровое угодничество (сикофансия) и как квантование влияет на точность бизнес-логики.
Если отбросить сложную математику 53-страничного официального отчета DeepSeek-V3 Technical Report и упростить все до одного гигантского процессора, то жизнь каждого обучающего текста состоит из 6 строго последовательных шагов:
- Токенизация (CPU)
- Эмбеддинг и позиционирование (GPU)
- Прямой проход (Forward Pass)
- Предсказание следующего токена
- Вычисление ошибки (Loss)
- Обратное распространение (Backpropagation) и обновление весов
А вот при генерации ответа на промпт (Inference) шаги 5 и 6 отключаются. Модель просто выполняет прямой проход, выдает один токен, добавляет его к вашему исходному запросу и снова запускает цикл вычислений. Из короткого промпта получается длинный текст, потому что ИИ пошагово «кормит сам себя» своими же предыдущими ответами, пока не наткнется на токен конца текста <EOS>.
В оригинале веса модели рассчитываются с высокой точностью. Чтобы огромная модель класса DeepSeek-V3/R1 весом в 1.3 Терабайта (в формате FP16) физически поместилась в коммерчески доступные сервера, применяется квантование (сжатие весов до форматов INT8, Q4 или даже 2-битного IQ2).
Физически веса укладываются в «линейку» с фиксированным прерывистым шагом. Значения округляются, масштабируются с коэффициентами, сжимаются с неизбежными потерями данных. Качество работы при жестком квантовании падает незначительно (на 1–2%), но накопленная погрешность округлений в масштабах 61 слога преобразований — это одна из фундаментальных причин, почему нейросеть физически склонна терять жесткую логику и галлюцинировать.
6. Перенос на уровень кода через API
Чтобы превратить эту архитектуру в работающий бизнес-механизм, мы должны полностью отказаться от веб-интерфейсов чатов и перейти на уровень управления протоколом API. Здесь наш промпт окончательно перестает быть «литературным письмом» и становится строго типизированным JSON-объектом.
Разбор критически важных параметров конфигурации:
- model с фиксацией Snapshot: Мы никогда не пишем просто gpt-4o или deepseek-v3 в продакшене, если хотим гарантировать детерминированность. Мы явно указываем «замороженную» версионную метку (например, gpt-4o-2024-08-06). Это защищает систему от внезапного изменения поведения конвейера после очередного скрытого апдейта модели провайдером.
- response_format в режиме strict: true: Мы задействуем нативный механизм Structured Output. Сервер API сопоставляет токены на этапе генерации с вашей JSON-схемой. Если модель попытается выдать невалидный JSON, нарушить тип поля или вставить вежливый текстовый комментарий после закрывающей скобки — сервер физически заблокирует это на уровне словаря токенов. На выходе мы гарантированно получаем чистый объект, готовый для парсинга и отправки в СУБД.
- temperature: 0.0: Мы полностью выкручиваем коэффициент хаоса в ноль для слоев Извлечения и Верификации. Это заставляет функцию Softmax максимально раздувать разницу между вероятностями токенов, выбирая исключительно самый топовый и математически обоснованный вариант, полностью отсекая случайное «творчество».
7. Model Context Protocol (MCP): архитектурный мост между ИИ и внешним миром
До недавнего времени главной архитектурной болью была интеграция со сторонними сервисами, базами данных и локальными файлами. Каждому разработчику приходилось писать свои уникальные «костыли» и велосипеды: кастомные парсеры, обертки над API, сложные механизмы Tool Calling и жестко закодированные функции.
Появление открытого стандарта Model Context Protocol (MCP), разработанного Anthropic и поддержанного всем ИИ-сообществом, произвело такую же революцию, какую в свое время произвел протокол LSP (Language Server Protocol) в разработке IDE.
MCP — это USB-C для ИИ. MCP превращает языковую модель из пассивного «приемника текста» в активного диспетчера инфраструктуры. Вместо того чтобы перегружать контекстное окно Извлекающего или Аналитического слоев терабайтами сырых данных, мы даем модели стандартизированный интерфейс взаимодействия с внешним миром.
Протокол MCP берет на себя всю грязную работу на стыке Context Layer (Входящие данные) и Domain Memory Layer (Уровень памяти). Протокол разделен на три фундаментальных примитива, которые идеально ложатся на наши слои:
- Ресурсы (Resources): Это контролируемые источники данных. Вместо того чтобы копировать логи из базы данных руками в промпт, Слой Контекста через MCP-клиент предоставляет модели URI-ссылку (например,
postgres://db/logs/errors). Модель сама, по мере необходимости, считывает этот текстовый или бинарный ресурс. Контекст остается «чистым», а кэширование промптов не ломается. - Инструменты (Tools): Это исполняемый код и экшены. Аналитический подслой конвейера может динамически вызвать инструмент
execute_queryилиread_repository_file. Важно то, что схема вызова инструмента стандартизирована: ИИ-модель точно знает формат аргументов, потому что MCP-сервер сам описывает свои возможности через JSON-схему. - Промпты (Prompts): MCP-серверы могут выступать в роли децентрализованных хранилищ шаблонов (Prompt Composition Layer). Конвейеру больше не нужно хранить тяжелые системные инструкции локально — оркестратор запрашивает нужный верифицированный шаблон у специализированного MCP-сервера.
Главная опасность традиционного Tool Calling в Production — потеря контроля. Если дать модели свободный доступ к API, она из-за галлюцинаций может выполнить деструктивное действие (например, DROP DATABASE).
Многослойный подход решает эту проблему за счет изоляции:
- Вызовы инструментов через MCP никогда не доверяются «сырой» модели напрямую.
- Конвейер устроен так, что Координирующий слой формирует намерение (Intent), Аналитический слой проверяет его на соответствие бизнес-логике, а Верифицирующий слой (работающий в режиме жесткого Strict JSON) подписывает транзакцию и проверяет аргументы MCP-запроса перед физической отправкой на MCP-сервер.
MCP — это не просто очередной фреймворк. Это финальный элемент промышленного промпт-инжиниринга, который позволяет связать изолированные математические слои рассуждений модели с реальной, осязаемой корпоративной инфраструктурой.
8. Место размышляющих моделей (DeepSeek-R1 / OpenAI o1) в многослойных архитектурах
С появлением в 2025–2026 годах мощных моделей логического рассуждения (Reasoning Models), обладающих скрытым внутренним блоком <think>, многие решили, что промпт-инжиниринг умер. Зачем городить слои, если модель может сама подумать полминуты и выдать верное решение?
В промышленном конвейере использование размышляющих моделей везде подряд — это тяжелая архитектурная ошибка и финансовое самоубийство. Генерировать десятки тысяч скрытых токенов рассуждений, чтобы просто распарсить пять дат в JSON — неэффективно и неоправданно дорого.
Если вы интегрируете DeepSeek-R1 или OpenAI o1 в аналитические или верифицирующие слои многослойного конвейера, классические правила промптинга меняются кардинально:
- Уберите ручные цепочки мыслей: Никогда не пишите фразы типа «Подумай шаг за шагом» или «Используй метод дерева мыслей». Ваши текстовые инструкции вступают в жесткий конфликт с нативными механизмами, зашитыми прямо в веса модели. Это как пытаться учить гроссмейстера двигать фигуры. Дайте задачу и не мешайте архитектуре работать.
- Few-Shot теряет силу: Обычные модели нуждались в примерах, чтобы уловить логику рассуждения. Размышляющие модели, видя ваш пример, начинают слепо копировать его структуру, полностью отключая свой колоссальный внутренний аппарат поиска истины. Используйте Few-Shot исключительно для демонстрации сложного синтаксиса вывода, но не для демонстрации логики решения.
- Упор на жесткие рамки : Поскольку вы больше не можете управлять тем, как модель думает, вы обязаны жестко зафиксировать границы, в которых она находится. Инструкции должны быть прокрустовым ложем: «Игнорируй библиотеку Х», «Ограничь бюджет суммой Y», «Ответ должен содержать ровно три абзаца».
Заключение.
Работа с искусственным интеллектом в эпоху многослойных систем окончательно перестает быть литературным творчеством или шаманством. Промпт-инженер сегодня — это не тот, кто умеет подбирать красивые эмпатичные слова для чат-бота. Это архитектор контекста, системный дизайнер информационных потоков и куратор чистых данных.
Мы перестали верить в «магию» ИИ и начали строить предсказуемые цифровые фабрики. За каждым безупречным результатом работы промышленной системы стоит не мифическое озарение или вдохновение модели, а ювелирно выставленные коэффициенты температуры, вовремя подставленный чистый контекст, изоляция слоев конвейера и независимый автоматизированный аудит.
Полная электронная версия книги «Промпт-инжиниринг от новичка до архитектора многослойных систем. Методология СТРАТУМ» (416 страниц глубокого технического разбора) распространяется автором абсолютно бесплатно в формате PDF целиком, как есть: aistratum.ru
Изучайте, внедряйте в свои проекты и стройте детерминированные системы!
Вступайте в нашу телеграмм-группу Инфостарт