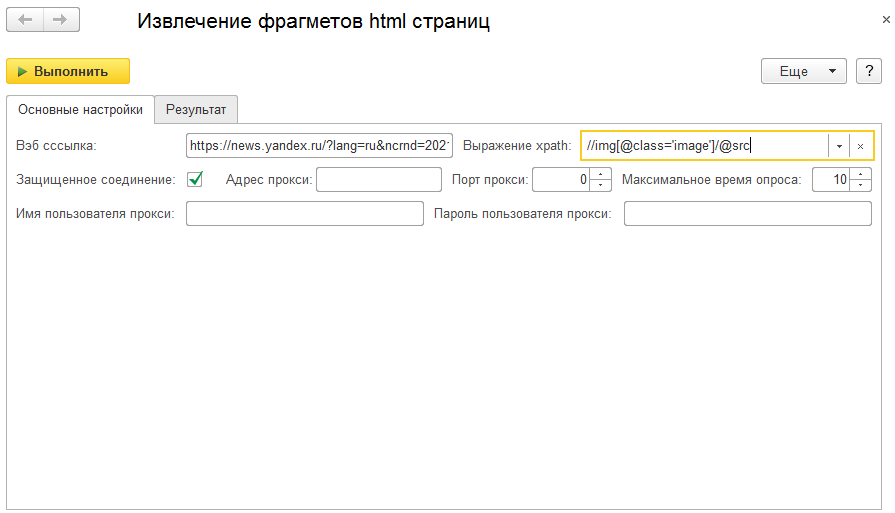
Данная обработка (управляемая форма) позволяет извлекать фрагменты html страницы. Для работы понадобится url целевой страницы и выражение поиска. Если у вас используется проски сервер для выхода в интернет, то есть возможность указать его реквизиты. Вывод результатов поиска происходит в текстовый документ на закладке "результат".
Файлы
ВНИМАНИЕ:
Файлы из Базы знаний - это исходный код разработки.
Это примеры решения задач, шаблоны, заготовки, "строительные материалы" для учетной системы.
Файлы ориентированы на специалистов 1С, которые могут разобраться в коде и оптимизировать программу для запуска в базе данных.
Гарантии работоспособности нет. Возврата нет. Технической поддержки нет.
Вы можете заказать платную доработку или адаптацию этой разработки под вашу конфигурацию на «Бирже
заказов».
0% комиссии — оплата напрямую исполнителю;
Исполнители любого масштаба — от отдельных специалистов до команд под проект;
Прямой обмен контактами между заказчиком и исполнителем;
Безопасная сделка — при необходимости;
Рейтинги, кейсы и прозрачная система откликов.
Данный интрумент возможно будет полезен тем, кто занимается парсингом сайтов. У меня же часто возникала задача извлечь все ссылки из страницы сайта по определенному фильтру. Порядок работы у обработки следующий:
Обработка загружает страницу в сыром (строковом) виде http запросом GET.
Обработка создает на основе строки страницы объект html.
Обработка копирует теги тела html документа и их атрибуты в документ DOM.
С помощью выражения поиска ищутся фрагменты и помещаются в массив.
Элементы массива выводятся в результат (текстовый документ). Если массив найденных элементов пустой, тогда выводится документ dom в виде xml. В дальнейшем xml можно обработать (протестировать) сторонними инструментами.
Тестирование с прокси сервером не проводил, потому как нет такого окружения. Если у вас не отрабатывает xpath запрос, то возможно, что запрос не верен, а также страница подгружается фрагментами к основной, то есть этих фрагментов просто нет. В конце концов это не браузер, а объект hhtp соединение. К обработке я написал небольшую справку, где есть примеры выражений xpath. Обработка самодостаточна и запустится даже в пустой конфигурации. Собствено суть этой разработки в ориганальности идеи переноса тегов документа html в документ dom, в котором и возможна работа с выражениями поиска xpath. Кроме того, ряд процедур и функций я использую как универсальные.
Программный продукт "Управление доставками в 1С" позволяет обмениваться с личным кабинетом Boxberry, СДЭК, Энергия, Почта России, DPD, ПЭК, Grastin, Деловые Линии, КСЕ, Dalli, ЯндексДоставка. Упрощает создание заявок и резервирование заказов прямо в интерфейсе 1С
Интеграционный модуль обмена между конфигурацией Альфа Авто 5 и Альфа Авто 6 и порталом AUTOCRM / LOGICSTARS. Данный модуль универсален. Позволяет работать с несколькими обменами AUTOCRM / LOGICSTAR разных брендов в одной информационной базе в ручном и автоматическом режиме.
Расширение для автоматизации передачи данных между сервисом Vetmanager с 1С: Бухгалтерия 3.0. Решение позволяет загружать документы и справочники из Ветменеджер в 1С:Бухгалтерию, сокращая время на ручной ввод данных и минимизируя ошибки.
Модуль интеграции 1С с OpenCart 2.x, 3x позволяет обмениваться данными между OpenCart (самая популярная бесплатная cms для интернет-магазинов) и 1С:Предприятие 8.
Модуль "Экспортер" — это расширение для 1С, предназначенное для автоматизации процессов выгрузки данных. Оно позволяет эффективно извлекать, преобразовывать и передавать данные из систем 1С в интеграционную платформу Spot2D. Подсистема упрощает настройку, снижает количество ручных операций и обеспечивает удобный контроль данных.
Обмен данными с "Порталом поставщиков" zakupki.mos.ru Москвы и Московской области с целью создания оферт для закупок государственными учреждениями. Модуль устраняет рутину, минимизирует ошибки и помогает выигрывать больше закупок. Работает строго по требованиям 44-ФЗ.
Расширение для 1С:Управление Автотранспортом (ПРОФ) автоматизирует мониторинг транспорта (пробег, расход, координаты, стоянки) и формирование путевых листов. Включает отчеты, фоновую загрузку данных, работает без активации константы мониторинга. Формы — с открытым кодом, общие модули защищены. Доступна демо-версия. Снижает ручной ввод и повышает точность учета.
Блин, я уж подумал, 1сники наконец сделали xpath в html.. Крутая обработка, наверное, но все-таки получается так, что надо пересобрать дерево документа после его загрузки, а это дополнительные временные и вычислительные затраты..



{kind=link}