











{kind=link}
Введение
Временами требуется проанализировать "сырые" логи технологического журнала, чтобы решить проблемы зависания, взаимоблокировок, медленных запросов и много чего еще.
Парсить непосредственно содержание сами логов на предмет нужных событий - утомительное занятие. Для того, чтобы этот процесс как-то автоматизировать, я решил написать максимально универсальный инструмент, который позволяет решить проблему поиска нужных событий в кластере из нескольких рабочих процессов, а то и серверов.
Описание
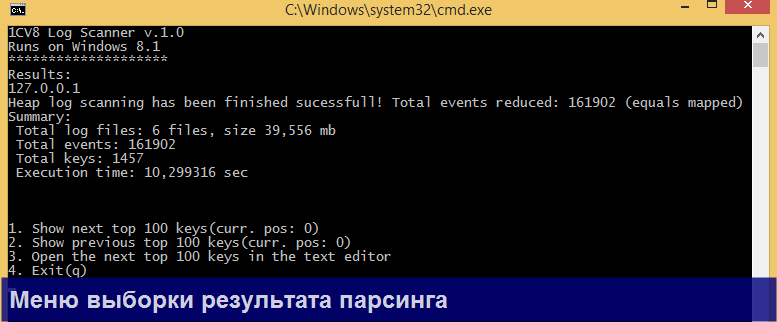
V8 Log Scanner - open-source проект на core java 1.8. Без лишней скромности, это продвинутый и весьма быстрый парсер, нацеленный на анализ логов такого объема, который какой-нибудь notepad++ даже побоится открыть (прим. в notepad++ зашито ограничение в файл размером 500 мб).
По сути V8 Log Scanner – легковесная кроссплатформенное консольная утилита, в которой разбор логов выполняется с помощью sql синтаксиса. Несмотря на свою «консольность», в утилите есть меню, поэтому вводить вручную, а тем более держать в голове команды, вообще нет никакой необходимости. Все действия в утилите осуществляются через ввод цифр с клавиатуры, т.е. чтобы выбрать первый пункт мы должны ввести 1 и нажать Enter
Не могу сказать, что являюсь адептом java, но тем не менее утилита активно использует многопоточность, собственный ByteChannel файловый ридер, java Stream API, регулярные выражения, а также паттерн Map-Reduce. Благодаря всему этому объем потребленной памяти во время парсинга зависит только лишь от размера выходной выборки. Так что, например, парсинг нескольких гигабайтов лога ради 2-3 событий является совсем не затратным по ресурсам компьютера. На следующей картинке наглядно видно, что парсинг 800 мб лога отнимает в среднем 200 мб памяти.
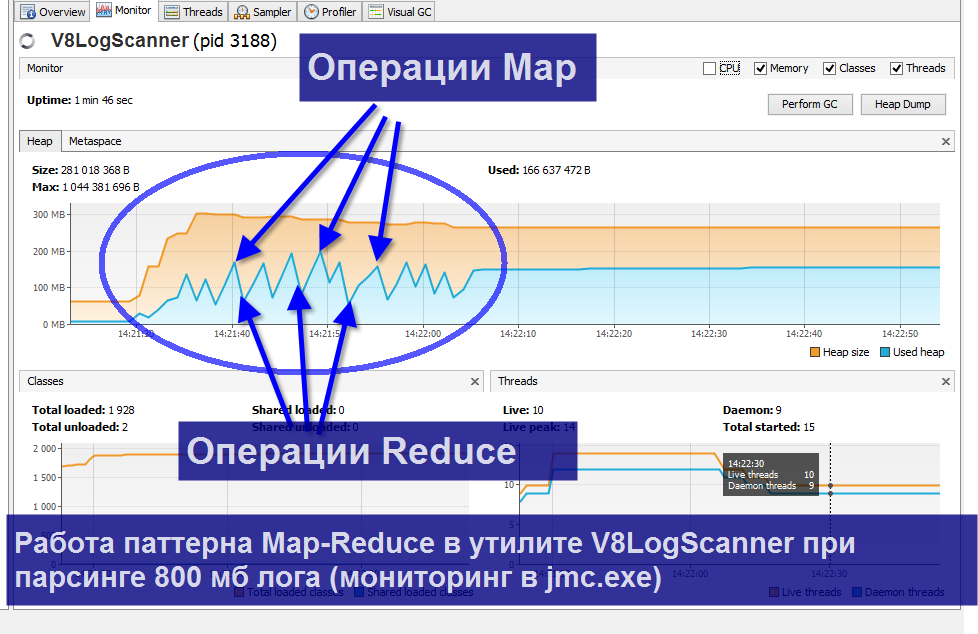
Здесь map-reduce – это фактически оператор СГРУППИРОВАТЬ ПО, только выполяемый ресурсами традиционного ЯП, а не СУБД.
Инструкция
По шагам это выглядит так:
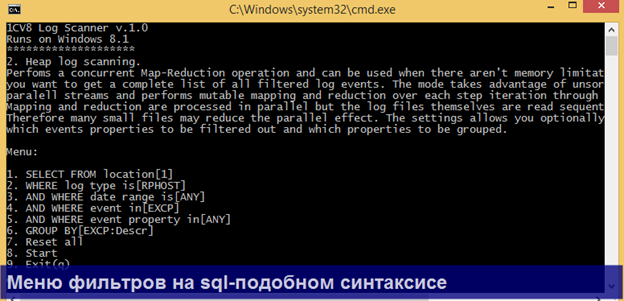
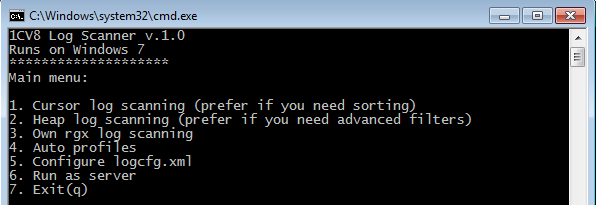
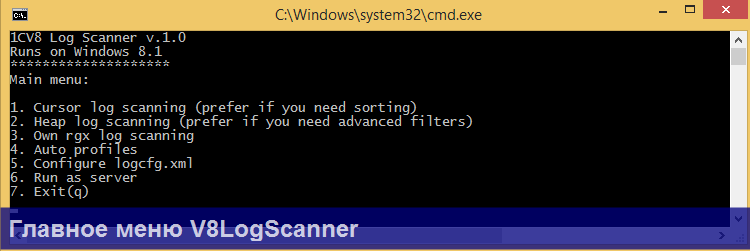
1. В главном меню Вы выбираете один из 3 доступных алгоритмов парсинга.

1) Cursor log scanning – когда требуется сортировка событий по их свойствам и ограничение конечной выборки с помощью оператора ПЕРВЫЕ N для экономного расхода памяти
2) Heap log scannning – когда хотите получить абсолютно все события по заданным фильтрам, а не только ПЕРВЫЕ N
3) Own rgx log scanning – когда хотите ввести собственное регулярное выражение. При этом не нужно заботится о "захвате" отдельных блоков событий регулярным выражением. Утилита это делает сама при помощи следующего выражения:
.+?(?=\\d{2}:\\d{2}\\.\\d{6})
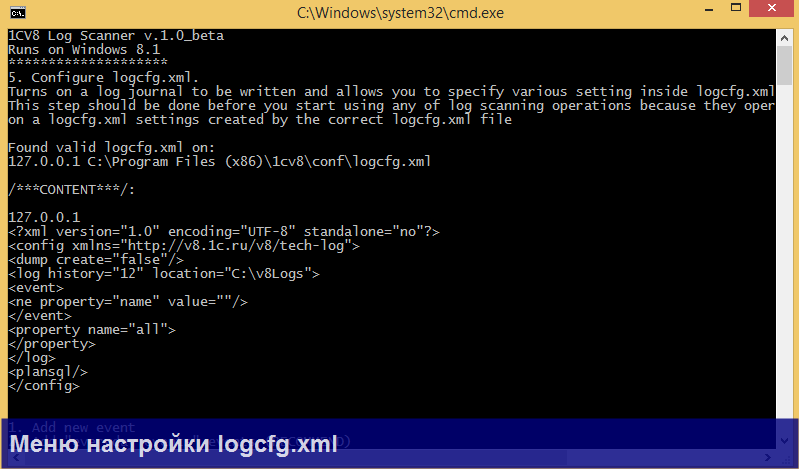
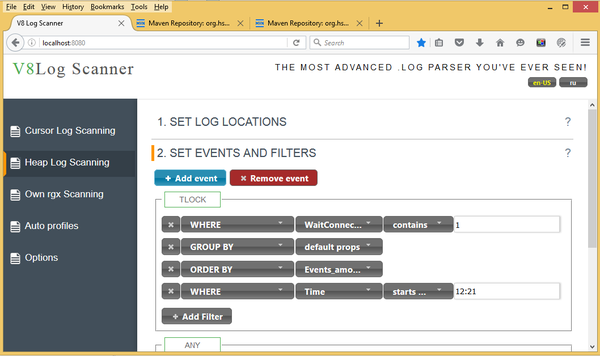
2. Далее заполняете доступные операторы запроса с помощью нового меню. Справа от каждого пункта меню показываются текущие настройки для данного фильтра. При этом автоматически сканирутся все каталоги, исходя из настроек в logcfg.xml.

Не забудьте заполнить меню:
1. Select from location [0]
В нем нужно указать папку, из которой нужно брать логи. Также в меню есть возможность автоматически подтянуть каталоги из файла logcfg.xml.
3. Затем нажимаете Start и получаете на выходе результат в виде выборки.
Если фильтры для парсинга не ведены в предыдущем меню, а каталог логов исчисляется гигабайтами, то будьте готовы к значительному расходу памяти (максимум до 1/4 памяти компьютера), т.к. туда будет помещена вся конечная выборка. Если памяти не хватит для парсинга, утилита упадет без ошибок.
Отсюда совет - задавайте хотя бы минимальные фильтры по виду события (and WHERE Event in [...] ).
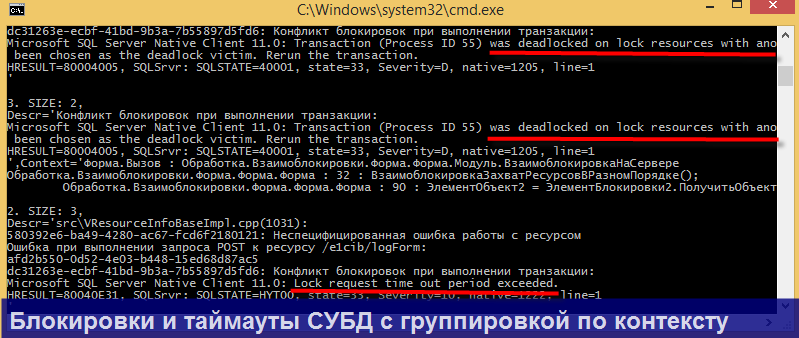
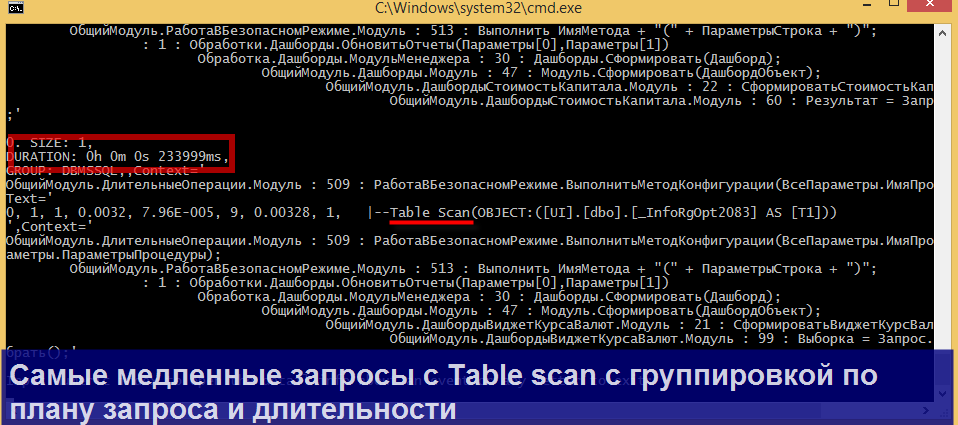
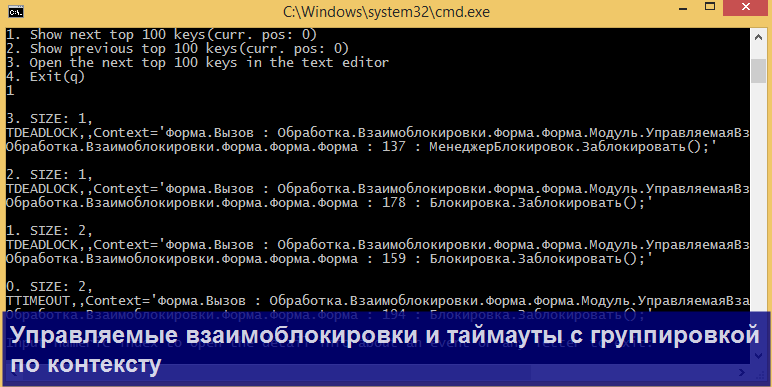
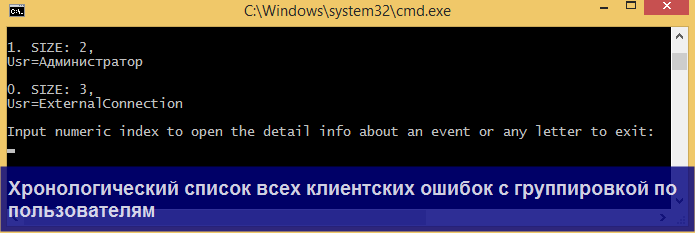
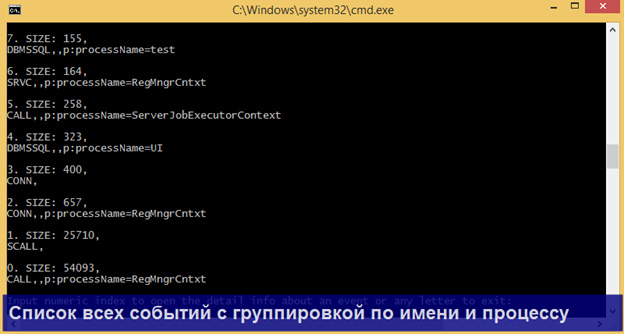
Каждая строка выборки это пара ключ (key) – значение (event), где ключ – поле группировки (из оператора GROUP BY), а значение – массив событий логов. По выборке Вы можете двигаться по ключам либо вперед, либо назад.

Отмечу, что для каждого ключа можно вывести полный список событий, если ввести на клавиатуре цифрой соответствующий индекс ключа.
Примеры
Продемонстрирую несколько конкретных сценариев парсинга, в которых может пригодиться утилита.




Для всех перечисленных сценариев уже прописаны настройки, доступные через меню Main => Auto profiles, так что Вам не придется их настраивать вручную!
Дополнительные возможности
Во-первых, в V8 Log Scanner встроен конструктор файла настройки ТЖ logcfg.xml, доступный через меню Main => configure logcfg.xml. Конструктор позволяет задать настройки и автоматически сформировать файл в нужном каталоге установки платформы.

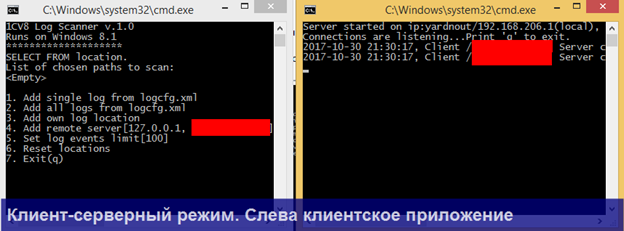
Во-вторых, V8 Log Scanner может работать в клиент-серверном режиме в меню Main => Run as server. Например, вы можете поместить утилиту в режиме запуска сервер в планировщик заданий или установить как сервис windows (для этого поставляются отдельные bat-ники) непосредственно на сервере приложений, на котором собираются логи и работать с утилитой удаленно через локальную сеть.

После запуска скрипта install_service.bat нельзя перемещать каталог с утилитой, иначе служба Windows не будет стартовать.
Заключение
Как уже говорилось, утилита находится в статусе бета-версии, поэтому не все функции могут работать как ожидается. Буду признателен за обратую связь и pull-request-ы на github-e. Исходники и билды доступны в репозитории на github https://github.com/ripreal/V8LogScanner
p.s. всем известные КИП или сервисы Гилева позволяют решают похожие задачи без необходимости копаться в логах. Маленькая и скромная утилита V8 Log Scanner не является их конкурентом. Но она может быть весьма полезна, если упомянутые сервисы не настроены для конкретной базы или нужно найти в логах, разбросанных по всем серверам, какие-то специфичные события (events) из журнала.
Вступайте в нашу телеграмм-группу Инфостарт