После прочтения статьи о недокументированной возможности добавления миллисекунд к дате (для тех, кто еще не знает, вот ссылка), задался вопросом: а что с числами? До какого предела точности мы можем вычислять результат?
Первое, что сразу пришло в голову - это попытаться определить машинное эпсилон, исходя из предположения, что представление числа в 1с это просто число с плавающей точкой, хранящееся как мантисса и показатель степени. В результате проверки обнаружилось, что предела деления как такового не существует.
При попытке вычисления программа просто зависает:
e = 1;
Пока 1 + e/2 > 1 Цикл
e = e/2;
КонецЦикла;
Сообщить(е);
Получается, что мы можем делать вычисления с неограниченной точностью, а точнее пока не закончится оперативная память.
Итак, проверим это. Возьмем произвольное число, например 23 и поделим его на 10 в степени 1000, прибавим к полученному результату 1.
а = 1 + 23*Pow(10, -1000);
Сообщить(а); //1
Возвращается вроде единица без хвостика. Однако, это только кажется. Отнимем от результата 1, а после домножим то, что получилось обратно на 10^1000:
а = 1 + 23*Pow(10, -1000);
Сообщить(а); //1
Сообщить((а-1)*Pow(10, 1000)); //23
Наше число 23 никуда не пропало, оно хранилось в переменной а. Дробная часть, несмотря на ничтожную значимость по сравнению с целой частью, сохранилась.
Очевидно, что серьезная финансовая программа не может работать с такими стандартными типами как float и double и должна использовать тип, который обеспечивает поддержку десятичной арифметики с плавающей запятой (например, в java для этих целей используется тип BigDecimal, в Python тип Decimal). Получается, 1с предоставляет пользователю возможность рассчитывать себестоимость продукции с теоретически бесконечной точностью.
Однако, на вывод данных ограничения все же накладываются. Минимальное число (больше нуля), которое может отобразить программа это 10^(-324). Не спрашивайте почему.
а = Pow(10,-324);
Сообщить(а); //0,000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000001
а = Pow(10,-325);
Сообщить(а); //0
Следовательно, мы можем производить различные математические вычисления с космической точностью. И это без всяких внешних компонент.
Теперь перейдем к теме и попробуем рассчитать число пи со сколь угодно малой погрешностью.
Сначала немного теории...
Один из самых простейших способов вычислить число пи - это использовать известную с начала XVIII века формулу Джона Мэчина:
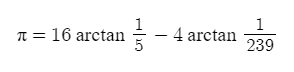
Самое замечательное в ней то, что арктангенс прекрасно раскладывается в ряд Тэйлора:
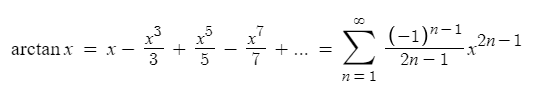
Переводим это в код:
Пи = 0;
Для Сч = 1 По 1000 Цикл
Зн = ?(Сч%2 = 0, -1, 1);
Ч = (Сч*2-1);
Пи = Пи + Зн*(16/(Ч*Pow(5,Ч)) - (4/(Ч*Pow(239,Ч))));
КонецЦикла;
Сообщить(Пи) //3,141592653589793238462643383529999816173450437691564002130.......
И.... Сразу получаем... Всего 27 верных знаков после запятой.
Увеличение счетчика не приводит к точности вычислений.
Вы, конечно же, догадались в чем здесь проблема. Дело в том, что при делении, например, 1 на 3 выводится результат 0,333333333333333333333333333, ограниченный только 27 знаками. Можно ли обойти это ограничение? Оказывается, точность деления зависит от точности числителя дроби и следовательно, если мы добавим к нему очень малую величину, то результат будет вычислен с той же точностью.
Немного подправим код выше:
Пи = 0;
Ош = Pow(10,-2000);
Для Сч = 1 По 1000 Цикл
Зн = ?(Сч%2 = 0, -1, 1);
Ч = (Сч*2-1);
Пи = Пи + Зн*((16+Ош)/(Ч*Pow(5,Ч)) - ((4+Ош)/(Ч*Pow(239,Ч))));
КонецЦикла;
Далее попробуем сравнить точность полученного результата со справочным значением числа пи (первые 4 млн. знаков можно взять отсюда). Для этого будем извлекать по 10 знаков полученного числа в строку:
//Число получено, но 1с отображает только 324 знака после запятой
//Выведем домножением остальные символы
ПиСтрокой = "3.";
Для Сч = 1 По 100 Цикл
ПиСтрокой = ПиСтрокой + Сред(Пи, 3,10);
Пи = Пи*Pow(10,10)%1;
КонецЦикла;
//Сравнение с оригиналом:
ПиОриг = "3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456485669234603486104543266482133936072602491412737245870066063155881748815209209628292540917153643678925903600113305305488204665213841469519415116094330572703657595919530921861173819326117931051185480744623799627495673518857527248912279381830119491298336733624406566430860213949463952247371907021798609437027705392171762931767523846748184676694051320005681271452635608277857713427577896091736371787214684409012249534301465495853710507922796892589235420199561121290219608640344181598136297747713099605187072113499999983729780499510597317328160963185950244594553469083026425223082533446850352619311881710100031378387528865875332083814206171776691473035982534904287554687311595628638823537875937519577818577805321712268066130019278766111959092164201989";
Сообщить("Пи оригинал: " + ПиОриг);
Сообщить("Пи вычислен: " + ПиСтрокой);
Для Сч = 3 По 1002 Цикл
Если Сред(ПиОриг, Сч, 1) <> Сред(ПиСтрокой, Сч, 1) Тогда
Прервать;
КонецЕсли;
КонецЦикла;
Сообщить("Точность вывода знаков после запятой: " + (Сч-3));//Точность вывода знаков после запятой: 1 000
В результате за 1 секунду мы получили 1000 верных знаков. Напомню: в конце XIX века Вильям Шенкс нашёл 707 знаков числа пи, потратив на это 20 лет своей жизни. Однако, в 40-х годах, с помощью первых появившихся ЭВМ, было выяснено, что в своих расчетах он допустил ошибку на 520-м знаке и дальнейшие его вычисления оказались неверными.
Далее попробуем вычислить больше знаков и воспользуемся для этого формулой Бэйли — Боруэйна — Плаффа, выраженной через отношение двух полиномов:
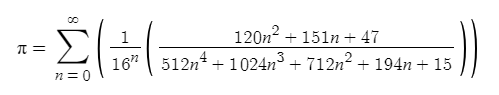
Код:
Пи = 0;
Ош = Pow(10,-10002);
Ст16 = 1;
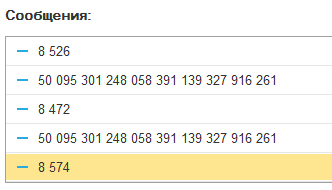
Для Сч = 0 По 8298 Цикл
к1 = Сч;
к2 = к1*к1;
к3 = к2*к1;
к4 = к3*к1;
Числ = (120*к2+151*к1+47)+Ош;
Знам = (512*к4+1024*к3+712*к2+194*к1+15)*Ст16;
Ст16 = Ст16 * 16;
Пи = Пи + Числ/Знам;
КонецЦикла;
После сравнения с оригиналом получаем за 25 секунд 10 000 верных цифр после запятой. Уже что-то.
И напоследок, нельзя не привести способ вычисления пи согласно безумной формуле братьев Чудновских (вдруг кому пригодится), с помощью которой они установили рекорд вычисления (на тот момент): 5 триллионов знаков после запятой!
Но для этого нам понадобится изначально вычислить квадратный корень из числа 10005, входящий в формулу. Для этого воспользуемся итерационной формулой Герона.
а = 10005; //Число из которого извлекам корень
КвКорень =sqrt(а); //его начальное приближение
Ош = Pow(10,-300000);
Для Сч = 1 По 15 Цикл
КвКорень = (КвКорень+(а+Ош)/КвКорень)/2;
КонецЦикла;
И теперь вычислим пи методом Чудновских:
Пи = 13591409;
ak = 1;
k = 1;
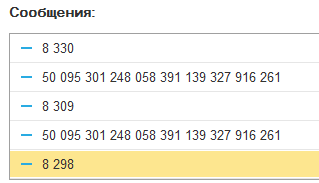
Для Сч = 1 По 20010 Цикл
ak = (ak * -((6*k-5)*(2*k-1)*(6*k-1))+Ош)/(k*k*k*26680*640320*640320);
Пи = Пи + ak*(13591409 + 545140134*k);
k = k + 1;
КонецЦикла;
Пи = (Пи * КвКорень+Ош)/4270934400;
Пи = (1+Ош)/Пи;
В результате 283 789 точных знаков за 3 минуты! «У кого есть охота, пусть идёт дальше», как сказал когда-то Людольф ван Цейлен, вычислив 4 столетия назад 20 точных знаков числа пи после 10 лет упорной работы.
Спасибо, что дочитали до конца.
Вступайте в нашу телеграмм-группу Инфостарт