Добрый день, меня зовут Александр Бобрышов, я представляю компанию «Проф ИТ», мы являемся «Центром внедрения ERP». Помимо 1С, наша компания занимается еще и интеграцией всевозможных продуктов Microsoft (у нас есть Gold статус партнера), и другими интеграциями.
И сейчас я расскажу об одном нашем целевом проекте по консолидации данных из трех десятков предприятий без привлечения программистов на местах.
Исходные данные проекта по консолидации

Заказчиком проекта был большой холдинг, куда входило множество разнородных компаний, таких, как автотранспортные предприятия, управление горнолыжными курортами, управление аэропортом, торговые компании, промышленные компании по производству, общепит и др.
Очевидно, что в каждом из этих случаев ведение бухгалтерии различается. Плюс ко всему, бухгалтера– личности творческие, они, помимо прочего, могут в одной и той же сфере бизнеса вести бухгалтерию по-разному, вносить какие-то свои корректировки так, как им нравится.

Всю эту информацию было необходимо загрузить в основную базу холдинга, которая основана на продукте Oracle E-Business Suite, где структура данных совершенно другая, и подход к ведению бухгалтерии также другой. Соответственно, как все это консолидировать, заказчик не знал.

Третья проблема – это отсутствие программистов на местах. Не во всех филиалах и не во всех компаниях этого холдинга были программисты, которые могли бы что-то на месте сделать.

Соответственно, нам было нужно:
-
Собрать бухгалтерские данные со всех этих предприятий;
-
Далее – необходимо было обеспечить проверку корректности этих бухгалтерских данных по тем правилам, которые мы должны были задать и которые видела для себя головная компания;
-
Передать эти данные в хранилище;
-
Дальше – нам необходимо было организовать удобное сопровождение этого обмена, потому что, помимо прочего, все филиалы территориально достаточно разрознены. Соответственно, управлять этим всем достаточно тяжело, поэтому было принято решение все вести именно в центральной базе.
-
Нужно было по максимуму упростить работу бухгалтера, чтобы порог вхождения был достаточно мал, и ему не приходилось сильно разбираться. Чтобы была одна кнопка, которая называлась «Сделать хорошо».

Я постараюсь рассказать:
-
О том, какую мы архитектуру выбрали для нашего проекта;
-
Как мы наладили выгрузку данных «по одной кнопке», чтобы бухгалтер сильно не думал;
-
Как у нас организовано создание и модификация правил обмена (правил конвертации и выгрузки данных) из конечных баз в центральную.
-
И, соответственно, покажу, как мы организовали мониторинг состояния обмена из единого центра управления.
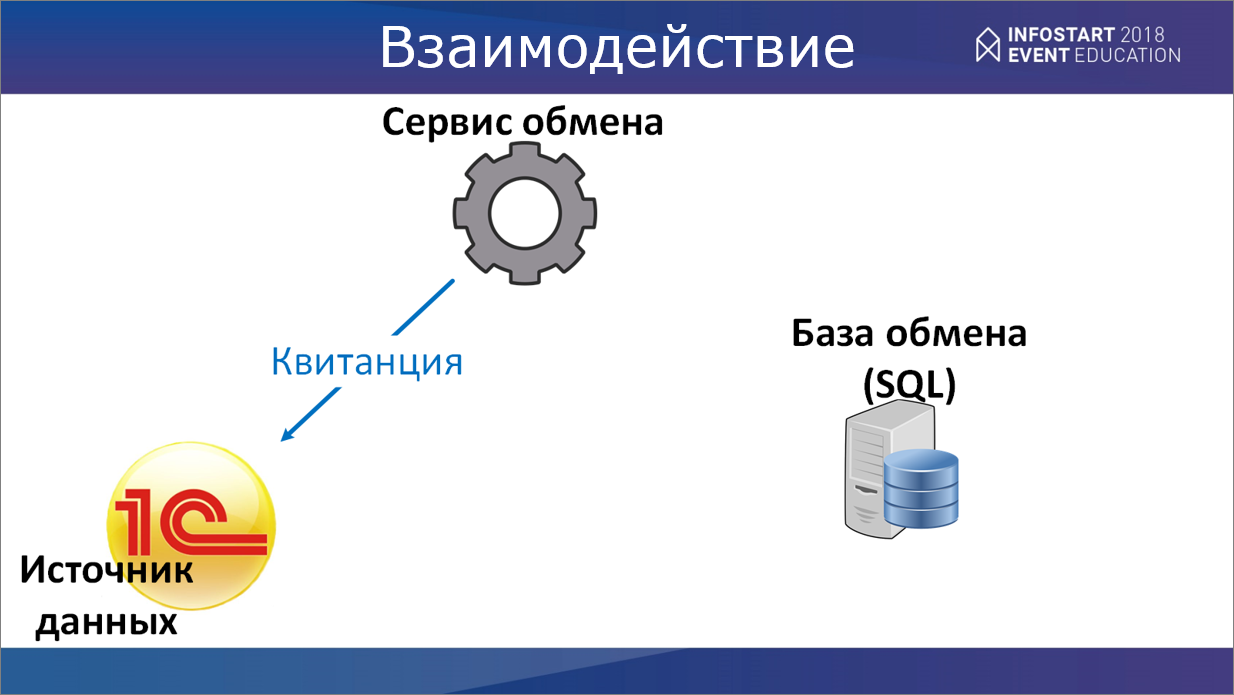
Общая архитектура системы

Общая архитектура системы представлена на слайде:
-
Есть источники данных – это левая часть картинки;
-
И есть центральная база.
Центр представлен:
-
Сервисом обмена, который передает данные в базу обмена на MS SQL (в эту базу стекаются данные из всех филиалов).
-
И есть управляющая сервисная база, написанная «с нуля» на 1С. В этой базе создаются правила обмена, и, по сути, ведется все сервисное обслуживание.
-
Далее эти данные посредством регламентного задания сервисной базы попадают уже непосредственно в хранилище данных – в базу Oracle E-Business Suite.
Это наша архитектура в общих чертах.
Каким образом мы пытались сделать так, чтобы программисты на местах для поддержки обмена данными не привлекались?
Изначально мы говорили о том, что будем хранить обработку для выгрузки в каком-то заранее обговоренном каталоге, откуда бухгалтера будут сами брать и пользоваться ею. Но заказчик поставил нам условие, что никаких дополнительных внешних каталогов быть не должно, для приема и отправки данных будет использоваться только один веб-адрес с открытым портом.
Поэтому мы отказались от использования каталога и сделали так, чтобы наша обработка, которая будет выгружаться на места, «загонялась» в бинарные данные, помещалась непосредственно в таблицу SQL и потом уже при старте конечной системы преобразовывалась обратно в основную обработку для выгрузки.

Расскажу про сам сервис обмена:
-
Так как у нас, по сути, было только одно небольшое окошко – веб-адрес с открытым портом, мы написали свою собственную службу Windows,
-
Эта служба разработана на C#.
-
Она работает именно как HTTP-сервис – позволяет принимать HTTP-запросы и отдает на них какие-то ответы.
-
Все данные передаются в формате XML.
Каким образом построена работа этого сервиса?
У него есть два метода – «exec» и «save».
-
Метод «exec» вызывает хранимую процедуру с базой обмена на SQL.
-
А метод «save» просто помещает передаваемые данные в ту таблицу, которая указана в качестве параметра данного метода.
Это в общих чертах.
База обмена
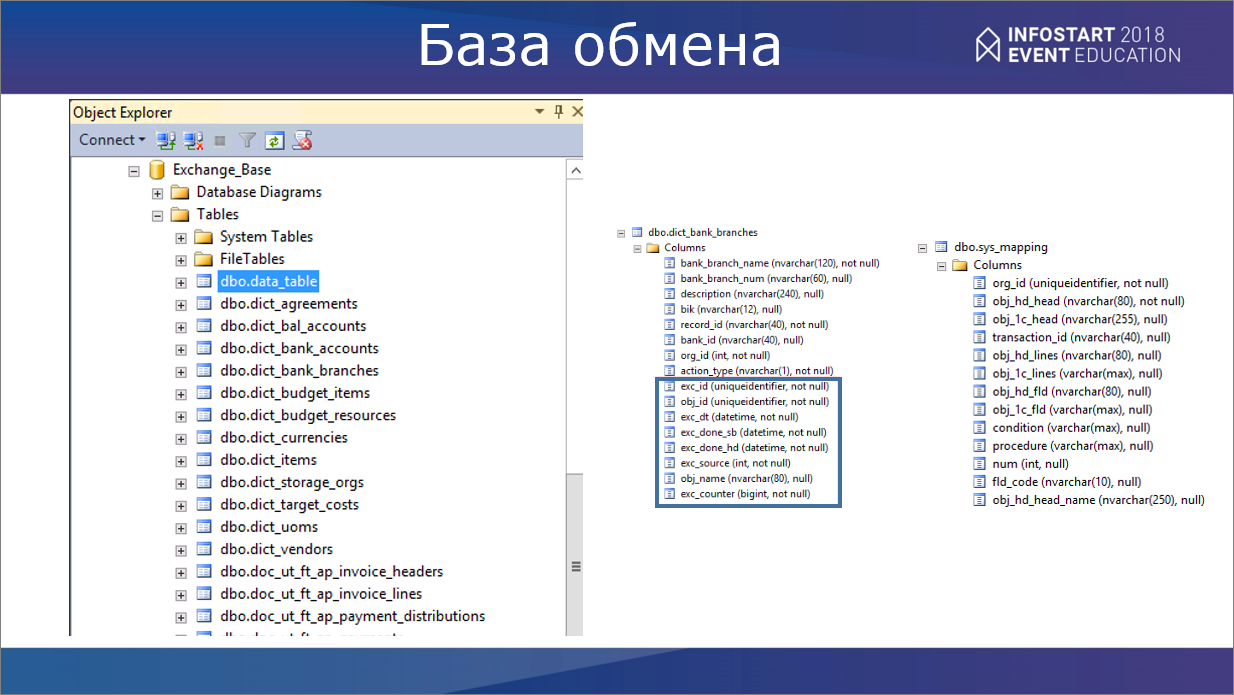
Сама база обмена, как я уже говорил – это SQL-база, которая по структуре таблиц полностью соответствует нашему хранилищу. Все таблицы всех справочников и документов полностью повторяют структуру таблиц хранилища данных на Oracle.

На каждую таблицу данных есть свои сервисные поля. Люди, которые занимаются интеграцией, все это прекрасно знают – это флажки, идентификаторы пакетов и т.д.

Соответственно, в базе обмена у нас есть основная таблица, которая содержит в себе правила сопоставления для объектов хранилища и объектов из 1С, которые будут применяться при выгрузке. Это – святая святых.
Сервисная база

Итак, есть основная таблица SQL с правилами конвертации, про которую я рассказал. А это – обработка в 1С, которая заполняет эту таблицу. Разобью ее на три части, на три сектора.
В первом секторе мы задаем наши правила в разрезе:
-
Объектов хранилища данных;
-
Конфигурации (конфигурационной единицы)
-
И хозяйственной операции. Мы не привязываемся к конкретным документам 1С, которые соответствуют объекту «Дебиторский счет-фактура» в OeBS («Реализация товаров и услуг», «Чек ККМ» и прочие) – мы свели все это в хозяйственную операцию. Это такая надстройка, абстрактная структура. И уже для данной хозяйственной операции мы задаем, какие для нее будут документы.
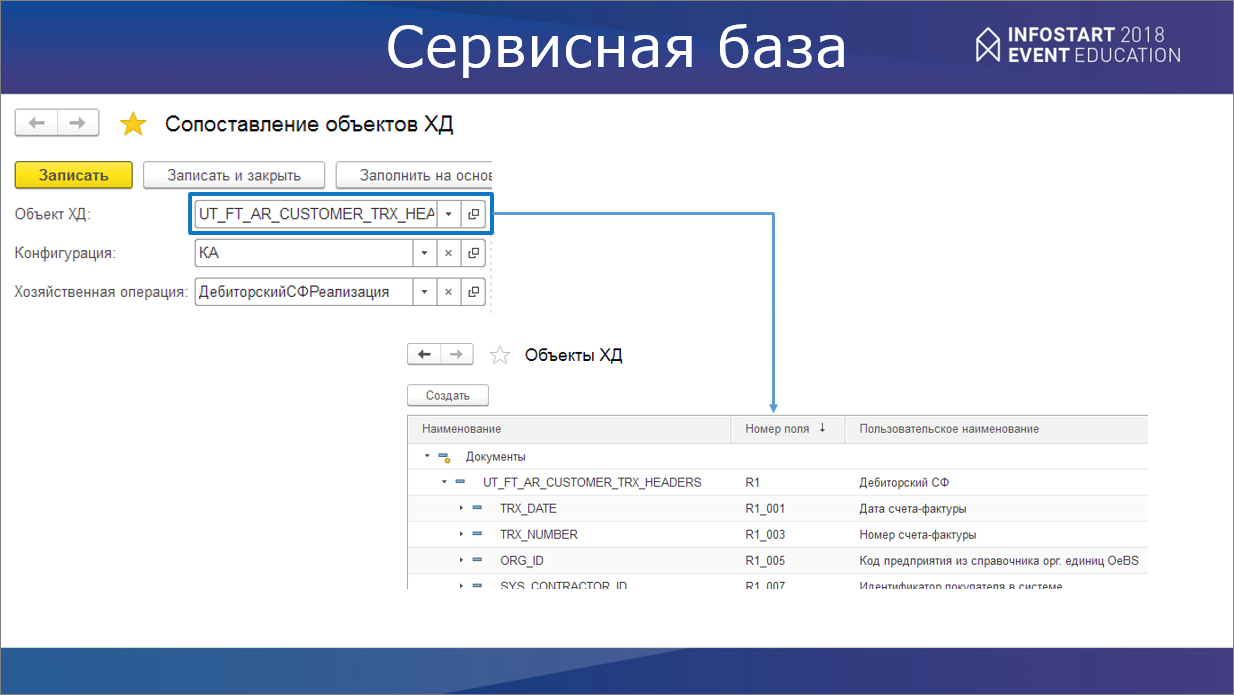
Здесь можно подробнее увидеть, как устроена иерархия объектов хранилища. Она повторяет структуру целевой базы.
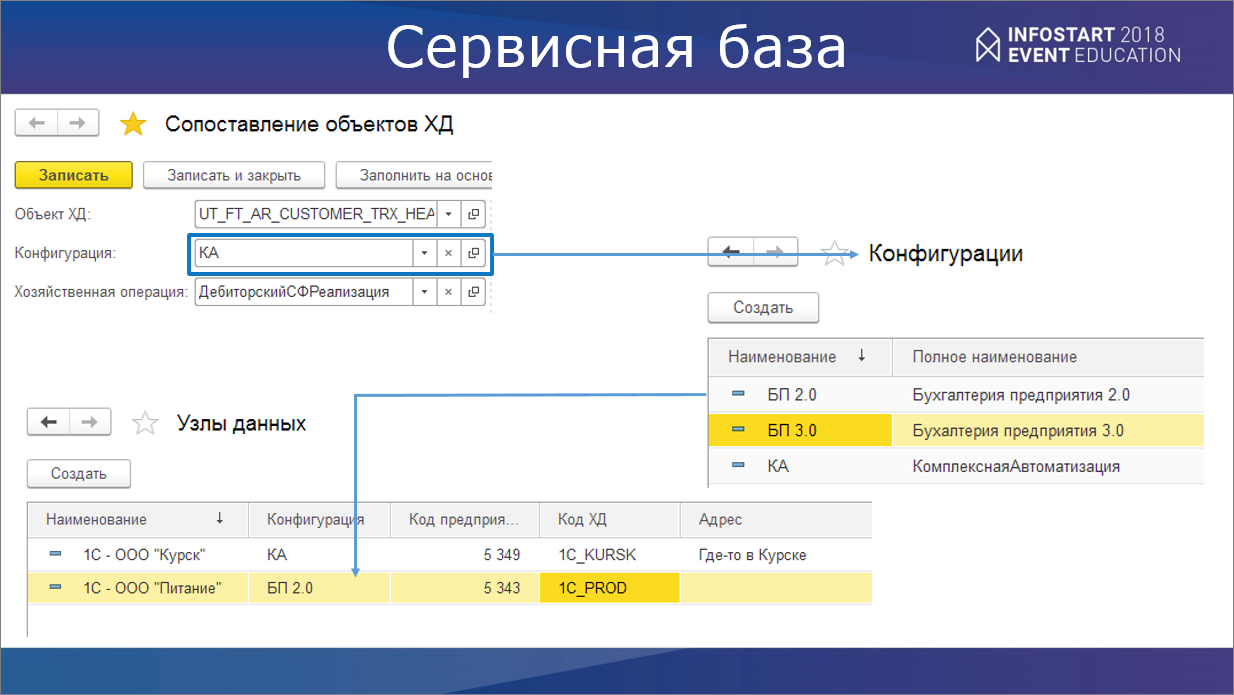
Связь филиалов с правилами сопоставления осуществляется через конфигурационные единицы. Допустим, у нас есть филиал в Курске, который работает на конфигурации БП2.0. Но правила мы пишем не для Курска, а для БП2.0. Это упрощает работу, потому что, если конфигурации в разных филиалах совпадают, для них действуют единые правила. А поскольку конфигурации, по большей части, были типовые, с этим все просто. Было несколько отклонений, для них мы выдумывали отдельные конфигурационные единицы – КА_1, например (доработанная «Комплексная автоматизация»).

На слайде показана карточка хозяйственной операции.
-
На второй вкладке формы производится привязка к объектам 1С – мы привязываем к данной хозяйственной операции те виды документов и справочников, которые могут в ее рамках использоваться.
-
Также для каждой хозяйственной операции мы задаем разрешенные проводки. Если проводка разрешена, и она основная, то по указанным видам документов выбираются и анализируются все движения по регистру бухгалтерии. И если в результате этого анализа обнаруживается, что документ, который участвует в этом обмене, имеет какую-то запрещенную проводку, бухгалтеру при выгрузке данных на месте сразу выводится сообщение о том, что по такому-то документу есть запрещенная проводка, которую необходимо исправить.

Далее – мы придумали механизм более гибкой привязки объектов 1С к объекту хранилища.
Вы все прекрасно знаете, что написать правила один раз так, чтобы они работали для всех, невозможно – в любом случае будут какие-то отклонения, какие-то условности. Мы попытались реализовать эти условности через дополнительную надстройку.
На слайде выделена процедура, написанная кодом 1С. Программист может ее редактировать, если ему нужно выполнить какие-то дополнительные операции перед выгрузкой.

Например, у нас есть хозяйственная операция ДебеторскийСФРеализация, в рамках которой используется документ РеализацияТоваровУслуг, но для данного документа нам нужно отобрать только те проводки, которые сформированы с определенным видом операции. Этот отбор мы можем реализовать в коде – здесь мы отфильтровываем какие-то вещи или можем их подменить.
Для удобства мы написали свой маленький редактор кода на HTML – это поле HTML, оно раскрашивается.

В коде используются определенные функции для внутренних проверок. Например, мы создали функцию ОбъектВида(), куда передаем необходимый тип, чтобы она сверила его с типом внутренней переменной Объект, чтобы проверить, что это – «Реализация товаров и услуг» или еще что-нибудь.
Таких функций мы описали достаточно много – это, по сути, маленькое «программирование в программировании».

Код можно проверять. По кнопке «Проверка» запускается выполнение этого кода с учетом всех встроенных процедур, которые у нас используются (таких, как ОбъектВида()). И просто проходит синтаксический контроль. Если есть какая-то ошибка, мы об этом говорим.
Все переменные, которые у нас со знаком $, после точки не анализируются (по умолчанию считается, что конструкция верная).

Есть дополнительные функции, которые позволяют вставлять в этот код объекты 1С с теми наименованиями, которые есть в конфигурации. Для этого мы сделали выгрузку структуры конфигурации из филиалов.
Здесь пользователь (программист) может подставить в код табличную часть или реквизит из документа, может вызвать синтакс-помощник с описанием той или иной функции.

Третья часть нашей обработки – это непосредственно сопоставление.
Здесь мы говорим, какие поля у нас с какими сопоставляются. Грубо говоря, у нас есть поле объекта хранилища данных, и мы можем сопоставить его со значением поля 1С (например, Объект.Номенклатура) либо напрямую, либо с какими-то условиями. Каждое такое поле выполняет роль процедуры – там тоже есть миниредактор, есть условия, мы даже можем вводить сюда какие-то сложные конструкции. Но это будет выполняться не по процедуре «Выполнить», а по процедуре «Вычислить».
Взаимодействие сервисной базы и базы обмена (SQL)
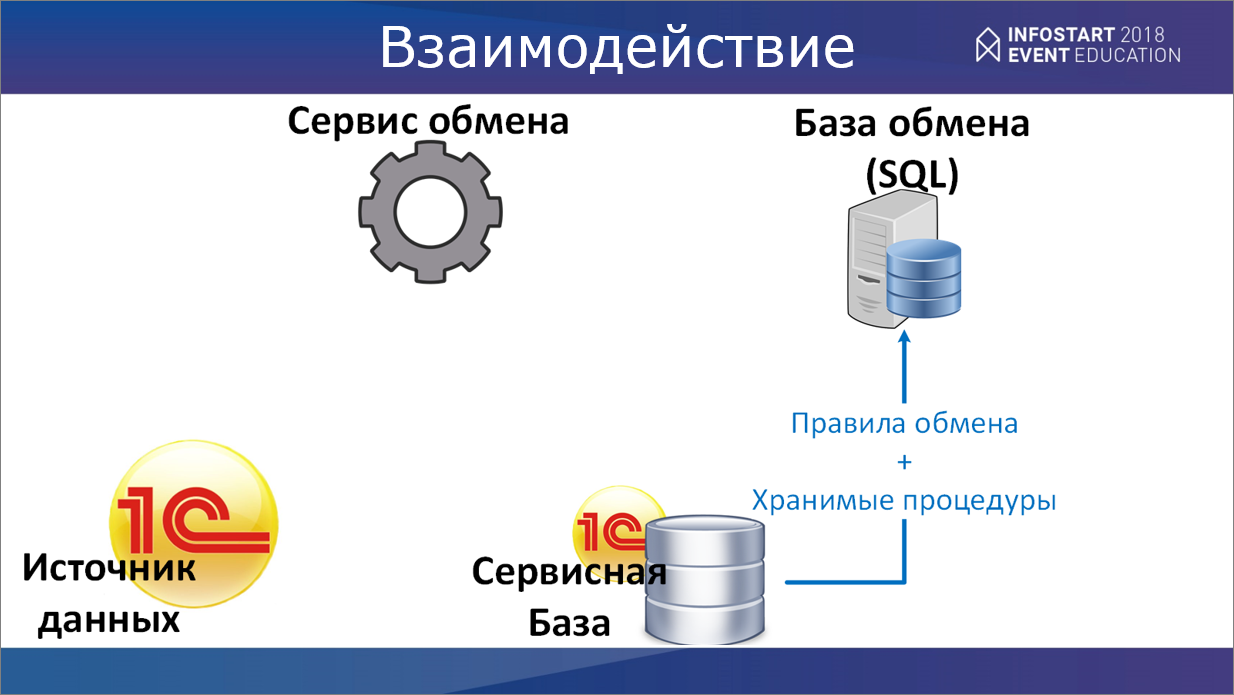
Далее – как у нас идет взаимодействие всего этого?
Помимо того, что у нас есть правила обмена, которые мы задаем нашей чудо-обработкой, у нас, помимо прочего, из сервисной базы в базу обмена выгружаются еще и все хранимые процедуры, которые будут использоваться нашим сервисом.
Это – регламентный обмен, который поставляет данные в базу обмена.
Взаимодействие источника данных и базы обмена (SQL) через сервис обмена
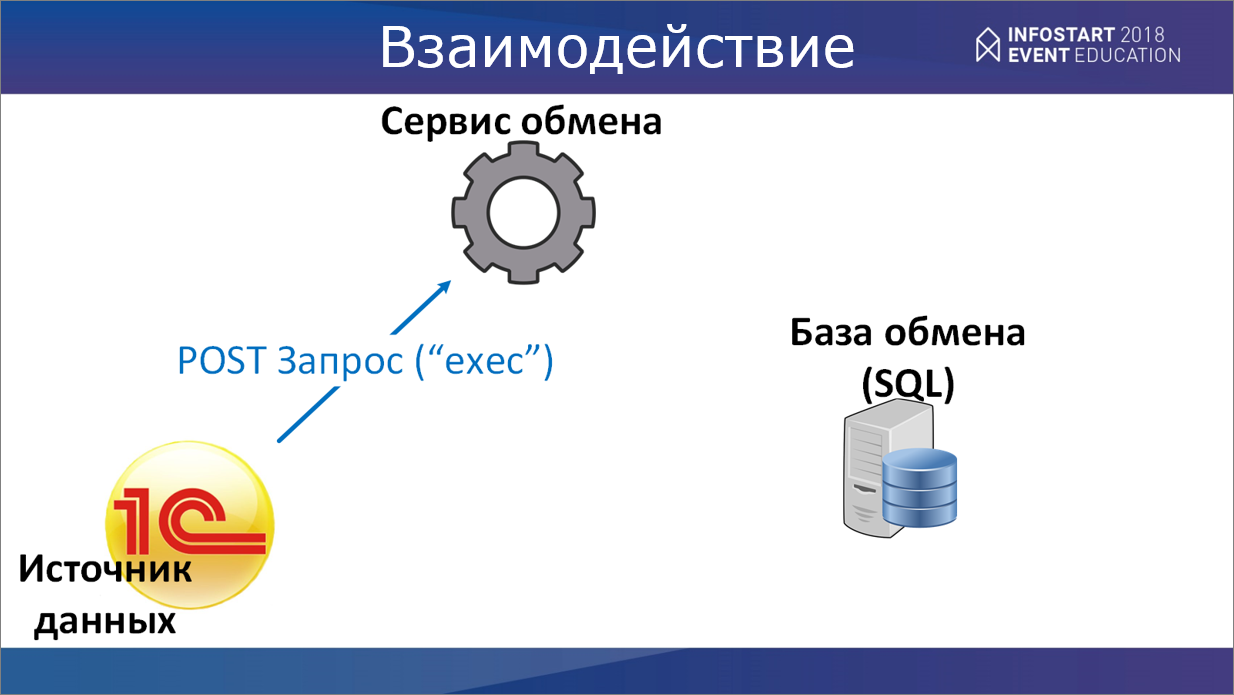
Как происходит взаимодействие с источником данных?
Источник данных соединяется с сервисом обмена и посылает POST запрос с методом «exec» и в качестве параметра передает туда имя хранимой процедуры, которая должна выполниться.

Сервис обмена вызывает эту хранимую процедуру в нашей базе SQL.
Хранимая процедура может либо что-то выполнить внутри – сделать какие-то манипуляции с базой, либо выбрать какие-то необходимые нам коллекции. Соответственно, если будет несколько выборок, каждая из них обернется в свою коллекцию.
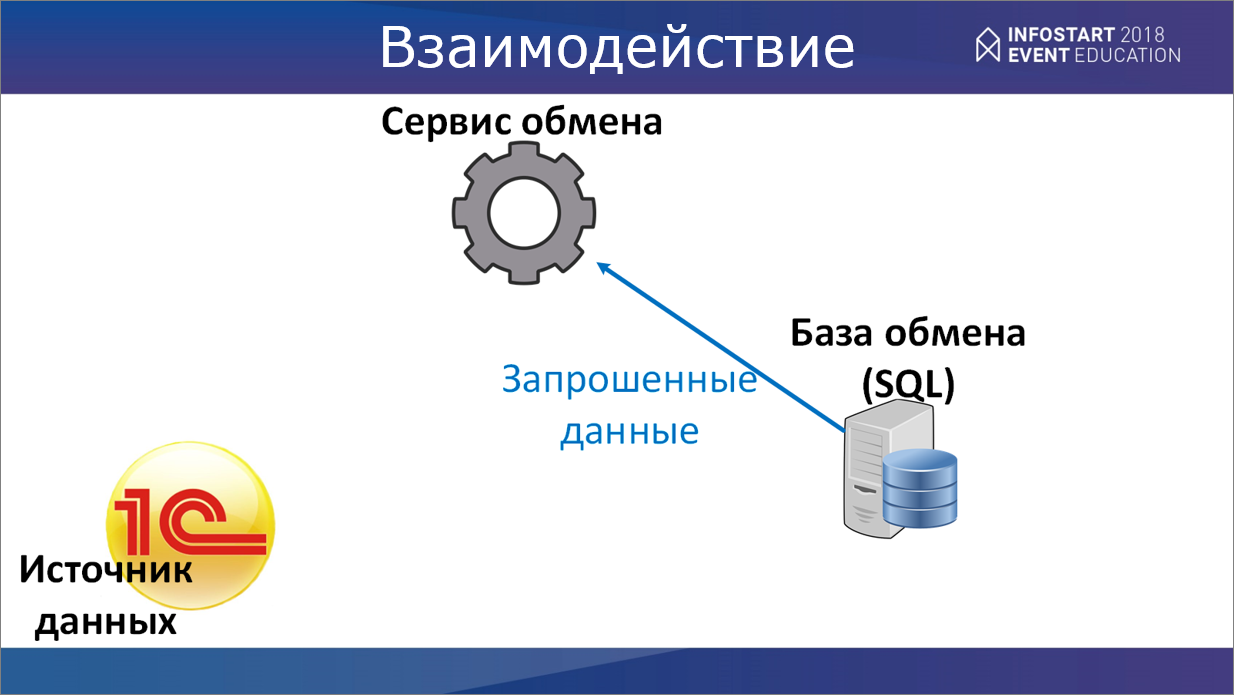
Запрошенные данные будут переданы обратно в сервис обмена.
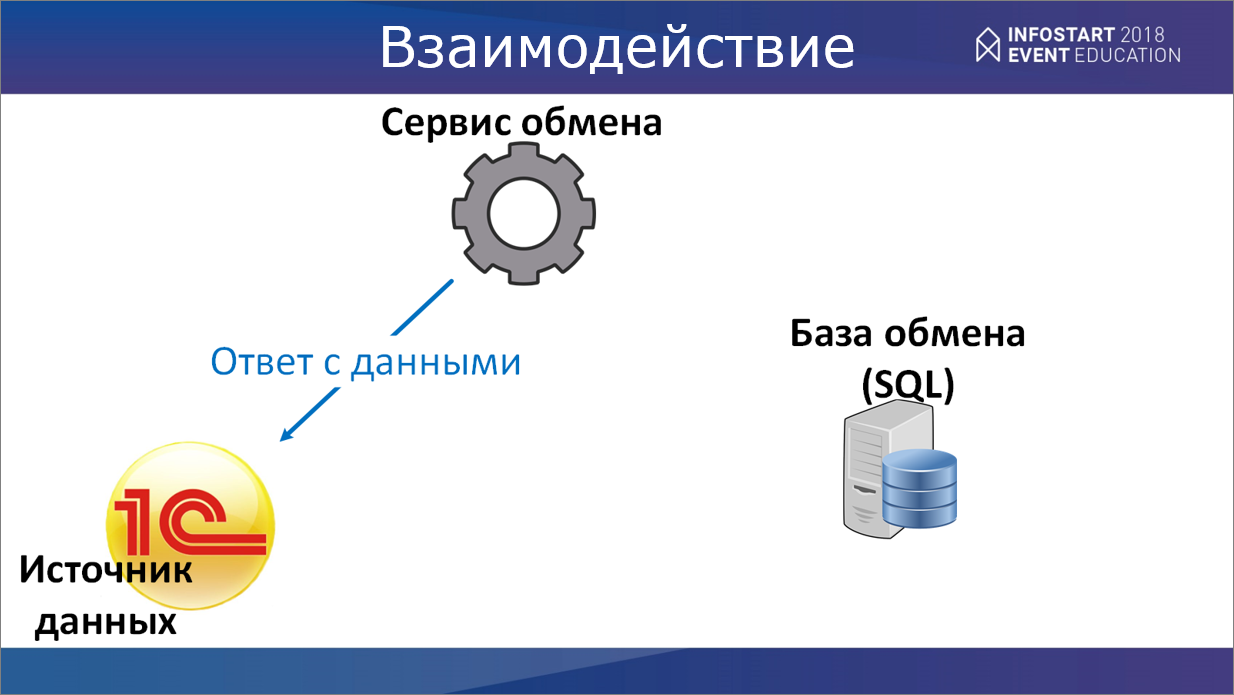
Сервис обмена преобразовывает эти данные в XML и передает их источнику. А дальше источник с этими данными делает необходимые манипуляции.
В качестве данных, в частности, могут быть переданы правила обмена и непосредственно обработка самой выгрузки.
Выгрузка данных в филиалах
Расскажу, как действует выгрузка данных в филиалах.
Мы разослали по всем филиалам через «Дополнительные отчеты и обработки» стартовую обработку, единственная задача которой – подключиться к сервису обмена и запросить первоначальные данные, которые включают в себя непосредственно обработку по выгрузке.
Эта обработка по выгрузке – единая для всех, мы тиражировали ее из нашей сервисной базы. Изменения в нее вносятся централизованно, и ее обновленная версия помещается в базу обмена в виде бинарных файлов.
Соответственно, стартовая обработка в филиалах подключается и получает актуальную обработку выгрузки.
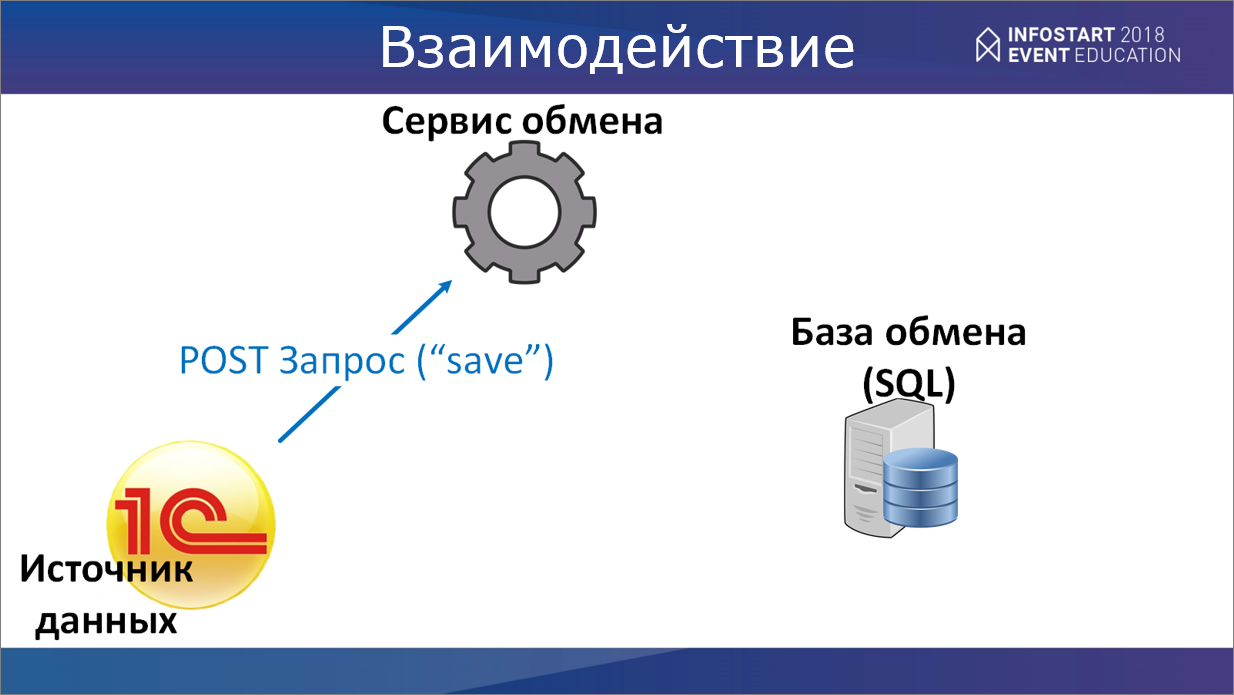
Теперь о выгрузке данных из источника. Допустим, мы все правила получили, бухгалтер проверил, что все проводки соответствуют нашим правилам, никаких ошибок нет, он нажимает кнопку «Отправить данные». Эти данные, опять же, заворачиваются в XML, и вызывается метод «save», которому передается параметром этот XML. В XML у нас содержится имя таблицы, куда необходимо поместить данные, и сама коллекция (причем, этих коллекций может быть несколько).

Сервис обмена принимает эти данные и помещает их в базу обмена.
Далее – возвращает квитанцию с ответом, передал он данные или нет. Если что-то по какой-то причине не было помещено, то те данные, которые у нас не прошли, мы обрабатываем повторно и, соответственно, не снимаем с регистрации объекты, которые находятся в источнике данных.
Регистрация данных в источниках осуществляется простейшим методом. В каждой типовой конфигурации есть план обмена «Полный», куда включены абсолютно все объекты системы. Он один раз настраивается, и далее, все наши документы и справочники регистрируются в созданном узле этого плана обмена и выгружаются по этим зарегистрированным изменениям. Если что-то не прогрузилось, мы просто объекты с регистрации не снимаем.
Мониторинг обмена с помощью сервисной базы

Как это все мониторится? Для бизнеса и админов этого обмена мы в сервисной базе сделали обработку, где можно посмотреть, какие филиалы, когда выходили на связь, были ли по каким-то филиалам ошибки.
Все это визуализировано на карте – обычный HTML с разметкой, где обозначены наши филиалы. При наведении мышкой выводится дополнительная информация о том, когда был последний обмен, сколько ошибок было по обмену и т.д.
Есть отчет по ошибкам. В нем видно, в каком филиале была ошибка, что это за ошибка. Если у пользователя при выгрузке данных была какая-то запрещенная операция, все это фиксируется и попадает в этот отчет.
Ответы на вопросы
Насколько я понял, у вас есть огромное количество разных баз, и стоит задача привести их к некоему единому пониманию на уровне бизнеса. Вы пишите хранимые процедуры в какой-то центральной базе, и потом эти хранимые процедуры рассылаете на места или как?
-
У нас есть основная хранимая процедура, мы ее назвали GetData (получить данные). Там есть несколько запросов, которые обращаются к таблицам – в том числе с маппингом, по связкам. С помощью этой хранимой процедуры, простыми SELECT-ами, выбирается вся необходимая для филиала информация. Соответственно, сервис обращается к этой хранимой процедуре, получает все эти данные, заворачивает их в XML и отдает в филиал. И есть еще одна специфическая хранимая процедура, о которой я хочу рассказать отдельно. Почему вообще заказчик изначально затеял этот проект? У них интеграция была построена наоборот – они сначала получали данные из регистра бухгалтерии (все проводки по оборотам за какой-то период), а потом с помощью скрипта на Oracle из 3000 строк весь этот массив данных анализировали, и делали транзакционные вставки в записи. Грубо говоря, есть оборот по какому-то определенному счету за период, а этот скрипт, в зависимости от того, какие в проводке использовались субконто, определял, что это за операция, и дальше уже вставлял транзакционную запись непосредственно в ту или иную таблицу (дебиторский счет-фактура, кредиторский счет-фактура, либо это вообще поступление денежных средств). Мы сказали, что это неправильно, нужно пойти обратным путем – сначала собрать транзакционные данные, а уже из этих транзакционных данных собрать обороты. И это будет правильно. Поэтому мы привязались именно к документу 1С – получали совершенные этим документом проводки, и на основании этих проводок по месяцам делали собственную оборотно-сальдовую ведомость, которая хранилась в отдельной таблице – GLLines. Для этого была написана отдельная хранимая процедура, которая собирала транзакционные данные для всех этих проводок и заворачивала их в оборотно-сальдовую ведомость. Эту хранимую процедуру тоже можно было редактировать в сервисной базе. И потом при обмене, когда все транзакционные данные помещены, перед тем как выгружать данные в хранилище, вызывается эта процедура, которая по существующим транзакциям пересчитывает обороты.
Я так понял, в вашей сервисной обработке программист работает в терминологии полей SQL и хранимых процедур. Насколько сложно взять простого смертного 1С-ника, пересадить на это и обучить? Какими знаниями должен обладать человек, чтобы успешно решать эти настройки, которые будут отправляться на места?
-
Здесь порог вхождения достаточно высокий, недостаточно написать SELECT * FROM *. Терминологию T-SQL нужно знать, хотя бы на начальном уровне. Мы согласовывали это с заказчиком, у них были специалисты.
Приходит молодой 1С-ник, который достаточно хорошо знает 1С. Если дать ему задачу разобраться в этом механизме, сколько времени нужно, чтобы быть уверенным, что он это сделает?
-
Сколько времени нужно, чтобы обучить человека азам T-SQL? Примерно так, наверное, и будет. Если 1С-ник понимает и мыслит именно на уровне структуры данных, у него аналитический, а не гуманитарный склад ума, то я думаю, можно научить за неделю. Все люди разные и восприятие информации у всех отличается. Кто-то сможет за 2-3 дня понять структуру и идею, как это все работает. А так как у нас все 1С-ники пишут запросы грамотно (у нас есть статус Эксперта по технологическим вопросам), то люди очень быстро начинают понимать, как эти запросы выстраиваются на уровне SQL, потому что это, по сути, то же самое, что и методология создания запросов.
А как вы проверяете новые изменения, которые внесли, работают? Как у вас сделана проверка того, что все это валидируется и работает?
-
У нас есть проверка кода, я показывал ее на скриншоте. Если мы для хранимой процедуры написали много строк, которые выполняются перед выгрузкой, этот код можно проверить непосредственно в сервисной базе. Какие-то синтаксические ошибки начального уровня он находит.
А если поле как-то не так названо?
-
Мы загружаем в сервисную базу структуру конечной конфигурации, поэтому у нас там есть помощник, который может вставить для объекта подчиненный реквизит (например, Номенклатура.ВидНоменклатуры). Этот реквизит он может взять непосредственно из структуры конфигурации, для которой он пишет это правило. В данном случае, мы пытались минимизировать эти ошибки. Но даже если ошибка вылезет при выгрузке данных у бухгалтера, например, при попытке обращения к какому-то несуществующему реквизиту, система не падает, она фиксирует эти ошибки и передает их обратно в сервисную базу.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2018 EDUCATION.


Вступайте в нашу телеграмм-группу Инфостарт