




{kind=link}
Я не люблю, когда к месту и не к месту употребляют термин «Искусственный интеллект». «Искусственный интеллект отделяет котиков от собачек», «искусственный интеллект помогает ловить преступников», «абонентам помогут сократить расходы с помощью искусственного интеллекта». Чувствуется в этом какая-то попытка выдать желаемое за действительное. Я предпочитаю термин «Машинное обучение». По крайней мере именно про него я буду рассказывать дальше.
В статье я расскажу, каким образом сокращал затраты на первую линию HelpDesk. Она носит познавательный и чисто технический характер, я не раскрываю вопросов сколько денег удалось сэкономить на персонале за счет внедрения данного функционала и насколько в целом оправдана оказалась разработка с экономической точки зрения.
Обращаю внимание, что несмотря на ресурс, где статья опубликована – непосредственно к 1С она практически не имеет отношения. Только математика и Python.
Постановка задачи:
Есть 15 тысяч инцидентов в месяц, поступающих с 3000 магазинов. Необходимо придумать решение, которое позволит сократить трудозатраты на решение инцидентов без увеличения либо даже с сокращением штата.
Было решено реализовать две функции:
- Автоматический вариант решения. Сразу после того, как сотрудник набрал текст инцидента можно, проанализировав его, предложить ему возможное решение.
- Предсказание правильного классификатора. Выбор правильного классификатора — это функция 1 линии техподдержки, правильный выбор позволяет корректно маршрутизировать инцидент, что в свою очередь сокращает время на решение инцидента. Ну, думаю всем очевидно, что если к 1С-нику придет инцидент, что между двумя узлами есть потеря сетевых пакетов, то время решения инцидента увеличится на время пока сотрудник увидит этот инцидент, вернет его на первую линию, а там уже правильно маршрутизируют ошибочно назначенный инцидент.
Реализовать удалось обе функции, о первой я расскажу в этой статье, а про вторую – в следующей.
Немного теории.
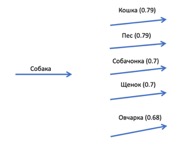
В 2013 году в компании Google был разработан инструмент для анализа семантики естественных языков word2vec. Идея инструмента – подать на вход текстовый корпус, затем внутри происходит компьютерная магия и на выходе мы получаем матрицу, в которой каждое из слов нашего корпуса представлено как вектор, причем чем более сонаправлены вектора (чем больше косинусное произведение между ними), тем они более похожи.

На картинке я попытался изобразить ТОП-5 векторов, наиболее близких слову «Собака». Обучение матрицы происходило на википедии и на национальном корпусе русского языка. Самостоятельно поиграться можно например тут https://rusvectores.org/ Естественно на рисунке лишь схема, на самом деле матрица является не двумерной, то есть каждое слово задается не двумя координатами, а сотней и более.
Размерность матрицы задается, как параметр перед началом обучения, очевидно, что чем больше размерность – тем более точные результаты мы получим, однако сложность, а следовательно длительность обучения экспоненциально зависит от размерности. Документации и статей по word2vec достаточно, используется он весьма активно и интересующимся я рекомендую ознакомиться с этим инструментом более глубоко.
Для решения первой задачи сделаем следующее предположение – у нас есть инцидент и его решение, которое придумано человеком. Переведем текст инцидента в вектор и примем его за эталон. Теперь возьмем поступивший инцидент и так же переведем его в вектор, чем более сонаправлены полученные два вектора (чем между угол между ними) тем выше вероятность того, что решение эталонного инцидента подойдет для решения нового. Тестирование показало, что предположение в целом верное, то есть на больших объемах его вполне можно использовать в продуктивной среде.
Вся разработка велась на Python в среде Anaconda. При установке Анаконды часть необходимых библиотек устанавливается сразу, часть необходимо будет доустановить. Так как статья не ставит своей целью обучить программированию на Python, я не буду углубляться в вопросы «как поставить библиотеку», «а почему написано именно так», однако готов при необходимости обсудить это в комментариях. Так же обязательно выслушаю советы опытных питонистов, потому что уверен, мой код далек от оптимального.
Объявим нужные нам библиотеки:
import warnings
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')
#Подавляем лишние оповещения
import pyodbc
#Все инциденты считываются из базы данных, библиотека для доступа к SQL
import pandas as pd
#Про pandas написано куча книг. Кратко - pandas это высокоуровневая Python библиотека для анализа данных.
import re
#Ммм, регулярки (картинка с Гомером)
import pymorphy2
morph = pymorphy2.MorphAnalyzer()
#Морфологический анализатор.
import logging
logging.root.handlers = []
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
#Библиотека для логирования
from smart_open import smart_open
#Библиотека для работы с большими удаленными файлами
import numpy as np
#Библиотека для работы с большими многомерными массивами
from numpy import random
import genism
# Библиотека обработки естественного языка
import nltk
#пакет библиотек и программ для символьной и статистической обработки естественного языка
from sklearn.model_selection import train_test_split
from sklearn import linear_model
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from sklearn.metrics import accuracy_score, confusion_matrix, recall_score
# sklearn - бесплатная библиотека машинного обучения для языка программирования Python
import matplotlib.pyplot as plt
#Необходимо для рисования графиков
from gensim.models import Word2Vec
#А вот и сам Word2Vec
from sklearn.neighbors import KNeighborsClassifier
from sklearn import linear_model
from nltk.corpus import stopwords
#Стоп слова нужны, чтобы исключить общеупотребительные слова не несущие для наших целей смысловой нагрузки
%matplotlib inline
Загрузим стоп слова
stop_words = stopwords.words('russian')
Загрузка инцидентов ведется из базы данных инцидентов. При необходимости выполнить загрузку можно из любого источника.
connection_string_remedy = 'DRIVER={ODBC Driver 17 for SQL Server};SERVER=MyServer;DATABASE=MyBase;UID=user;PWD=password'
Объявим функцию, которая приведет текст инцидента к машиннообрабатываемому виду. Для этого мы сделаем следующее:
1. Удаляем всё лишнее (цифры, подписи, телефоны)
2. Приводим к нижнему регистру.
3. Удаляем стоп-слова.
4. лемматизируем и добавляем часть речи (ну кстати тестирование показало, что добавление части речи не улучшает результат, поэтому ниже этот функционал закомментирован.
def lemmatization(text,morphing = True):
stop_words = stopwords.words('russian')
border = text.find('Для решения инцидента заявитель должен предоставить')
#После этого текста в инциденте у нас идет служебная информация, ФИО сотрудника,
#магазин, с которого он обратился, номер телефона, IP адрес компьютера и прочее
#то, что для наших целей явно мешает. Удаляем.
if border > 0:
text = text[0:border]
text = text.lower()
text = re.sub(r"\d+", "", text, flags=re.UNICODE)
text = re.sub('\W', ' ', text).split()
if morphing == False:
return text
text_new = ''
x = 0
previous_word_ne = False
for item in text:
if item == 'не':
previous_word_ne = True
#это важная часть. Так как машина превращает слова в вектора – для нее «работает» и «не работает» не антонимы,
# а просто -в первом случае один вектор, а во втором случае два и они между собой не связаны.
#Поэтому превратим два слова «не работает» в одно «не_работает»
if len(item) > 2:
if not (item in stop_words):
if previous_word_ne:
text_new = text_new+'не_'+morph.parse(item)[0].normal_form+' '#'_'+str(morph.parse(item)[0].tag.POS)+' '
# morph.parse(item)[0].normal_form – приведение к нормальной форме: «Побежали» -> «бежать», «компьютеров» -> «компьютер» и т.д.
previous_word_ne = False
else:
text_new = text_new+morph.parse(item)[0].normal_form+' '#'_'+str(morph.parse(item)[0].tag.POS)+' '
return text_new
Результат работы функции:
lemmatization ("Для решения первой задачи сделаем следующее предположение – у нас есть инцидент и его решение, которое придумано человеком")
'решение один задача сделать следующий предположение инцидент решение который придумать человек '
Загрузим данные в DataFrame:
%%time
cnxn = pyodbc.connect(connection_string_remedy)
cursor = cnxn.cursor()
sql = '''
SELECT Number, Description, ShortDescription
FROM [MyBase].[dbo].[MyTable] (nolock)
where cast(DateCreate as date) > '2018-01-01'
and '''
#Здесь Description – текст инцидента, а ShortDescription его классификатор
#Кладем результат запроса в DataFrame и лемматизируем текст инцидента
df_result = pd.read_sql_query (sql, cnxn)
for index, row in df_result.iterrows():
text = row['Description']
text_new = lemmatization(text)
df_result.iat[index,1]=text_new
Создаем список классификаторов, берем только инциденты, количество которых больше заданного значения, в нашем случае берем только инциденты, которых с указанным классификатором больше 1000.
my_tags = (df_result['ShortDescription'].value_counts()>1000)
my_tags = my_tags[my_tags == True].index.tolist()
len(my_tags)
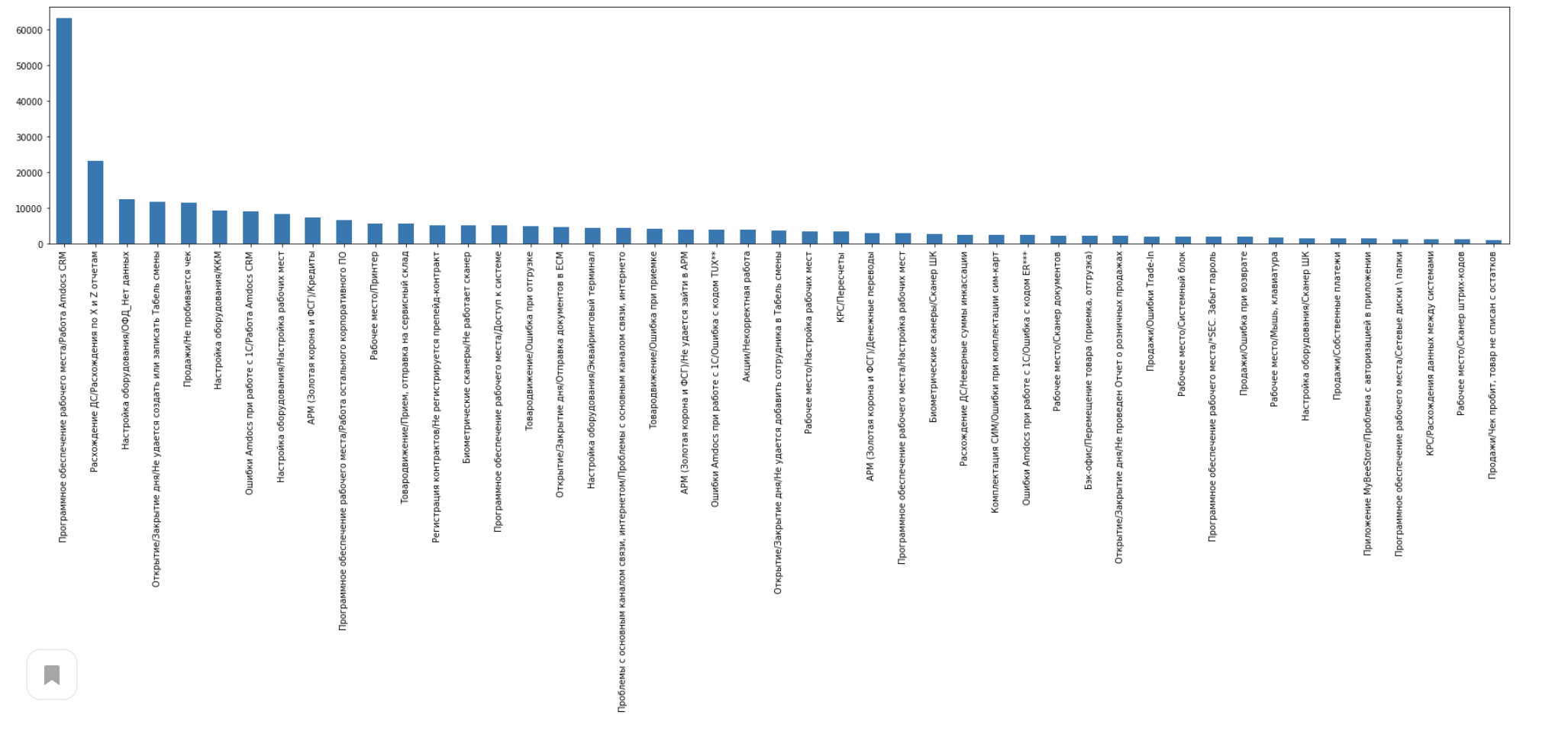
У меня получилось 57 самых частых классификаторов. Данный параметр нужно подбирать на основании ваших данных.
Копируем DataFrame, чтобы заново не готовить исходный DataFrame. Дальше работаем только с отфильтрованным DataFrame. Сравниваем количество в отфильтрованном и полном DataFrame
df_result_filter = df_result[df_result['ShortDescription'].isin(my_tags)]
print(df_result.count())
print(df_result_filter.count())
df_result_filter.to_csv('Data/df_result_filter.csv', encoding = "utf-8")
У меня получилось 553551 инцидент в неотфильтрованном и 509497 инцидентов в отфильтрованном датафреймах.
Теперь давайте посмотрим на распределение инцидентов по классификаторам:
df_result_filter.ShortDescription.value_counts().plot(kind="bar", rot=90)
plt.rcParams['figure.figsize'] = [30, 5]
plt.show()
Разбиваем наш датафрейм на тренировочную и тестовую части. Как понятно из названия – на тренировочной мы будем обучать нашу модель, а на тестовой – проверять результат обучения.
train_data, test_data = train_test_split(df_result_filter, test_size=0.1, random_state=42)
Далее создадим вспомогательные функции:
Вспомогательная функция для вывода на экран матрицы ошибок, результат ее вы увидите чуть позднее, когда мы обучим модель.
def plot_confusion_matrix(cm, title='Confusion matrix', cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(my_tags))
target_names = my_tags
plt.xticks(tick_marks, target_names, rotation=90)
plt.yticks(tick_marks, target_names
plt.ylabel('True label')
plt.xlabel('Predicted label')
fig = plt.gcf()
fig.set_size_inches(18.5, 10.5)
fig.savefig('test2png.png', dpi=100)
Функция, непосредственно вычисляющая матрицу ошибок.
def evaluate_prediction(predictions, target, title="Confusion matrix"):
print('accuracy %s' % accuracy_score(target, predictions))
print('recall %s' % recall_score(target,predictions, average='micro'))
cm = confusion_matrix(target, predictions)
cm_normalized = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plot_confusion_matrix(cm_normalized, title + ' Normalized')
Функция, превращающая текст инцидента в вектор
def word_averaging(wv, words):
all_words, mean = set(), []
for word in words:
if isinstance(word, np.ndarray):
mean.append(word)
elif word in wv.vocab:
mean.append(wv.syn0norm[wv.vocab[word].index])
all_words.add(wv.vocab[word].index)
if not mean:
logging.warning("cannot compute similarity with no input %s", words)
# FIXME: remove these examples in pre-processing
# return np.zeros(wv.layer1_size,)
return np.zeros(wv.vector_size,)
mean = gensim.matutils.unitvec(np.array(mean).mean(axis=0)).astype(np.float32)
return mean
def word_averaging_list(wv, text_list):
return np.vstack([word_averaging(wv, review) for review in text_list])
#Разобьем полученные данные на массив (ndarray), строками в котором будут списки (list), где каждый элемент списка – отдельное слово.
def w2v_tokenize_text(text):
tokens = []
for sent in nltk.sent_tokenize(text, language='english'):
for word in nltk.word_tokenize(sent, language='english'):
if len(word) < 3:
continue
tokens.append(word)
return tokens
Приступаем непосредственно к тренировке.
#Используя вышеобъявленную функцию превратим наш Датафрейм в массив с инцидентами (каждый инцидент это список, в котором отдельный элемент списка – слово)
inc_tokenized = df_result.apply(lambda r: w2v_tokenize_text(r['Description']), axis=1).values
Посмотрим, что у нас получилось, возьмем 50-ый элемент массива:
inc_tokenized[50]
['добрый',
'день',
'ошибочно',
'отгрузить',
'телефон',
'просить',
'отменить',
'отрузка',
'поставить',
'остаток',
'телефон',
'мочь',
'вернуть',
'клиент',
'номер',
'сейф',
'пакет',
'номер',
'отгрузка',
'заранее',
'спасибо',
'табельный',
'номер']
Обучим нашу модель
%%time
model = Word2Vec(inc_tokenized,
size=200,
window=5,
min_count=3,
workers=8)
wv = model.wv
Создадим L2-нормированные вектора и сохраним результат, он нам потребуется в дальнейшем
wv.init_sims(replace=True)
wv.save_word2vec_format('data/key_vectors_inc.bin')
Ну теперь давайте немного поиграем в ассоциации. Попросим показать нашу модель наиболее близкие по смыслу слова к тому, которое мы укажем. Обратите внимание, база для обучения – это инциденты от сотрудников магазинов сотовой связи (телефоны, аксессуары, сим-карты и т.п.)
wv.most_similar(positive=['ошибка'])
[('сообщение', 0.653794527053833),
('ощибка', 0.5926002264022827),
('табличка', 0.552541196346283),
('ошбка', 0.525760293006897),
('надпись', 0.5208160281181335),
('окошко', 0.5118091106414795),
('попытка', 0.49567654728889465),
('сбой', 0.48171132802963257),
('окно', 0.4712887406349182),
('уведомление', 0.46060070395469666)]
wv.most_similar(positive=['сим'])
[('симкарта', 0.801783561706543),
('симка', 0.7723581790924072),
('sim', 0.7251297235488892),
('болванка', 0.6134322881698608),
('бронзовый', 0.5933068990707397),
('сикарта', 0.592644989490509),
('icc', 0.582025408744812),
('ctn', 0.581929087638855),
('не_сим', 0.5614026188850403),
('бронза', 0.5609164237976074)]
wv.most_similar(positive=['телефон'])
[('смартфон', 0.8400038480758667),
('айфон', 0.7854971885681152),
('планшет', 0.7388856410980225),
('lite', 0.6476684212684631),
('iphone', 0.613440990447998),
('vita', 0.610135018825531),
('nokia', 0.6086500287055969),
('апп', 0.6069196462631226),
('товар', 0.6057144403457642),
('prime', 0.6033762693405151)]
Да, синонимы слов это конечно интересно, но для нашей задачи никакой пользы не несет, поэтому мы будем превращать в вектора целиком инциденты.
Разобьем инциденты по словам и затем по каждому инциденту, после чего сложив все вектора в инциденте (то есть складываем отдельные слова инцидента выраженные в векторной форме) нормализуем его и получим некий вектор, который показывает нам тематику определенного инцидента (по крайней мере мы предполагаем, что это будет так).
%%time
full_tokenized = df_result.apply(lambda r: w2v_tokenize_text(r['Description']), axis=1).values
X_full_word_average = word_averaging_list(wv,full_tokenized)
df_result['X_full_word_average'] = list(X_full_word_average)
Это позволит нам искать не похожие слова, а похожие инциденты. Давайте проверим, работает ли наше предположение.
Определим функцию, которая вернет нам расстояние между выбранным вектором и матрицей векторов.
def find_similar_index(a, A):
subs = (a[:,None] - A)
sq_dist = np.einsum('ij,ij->j',subs, subs)
return sq_dist
Преобразуем наш инцидент в вектор и найдем вектора, которые наиболее близки нашему. Выберем только те, расстояние до которых меньше 0.3. Чем меньше расстояние – тем ближе наш инцидент к полученному.
df_result_copy = df_result_filter
inc_text = '''
Добрый день. Не получается распечатать ценники по акции Самсунг
с услугами связи и акссесуарами. Ценник должен быть акционный. Название
акции в 1С - Акция «Samsung 3-я цена». Данную акцию не находит. И
выдает ошибку. Скрин приложен.
'''
inc_lemmatization = (lemmatization(inc_text))
inc_tokenize = w2v_tokenize_text(inc_lemmatization)
inc_average_list = word_averaging(wv,inc_tokenize)
df_result_copy['similar_index'] = find_similar_index(inc_average_list,X_full_word_average.T)
df_result_copy = df_result_copy.sort_values('similar_index')
df_order = df_result_copy[df_result_copy['similar_index']<0.3].head(1000)
df_order.head(10)
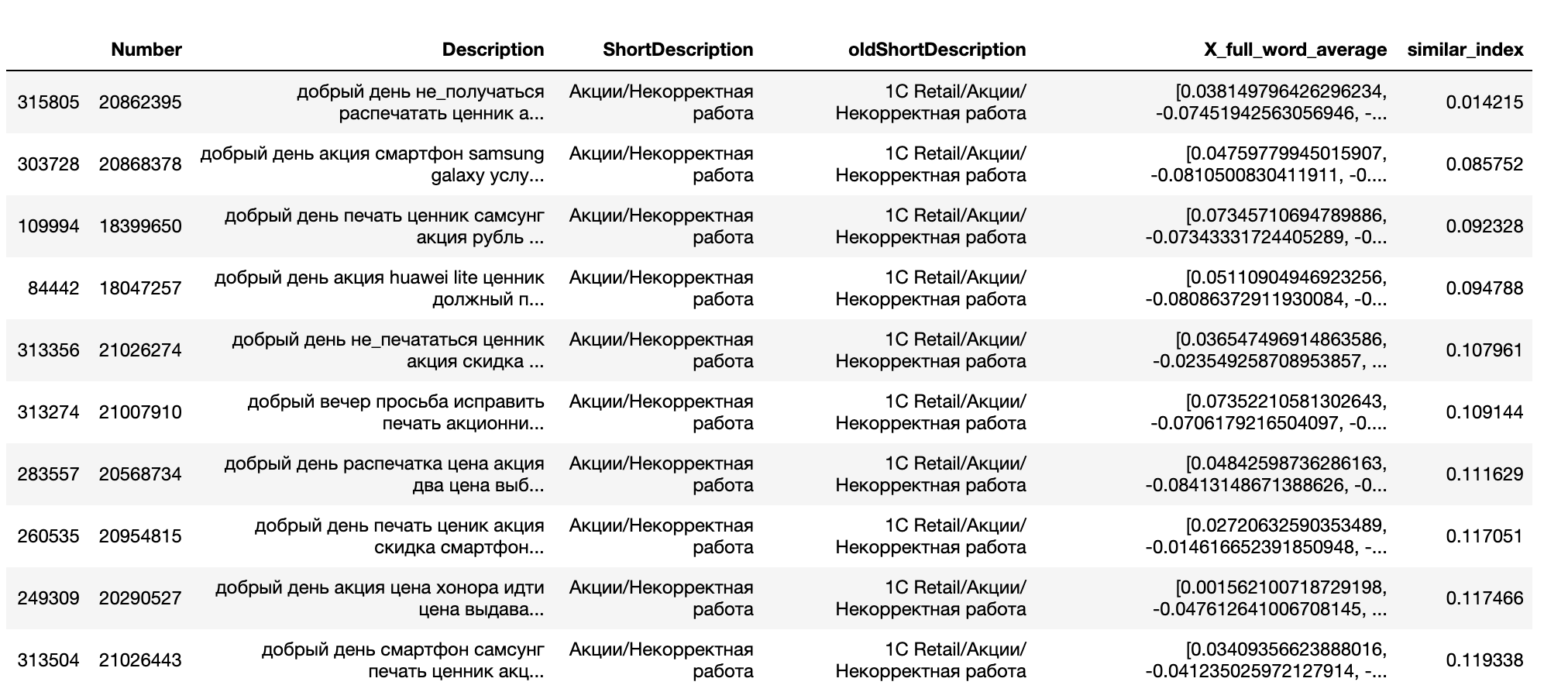
Как видим, для нашего инцидента есть множество похожих. В нашей таблице тексты инцидентов уже лемматизированы, но ничего не мешает посмотреть на исходный текст инцидентов:
Инцидент с номером 20862395 это исходный инцидент, посмотрим следующие:
|
Номер инцидента |
Текст |
|
20868378 |
'Добрый день, по акции Смартфоны Samsung Galaxy с услугами связи и аксессуарами невозможно напечатать акционный ценник, нет данной акции. Когда набираешь артикул выдает ошибку |
|
18399650 |
Добрый день! При печати ценника на Самсунг по акции А30 всего за 99 руб/мес не дает выбрать акцию. Нет возможности напечатать акционный ценник |
|
18047257 |
Добрый день, по акции HUAWEI P30 lite ценник должен печататься с суммой 16590р цена по акции, полная цена смартфона 21990р, ценник не корректный,Ю скрины во вложении |
|
21026274 |
Добрый день. Не печатаются ценники по акции скидка на смартфон apple при покупке доп товаров и услуг |
Изначальную задачу, найти похожие инциденты можно считать выполненной. Если бы в нашей системе HelpDesk были решения для различных типов инцидентов, фактически база знаний, то можно было бы использовать ее, но к сожалению у нас такой готовой базы нет, поэтому нам пришлось еще немного попрограммировать. Тут я очень сокращу свое повествование и просто опишу решение в двух словах.
Создаем для основных проблемных ситуаций описание решения, которое сотрудник может выполнить самостоятельно, например если речь идет о неработающем принтере просьба проверить бумагу, если о невозможности печати чека – убедиться что бумага вставлена в фискальный регистратор и т.д.
Когда сотрудник ввел текст инцидента первым делом мы отправляем его (текст, а не сотрудника) на поиск похожих инцидентов. В случае если среди похожих есть инцидент с готовым решением – покажем его сотруднику и спрашиваем подошло ли решение. Если решение подходит – мы не создаем инцидент, считая что проблема решена.
Вступайте в нашу телеграмм-группу Инфостарт