


Данная публикация предваряет ряд статей об альтернативных способах работы с XML. "Альтернативных", потому что как правило работа с XML в 1С ограничивается разбором xml при помощи последовательного чтения - построчного разбора текстового содержимого. А ведь есть еще и другие способы.
Например, использование языка запросов к XML xPath или шаблонов трансформации XSL. Об этих вариантах будет рассказано в следующих статьях. Но все они опираются на базовое представление документов XML в виде DOM. О том, что такое DOM (document object model или объектная модель документа) и пойдет речь в публикации.
DOM базируется на представлении документа любой структуры в виде дерева узлов, каждый узел (нода) которого представляет собой элемент, атрибут элемента, текстовое значение элемента и т.п.. Связь между узлами построена по принципу "родитель - подчиненные". У корня документа (дерева DOM) родителя нет. У тупикового элемента нет подчиненного (такие элементы абстрактно называются листьями дерева). Таким образом модель DOM может создаваться не только для XML, но фактически для любого структурированного документа (HTML, XHTML). Так, например, браузер пользователя, получая HTML код веб-страницы из интернета, строит дерево DOM этой страницы в оперативной памяти компьютера пользователя.
Модель DOM открывает широкие возможности по манипуляции данными документа. Можно создавать новые узлы, вставлять их на разных уровнях дерева, копировать узлы, удалять узлы, искать узлы по разным параметрам и многое другое.
Модель DOM документа XML наглядно представлена на рисунке ниже.
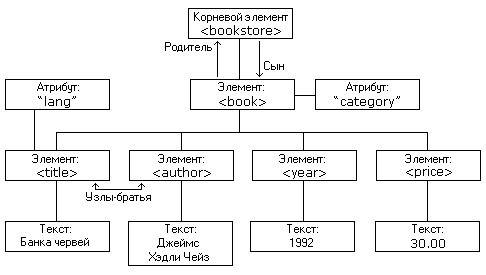
Любой современный язык программирования имеет в своем составе средства (парсеры) для работы с таким деревом. Получая на вход строковое содержимое XML-парсер выстраивает в оперативной памяти дерево узлов и выполняет манипуляции с данными дерева. Преимущество такого подхода перед построчным разбором очевидно: одним запросом к дереву можно выбрать необходимы данные, не перебирая построчно весь документ, ведь в оперативной памяти находится полное представление элементов со всеми взимосвязями.
В платформе 1С модель DOM представлена специальным объектом ДокументDOM, который в свою очередь строится при помощи объекта ПостроительDOM и его метода Прочитать. На вход этому методу, как правило, подается либо объект ЧтениеXML, либо ЧтениеHTML, при помощи которых осуществляется непосредственное считывание из файлов или загрузка из строки текстового содержимого XML или HTML. Ну и далее есть ряд конструкций, позволяющих извлекать данные из объектоной модели прочитанного документа.

Из всех вариантов самым интересным с моей точки зрения является вариант №1 с использованием метода ВычислитьВыражениеXPath. Ему будет посвящена следующая статья.
Плюсы построчного разбора: потребность в ресурсах меньше. Минусы: долго по времени, чтобы получить данные нужно построчно прочитать весь файл, сложность программного кода при разборе XML-документов со сложной структурой.
Преимущество выборки через DOM: скорость выборки данных, простота программного кода. Минусы: требовательность к ресурсам, на построение и запросы к DOM расходуется оперативная память и процессорные мощности.
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}