Введение
Когда в таблице мало строк, затраты на ее сканирование несущественны, а для поиска в "больших таблицах" лучше использовать индексы. Есть как минимум один класс задач, когда бинарные индексы де-факто не помогают. Поиск по условию "LIKE %СтрокаПоиска" или "LIKE %СтрокаПоиска%" фактически равносилен скану таблицы. Например, поиск по телефонным номерам, поиск по номерам документов чаще всего происходит по последним символам.
Если для колонки таблицы планируется использовать поиск с условием "LIKE %СтрокаПоиска1", то нужно создать вспомогательную колонку, содержащую "инвертированные" данные исходной колонки. Вспомогательную колонку индексировать. Поиск производить по "инвертированному" значению, при этом условие поиска примет вид "LIKE СтрокаПоиска2%". Например, если СтрокаПоиска1 = "56789", то СтрокаПоиска2 = "98765".
Конкретный пример
Обратились пользователи: форма поиска контрагентов работает о-о-очень медленно. Всегда используется условие «LIKE %Строка поиска%» (провоцирует сканирование) для заполненных полей.
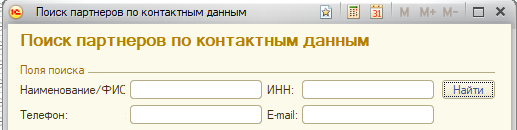
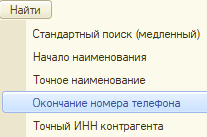
"Универсальную" кнопку переделал в список условий поиска, которые используют индекс. Медленную процедуру оставил для совместимости.
Пользователю необходимо одновременно искать контрагента по контактным данным, контактным данным партнера, контактным лицам. Это разные таблицы СУБД, кроме номеров телефона они содержат другую информацию. Один и тот же номер телефона может быть записан в разных форматах, расстановка символов "(, ), -, +" изменяется. По описанным причинам, индекс полнотекстового поиска не подходит. К тому же бинарный индекс занимает меньше места.
Почему выбраны последние цифры телефона? Например, выдуманный телефон 5-67-89, из соседнего села 8(243)56-789, из соседней области +7(395243)56-789, (моя малая Родина - привет землякам!) из соседней страны еще более сложный, но оканчивается также. Именно поэтому используют поиск телефона по последним цифрам. В СУБД поиск с условием «LIKE %56789» вызовет по факту сканирование таблицы, скорость О(N). Используем один из вариантов решения, разбиравшийся на вебинара Виктора Богачева – вспомогательный регистр МОЙ_ПоискТелефонов, хранит "инвертированные" номера контрагентов. Измерения - "ОбратныйНомер, ВладелецТелефона". Регистр заполняется по существующим номерам и обновляется при изменении телефонов из форм справочников Контрагенты, Партнеры, Контактные лица. Например: для телефона +8(395243)56-789 храним в таблице номер 987653425938. При поиске телефона переворачиваем его, убираем нечисловые символы. Ищем с условием «LIKE 98765%». Значение 98765 находится по бинарному индексу, скорость О(logN). Если в таблице N=1024 записей, то logN = 10, ускорение в сто раз.
Заключение
Помните, что поиск по условию «LIKE %Строка поиска» (равносильно сканированию) всегда можно привести к поиску по условию «LIKE Строка поиска%» (использует индекс). Решения для «LIKE %Строка поиска%» также существуют и на вебинаре также рассматриваются.
//функция общего модуля
&НаСервере
Функция ИнвертированныйНомерТелефона(Знач НомерТелефона) Экспорт
НомерТелефона = СокрЛП( НомерТелефона );
ДлинаНомера = СтрДлина( НомерТелефона );
Результат = "";
Если ДлинаНомера = 0 Тогда
Возврат "";
КонецЕсли;
Для Счетчик = 1 По ДлинаНомера Цикл
Цифра = Сред(НомерТелефона, Счетчик, 1);
Если Цифра >= "0" И Цифра <= "9" Тогда
Результат = Цифра + Результат;
КонецЕсли;
КонецЦикла;
Возврат Результат;
КонецФункции
//Начальное заполнение вспомогательной таблицы "инвертированных" номеров телефонов:
&НаСервере
Процедура КешироватьНомера() Экспорт
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| КонтрагентыКонтактнаяИнформация.Представление КАК НомерТелефона,
| КонтрагентыКонтактнаяИнформация.Ссылка КАК ВладелецТелефона
|ИЗ
| Справочник.Контрагенты.КонтактнаяИнформация КАК КонтрагентыКонтактнаяИнформация
|ГДЕ
| КонтрагентыКонтактнаяИнформация.Ссылка.Партнер.Ссылка ЕСТЬ НЕ NULL
| И КонтрагентыКонтактнаяИнформация.НомерТелефона <> """"
| И НЕ КонтрагентыКонтактнаяИнформация.Ссылка.ПометкаУдаления
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ПартнерыКонтактнаяИнформация.Представление,
| Контрагенты.Ссылка
|ИЗ
| Справочник.Партнеры.КонтактнаяИнформация КАК ПартнерыКонтактнаяИнформация
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
| ПО ПартнерыКонтактнаяИнформация.Ссылка = Контрагенты.Партнер
| И (ПартнерыКонтактнаяИнформация.НомерТелефона <> """")
| И (НЕ ПартнерыКонтактнаяИнформация.Ссылка.ПометкаУдаления)
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ЛицаКонтактнаяИнформация.Представление,
| Контрагенты.Ссылка
|ИЗ
| Справочник.КонтактныеЛицаПартнеров.КонтактнаяИнформация КАК ЛицаКонтактнаяИнформация
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
| ПО ЛицаКонтактнаяИнформация.Ссылка.Владелец = Контрагенты.Партнер
| И (ЛицаКонтактнаяИнформация.НомерТелефона <> """")
| И (НЕ ЛицаКонтактнаяИнформация.Ссылка.ПометкаУдаления)
|ИТОГИ ПО
| ВладелецТелефона";
РезультатЗапроса = Запрос.Выполнить();
ВыборкаГрупп = РезультатЗапроса.Выбрать( ОбходРезультатаЗапроса.ПоГруппировкам );
НаборРегистра = РегистрыСведений.МОЙ_ПоискТелефонов.СоздатьНаборЗаписей();
НаборРегистра.Очистить();
Пока ВыборкаГрупп.Следующий() Цикл
КонтрольУникальности = Новый Соответствие;
ВыборкаДетальная = ВыборкаГрупп.Выбрать( ОбходРезультатаЗапроса.Прямой );
Пока ВыборкаДетальная.Следующий() Цикл
ИнвертированныйНомер = ИнвертированныйНомерТелефона( ВыборкаДетальная.НомерТелефона );
Если КонтрольУникальности[ИнвертированныйНомер] = Истина
ИЛИ ПустаяСтрока(ИнвертированныйНомер) Тогда
Продолжить;
КонецЕсли;
ЗаписьРегистра = НаборРегистра.Добавить();
ЗаписьРегистра.ВладелецТелефона = ВыборкаДетальная.ВладелецТелефона;
ЗаписьРегистра.ИнвертированныйНомер = ИнвертированныйНомер;
КонтрольУникальности.Вставить(ИнвертированныйНомер, Истина);
КонецЦикла;
КонецЦикла;
НаборРегистра.Записать();
КонецПроцедуры
//Подписка на событие при записи Контрагента, Партнера, Контактного лица
Процедура КешироватьТелефоныПриЗаписи(Источник, Отказ) Экспорт
Если Отказ Тогда
Возврат;
КонецЕсли;
Если ТипЗНЧ(Источник) = Тип("СправочникОбъект.Контрагенты") Тогда
Телефоны = Источник.КонтактнаяИнформация;
Контрагент = Источник.Ссылка;
ИначеЕсли ТипЗНЧ(Источник) = Тип("СправочникОбъект.Партнеры")
ИЛИ ТипЗНЧ(Источник) = Тип("СправочникОбъект.КонтактныеЛицаПартнеров") Тогда
Телефоны = Телефоны(Источник.Ссылка);
Контрагент = ?( Телефоны.Количество() > 0, Телефоны[0].Ссылка, Неопределено );
Иначе
Возврат;
КонецЕсли;
Для каждого Телефон Из Телефоны Цикл
Если ПустаяСтрока(Телефон.НомерТелефона) Тогда
Продолжить;
КонецЕсли;
ЗаписьРегистра = РегистрыСведений.МОЙ_ПоискТелефонов.СоздатьМенеджерЗаписи();
ЗаписьРегистра.ВладелецТелефона = Контрагент;
ЗаписьРегистра.ИнвертированныйНомер = ИнвертированныйНомерТелефона(Телефон.Представление);
ЗаписьРегистра.Записать();
КонецЦикла;
КонецПроцедуры
Функция Телефоны(ВладелецТелефона)
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ РАЗРЕШЕННЫЕ
| ПартнерыКонтактнаяИнформация.Представление КАК Представление,
| Контрагенты.Ссылка КАК Ссылка,
| ПартнерыКонтактнаяИнформация.НомерТелефона КАК НомерТелефона
|ИЗ
| Справочник.Партнеры.КонтактнаяИнформация КАК ПартнерыКонтактнаяИнформация
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
| ПО ПартнерыКонтактнаяИнформация.Ссылка = Контрагенты.Партнер
| И (ПартнерыКонтактнаяИнформация.Ссылка = &ВладелецТелефона)
| И (НЕ ПартнерыКонтактнаяИнформация.Ссылка.ПометкаУдаления)
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ЛицаКонтактнаяИнформация.Представление,
| Контрагенты.Ссылка,
| ЛицаКонтактнаяИнформация.НомерТелефона
|ИЗ
| Справочник.КонтактныеЛицаПартнеров.КонтактнаяИнформация КАК ЛицаКонтактнаяИнформация
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
| ПО ЛицаКонтактнаяИнформация.Ссылка.Владелец = Контрагенты.Партнер
| И (ЛицаКонтактнаяИнформация.Ссылка = &ВладелецТелефона)
| И (НЕ ЛицаКонтактнаяИнформация.Ссылка.ПометкаУдаления)";
Запрос.УстановитьПараметр("ВладелецТелефона", ВладелецТелефона);
РезультатЗапроса = Запрос.Выполнить();
Возврат РезультатЗапроса.Выгрузить();
КонецФункции
R03;
//функция общего модуля
&НаСервере
Функция ИнвертированныйНомерТелефона(Знач НомерТелефона) Экспорт
НомерТелефона = СокрЛП( НомерТелефона );
ДлинаНомера = СтрДлина( НомерТелефона );
Результат = "";
Если ДлинаНомера = 0 Тогда
Возврат "";
КонецЕсли;
Для Счетчик = 1 По ДлинаНомера Цикл
Цифра = Сред(НомерТелефона, Счетчик, 1);
Если Цифра >= "0" И Цифра <= "9" Тогда
Результат = Цифра + Результат;
КонецЕсли;
КонецЦикла;
Возврат Результат;
КонецФункции
//Начальное заполнение вспомогательной таблицы "инвертированных" номеров телефонов:
&НаСервере
Процедура КешироватьНомера() Экспорт
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ
| КонтрагентыКонтактнаяИнформация.Представление КАК НомерТелефона,
| КонтрагентыКонтактнаяИнформация.Ссылка КАК ВладелецТелефона
|ИЗ
| Справочник.Контрагенты.КонтактнаяИнформация КАК КонтрагентыКонтактнаяИнформация
|ГДЕ
| КонтрагентыКонтактнаяИнформация.Ссылка.Партнер.Ссылка ЕСТЬ НЕ NULL
| И КонтрагентыКонтактнаяИнформация.НомерТелефона <> """"
| И НЕ КонтрагентыКонтактнаяИнформация.Ссылка.ПометкаУдаления
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ПартнерыКонтактнаяИнформация.Представление,
| Контрагенты.Ссылка
|ИЗ
| Справочник.Партнеры.КонтактнаяИнформация КАК ПартнерыКонтактнаяИнформация
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
| ПО ПартнерыКонтактнаяИнформация.Ссылка = Контрагенты.Партнер
| И (ПартнерыКонтактнаяИнформация.НомерТелефона <> """")
| И (НЕ ПартнерыКонтактнаяИнформация.Ссылка.ПометкаУдаления)
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ЛицаКонтактнаяИнформация.Представление,
| Контрагенты.Ссылка
|ИЗ
| Справочник.КонтактныеЛицаПартнеров.КонтактнаяИнформация КАК ЛицаКонтактнаяИнформация
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
| ПО ЛицаКонтактнаяИнформация.Ссылка.Владелец = Контрагенты.Партнер
| И (ЛицаКонтактнаяИнформация.НомерТелефона <> """")
| И (НЕ ЛицаКонтактнаяИнформация.Ссылка.ПометкаУдаления)
|ИТОГИ ПО
| ВладелецТелефона";
РезультатЗапроса = Запрос.Выполнить();
ВыборкаГрупп = РезультатЗапроса.Выбрать( ОбходРезультатаЗапроса.ПоГруппировкам );
НаборРегистра = РегистрыСведений.МОЙ_ПоискТелефонов.СоздатьНаборЗаписей();
НаборРегистра.Очистить();
Пока ВыборкаГрупп.Следующий() Цикл
КонтрольУникальности = Новый Соответствие;
ВыборкаДетальная = ВыборкаГрупп.Выбрать( ОбходРезультатаЗапроса.Прямой );
Пока ВыборкаДетальная.Следующий() Цикл
ИнвертированныйНомер = ИнвертированныйНомерТелефона( ВыборкаДетальная.НомерТелефона );
Если КонтрольУникальности[ИнвертированныйНомер] = Истина
ИЛИ ПустаяСтрока(ИнвертированныйНомер) Тогда
Продолжить;
КонецЕсли;
ЗаписьРегистра = НаборРегистра.Добавить();
ЗаписьРегистра.ВладелецТелефона = ВыборкаДетальная.ВладелецТелефона;
ЗаписьРегистра.ИнвертированныйНомер = ИнвертированныйНомер;
КонтрольУникальности.Вставить(ИнвертированныйНомер, Истина);
КонецЦикла;
КонецЦикла;
НаборРегистра.Записать();
КонецПроцедуры
//Подписка на событие при записи Контрагента, Партнера, Контактного лица
Процедура КешироватьТелефоныПриЗаписи(Источник, Отказ) Экспорт
Если Отказ Тогда
Возврат;
КонецЕсли;
Если ТипЗНЧ(Источник) = Тип("СправочникОбъект.Контрагенты") Тогда
Телефоны = Источник.КонтактнаяИнформация;
Контрагент = Источник.Ссылка;
ИначеЕсли ТипЗНЧ(Источник) = Тип("СправочникОбъект.Партнеры")
ИЛИ ТипЗНЧ(Источник) = Тип("СправочникОбъект.КонтактныеЛицаПартнеров") Тогда
Телефоны = Телефоны(Источник.Ссылка);
Контрагент = ?( Телефоны.Количество() > 0, Телефоны[0].Ссылка, Неопределено );
Иначе
Возврат;
КонецЕсли;
Для каждого Телефон Из Телефоны Цикл
Если ПустаяСтрока(Телефон.НомерТелефона) Тогда
Продолжить;
КонецЕсли;
ЗаписьРегистра = РегистрыСведений.МОЙ_ПоискТелефонов.СоздатьМенеджерЗаписи();
ЗаписьРегистра.ВладелецТелефона = Контрагент;
ЗаписьРегистра.ИнвертированныйНомер = ИнвертированныйНомерТелефона(Телефон.Представление);
ЗаписьРегистра.Записать();
КонецЦикла;
КонецПроцедуры
Функция Телефоны(ВладелецТелефона)
Запрос = Новый Запрос;
Запрос.Текст =
"ВЫБРАТЬ РАЗРЕШЕННЫЕ
| ПартнерыКонтактнаяИнформация.Представление КАК Представление,
| Контрагенты.Ссылка КАК Ссылка,
| ПартнерыКонтактнаяИнформация.НомерТелефона КАК НомерТелефона
|ИЗ
| Справочник.Партнеры.КонтактнаяИнформация КАК ПартнерыКонтактнаяИнформация
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
| ПО ПартнерыКонтактнаяИнформация.Ссылка = Контрагенты.Партнер
| И (ПартнерыКонтактнаяИнформация.Ссылка = &ВладелецТелефона)
| И (НЕ ПартнерыКонтактнаяИнформация.Ссылка.ПометкаУдаления)
|
|ОБЪЕДИНИТЬ ВСЕ
|
|ВЫБРАТЬ
| ЛицаКонтактнаяИнформация.Представление,
| Контрагенты.Ссылка,
| ЛицаКонтактнаяИнформация.НомерТелефона
|ИЗ
| Справочник.КонтактныеЛицаПартнеров.КонтактнаяИнформация КАК ЛицаКонтактнаяИнформация
| ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Контрагенты КАК Контрагенты
| ПО ЛицаКонтактнаяИнформация.Ссылка.Владелец = Контрагенты.Партнер
| И (ЛицаКонтактнаяИнформация.Ссылка = &ВладелецТелефона)
| И (НЕ ЛицаКонтактнаяИнформация.Ссылка.ПометкаУдаления)";
Запрос.УстановитьПараметр("ВладелецТелефона", ВладелецТелефона);
РезультатЗапроса = Запрос.Выполнить();
Возврат РезультатЗапроса.Выгрузить();
КонецФункции
R03;
приложена фотография разрешительной переписки.