Хочу поделиться опытом Авито о том, как мы переводили всю инфраструктуру 1С на Linux и PostgreSQL. История, о которой я буду рассказывать, закончилась успешно, и это уже проверено временем.

Немного о себе. С 2011 года я занимаюсь автоматизацией на базе 1С, в основном крупного бизнеса. 5 лет работал в консалтинге директором практики, а с 2021 года развиваю проектный офис и продуктовое управление в Авито.
Имею сертификаты PMP, ITIL 4, Google PM и другие. Стараюсь идти в ногу со временем, чтобы понимать, о чем в целом в мире на тему нашей экспертизы разговаривают.
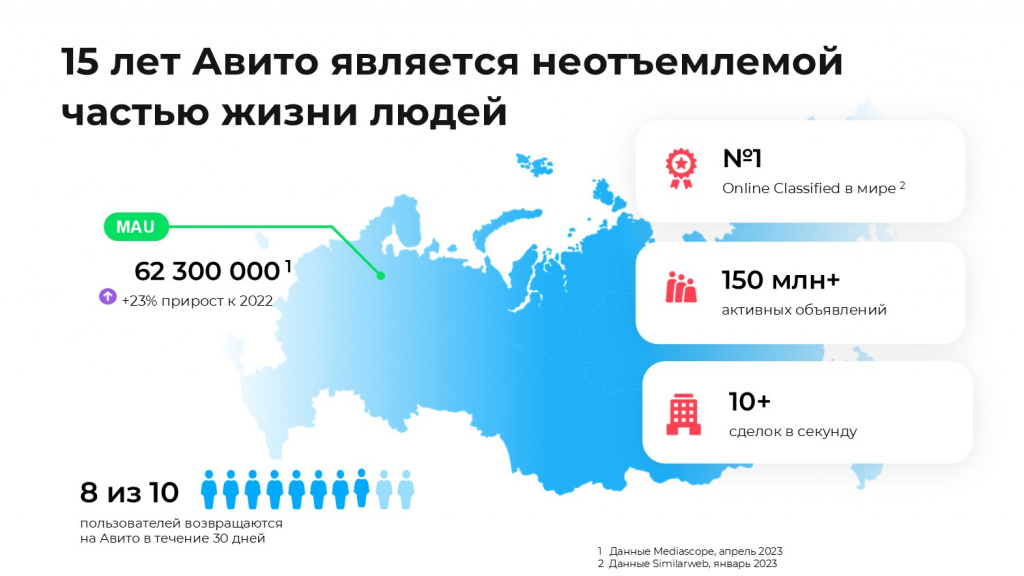
Не буду долго останавливаться на том, что такое “Авито”, потому что статистически большинство россиян были или байерами, или селлерами на нашей площадке. Этот слайд здесь для того, чтобы показать: мы в Авито верим, что делаем реально крутой продукт для наших пользователей – для нас это не пустое слово.
А для того, чтобы продукт был крутым, нужно, чтобы подводная часть айсберга, частью которого является 1С, тоже была восхитительной. Это как раз и было в зоне ответственности нашего проекта по переходу 1С на PostgreSQL и Linux – сделать так, чтобы фундамент работал безупречно.
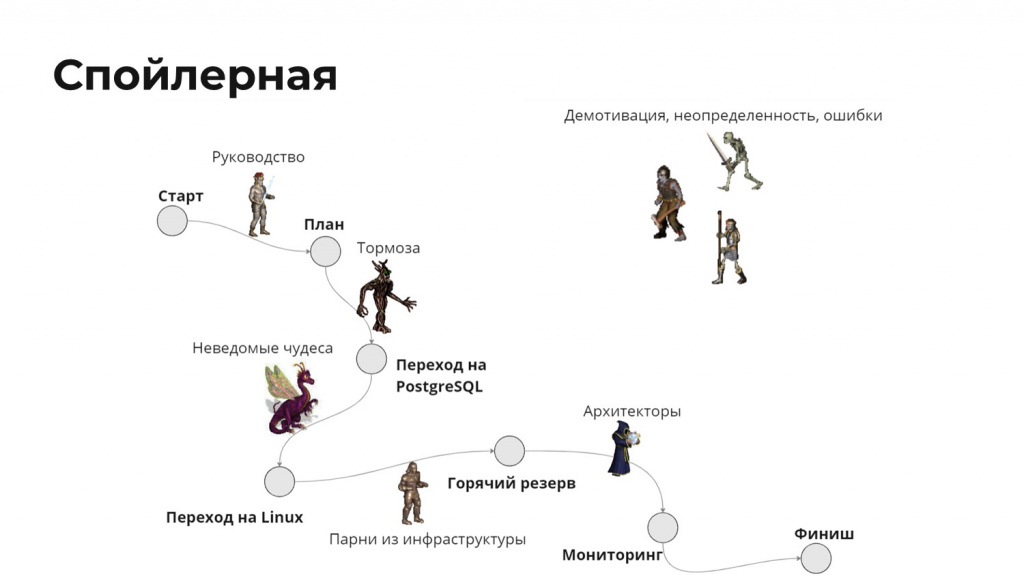
Я расскажу про то, как шел этот проект, из каких этапов он состоял, подсвечу важные вехи. Но самым ценным, как мне кажется, будет то, что я расскажу про «черных лебедей», с которыми мы столкнулись:
-
это и руководство, которое нас челленджило;
-
и тормоза, которые возникли с переходом на PostgreSQL;
-
и демотивации;
-
и неопределенности;
-
и «очень ответственные архитекторы».
Все это у нас было, и я об этом буду рассказывать.
Веха №0. Перед стартом. Мы помним, как все начиналось
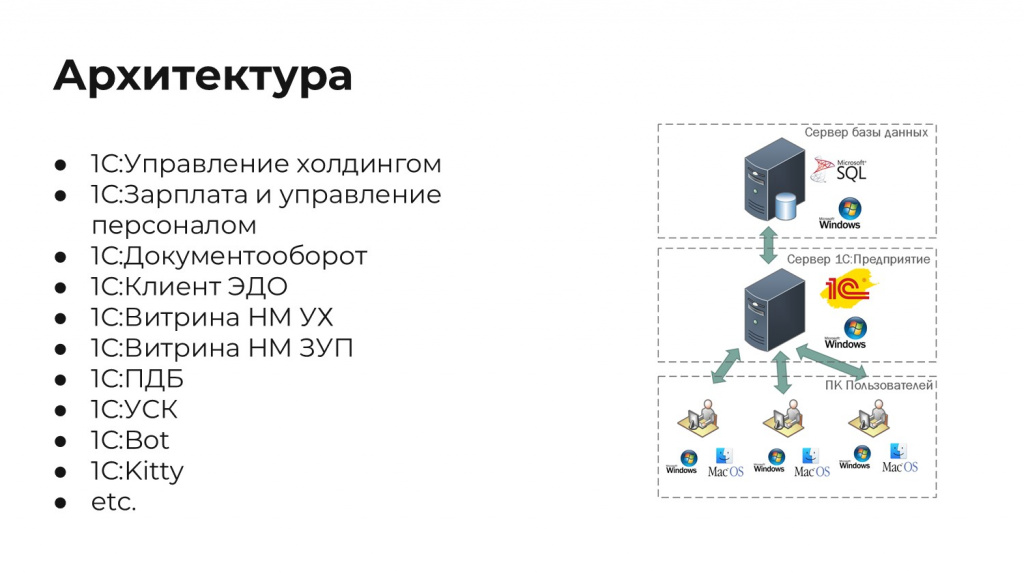
Расскажу, с чего мы начали. Поскольку я не настоящий сварщик и все-таки выступаю в секции управления, на слайде примитивная схема:
-
В начале проекта на сервере баз данных мы использовали СУБД MS SQL под Windows.
-
Сервер приложений 1С тоже работал под управлением ОС Windows.
-
На сервере было развернуто 15 1С-ных инстансов:
-
Центральная и самая большая база у нас – это 1С:Управление холдингом, выполняющая функции ERP-системы. Так как у нас операционная компания и материальных потоков нет, ERP как таковая нам не нужна.
-
Конечно, 1С:ЗУП.
-
1С:Документооборот как BPM-система, через которую проходит достаточно много процессов.
-
Отдельно 1С:Клиент ЭДО – у нас много электронных документов,
-
И две витрины налогового мониторинга – бухгалтерии так понравилось, что они вторую заказали.
-
В общем, у нас было много всего на 1С, и все это работало под управлением Windows.

В цифрах:
-
У нас примерно 180 тысяч реализаций в месяц, и специфика такова, что мы эти реализации отражаем в течение 6 часов. У нас есть очень короткий диапазон, когда мы можем загрузить эти данные из биллинга и провести в учете.
-
Много договоров с клиентами, потому что у нас больше 1 миллиона клиентов.
-
2.5 миллиона проводок.
-
У нас очень короткий период закрытия. Во времена, когда мы принадлежали западному холдингу, от нас требовали, чтобы мы 2 числа уже сформировали отчетность за предыдущий месяц. Это тоже накладывает определенные ограничения на то, что мы будем делать в рамках проекта.

Предпосылки:
-
Первая предпосылка кажется совершенно очевидной – западные вендоры помахали нам рукой. Компании IBM, Slack, Nintex (движок SharePoint) реально ушли от нас, и мы почувствовали это на себе.
-
Еще одной немаловажной предпосылкой было то, что в Авито уже давно большая продуктовая линейка – тысячи серверов в нескольких дата-центрах – работает под управлением Linux и PostgreSQL. А поскольку мы являемся частью технического департамента, от нас ожидали, что мы выровняем ситуацию и тоже будем работать под общими политиками управления ИТ.
Веха №1. План. Как спланировать, если ничего не понятно
Я искренне верю, что планирование очень важно, потому что план, сделанный не для проформы – это отличная путеводная звезда.

План начинается с цели. Но если мы определяем цель, как «Нам нужно перейти на Linux и PostgreSQL. Поехали!»…

… то с такой целью мы не доедем.

Надо понимать, что цель – это outcome, за который спонсор (или заказчик проекта) платит деньги.
Переход на Linux и PostgreSQL сам по себе не нужен – нужно обеспечить отказоустойчивость архитектуры бэк-офисных систем, которые представлены продуктами 1С. А то, каким образом мы будем идти к этой цели – это уже конкретные задачи:
-
Перевод продовых инстансов 1С на Linux и PostgreSQL.
-
Создание отказоустойчивого кластера уровня «горячей резерв» с uptime 99.5%.
-
Мониторинг, потому что от наших систем требуется быстрое закрытие, и пользователи работают практически 24/7. Это тоже важно.
Такие задачи мы определили и пошли в планирование.
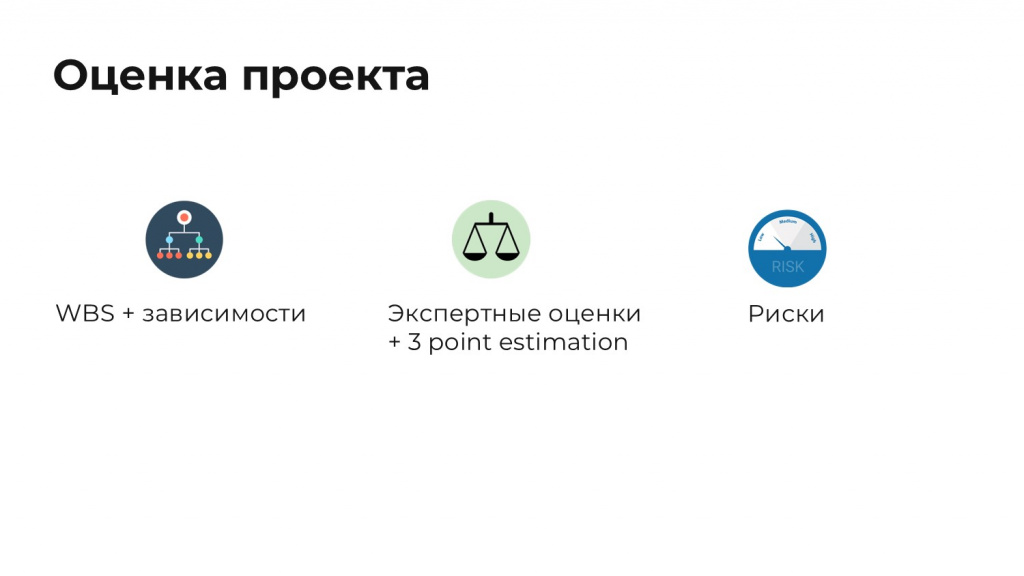
Нам нужно было оценить проект.
Проще всего оценить проект сравнительным методом, зная стоимость проекта на маленьких, на больших, на одной базе, на 10 базах. Но мы таких проектов сами ранее не делали и оценить сравнительным методом не могли. Более того, в целом, на тот момент, когда мы начинали переход, практики на рынке было не очень много – даже посоветоваться было не с кем.
Поэтому мы построили:
-
WBS – иерархическую структуру работ;
-
по каждой задаче дали экспертные оценки;
-
добавили риски.
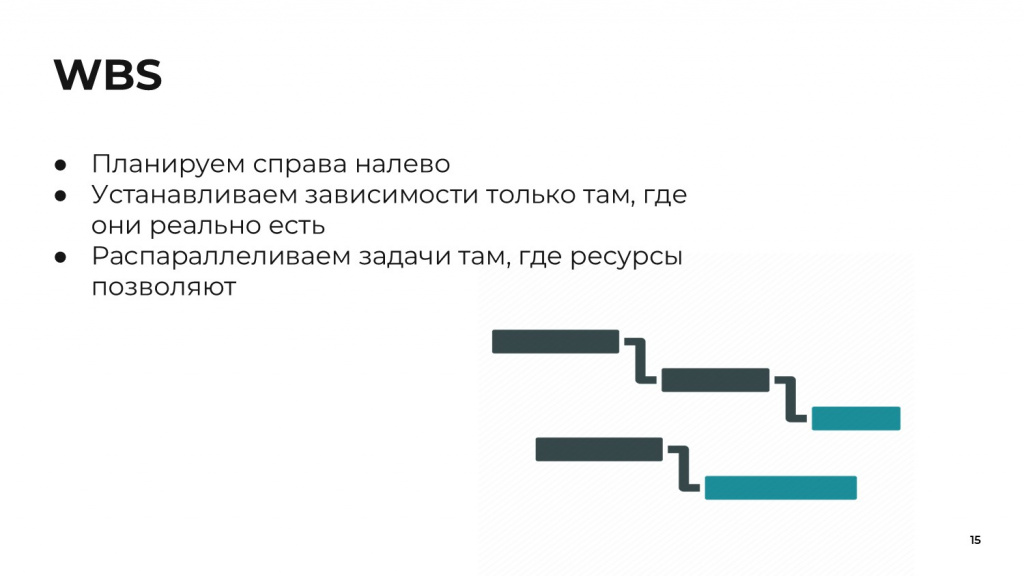
Немного скажу про методику составления документа иерархической структуры работ WBS. Казалось бы, это банально, но ей почему-то редко уделяют должное внимание на этапе планирования.
-
Во-первых, в условиях высокой неопределенности я рекомендую проводить планирование справа налево. В утрированном и примитивном виде это может выглядеть так:
-
Для перехода на PostgreSQL нам нужно запустить продовые базы на PostgreSQL.
-
А для этого их нужно протестировать в новой инфраструктуре.
-
А для этого нужно отрефакторить конфигурации.
-
А для этого нужно настроить серверы.
-
А для этого нужно серверы привезти в дата-центр и воткнуть в стойки.
-
-
На этом этапе я очень рекомендую устанавливать зависимости только там, где они действительно есть логически. Например:
-
Очевидно, что есть связь между привозом серверов в дата-центр и втыканием их в стойки – раньше не получится воткнуть.
-
Но нет логической связи между переводом Управления холдингом и ЗУП. Управление холдингом – страшно, ЗУП – тоже страшно, но меньше. Это не связь. Я рекомендую здесь не устанавливать зависимость.
-
-
Я рекомендую устанавливать зависимости только там, где мы действительно никак не проходим по ресурсу. Сначала распланировать ресурсы, и если их не хватает, проставить ресурсные зависимости – ЗУП после УХ, потому что сразу не сможем… или сможем, не знаю.

Оценка. Обычно в комьюнити есть недоверие к экспертным оценкам. Но если у вас есть эксперт на проекте, метод «ленинского прищура» (так экспертную оценку называют коллеги из «Стартоплана») – это нормально.
Есть еще один инструмент, который я очень рекомендую – это оценка по трем точкам, когда мы даем:
-
оптимистичную оценку (O);
-
пессимистичную оценку (P);
-
и реалистичную, most likely оценку (M)
Как один из методов, я рекомендую most likely оценку брать четыре раза, потому что мы находимся в мире нормального распределения, и эта оценка больше похожа на правду.
Надо понимать, что для «популярной» оценки небольшой задачи со значениями O=2, M=4, P=8, такой способ расчета отличается от среднего значения на 7,5%. Для годового проекта – это месяц, что прилично.
Про риски я сейчас не сказал, об этом подробнее расскажу позже.
Веха №2 Переход на PG. Как не провалить все в самом начале
Когда мы подготовили план и все оценили, начался первый этап – мы приступили к переходу на PostgreSQL.

Кто был в нашей команде? Кого мы взяли с собой на борт?
-
DevOps-инженеры;
-
администраторы;
-
разработчики – причем в основной команде у нас было два разработчика, а на рефакторинг мы привлекали разработчиков из продуктовых команд;
-
аналитики;
-
бесценный руководитель проекта в моем лице.
Всего в команде было 7 человек на постоянной основе.
На слайде не указано, но важно и честно будет сказать, что неоценимую экспертную помощь нам оказали коллеги из «ИнфоСофт». Им респект и уважуха. Без них нам было бы гораздо тяжелее.

Переход на PostgreSQL состоял из трех этапов:
-
Мы выбрали решение для дальнейшей работы.
-
Протестировали, отрефакторили и соптимизировали код под него.
-
Потом на проде мы посмотрели, что получилось.
Ключевым риском этого этапа и в целом всего перехода на PostgreSQL для нас стала деградация производительности. Учитывая, что у нас быстрое закрытие и большой объем данных, это могло бы быть критично.
Именно на базе работы с этим риском мы и построили план всего проекта. Определили ключевые операции, которые не должны проявить деградацию, и решили, что тестирование и рефакторинг построим вокруг них.

Здесь прилетел первый «черный лебедь»:
-
Команды запланировали более 400 тест-кейсов по ключевым операциям. Мы поняли, что их придется писать очень долго. О том, что мы с этим сделали, я скажу позже.
-
Вторая часть этого «черного лебедя» была в том, что тормоза проявились в громадном легаси – у нас начал тормозить громадный встроенный блок отражения выручки, те самые 180 тысяч реализаций. Это было ожидаемо, но на этапе планирования мы не хотели об этом думать. Пришлось покопаться, раскрыть бизнес-логику, которую писали 7 лет. Это определенным образом сказалось.
-
И еще, конечно, определенную сложность создавало то, что у нас «бесконечный» период закрытия. Это значит, что для сдачи отчетности 2-го числа нужно весь месяц что-то делать: вовремя считать зарплату, сразу отражать расходы и так далее. А переход через dt большой конфигурации, такой как «Управление холдингом», занимал достаточно много времени – у нас технологическое окно было почти 20 часов. Это тоже стало «черным лебедем». Мы об этом не думали, но жизнь заставила нас об этом подумать. Пришлось потом согласовывать технологические окна.

Итоги этого этапа:
-
Выбор решения сводился к тому, чтобы выбирать «ванильный» PostgreSQL или решение Postgres Pro. Первый вариант рассматривался с учетом того, что в Авито все работает под управлением «ванильного» PostgreSQL и есть свои DBA, которые умеют пилить и готовить это. Но мы все-таки выбрали Postgres Pro, потому что денег у нас было чуть больше, чем времени. Мы решили лучше купить опыт и пойти по проторенной дорожке, чем набивать шишки в конфигурировании DBA-шниками самостоятельно.
-
Мы почелленджили и уменьшили количество ключевых операций в 3 раза – с 400 до 144. Мы строго смотрели на тимлидов продуктовых команд и спрашивали: «Это действительно ключевая операция?» Так из 400 мы сделали 144. Надо сказать, что только 28 из 144 операций показали деградацию производительности. И 28 мы рефакторили.
-
И потом, когда мы на проде перевели все базы на PostgreSQL, из тех 400 критических операций, которые мы почелленджили, всего лишь 8 кейсов начали тормозить. Но к каждой из них за пару часов можно было либо найти какой-то воркэраунд (обходной путь), либо нормально отрефакторить. Бизнес при этом не пострадал – определенные неудобства были, но не смертельно. Подход с тем, чтобы оставить только самое важное и поговорить про цену и качество, себя оправдал.
Веха №3. Переход на Linux. Партия сказала: надо!
Таким образом у нас прошла осень – таймлайн того, как мы переходили, я потом отдельно покажу. Мы подошли к Linux.
Здравый смысл, коллеги из «ИнфоСофт» и в целом комьюнити рекомендовали не спешить, потому что реальной сильной причины спешить не было, а вендор дотягивает платформу под работу на Linux. Но партия сказала: «Надо!», мы ответили: «Есть!»

Главный «черный лебедь», который у нас проявился на этом этапе, заключается в том, что одним из первых быть трудно:
-
Очень сложно погуглить ответы на вопросы.
-
Ты просто не знаешь вопросы, на которые нужно гуглить ответы – это создает еще большую проблему, потому что ты набиваешь себе шишки.
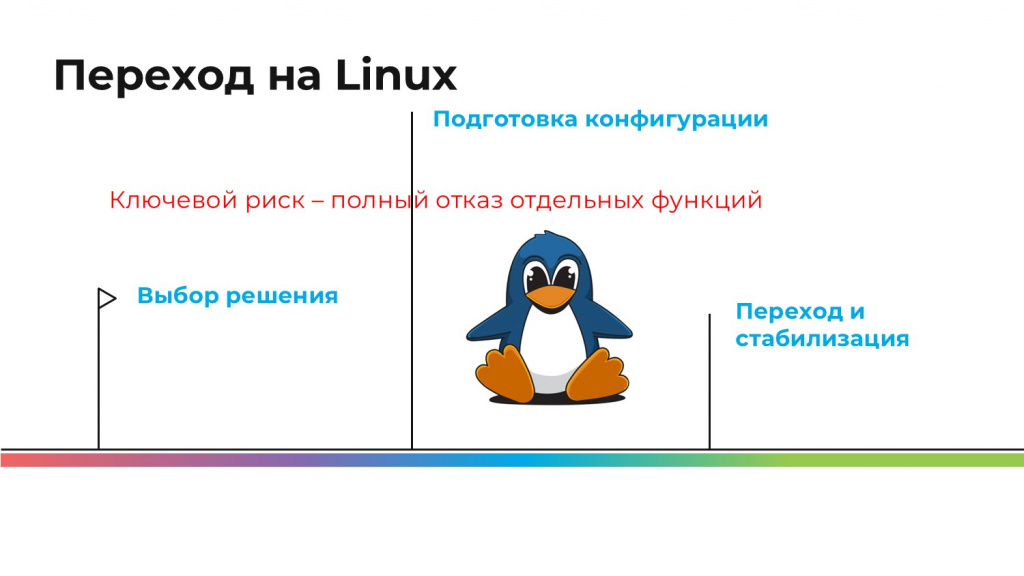
У перехода на Linux было три этапа – на самом деле, намного больше, но для презентации я немного примитивизирую.
-
Мы выбирали, какой конкретно Linux мы выберем.
-
Мы готовили конфигурацию.
-
Затем был переход и стабилизация.
Ключевым риском перехода на Linux стал полный отказ отдельных функций:
-
Мы обсудили, отказом от каких возможностей нам грозит переход на Linux: сюда можно отнести криптографию, интеграцию через COM, регулярные выражения и прочее.
-
Проанализировали конфигурацию на предмет наличия таких паттернов.
-
И переработали их.

Какие «черные лебеди» были здесь?
Я до этого не акцентировал ваше внимание, но у нас бОльшая часть компании работает на MacOS, и для работы с 1С у них использовалась доменная авторизация и аутентификация SSO – отказ от нее с переходом на Basic-авторизацию стал бы очень серьезным ударом по User Experience.
Мы попытались настроить SSO стандартными средствами 1С через Apache и Kerberos, и в какой-то момент нам даже показалось, что настроили, но вмешалась магия. В какой-то момент мы уже на проде перешли на доменную авторизацию, перекатили наши базы, подменялся токен, и пользователи аутентифицировались не под собой. Например, в 1С заходил Иван Иванов, а пользователь подменялся на «Петр Петров». У нас даже пользователи успели насоздавать документы на проде в таком состоянии, но потом пришлось все откатить.
Мы совсем не предполагали, что это будет для нас проблемой. Но это стало проблемой. И то, что мы не подумали об этом своевременно, затормозило нас в переходе на Linux на месяц или даже на полтора.
Итоговое решение было таким:
-
Для пользователей, которые работают с десктопных приложений, не через браузер, мы в итоге смогли поднять стандартный коробочный способ аутентификации,
-
А для пользователей, которые работают через браузер, мы внедрили решение KeyCloak. Это решение, которое и так уже используется как проксирующий сервис аутентификации для некоторых других внутренних сервисов в Авито. Сервис нормально себя зарекомендовал, прекрасно работает.
Вторая проблема была в том, что поскольку компьютеры на MacOS не находятся в домене, нам было неудобно распространять для них список баз данных. К тому же в процессе перехода серверов на Linux – пока мы переходили и откатывались – путь к базам несколько раз менялся, и это начало создавать бешеную фрустрацию у пользователей MacOS – в очередной раз поменять имена серверов для них было сложно, и всё начинало «искрить».
Тогда мы приняли решение максимально перевести маководов на работу через браузер. За два часа нарисовали такой примитивный лендинг (на слайде). Сказали им: «Ребят, вот вам лендинг с кнопочками, отсюда откроется нужная вам база. Не надо, пожалуйста, через 1С никуда ходить».
Кроме этого, в Документообороте и Управлении холдингом у нас много процессов согласования, которые работают через почту, и при смене имени сервера автоматические ссылки для перехода в базу из письма «Нажми, чтобы согласовать» стали неактуальными. Поэтому после внедрения этого лендинга мы еще приняли решение дать всем базам проксирующие имена, чтобы они были не по имени сервера, а по имени базы. Опубликовали все это в интернете, и с тех пор мы не боимся смены сервера в кластере.

Вторая проблема, которая возникла:
-
Мы не вовлекли должным образом продуктовые команды – не объяснили им, зачем этот проект. А поскольку у них были свои планы по внедрению своих продуктовых проектов, они с разной степенью деликатности сказали нам, где видели наш переход на Linux.
-
Этот конфликт определенным образом демотивировал и продуктовые команды, и нас, и с ним пришлось работать – искать разные подходы к разным командам. Где-то мы сами подключались на тестирование, где-то с командами проговаривали. Но это то, о чем мы не подумали, и это выстрелило.
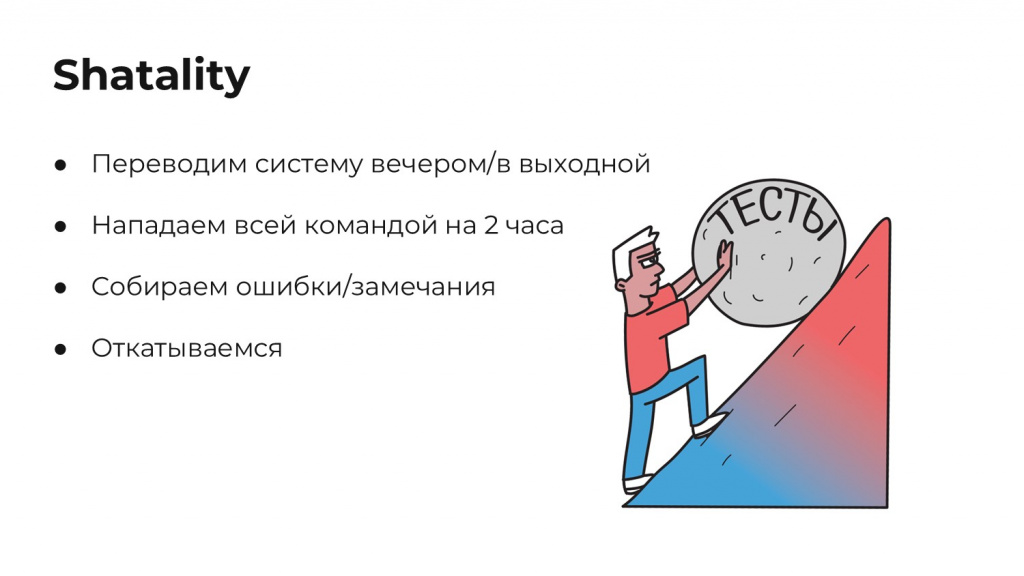
И здесь я хочу поделиться историей, которая нам помогла продвинуться.
-
В Авито есть такой термин – shatality (шаталити). Это продовое испытание стабильности сервисов, когда мы отключаем каналы связи, намеренно перегружаем какие-то продовые сервисы, даем высокую нагрузку.
-
Мы переводили на Linux все наши продовые инстансы 1С на проде вечером или в выходной, и на два часа нападали туда всей нашей командой автоматизации – смотрели, что получится.
-
При обнаружении ошибок – откатывались
Потому что стейдж не повторяет прод никогда – сетевая связанность, настройки, компоненты никогда не идентичны. И только шатание на проде реально позволило нам перейти на Linux и не иметь ошибок.
Что может быть лучше тестирования на проде, правда ведь?
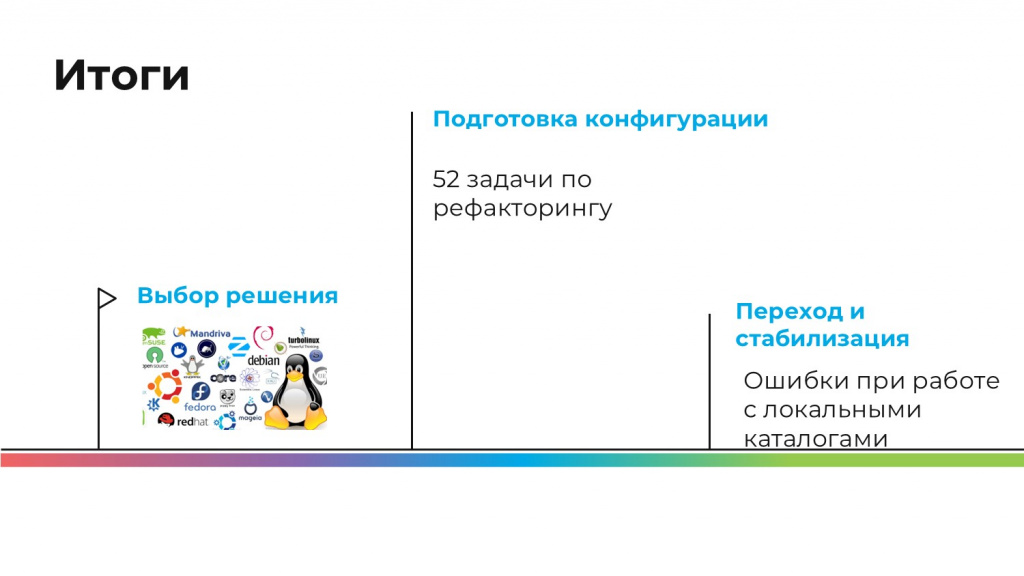
Итоги перехода на Linux:
-
Сборок Linux намного больше, чем выбор в PostgreSQL. На самом деле мы выбирали между Debian и Ubuntu. Ubuntu, потому что она рекомендуется 1С, а Debian, потому что это наш корпоративный шаблон. В итоге мы пошли в Debian, никаких проблем из-за этого не испытали. Просто нам так проще следовать корпоративной IT-политике.
-
У нас всего было 52 задачи по рефакторингу, и мы успешно с ними справились.
-
На проде мы совершенно очевидно знали, что у нас будут проблемы с локальными файлами. Мы знали об этом заранее лучше, чем о всем другом. И, конечно, на проде именно это выстрелило, потому что мы думали о более сложных вещах, а об этом не думали.

Здесь тоже у нас был «черный лебедь» – поскольку мы работаем в техническом департаменте, где люди знают, как идеально готовить Linux, руководство стало нас челленджить: «Доколе? Когда уже все будет?»
В этой ситуации я могу порекомендовать следующее:
-
Не отвечайте сразу, потому что когда вы в пылу проекта, сразу хочется ответить что-то обидное – надо выдохнуть и подождать.
-
Проведите сжатие расписания – вполне возможно, что его можно сжать, особенно когда проект уже идет: неопределенность снизилась и по ресурсам, может быть, уже произошли какие-то изменения.
-
Рекомендую работать с критическим путем, потому что не всегда самая длинная задача – это задача на критическом пути. Я не знаю других способов, кроме как использовать для этого MS Project. Знаю, что в учебниках по проектному управлению учат отрисовывать критический путь вручную, но это, конечно, издевательство. Я использую для этого MS Project.
-
Когда расписание уже сжато, покажите прозрачность. Руководство же переживает не из-за того, что переход долгий, а из-за того, что сомневается в продуманности ваших действий. Если им показать: «Я знаю, что делать, и это можно сделать только за такое время», это повышает уровень доверия.
-
И, конечно, важно обеспечить инкрементальность – выкатывать пользу в виде инкрементов как можно раньше. Это про применение Scrum, Agile и других гибких методик.

Про проектный подход.
Когда нас немного почелленджили по срокам, мы поменяли проектный подход.
-
На этапе планирования мы использовали предиктивный подход, который еще называют «Водопад», чтобы смотреть максимально вперед. Не потому, что мы такие закостенелые, а потому, что неопределенность была высокая, и мы не могли распылять усилия.
-
Переход на Postgres и на Linux мы делали скорее инкрементально – брали одну базу, переводили ее, а потом уделяли внимание другой.
-
А мониторинг и горячее резервирование мы делали уже итеративно – каждый раз улучшая результат того, что мы сейчас имеем.
Веха №4. Горячий резерв. Цель оправдывает средства

Расскажу про этапы создания горячего резерва:
-
Мы выбирали, как мы будем резервировать.
-
У нас ключевые базы резервируются на уровне кластера, который разнесен по двум дата-центрам.
-
А небольшие базы резервируются средствами виртуализации. Это не совсем горячий резерв, но это позволяет нам иметь отказоустойчивую архитектуру – когда виртуалка упала в одном дата-центре, она поднялась в другом.
-
-
Мы настраивали горячий резерв:
-
для базы данных;
-
для application-сервера;
-
для сервера лицензирования.
-
-
И потом уже настраивали автоматическое переключение. Здесь мы уже шли через итеративный подход – сначала мы просто настроили репликацию базы данных так, чтобы в случае аварии человек бы ее переключал. Или сначала настроили какую-то примитивную отказоустойчивость для application-сервера – например, для маленьких баз средствами виртуализации. А потом подумали об автоматическом переключении более серьезно.

Здесь надо рассказать про «черного лебедя», который называется неопределенность, потому что команде было сложно. Особенно когда в команде крутые эксперты, им сложно признаваться, что они чего-то не знают.
Я неопределенность делю на два типа: «У нас вообще нет никаких вариантов» и «Мы не знаем, какой вариант лучше»
-
В случае «Мы не знаем, какой вариант лучше», команде каждый раз нужно напоминать про цену качества – то или иное решение нужно рассматривать с точки зрения того, сколько ты инвестируешь денег.
-
Иногда нужно принять риски и сделать нормально.
-
Но не обязательно делать идеально всегда – здесь можно помогать, фасилитировать выбор решения через цену качества.
-
-
Если «Вообще нет вариантов», то здесь можно использовать:
-
Брейншторминг.
-
Подглядывать за тем, как решают такие задачи в похожих отраслях.
-
И здесь еще имеет смысл привлечение внешних экспертов, потому что команде экспертов сложно признаться, что они что-то не знают.
-
Стоит сказать, что на нашем проекте не было ситуации, когда у нас вообще не было вариантов. Это вообще редкий случай – обычно команды и эксперты все-таки мечутся между двумя, тремя, четырьмя вариантами.
Веха №5. Мониторинг

Мы переходим к завершающему этапу проекта – настройка мониторинга.
-
Здесь мы тоже выбирали, как будем мониторить.
-
Определяли, какие метрики и алерты будем делать.
-
Настраивали мониторинг на уровне железа серверов.
-
Настраивали мониторинг на уровне СУБД, application-сервера и сервера лицензирования.

Здесь был «черный лебедь», который называется демотивация, потому что команда на самом деле уже подустала к этому этапу. В результате все это вылилось в конфликт на тему, что мониторить и как мы будем алертить. Там были крайние точки зрения:
-
Одна точка зрения: «Давайте сделаем два самых важных алерта – сервер умер и сервер взорвался».
-
Вторая крайняя точка, особенно у ответственных архитекторов: «Давайте мы настроим 100500 алертов и они будут нам во все каналы звонить и писать».
Была немного токсичная дискуссия на эту тему.

Еще хочу сказать про мотивацию. Есть несколько способов работы с мотивацией:
Например, есть способ от Тони Роббинса: «Если ты должен сделать мониторинг, возьми и сделай».

У нас на проекте был исключительно мужской коллектив, поэтому такие способы тоже работают.
Но если говорить серьезно, кроме шуток, то здесь надо работать не с мотивацией, а с устранением демотивирующих факторов.
На этом проекте и на многих других демотивирующие факторы – это неопределенность и дедлайны.
Если у вас работают не джуны, а базово замотивированные люди; вы гигиенически платите им зарплату, которую они ожидают; задачи плюс-минус интересные; дождь им не капает на голову, когда они работают, устраняйте демотивирующие факторы – неопределенность и дедлайны – это поможет команде быть базово мотивированной.
Для этого можно:
-
фасилитировать выработку решений – то, что я говорил про неопределенность;
-
помогать с экспертами;
-
ограждать от рисков и неприятных вопросов «Доколе?»,
Это нормальная работа руководителя проекта.
Итоги этого этапа:
-
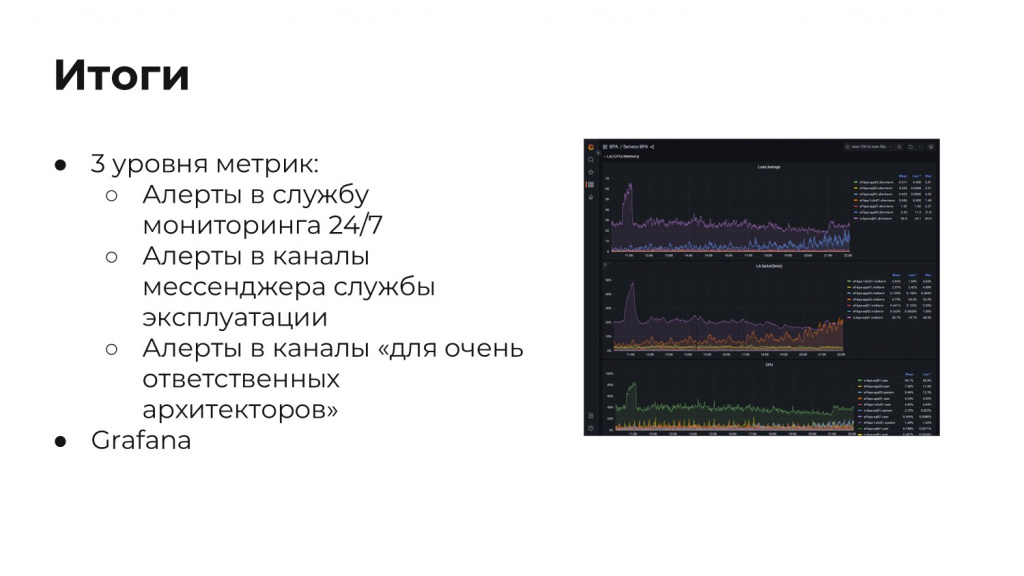
Мы настроили три уровня метрик:
-
Первый – это критические алерты в службу мониторинга 24/7. У нас есть служба, которая мониторит жизнь продукта Avito.ru. Это люди, которые с красными глазами, не моргая, смотрят в Grafana. Мы им тоже передали свои метрики, и они звонят нашим дежурным, если что-то пошло не так с 1С. Таких алертов у нас мало, по 2-3 для каждого уровня: для железа, для СУБД, для application.
-
Это алерты в каналы мессенджера для админов нашей службы эксплуатации. Это то, на что мы должны отреагировать в рабочее время. В нерабочее время они не являются критичными, а в рабочее время мы должны с этим работать.
-
И мы сделали канал «для очень ответственных архитекторов». Они могут найти любые алерты на любую тему, на которую им только хочется.
-
-
И конечно, мы настроили мониторы в Grafana для того, чтобы анализировать, что пошло не так, если что-то пошло не так.
Итоги проекта. Опыт – сын ошибок трудных
Итоги банальные:
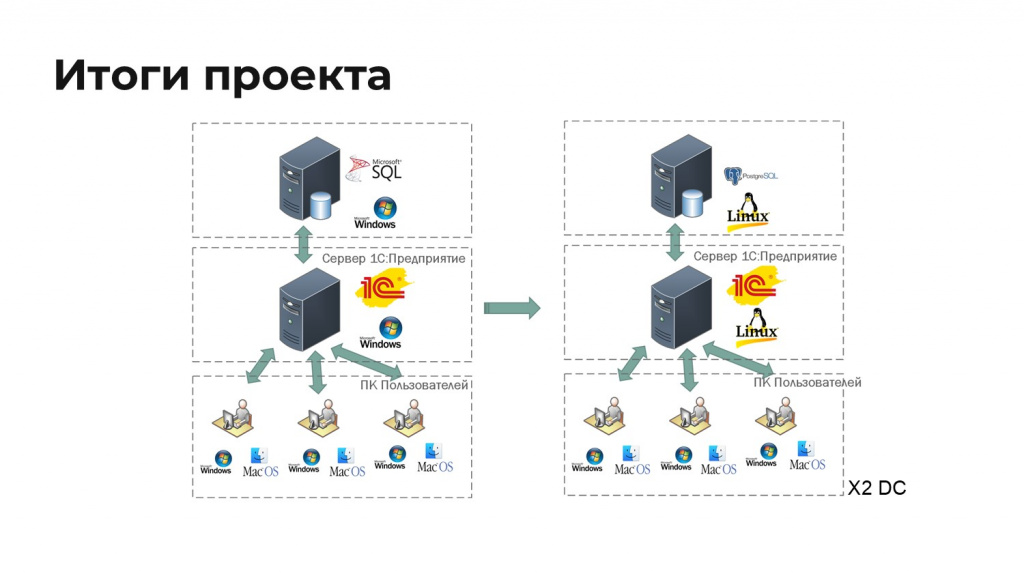
-
Мы избавились от MS SQL на уровне сервера базы данных.
-
Избавились от Windows на уровне application-сервера.
-
У нас все это теперь реплицируется в двух дата-центрах – при отключении одного дата-центра все автоматически поднимается во втором дата-центре.
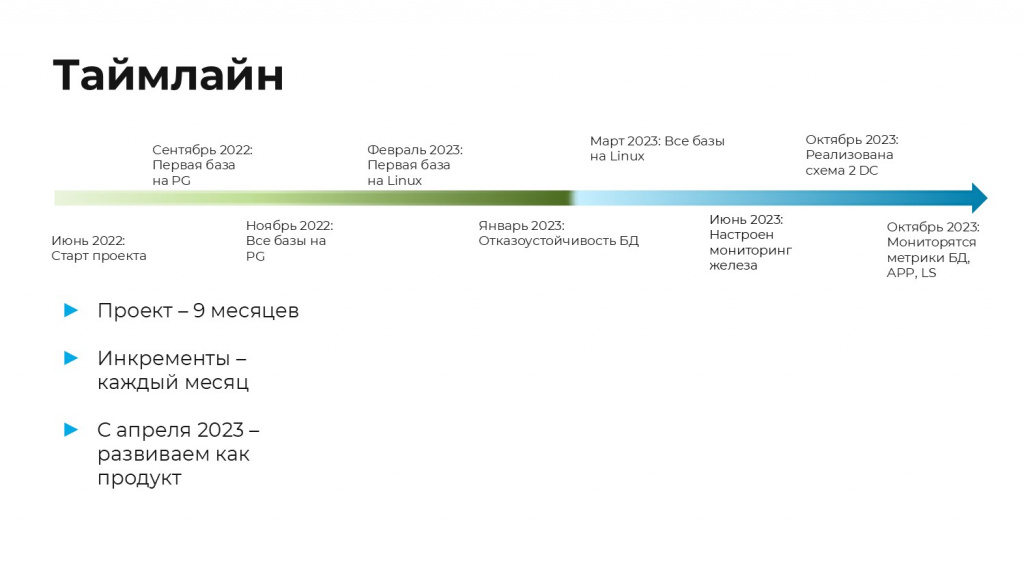
Активная фаза проекта у нас шла 9 месяцев до апреля 2023 года. Мы продолжаем заниматься этим процессом. Сейчас в рамках продуктового развития происходит докручивание, когда мы докручиваем метрики, улучшаем отказоустойчивость, проводим в шаталити, понимаем, что может пойти не так. Эта история – про бесконечное развитие.

Какими инсайтами я бы хотел поделиться?
-
Самый главный инсайт – миссия выполнима. Объективно, когда нам нужно было переходить, поджилки тряслись. Здесь, наверное, спасибо самому главному руководству, которое не дало нам путей для отступления.
-
Я лично ожидал, что потребуется тотальная переработка, потому что у нас категорически кастомизированные конфигурации. Не потребовалась.
-
Ключевой инсайт – делать акцент на рисках.

На этом проекте, как нигде, я понял, что риски стоит разделять на:
-
Риски, угрожающие проекту, из-за которых проект сломается – bus фактор, дефицит ресурсов, ошибки в планировании и так далее.
-
Риски для бизнеса – что будет, если мы своими действиями навредим бизнесу?

С этими группами риков нужно по-разному работать.
-
Обычно все помнят про mitigation-план – как нужно подстраховаться, чтобы риск не случился.
-
Но очень мало думают про contingency-план – это что мы делаем, когда риск сработал.
-
С проектными рисками нормально сказать: «Да у меня есть резервы, я запланировал дополнительное время, дополнительные деньги» или «Я со своей бесконечной харизмой пойду и договорюсь с заказчиками».
-
А с бизнесовыми рисками у вас никаких резервов не хватит покрыть, если вы сломаете выплаты клиентам или вашим поставщикам. Поэтому нужно придумывать какой-то план B, шаталити, как вы будете откатываться или что-то еще.
-
Обычно contingency-планам не уделяют должного внимания.

Ошибок на проекте было очень мало, потому что было очень талантливое управление. Но если серьезно, то:
-
Мы не вовлекли продуктовые команды – это очень сильно нас откинуло назад и затормозило.
-
Мы не смотрели в следующие этапы. Вряд ли это можно было поменять, потому что у нас не было достаточной экспертизы, чтобы осознавать стоящие перед нами задачи. Но это ошибка.
-
И мы не уменьшили объем продуктовой разработки. Надо сказать, что если бы мы навалились всем коллективом, всю работу по переходу можно было уместить в 4 спринта. У нас двухнедельные спринты – то есть ушло бы 2 месяца. Но у нас шел миллион важных, срочных, нужных проектов. Это ошибка.

И немного формальные результаты:
-
Мы снизили зависимость от западных вендоров.
-
Мы сделали отказоустойчивую архитектуру – теперь с нами ребята из технического департамента здороваются за руку и едят за одним столом.
-
Это финансовая выгода, которую мы еще не посчитали, потому что сравнить затраты один к одному нельзя – у нас была не отказоустойчивая архитектура на Microsoft, а сейчас мы сильно выросли в железе. Сейчас занимаемся тем, чтобы посчитать выгоду, и нам хочется верить, что мы сэкономили.
Вопросы и ответы
Почему у вас была проблема с SSO, когда вы рассказывали про авторизацию, что заходите под собой, а авторизовываетесь под Ивановым. Это проблема именно платформы?
По поводу SSO я хочу процитировать Антона Дорошкевича: «1С – лучшая платформа в мире, поэтому как я могу сказать, что проблема в 1С?»
Но если серьезно, то проблема где-то посередине. Проблема в том, как мы готовили 1С, и проблема в готовности 1С к этому.
Подмена токенов, которая происходила при аутентификации – я склонен предполагать, что мы вместе что-то сделали не так.
Мы просто столкнулись с этой проблемой и не знали, как ее решать. Поэтому это была проблема планирования.
Как происходил замер производительности по ключевым операциям? Это был APDEX в рамках 1С?
В первую очередь мы ориентировались на мнение аналитиков, потому что у нас аналитики понимают, как и за какое время что должно проводиться на проде. Поэтому первично мы просто попросили аналитиков прогнать тест-кейсы и поделиться своим впечатлением – тормозит, не тормозит. Нам не были важны секунды, там если есть деградация, ее очень сильно сразу видно, она кратная.
APDEX мы тоже использовали, но уже тогда, когда начинали рефакторить. А первоначально просто аналитики прогнали тест-кейсы и посмотрели по ним замеры времени, чтобы выявить проблемные места.
С какой базы вы начинали переход? С самой маленькой? Наверняка же вы не с УХ начинали?
У нас разработка разбита на 4 продуктовые команды, и за каждую базу отвечает своя команда. Поэтому подготовку рефракторинга мы начали одновременно.
Но сам переход мы начинали с зарплатной базы, потому что мы любим риск. Если без шуток, то в ЗУП как раз-таки проблем с закрытием сильно меньше. После выплаты зарплаты есть спокойное время до начисления или после выплаты аванса, начисления зарплаты, когда ты можешь откатиться.
И она маленькая, ее откатывать легко, по сравнению с Управлением холдингом. Поэтому мы начинали с нее.
Если же говорить про таймлайн, то мы, например, 5 сентября перевели ЗУП, а в октябре мы уже закончили все базы переводить на PostgreSQL.
Немного за рамками осталась клиентская часть. Я имею в виду не MacOS, а, допустим клиенты на Windows у вас через RDS работают или через веб-публикацию?
Для пользователей ничего не поменялось, клиентская часть осталась как есть:
-
У нас есть профессиональные пользователи – те, которые должны пользоваться 1С постоянно по долгу службы. У них 1С просто установлен локально.
-
И есть пользователи, которые пользуются 1С время от времени. В основном это менеджеры, которые что-то согласуют – какие-то заявки, платежи. Мы их и раньше максимально старались перевести на веб, а теперь уж и подавно просим перейти на веб. Но, в общем и целом, если кто-то очень сильно хочет на MacOS локально установить 1С и пользоваться – ради Бога. Мы просто их предупреждаем, что это будет постоянный геморрой с перепрописыванием каждый раз пути к базе. А так – пожалуйста.
Какие размеры баз? Самая большая база?
В Управлении холдингом порядка 2 терабайт. О технической стороне процесса перехода 2-терабайтной базы на Linux+PostgreSQL рассказывал наш руководитель разработки Алексей Климашенко.
Проект длился 9 месяцев. За эти 9 месяцев продуктовая команда тоже что-то делала. Как согласовались действия того, что делала продуктовая команда и рефакторинг? Есть риск того, что продуктовая команда могла вам привнести что-то, чего вы не ожидали? Или не было таких рисков?
Такой риск был, но, конечно, мы проговаривали это с командами – когда мы начали переходить, сразу выкатили какое-то количество инструкций для команд, на что надо обращать внимание при разработке.
Там была проблема не столько с командами, сколько с тем, что у нас достаточно много подрядчиков, и мы не знаем, кто там конкретно разрабатывает – программист сегодня Иванов, завтра Петров. Мы за них больше переживали, но такой проблемы не было.
Может быть, одну задачку нам донесли, которая начала тормозить. Учитывая, что у нас в спринте в среднем где-то 120 задач, а мы в месяц делаем в среднем где-то 200 задач, то одна за все время – это погрешность.
Здесь надо разделять то, что мы рефакторим для PostgreSQL, и то, что мы рефакторим для Linux. У нас был мануал – какие паттерны нужно использовать при разработке под Linux.
Я слышал, что при открытии под Linux больших форм на сто тысяч срок (например, в документе «Установка цен») форма могла открываться полтора часа, при том, что на майкрософтовских решениях она открывалась 2-3 минуты. С чем-нибудь подобным сталкивались?
Мне кажется, у нас были проблемы с формами, но все-таки они были про PostgreSQL, а не про Linux на application-сервере.
Причем мне кажется, что эти проблемы были среди тех 8, которые выстрелили уже на проде, то есть именно интерфейсное интерактивное взаимодействие.
Мы их как-то быстро отрефакторили, и ничего такого мне не запомнилось, с чем бы мы пострадали.
Получается, что скорее всего проблемы именно с PostgreSQL?
У нас деградация производительности была только из-за перехода на PostgreSQL.
Когда вы перевели УХ на PostgreSQL, вы регулярно обновляете УХ на релизы от вендора или нерегулярно?
У нас очень кастомное Управление холдингом – мы обновляемся в основном один раз в год.
И перескакиваете на все релизы за раз?
Мы идем как положено идти, обновляясь на каждый релиз с потерей форм и всего прочего. Мы один раз в год обновляем именно релиз конфигурации Управление холдингом, потому что она очень сильно доработанная. Со следующего года мы собираемся хотя бы на два раза в год перейти.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT.