Искусственный интеллект (ИИ) – одна из самых популярных тем не только в IT-сообществе, но и среди обычных людей. При этом в ИИ мало кто разбирается. Многим страшно, многим непонятно, многим очень интересно. Самым ярким представителем ИИ сейчас являются большие лингвистические модели (LLM). Их отношение к «настоящему» ИИ примерно как у ежика к балерине, но удобнее использовать термин «искусственный интеллект», чем постоянно объяснять, что такое LLM.
Вокруг ИИ сформировалось несколько лагерей.
Одни утверждают, что ИИ – это лишь «Т9 на стероидах», способный только подставить следующее слово, нарисовать что-то псевдоновое на основе существующего или написать текст в стиле Гоголя. Создать нечто принципиально новое он не способен.
Другой лагерь обещает нам, что через год-два люди гуманитарных профессий – дизайнеры, писатели, художники, музыканты, составители ТЗ, а также программисты – останутся без работы, так как ИИ все сделает за них.
Серьезные исследователи ИИ сравнивают его текущее состояние со студентом, у которого «офигенно подвешен язык»: говорит красиво и убедительно, но по сути – «сплошная вода», пусть и очень качественно поданная.
Есть и радикальный лагерь, считающий, что ИИ уже управляет миром, потому что миром сейчас управляет информация. На текущем уровне развития человек практически не способен отличить созданный ИИ текст, изображение, фото, видео или аудио от созданного человеком. По их мнению, Skynet давно захватил мир.
В свете этого живое, «ламповое» общение человека с человеком без цифровых посредников становится особенно ценным. При подготовке и написании данной статьи не использовался ни один ИИ.
Меня зовут Антон Дорошкевич и в этой статье я проведу вас по «темному лесу» ИИ. Мы пройдем по тропинкам, где увидим чудеса, которые уже используются в СУБД.
В статье речь пойдет исключительно о СУБД PostgreSQL, как о самой «православной» и бурно развивающейся системе управления базами данных в экосистеме 1С. Прямого искусственного интеллекта внутри СУБД, конечно, нет. Так же, как нет больших языковых моделей (LLM). Но свой «черный ящик» в СУБД существует давно – это планировщик запросов.
Сейчас мы выступаем в роли операторов кибераватаров планировщика. Мы задаем ему вопрос – наш запрос из 1С, который интерпретатор 1С превращает в SQL. Мы отправляем этот запрос в «черный ящик» (планировщик) и ждем на выходе ответ в виде плана запроса. Точно так же мы взаимодействуем с большими лингвистическими моделями типа ChatGPT – задаем вопрос и получаем ответ.
При этом мы можем превратиться из оператора в тренера модели. Рассмотрим, как можно «подкрутить» этот черный ящик, чтобы он выдавал устраивающие нас ответы.
Планировщик запросов: эволюция и проблема ошибок
Планировщик существует с первого дня появления СУБД – примерно 30 лет. Длительное время математических функций и достаточно понятных алгоритмов хватало, чтобы планировщик выдавал качественный ответ. Но потом появилась 1С со сложными запросами на тысячи строк и огромными объемами данных. Из-за чего планировщик перестал справляться за счет математики и статистики – начался рост ошибок.
Пару лет назад началось развитие машинного обучения (ML) внутри СУБД для помощи планировщику. Один из видов такого ML называется Adaptive Query Optimizer, или AQO (адаптивный планировщик).
Устройство AQO
Как работает AQO?
Вы выполняете запрос -> AQO запоминает все узлы плана этого запроса. Самое главное – он запоминает, сколько строк планировалось получить на каждом узле плана и сколько в результате получил. Если разница между предполагаемым и фактическим количеством строк значительна (например, в 5 раз), то при следующем выполнении похожего запроса вместо изначально сгенерированного плана (предполагаемый план) будет использован фактический план предыдущего выполнения. Это помогает планировщику строить более качественные планы в будущем.
Режимы работы AQO
AQO может работать в таких режимах, как:
-
Обучение (learn). AQO собирает статистику по всем выполненным запросам, обучается и делает предсказания на основе этой статистики. На данный момент нельзя ограничить сбор по длительности запросов или другим параметрам – собирается все. Это самый «легкий» режим.
-
Контроль (controlled). AQO использует накопленную статистику для построения планов только для тех запросов, которые уже «видел» (обучился на них). На новых запросах он не обучается и никак на них не влияет, но по уже известным собирает статистику.
-
Заморозка (frozen). AQO поправляет планы только для тех запросов, на которых уже обучился. Новым запросам он не обучается и на них никак не влияет. Самый «жесткий» режим.
Особенности работы с AQO в экосистеме 1С
AQO может работать только в одном режиме в конкретный момент времени. В экосистеме 1С, к сожалению (а может, и к счастью), данные постоянно меняются в бешеных объемах. Закрылся месяц – данные за предыдущий месяц стали другими. Например, в январе пользователи запрашивают отчеты за прошлый год, а в феврале – за прошлый месяц (за январь). Такие сценарии использования уникальны и «сносят голову» системам машинного обучения СУБД.
Что же делать? Предлагаю свой алгоритм работы с AQO:
-
После закрытия месяца и пересчета итогов включаем режим обучения (learn) AQO. Это нужно, чтобы планировщик знал о наличии итоговых данных.
-
Обучаем AQO на релевантном периоде: день, неделя – тот период, где собирается максимум типичных пользовательских запросов.
-
Переводим AQO в режим заморозки (frozen). Он будет работать на этих накопленных данных до следующего закрытия месяца, так как распределение и объем данных сильно не меняется.
Режим контроля (controlled) можно использовать, только если вы уверены, что данные в системе меняются постоянно, и нет статичных участков. Это очень ресурсоемкий режим (потребляет много оперативной памяти и ресурсов процессора), требующий значительной мощности сервера.
Пример эффективности AQO: ускорение запроса в 140 раз
Что мы можем получить в итоге? Рассмотрим пример плана запроса:
Изначальный план
Nested Loop (cost=0.43..558722.77 rows=1 width=189) (actual time=0.067..420179.702 rows=2868472 loops=1)
-> Seq Scan on tt831 t2 (cost=0.00..976.85 rows=311 width=122) (actual time=0.011..15.130 rows=33385 loops=1)
-> Index Scan using tt834__q_000_f_002_type__q_000_f_002_rtref__q_000_f_002_rrr_idx on tt834 t1 (cost=0.43..16.70 rows=1 width=182) (actual time=5.623..12.570 rows=86 loops=33385)
Index Cond: ((_q_000_f_002_type = t2._q_001_f_006_type) AND (_q_000_f_002_rtref = t2._q_001_f_006_rtref) AND (_q_000_f_002_rrref = t2._q_001_f_006_rrref))
Filter: ((t2._q_001_f_007_type = _q_000_f_003_type) AND …AND (t2._q_001_f_010 = _q_000_f_011))
Rows Removed by Filter: 20823
Planning Time: 0.665 ms
Execution Time: 420262.190 ms
Ключевой момент – метод соединения таблиц в левом верхнем углу: Nested Loop. Любимый метод, из-за которого часто тормозит расчет себестоимости на PostgreSQL. PostgreSQL часто выбирает Nested Loop там, где этого делать не стоит. Почему же он это делает?
В нашем примере планировщик по статистике предположил, что для соединения поступит всего 311 строк (rows). Исходя из этого, он выбрал Nested Loop – очень дешевый способ для такого объема (доли секунды). Фактически поступило 33 385 строк. Запрос выполнялся 420 секунд. AQO увидел разницу в более чем 100 раз (311 против 33 385).
План после AQO
Hash Join (cost=186952.07..483886.96 rows=1 width=189) (actual time=1491.950..2993.426 rows=2868472 loops=1)
Hash Cond: ((t2._q_001_f_006_type = t1._q_000_f_002_type) AND (t2._q_001_f_006_rtref = t1._q_000_f_002_rtref) AND … AND (t2._q_001_f_010 = t1._q_000_f_011))
-> Seq Scan on tt831 t2 (cost=0.00..976.85 rows=33385 width=122) (actual time=0.012..2.999 rows=33385 loops=1)
-> Hash (cost=106640.65..106640.65 rows=2868265 width=182) (actual time=1490.148..1490.150 rows=2868472 loops=1)
Buckets: 4194304 Batches: 1 Memory Usage: 642749kB
-> Seq Scan on tt834 t1 (cost=0.00..106640.65 rows=2868265 width=182) (actual time=0.012..238.793 rows=2868472 loops=1)
Planning Time: 0.383 ms
Execution Time: 3070.432 ms
В следующий раз, когда прилетел похожий запрос, AQO подсказал планировщику предполагаемое количество строк – 33 385. СУБД действительно получила такое количество строк и планировщик сам выбрал метод соединения Hash Join. Скорость выполнения запроса составила 3 секунды против 420 секунд ранее!
Важно. Мы не меняли код 1С, не добавляли индексы, не вмешивались в структуру базы или текст SQL-запроса. Изменился только план выполнения. Планировщику хватило корректной информации о количестве строк во временной таблице, чтобы построить оптимальный план.
Ограничения AQO
Что будет, если включить AQO на проде?
Сделаю небольшую провокацию: не верьте никаким графикам! Никакая нагрузка, показанная на чужих графиках, не повторится точно также на вашей базе. Достижения на других системах – это правда только для этих систем. Единственный способ узнать, поможет ли AQO вам – это прогнать нагрузочный тест на вашей системе.
Разберем преимущества и недостатки применения AQO на 1С.
Преимущества. Использование AQO на больших запросах, которые «нечеловекочитаемы», часто спасает в безвыходных ситуациях. Особенно на запросах из ERP – динамически собираемых текстах запроса, уникальных каждый раз.
Чем еще хорош AQO? Его можно включать и выключать на лету. Например, включили AQO и запустили долгий запрос (расчет себестоимости). Первый запрос пройдет долго, второй – значительно быстрее. Но только в том случае, если планировщик ошибался в количестве строк. Если же планировщик не ошибался в предполагаемом плане и он несильно отличался от фактического по объему строк, то AQO ничем не поможет.
Недостатки. Время выполнения запросов увеличилось. Это ловится на маленьких запросах. AQO может подсунуть им неоптимальный план. Например, он использует Hash Join вместо более быстрого метода для малого объема данных – Nested Loop.
Главные минусы AQO:
-
Помогает только тогда, когда планировщик ошибался в оценке количества строк. Если оценка была верна, AQO не поможет.
-
Нужно как минимум один раз «перетерпеть» долгий запрос. На практике – 3-4 раза: первый раз накапливается статистика и подсовывается планировщику; второй раз может прилететь другая статистика, опять запоминается; и так далее. Лишь на 3-4 итерации достигается стабильно хороший результат. Это неизбежный минус работы AQO.
В том числе и из-за этого минуса появился другой механизм машинного обучения: Replan.
Replan
Важная ремарка: и AQO, и Replan работают только в Enterprise версии PostgreSQL (от Postgres Pro). AQO доступен и в бесплатной версии Postgres Pro для 1С. Replan – только в Enterprise.
Replan – это подправка плана запроса на лету согласно определенным триггерам.
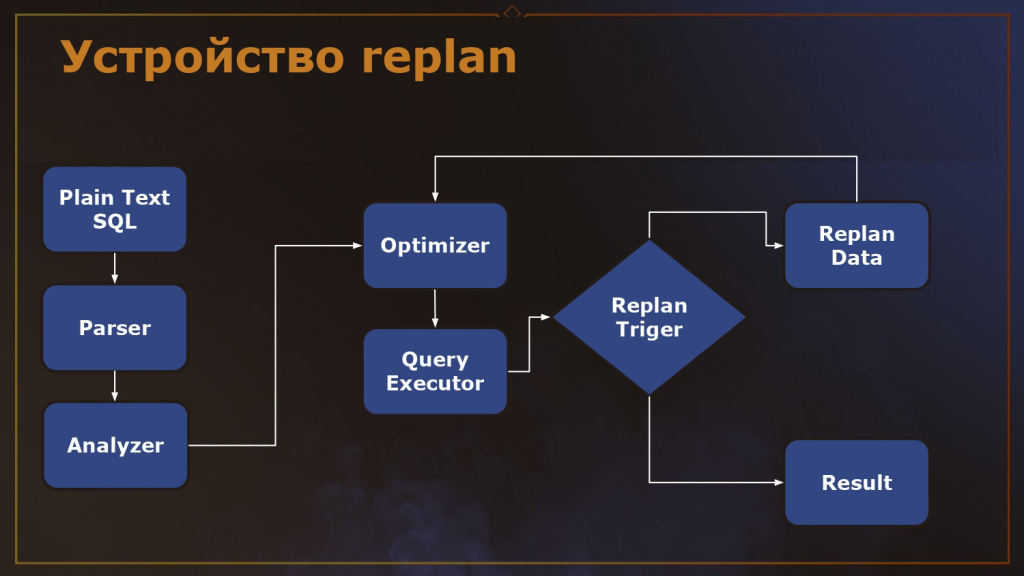
Как устроено планирование? Поступает план запроса, он проходит парсер, анализатор – это неизменно. Затем поступает в оптимизатор (планировщик/Optimizer). После оптимизатора запрос идет в исполнитель (Query Executor) – движок, выполняющий запрос по полученному плану.
У Replan есть триггеры.
Допустим, мы установили, что в нашей системе любой запрос к СУБД длительнее 10 секунд считается плохим и требует попытки перепланирования. Что делает Replan? Когда запрос поступает в исполнитель, Replan начинает отсчет времени. Как только срабатывает тайм-аут (10 секунд), Replan останавливает выполнение запроса и делает подтранзакцию. На этот момент он уже знает фактический план, который «набежал» за эти 10 секунд.
Обратимся к предыдущему примеру из раздела «Пример эффективности AQO: ускорение запроса в 140 раз». За 10 секунд обработано 3 000 строк из фактических 33 000. Replan снимает этот частичный фактический план и отдает его обратно планировщику (Optimizer), подсовывая ему фактические данные (3 000 строк вместо предполагаемых 311). Планировщик, видя новые данные, может построить другой план (например, Hash Join). Если повезет, новый план выполнит запрос быстрее.
А если план не поменялся или не улучшился? Replan смотрит, отличается ли новый план от предыдущего. Если не отличается или за установленное количество попыток (например, 5 или 10) улучшения не достигнуто, Replan сдается и пропускает запрос на выполнение.
Чтобы не войти в бесконечный цикл, когда Replan постоянно подсовывает новые планы планировщику, существует настройка – количество перепланирований.
Важно подобрать баланс настроек:
-
replan_query_execution_time
Триггер по времени. Не ставьте слишком низкое значение. Например, один и тот же запрос всегда выполняется 1 секунду и вы решили сократить время до 0,7 секунд. Ваш запрос выполнялся установленное время, а затем пошел на репланирование. Его план никак не изменился и он снова пошел выполняться. Replan понимает, что в этой ситуации он бессилен и пропускает этот запрос выполняться дальше без остановки.
-
replan_overrun_limit
Триггер по коэффициенту ошибки в количестве предполагаемых и фактически полученных строк в узле плана.
-
replan_memory_limit
Триггер по использованию памяти. Используется, когда потребление памяти рабочим процессом превышает заданное значение. Останавливает запрос и идет на перепланирование, если он может «положить» сервер.
-
replan_max_attempts
Максимальное количество попыток перепланирования.
Главный минус Replan – как и AQO, он помогает только тогда, когда планировщик ошибался в оценке количества строк.
Несмотря на то, что машинное обучение шагает по миру, помните, что человек с головой гораздо круче любого ИИ. Желаю всем подходить к своим системам именно с умом, а не только с надеждой на ИИ.
P.S. С момента выступления до публикации прошло много времени, и сейчас replan уже называется AQE, намного поумнел напару с планировщиком, и расчет себестоимости в ERP практически приравнялся к скорости MS SQL.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вайб-кодинг — ИИ пишет за вас в 1С
Решение «Вайб-кодинг» внедряет искусственный интеллект прямо в 1С: пишет корректный код, анализирует метаданные и помогает автоматизировать проектные задачи. Поддерживает GPT-4, Llama, Claude и Gemini.
Вступайте в нашу телеграмм-группу Инфостарт