Меня зовут Иван Казеев, я старший разработчик в команде 1С-тестирования компании Ozon. Хочу рассказать о возможностях Vanessa Automation – какие интересные приемы она предоставляет «из коробки».
У нас на повестке три темы:
-
Подготовка данных – как с помощью стандартных шагов Vanessa Automation подготовить тестовые данные.
-
Циклы в табличных частях – как с помощью циклов в шагах Vanessa Automation сравнить различные табличные части.
-
Использование простых выражений на языке 1С – как упростить процесс тестирования, сделать его более гибким и эффективным.
Подготовка данных. Как подготовить и создать данные для тестов с помощью Ванессы
При написании автотестов зачастую приходится сталкиваться с вопросом – какие данные использовать для тестов. Например, мы можем использовать существующие данные из базы, если для тестирования используется копия прода. Но это не всегда может быть удобно – по различным причинам.
Предлагаю рассмотреть альтернативный способ – воспользоваться шагами из стандартной библиотеки Vanessa Automation, входящими в группу «Подготовка и загрузка данных», и одноименным инструментом.

На слайде можно увидеть часть шагов, которые можно использовать для создания данных – они начинаются на «И я проверяю или создаю…» и «И я перезаполняю для объекта табличную часть…».

Но если мы просто добавим эти шаги в редактор Vanessa Automation, то с ними в таком виде работать не очень удобно – они неинформативно выглядят, и непонятно, как их использовать.

Чтобы с этими шагами было работать удобнее, в Vanessa Automation встроен специальный инструмент «Подготовка и загрузка данных», который находится в меню «Инструменты».
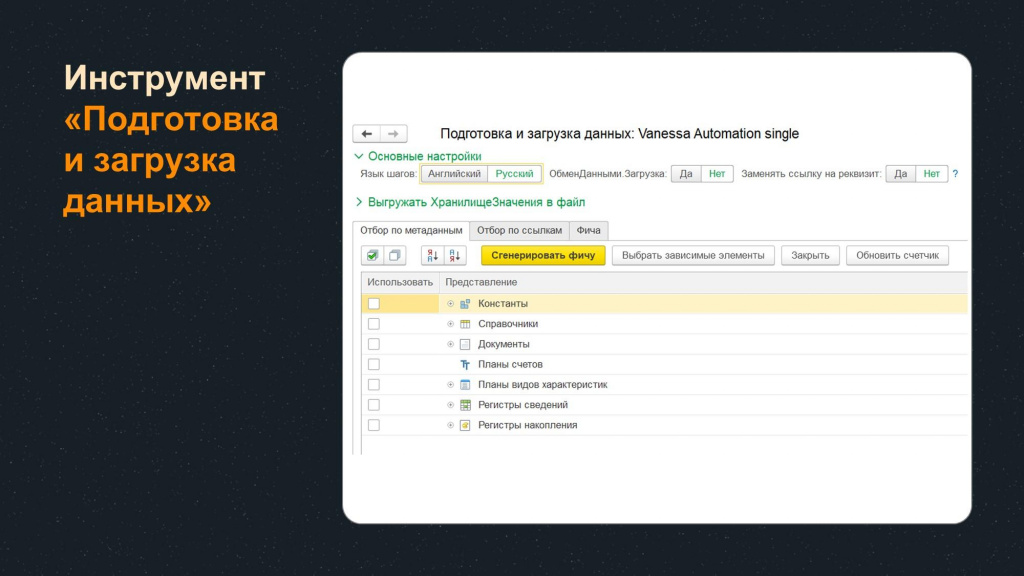
На слайде показана основная форма инструмента «Подготовка и загрузка данных».
В верхней части желательно выбрать язык – поскольку мы используем русский язык, устанавливаем значение переключателя «Русский».
Ниже расположены три вкладки:
-
Отбор по метаданным
-
Отбор по ссылкам
-
Фича
На вкладке «Отбор по метаданным» отображается дерево всех метаданных текущей базы. Для этого дерева можно:
-
Выбрать ветку вида метаданных целиком и сгенерировать шаги для создания всех справочников или всех документов.
-
Либо раскрыть ветку метаданных подробнее и выбрать определенный вид документа – например, «Отпуск» и сгенерировать шаги по созданию всех документов отпуска, которые есть в текущей базе.
Но при большом количестве объектов их генерация может занять значительное время, поэтому удобнее использовать точечный отбор на закладке «Отбор по ссылкам».
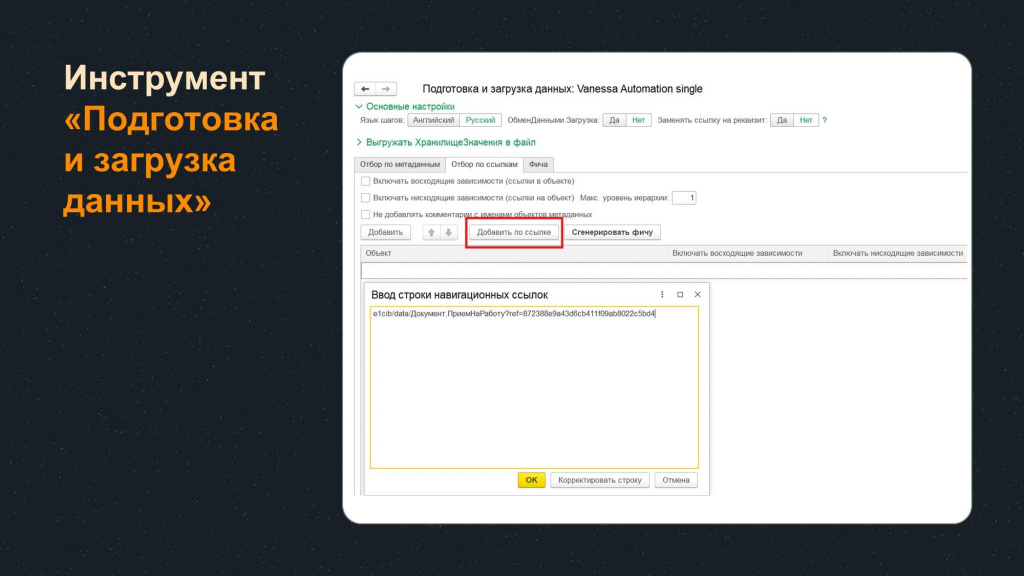
На закладке «Отбор по ссылкам» мы можем сгенерировать шаги для создания объекта по конкретной навигационной ссылке – выбрать любой существующий объект в базе, получить его навигационную ссылку, нажать кнопку «Добавить по ссылке» и сгенерировать шаги по его созданию.
В данном случае мы выбираем навигационную ссылку конкретного документа «Прием на работу». Сразу после добавления этой ссылки в табличную часть по кнопке «Сгенерировать фичу» можно получить шаги для получения аналогичного документа при подготовке данных для тестирования.
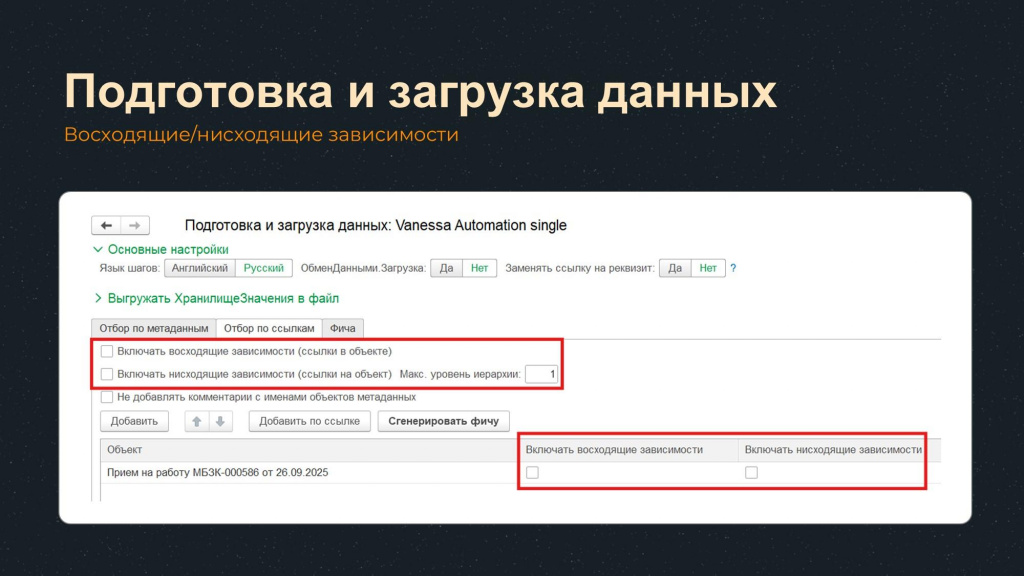
Обратите внимание, что здесь в шапке и табличной части есть опции «Включать восходящие зависимости» и «Включать нисходящие зависимости».
-
Восходящие зависимости – это ссылки, которые используются внутри объекта. Например, если в документе «Прием на работу» указан реквизит «Организация», то при генерации фичи будут добавлены шаги по созданию этой организации.
-
Нисходящие зависимости – это движения по регистрам, связанные с объектом. Здесь нужно быть осторожным: при большом количестве движений генерация может занять много времени и даже привести к нехватке памяти на сервере.
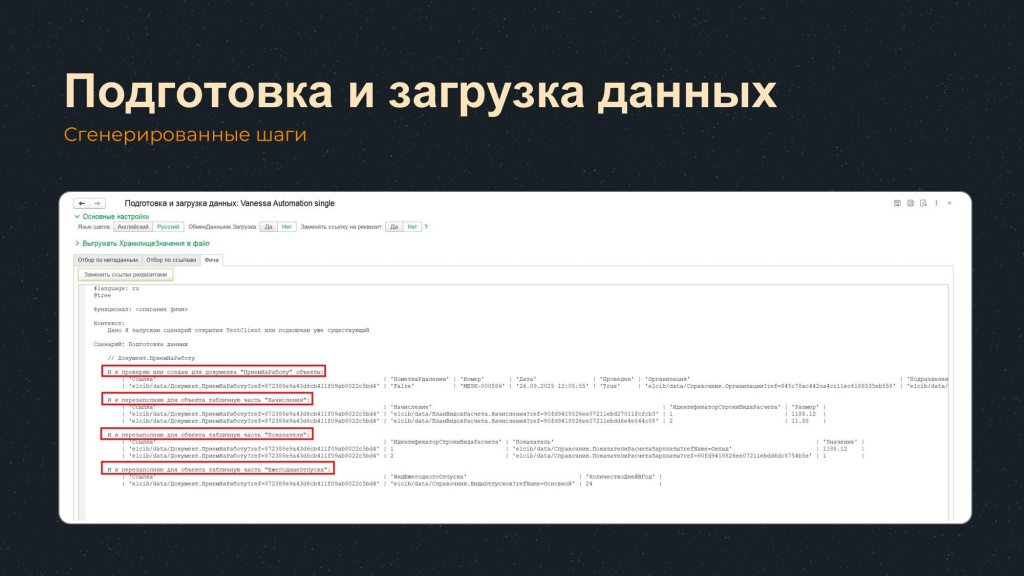
После того как мы добавили ссылку и нажали «Сгенерировать фичу», на закладке «Фича» появляется текст готовых шагов:
-
И я проверяю или создаю для документа ПриемНаРаботу объекты– шаг создает или проверяет наличие документа. -
Три шага по заполнению табличных частей в этом документе.
Мы можем скопировать сгенерированные шаги и вставить их непосредственно в редактор Vanessa Automation, чтобы продолжить там производить с ними различные манипуляции.

Сгенерированные шаги представляют собой написанные на языке Gherkin конструкции с таблицами, куда входят все необходимые параметры и значения реквизитов объекта.
Причем для выполнения этих шагов нет необходимости подключать клиент тестирования. Все действия происходят на стороне тест-менеджера.

Как правило, эти таблицы получаются достаточно объемными – с большим количеством реквизитов, включая незаполненные. Ненужные колонки можно просто удалить.
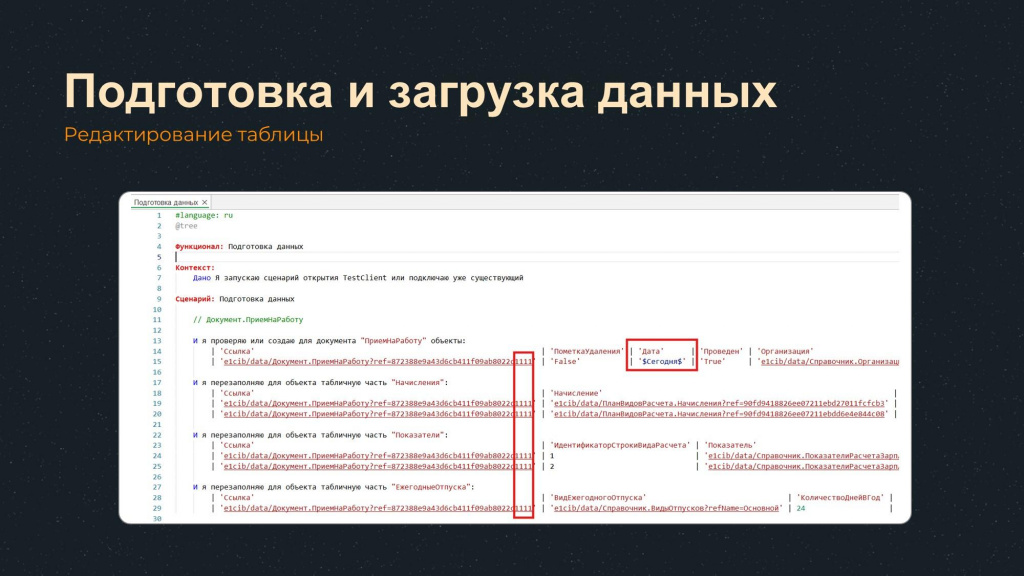
Важно понимать, что если просто выполнить эти шаги в Vanessa Automation, ничего нового не создастся, так как сам документ с такой ссылкой и соответствующими значениями реквизитов в этой базе уже существует – просто выполнится проверка реквизитов и перезаполнятся табличные части на идентичные.
Для создания нового документа нам нужно отредактировать ссылки, сделать их уникальными – например, просто заменить последние несколько символов произвольными значениями.
Однако, если нарушить структуру таблицы или указать некорректные ссылки, при выполнении такие шаги упадут. Поэтому обязательно проверяйте всю таблицу на синтаксическую корректность и убедитесь, что все ссылки указаны правильно.
Далее имеет смысл заменить некоторые значения реквизитов. Например, для корректности регулярных прогонов теста требуется подставлять актуальные даты – для этого можно воспользоваться переменными.
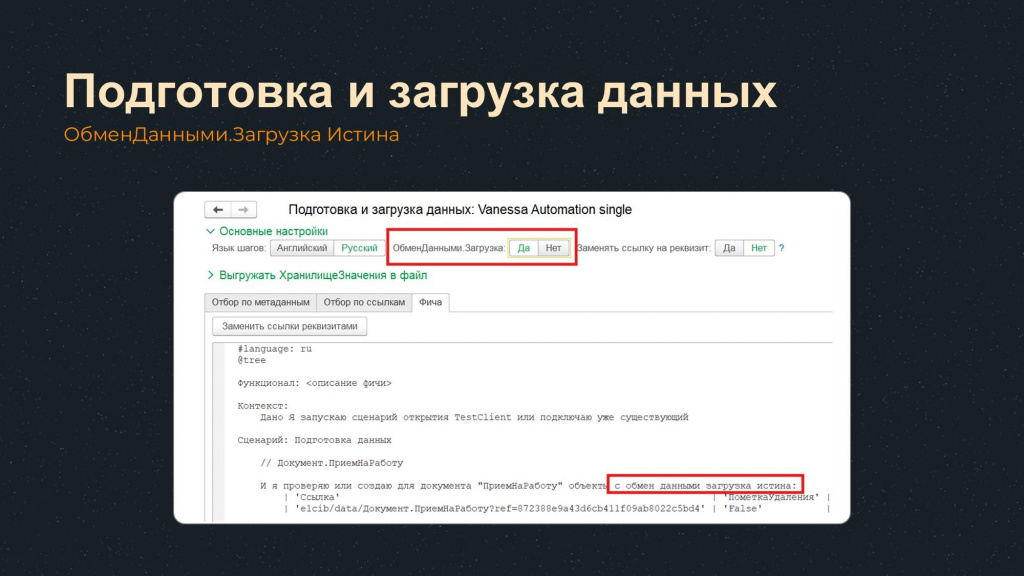
Также в некоторых случаях может потребоваться использовать режим «ОбменДанными.Загрузка = Истина».
Этот режим можно включить с помощью переключателя в верхней части формы. Либо просто вручную приписать к шагу с обмен данными загрузка истина.

Еще важно учитывать, что если при создании документа у нас в таблице указано значение Проведен = True, может возникнуть ситуация, что у данного документа не будет движений по всем необходимым регистрам.
На практике для этой проблемы выработали следующее решение – при создании документа использовать значение Проведен = False, чтобы документ создался непроведенным, а последним шагом добавить создание этого же документа, но в таблице сделать только две колонки – первая со ссылкой, а во второй указать Проведен = True. В таком случае все движения документа должны установиться корректно.
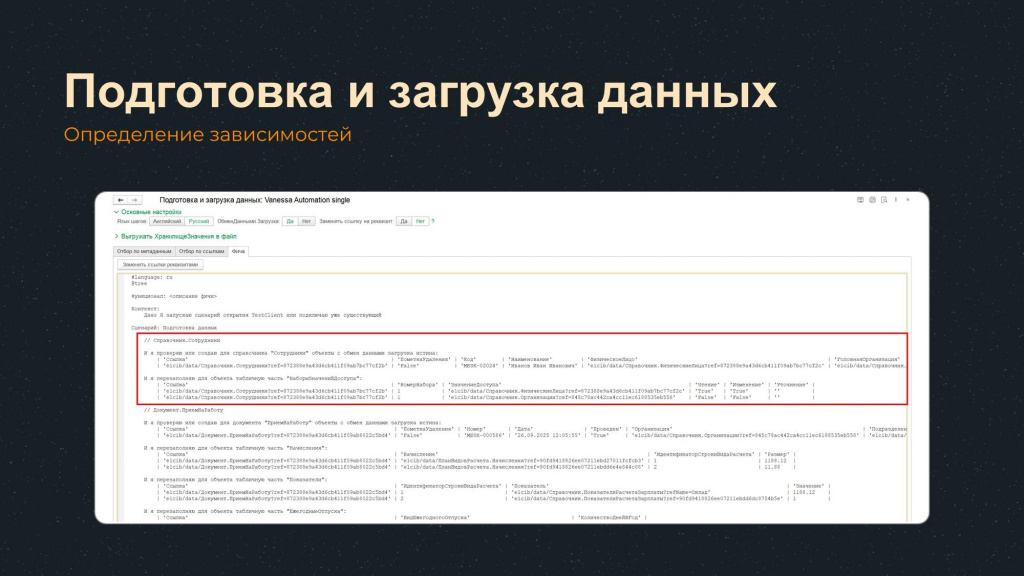
Также при создании документа необходимо учитывать различные зависимости.
Например, логично предположить, что при создании в ЗУП документа «Прием на работу», нам понадобится сотрудник. Значит необходимо заранее об этом позаботиться и до создания документа создать элемент справочника «Сотрудники». И в целом, чтобы не получить неожиданного результата, я рекомендую все создания объектов выполнять последовательно с точки зрения логики их создания в базе.
Полученные таблицы можно вертикально масштабировать, добавляя дополнительные строки для создания нескольких документов или элементов справочников одним шагом. Или можно создать экспортный сценарий на основе данной подготовки и использовать параметры для подстановки различных значений и создания нескольких различных документов одним шагом.
Таким образом можно достаточно просто создать все необходимые тестовые данные и использовать их в работе. Да, возможно, придется немножко подучиться, если вы с этим не работали, но в целом оно себя окупает.
Использование циклов для работы с табличными частями. Как сравнить значения одной табличной части с другой
Следующая тема – использование циклов для работы с табличными частями.
При работе тестировщика часто необходимо сравнить табличные части, например, проводки. Один из вариантов решения этой задачи в Vanessa Automation – это использование циклов.
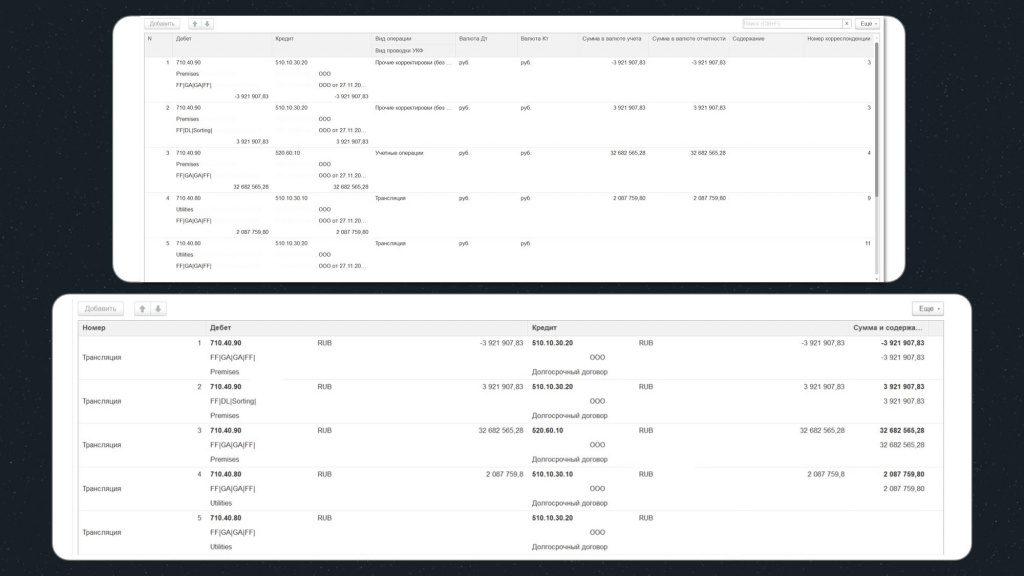
Рассмотрим реальный кейс интеграции, когда в одной базе нужно создать документ, далее его выгрузить в другую базу, а потом проверить соответствие проводок в одной и другой табличной части.
На слайде показаны две табличные части:
-
верхняя – это проводки из исходной базы;
-
нижняя – это проводки в базе назначения.
Как можно видеть, структура табличных частей отличается, поэтому недостаточно их просто выгрузить в файлы, а потом сравнить по шаблону.
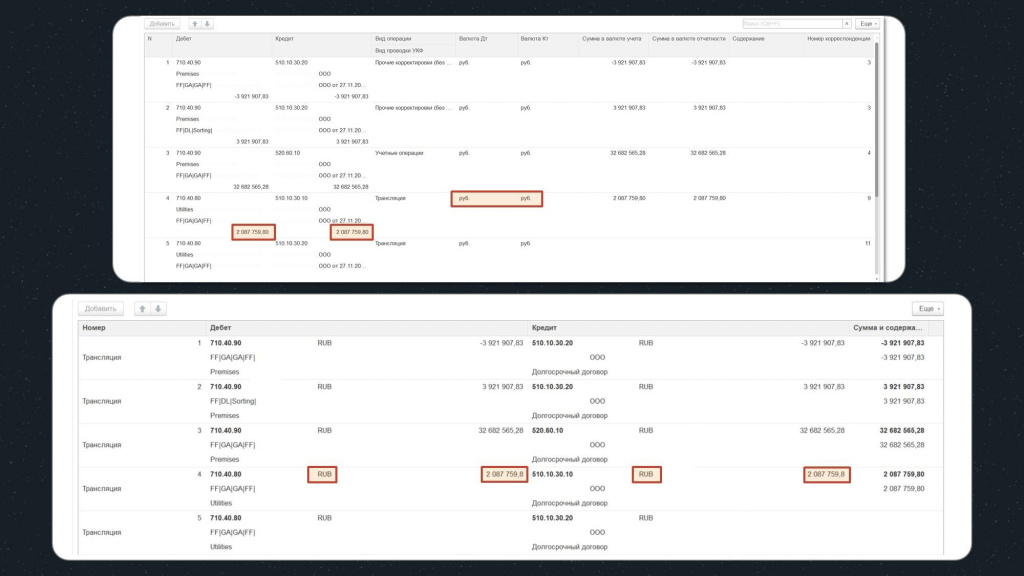
Кроме этого, здесь есть нюансы со значениями реквизитов:
-
В исходной базе суммы дебета и кредита имеют в дробной части нули, а в базе назначения нули срезаются.
-
Также наименование валют – в исходной базе у нас русскоязычное наименование «руб.», а в базе назначения – на латинице «RUB» .
Все это мы сейчас учтем.
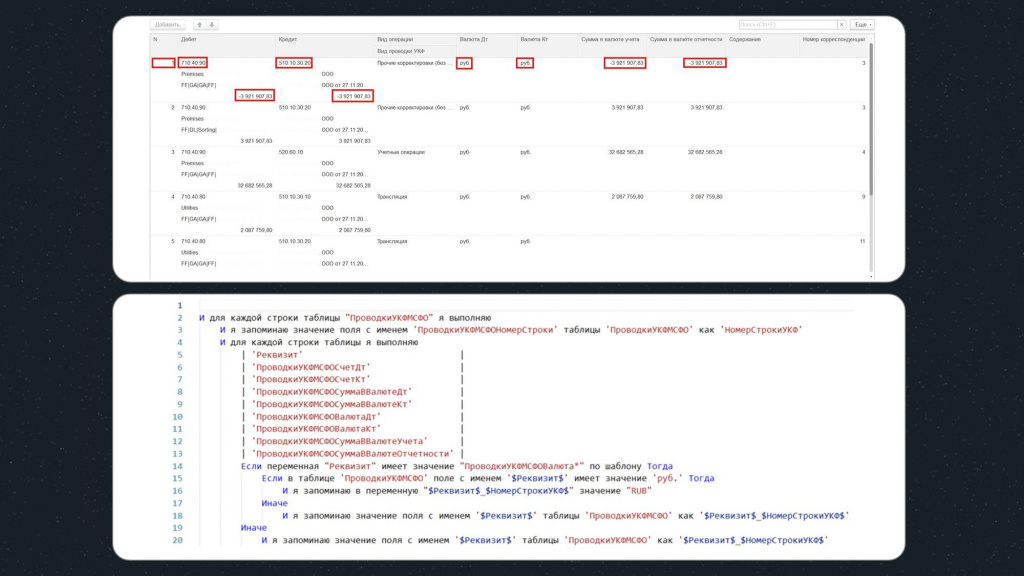
Давайте посмотрим, как мы это можем сделать.
-
Скриншот сверху – это проводки в исходной базе, здесь выделены значения полей, которые нам необходимо запомнить.
-
Снизу – конструкция, с помощью которой мы будем производить сравнение.
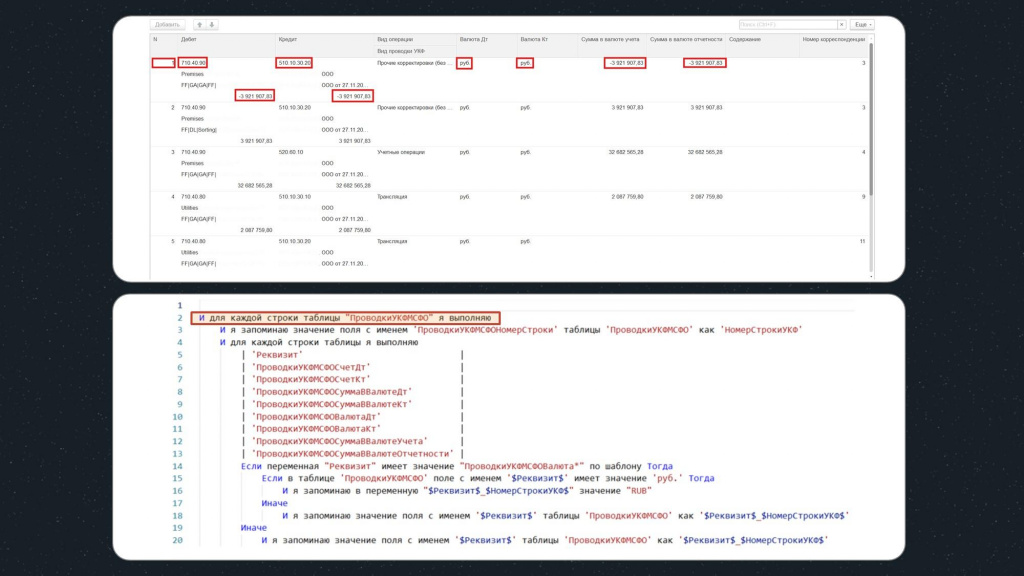
На первом шаге этой конструкции используется цикл, в рамках которого для каждой строки табличной части будут выполняться подчиненные шаги – в рамках этого цикла мы будем двигаться по табличной части вертикально.
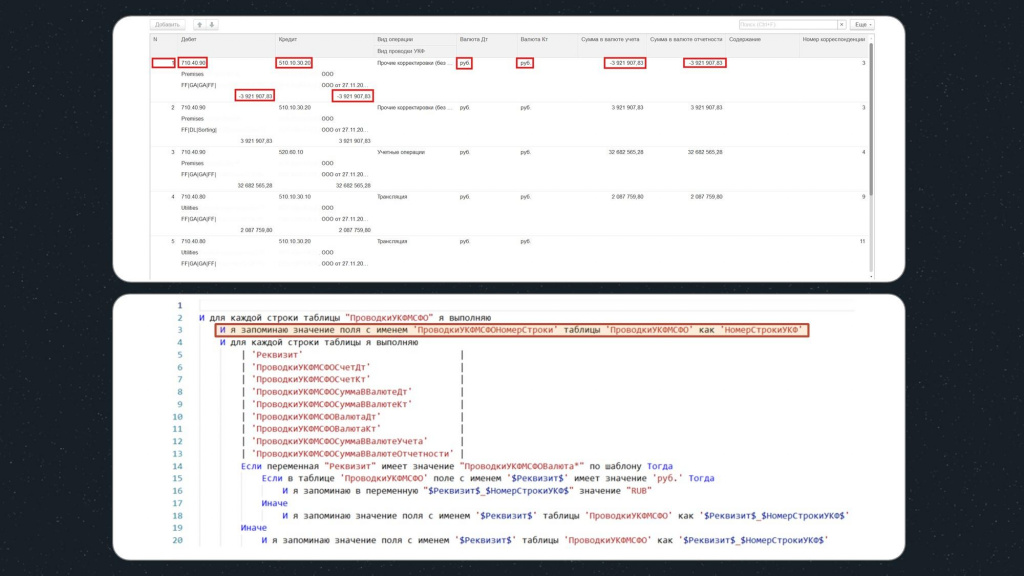
Первое, что мы делаем – это запоминаем значение поля «ПроводкиУКФМСФОНомерСтроки» в переменную «НомерСтрокиУКФ», она нам в дальнейшем понадобится.
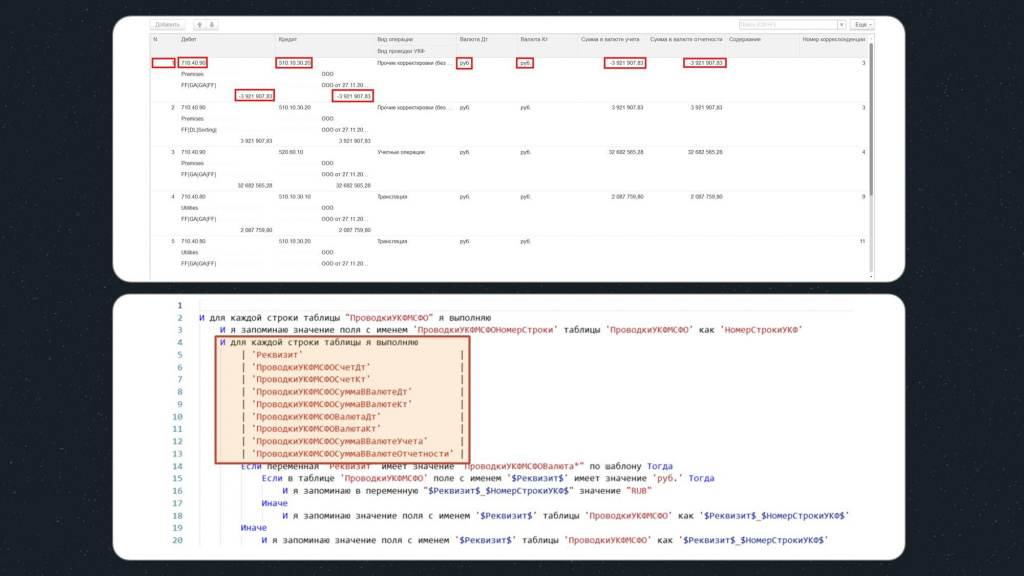
Далее идет еще один цикл, но уже с подчиненной таблицей, содержащей имена всех реквизитов в строке табличной части, которые нам необходимо будет проверить. В этом цикле мы будем двигаться по полям каждой строки горизонтально.
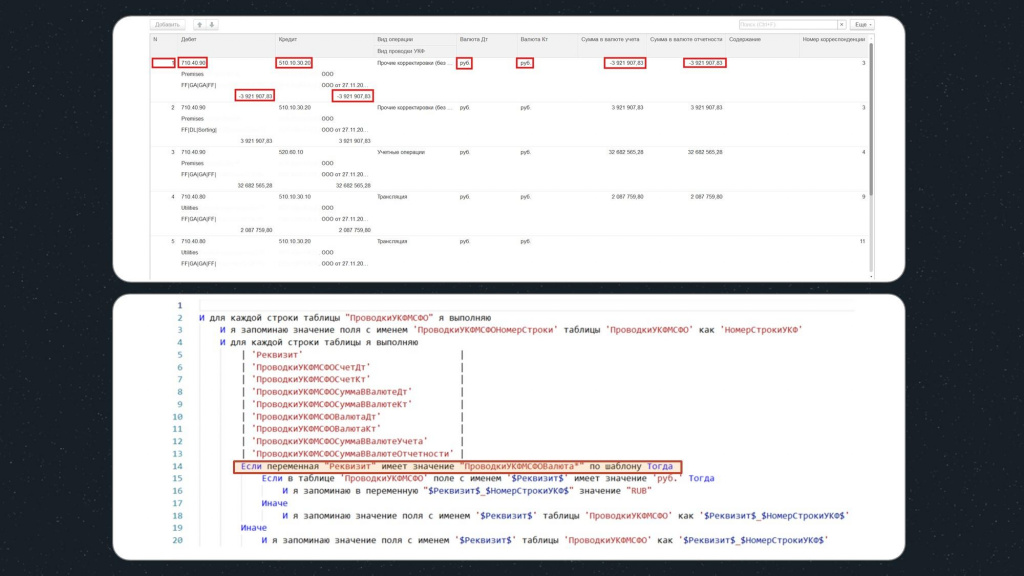
Однако мы помним, что для цикла с реквизитами у нас есть несколько условий – в частности, есть нюанс с различным наименованием валюты «Рубли» в исходной базе и базе назначения.
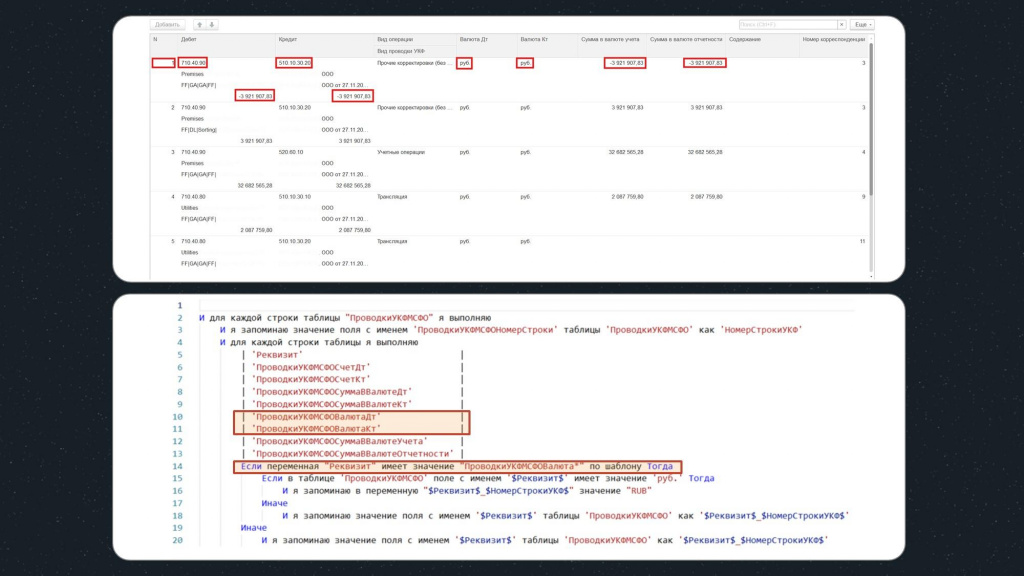
Поэтому, если мы попадаем на реквизиты «ПроводкиУКФМСФОВалютаДт» или «ПроводкиУКФМСФОВалютаКт», нам с ними нужно поработать отдельно:
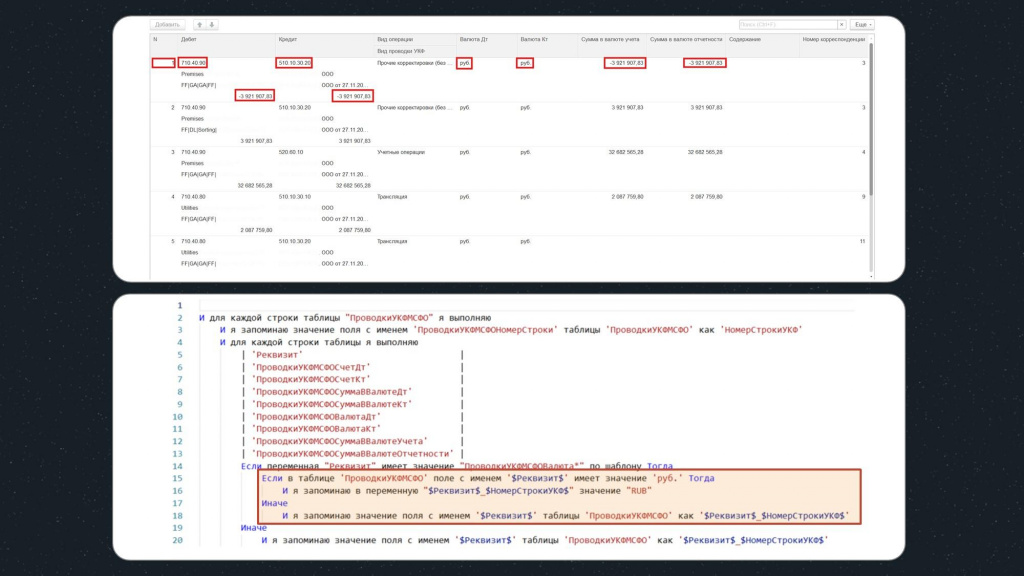
Обратите внимание, в данном условии мы проверяем соответствие имен реквизитов таблицы по шаблону «ПроводкиУКФМСФОВалюта*»:
-
Если значение валюты – «руб.», мы запоминаем в переменную значение «RUB», чтобы потом сверить с результатом в базе назначения.
-
Если же используется другая валюта, с наименованием которой у нас проблем нет, мы запоминаем, как есть.
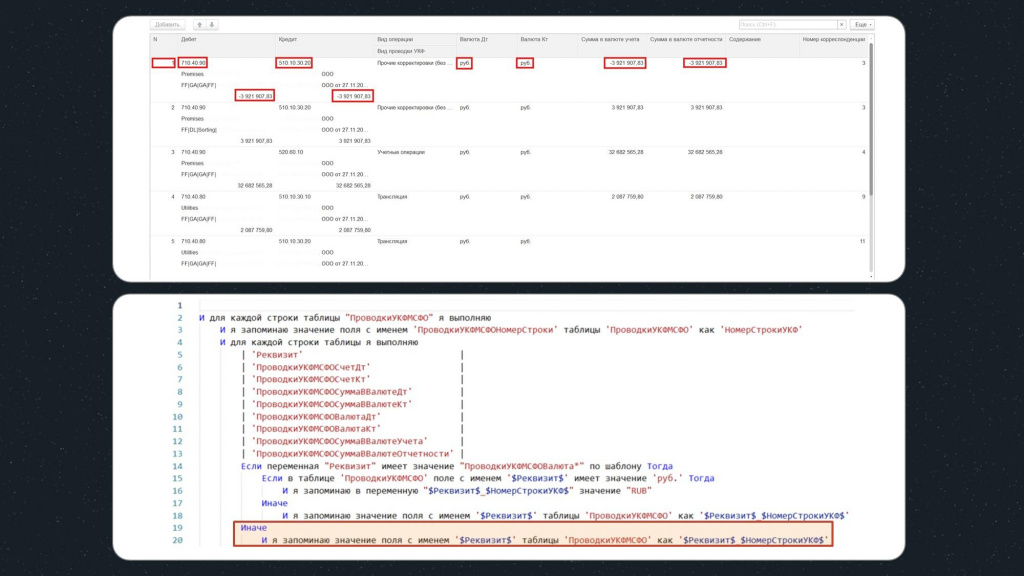
А для других реквизитов мы просто запоминаем значение в переменную с помощью шага:
И я запоминаю значение поля как $Реквизит$_$НомерСтрокиУКФ$
В итоге все значения всех реквизитов для каждой строки таблицы мы запомнили в отдельные переменные.
Обратите внимание, что наименование итоговой переменной собирается динамически из других переменных:
-
переменная
$Реквизит$соответствует реквизиту из строки таблицы; -
а
$НомерСтрокиУКФ$берется из переменной номера строки, которую мы запоминаем в каждой итерации цикла.
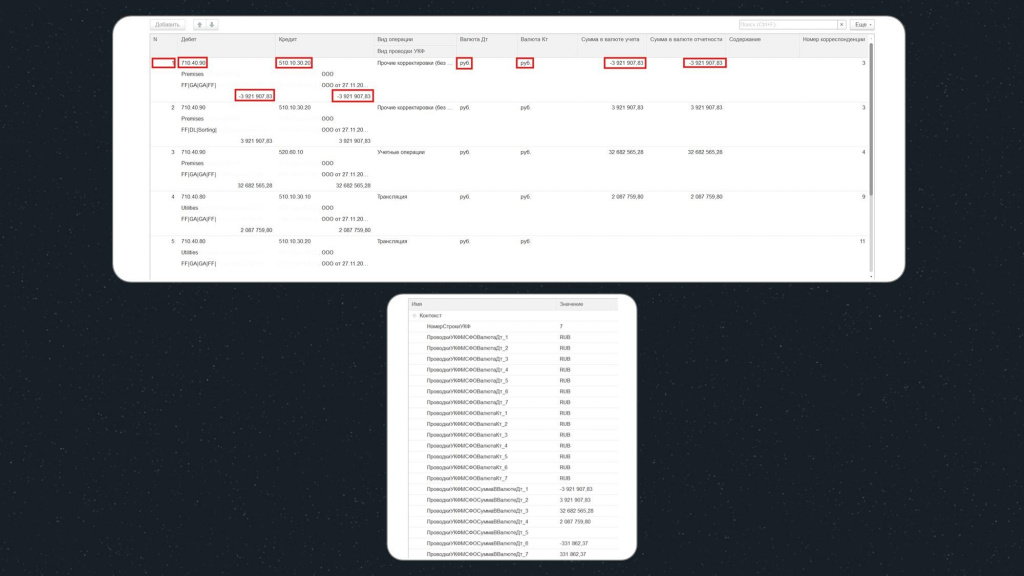
В итоге у нас получается портянка переменных – для всех 7 строк и для всех полей нашей исходной таблицы.
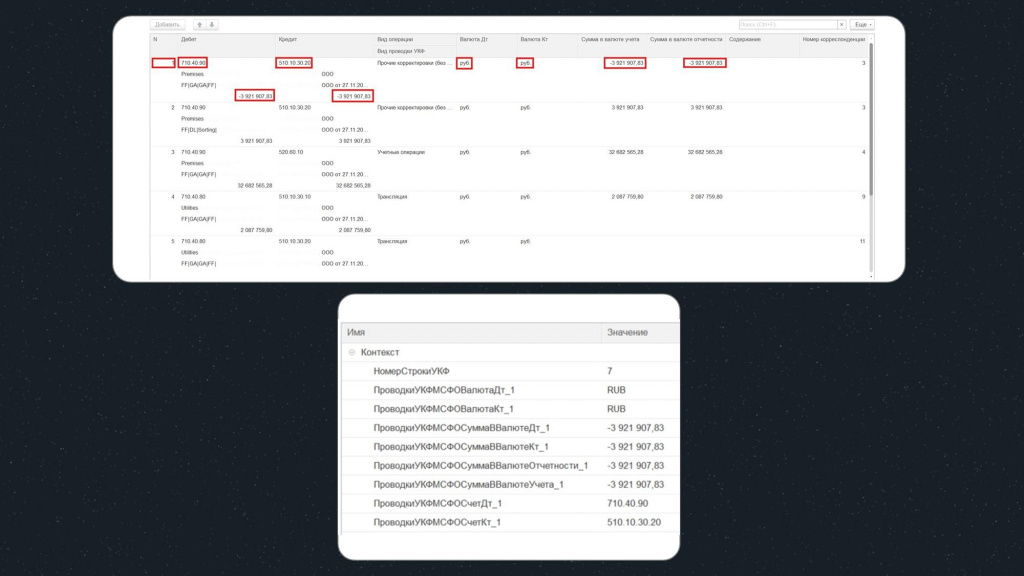
На слайде показаны более подробно имена реквизитов и их значения для первой строки исходной таблицы – их можно узнать по постфиксу «_1». Кроме того, здесь же можно увидеть переменную НомерСтрокиУКФ, в которой хранится номер последней строки табличной части – она нам еще пригодится.
Таким образом мы сохранили все нужные значения реквизитов. Причем неважно, сколько строк будет в таблице: хоть миллион – все это выполнится.
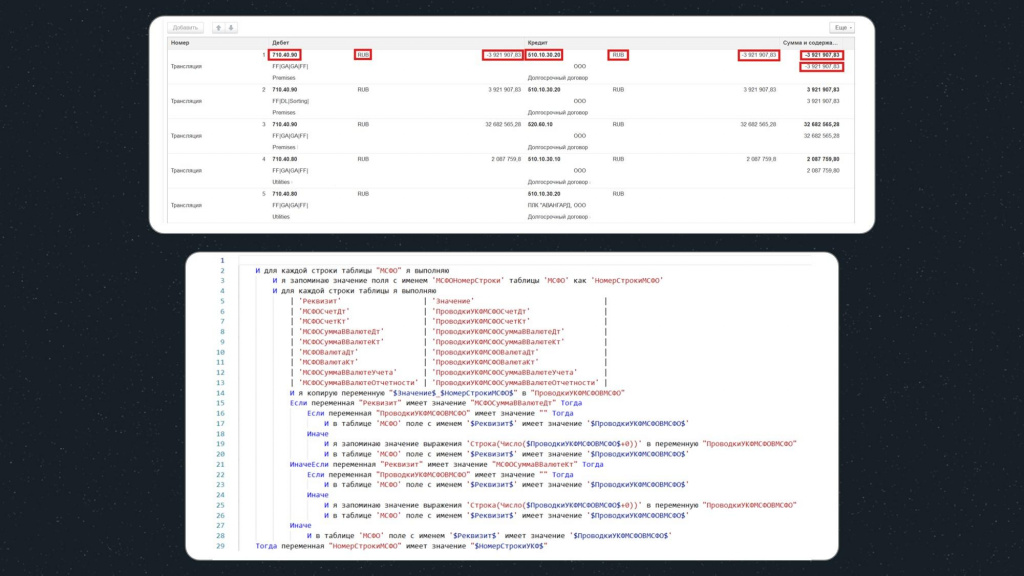
Далее документ выгружается в базу назначения, и мы начинаем проверять другую табличную часть.
Здесь для проверки соответствия значений исходной базы и базы назначения также используется цикл, но его конструкция уже имеет немного другой вид. Разберем его подробнее.
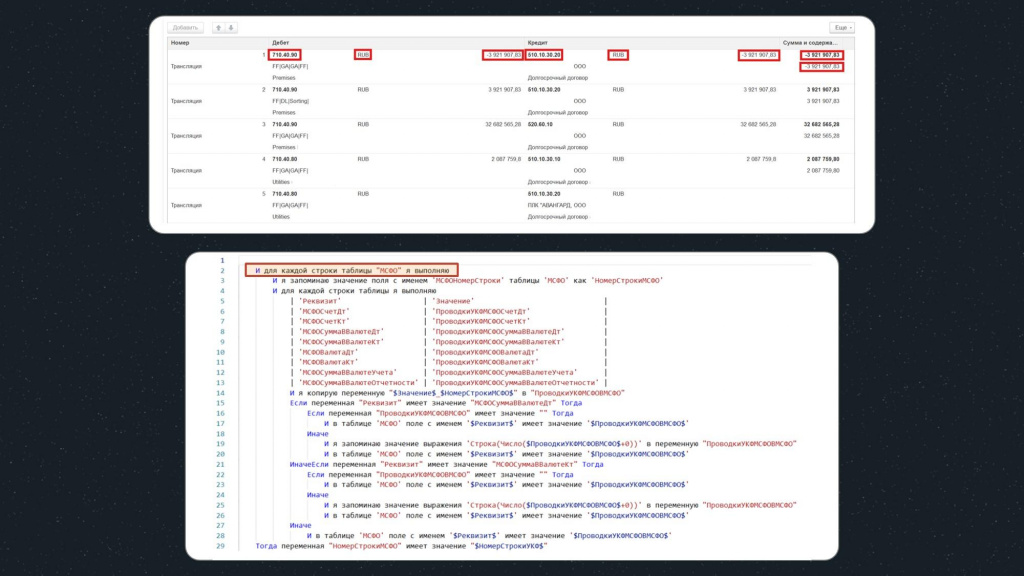
Первая строка аналогична предыдущему циклу, т.е. проходимся по всем строкам табличной части базы назначения.
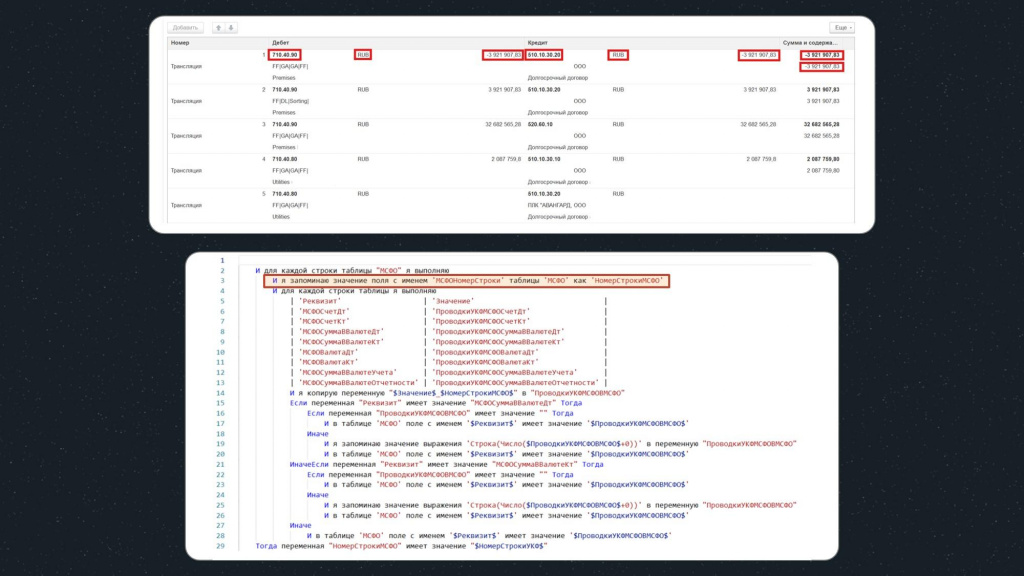
Точно так же запоминаем номер строки в переменную – здесь она уже называется «НомерСтрокиМСФО».
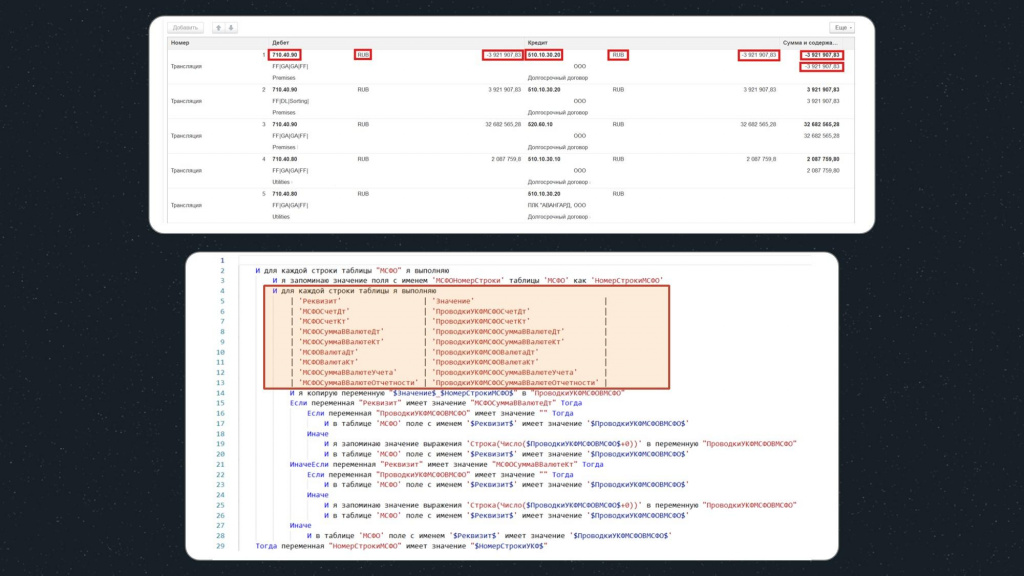
А второй цикл здесь уже немного побольше – у нас, кроме колонки «Реквизит» появилась еще и колонка «Значение»:
-
«Значение» – это имя реквизита из первой базы;
-
«Реквизит» – это имя соответствующего реквизита в базе назначения.
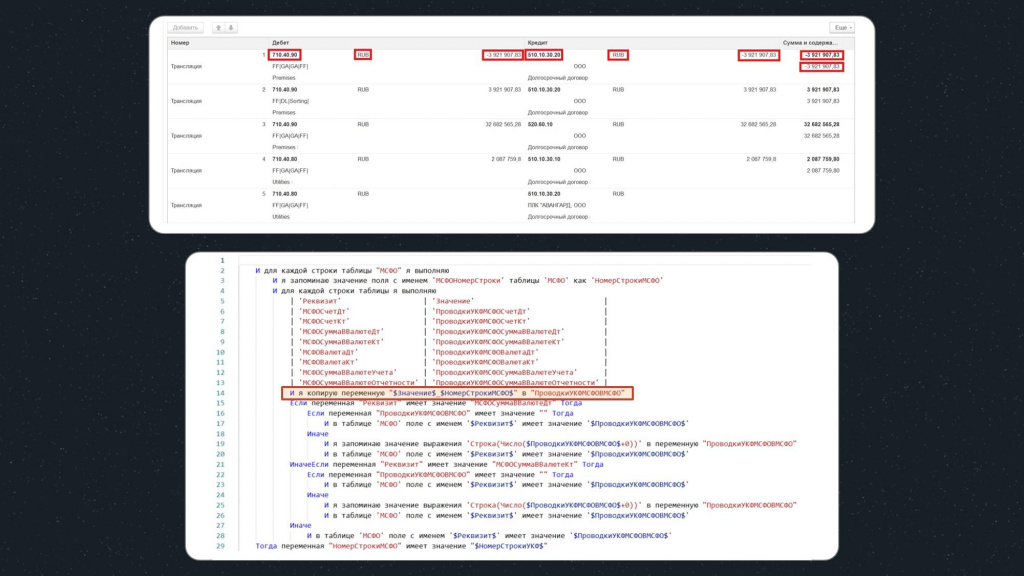
Далее мы опять динамически собираем имена переменных: берем имя реквизита из поля «Значение», добавляем номер строки и получаем переменную, которую ранее создали в базе-источнике. Копируем это значение в новую переменную «ПроводкиУКФМСФОВМСФО» и переходим к проверке.
И я копирую переменную $Значение$_$НомерСтрокиМСФО$ в ПроводкиУКФМСФОВМСФО
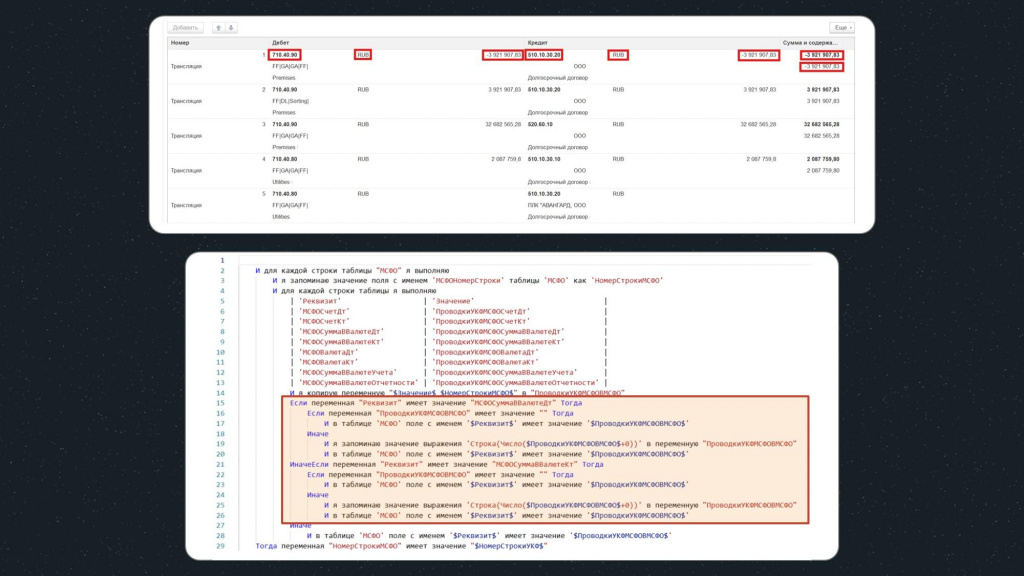
Далее у нас проверяются несколько условий.
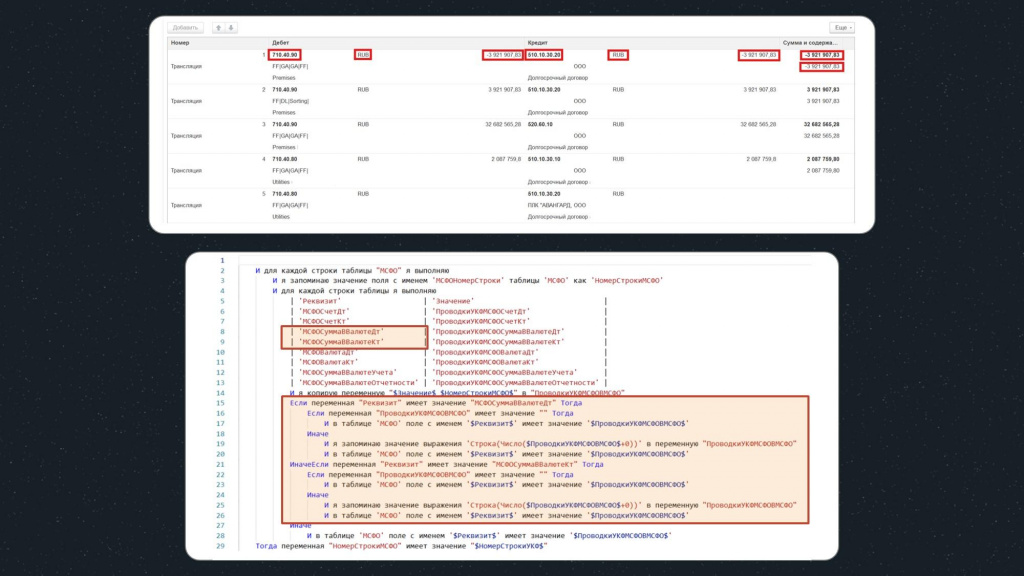
Первое условие проверяет суммы полей «МСФОСуммаВВалютеДт» и «МСФОСуммаВВалютеКт» – это нужно, потому что у сумм в базе назначения срезаются нули.
-
Если значение пустое, мы проверяем, что оно таким и должно быть:
И в таблице поле с именем $Реквизит$ имеет значение $ПроводкиУКФМСФОВМСФО$ -
Если значение не пустое, убираем из суммы лишние нули после запятой. Для этого преобразуем переменную к типу «Число», прибавляем ноль, далее преобразуем обратно в строку и получаем новую переменную:
И я запоминаю значение выражения Строка(Число($ПроводкиУКФМСФОВМСФО$+0)) в переменную ПроводкиУКФМСФОВМСФО
а потом сравниваем эту переменную со значением реквизита:
И в таблице поле с именем $Реквизит$ имеет значение $ПроводкиУКФМСФОВМСФО$
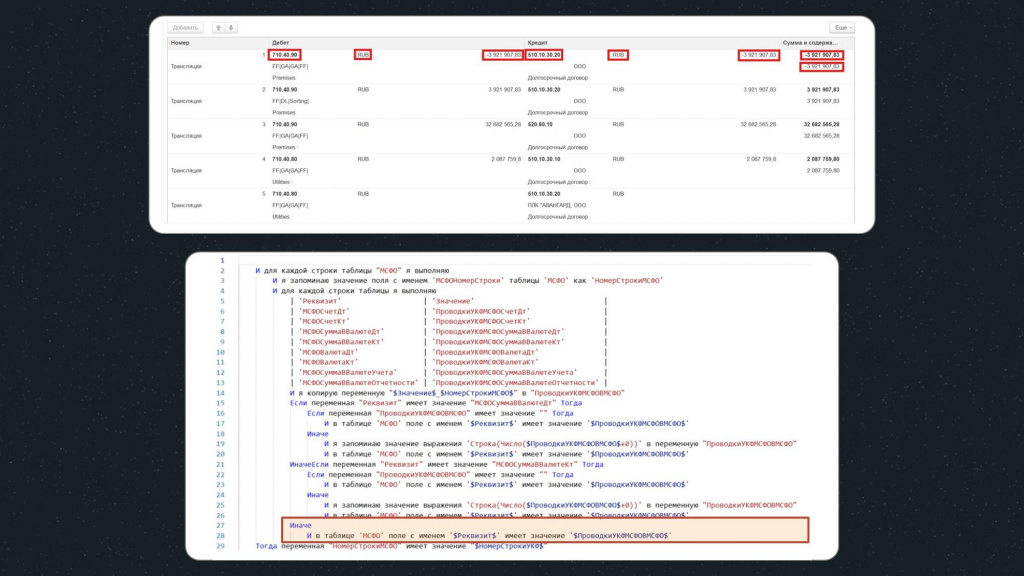
Для остальных полей, где преобразование не требуется, тоже просто сравниваем значение:
И в таблице поле с именем $Реквизит$ имеет значение $ПроводкиУКФМСФОВМСФО$
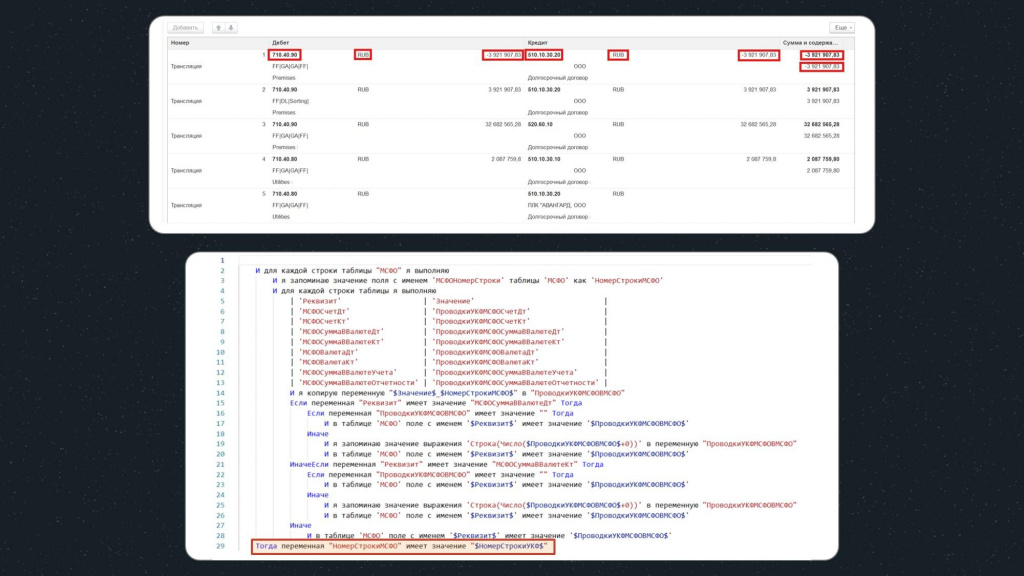
И последним шагом мы сверяем количество строк в табличных частях из первой и второй базы, сравнивая значения соответствующих переменных:
Тогда переменная НомерСтрокиМСФО имеет значение $НомерСтрокиУКФ$
Вот таким нехитрым образом можно проверить корректность заполнения табличных частей.
Аналогичный подход можно применять и для табличных документов, только там циклы будут немного посложнее, но тоже реализуемо.
Использование простых выражений в шагах Ванессы. Простые выражения на языке 1С
Следующая тема – это использование простых выражений в шагах Vanessa Automation.
При написании автотестов мы постоянно сталкиваемся с необходимостью заполнять поля, а также проверять на соответствие данные в различных полях и ячейках. Это могут быть даты, числа, строки.
Если данные заранее известны, то проблем обычно нет. Но что, если нужно вычислить определенную дату, взять часть строки из поля или привести числа в определенный формат?
Разработчики, возможно, посмотрят на это и скажут: «Ну это же элементарно». Но начинающие тестировщики не всегда глубоко разбираются в коде, а иногда вообще не имеют опыта программирования. И у них с этим могут быть сложности – например, как заполнить поле «Дата» не текущим днем, а каким-то другим, либо проверить данное поле на наличие в нем даты, отличающейся от текущей.
Поэтому я решил подсветить тему работы с числами, строками и датами подробнее.

Давайте посмотрим, что мы вообще можем делать с числами:
-
простые арифметические операции: сложение, умножение, вычитание, деление:
И я запоминаю значение выражения '1+1' в переменную "Сложение"
// {"Сложение": 2}
И я запоминаю значение выражения '4-1' в переменную "Вычитание"
// {"Вычитание": 3}
И я запоминаю значение выражения '3*2' в переменную "Умножение"
// {"Умножение": 6}
И я запоминаю значение выражения '8/2' в переменную "Деление"
// {"Деление": 4} -
преобразование значений к типу «Число»:
И я запоминаю значение выражения 'Число($Переменная$) + 1' в переменную "РезультатЧислом"
// {"РезультатЧислом": 5,15} -
округление – либо с помощью функции «Формат», либо с помощью Окр(), либо отсекая дробную часть с помощью Цел():
И я запоминаю значение выражения 'Формат(15.45, "ЧДЦ=1")' в переменную "Результат"
// {"Результат": "15,5"}
И я запоминаю значение выражения 'Окр(4.15, 1, РежимОкругления.Окр15как10)' в переменную "Результат"
// {"Результат": 4,1}
И я запоминаю значение выражения 'Цел(15.99)' в переменную "Результат"
// {"Результат": 15} -
и еще одна удобная возможность – вывод лидирующих нулей, это бывает довольно полезно:
И я запоминаю значение выражения 'Формат(123, "ЧЦ=6; ЧВН=; ЧГ=")' в переменную "Результат"
// {"Результат": "000123"}
Конечно, тут с точки зрения тестирования охвачено далеко не все – я выделил только наиболее часто встречающиеся моменты, но, возможно, они тоже будут вам полезны.

Со строками возможностей гораздо больше.

Мы можем убирать пробелы в начале строки (СокрЛ()), в конце строки (СокрП()) или с обеих сторон (СокрЛП()):
И я запоминаю значение выражения 'СокрЛ(" Убрать пробелы слева")' в переменную "СтрокаБезПробела"
// {"СтрокаБезПробела": "Убрать пробелы слева"}
И я запоминаю значение выражения 'СокрП("Убрать пробелы справа ")' в переменную "СтрокаБезПробела"
// {"СтрокаБезПробела": "Убрать пробелы справа"}
И я запоминаю значение выражения 'СокрЛП(" Убрать пробелы с двух сторон ")' в переменную "СтрокаБезПробела"
// {"СтрокаБезПробела": "Убрать пробелы с двух сторон"}

Можем сократить строку, оставив определенное количество символов слева, справа или посередине с помощью методов Лев(), Прав(), Сред():
И я запоминаю значение выражения 'Лев("Оставить 11 символов слева", 11)' в переменную "СокращеннаяСтрока"
// {"СокращеннаяСтрока": "Оставить 11"}
И я запоминаю значение выражения 'Прав("Оставить 6 символов справа", 6)' в переменную "СокращеннаяСтрока"
// {"СокращеннаяСтрока": "справа"}
И я запоминаю значение выражения 'Сред("Оставить часть строки в середине", 10, 12)' в переменную "СокращеннаяСтрока"
// {"СокращеннаяСтрока": "часть строки"}

Еще одна полезная возможность – это изменение регистра в тексте. Это особенно полезно в печатных формах, где нужно учитывать, что значения в ячейках могут быть написаны частично в верхнем регистре, а частично – в нижнем.
И Я запоминаю значение выражения 'НРег("Строка в НИЖНЕМ регистре")' в переменную "НижнийРегистр"
// {"НижнийРегистр": "строка в нижнем регистре"}
И Я запоминаю значение выражения 'ВРег("Строка в ВЕРХНЕМ регистре")' в переменную "ВерхнийРегистр"
// {"ВерхнийРегистр": "СТРОКА В ВЕРХНЕМ РЕГИСТРЕ"}
Или использовать титульный регистр, где каждое слово написано с заглавной буквы:
И Я запоминаю значение выражения 'ТРег("каждое слово с заглавной буквы")' в переменную "ТитульныйРегистр"
// {"ТитульныйРегистр": "Каждое Слово С Заглавной Буквы"}

Также полезный метод – СтрНайти(), позволяет найти символ или подстроку внутри строки, получая в итоге его порядковый номер: можно искать с начала, с конца или с определенного символа. Далее покажу на примере, для чего это может понадобиться:
И я запоминаю значение выражения 'СтрНайти("Найдем в строке слово поиск", "поиск", НаправлениеПоиска.СНачала)' в переменную "РезультатПоиска"
// {"РезультатПоиска": 23}
И я запоминаю значение выражения 'СтрНайти("Найдем в строке слово поиск", "поиск", НаправлениеПоиска.СКонца)' в переменную "РезультатПоиска"
// {"РезультатПоиска": 23}
И я запоминаю значение выражения 'СтрНайти("Найдем в строке слово Найдем", "Найдем", НаправлениеПоиска.СКонца, 6)' в переменную "РезультатПоиска"
// {"РезультатПоиска": 1}
Также можно учитывать номер вхождения – например, если у нас в исходной строке несколько одинаковых слов, то помимо направления поиска можно указать номер вхождения и найти необходимое нам слово.
И я запоминаю значение выражения 'СтрНайти("Найдем в строке слово Найдем", "Найдем", НаправлениеПоиска.СКонца, 3, 2)' в переменную "РезультатПоиска"
// {"РезультатПоиска": 1}

Также очень полезная вещь это замена в строке – можно заменить одно слово на другое.
И я запоминаю значение выражения 'СтрЗаменить("Заменим ОДНО слово на другое", "ОДНО", "ЭТО")' в переменную "Результат"
// {"Результат": "Заменим ЭТО слово на другое"}
И еще одна не менее полезная вещь для проверки печатных форм – это число прописью. Если у вас есть число, которое нужно вывести прописью, такая возможность тоже есть – плюс ее можно настроить под себя: с рублями, копейками и дробной частью.
И я запоминаю значение выражения 'ЧислоПрописью("123500,56", "л=ru_RU; р=рубль, рубля, рублей; м, копейка, копейки, копеек, ж, 2")' в переменную "СуммаПрописью"
// {"СуммаПрописью": "Сто двадцать три тысячи пятьсот рублей 56 копеек"}
И я запоминаю значение выражения 'ЧислоПрописью("123500,56", , , , , , , , , 2)' в переменную "СуммаПрописью"
// {"СуммаПрописью": "Сто двадцать три тысячи пятьсот рублей 56 копеек"}

Разберем работу со строками на практическом примере.
Допустим, в комментарии документа указана ссылка на другой документ. Но комментарий – это просто строка, перейти по ней напрямую нельзя. Однако мы можем извлечь номер документа из текста, открыть список документов, найти нужный и продолжить работу.
Например, строка выглядит так: «Создан роботом для документа Прием на работу 0000-0000000005 от 11.10.2025»
И я запоминаю в переменную "Строка" значение 'создан роботом для документа "Прием на работу 0000-0000000005 от 11.10.2025"'
// {"Строка": "создан роботом для документа \"Прием на работу 0000-0000000005 от 11.10.2025\""}
Чтобы достать номер, находим начало номера (предполагаем, что символ дефиса встречается в тексте только один раз в номере и смещаемся назад на четыре символа)
И я запоминаю значение выражения 'Число(СтрНайти($Строка$, "-", НаправлениеПоиска.СНачала) - 4)' в переменную "НачалоНомера"
// {"НачалоНомера": 47}
Зная, что номер всегда фиксированной длины (16 символов), вырезаем нужный фрагмент строки:
И я запоминаю значение выражения '$НачалоНомера$ + 16' в переменную "КонецНомера"
// {"КонецНомера": 63}
В итоге получаем номер документа в переменную:
И я запоминаю значение выражения 'Сред($Строка$, $НачалоНомера$, 16)' в переменную "НомерДокумента"
// {"НомерДокумента": "0000-0000000005"}

И последнее, но не менее важное для тестирования – это работа с датами. С ними в 1С тоже есть свои нюансы, давайте подробнее об этом поговорим.

Даты можно приводить к определенному формату с помощью одноименной функции Формат(). Можно получать дату в локальном формате, используя параметр ДЛФ, либо в произвольном – параметр ДФ.
Мне больше нравится произвольный формат, потому что в нем можно получить дату практически в любом виде: в цифровом через точку, с месяцем прописью, поменять порядок частей даты, добавить дополнительные символы («г.» и т.д.)
И я запоминаю значение выражения 'Формат(ТекущаяДата(), "ДЛФ=Д")' в переменную "Сегодня"
// {"Сегодня": "11.10.2025"}
И я запоминаю значение выражения 'Формат(ТекущаяДата(), "ДФ=дд.ММ.гггг")' в переменную "Сегодня"
// {"Сегодня": "11.10.2025"}
И я запоминаю значение выражения 'Формат(ТекущаяДата(), "ДЛФ=ДД")' в переменную "Сегодня"
// {"Сегодня": "11 октября 2025 г."}
И я запоминаю значение выражения 'Формат(ТекущаяДата(), "ДФ=\'дд мммм гггг\'\ г.\'")' в переменную "Сегодня"
// {"Сегодня": "11 октября 2025 г."}
И я запоминаю значение выражения 'Формат(ТекущаяДата(), "ДФ=\'ММММ гггг\'")' в переменную "ТекущийМесяцИГод"
// {"ТекущийМесяцИГод": "Октябрь 2025"}
Это неисчерпывающий список, вариантов гораздо больше.

Мы также можем прибавлять или вычитать дни относительно текущей даты, используя для этого арифметические операции и функцию ТекущаяДата().
Если нужно добавить один день, можно:
-
прибавить количество секунд в сутках;
-
либо использовать функцию
КонецДня()и добавить одну секунду.
Такой способ особенно удобен, если вы выводите дату в формате «День, Месяц, Год», но если важна точность до часов и минут, это надо учитывать.
Таким же образом можно вычитать дни:
И Я запоминаю значение выражения 'Формат(ТекущаяДата() + 86400, "ДФ=дд.ММ.гггг")' в переменную "Завтра"
И Я запоминаю значение выражения 'Формат(КонецДня(ТекущаяДата()) + 1, "ДФ=дд.ММ.гггг")' в переменную "Завтра"
И Я запоминаю значение выражения 'Формат(ТекущаяДата() - 86400, "ДФ=дд.ММ.гггг")' в переменную "Вчера"
И Я запоминаю значение выражения 'Формат(НачалоДня(ТекущаяДата()) - 1, "ДФ=дд.ММ.гггг")' в переменную "Вчера"
Помимо получения начала или конца дня можно получать начало или конец года, квартала, месяца, недели через функции:
-
НачалоГода(ТекущаяДата()) -
НачалоКвартала(ТекущаяДата()) -
НачалоМесяца(ТекущаяДата()) -
НачалоНедели(ТекущаяДата()) -
НачалоДня(ТекущаяДата()) -
НачалоЧаса(ТекущаяДата()) -
НачалоМинуты(ТекущаяДата())
Чтобы прибавить несколько дней, мы используем простую математическую операцию – умножаем количество дней на количество секунд в сутках и прибавляем к текущей дате (или отнимаем).
И я запоминаю значение выражения 'Формат(ТекущаяДата() + 7 * 86400, "ДФ=дд.ММ.гггг")' в переменную "ПлюсНеделя"
И я запоминаю значение выражения 'Формат(ТекущаяДата() - 7 * 86400, "ДФ=дд.ММ.гггг")' в переменную "МинусНеделя"

Отдельная полезная функция – ДобавитьМесяц(). С помощью этой функции можно как прибавлять месяцы, так и вычитать их через отрицательные значения.
Это важно, потому что количество дней в месяцах не постоянное, и при использовании сложения или вычитания дней можно установить некорректный месяц.

И последнее, что мы рассмотрим – это преобразование строки в дату.
Дело в том, что стандартные шаги по запоминанию значения даты с поля формы возвращают строковый тип переменной. Чтобы снова работать с ней как с датой, рекомендуется использовать БСП-шную функцию СтроковыеФункцииКлиентСервер.СтрокаВДату():
И я запоминаю значение выражения 'СтроковыеФункцииКлиентСервер.СтрокаВДату($Дата$)' в переменную "ДатаИзПоля"
Эти полезные приемы могут вам пригодиться при написании автотестов с помощью Vanessa Automation.
Вопросы и ответы
Вопрос по поводу таблиц для проверки движений. Не кажется ли вам, что было бы эффективнее если бы тестировщик вообще не задумывался о способах сравнения? Он ведь может просто прийти к разработчику, описать ему правила проверки и попросить сделать специальный шаг, в котором спрятаны все эти слои абстракции и который можно было вызвать одной строкой. Или тестировщик все-таки должен разбираться в этом и пытаться решать такие задачи самостоятельно?
В данном случае я считаю, что тестировщик вполне может сделать это сам. Да, на первый взгляд решение может выглядеть громоздко, но по факту нужно просто немного вникнуть и разобраться.
Когда мы идем к разработчику, мы тратим его врепмя, отвлекая от основных задач. Конечно, бывают ситуации, когда что-то действительно сложное или объемное – тогда логично подключать разработчика. Но конкретно такую задачу тестировщик вполне способен реализовать самостоятельно.
Вопрос по поводу проведения документов. Вы сказали, что сначала нужно создавать документ с реквизитом Проведен = False, а потом последней строкой перезаписывать его с Проведен = True. Не кажется ли вам, что корректнее проводить с помощью специального шага сценария? Вы же тогда при проведении документа сразу увидите ошибки, которые могут не возникнуть при программном создании.
Здесь важно понимать контекст. Речь идет о подготовке данных, а подготовку данных тестировать не нужно – она служебная. Например, если мы тестируем функциональность приема на работу, нам нужен сотрудник. Мы создаем его через подготовщик данных. Но самого сотрудника мы не тестируем – он лишь вспомогательная сущность.
Подготовка данных должна выполняться максимально быстро и не усложнять тест.
Как вы считаете, можно ли с помощью подготовщика данных выдернуть набор данных из одной базы данных, а потом с помощью Vanessa Automation создать их в другой базе данных?
Если структура этих баз идентична – имена реквизитов и их количество совпадает, то это вполне реально.
По сути, сгенерированные шаги в формате Gherkin здесь выступают в качестве сериализатора. Технические ограничения есть, но если структура конфигураций совместима, данные загрузятся корректно.
Более того, есть примеры, когда на Vanessa Automation реализовывали практически полноценный обмен данными – интерактивно, через пользовательские сценарии.
Что делать, если для подготовки данных нужно выгрузить регистр, в котором 10-30 тысяч записей? Есть ли у вас лайфхаки для таких задач?
Да, такая проблема есть. В основном, она связана с использованием нисходящих зависимостей – в этом случае действительно приходится долго ждать. Вместо этого мы сейчас нисходящие зависимости не используем, а просто проводим документ напрямую.
Также можно вручную создать таблицу Gherkin для регистра и указать только нужные поля, тем самым сократить объем данных.
Согласен, что гибких механизмов отбора в обработке не хватает, но это можно обойти.
Насколько глубоко, по-вашему, тестировщик должен уметь программировать?
Я считаю, что тестировщик должен разбираться в базовых шагах – знать, что такое условия и циклы, использовать простые выражения, потому что без них не обойтись. Рано или поздно тестировщик столкнется с необходимостью форматировать строки и работать с датами. Если он этого не знает – это можно довольно быстро освоить.
А дальше – по желанию. Кто хочет развиваться, постепенно углубляется в код.
А вообще в Vanessa Automation изначально заложена идея формирования собственной библиотеки шагов, которые как раз и готовят для команды более продвинутые специалисты.
Все эти нюансы можно вынести в экспортные шаги, которые остальные тестировщики будут использовать, как готовые шаги в библиотеке. Кроме этого, вы можете реализовать полноценный шаг в виде обработки.
Это классическая идея Gherkin – использовать предметно-ориентированную библиотеку шагов (ubiquitous language), предназначенную для тестирования конкретной предметной области. Отсюда и механизм экспортных сценариев, а также групповых шагов. Это позволяет реализовать шаги в терминах Геркина, не заходя в программирование. И это надо использовать.
Можно ли вместо библиотеки шагов организовать в репозитории папку с микрофичами – например, для сохранения файла или других часто используемых методов?
Да, вполне. Если есть повторяющиеся действия – их нужно выносить в переиспользуемые сценарии. Особенно если эти действия применимы для нескольких конфигураций.
Зачем для каждого проекта писать одно и то же с нуля, если это можно вынести в экспортные шаги, которые будут переиспользоваться всеми командами?
Вы рассказывали, что проверяли две табличные части в двух разных базах. Но я не понял, вы в одном фича-файле проверяли две базы или это все-таки два разных фича-файла? Как это практически делается?
Практически это один сценарий, где используется два цикла и есть промежуточные шаги по выгрузке и проверке, что документ корректно выгрузился, корректно загрузился. Но да, мы рассмотрели только финальную часть этого сценария – по проверке непосредственно движений.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.
Вступайте в нашу телеграмм-группу Инфостарт