












Как я перестал платить за API и подружился с браузерными ИИ (опыт 1С-разработчика в России)
Честный разбор DeepSeek, Perplexity, Google AI, Grok, Phind, Yandex GPT, GigaChat, Claude, Copilot, Codex, Ollama — с цифрами, кейсами и подводными камнями
Вступление: почему я вообще начал этим заниматься
Я 1С-разработчик, работаю в небольшой компании. Занимаюсь и доработкой типовых конфигураций, и написанием самописных систем — от УТ до ЗУП и самописного производства. Комп у меня обычный: i5, 16 GB RAM, видеокарта старая на 4 GB. Для 1С хватает, для локальных нейросетей — нет.
Раньше я использовал ChatGPT через API. Покупал доллары, пополнял счёт через крипту, потом через банк перестало работать. В итоге заморочек стало больше, чем пользы. Плюс счета иногда уходили в 30–50 долларов в месяц, если активно работал с большими модулями. При нашем курсе и зарплате это уже чувствительно.
Потом я попробовал поднимать локальные модели через Ollama. Думал, сейчас разверну себе DeepSeek-Coder 33B на компе, и буду парить в облаках. На практике оказалось, что "бесплатно" — это если у тебя есть железо за 200 тысяч. А у меня его нет.
В итоге я перешёл на браузерные ИИ. Они работают прямо в браузере, не требуют мощного компа, многие бесплатны, а по качеству часто не уступают платным API. За полгода я перепробовал почти всё, что доступно в РФ, и теперь могу сказать, кто на что способен в реальной работе с 1С.
DeepSeek: мой основной инструмент для больших модулей
DeepSeek я открыл случайно — кто-то из коллег скинул ссылку. Сказал: "Китайцы сделали модель с контекстом в миллион токенов". Я подумал, что это маркетинг, но решил проверить.
Как это работает на практике
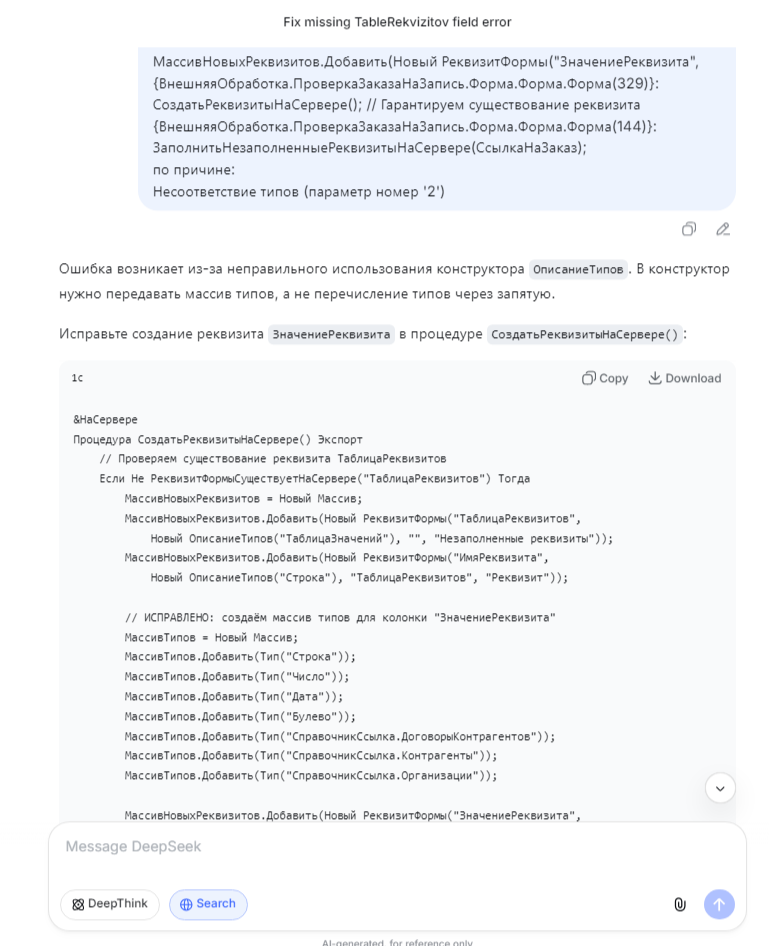
Я взял свой самый большой общий модуль — там было около 5800 строк. В нём куча процедур по работе с регистрами, сложные запросы, пересчёты. В обычных ИИ (ChatGPT, Claude в бесплатной версии) я бы не смог загрузить его целиком — приходилось бы резать на 4–5 частей и потом склеивать ответы.
DeepSeek проглотил его за секунду. Я попросил найти все места, где используется регистр "ОстаткиТоваров", и составить список процедур. Он выдал полный список с указанием строк, плюс заметил, что в одной процедуре регистр вызывается с неправильным набором измерений — там был лишний параметр, который я пропустил при рефакторинге. За 5 минут нашёл то, на что я бы потратил час ручного просмотра.
Глубокое мышление — это реально полезно
У DeepSeek есть фишка: он показывает, как "думал" перед ответом. Это не просто маркетинг, а реально помогает понять логику.
Например, я попросил переписать процедуру распределения затрат, которая работала медленно. Вместо того чтобы просто выдать код, он сначала написал:
-
"Исходная процедура делает три прохода по регистру, что даёт О(n * 3)
-
"Можно объединить в один проход с накоплением итогов."
-
"Предлагаю использовать временную таблицу для промежуточных расчётов."
И только потом выдал код. Причём код работал — после тестов время выполнения упало с 12 секунд до 2.5.
Ограничения, которые бесят
Главный минус DeepSeek — он обрезает диалог. Не по количеству токенов в сообщении, а по длине всей переписки. После 10–15 сообщений (зависит от объёма) он начинает "забывать" начало диалога. А если продолжить, то может вообще выдать ошибку и предложить начать новый чат.
Я нашёл лайфхак: если работаешь над большим проектом, нужно вести "сессионную" работу. Каждый новый модуль — новый чат. В начале чата кидаешь задание и модуль, получаешь ответ, сохраняешь его, и начинаешь новый чат для следующей задачи. Неудобно, но терпимо.
Ещё он иногда галлюцинирует на сложных запросах. Один раз он предложил использовать в запросе поле, которого в регистре не было. Я потратил 20 минут, чтобы понять, что это выдумка. Но в целом процент галлюцинаций ниже, чем у других бесплатных моделей.
Работа с файлами
DeepSeek в браузерной версии позволяет загружать файлы. Я пробовал загружать модули в формате .txt, .bsl, даже .epf — он их открывает и читает. Но есть лимит: файл не должен быть больше 50 МБ, хотя я больше 10 МБ и не встречал в 1С.
Можно загрузить несколько файлов за раз — я кидал сразу 3 модуля и просил найти пересечения. Он справлялся, но если файлов больше 5, начинал путаться.
Perplexity: поисковик с памятью, который не любит большие объёмы
Perplexity я использую как второй инструмент. Он хорош для поиска информации и долгих переписок.
Как я использую его в работе
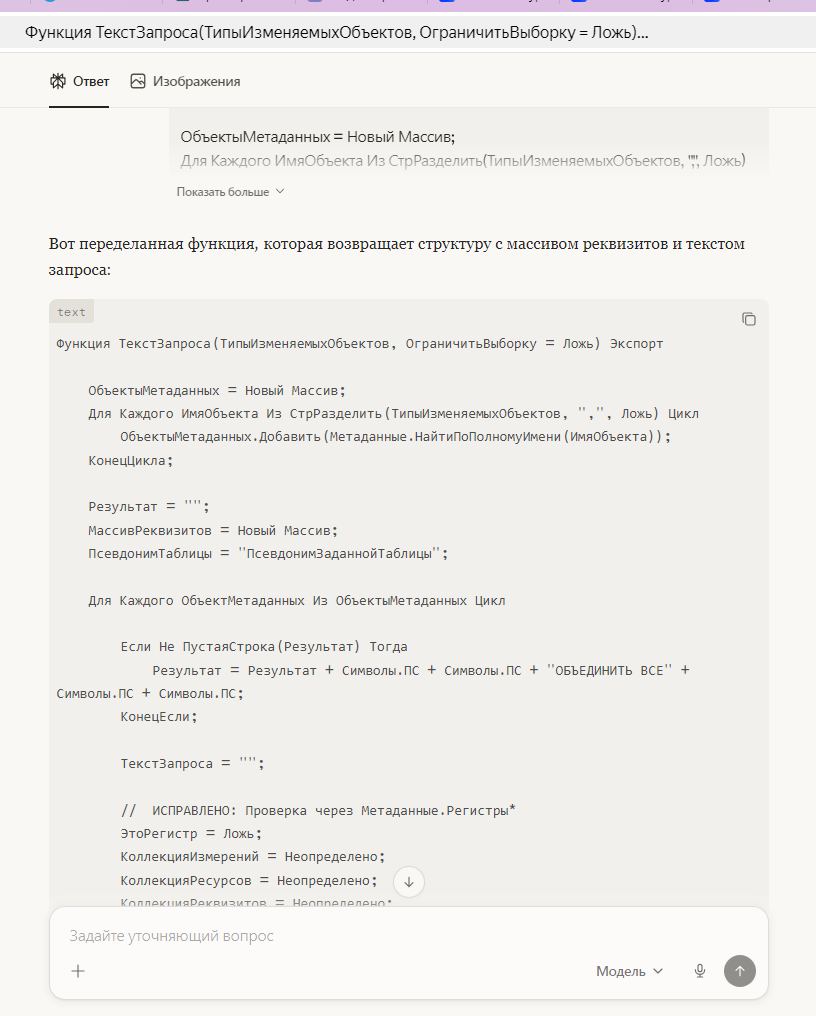
Недавно я переписывал обмен с маркетплейсом. В 1С была ошибка: при выгрузке заказов в Ozon дублировались отгрузки. Я закинул в Perplexity код процедуры (около 800 строк, больше он не берёт) и описал проблему.
Он не просто выдал исправление, а сначала нашёл в интернете свежие статьи по интеграции 1С с Ozon, выдал ссылки на форумы, процитировал документацию API. Потом проанализировал мой код и нашёл место, где не сбрасывался флаг отгрузки после успешной отправки. Итог: ошибка исправлена за час, хотя я сам копался бы полдня.
Где он бесит
Главная боль — он не берёт большие модули. Если код больше 700–800 строк, Perplexity начинает резать его сам, теряя контекст. Я пробовал загрузить модуль на 2000 строк — он разбил его на три части и анализировал отдельно. В итоге ответ был бессвязным, пришлось самому склеивать.
В бесплатной версии нельзя прикреплять много файлов. Лимит — 2–3 файла за раз. Если у меня конфигурация из 20 модулей, я не могу загрузить всё сразу. Приходится либо склеивать их в один файл, либо анализировать по одному.
Попытка передать больше одного файла получаем такой эррор.
Ещё в Perplexity есть "Pro search" — он включается автоматически, когда модель считает, что нужно искать в интернете. Это иногда раздражает, потому что на простые вопросы ("напиши мне шаблон отчёта СКД") он всё равно лезет в интернет и тащит кучу лишней информации.
Что хорошо
Долгая переписка — это реально круто. Я веду в Perplexity проектную переписку по одному модулю уже три недели. Мы обсуждаем архитектуру, я правлю код, кидаю новые версии, он помнит, что было в начале. В DeepSeek такой диалог уже 5 раз бы оборвался.
Поиск с цитатами — тоже полезно. Когда нужно сверить что-то с документацией или найти решение редкой проблемы, Perplexity выдаёт ссылки на первоисточники. Я могу открыть их и проверить, не галлюцинирует ли модель.
Google AI (Gemini): эрудит с микроскопическим контекстом
Gemini я использую редко, но иногда он выручает.
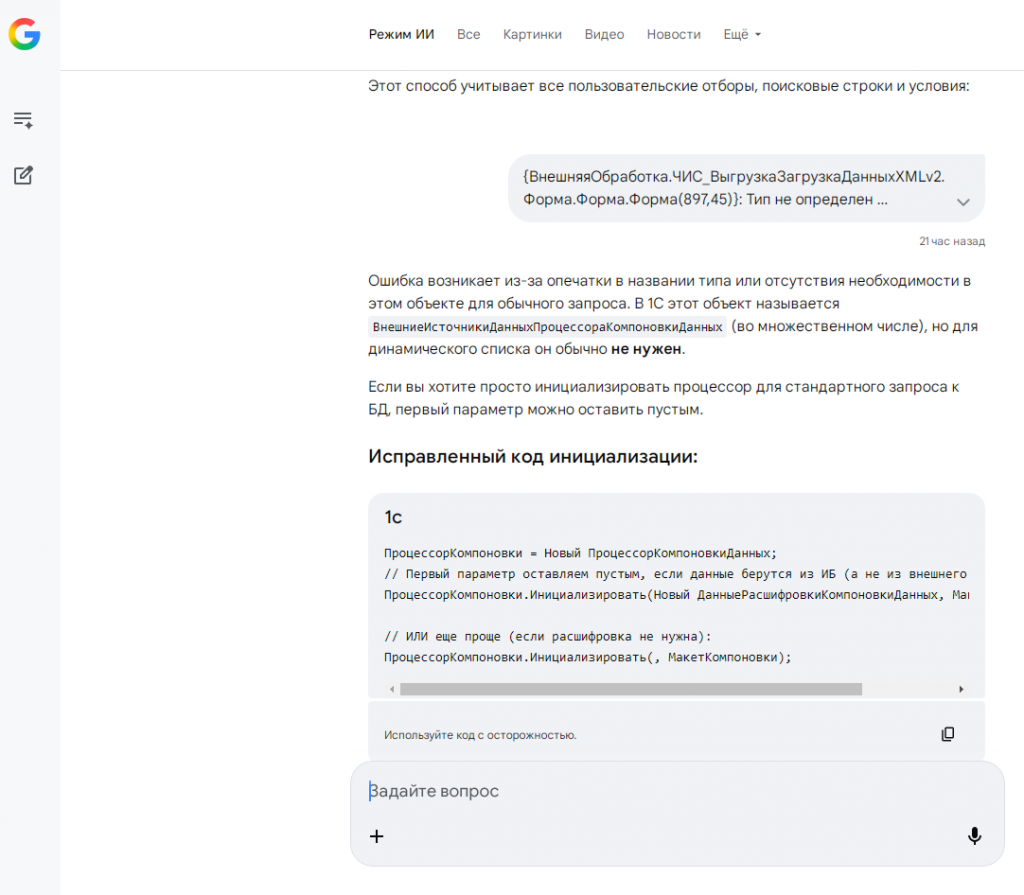
Когда он полезен
У Gemini огромная база знаний. Однажды я искал информацию по недокументированным параметрам метода "Записать" в справочниках 1С. DeepSeek и Perplexity дали общие ответы. Gemini выдал детальную информацию с примерами, ссылками на старые форумы и даже упомянул, в каких релизах эти параметры появились.
Ещё он умеет читать файлы из Google Drive. Я кидаю на диск документацию (инструкции, техкарты), даю ссылку, и Gemini анализирует. Это удобно, когда нужно быстро найти что-то в больших текстах.
Почему я им почти не пользуюсь
Контекст — катастрофа. Я пробовал загрузить модуль на 400 строк, Gemini выдал ошибку: "слишком длинный ввод". В 1С 400 строк — это маленькая процедура. Для анализа реального модуля он просто не годится.
В бесплатной версии он медленный. В часы пик ответа можно ждать 30–40 секунд. Причём часто он начинает отвечать, потом "задумывается" и выдаёт ошибку. Перезагружаешь, начинаешь заново — бесит.
Ещё у Gemini странная цензура. Однажды я спросил, как оптимизировать запрос, который выполняется 20 секунд. Он отказался отвечать, сказав, что "не может рекомендовать оптимизации, влияющие на производительность". Что за бред? В итоге я задал тот же вопрос DeepSeek и получил нормальный ответ.
Grok: свобода и никаких лимитов
Grok я начал использовать недавно
Что меня подкупило
Нет лимитов на файлы. Я закинул в Grok 15 модулей (общей суммой около 8000 строк) и попросил найти дублирование кода. Он обработал всё за пару минут и выдал список из 12 мест, где код повторяется. В других ИИ я бы или не смог загрузить столько, или пришлось бы платить.

Нет лимитов на длину переписки. Я веду в Grok переписку по одному проекту уже месяц. Мы обсуждаем архитектуру, я правлю код, кидаю новые версии. Он всё помнит, не обрезает.
Минимум цензуры. Однажды мне понадобилось сгенерировать запрос на прямую модификацию базы через COM-соединение (для миграции данных из старой базы). Yandex GPT и GigaChat заблокировали запрос. Gemini выдал отписку. DeepSeek ответил, но с оговорками. Grok просто написал работающий код.
Что бесит
В РФ он заблокирован.
Требует подписки X Premium. Бесплатный доступ в X (Twitter) — это игрушка, там жёсткие лимиты. Полноценная версия стоит 8–16 долларов в месяц.
Нет встроенного поиска в бесплатной версии. Если нужно найти что-то актуальное, приходится копировать ссылки вручную.
RIP Phind: визуализация и технарика, но под колпаком
Phind был очень крут но увы не выдержал конкуренции
Phind я использую, когда нужно нарисовать схему или быстро найти техническую информацию.
Блок-схемы — его сильная сторона
Я попросил Phind нарисовать блок-схему алгоритма распределения затрат. Он не просто выдал текст, а сгенерировал описание в формате Mermaid, которое я вставил в Markdown и получил визуальную схему. Потом я вставил эту схему в документацию к проекту — получилось наглядно.
Ещё он умеет объяснять код. Я закинул модуль с кучей вложенных запросов, и он построил дерево вызовов, показал, какие таблицы откуда берутся. Это помогло найти узкое место.
Цензура — это жесть
Однажды я спросил, как обойти защиту от модификации в 1С (для легальной отладки собственного кода). Phind выдал: "Я не могу помочь с этим запросом". В DeepSeek я получил нормальный ответ с пояснением, как снять защиту в конфигураторе.
Таких случаев было много. Любой запрос, который касается "обхода", "взлома", "недокументированных функций", Phind блокирует или даёт общий ответ без конкретики.
Лимиты
По длине кода — средние. Модуль на 2000 строк он ещё переваривает, но 3000 — уже проблема. Начинает резать или выдавать ошибку.
Файлы загружать можно, но я заметил, что он хуже работает с 1С-кодом, чем DeepSeek. Часто путает синтаксис, предлагает конструкции, которых в 1С нет.
Яндекс GPT и GigaChat: наши, родные, но не для 1С

Пробовал оба. Честно говоря, разочаровался.
Яндекс GPT
Плюсы:
-
Хорошо понимает русский язык, формулировки естественные.
-
Интеграция с Поиском — если нужно найти что-то в рунете, он справляется.
-
Работает напрямую
Минусы:
-
Контекст — строк 500–600, дальше всё. Для 1С это несерьёзно.
-
Нет загрузки файлов в бесплатной версии. Только копипаст.
-
Цензура — на любой "опасный" запрос (даже про оптимизацию запросов) может выдать отписку.
-
Платный API — если хочешь нормально работать, толкают в API с оплатой за токены.
Я попробовал загрузить в него модуль на 1000 строк через копипаст — он просто обрезал код и проанализировал только первые 500 строк. Бесполезно.
GigaChat
Плюсы:
-
Стабилен в РФ, не блокируется. -
Иза блокировки телеграмма постоянно приходится пользаватся VPN что не есть удобно
-
Для госсектора может быть плюсом — обещают соответствие 152-ФЗ.
-
Генерация изображений
Минусы:
-
Контекст ещё меньше — 300–400 строк.
-
Цензура жёсткая, отвечает как чиновник: много слов, мало смысла.
-
Толкает в платный API, цены сопоставимы с зарубежными, а качество ниже.
Я задал GigaChat вопрос про оптимизацию регистра расчётов. Он выдал общие фразы про "использование индексов" и "правильную настройку измерений". В DeepSeek я получил конкретный код с пояснениями, как переписать запрос.
Claude, Copilot, Codex: мощные, но доступ в РФ ограничен и требует деньги
Эти инструменты я пробовал, но быстро понял, что для 1С и для жизни в РФ они — овчинка выделки не стоит.
Claude
Claude реально мощный. Контекст 200 000 токенов — это можно загрузить документацию на весь проект. Проекты (Projects) — удобная штука: создаёшь папку, заливаешь туда модули, инструкции, и Claude работает в этом контексте.
Но:
-
В РФ заблокирован.
-
Бесплатная версия даёт 30–100 сообщений в день (сброс каждые 5 часов). Если активно работать, лимит заканчивается за пару часов.
-
Платная — $20/мес. Оплатить из России можно через крипту или зарубежную карту, но это геморрой.
-
1С он знает слабо. Я пробовал загружать модули — синтаксис понимает, но специфику платформы (регистры, СКД) часто путает.
GitHub Copilot
Copilot я пробовал в VS Code с расширением 1C. Подсказки появлялись, но часто были нерелевантными. Он предлагал конструкции из Python или JS, которые в 1С не работают.
Бесплатная версия — 2000 автодополнений в месяц. Это на день-два работы. Платная — $10–39/мес, оплатить из России проблема.
Плюс для установки и авторизации. GitHub периодически блокирует доступ из РФ.
OpenAI Codex
Codex — это отдельная история. Модель GPT-5.3-Codex сейчас считается одной из лучших для программирования. Но:
-
В РФ официально недоступен. Нужена зарубежная карта.
-
Оплата API — в долларах, цены не детские.
-
1С он не знает. Обучался на открытых репозиториях, где 1С почти нет.
Vibe coding
Модное слово. Суть: ты описываешь задачу на русском, ИИ (Replit, Bolt.new, Lovable) генерирует готовое приложение на JavaScript/Python/React.
Для 1С это бесполезно — он не генерирует наш язык. Плюс большинство этих сервисов в РФ заблокированы. Я пробовал Bolt.new — он сгенерировал красивый фронтенд на React, но мне-то нужен был модуль обмена для 1С.
Ollama: когда хочется всё своё, но железо не тянет
Я потратил на эксперименты с Ollama две недели. Скачал, установил, попробовал несколько моделей.
Что получилось
Модели 7B (Mistral, Qwen 7B) на моём 16 GB RAM запускаются. Но:
-
Скорость — 2–3 токена в секунду. Это значит, что ответ на 500 слов ждёшь минуту.
-
Контекст — модель заявляет 8–32K токенов, но на практике при большом контексте скорость падает до 0.5 токена/сек.
-
Качество — квантованные модели (Q4, Q5) тупят. Я загрузил модуль на 2000 строк, модель начала галлюцинировать, придумывать несуществующие процедуры.
Модели 33B (DeepSeek-Coder 33B, Qwen 32B) на моём железе не запускаются вообще. Нужна видеокарта с 24 GB VRAM (RTX 3090/4090) или 64 GB RAM для квантованной версии. Стоимость такого железа — от 100–200 тысяч рублей.
Про обучение
Я думал, что смогу дообучить модель на своих модулях 1С. Быстро понял, что это нереально:
-
Full fine-tuning требует видеокарты с 24–80 GB VRAM и тысяч размеченных примеров.
-
LoRA/QLoRA — проще, но всё равно нужен GPU с 12–24 GB VRAM и время на настройку.
-
Проще всего — RAG (векторная база). Я развернул Chroma, добавил туда свои модули, подключил через Ollama. Это работает, но модель всё равно не "обучается", а просто ищет похожие куски кода. Качество — ниже, чем у браузерного DeepSeek.
Вердикт
Если у вас есть мощный игровой комп с RTX 3090/4090 — можно попробовать. Для обычного 1С-разработчика с рабочим компьютером Ollama — это дорого, сложно и результат хуже, чем у бесплатного DeepSeek.
Моя итоговая таблица
| Инструмент | Для чего использую | Что бесит | Доступ в РФ | Сколько денег |
|---|---|---|---|---|
| DeepSeek | Анализ больших модулей (до 6000 строк), рефакторинг, сложные алгоритмы | Обрезает диалог, иногда галлюцинирует | Да | 0 рублей |
| Perplexity | Поиск с источниками, долгие переписки по проекту | Не берёт большие модули, мало файлов | Да | 0 / Pro 20$ |
| Google AI (Gemini) | Теоретические воп
росы, быстрый поиск по документации |
Контекст 300 строк, медленный, цензура | Да | 0 / API платно |
| Grok | Нет лимитов на файлы, минимум цензуры, долгие проекты | Доступ ограничен, подписка, нет поиска в бесплатной | Нет | Подписка X Premium |
| Yandex GPT | Русскоязычные вопросы, интеграция с поиском | Малый контекст, нет файлов, толкает в API | Да | 0 / API платно |
| GigaChat | Если нужно "по закону" | Очень малый контекст, цензура, API | Да | 0 / API платно |
| Claude | Когда нужно загрузить кучу документации (200K токенов) | Доступ ограничен в РФ, лимиты сообщений, сложная оплата | Нет | 0 (лимит) / 20$ |
| GitHub Copilot | — | Не знает 1С, Доступ ограничен в РФ, платно | Нет | 10–39$/мес |
| Ollama | — | Нужно мощное железо, настройка, ниже качество | Локально | Железо своё |
Что я использую сейчас
Коллеги, я перепробовал кучу вариантов. Вот мой финальный стек:
-
DeepSeek — для 80% задач. Большие модули, сложные алгоритмы, рефакторинг. Бесплатно, Доступ в РФ не ограничен.
-
Perplexity — когда нужен поиск с источниками или долгая переписка по проекту.
-
Phind — если нужно нарисовать блок-схему или визуализировать логику.
-
Claude / Grok — если совсем прижмёт но Доступ ограничен в РФ
Отечественные Yandex GPT и GigaChat я не использую — малый контекст и неудобно работать с кодом. Локальные модели (Ollama) забросил — железо не тянет, а результат хуже.
Для меньших галлюцинации в работе с браузерными ИИ им нужно передавать контекст метаданных я использую данный инструмент --> "Meta1C AI Bridge",
в процессе генерации N попыток ИИ дают множество вариантов процедур, что замусоривают код, появляются лишние процедуры и функции. нахождение таких функции так же помогает--> "Meta1C AI Bridge"
P.S. Я в курсе, что власти готовят законы, которые могут ограничить зарубежные ИИ. Китайские модели (DeepSeek, Qwen) пока вне зоны риска. Если DeepSeek заблокируют — буду искать дальше. Пока он мой главный помощник.
Если у вас есть свои лайфхаки — как платить за Claude из России, как заставить Copilot понимать 1С, как разогнать Ollama на 16 GB RAM — пишите. Я открыт к экспериментам.
Удачи с кодингом.
Вступайте в нашу телеграмм-группу Инфостарт