

{kind=link}
Почему не векторная база с деревом
Первый вопрос, который возникает при проектировании RAG: почему не использовать специализированную векторную базу (Qdrant, Weaviate, Pinecone) с иерархическим деревом документов?
Причина 1: документ 1С не самодостаточен без контекста.
Например, статья из документации о конфигурации Зарплата и управление персоналом может называться «Настройка» — а в контексте статьи нет отсылки, о чем она. Объект конфигурации Справочник.Сотрудники имеет смысл только в связке с реквизитами, табличными частями и модулями. Дерево в векторной базе не решает эту проблему — оно лишь добавляет навигацию, но не контекст внутри чанка.
Также стоить отметить, что дерево в векторной базе хорошо для статичной информации, когда нет постоянных изменений, обновлений информации, а уж тем более конфигураций 1С. Например, “Библиотека стандартных подсистем” - множество релизов, или описание синтаксиса языка 1С (новые методы, свойства, обработчики постоянно добавляются с выходом платформы).
Решение: хлебные крошки прямо в тексте чанка — heading_path вшивается в начало каждого чанка при индексировании, и модель эмбеддингов сразу видит полный контекст. Они могут быть как перечнем структуры разделов, текстовым ключом для связки, ключ описания объекта метаданных.
Причина 2: стоимость обновления.
Документация по 1С обновляется регулярно. При изменении статьи нужно пересчитать эмбеддинги затронутых чанков. В специализированной векторной базе это дополнительные затраты пересборки дерева. В нашем случае PostgreSQL с расширением pgvector уже используется как основная БД — добавить колонку embedding halfvec(1024) к таблице article_chunks значительно дешевле.
Слой 1: Построение чанков с хлебными крошками
Первый и самый важный слой — правильное разбиение статей на чанки. Плохой чанк испортит всё последующее ранжирование.
Алгоритм split_markdown_into_chunks
def split_markdown_into_chunks(
text: str,
max_len: int = 800,
overlap: int = 220,
include_heading_path: str = "full_path",
) -> list[str]:
"""
Markdown-aware разбиение текста на чанки для RAG.
1. Убирает YAML frontmatter
2. Разбивает по заголовкам (#, ##, ###)
3. Секции > max_len разбиваются по абзацам
4. Блоки кода не разрываются
5. Добавляет overlap между соседними чанками
"""
body = _strip_frontmatter(text)
sections = _split_by_headers(body)
chunks: list[str] = []
for section, heading_path, current_heading in sections:
# heading_path = ["Зарплата", "Начисление", "Настройка НДФЛ"]
context_heading = " > ".join(heading_path) # режим full_path
section_with_context = f"{context_heading}\n\n{section}"
if len(section_with_context) <= max_len:
chunks.append(section_with_context)
else:
sub_chunks = _split_section_by_paragraphs(section_with_context, max_len)
chunks.extend(sub_chunks)
return _add_overlap(chunks, overlap)
Ключевое решение — режим full_path: в начало каждого чанка добавляется полная цепочка заголовков. Например:
Зарплата и управление персоналом > Начисление зарплаты > Настройка НДФЛ
Для корректного расчёта НДФЛ необходимо указать ставку налога...
Это позволяет модели эмбеддингов понять контекст даже для коротких технических фрагментов.
Индексирование с хлебными крошками
При сохранении чанка в БД heading_path сохраняется отдельно в поле meta — для последующей фильтрации и формирования ссылок:
embed_input = (
f"{chunk_record['heading_path']}\n\n{chunk_text}"
if chunk_record["heading_path"]
else chunk_text
)
chunk_embedding = await embed_text(embed_input)
chunk_obj = ArticleChunk(
article_id=article_id,
chunk_text=chunk_text,
embedding=chunk_embedding,
meta={
"chunk_index": idx,
"total_chunks": total_chunks,
"heading_path": chunk_record["heading_path"],
"heading_level": chunk_record["heading_level"],
},
)
Обратите внимание: в эмбеддинг подаётся heading_path + chunk_text, а в БД хранится только chunk_text.
Это позволяет при поиске использовать семантику заголовков, не раздувая хранимый текст.
Слой 2: Redis — кеш эмбеддингов запросов
Генерация эмбеддинга через локальную LM Studio модель (text-embedding-qwen3-embedding-4b) занимает 50–200 мс. При повторяющихся запросах (а в RAG-системе агенты часто задают похожие вопросы) это накапливается.
Решение: Redis-кеш эмбеддингов с TTL.
def _cache_key(text: str, model: str, dimensions: int | None) -> str:
"""SHA256 от model:dimensions:text — инвалидируется при смене модели."""
payload = f"{model}:{dimensions}:{text}"
return "embed:" + hashlib.sha256(payload.encode()).hexdigest()
async def cache_get(text: str, model: str, dimensions: int | None) -> list[float] | None:
r = get_redis()
if r is None:
return None
try:
data = await r.get(_cache_key(text, model, dimensions))
return json.loads(data) if data else None
except Exception:
return None
Интеграция в embed_text:
async def embed_text(text: str) -> list[float]:
model = _get_embed_model_name()
dims = _get_embed_dimensions()
# Проверяем Redis-кеш перед вызовом API
if _cache_enabled():
cached = await cache_get(input_text, model, dims)
if cached is not None:
return cached # cache hit — 0 мс вместо 100+ мс
response = await to_thread(client.embeddings.create, model=model, input=input_text)
vector = response.data[0].embedding
if _cache_enabled():
await cache_set(input_text, model, dims, vector, _cache_ttl())
return vector
Ключ кеша включает имя модели и размерность — при смене модели эмбеддингов старые записи автоматически становятся невалидными.
Слой 3: Векторный поиск (pgvector)
Основной поиск — косинусное расстояние через оператор <=> расширения pgvector. Используется тип halfvec для экономии памяти (16-битные float вместо 32-битных):
SELECT
ac.id,
ac.article_id,
ac.chunk_text,
ac.meta,
ac.embedding::halfvec(1024) <=> CAST(:query_embedding AS halfvec(1024)) AS distance
FROM article_chunks ac
INNER JOIN articles a ON ac.article_id = a.id
WHERE a.job_id IN (
SELECT id FROM jobs WHERE load_mode IN ('hbk', 'docs')
)
AND a.destination = :destination
ORDER BY distance
LIMIT :limit;
score = 1 - distance — чем ближе к 1, тем релевантнее чанк.
Слой 4: RRF (Reciprocal Rank Fusion)
Векторный поиск хорошо находит семантически близкие тексты, но плохо работает с точными терминами — например, &НаКлиентеНаСервере или УстановитьПривилегированныйРежим. Для таких запросов нужен полнотекстовый поиск (FTS).
RRF объединяет два ранжированных списка — векторный и FTS — без необходимости нормализовывать их оценки к единой шкале:
@staticmethod
def _rrf_merge(
vector_results: list[dict],
fts_results: list[dict],
top_k: int,
k: int = 60,
) -> list[dict]:
"""
score_rrf = 1/(k + rank_vector) + 1/(k + rank_fts)
k=60
"""
scores: dict[int, float] = {}
items: dict[int, dict] = {}
for rank, item in enumerate(vector_results, start=1):
chunk_id = item["id"]
scores[chunk_id] = scores.get(chunk_id, 0.0) + 1.0 / (k + rank)
items[chunk_id] = item
for rank, item in enumerate(fts_results, start=1):
chunk_id = item["id"]
scores[chunk_id] = scores.get(chunk_id, 0.0) + 1.0 / (k + rank)
if chunk_id not in items:
items[chunk_id] = item
sorted_ids = sorted(scores, key=lambda cid: scores[cid], reverse=True)
# Нормализация min-max для совместимости со шкалой cosine score
s_min, s_max = min(scores.values()), max(scores.values())
score_range = s_max - s_min if s_max > s_min else 1.0
result = []
for cid in sorted_ids[:top_k]:
entry = dict(items[cid])
entry["score"] = round((scores[cid] - s_min) / score_range, 6)
result.append(entry)
return result
Документ, найденный обоими методами, получает два слагаемых и поднимается выше. Документ только из одного списка — одно слагаемое.
Подмешивание чанков встроенного языка 1С (HBK-буст)
Если агент вызвал инструмент без фильтра по разделам статей к результатам RRF добавляются топ-чанки из описания встроенного языка 1С (load_mode='hbk'). Это критично: если агент спрашивает «как работает ТаблицаЗначений», он хочет увидеть описание из синтакс-помощника, а не только сводные статьи 1С.
# При поиске без destination подмешиваем HBK-чанки
if destination is None:
hbk_items = self._hbk_boost_search(query, query_emb, hbk_limit, release)
existing_ids = {item["id"] for item in merged}
boost_items = [item for item in hbk_items if item["id"] not in existing_ids]
merged = boost_items[:boost_count] + merged # HBK-чанки в начало
Слой 5: BM25 Reranking (опционально)
После RRF у нас есть 50–100 кандидатов. BM25 reranker уточняет их порядок, учитывая точное совпадение терминов запроса с текстом чанка.
Когда BM25 помогает
BM25 особенно эффективен, когда:
-
Запрос содержит специфические термины 1С (
ОбщийМодуль,РегистрСведений,&НаСервере) -
Запрос содержит точные имена объектов (
Справочник.Номенклатура) -
Векторная модель «размывает» смысл коротких технических запросов
Токенизация для 1С
Стандартная токенизация не подходит для технической документации 1С. Реализована специальная:
GUID_RE = re.compile(r"\b[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}\b", re.I)
VERSION_RE = re.compile(r"\bv?8\.\d+(?:\.\d+){1,3}\b", re.I)
DIRECTIVE_RE = re.compile(r"[&\#][А-ЯA-Z][А-ЯёA-Za-z0-9_]*", re.I)
def _tokenize(self, text: str, expand_query: bool = False) -> list[str]:
"""
Токенизация для русского языка и технической документации 1С.
- GUID и версии платформы как «якорные» токены
- Директивы препроцессора (&НаКлиенте, #Если)
- Разбивка CamelCase, snake_case, dotted.names
- Расширение по словарю сокращений 1С (только для запроса)
"""
text = _norm_text(text) # ёU94;е, 1cU94;1с, унификация тире
out = []
# Якорные токены — важны для точного матча
for g in GUID_RE.findall(text):
out.append(g.lower())
for v in VERSION_RE.findall(text):
out.append(v.lower())
for d in DIRECTIVE_RE.findall(text):
out.append(d.lower())
for t in TOKEN_RE.findall(text):
if t in RU_STOP or (len(t) == 1 and not t.isdigit()):
continue
# Разбиваем идентификаторы: ОбщийМодуль.Процедура U94; ["общиймодуль", "процедура"]
for p in _split_identifier(t):
out.append(p.lower())
return out
Комбинирование векторного и BM25 score
def rerank(self, query: str, candidates: list[dict], top_k: int,
vector_weight: float = 0.6, bm25_weight: float = 0.4) -> list[dict]:
query_tokens = self._tokenize(query, expand_query=True)
bm25_scores = self.bm25.get_scores(query_tokens)
# Нормализация BM25 к [0, 1]
max_bm25 = max(bm25_scores) if len(bm25_scores) > 0 else 1.0
normalized_bm25 = [
min(s / max(max_bm25, 10.0), 1.0) if s > 0 else 0.0
for s in bm25_scores
]
reranked = []
for i, candidate in enumerate(candidates):
vector_score = candidate.get("score", 0.0)
bm25_score = normalized_bm25[i]
# Взвешенное среднее: 60% вектор + 40% BM25
combined = vector_weight * vector_score + bm25_weight * bm25_score
reranked.append({**candidate, "score": combined,
"vector_score": vector_score, "bm25_score": bm25_score})
reranked.sort(key=lambda x: x["score"], reverse=True)
return reranked[:top_k]
Веса 1.2 / 1.0 подобраны эмпирически на тестовых запросах. При необходимости настраиваются через переменные окружения VECTOR_SCORE_WEIGHT и BM25_SCORE_WEIGHT.
Слой 6: Cross-encoder реранжинг по эмбеддингам
После BM25 reranking (опционально) применяется более дорогой, но точный cross-encoder — модель (bge-reranker-v2-m3), которая оценивает пару (запрос, чанк) совместно, а не по отдельности.
Когда используется: На слабом железе этот шаг опционален — он добавляет 200–500 мс на запрос.
Когда помогает: cross-encoder видит взаимодействие между запросом и текстом и лучше оценивает релевантность для длинных, многосмысловых запросов.
# Применяется после BM25, к топ-N кандидатам
if use_embed_reranker and self.embed_reranker:
embed_opts = get_embed_rerank_settings(self.db)
if embed_opts["enable_embed_reranker"] and embed_opts["model"]:
results = await self.embed_reranker.rerank(
query=query,
candidates=results[:embed_opts["candidates"]],
top_k=top_k,
model=embed_opts["model"],
base_url=embed_opts["base_url"],
endpoint=embed_opts.get("endpoint", "rerank"),
)
Слой 7: Постобработка через рассуждающую модель
Финальный слой — RagPostprocessor. Он принимает топ-K чанков и формирует структурированный ответ через LLM с рассуждением.
Зачем нужен: чанки — это фрагменты документации. Пользователь хочет готовый ответ, а не список отрывков. Постпроцессор:
-
Синтезирует ответ из нескольких чанков
-
Выделяет ключевые тезисы (
key_points) -
Формирует список источников (
sources) со ссылками -
Добавляет предупреждения (
warnings) при противоречиях
Контракт ответа:
def normalize_rag_to_contract(semantic_result: dict, postprocess_used: bool = False) -> dict:
"""
Контракт: {
"answer": str,
"key_points": list,
"sources": list,
"warnings": list,
"postprocess_used": bool
}
"""
Для длинных ответов используется стратегия Map-Reduce:
-
Map: каждый батч чанков обрабатывается отдельно
-
Reduce: промежуточные ответы объединяются в финальный
Зачем кешировать результаты постобработки:
Постобработка — самый дорогой шаг, поэтому лучше кешировать результаты запрос-ответ
def build_cache_key(
query: str,
rag_result: dict,
rag_postprocess_model: str,
rag_postprocess_temperature: float,
rag_postprocess_context_window: int,
) -> str:
"""
Детерминированный ключ: SHA256 от (запрос + чанки + параметры модели).
При изменении любого параметра — промах кеша.
"""
payload = {
"query": query.strip(),
"rag_result": _normalize_rag_result(rag_result),
"rag_postprocess_model": rag_postprocess_model.strip(),
"rag_postprocess_temperature": float(rag_postprocess_temperature),
"rag_postprocess_context_window": int(rag_postprocess_context_window),
}
raw = json.dumps(payload, sort_keys=True, ensure_ascii=False)
return hashlib.sha256(raw.encode("utf-8")).hexdigest()
Ключ кеша включает параметры модели — при смене модели или температуры старые записи автоматически инвалидируются.
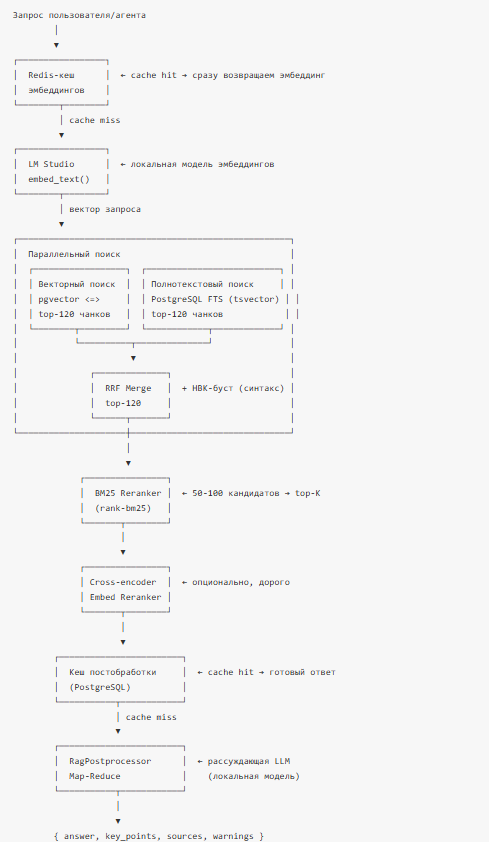
Полная схема RAG-пайплайна
Итоги
Каждый слой решает конкретную проблему:
|
Слой |
Проблема |
Решение |
|---|---|---|
|
Хлебные крошки |
Чанк без контекста непонятен |
|
|
Redis-кеш эмбеддингов |
Повторные запросы медленные |
TTL-кеш по SHA256 от текста+модели |
|
pgvector |
Семантический поиск |
|
|
RRF |
Точные термины теряются |
Объединение векторного + FTS |
|
HBK-буст |
Синтаксис 1С не находится |
Подмешивание чанков из синтакс-помощника |
|
BM25 |
Неточное ранжирование терминов |
Взвешенное среднее vector+BM25 |
|
Cross-encoder |
Многосмысловые запросы |
Совместная оценка пары (запрос, чанк) |
|
Постобработка |
Чанки ≠ готовый ответ |
Map-Reduce через рассуждающую LLM |
|
Кеш постобработки |
LLM медленная |
SHA256 от (запрос + чанки + параметры) |
Всё это работает на ноутбуке MSI Katana HX: Intel Core i5-14450HX (2.40 GHz), ОЗУ 32 ГБ, NVidia GeForce RTX 4060 (8 Гб) Ti Laptop GPU. — локальная модель для эмбеддингов (text-embedding-qwen3-embedding-4b) через LM Studio.
-
PostgreSQL v17 в Docker.
-
модель для Cross-encoder (bge-reranker-v2-m3) в Docker с отдельным эндпойнтом /v1/reranker.
-
Redis для кеша в Docker.
-
модель для Постобработки (qwen3.6-plus-preview) через openrouter.ai.
В базе:
-
разделов ~ 30: загруженные книги, встроенный синтаксис помощник, полное руководство платформы 1С, различные библиотеки (Библиотека стандартных подсистем, Библиотека интернет-поддержки пользователей и.т.п.), разнородная информация с профильных сайтов, различные конфигурации 1С.
-
статей ~ 80, 000
-
чанков ~ 1 500 000
-
информация о кодовой базе различных конфигураций ~ 5 000 000.
На вопрос “какой latency?” - мне хватает)
-
для documents1c ~ 25 секунд по всему пайплайну, основная боль это постобработка.
-
для metadata1c ~ 6 секунд, т.к. там урезанный пайплайн.
Ну и не забываем, это все крутится на ноутбуке.
Всем удачи при проектировании RAG для 1С!
Вступайте в нашу телеграмм-группу Инфостарт