В этой статье я расскажу, с какими проблемами мы столкнулись в начале внедрения автоматизации, как их решали и к каким итогам пришли.
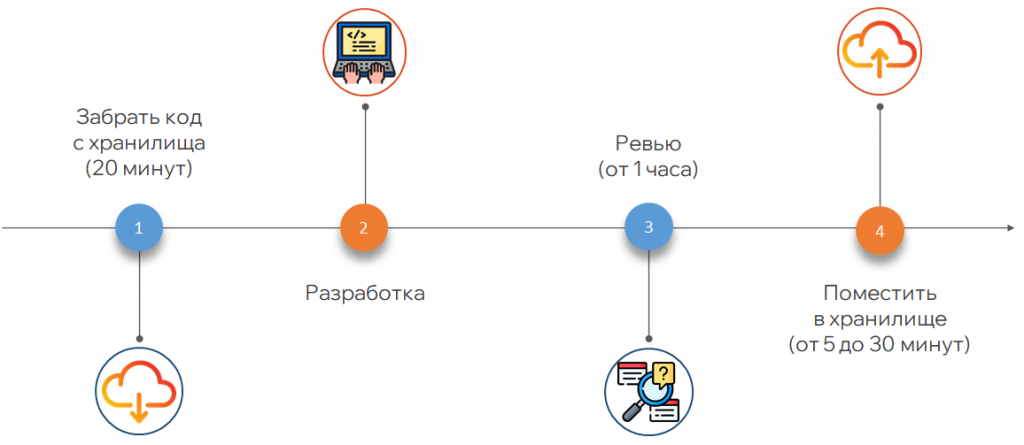
На старте была неудобная работа с хранилищем. Хранилище работало в файловом варианте: оно лежит где-то в папке и из него неудобно получать код. Получение данных занимало 30 и более минут.
Команда росла, нужно было переключаться между задачами. Становилось непонятно, где хранить доработанный код, как его фиксировать. Если нескольким разработчикам нужно вести работу над одной задачей, процесс тоже становился неудобным.
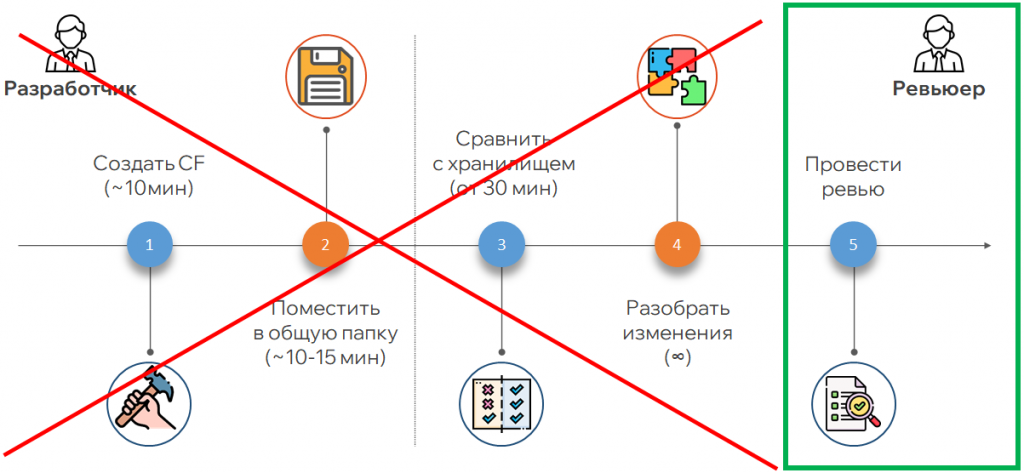
Ревью включало множество лишних действий. Процесс помещения объектов в хранилище был долгим: нужно захватывать все объекты, которые планируешь дорабатывать. Если кто-то захватил объект и ушел в отпуск, работа блокировалась.
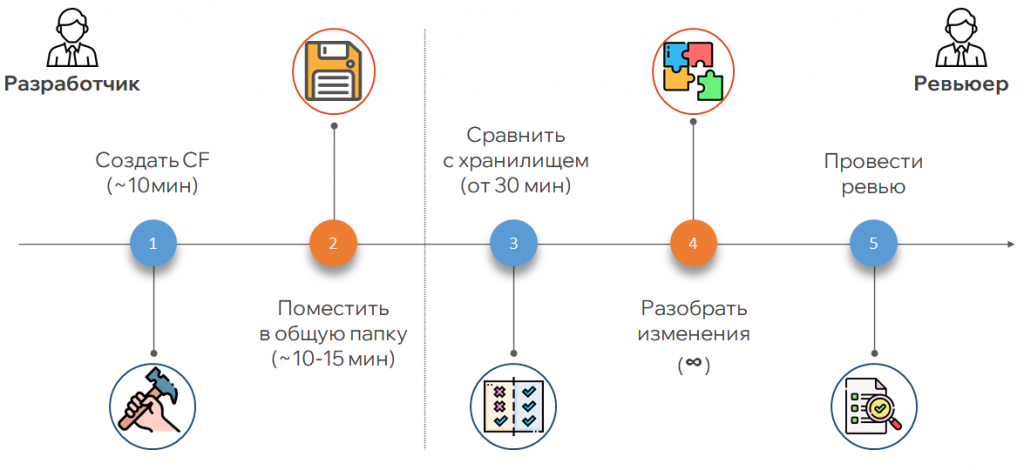
Код-ревью тормозил процесс из-за большого количества ручных операций. Чтобы отдать задачу на проверку, нужно было создать cf-файл, поместить его в общую папку, где иногда не хватало места. Ревьюер забирал файл, сравнивал его с хранилищем и смотрел изменения. Они могли отличаться, и приходилось дополнительно разбирать с разработчиком, что было изменено. Финальным этапом становилось само ревью, при этом не было единой точки входа, где фиксировалось бы, что именно нужно доработать, и не было структуры выполнения доработок.
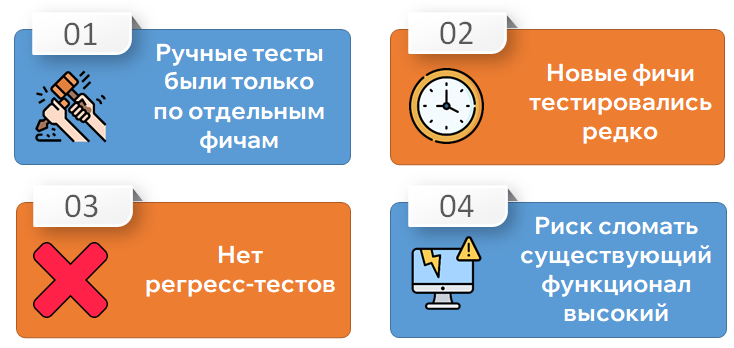
Процесса тестирования фактически не существовало. Отдельные фичи тестировались, но полного тестирования перед выкладкой в прод не было.
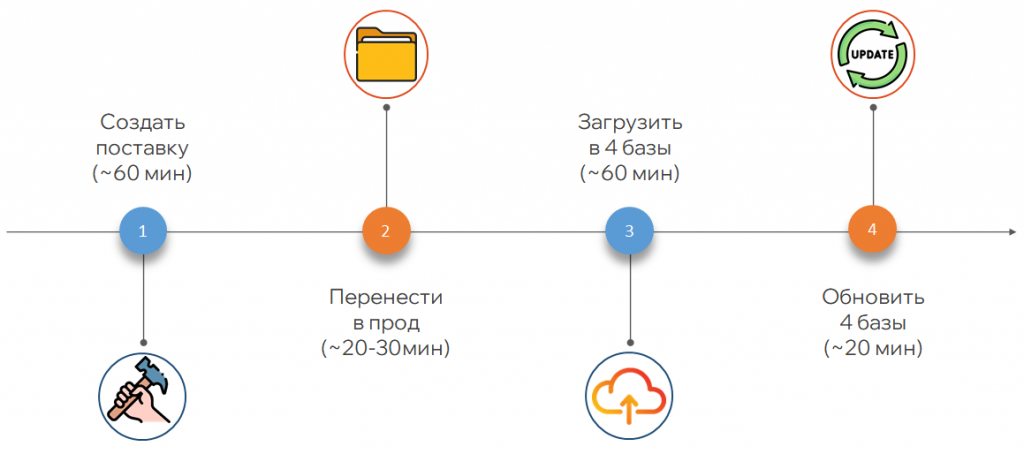
Еще одной проблемой был полностью ручной процесс сборки релиза. Чтобы собрать релиз, нужно было уточнить у разработчиков, все ли изменения выложены, создать файл поставки, передать его по сети, так как разработка и продовая база находятся в разных сегментах. Передача занимала много времени. Затем нужно было загрузить конфигурацию в четыре продовые базы. Загрузка шла долго. Процесс полностью ручной: обновления приходилось подтверждать вручную во всех всплывающих окнах. В таком процессе легко допустить ошибку.

Последняя крупная проблема – работа с фиксами. Фиксы накатывались через расширения, при этом не было единой структуры работы: что считать фиксом, что доработкой. После обновления нужно было уточнять у разработчиков, какие расширения удалить. Если что-то не удалить, могла появиться ошибка.
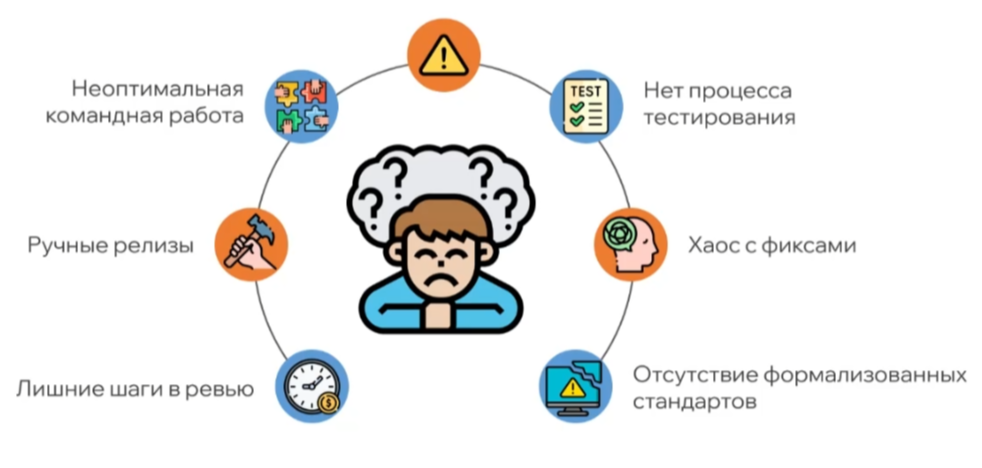
В результате сформировался объемный набор проблем: неоптимальная командная работа, ручные процессы релизов, хаос с фиксами и другие сложности, которые требовали решения.
Решение проблем
Мы знали, что есть метод выгрузки файлов, и однажды, исследуя конфигурацию, решили проверить, существует ли выгрузка с помощью скриптов. Оказалось, да, и это дало полет фантазии, как можно все автоматизировать.
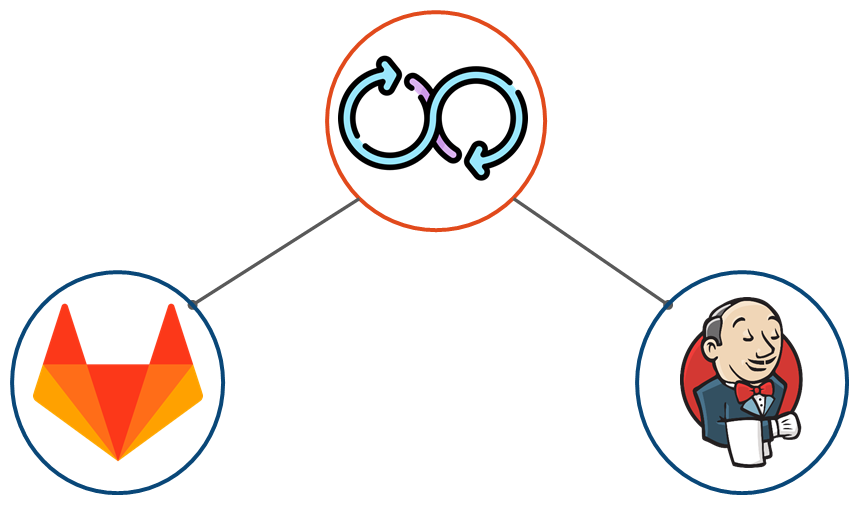
Для решения проблем автоматизации мы выбрали два инструмента: GitLab для управления кодом, ветками и merge-request, и Jenkins как инструмент доставки кода в прод.
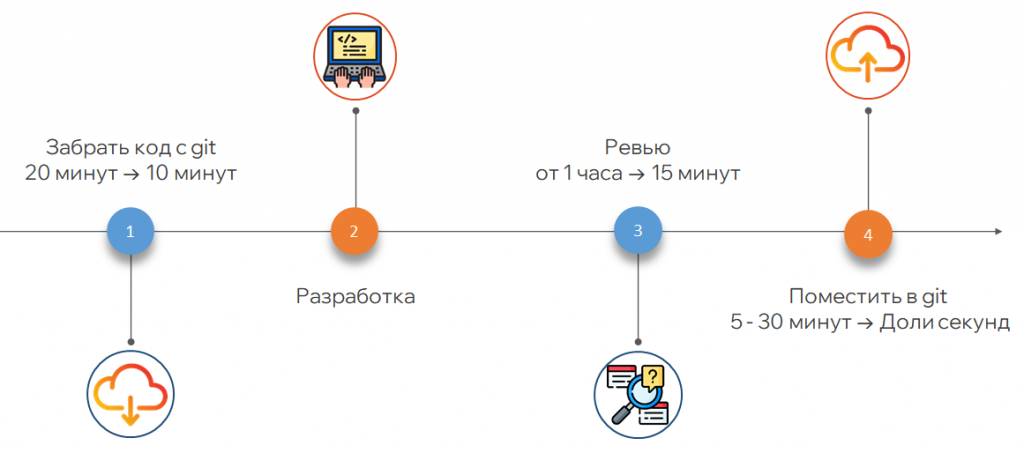
В команде приняли решение перейти на Git. Что это дало: забрать код из Git, обновить и загрузить в файловую базу теперь занимает около 10 минут – быстро и удобно.
В разработке стало удобно вести несколько задач: переключение между ветками позволяет по коммитам посмотреть, что менялось. Это особенно критично, когда срочно забирают баг. Совместная работа нескольких разработчиков перестала быть проблемой.
Ревью сократили в разы, а помещение кода в Git стало проще и удобнее. Появилась единая точка входа для разработчика, аналитика, тестировщика и архитектора, где можно посмотреть, что дорабатывалось, как дорабатывалось, какой код был написан. Если код некорректный, от него легко отказаться, чего неудобно было делать в хранилище.
С использованием merge-request мы убрали все ручные действия, оставили только самый важный процесс – ревью. В одном месте видны замечания и способы их исправления.
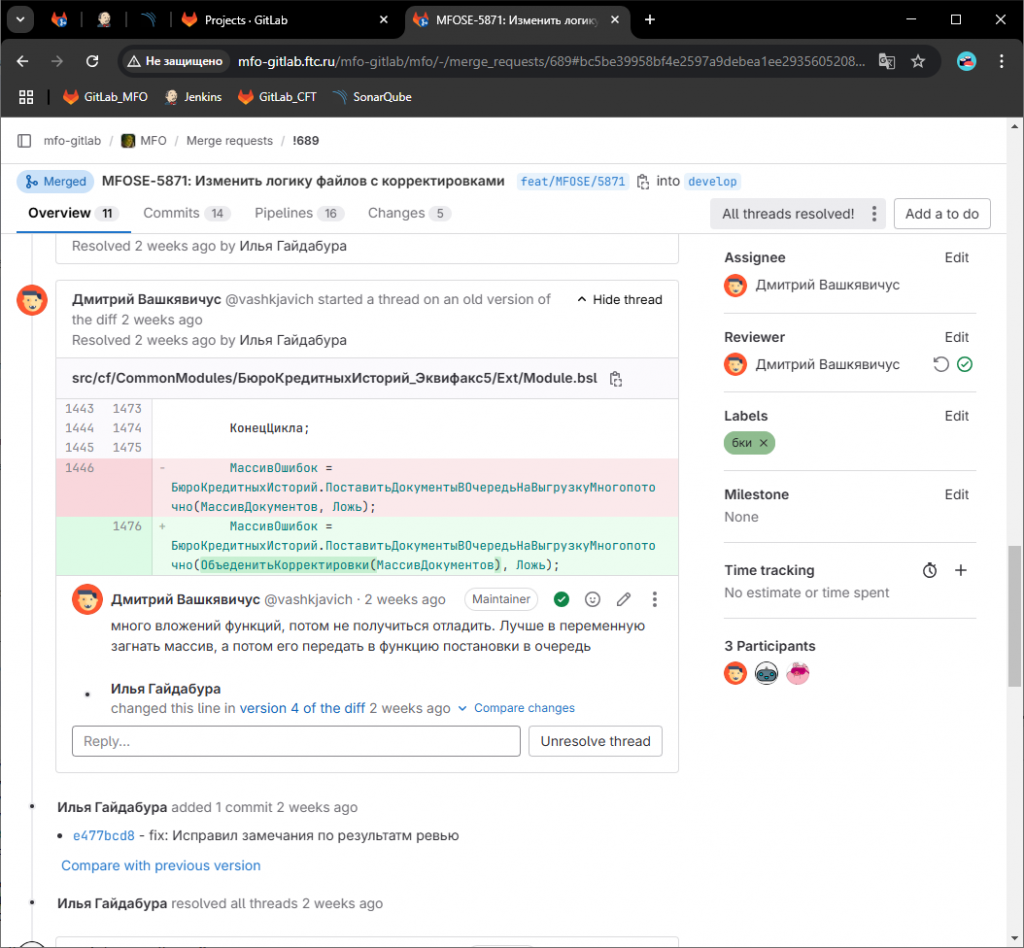
Пример того, как это может выглядеть.
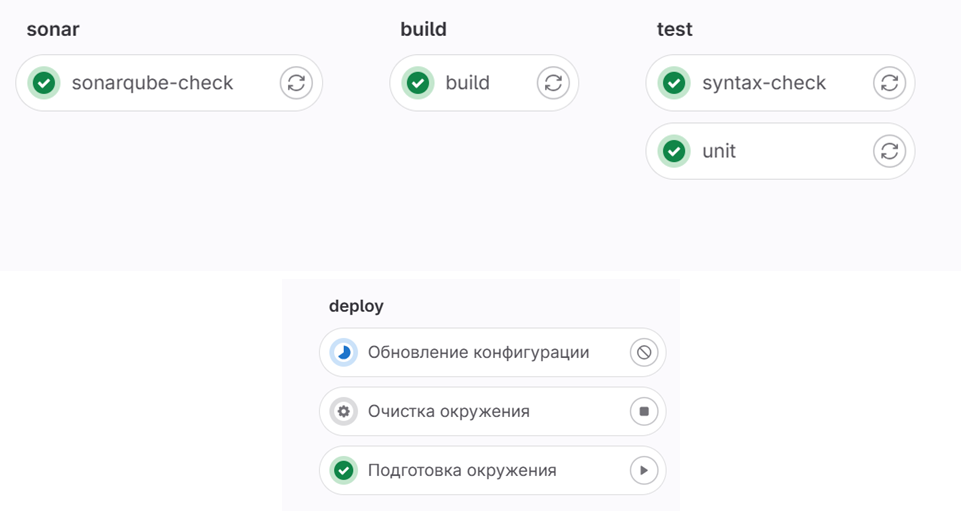
Merge-request используют не только для код-ревью: в них подключены автоматизированные проверки. Прикрутили Sonar, который проверяет код на соответствие стандартам. Добавили сборку, проверяющую, что проект собирается корректно по структуре. Включили синтаксическую проверку – особенно важную на начале перехода на Git, когда конфигурация периодически ломалась из-за дублирования кода при разрешении конфликтов. Сборка проходила успешно, но при обращении к модулю база падала. Это удалось закрыть синтаксической проверкой: достаточно выбрать клиент-сервер и прогнать проверку.
Мы также подготовили решение для будущей задачи – внедрение юнит-тестов.
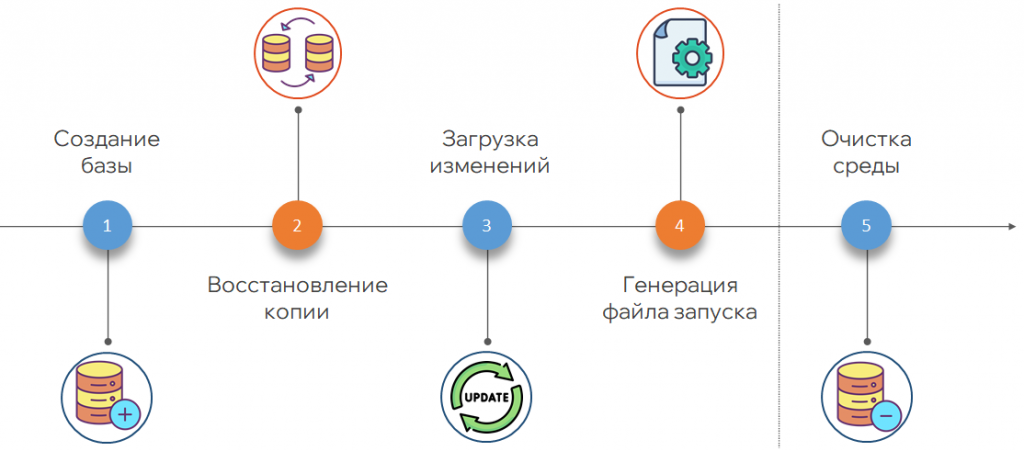
Следующий шаг – создание тестового окружения. Если все предыдущие проверки прошли успешно, у тестировщика, аналитика и других участников процесса появляется удобная кнопка «создать тестовое окружение» в GitLab. Создается новая серверная база, на нее разворачивается актуальная копия тестового стенда, загружаются изменения из ветки, конфигурация обновляется, генерируется файл для быстрого входа в базу без добавления ее в список. После слияния или отмены merge-request тестовая среда автоматически очищается.

Еще одна полезная возможность – сборка внешних отчетов и обработок. Если разработчик их дорабатывает, он нажимает кнопку «собрать», и файлы прикрепляются в виде артефактов. Их можно скачать и протестировать на развернутой базе или на любой тестовой базе.
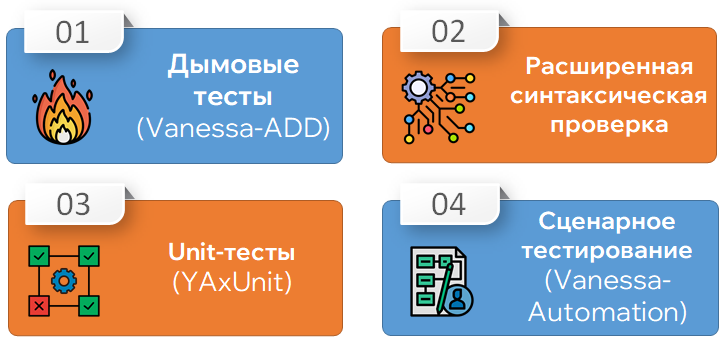
Внедрение процесса тестирования. Первым шагом стали дымовые тесты, написанные на Vanessa-ADD, так как инструмент удобный и уже содержит большое количество готовых дымовых тестов.
Подключили расширенную синтаксическую проверку, которая проверяет дополнительные вещи. Например, связанность функций формы с функциями в модуле.
Внедрили unit-тесты. Так как база бэковая и количество пользователей минимальное, основной объем тестов должен быть модульным.
Для немногочисленных пользователей написали сценарные тесты на Vanessa-Automation.
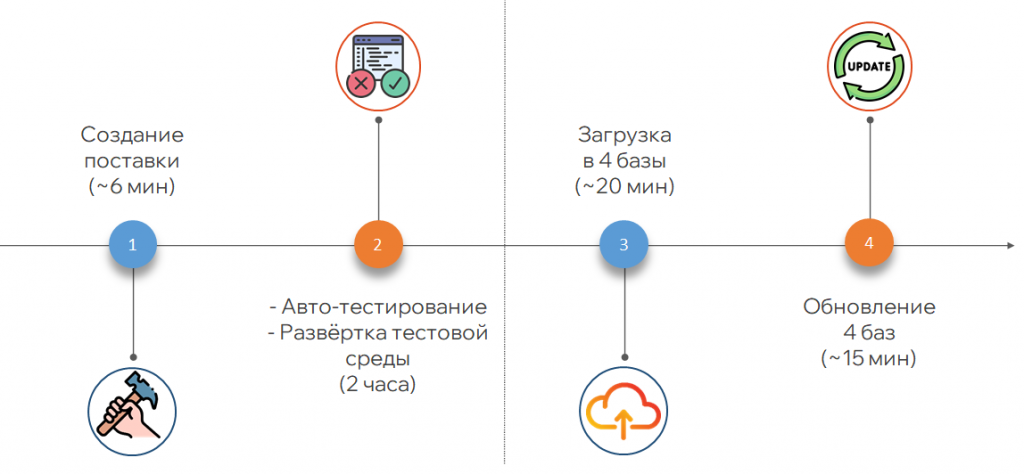
Полностью автоматизировали процесс сборки и доставки релизов в прод. Создание поставки занимает около шести минут. Автоматически в определенный день релиз-менеджер создает ветку «Релиз», и на ней запускаются все скрипты: создание поставки, набор автоматических проверок, разворачивание тестовой среды, приближенной к продовой, где тестировщики могут выполнять регресс-тесты. После успешного прохождения шагов запускается предварительная загрузка конфигурации. Теперь она проходит быстрее. В назначенное время происходит обновление базы – тоже быстро.
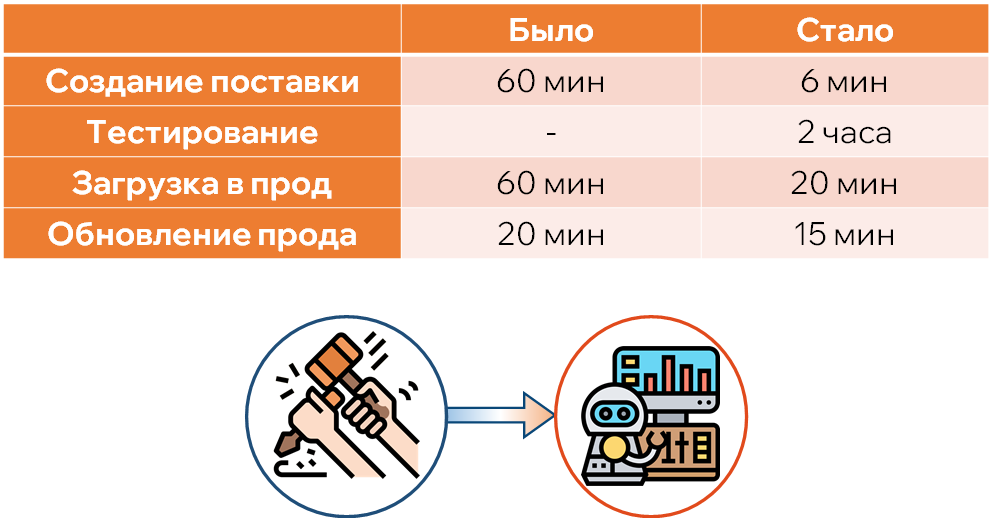
Что это нам дало: мы сократили время на создание поставки, загрузку и обновление продовой базы в разы. За счет этого появилось время для внедрения тестирования.
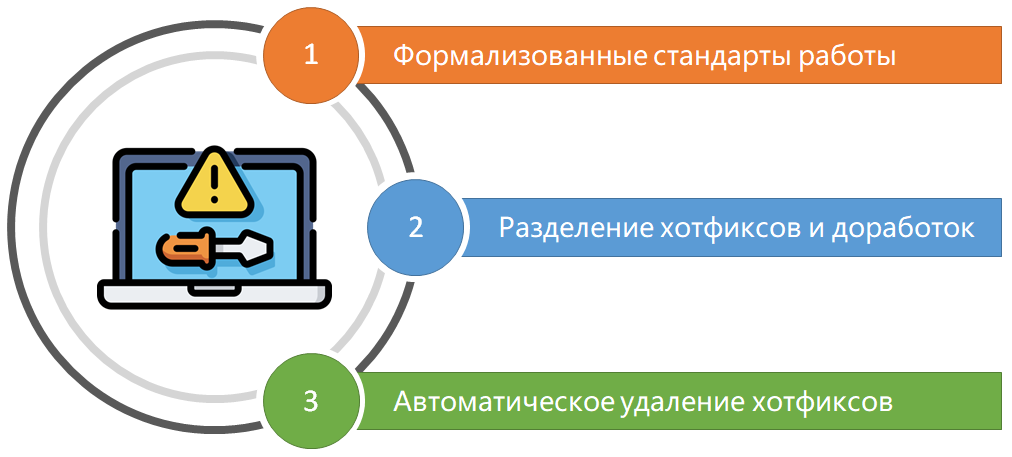
Последняя, но не менее важная проблема – структуризация хотфиксов. Мы утвердили и формализовали стандарты работы с ними. Появилось четкое разделение: что является хотфиксом, а что доработкой. В результате мы получили автоматическое удаление хотфиксов после обновления продовой базы.
Трудности, возникшие при внедрении автоматизации
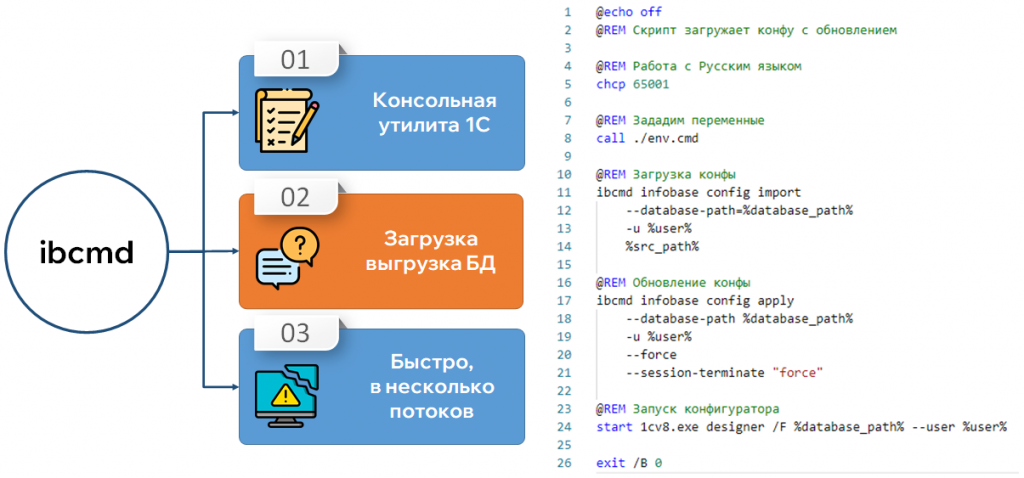
Первой проблемой стал долгий импорт конфигурации. Большая конфигурация из Git может загружаться 30–60 минут. Для решения выбрали скрипты на ibcmd. Это стандартное коробочное решение для работы с базой данных с большим набором возможностей. Для нас его плюсы – прямая работа с базой данных и многопоточная обработка, которая ускоряет загрузку конфигурации в файловую базу.
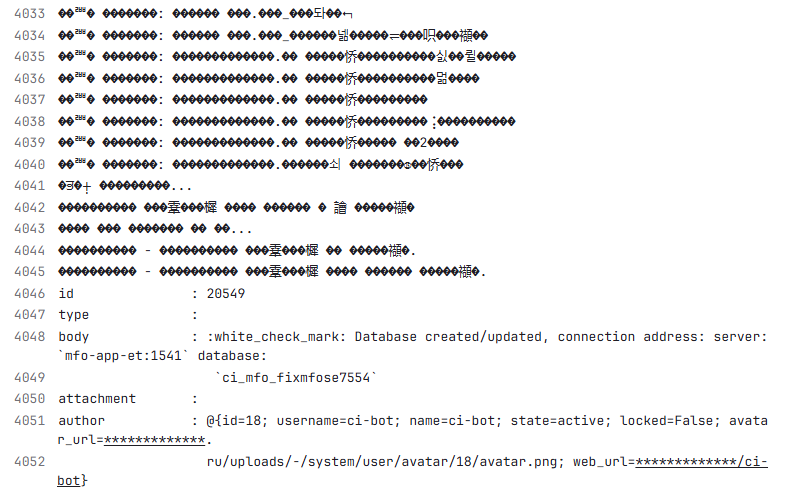
Следующая проблема – кодировка. Так как мы пишем на русском языке, логи тоже на русском, и при выполнении пайплайнов мы часто получали искаженные символы. Решение простое: при запуске раннеров обязательно указывать кодировку. Для Java это обычно utf-8. В скриптах добавляли строку chcp 6500 в начале, и проблемы с кодировкой исчезали.
Переход на Git занял примерно год – долго, потому что любое новое и непривычное вызывает сопротивление. За это время мы написали инструкции: как получить ветку, как выгрузить, загрузить, отправить изменения, как создать merge-request и так далее.
Также мы постепенно приучали команду к Git через выгрузку внешних отчетов и обработок. Единого хранилища для них не было, и мы предлагали ребятам хотя бы попробовать выгрузку через Git, чтобы увидеть, как это работает. Финальной точкой стало полное внедрение одного проекта на Git. Оттуда практики распространились на другие проекты.

Последняя проблема, которую мы пока не решили – долгая загрузка в прод для некоторых баз. Иногда кажется, что базы лежат на одном сервере и выглядят одинаково, но одна загружается полтора часа, а другая 20 минут. Причина неизвестна. Когда решим, возможно, сделаем отдельную статью о том, как это исправили.
Итоги внедрения автоматизации
Для бизнеса:
-
Быстрая и стабильная поставка,
-
Меньше трудозатрат,
-
Рост качества,
-
Появилась возможность масштабировать процессы на другие проекты без кратного увеличения трудозатрат на поддержку и запуск процессов,
-
Рост команды без потерь эффективности.
Для команды:
-
Работа с современным стеком и стандартами,
-
Развитие в технологиях вокруг 1С: мы не только пишем в конфигураторе, но и используем другие инструменты.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.


Вступайте в нашу телеграмм-группу Инфостарт