















GPU Compute Engine для 1С - Когда оптимизация больше не помогает, меняем подход
Часть 1. Проблематика
В открытом доступе сотни материалов по ускорению 1С.
Оптимизация запросов. Индексация баз данных. Настройка планов выполнения. Использование временных таблиц. Пакетная обработка данных.
Все эти методы работают. До определённого предела.
Но что делать, когда код уже написан профессионалом? Запросы уже оптимальны. Индексы расставлены грамотно. Временные таблицы используются там, где нужно. Циклы написаны без обращения к базе на каждой итерации.
Вы выжали из сервера всё, что могли. А расчёт себестоимости или авансов всё равно занимает часы.
Потому что проблема не в качестве кода.
Корень проблемы
Классический подход в 1С — последовательная обработка данных. Цикл по строкам таблицы. Даже если каждая итерация выполняется быстро, миллион итераций даёт заметное время ожидания.
Это фундаментальное ограничение архитектуры. Процессор (CPU) создан для универсальных задач, но он обрабатывает данные последовательно. На задачу выделяется 1-4 потока, не больше.
Вы не можете заставить 32-ядерный сервер считать один цикл быстрее. Он просто не умеет этого.
Что предлагается
Сменить подход. Перенести вычисления с процессора на видеокарту.
Видеокарта (GPU) имеет иную архитектуру. Тысячи небольших ядер работают параллельно. Каждое ядро глупее CPU-ядра, но их многократно больше.
Задача, которая требует миллиона однотипных арифметических операций, на GPU выполняется за то же время, что и одна операция — просто потому, что все миллион запускаются одновременно.
Разница между последовательным перебором на CPU и параллельным расчётом на GPU достигает 600-700 раз в пользу GPU. И с ростом объёма данных разрыв только увеличивается.
Это не про "ускорить код на 10%". Это про смену парадигмы расчёта. И следующий материал покажет, как это реализовать на практике.
Часть 2. Первая версия — уже прорыв

Прежде чем рассказывать, что появилось во второй версии, давайте честно признаем: первая уже вынесла мозг.
Там было доказано, что видеокарта может считать 1С-задачи не просто быстрее, а в 600-700 раз быстрее. Не на синтетике. На реальной задаче — расчёт авансов покупателей.
Миллион операций. Контрагенты, оплаты, отгрузки, долги. В 1С это минуты ожидания. На GPU — миллисекунды.
Как так получается?
Потому что пока CPU послушно перебирает строки по одной — одна, потом следующая, потом ещё одна — GPU запускает тысячи потоков одновременно. Каждый поток считает своего контрагента. И все они работают параллельно, не мешая друг другу.
Это не оптимизация. Это смена архитектуры.
Что в первой версии:
-
Полный разбор задачи
-
Код шейдера (GLSL) — 60 строк
-
Конфиг под любую базу
-
Замеры до/после
-
Объяснение, почему индексы и SSD не спасают
И самое главное — всё работает локально. Данные не уходят в облако. Только ваша видеокарта и ваша база.
Где всё это посмотреть?
🔗 Статья на Инфостарт: GPU Compute Engine: Ускоряем массовые расчёты авансов в сотни раз
📺 Видео, как оно работает: Демонстрация на Rutube
Там же исходники, примеры настройки и честные ответы на комментарии.
Если вы ещё не видели первую часть — настоятельно рекомендую. Вторая версия строится на её фундаменте и предполагает, что базовые принципы вам уже понятны.
Часть 3. Три метода себестоимости — одновременно. На видеокарте. Впервые в 1С.

Хорошо. Забыли про движок. Говорим про задачу.
Себестоимость списания товаров — это боль №1 в любой торговой конфигурации.
Списали товар со склада. По какой цене? FIFO? LIFO? Средней?
В 1С это считается часами. Особенно когда документов миллион. Особенно когда нужно посчитать всеми тремя методами сразу — для отчётности, для управленки, для сравнения.
Обычный подход: запустил FIFO — жди. Закончилось — запустил LIFO — снова жди. Средняя — третья очередь.
И каждый раз — полный перебор всех данных. Потому что методы разные, алгоритмы разные, переиспользовать результаты нельзя.
А что, если всё сразу?
Один расчёт. Три результата для каждой операции: себестоимость по FIFO, по LIFO и по средней.
Это меняет правила игры.
Вместо трёх последовательных запусков — один. Данные прочитаны один раз. На GPU ушли один раз. Результат — три колонки в одной таблице.
Как это выглядит на практике
В регистре движений: приходы и расходы товара. Отсортировано по товару и дате.
Каждый поток GPU — один товар. Внутри потока — движение по его истории.
Пришла партия — кладём в очередь FIFO (в конец), в стек LIFO (наверх), пересчитываем среднюю цену.
Ушла партия — берём из очереди FIFO (из начала), из стека LIFO (сверху), из средней цены (текущее значение). Списываем. Считаем себестоимость расхода.
Всё одновременно. В одном цикле. На одном ядре GPU.
Почему это прорыв
Потому что на CPU вы так не сделаете.
Три метода — три разных алгоритма работы с памятью. FIFO нужна очередь (забираем с головы). LIFO — стек (забираем с хвоста). Средняя — просто текущее среднее. На CPU они конфликтуют за кэш, за память, за время.
На GPU — плевать. Тысячи товаров обрабатываются независимо. У каждого своя очередь, свой стек, своя средняя. И всё это в регистрах одного потока.
Цифры (скоро будут)
Первая версия на авансах дала ускорение 600-700 раз всего на 100 000 записей.
Здесь задача сложнее. Но принцип тот же: параллельная обработка тысяч товаров на тысячах ядер GPU.
Разница с CPU будет не просто заметной. Она будет сокрушительной.
Куда катится мир
Посмотрите, что происходит вокруг.
Искусственный интеллект считает миллиарды параметров на GPU.
Научные симуляции — на GPU.
Рендеринг, анимация, анализ данных — на GPU.
А 1С до сих пор гоняет циклы на CPU.
Это временно. Аномалия. Потому что раньше не было простого способа связать 1С и GPU.
Теперь есть.
Расчёт себестоимости тремя методами одновременно — только начало. Дальше — остатки на каждый день, скользящие средние, распределение косвенных расходов, расчёт НДС...
Всё это уйдёт на видеокарту. Вопрос не в «если», а в «когда».
Лучше когда — сейчас.
Часть 4. Как это работает под капотом: от 1С до GPU и обратно
Теперь — детали. Как данные из 1С попадают на видеокарту, что с ними там происходит и как результат возвращается обратно.
Общая схема
1С → SQLite/PostgreSQL → движок → GPU → движок → SQLite/PostgreSQL → 1С

Звучит просто. Но за этой цепочкой — несколько ключевых моментов, без которых ничего не заработает.
Шаг 1. Подготовка данных в 1С
Перед тем как отдать данные движку, 1С должна их правильно выгрузить.
Что нужно сделать на стороне 1С:
-
Выбрать нужные данные из регистров или документов
-
Привести к плоской таблице (одна операция — одна строка)
-
Выгрузить в SQLite или PostgreSQL
Важный нюанс: никакой бизнес-логики в этой выгрузке быть не должно. Только сырые данные. Все расчёты — на GPU.
Примерная структура таблицы для задачи с себестоимостью:
CREATE TABLE Movements ( id INTEGER, product_id INTEGER, operation_date DATE, operation_type INTEGER, -- 1 = приход, 0 = расход quantity INTEGER, -- количество * 100 price INTEGER, -- цена за единицу * 100 ...)
Все суммы и количества — в целых числах, с учётом масштаба. Никаких float.
Шаг 2. Что делает движок
Движок получает на вход:
-
Путь к базе данных
-
Конфигурационный файл (config.json)
-
Скомпилированный шейдер (shader.spv)
Действия движка по порядку:
2.1. Читает конфиг
Из config.json движок узнаёт:
-
Какая таблица — источник (input_table)
-
По каким колонкам сортировать (sort_by)
-
По какой колонке группировать (group_by)
-
Какие колонки загружать и как их масштабировать (input_columns)
2.2. Загружает данные из БД
Движок выполняет примерно такой SQL-запрос:
SELECT id, product_id, operation_type, quantity, priceFROM MovementsORDER BY product_id, operation_date
Сортировка критически важна. Весь расчёт завязан на том, что операции одного товара идут подряд, строго по дате.
2.3. Делит данные на группы
После загрузки движок проходит по отсортированным данным и определяет границы групп.
Пример:
|
Строка |
product_id |
Действие |
|
0-99 |
1 |
Группа 1 |
|
100-249 |
2 |
Группа 2 |
|
250-300 |
3 |
Группа 3 |
Для каждой группы запоминаются row_start и row_end (индексы первой и последней строки группы).
2.4. Загружает данные на GPU
Движок создаёт три буфера в памяти видеокарты:
Буфер 0 — входные данные
[все строки, все колонки, одним массивом int-ов]
Буфер 1 — диапазоны групп
[start0, end0, start1, end1, start2, end2, ...]
Буфер 2 — выходные данные
[пока пусто, место под результат]
2.5. Запускает шейдер
Движок запускает ровно столько потоков, сколько получилось групп.
Каждый поток получает:
-
gl_GlobalInvocationID.x — номер группы (0, 1, 2, ...)
-
Доступ ко всем трём буферам
-
Push-константы — индексы колонок (чтобы знать, где в строке лежит цена, а где — тип операции)
Один поток = одна группа = один товар.
Поток делает следующее:
// Определил свои границы
uint row_start = ranges[gid * 2];
uint row_end = ranges[gid * 2 + 1];
// Прошёл по всем своим строкам
for (uint i = row_start; i < row_end; i++) {
// Взял тип операции и количество
int op_type = data[i * num_cols + col_type];
int qty = data[i * num_cols + col_qty];
int price = data[i * num_cols + col_price];
// Приход — добавил в FIFO, LIFO, пересчитал среднюю
// Расход — списал из FIFO, LIFO, по средней
// Записал результат для этой строки
result[i * 3 + 0] = avg_cost;
result[i * 3 + 1] = fifo_cost;
result[i * 3 + 2] = lifo_cost;
}
Важно: тысячи таких потоков работают одновременно. Каждый — со своей группой, своими очередями, своей памятью. Они не мешают друг другу, не блокируют, не ждут.
2.6. Скачивает результат
После завершения всех потоков движок копирует буфер результата обратно в оперативную память.
Шаг 3. Запись результата обратно в БД
Движок формирует SQL-запрос на обновление:
UPDATE Movements SET avg_cost = ?, fifo_cost = ?, lifo_cost = ?WHERE id = ?
И выполняет его для каждой строки (пакетно, разумеется).
Шаг 4. 1С забирает результат
После того как движок отработал, 1С может:
-
Прочитать обновлённые данные из той же таблицы
-
Использовать их для формирования движений по регистрам
-
Или просто показать в отчёте
Данные лежат в той же базе, в тех же строках. Дополнительных действий не требуется.
Что происходит с памятью
На CPU (в 1С):
-
Таблица в памяти
-
Цикл по строкам
-
Одна строка за раз
На GPU:
-
Все строки загружены в VRAM
-
Тысячи потоков одновременно читают свои диапазоны
-
Кэши, регистры, разделяемая память — всё работает на полную
Ключевые ограничения (честно)
-
Данные должны помещаться в VRAM. Если нет — движок разобьёт на чанки, но скорость упадёт.
-
Сложная логика с ветвлениями — не для GPU. Если внутри группы нужно ходить в справочники, обращаться к другим таблицам — оставляйте на CPU.
-
Сортировка и группировка — ответственность движка. Он умеет, но время на подготовку тоже нужно учитывать.
-
Шейдер пишете вы. Движок — универсальный. Алгоритм перекладывать на вас.
Что в итоге
Данные из 1С → плоская таблица → движок → GPU → параллельный расчёт → обратно в базу.
Вся магия — внутри шейдера. Внешняя обвязка — стандартная и проверенная.
Часть 5. Реализация на стороне 1С

Теперь — как это выглядит в коде 1С. Без магии, только практика.
Что создано в демо-конфигурации
Для демонстрации работы созданы простые, но показательные объекты:
Документы
«Приходный ордер» — фиксирует поступление товара на склад. Хранит:
-
Дату
-
Товар (номенклатуру)
-
Количество
-
Цену за единицу
«Расходный ордер» — фиксирует выбытие товара. Хранит:
-
Дату
-
Товар
-
Количество
Никакой лишней логики. Только факты хозяйственной жизни.
Регистр накопления
«ПартииТоваров» — остаточный регистр, который хранит себестоимость списания. Для каждой партии (каждого приходного документа) хранит:
-
Товар
-
Остаток количества
-
Цену за единицу
Именно этот регистр позволяет потом увидеть, по какой цене был списан товар в каждом расходном ордере.
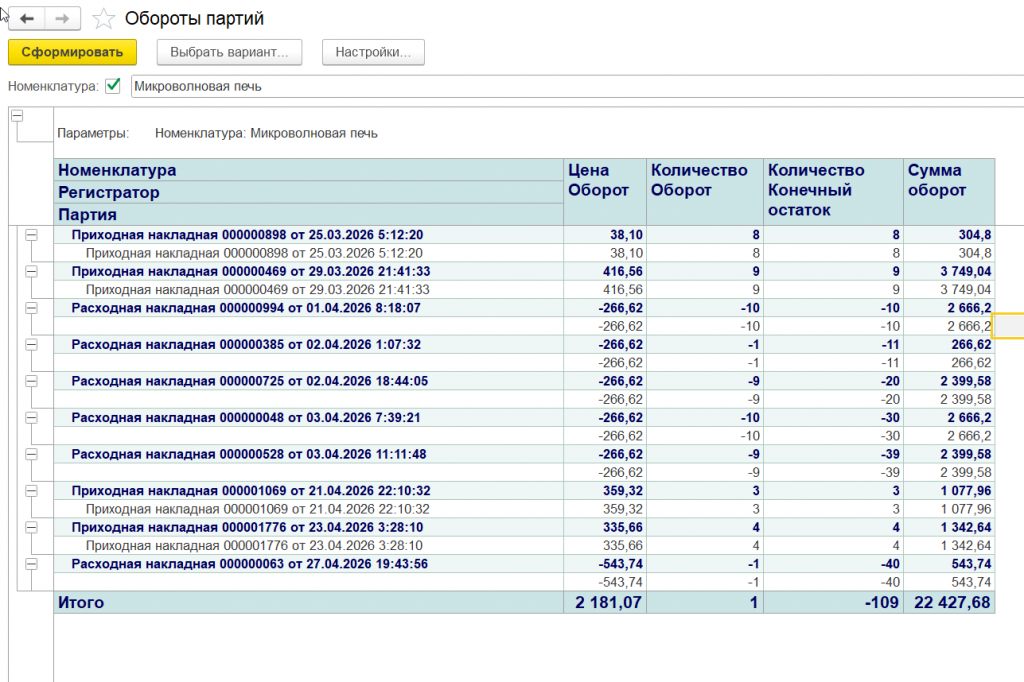
Отчёт
«ОборотыПартий» — простая форма, которая показывает для каждого расходного ордера:
-
FIFO себестоимость
-
LIFO себестоимость
-
Среднюю себестоимость
-
Сумму расхода (количество × себестоимость)
Отчёт может брать данные двумя способами:
-
Из регистра «ПартииТоваров» — то, что насчитала 1С классическим алгоритмом
-
Из временной таблицы с результатами GPU — то, что насчитала видеокарта
Идеальный инструмент для сверки. Показывает две колонки рядом. Если цифры совпадают — значит, оба метода работают правильно.
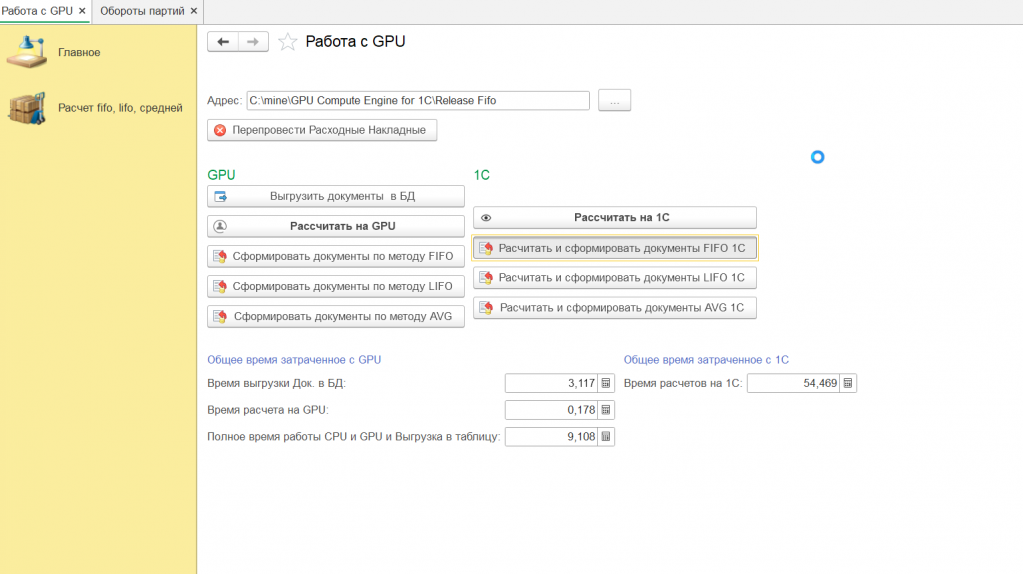
Обработка «Выгрузка на GPU»
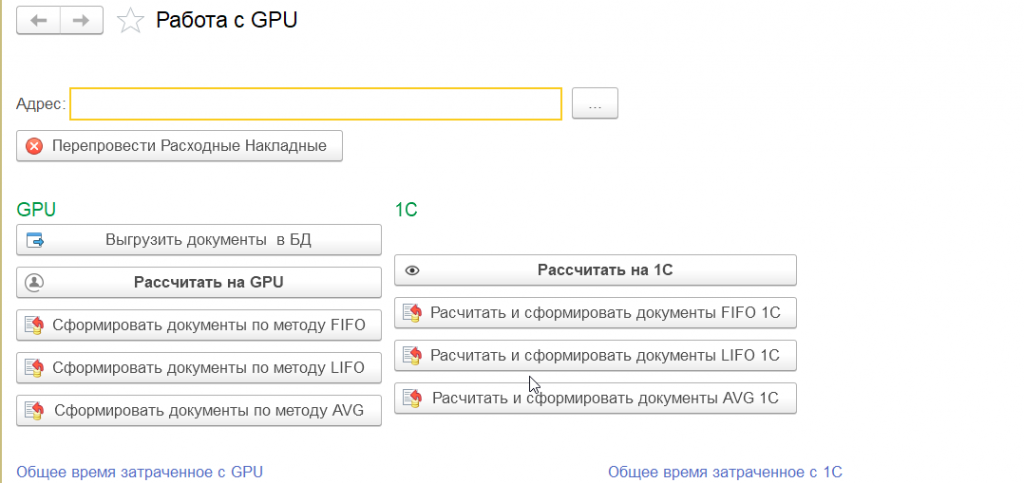
Это главный управляющий объект. Именно здесь происходит вся оркестрация.
Интерфейс обработки
Пользователь видит простую форму с несколькими полями.
Но вначале нужно выбрать папку с программой в верхней части есть поле "Адрес" оно должно быть заполнено.
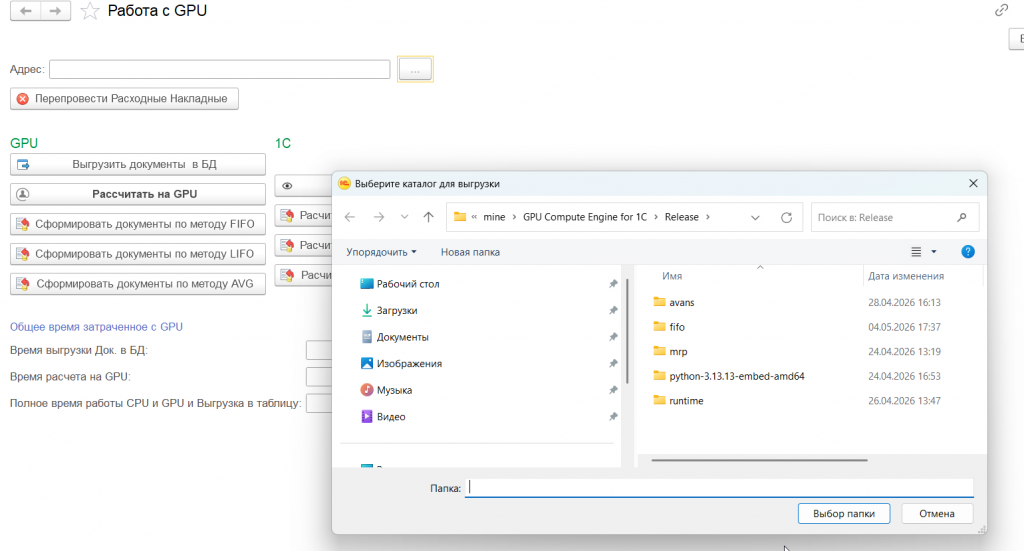
Слева методы которые относятся к расчетам на GPU а справа те, что делают те-же расчеты на стороне 1С.
Пройдемся по методам GPU (слева)
"Выгрузить документы в БД" - выгружает документы в sqlite. Важно!!! Нужно зайти под администратором и доустановить программу связки 1С с SQLite. Программа лежит так-же в папке с приложением.
"Рассчитать на GPU" - система делает расчеты всех 3х видов Fifo, Lifo, средней - на стороне видеокарты.
"Сформировать документы по методу..." - соотв-но перезаписывает документы по одному из 3х методов.
Пройдемся по методам 1С (справа)
"Рассчитать на 1С" - делает 3 расчета методов: Fifo, Lifo, средней - на стороне 1C.
"Рассчитать и сформировать документы по методу..." - соотв-но рассчитывает и перезаписывает документы по одному из 3х методов.
Зачем это нужно?
Пользователь в этой обработке сформировать любой вид расчета, замерить время и проанализировать данные с помощью отчета.
Так-же отмечу, что во вложении лежит не 1 а 2 информационных базы:
- ИБ для демонстации расчета fifo lifo средней на GPU (3 000 док.).dt
- ИБ для демонстации расчета fifo lifo средней на GPU (50 000 док.).dt
- Исключительно для удобства понимания процессов которые тут заложены. На 3000 документах проще проверить корректность расчетов, а 50000 лучше показывают разрыв между GPU и 1С
И да, разрыв по моим замерам составил разницу в 300 раз в пользу GPU.
Что делает обработка при нажатии на GPU
Шаг 1. Сбор данных
Обработка выполняет запрос к документам:
&НаКлиенте
Процедура РаcсчитатьнаGPU(Команда)
ПутьКPython = ЭтаФорма.Адрес+"\python-3.13.13-embed-amd64\python.exe";
ПутьКСкрипту = ЭтаФорма.Адрес+"\fifo\solve.py";
Команда = """" + ПутьКPython + """ """ + ПутьКСкрипту + """";
Попытка
// Запускаем с ожиданием завершения
ЗапуститьПриложение(Команда, , Истина);
Сообщить("Скрипт выполнен!");
Исключение
Сообщить("Ошибка: " + ОписаниеОшибки());
КонецПопытки;
ПутьКЛогу = ЭтаФорма.Адрес+"\fifo\solve.log";
// . Читаем и парсим лог
Если ПроверитьФайл(ПутьКЛогу) Тогда
РазобратьЛогФайл(ПутьКЛогу);
Иначе
Сообщить("Лог файл не создан!");
КонецЕсли;
КонецПроцедуры
На выходе — плоская таблица «Операции», где каждая строка — или приход, или расход. Идеально для загрузки в движок.
Шаг 2. Выгрузка в SQLite
Обработка подключается к базе base.db (или PostgreSQL) и выгружает таблицу целиком.
Код максимально простой — через ADO или встроенную работу с SQLite через внешнюю компоненту.
Шаг 3. Запуск движка
1С
ЗапуститьПриложение("compute_engine.exe config.json");
Движок делает свою работу (описано в части 4). Обработка ждёт завершения, показывая прогресс.
Шаг 4. Загрузка результата
После завершения движка обработка загружает из БД обновлённые строки с рассчитанными себестоимостями.
Каждая операция теперь содержит:
-
fifo_cost — себестоимость единицы по FIFO
-
lifo_cost — по LIFO
-
avg_cost — по средней
Шаг 5. Запись в регистр 1С
Обработка проходит по расходным ордерам и для каждого формирует записи в регистр «ПартииТоваров».
Это важно: GPU посчитал цифры. А 1С должна их куда-то положить, чтобы потом отчёт мог их показать. Регистр — это «мостик» между внешним расчётом и внутренней отчётностью.
Расчёт на стороне 1С (для сравнения)
В этой же обработке реализован классический алгоритм расчёта на CPU:
-
Запрос всех операций, сортировка по дате
-
Цикл по строкам
-
Отдельные очереди для FIFO, отдельные массивы для LIFO, переменная для средней
-
Запись в тот же регистр «ПартииТоваров»
Алгоритм абсолютно стандартный. Именно так расчёт себестоимости делают в типовых конфигурациях. Именно так он работает часами при большом объёме.
Зачем это нужно в обработке?
Чтобы пользователь мог нажать две кнопки:
-
«Рассчитать на 1С» — получить классический результат (и время)
-
«Рассчитать на GPU» — получить результат видеокарты (и время)
И сравнить. И увидеть разницу своими глазами.
Итог: полная картина
|
Компонент |
Назначение |
|
Приходный ордер |
Ввод данных — поступление товаров |
|
Расходный ордер |
Ввод данных — выбытие товаров |
|
Регистр «ПартииТоваров» |
Хранение результатов расчёта |
|
Обработка «Выгрузка на GPU» |
Оркестрация: сбор → выгрузка → запуск → загрузка |
|
Отчёт «ОборотыПартий» |
Верификация: сравнение 1С и GPU |
Всё вместе образует замкнутый цикл:
-
Пользователь заполняет документы
-
Нажимает кнопку в обработке
-
Видеокарта считает себестоимость тремя методами
-
Результат попадает в регистр
-
Отчёт показывает цифры и сверяет с классическим расчётом
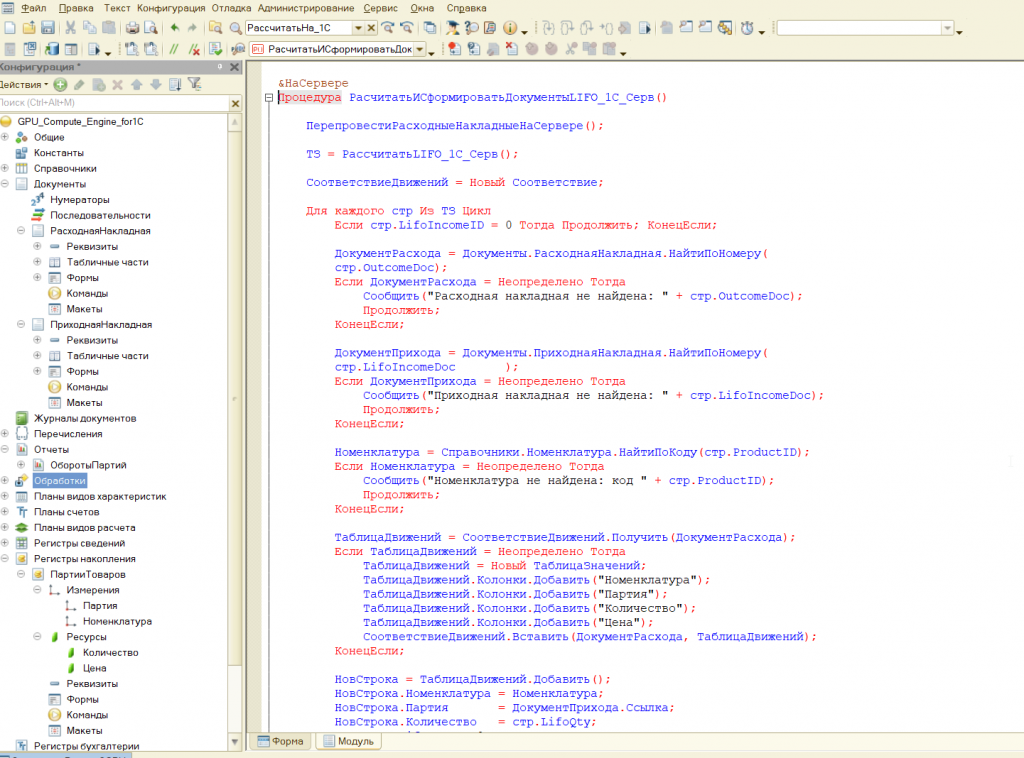
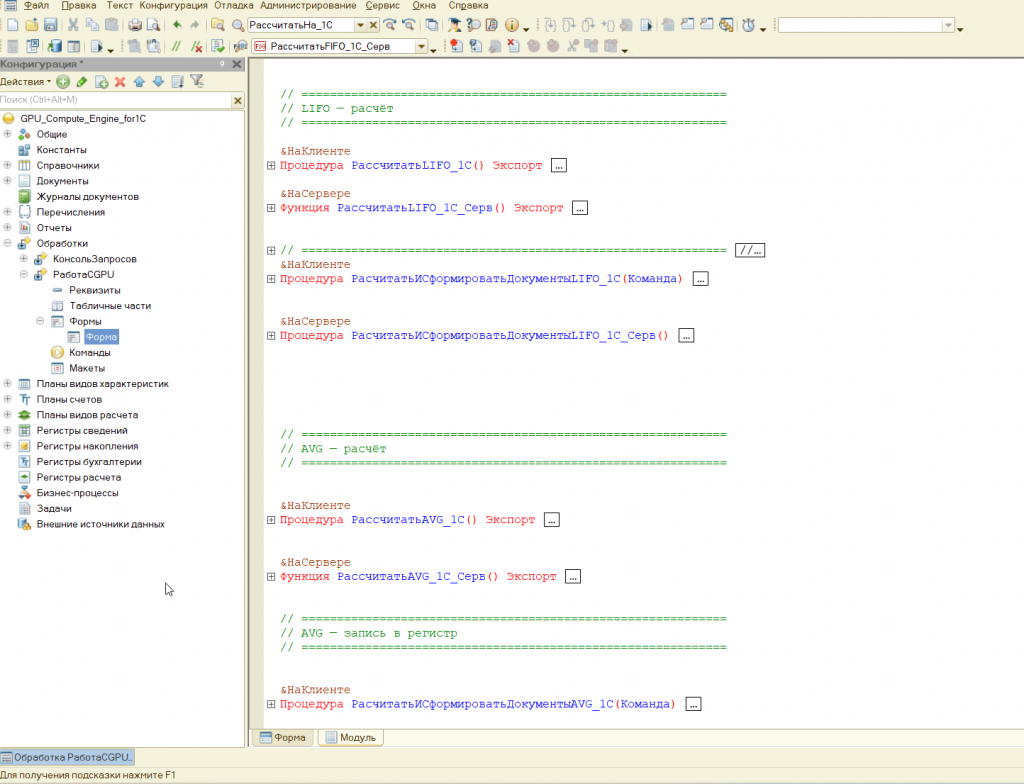
Часть кода на 1С. Код простой, специально не усложнял, писал все этапы отдельно.
// ============================================================
// FIFO — запись в регистр GPU
// ============================================================
&НаКлиенте
Процедура СформироватьДокументыПоМетоду_FIFO(Команда)
СформироватьДокументыПоМетоду_FIFO_Серв();
КонецПроцедуры
&НаСервере
Процедура СформироватьДокументыПоМетоду_FIFO_Серв()
ПерепровестиРасходныеНакладныеНаСервере();
ТЗ = ВернутьТЗРасчетыИзSQLite();
// ТЗ.Скопировать(новый Структура("ProductID",143))
// Ключ = ДокументРасхода, Значение = Таблица движений для этого документа
СоответствиеДвижений = Новый Соответствие;
Для каждого стр Из ТЗ Цикл
Если стр.FifoIncomeID = 0 Тогда Продолжить; КонецЕсли;
// Получаем документ расхода
ДокументРасхода = Документы.РасходнаяНакладная.НайтиПоНомеру(стр.OutcomeDoc);
Если ДокументРасхода = Неопределено Тогда
Продолжить;
КонецЕсли;
// Получаем документ прихода (партия)
ДокументПрихода = Документы.ПриходнаяНакладная.НайтиПоНомеру(стр.FifoIncomeDoc);
Если ДокументПрихода = Неопределено Тогда
Продолжить;
КонецЕсли;
// Находим номенклатуру по коду
Номенклатура = Справочники.Номенклатура.НайтиПоКоду(стр.ProductID);
Если Номенклатура = Неопределено Тогда
Сообщить("Номенклатура не найдена: код " + стр.ProductID);
Продолжить;
КонецЕсли;
// Получаем или создаем таблицу движений для этого документа
ТаблицаДвижений = СоответствиеДвижений.Получить(ДокументРасхода);
Если ТаблицаДвижений = Неопределено Тогда
ТаблицаДвижений = Новый ТаблицаЗначений;
ТаблицаДвижений.Колонки.Добавить("Номенклатура");
ТаблицаДвижений.Колонки.Добавить("Партия");
ТаблицаДвижений.Колонки.Добавить("Количество");
ТаблицаДвижений.Колонки.Добавить("Цена");
СоответствиеДвижений.Вставить(ДокументРасхода, ТаблицаДвижений);
КонецЕсли;
// Добавляем движение в таблицу
НовСтрока = ТаблицаДвижений.Добавить();
НовСтрока.Номенклатура = Номенклатура;
НовСтрока.Партия = ДокументПрихода.Ссылка;
НовСтрока.Количество = стр.FifoQty;
Если стр.FifoQty <> 0 Тогда
НовСтрока.Цена = стр.FifoCost / стр.FifoQty;
Иначе
НовСтрока.Цена = 0;
КонецЕсли;
КонецЦикла;
// Записываем движения для каждого документа
Для каждого КлючЗначение Из СоответствиеДвижений Цикл
ДокументРасхода = КлючЗначение.Ключ;
ТаблицаДвижений = КлючЗначение.Значение;
// Создаем набор записей регистра
НаборЗаписей = РегистрыНакопления.ПартииТоваров.СоздатьНаборЗаписей();
НаборЗаписей.Отбор.Регистратор.Установить(ДокументРасхода);
НаборЗаписей.Прочитать();
НаборЗаписей.Очистить();
// Добавляем все движения для этого документа
Для каждого ДвижениеСтрока Из ТаблицаДвижений Цикл
Запись = НаборЗаписей.Добавить();
Запись.ВидДвижения = ВидДвиженияНакопления.Расход;
Запись.Период = ДокументРасхода.Дата;
Запись.Номенклатура = ДвижениеСтрока.Номенклатура;
Запись.Партия = ДвижениеСтрока.Партия;
Запись.Количество = ДвижениеСтрока.Количество;
Запись.Цена = ДвижениеСтрока.Цена;
КонецЦикла;
// Записываем одним пакетом
НаборЗаписей.Записать();
// Сообщаем пользователю
Сообщить("Изменен документ: " + ДокументРасхода.Номер + " от " + Формат(ДокументРасхода.Дата, "ДФ=dd.MM.yyyy"));
КонецЦикла;
Если СоответствиеДвижений.Количество() = 0 Тогда
Сообщить("Документы для перепроведения не найдены");
КонецЕсли;
КонецПроцедуры
Часть 6. Итоги: цифры, файлы, выводы

Что внутри скачиваемого архива
Когда вы приобретаете эту разработку, вы получаете полный комплект для работы и экспериментов.
Движок и всё для его работы
-
compute_engine.exe — исполняемый файл
-
base.db — SQLite-база (или настройки для PostgreSQL)
-
config.json — конфигурация для FIFO/LIFO/средней
-
shader.comp — вычислительный шейдер (исходный код)
-
shader.spv — скомпилированный шейдер
-
solve.py — скрипт-оркестратор
-
Инструкция по запуску
Две информационные базы 1С
ИБ №1. Демонстрационная (3 000 документов)
Лёгкая версия для быстрого знакомства. Вы быстро увидите, как всё работает, поймёте логику, протестируете на небольшом объёме. Разница между 1С и GPU на этом объёме — уже 40 раз. Этого достаточно, чтобы оценить потенциал.
ИБ №2. Расширенная (50 000 документов)
Версия для погружения в мир больших данных. Здесь разница раскрывается в полную силу — 300 раз. Вы сможете:
-
Почувствовать, как 1С начинает «задумываться» на классическом расчёте
-
Увидеть, что видеокарта работает с тем же «листом ожидания», что и на 3 000 документах
-
Понять, куда уходит время в реальных внедрениях
Обе базы содержат одинаковые документы — приходные и расходные ордера, регистр, отчёт и обработку. Разница только в количестве строк.
Цифры, которые говорят сами за себя
|
Объём данных |
Ускорение GPU vs 1С |
Что это значит |
|
3 000 документов |
40 раз |
Расчёт, который в 1С идёт 1 минуту, на GPU — 1.5 секунды |
|
50 000 документов |
300 раз |
1 час работы 1С превращается в 12 секунд на GPU |
|
500 000+ (ваши данные) |
600-700+ раз |
Закрытие месяца с вечера на утро → кнопка и чашка кофе |
Важный вывод: разрыв растёт вместе с данными. На маленьких объёмах GPU уже выигрывает. На больших — уничтожает.
На вашей реальной базе, где миллионы записей в регистрах, разница будет ещё более впечатляющей. 1С будет считать часы, GPU — секунды.
Как это проверить самостоятельно
Всё уже сделано за вас.
-
Скачайте архив (ссылка ниже)
-
Откройте любую из двух ИБ
-
Запустите обработку «Выгрузка на GPU»
-
Нажмите «Рассчитать на 1С» — засеките время
-
Нажмите «Рассчитать на GPU» — засеките время
-
Откройте отчёт «ОборотыПартий» — убедитесь, что цифры совпадают
🔗 1я статья на Инфостарт: GPU Compute Engine: Ускоряем массовые расчёты авансов в сотни раз
📺 Как это работает на практике: Демонстрация на Rutube
Красивые выводы
Мы стоим на пороге перемен.
В 1С-разработке десятилетиями господствовал один подход: данные в памяти, циклы на CPU. Он работал, пока объёмы были терпимы. Сегодня он трещит по швам.
Миллионы строк в регистрах — это новая реальность. Ритейл, логистика, производство, маркетплейсы — данные растут лавинообразно. А привычные инструменты не поспевают.
Но выход есть.
Видеокарты — это не только для геймеров и AI-инженеров. Это мощь тысяч параллельных ядер, которая ждёт своего часа в каждой учётной системе.
FIFO, LIFO, средняя себестоимость, авансы, остатки, скользящие средние, распределение косвенных расходов — всё это идеальные кандидаты для переноса на GPU.
Сейчас — лучший момент начать.
Технология готова. Инструменты есть. Примеры работают. А конкуренты пока ещё считают на CPU.
Ссылки
📦 Архив со всеми файлами — в приложении к публикации
🔗 GitHub с исходным кодом движка: GPU-Compute-Engine-1C
🔗 Ссылка на статью 1 по этой же теме: GPU Compute Engine for 1C: Ускоряем массовые расчёты
🔗 Ссылка на статью 3 по этой же теме: GPU Compute Engine for 1C: Ускоряем массовые расчёты в MRP
🔗 Статья на Хабр: GPU Compute Engine для 1С: как перестать ждать часами и начать считать на видеокарте
Параметры системы на которой проводились расчеты:
🧠 Процессор (CPU)
AMD Ryzen 7 260 (Zen 4, 2024 год)
8 ядер / 16 потоков
Частота: до 5.1 ГГц
🎮 Видеокарта (GPU)
Дискретная: NVIDIA GeForce RTX 5060 Laptop GPU (драйвер 580)
🧬 Оперативная память (RAM)
32 ГБ DDR5 (две планки по 16 ГБ от A-DATA)
Частота: 5600 МГц
Последнее, но важное
В приложении к публикации лежит всё, что нужно для запуска и тестирования:
-
Движок с конфигурацией под FIFO/LIFO/среднюю
-
Две информационные базы 1С (3 000 и 50 000 документов)
-
Инструкция по установке и запуску
-
Исходные тексты шейдера и конфигов
-
Программы которые могут помочь для интеграции c SQLite и Vulkan
Скачивайте, устанавливайте, пробуйте. Сравнивайте цифры сами.
И помните: то, что сегодня считается «пределом возможностей 1С», завтра станет обычной кнопкой на панели.
Добро пожаловать в будущее параллельных расчётов.
Вступайте в нашу телеграмм-группу Инфостарт