

{kind=link}
Когда заходит речь об интеграции LLM (больших языковых моделей) и корпоративных систем, первый же вопрос от службы безопасности звучит так: «А куда полетят данные?».
В случае с какими-нибудь CRM или складским учетом еще можно подискутировать. Но когда дело касается 1С:ЗУП — это глухая стена. Ни один вменяемый ИТ-безопасник не разрешит работать с облачной LLM.
Поэтому моя задача звучала амбициозно: спроектировать архитектуру ИИ-агента, который сможет автономно расследовать ошибки расчетчиков в ЗУП, но при этом будет готов к развертыванию в полностью закрытом контуре на локальных моделях.
В этой статье (которая является скорее инженерным дневником, чем презентацией готового коробочного продукта) я расскажу, как я отказался от классического RAG, познакомили LLM с метаданными 1С и заставили нейросеть писать валидные 1C запросы, получая по рукам от HTTP сервиса 1С в случае ошибки.
(Спойлер: пока сервера под локальные модели уровня Gemma-4:31b находятся в стадии закупки, архитектуру я обкатывал на облачных API, так как код оркестратора от этого не меняется. Но обо всем по порядку).
Проблема: Почему обычный RAG не работает для 1С?
Классический подход к ИИ в бизнесе сейчас выглядит так: берем документацию, скармливаем в векторную базу данных (Chroma/Pinecone), подключаем LLM. Пользователь задает вопрос, ИИ находит похожий кусок текста и генерирует ответ (это и есть RAG — Retriever-Augmented Generation).
Для первой линии поддержки это работает неплохо, когда нужна справочная информация. Но когда бухгалтер или сотрудник службы поддержки пишет:
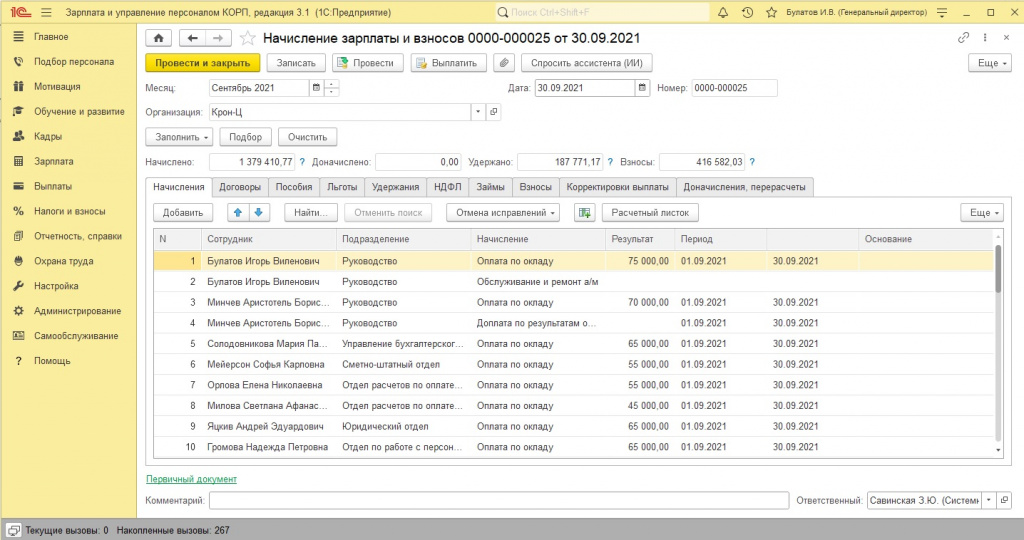
«Почему у Солодовниковой М.П. в Начислении ЗП №25 НДФЛ посчитался как 8515 рублей, хотя оклад 65 000? По моим расчетам должно быть 8450!»
Нейросети нужно залезть в конкретную базу, посмотреть конкретный документ, проверить вытеснения, сходить в регистры за прошлые периоды и найти причину.
Нам нужен был не умный справочник. Нам нужен был автономный агент.
Концепция ReAct: Даем ИИ "руки" и "глаза"
Я использовал паттерн ReAct (Reasoning and Acting) на базе фреймворка LangGraph (Python).
Суть в том, что мы даем языковой модели набор инструментов (tools) в виде HTTP-вызовов к серверу 1С. Получив вопрос, агент вступает во внутренний цикл:
-
Thought (Мысль): «Так, меня просят проверить НДФЛ. Сначала мне нужно получить данные из этого документа».
-
Action (Действие): Вызывает метод API get_calculation_details.
-
Observation (Наблюдение): Получает JSON с табличной частью документа.
-
Thought (Мысль): «Ага, я вижу оклад 65 000 и НДФЛ 8515. Действительно, не сходится. Пойду поищу историю начислений в регистрах за прошлые месяцы».
-
Action (Действие): Пишет 1С запрос и дергает API execute_1c_query.
-
И так далее, пока не найдет ответ.
Как это выглядит на практике (Разбор реального кейса)
Давайте посмотрим на то, как агент разбирает ту самую проблему с Солодовниковой из примера выше.
Демонстрация работы агента в интерфейсе 1С и терминале.
Давайте заглянем под капот и почитаем реальные логи оркестратора. Наблюдать за ходом мыслей ИИ — отдельный вид удовольствия. Модель ведет себя как настоящий стажер, который впервые открыл консоль запросов 1С и собирает все грабли синтаксиса. Но, в отличие от человека, она не впадает в депрессию, а методично исправляет свои ошибки.
Шаг 1. Погружение в контекст
Получив задачу («проверь начисленный НДФЛ по Солодовниковой...») агент первым делом читает локальную шпаргалку docs/Начисление зарплаты и взносов.md. Затем он дергает инструмент get_1c_calculation_details и получает табличную часть документа.
Шаг 2. Первая ошибка (Незнание таблиц)
Агент решает проверить налог запросом к документу и пишет:
ВЫБРАТЬ НДФЛ.ФизическоеЛицо...
Наш сервис 1С возвращает агенту ошибку: Поле не найдено "НДФЛ.Регистратор".
ИИ извиняется (внутренне), переписывает запрос правильно и успешно вытаскивает сумму налога из документа — 8 515 руб.
Шаг 3. Идем в регистры и ломаемся об Перечисления
Дальше агент понимает: чтобы найти причину расхождения, нужно лезть в историю — в РегистрНакопления.НачисленияУдержанияПоСотрудникам. Он пишет запрос, пытаясь отфильтровать НДФЛ через перечисление: ЗНАЧЕНИЕ(Перечисление.ВидыВзаиморасчетовССотрудниками.НДФЛ).
И снова получает по рукам от 1С Неверные параметры "Перечисление.ВидыВзаиморасчетов...".
Шаг 4. Осознание структуры
Агент понимает, что галлюцинирует архитектуру ЗУП. Он вызывает инструмент get_metadata("РегистрНакопления.НачисленияУдержанияПоСотрудникам").
Наш сервис отдает ему JSON со всеми измерениями, ресурсами и реквизитами регистра.
Шаг 5. Боль, страдания и синтаксис 1С
Получив метаданные, агент пытается написать правильный запрос, но тут начинается череда великолепных ошибок, знакомых каждому начинающему 1С-нику:
-
Ошибка даты: Агент пишет условие Период <= '2021-09-30'. 1С падает: Синтаксическая ошибка "'2021-09-30'" (забыл слово ДАТА).
-
Ошибка GUID'а: Агент решает использовать параметры. Он создает параметр &ФизЛицо, но вместо GUID'а сует туда строку с ФИО: "Солодовникова Мария Пахомовна". Наш Python-оркестратор ловит ошибку от 1С: ОШИБКА: Битый GUID или объект не существует.
-
Ошибка ПРЕДСТАВЛЕНИЯ: Агент решает обойти GUID и ищет по строке: ПРЕДСТАВЛЕНИЕ(НачислениеУдержание) ПОДОБНО "%НДФЛ%". 1С снова неумолима: Неверные параметры "ПОДОБНО" (нельзя использовать ПОДОБНО к функции ПРЕДСТАВЛЕНИЕ).
Шаг 6. Финальный успех и победа над контекстом
Спустя 4 итерации правок, агент находит верный синтаксис. Запрос отрабатывает и выплевывает 290 строк истории по НДФЛ сотрудника, начиная аж с 2012 года!
Срабатывает наш предохранитель: 1С обрезает выборку до 100 строк и шлет агенту предупреждение: "Запрос вернул слишком много данных... Чтобы не переполнять контекст, показаны только первые 100".
Этих данных агенту хватает. Он анализирует полученный JSON истории и выдает подробный ответ с разбором базы налогообложения.
Агент делает математический расчет: (65 000 + 500) * 13% = 8 515 руб. и выводит в интерфейс красивый, аргументированный ответ о том, что ошибки нет — система правомерно обложила налогом расходы на проезд.

Скриншот ответа агента из переписки в интерфейсе 1С
Но чтобы заставить LLM работать с 1С так стройно, нам пришлось решить несколько серьезных архитектурных проблем.
Обучаем LLM "видеть" 1С: Метаданные, безопасный запрос и СКД
Локальные модели (да и облачные тоже) имеют одну неприятную особенность — они обожают галлюцинировать. Если попросить ИИ написать запрос для 1С:ЗУП, он с радостью сгенерирует что-то вроде:
ВЫБРАТЬ * ИЗ Документ.НачислениеЗарплаты.Сотрудники
(Спойлер: табличная часть называется Начисления, а не Сотрудники).
Чтобы наш агент не фантазировал, я не стал загружать структуру всей конфигурации ему в системный промпт (это съело бы весь контекст). Вместо этого мы дали ему инструменты динамического исследования базы.
1. «Очки» для нейросети: инструмент get_metadata
Когда агент сомневается в именах таблиц или полей, он вызывает HTTP-метод get_metadata, передавая имя объекта (например, РегистрНакопления.НачисленияУдержанияПоСотрудникам).
На стороне 1С мы программно читаем метаданные и собираем их в удобный JSON. Но мы отдаем не просто шапку и табличные части. Для ЗУП критически важно знать архитектуру регистров, поэтому мы бережно собираем коллекции:
// Выдержка из HTTP-сервиса 1С
Ответ.Вставить("name", ОписаниеМетаданных.Имя);
Ответ.Вставить("dimensions", МассивИзмерений); // Измерения регистра
Ответ.Вставить("resources", МассивРесурсов); // Ресурсы
Ответ.Вставить("attributes", МассивРеквизитов); // Реквизиты
Ответ.Вставить("standard_attributes", МассивСтандартных); // Регистратор, Период и т.д.
Инсайт: Локальным моделям уровня Gemma-4:31b этого хватает с головой, чтобы построить в уме идеальную схему таблиц и написать рабочий запрос без ошибок (почти).
2. Безопасный запрос и укрощение GUID
Отправлять "сырые" строки от ИИ напрямую в Запрос.Выполнить() — это самоубийство. И дело даже не в безопасности самих данных (к счастью, 1С запросы работают только на чтение данных). Проблема в типизации и GUID-ах.
Если ИИ хочет найти данные по конкретному документу, он пишет запрос:
ГДЕ Ссылка = '3e16bbde-f9b8-11eb-80dd-4cedfb682551'
База 1С радостно падает с ошибкой несовместимости типов (Строка и Ссылка).
Мое решение: Я жестко запретил ИИ использовать GUID напрямую в тексте запроса. Вместо этого он обязан передавать их массивом параметров query_parameters (со строгой Pydantic-схемой на стороне Python).
Внутри 1С мы ловим этот массив, парсим тип объекта и конвертируем строку в реальную ссылку:
// Превращаем JSON-параметр от ИИ в ссылку 1С
УИД = Новый УникальныйИдентификатор(ЗначениеGUID);
МассивТипа = СтрРазделить(СтрокаТипа, "."); // Например: "Документ.НачислениеЗарплаты"
КлассОбъекта = НРег(МассивТипа[0]);
ИмяОбъекта = МассивТипа[1];
Если КлассОбъекта = "документ" Тогда
ЗначениеПараметра = Документы[ИмяОбъекта].ПолучитьСсылку(УИД);
// ... устанавливаем Запрос.УстановитьПараметр()
Предохранитель от переполнения контекста:
Что если ИИ напишет ВЫБРАТЬ * ИЗ РегистрНакопления.ОтработанноеВремя без условий? В ЗУП это могут быть миллионы записей. Огромный JSON улетит в Python и гарантированно вызовет OutOfMemory у локальной LLM.
Мы перехватываем этот момент на этапе сериализации:
Если ТаблицаЗначений.Количество() > 100 Тогда
Ответ.Вставить("warning", "ВНИМАНИЕ! Запрос вернул слишком много данных (" + ТаблицаЗначений.Количество() + " строк). Чтобы не переполнять контекст, показаны только первые 100. Добавь отборы в секцию ГДЕ, используй СГРУППИРОВАТЬ ПО или агрегатные функции (СУММА, МАКСИМУМ).");
// Жестко обрезаем ТЗ до 100 строк перед сериализацией в JSON
КонецЕсли;
Нейросеть получает этот предупреждение, понимает, что облажалась, и сама переписывает запрос с агрегатными функциями.
3. Как мы научили ИИ использовать отчеты 1С
Вытащить НДФЛ через запрос еще можно. А теперь представьте, что пользователь просит: "Выведи расчетный листок Иванова" или "Покажи штатное расписание". Писать запрос для таких вещей с нуля — это задача более серьезная, данные могут собираться из разных таблиц и иметь тонкие условия запросов.
В 1С уже есть сотни готовых отчетов на СКД. Мы написали инструмент execute_1c_report, который позволяет ИИ запускать типовые отчеты как функции!
Но СКД генерирует красивый табличный документ. LLM такое "кушать" не умеет. Ей нужен плоский JSON.
Я написал программный "бульдозер", который сносит всю визуальную структуру СКД и заставляет ее выплевывать сырые данные в ТаблицуЗначений:
// 1. Очищаем структуру (удаляем визуальные группировки разработчика)
Настройки.Структура.Очистить();
// 2. Добавляем ключевые поля, чтобы они не пропали
ПоляДляДобавления = Новый Массив;
ПоляДляДобавления.Добавить("Сотрудник");
// ... добавляем поля в Выбор ...
// 3. Создаем плоскую группировку "Детальные записи"
ГруппировкаДетальныеЗаписи = Настройки.Структура.Добавить(Тип("ГруппировкаКомпоновкиДанных"));
ГруппировкаДетальныеЗаписи.Использование = Истина;
ГруппировкаДетальныеЗаписи.Выбор.Элементы.Добавить(Тип("АвтоВыбранноеПолеКомпоновкиДанных"));
// 4. Указываем генератор для коллекции значений, а не для ТабДока!
МакетКомпоновки = КомпоновщикМакета.Выполнить(Схема, Настройки, , , Тип("ГенераторМакетаКомпоновкиДанныхДляКоллекцииЗначений"));
// Процессор выводит результат прямо в плоскую Таблицу Значений
ПроцессорВывода = Новый ПроцессорВыводаРезультатаКомпоновкиДанныхВКоллекциюЗначений;
ПроцессорВывода.УстановитьОбъект(ТаблицаРезультат);
ПроцессорВывода.Вывести(ПроцессорКомпоновки);
ИИ передает параметры (например, { "Сотрудник.Наименование": "Иванов" }), наш код находит их в КомпоновщикНастроек, подставляет и возвращает плоский массив данных. Агент счастлив, разработчик избавлен от написания мега-запросов.
Правда не все отчеты работают подобным образом, в дальнейшем планирую перетащить отчеты в расширение например с префиксом ИИ и более глубоко их адаптировать для работы с ИИ прописав инструкции для каждого, чтобы ИИ могла сама принимать решение о использовании отчета, знала какие параметры, отборы есть, какие данные возвращает и т.д.
4. Файловый RAG: Замена векторным базам данных
Мы принципиально не используем векторные базы (ChromaDB / FAISS) для работы с архитектурой 1С. Когда расчет ЗУП завязан на десятки общих модулей, кусковое извлечение текста (chunking) убивает логику алгоритма.
Вместо этого мы написали эмулятор работы программиста. У агента есть инструменты для работы с локальной папкой (WORKSPACE_DIR):
-
list_directory (аналог ls) — посмотреть, что лежит в папке.
-
search_in_files (аналог grep) — найти текст (например, формулу) по всем файлам исходного кода 1С (мы просто сделали выгрузку конфигурации в EDT).
-
read_file — прочитать кусок файла (с жестким лимитом на 300 строк).
Системный промпт: Как "воспитать" Gemma-4
Локальные модели требуют более жесткого структурирования, чем облачная крупная GPT. Системный промпт нашего агента больше похож на воинский устав. Вот несколько выдержек, которые спасли нас от хаоса:
-
«ТЕБЕ ЗАПРЕЩЕНО отвечать "я не смог получить данные", пока ты не выполнишь ВСЕ шаги поиска» (Лечит лень модели).
-
«ЗОЛОТОЕ ПРАВИЛО 1С:ЗУП: НИКОГДА не вычисляй итоговые суммы из таблиц Документов. Истинные суммы ВСЕГДА бери из РегистрРасчета».
-
«У документов НЕТ реквизита "Наименование". КАТЕГОРИЧЕСКИ ЗАПРЕЩЕНО писать Регистратор.Наименование. Используй функцию ПРЕДСТАВЛЕНИЕ(Регистратор)».
-
«БЕЗ LaTeX: ТЕБЕ КАТЕГОРИЧЕСКИ ЗАПРЕЩЕНО использовать синтаксис LaTeX для математических формул (никаких символов $$, \times). Используй стандартные знаки (, /).»* (1С-ное поле HTML документа ломалось от разметки LaTeX).
Это только начало пути (суровая реальность)
Сразу хочу оговориться: код и архитектура, показанные в этой статье — это не готовый продукт, который можно скачать, нажать «Далее-Далее-Готово» и уволить половину первой линии поддержки. Это концепт, MVP (Minimum Viable Product), инженерный дневник.
Я хотел показать главное: языковой модели можно безопасно доверить базу 1С:ЗУП, не нарушая NDA и законы о персональных данных. Локальная Gemma-4:31b, если дать ей правильные инструменты (метаданные, безопасные запросы, плоские СКД и файловый RAG), способна рассуждать как крепкий разработчик-стажер (а может и сеньор если дообучить).
Но мы честно признаем текущие ограничения:
-
Зацикливания. Иногда локальная модель "упрямится". Получив ошибку, она может попытаться отправить тот же самый запрос еще раз. Именно поэтому в оркестраторе LangGraph мы используем жесткое ограничение количества шагов (max_iterations), а в промпте пишем капсом запреты на повторение ошибок.
-
Ограничения контекста. Контекстное окно не бесконечно. Если агент прочитает три длинных общих модуля подряд и запросит таблицу на 500 строк, он просто "забудет" изначальный вопрос пользователя. Поэтому строгая обрезка строк (как в read_file, так и в запросах) — это вопрос выживания агента.
Куда мы движемся дальше?
Текущая реализация (чат в интерфейсе 1С с ожиданием ответа) — это лишь первый шаг. Сейчас это начало, тесты, но в моем бэклоге еще много планов по развитию этой архитектуры:
-
Асинхронность и фоновые задания. Ждать 40-60 секунд, пока агент анализирует логику вытеснений, глядя в зависший интерфейс 1С не хорошо. Мы планируем перевести общение в асинхронный формат. Например бухгалтер задает вопрос, 1С ставит фоновое задание, и когда агент находит ответ — пользователю приходит уведомление (Система Взаимодействия 1С например).
-
Проактивный аудит («Ночной дозор»). Зачем ждать вопроса от расчетчика? Агент может запускаться по регламентному заданию ночью: формировать типовые СКД-отчеты по проверке НДФЛ, искать минуса в регистрах, несостыковки в документах . К утру на столе у бухгалтера будет лежать сгенерированный отчет: "За ночь найдено 3 аномалии, вот причины, вот документы, в которых нужно поправить даты, суммы и т.д".
-
Дообучение модели. Сейчас мы тратим много токенов в системном промпте, объясняя модели особенности синтаксиса 1С (что нет COUNT, а есть КОЛИЧЕСТВО, что нужно использовать ПРЕДСТАВЛЕНИЕ() и т.д.). В планах — собрать датасет из успешных запросов к 1С и дообучить локальную модель (LoRA,DoRA), чтобы она писала запросы к 1С интуитивно. Благо БСП распространяется по лицензии Attribution 4.0 International (CC BY 4.0) и из нее можно брать легально качественные примеры. В перспективе можно на лету собирать данные для дообучения например с помощью ATLAS (Adaptive Teaching and Learning Alignment System).
-
Чтение кода через AST. Сейчас агент ищет код 1С полнотекстовым поиском по выгрузке EDT. Мы хотим дать ему инструмент, который будет парсить код 1С в абстрактное синтаксическое дерево (AST) и отдавать агенту только нужные процедуры со всеми их зависимостями, очищенные от "мусора".
Скрещивание локальных LLM и 1С — это непаханое поле. Инструментов мало, практики еще не сформированы.
Надеюсь, что данный архитектурный подход окажется полезным сообществу.
Проверено на следующих конфигурациях и релизах:
- Зарплата и управление персоналом КОРП, редакция 3.1, релизы 3.1.34.251
Вступайте в нашу телеграмм-группу Инфостарт