Сначала — что такое MCP
Прежде чем говорить о Buddy, нужно разобраться с аббревиатурой. MCP (Model Context Protocol) — это открытый протокол, предложенный Anthropic, который позволяет языковым моделям (Claude, GPT и другим) подключаться к внешним инструментам и источникам данных. Грубо говоря, это USB-стандарт для AI: хочешь дать модели доступ к Jira — подключаешь MCP-сервер для Jira. Хочешь к GitLab — подключаешь MCP-сервер для GitLab.
Каждый такой сервер — это небольшая программа, которая «переводит» команды от AI в реальные API-вызовы и возвращает данные обратно в понятном для модели виде.
До появления MCP AI знал только то, что вы ему рассказали в чате. С MCP он может сам пойти и посмотреть.
Что такое Buddy MCP сервер
Buddy — это не один MCP-сервер, а концепция: единый агрегирующий сервер (или конфигурация из нескольких серверов), который объединяет все инструменты вашей команды в одну точку контекста для AI-ассистента.
В живой реализации это обычно не просто «прокси на три MCP». Это небольшой серверный продукт: ядро с HTTP/MCP-транспортом, OAuth/SSO, хранилищем сессий и аудита, коннекторами к корпоративным системам и install-страницей для клиентов. Но для разработчика всё равно остаётся одна MCP-запись в конфиге:
"buddy-mcp": {
"url": "https://buddy.your-company.ru/mcp/v1",
"headers": {}
}
Представьте нового коллегу в команде. Умного, быстрого, готового помочь. Но в первый день он не знает ничего: ни как устроен проект, ни где лежит документация, ни что было в задаче, которую вы сейчас правите. Приходится объяснять всё с нуля каждый раз.
Buddy-сервер решает именно эту проблему. AI-ассистент с подключённым Buddy знает:
- Какие задачи сейчас в работе и что в них написано
- Какой код связан с каждой задачей
- Что задокументировано и где это найти
- Кто что делал и почему принималось то или иное решение
Это не «умный чат-бот». Это коллега, который уже всё прочитал.
Зачем это командам разработки
1С-разработка редко живёт в вакууме. Даже небольшая продуктовая команда обычно имеет:
- Трекер задач (Jira, Yandex Tracker, Redmine, Bitrix)
- Базу знаний (Confluence, Notion, Wiki, даже папку с Word-документами)
- Репозиторий (GitLab, GitHub, Bitbucket — или хотя бы хранилище 1С)
- Чаты (Teams, Telegram, Slack)
Buddy-подход говорит: подключи всё это к AI один раз — и перестань объяснять контекст вручную снова и снова.
Как Buddy устроен: один сервер для всей команды
Разница между Buddy и «набором MCP-серверов» не в функциях, а в том, как это разворачивается на команду.
Без единой точки входа каждый разработчик настраивает всё сам: токен для Jira, токен для Confluence, токен для GitLab, ссылка на репозиторий, пространство в вики... Десять человек в команде — это потенциально сотня конфигураций, которые расходятся, устаревают и ломаются в разное время у разных людей.
Один токен вместо десяти. Buddy-сервер подключается к инструментам один раз — на уровне сервиса. Jira, Confluence, GitLab авторизуются через сервисные аккаунты, которые настраивает администратор. Разработчик не думает об этом вообще.
На сервере это минимально превращается в один контейнер с HTTP-приложением. Например, backend на Go/Fiber публикует наружу /mcp/v1, держит OAuth-маршруты, пишет аудит в Postgres и регистрирует MCP tools из внутренних коннекторов:
services:
buddy-server:
image: your-registry/buddy-mcp-server:latest
env_file: .env
environment:
APP_NAME: buddy-server
HTTP_HOST: 0.0.0.0
HTTP_PORT: 8080
OAUTH_ENABLED: "true"
MCP_TRANSPORT_PATH: /mcp/v1
MCP_PUBLIC_BASE_URL: https://buddy.your-company.ru
ports:
- "127.0.0.1:8080:8080"
restart: unless-stopped
Клиентам при этом не важно, какие именно коннекторы живут внутри. Для них есть один адрес: https://buddy.your-company.ru/mcp/v1.
В общем виде архитектура выглядит так:
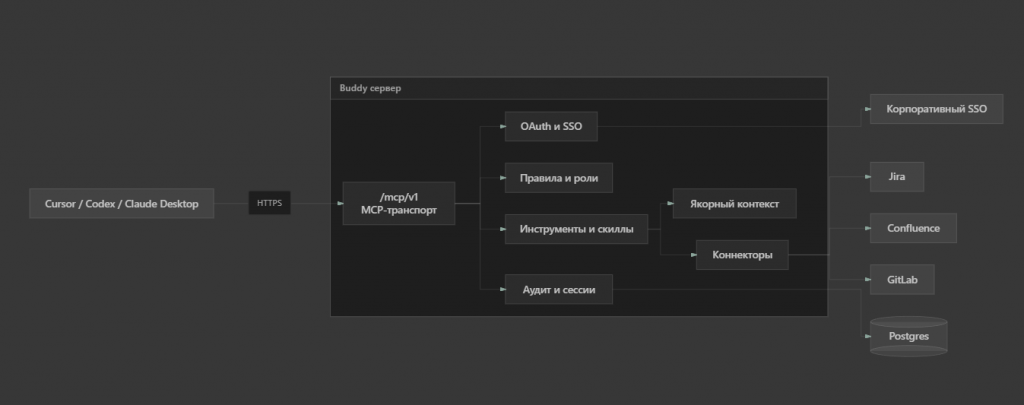
Клиент подключается к одному URL и работает через MCP. Внутри Buddy решает, какие коннекторы вызвать, как сходить в SSO и что записать в аудит. Корпоративные системы наружу не торчат — они доступны только через сервер.
SSO для всей команды. Buddy подключается к корпоративному провайдеру аутентификации — тому же, через который сотрудник входит в почту или VPN. Новый человек в команде получает доступ к AI-ассистенту со всеми инструментами в момент создания корпоративного аккаунта. Никаких отдельных регистраций и инструкций.
Часто это оформляется вообще без ручного редактирования JSON: разработчик открывает install-страницу, подтверждает подключение — и MCP сам появляется в клиенте.
https://buddy.your-company.ru/mcp/install
Общий контекст для всех. В Buddy можно задать набор общих файлов — архитектурные схемы, соглашения о кодировании, глоссарий, шаблоны задач — которые автоматически попадают в контекст AI для каждого члена команды. Один раз положил, все пользуются.
Технически это может быть не «папка с промптами», а полноценный слой контекста: сервер читает корпоративные якорные страницы, правила маршрутизации, системные реестры и отдаёт их AI-клиенту как часть MCP-инструкций и доступных tools.
Централизованный контроль. Все обращения к внешним сервисам идут через один сервер, который логируется и управляется. Для команд, которые осторожно относятся к AI-инструментам с точки зрения безопасности, это важнее, чем кажется: вместо десятков личных аккаунтов на сторонних платформах — одна точка аудита.
В production вокруг этого появляются отдельные контуры: админка для управления пользователями и ролями, хранение пользовательских токенов, аудит каждого вызова инструмента и ограничение доступа по ролям и окружениям. В сумме внедрение AI-ассистента перестаёт быть задачей на месяц: администратор настраивает Buddy один раз, а каждый новый разработчик просто логинится в удобном клиенте — Cursor, Codex, Zed, Claude-cli, Claude Desktop и так далее.
Что подключают на практике
Набор возможностей внутри Buddy определяется стеком конкретной команды. Нет единственно правильного списка: если у вас YouTrack вместо Jira, Notion вместо Confluence или GitHub вместо GitLab — подключаете то, что есть. Для пользователя это всё равно остаётся одним подключением, а маршрутизация по задачам, документации, коду и другим корпоративным источникам происходит уже внутри Buddy.
Jira MCP даёт AI прямой доступ к трекеру: читать задачи, acceptance criteria, комментарии, историю статусов, связанные баги. Вместо того чтобы пересказывать задачу в чате, вы просто говорите «разберись с DEV-412» — и AI сам идёт её читать, ищет связанные, анализирует.
JIRA_BASE_URL=https://jira.your-company.ru
JIRA_USERNAME=buddy-bot@your-company.ru
JIRA_API_TOKEN=...
JIRA_PROJECT_ALLOWLIST=DEV,ARCH,OPS
Confluence MCP открывает базу знаний: спецификации, архитектурные решения, регламенты, историю правок документов. Для 1С-команд особенно ценно при разборе багов — AI сразу проверяет, соответствует ли поведение задокументированной логике, а не тому, что вы описали в чате.
CONFLUENCE_BASE_URL=https://wiki.your-company.ru
CONFLUENCE_USERNAME=buddy-bot@your-company.ru
CONFLUENCE_API_TOKEN=...
CONFLUENCE_SPACE_ALLOWLIST=ARCH,DEV,KB
GitLab MCP — это история коммитов, merge request'ы, ветки и код. Полезный GitLab-коннектор внутри Buddy — не «дай AI прочитать файл», а маршрут по инженерной истории проекта:
- разработчик говорит «посмотри сервис заказов» — Buddy сначала помогает AI найти правильный проект в большой инсталляции, где название системы и путь к репозиторию редко совпадают;
- на вопрос «почему так написано?» AI идёт не в текущий файл, а в merge request: читает diff, комментарии ревью и обсуждение, в котором принималось решение;
- когда падает сборка, AI открывает pipeline, находит упавший job и читает его лог — а не просит у разработчика скриншот ошибки.
И всё это под централизованным контролем: какие репозитории видны, какие действия разрешены и что попадает в аудит — решает Buddy, а не личный токен на ноутбуке разработчика.
Админка. Когда Buddy становится общекомандным инструментом, рядом с ним почти неизбежно появляется отдельный интерфейс администрирования. Не для красоты, а для простых эксплуатационных вещей: посмотреть, кто подключён, кому разрешены write-действия в Jira, какие токены заведены — и что именно делал AI от имени конкретного пользователя.
Локальный bridge. Не все клиенты умеют или могут напрямую ходить в корпоративный MCP endpoint. Для них ставят тонкий локальный адаптер: он открывает браузер для входа через SSO, сохраняет токены в системном хранилище пользователя и передаёт запросы дальше в Buddy. Логика доступа, аудита и работы с корпоративными системами при этом остаётся на сервере.
Главный тезис: связность данных — это не удобство, это мультипликатор
Каждый из описанных MCP-серверов сам по себе полезен. Но их настоящая сила раскрывается только при условии: когда ваши данные связаны между собой.
Граф знаний вашей команды
Представьте, что все инструменты вашей команды — это узлы в сети. Между ними могут быть связи:

Когда эти связи существуют, AI может обходить граф — начать с любой точки и добраться до полного контекста.
Конкретный сценарий: поиск причины бага
Ситуация: в production обнаружен баг — скидка для корпоративных клиентов с годовым контрактом считается неправильно. Завели задачу DEV-498. Говорите AI: «Разберись».
Без связности:
Вы пишете в чат: «Смотри, вот стек ошибки, вот кусок кода, клиент говорит что скидка 12% вместо 15%...» Объясняете контекст вручную, потом ещё уточняете детали, которые AI не знает. Полчаса — и вы ещё даже не начали искать причину.
Со связностью:
- Вы создаёте баг-задачу DEV-498 в Jira
- Говорите AI: «Разберись с задачей DEV-498»
- AI читает DEV-498 → находит задачу в которой велась разработка DEV-412 → читает DEV-412 → находит ссылку на Confluence-страницу → читает спецификацию → идёт в GitLab → находит ветку feature/DEV-412 → читает коммиты → видит, что в одном из коммитов была изменена логика округления → читает код → видит расхождение со спецификацией
AI возвращается к вам с конкретной гипотезой, ссылкой на конкретную строку кода и цитатой из спецификации, которой она противоречит.
И всё это — не задав ни одного уточняющего вопроса.
Почему это работает: принцип обхода контекстного графа
В информатике есть понятие связного графа: структуры, где из любой вершины можно добраться до любой другой по цепочке рёбер. Ваши рабочие инструменты образуют такой граф, если соблюдаются простые правила:
Правило 1. Задачи ссылаются на документацию
В описании Jira-задачи — ссылка на релевантную Confluence-страницу. Не пересказ документа, а именно ссылка.
Правило 2. Коммиты и ветки содержат номер задачи
feature/DEV-412 вместо feature/discounts-fix. Сообщение коммита содержит [DEV-412]. Это занимает 0 дополнительного времени и создаёт навигационный якорь.
Правило 3. MR/PR связаны с задачами
В GitLab MR указан номер Jira-задачи, которую он закрывает. Многие трекеры и Git-платформы умеют это автоматически при правильно оформленных коммитах.
Правило 4. Документация ссылается на задачи
Архитектурное решение в Confluence содержит ссылку на задачу, в рамках которой оно было принято. Через полгода, когда кто-то спросит «а почему так?» — у AI будет ответ.
Что происходит при соблюдении этих правил:
AI превращается из системы «вопрос-ответ» в систему автоматического расследования. Вместо того чтобы отвечать на основе вашего описания ситуации, он сам собирает полный контекст, обходя граф связей.
Практические рекомендации: как не получить «умного попугая»
Начните с малого, но правильно
Не нужно сразу подключать все инструменты. Начните с одной связки, которая приносит максимальную боль прямо сейчас. Для большинства команд это Jira + Confluence + GitLab: задачи и код. Убедитесь, что коммиты содержат номера задач — это единственное изменение в процессе, которое требует усилий. А дальше наращивайте практики: внедрите gitflow, введите code review, подключите интеграцию Git и трекера — и так далее.
Не дублируйте — ссылайтесь
Главная ошибка — копировать описание из Confluence в Jira. Нужно не копировать, а ссылаться. Один источник правды, везде — ссылка на него. Тогда граф остаётся актуальным. Есть полезная практика создания задач на основании страниц с описанием.
Пишите в Jira то, что нужно AI
Acceptance criteria, описание «почему так, а не иначе», ссылки на обсуждения — это не бюрократия. Это контекст, который AI будет использовать вместо вас. Хорошо описанная задача = меньше вопросов от AI = быстрее результат. Кстати, описание задачи подготовить тоже может AI, используя исторические данные в ваших системах как шаблон.
Используйте Buddy для code review
Когда разработчик открывает MR, AI с Buddy может самостоятельно: прочитать задачу, прочитать спецификацию из Confluence, прочитать изменения в коде и проверить, соответствует ли реализация требованиям. Это не замена code review — это предварительный фильтр, который снимает самые очевидные несоответствия до того, как другие люди потратят на это время.
Итог
Buddy MCP сервер — это не конкретный продукт с кнопкой «установить». Это архитектурный принцип: дай AI-ассистенту единый, связный доступ ко всем источникам контекста вашей команды.
Три слагаемых результата:
- MCP-серверы для каждого инструмента (Jira, Confluence, GitLab и другие) — технический фундамент
- Связность данных между инструментами — организационная практика, почти бесплатная, если ввести её с самого начала
- Правильные вопросы — когда контекст есть, качество ответов AI определяется качеством ваших запросов
Разработчик, работающий с Buddy в связной среде, тратит меньше времени на объяснение контекста и больше — на решение реальных задач.
Буду рад вопросам и опыту тех, кто уже пробовал похожие подходы — пишите в комментариях.
Вступайте в нашу телеграмм-группу Инфостарт