Представьте, что в вашей базе 1С произошла какая-то беда, случилась какая-то проблема. Может быть, кому-то и представлять не надо. И вы открываете данные техжурналов, чтобы увидеть там причину и ничего там не находите. Либо находите что-то, но части данных, как раз необходимых для расследования, вам не хватает.
К сожалению, иногда такое случается. Просто в этот момент техжурнал поворачивается к нам своей темной стороной. И я предлагаю на эту темную сторону посмотреть поподробнее.
Я не буду рассказывать про то, что такое техжурнал, как его настраивать, как он устроен и так далее. Но на основных вещах все-таки хочу остановиться.

Недавно была такая большая веха в плане техжурнала. В 8.3.25 у нас наконец-то появилась возможность использовать новый формат. До этого формат был один – только текстовый.
То есть очень верное определение формата техжурнала – то, что он был текстовый, потому что структура там была очень плавающая. Были переносы строк, это было неудобно для парсинга, для обработки и так далее.
И в 8.3.25 появилась возможность – это не формат по умолчанию, но появилась возможность использовать формат JSON. Теперь у нас каждое событие техжурнала находится в отдельной строке. Соответственно, удобно искать, удобно все это парсить и так далее.
Но в самой структуре техжурнала есть некоторые особенности. И эти особенности никуда не делись. Они были в старом формате, и большая часть из них осталась и в новом формате. И именно про них я хочу поговорить.
Дубли свойств
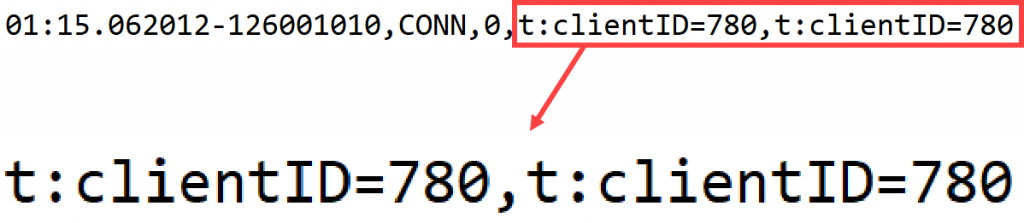
Первое, с чем приходится сталкиваться, – это дубли свойств. В данном примере у нас есть свойство t:clientID, и оно просто через запятую повторяется два раза. Благо, что именно в этом примере значение свойства одинаковое. Поэтому такая ситуация, помимо того, что очевидно: такого быть не должно, – особой проблемы не представляет. Потому что, как правило, во время парсинга парсеры оставляют последнее значение ключа. Если ключ дублируется, берется последнее значение. Так как значение одинаковое, проблемы нет. Но так бывает не всегда.

Вот, например, завершение транзакции, событие SDBL. И у нас там есть свойство Func, которое повторяется два раза, и значение этого свойства различное. И вот здесь при парсинге, как правило, первое значение потеряется, останется только второе.
И при настройке logcfg, то есть при настройке техжурнала, допустим, у вас будет задача на свойство Func установить фильтр. И вам придется думать: а к какому же из этих свойств ваш фильтр будет применен?
Маленький спойлер: ко второму, то есть к последнему значению. А на первое свойство получается, что у вас даже технической возможности поставить фильтр нет. Оно просто будет игнорироваться, фильтр будет применяться ко второму.
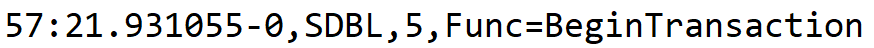
Причем такая загогулина есть только для завершения транзакции. А для начала транзакции и для большинства остальных событий все нормально. То есть Func у нас один. При завершении их почему-то два. Назовем это особенностями.
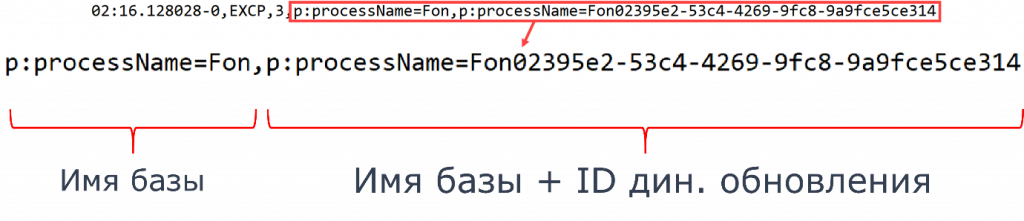
Помимо этого свойства есть другое популярное – p:processName. Его очень часто используют для фильтрации по имени базы. На самом деле в документации это свойство описано как серверный контекст, но в большинстве случаев туда пишется имя информационной базы 1С.
И если у вас было динамическое обновление, то могут появляться вот такие записи: сначала есть p:processName, потом идет запятая, потом еще раз p:processName, имя базы, а потом идет некий ID этого динамического обновления.
Чем это плохо? Опять же, при парсинге очень часто, если ключ повторяется, берется последнее значение. Соответственно, первое теряется, оно перезатирается. Если вы потом где-то в ClickHouse либо при использовании регулярных выражений рассчитываете на то, что у вас в этом свойстве лежит имя базы, то вас может ждать неприятный сюрприз. То есть это свойство равенства может не отработать.

То же самое свойство p:processName, но для других событий оно уже принимает совсем другой смысл. Здесь уже пишется не имя базы, и значения тоже разные. Обращаю ваше внимание: свойство одно и то же, но в разных ситуациях, в разных условиях значения пишутся абсолютно разные, так еще и дубли. Так что это тоже надо учитывать при парсинге, при построении скриптов.
Дубли событий
Итак, свойства у нас бывают разные, они могут дублироваться, и на них нельзя до конца положиться. Но, помимо этого, есть еще проблемы и с дублированием событий. Приведу пример.
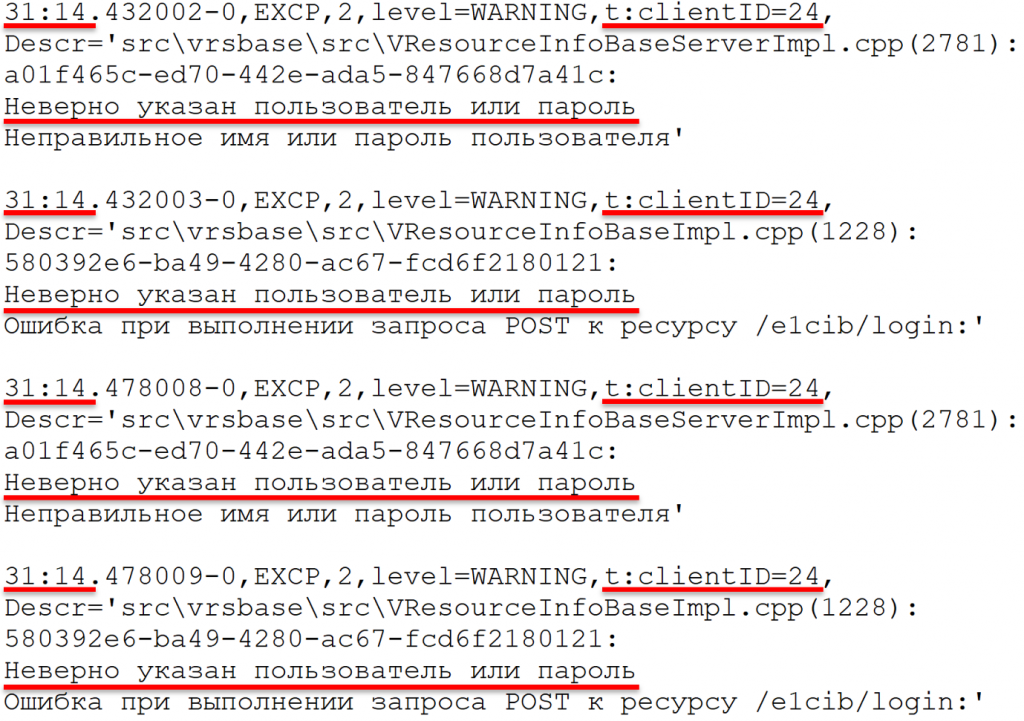
Вот фрагмент техжурнала. Я специально подчеркнул: у нас здесь событие EXCP. Судя по тексту ошибки, казалось бы, пользователь неверно ввел логин и пароль. Почему-то четыре раза подряд. Почему-то все это произошло в рамках одной секунды: 31 минута, 14 секунд. t:clientID один и тот же. То есть либо у пользователя очень быстрые пальцы, либо дело в чем-то еще.
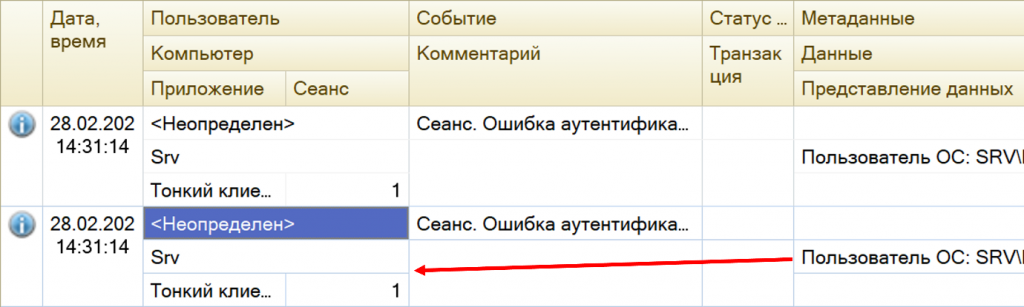
Если мы зайдем и откроем журнал регистрации, то увидим только два события. Одна и та же ситуация: в техжурнале событий четыре, в журнале регистрации событий – два.
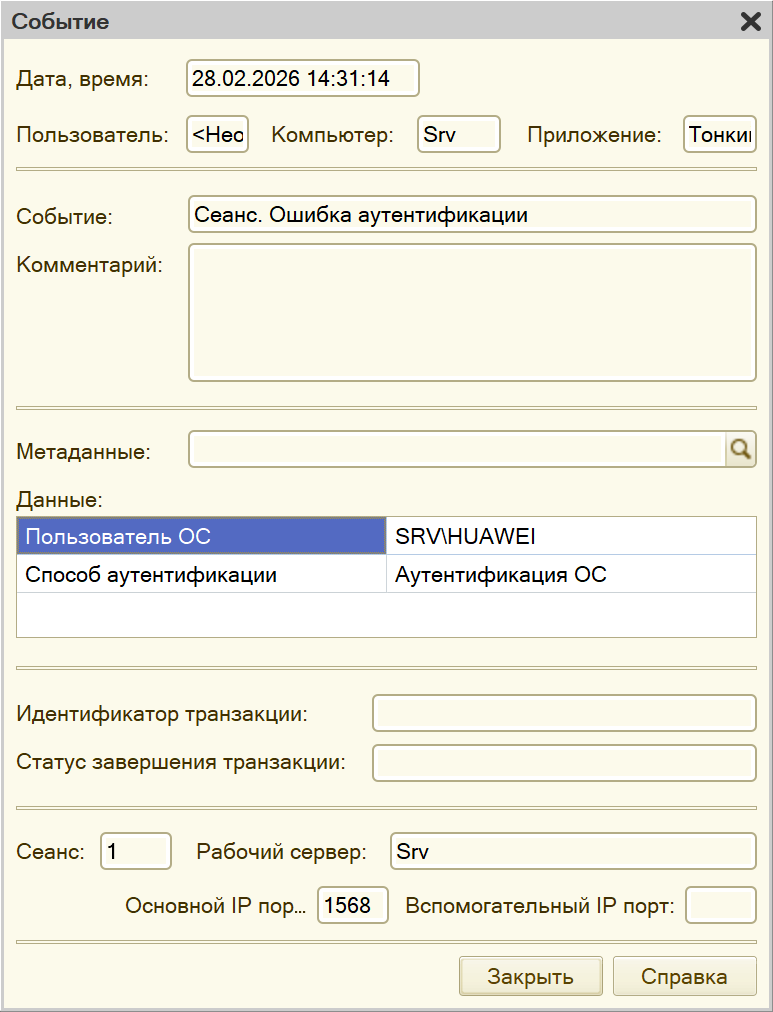
При этом, если мы откроем детали, то увидим, что как будто бы вход был с помощью аутентификации ОС. Хотя на самом деле – маленький спойлер – была попытка входа обычной аутентификации 1С. Но имени пользователя здесь нет.
И отсюда у меня вопрос. Просто подумайте: как, на ваш взгляд, увидев такую информацию, вы бы ее интерпретировали? Сколько попыток входа было на самом деле?
Попыток входа было… ни одной.
Дело в том, что все это – ложная ошибка, которая пишется в технологический журнал. У нее level написано warning, то есть высокий уровень. Но просто при появлении окна авторизации 1С пишет в техжурнал вот такие четыре ошибки неправильной авторизации, а в журнал регистрации пишет две.

Но при этом, когда вы действительно неправильно вводите логин и пароль, тогда в журнал регистрации пишется почти все то же самое. Благо ошибка хотя бы одна, хотя бы здесь ничего не дублируется.
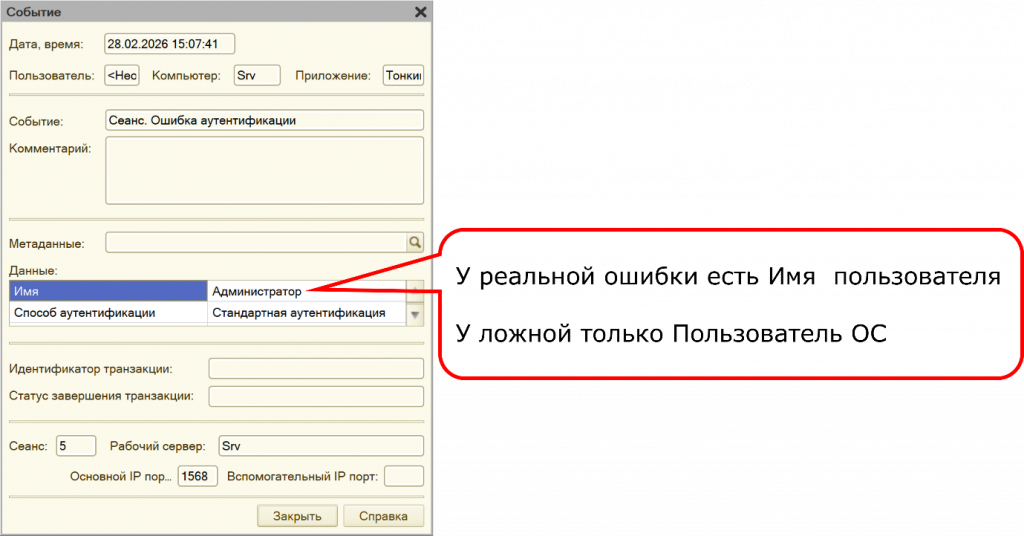
Но есть одно отличие: здесь появляется имя пользователя. Все-таки у реальной ошибки имя пользователя есть.
И, возможно, у вас вопрос: а как же тогда в техжурнале увидеть те ситуации, когда пользователь неправильно ввел логин и пароль?
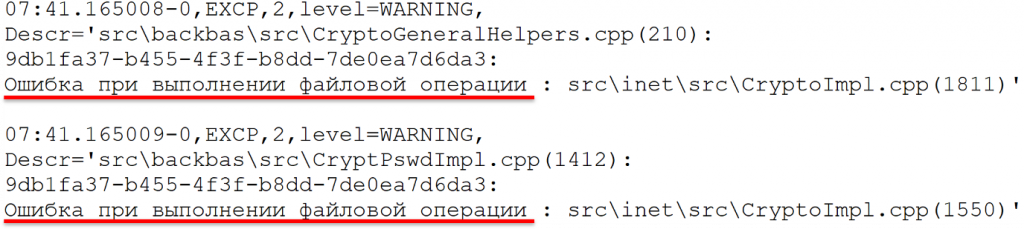
А вот так. Вот попробуйте догадаться, что это ошибка при вводе логина и пароля. Это реальная запись. Она все равно задублировалась, но надо было как-то догадаться.
Почему я на этом акцентирую внимание? Потому что вопросы безопасности сейчас очень актуальны. Во многих компаниях есть безопасники, у которых есть свои KPI, они делают отчеты. И бывает так, что в некоторых компаниях нужно предоставить отчет о том, сколько раз были попытки входа в систему, а мы такие молодцы отразили эти атаки и так далее.
Если вы будете ориентироваться на неверные записи в техжурнале, то в этих отчетах будет неверная информация.
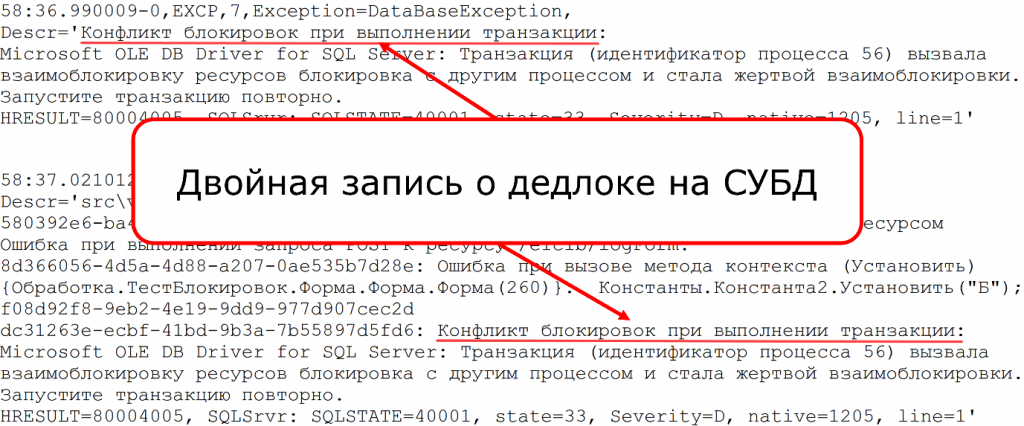
Но помимо логирования доступа есть и другие ошибки. Они могут быть менее критичны. Например, deadlock на СУБД. Тоже в техжурнал попадают две записи. Deadlock был один, а попадает два exception. Текст у них почти одинаковый.
Если ваша система мониторинга отслеживает вот эту подстроку – «конфликт блокировок» и так далее – и просто ведет подсчет, показывает вам, сколько было deadlock в системе, то вы можете видеть неверные данные.
Здесь решение гораздо проще. В первой строке видно: есть такое свойство – Exception=DataBaseException. Можно дополнительно фильтроваться по нему, чтобы не подгружать в вашу систему эти дубли и чтобы вы не думали, что у вас там очень много deadlock.
Поля «призраки»

Есть еще такая интересная категория полей. Я их называю «поля-призраки». Они в техжурнале могут неожиданно появляться и неожиданно исчезать.
Есть целый класс таких полей. Например, событие TLOCK – это событие установки управляемой блокировки. И у этого события есть такое свойство, называется escalating. Оно показывает, что была эскалация.
В итоге это свойство само по себе появляется в техжурнале только в тот момент, когда оно равно true. Если оно равно false, мы его в техжурнале никогда не увидим, его в принципе нет. А когда оно равно true, оно целиком появляется.
При этом тут же есть событие WaitConnections, которое показывает номер соединения виновника. И это событие присутствует всегда. То есть WaitConnections, неважно, заполнен он или пустой, всегда на месте. А вот escalating есть только в тот момент, когда он заполнен.

То же самое касается и свойств семейства LKP. LKP позволяют определять виновников на ожиданиях СУБД.
Поле «Sql» у событий DB…

Возможно, вы скажете: «Ну, это такие свойства, они большинству людей не нужны, это очень специализированные штуки». Но если бы все было так просто.
Есть замечательное свойство SQL. Туда пишется текст запроса. И иногда у события выполнения запроса не пишется текст запроса. То есть мы знаем, что запрос был, мы знаем, что он был долгий, мы даже контекст видим, откуда он вызывался. Но текста самого запроса, к сожалению, почему-то нет.
Такие ситуации тоже иногда бывают и очень доставляют неудобства. То есть даже свойство SQL, казалось бы, такое нерушимое и базовое, его очень часто используют при анализе, но на него тоже нельзя положиться в 100% случаев.
Особенности
Какие у нас еще есть особенности? Я объединил их сразу все в одну группу.

Есть такое замечательное свойство dbpid – это номер соединения с СУБД. В большинстве случаев оно заполнено, там стоит какая-то цифра. Но иногда вместо цифры может быть null. Либо может быть вообще пустота.
Если в ваших скриптах анализа используется некий шаблон, что в этом свойстве должна быть цифра, то такой шаблон просто эти строки не обработает.

Есть второе свойство, тоже часто используется, – номер сеанса. В некоторых событиях пишется не просто номер сеанса, а еще есть скобки, и в скобках пишется номер сеанса родителя. Такое тоже, к сожалению, бывает.
И если вы это не предусмотрели, не обработали или, опять же, в своей системе мониторинга в ClickHouse делаете фильтр SessionID равно тому-то, не учитывая, что в скобках может быть что-то еще, возможно, часть данных вы не увидите.

Имя пользователя. В большинстве событий это Usr, надо признать. Но бывают исключения: в некоторых это UserName.

Имя компьютера. Обычно это t:computerName. В некоторых событиях, как минимум в одном, – это ClientComputerName.
Эти особенности нужно знать и учитывать.
Анализ ожиданий

Это событие TLOCK. Казалось бы, известное событие, часто им пользуются для анализа управляемых ожиданий на управляемых блокировках.
Что здесь не так, на мой взгляд? Мы видим событие TLOCK. Видим, что была установлена блокировка на регистр накопления и на регистр сведений.
И теперь внимание, вопрос: как, на ваш взгляд, где же было ожидание? На регистре накопления или на регистре сведений? Где у нас проблемный объект?
Ответ здесь очень простой: исходя из одной этой записи мы не знаем. Потому что у нас есть просто WaitConnections=81. То есть мы установили блокировку на несколько объектов. Хорошо, что здесь их два, а вообще в конфигурации их может быть и пять, и более.
Чтобы понять, где было ожидание, на каком из объектов, нам надо найти виновника. А чтобы найти виновника, надо взять все эти номера соединений, TLOCK с номером соединения 81, и проверить, какие были установлены блокировки по всем этим таблицам. Более того, не просто по этим таблицам, а еще и по каким полям этих таблиц, чтобы там было пересечение. То есть одной этой записи в том виде, в каком она есть, нам просто не хватает для того, чтобы понять, где было ожидание.
Было бы логично, конечно, WaitConnections поместить внутрь свойства Locks, чтобы для каждого объекта был какой-то свой WaitConnection. Вот тогда эта запись в логе выполняла бы свою функцию. Сейчас она эту функцию выполняет далеко не всегда.
Контекст отделенный

С контекстом тоже очень интересная история. Возможно, вы часто встречали скрипты или сами их писали, пользовались ими, когда нам необходимо собрать какие-то события и сгруппировать их по последней строке контекста. Как правило, используется свойство Context, которое есть в самом событии. То есть у нас есть какое-нибудь событие DBMSSQL, и у него есть свойство Context. И там показан стек вызова: откуда этот запрос к нам прилетел.
Но иногда контекст пишется отдельным событием. То есть у самого события нет контекста, но под ним пишется само событие Context, и там показывается этот самый контекст.
Если в этих скриптах, в этих инструментах, которые вы используете, нет такой обработки, которая учитывает, что контекста может не быть, а если его нет, надо поискать отдельное событие Context с тем же номером, ClientId и так далее, то часть событий вы теряете, то есть вы не знаете их контекста.
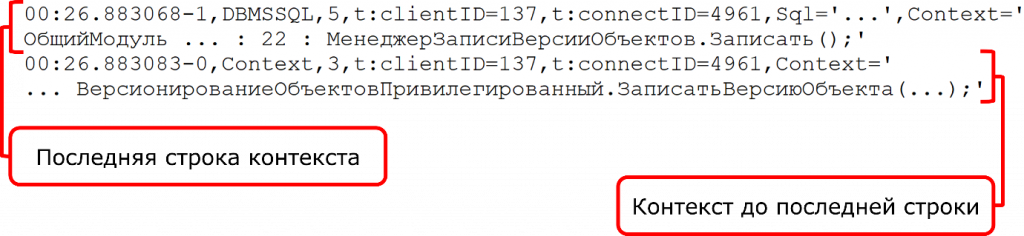
Но и тут все не так просто. Бывает, когда контекст разделяется. Часть контекста находится у самого события – последняя строчка, а все, что до последней строки, то есть с первой по предпоследнюю, пишется отдельным событием Context.
И тогда, чтобы получить весь стек вызова, надо взять само событие, его контекст, поискать отдельное событие Context, слепить их друг с другом – и только тогда вы получите полный стек вызова.
Попробуйте это скриптом сделать, если интересно. Очень занимательная задача.
Вездесущее событие

Есть еще интересное событие. Например, вы настраиваете что-то, хотите отловить запросы или call-события – неважно. И когда вы пишете парсер, неважно, скрипт это или еще что-то, вы рассчитываете, что там будут события только этого вида и больше никакие другие.
Но есть одно событие, которое пролезает практически везде. То есть как бы вы ни настраивали, оно может встретиться абсолютно неожиданно. Это событие называется Exception (EXCP).
Даже если вы ловите одни запросы или одни call-события, deadlock и прочее, записи с событием Exception вам все равно будут попадаться. И ваш парсер, если вы используете какой-то свой, ваши скрипты должны это учитывать, чтобы не падать, потому что у Exception свой набор полей.
" или '

Есть еще одна интересная вещь. В большинстве случаев это касается старого формата техжурнала, то есть текстового. В JSON с этим чуть-чуть получше, но все равно и в JSON тоже есть свои особенности.
Обычно техжурнал как пишется? Есть некая преамбула: метка времени и так далее. Потом идет имя события, потом идут свойства: свойство = значение, запятая. И дальше опять свойство, значение, запятая – и так далее. Вот такой формат описан в документации.
Но что, если у нас в самом значении содержится запятая? Как техжурнал это обрабатывает?
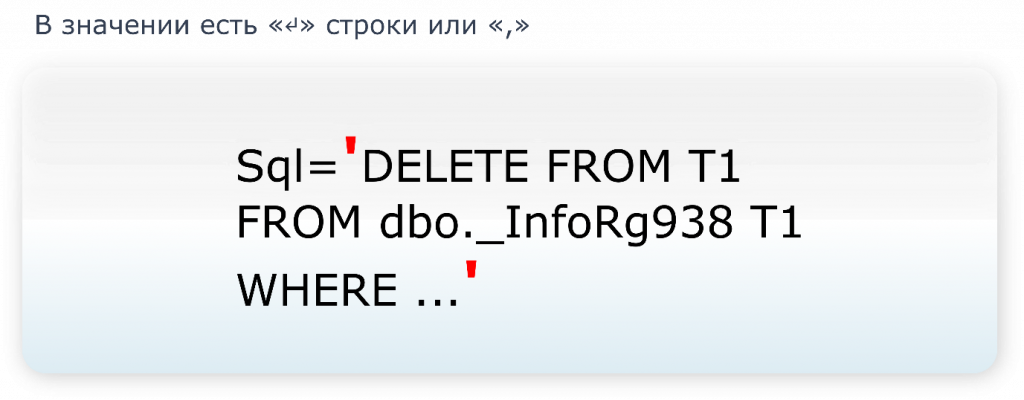
Открываем документацию, там написано: если в значении есть запятая либо перенос строки, тогда само значение обрамляется одинарной кавычкой, апострофом. О’кей, все просто.
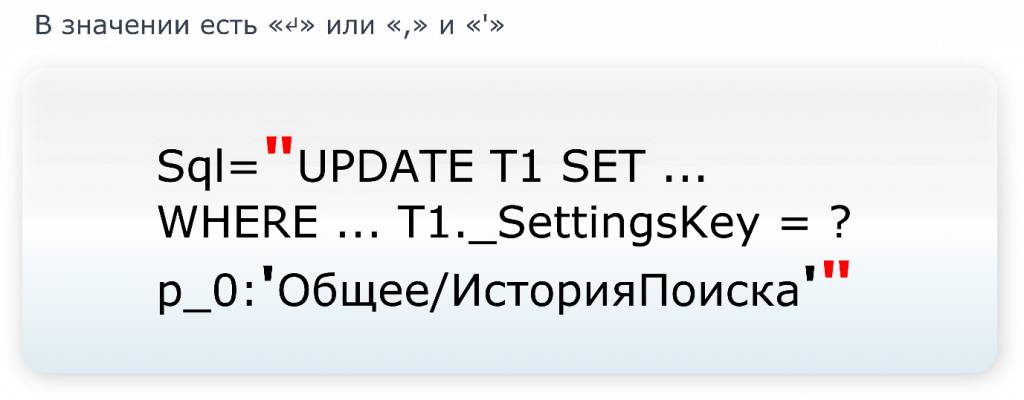
Но если у нас в самом значении есть апострофы, чем тогда обрамлять значение? Тогда мы обрамляем значение кавычками.

Но ведь возможна и третья ситуация, когда у нас есть и апострофы, и кавычки. И как же наш парсер должен разобраться и понять, где все-таки значение заканчивается?
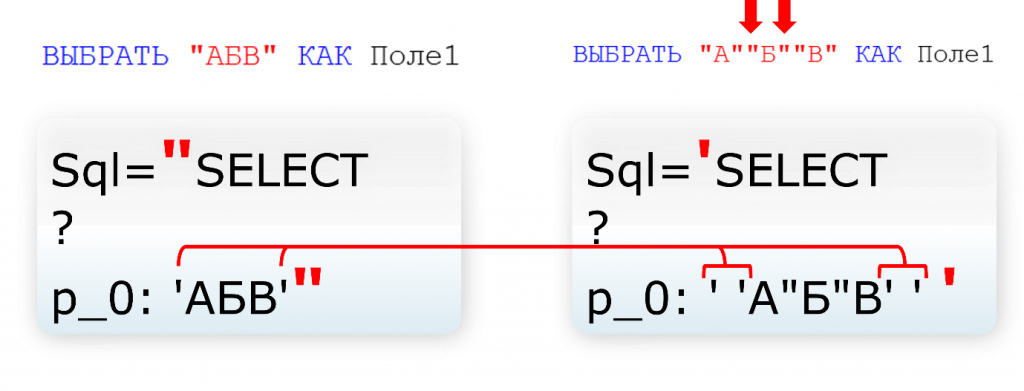
Что 1С говорит в этом случае? Покажу на примере, чтобы было нагляднее.

Если мы делаем вот такой запрос, он у нас запишется так, как показано ниже. Само значение, так как оно текстовое, в тексте запроса обрамляется апострофами. Соответственно, 1С видит, что в значении есть апострофы, и обрамляет само значение в кавычки.

А если у нас есть кавычки – в данном случае буква «Б» в кавычках, – 1С видит, что количество кавычек и количество апострофов одинаковое. В этом случае выбираются апострофы: все заключается в апострофы, кавычки остаются как были на месте, а апострофы внутри значения задваиваются.
Вот такая логика. Это в старом формате техжурнала.
Это к тому, что если вы решите написать свой универсальный парсер техжурнала – не JSON, а именно такой, который работает везде, на всех платформах, – просто поверьте, это попьет у вас несколько дней крови.
Если у вас есть JSON, то там все несколько проще. В JSON значение всегда обрамляется кавычками, что бы ни случилось. Но если кавычки встречаются внутри значения, они экранируются и все равно задваиваются. Зачем их задваивать, пока не очень понятно, но хотя бы они экранируются. То есть там все проще.
ИИ
Как же обойти эту популярную тему? Как можно, например, использовать искусственный интеллект для парсинга, для анализа логов?
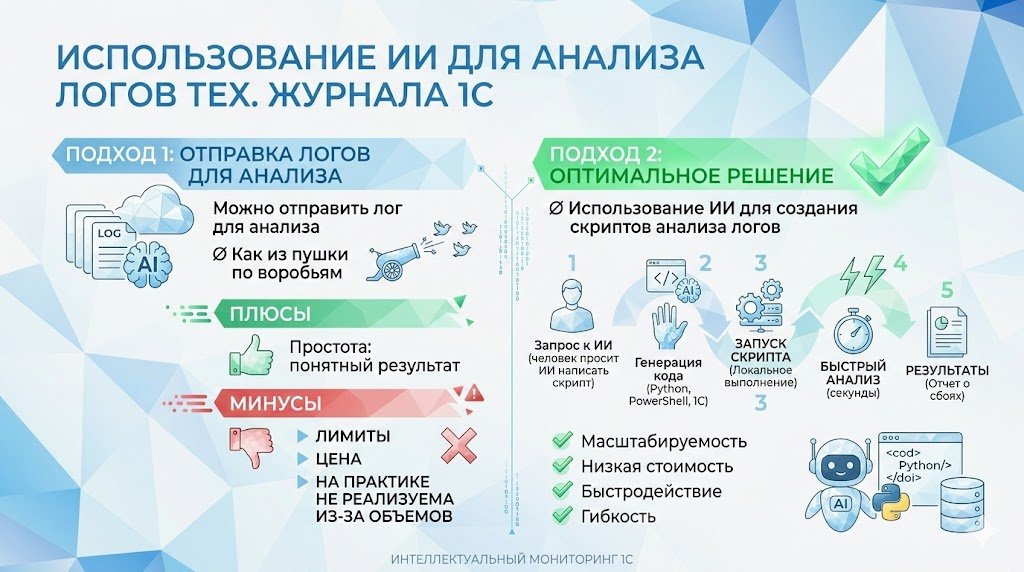
На мой взгляд, именно для такой базовой задачи анализа техжурнала есть два подхода.
Первый – когда вы берете техжурнал, либо его фрагмент, либо целиком, и закидываете его в ИИ. Говорите: «Уважаемый, вот такой-то формат техжурнала. Он простой, описывается буквально в два предложения. Сделай мне то-то и то-то». Что вам надо, так и пишите: «Сгруппируй мне по последней строке контекста» – и так далее.
На удивление, это очень хорошо работает, когда задача четкая и понятная, когда у него структурированный лог. Желательно с одним, максимум двумя событиями – он это все может переварить.
Но для реального использования, конечно, есть масса ограничений. Во-первых, объем логов у нас, как правило, большой. Гигабайты туда не покидаешь, потому что это дорого, никаких токенов не хватит. То есть есть некие лимиты. Это максимум десятки мегабайт.
Но есть и второй подход. Мы описываем задачу, описываем формат лога. Особенно если это JSON, можем кинуть ему маленький фрагмент и говорим задачу: «Сделай нам скрипт, который делает то-то и то-то» – то, что вам нужно.
Опять же, работает на удивление быстро. И да, он может поглючить пару раз. Вы эту ошибку берете, ему же скармливаете, он вам все переделывает. И этот скрипт вы потом, конечно, можете запускать уже на своих объемах, на своих гигабайтах. Это будет работать.
То есть вещь действительно удобная и на практике сильно ускоряет время, особенно когда надо сделать какую-то нетиповую штуку.
И тут же хочу буквально пару слов сказать. Есть такая интересная нейронка, называется NotebookLM от Google. Ее очень удобно использовать как свою персональную базу знаний.
Вы туда кидаете видео на YouTube, загружаете документацию по 1С, кидаете ссылки на статьи. А потом можете задавать ей вопросы, можете скармливать ей логи и так далее. Получается ваш личный советник, который закрывает вопросы по 1С. По крайней мере, он закрывает очень многие вопросы.
Заключение
Если вдруг после этой статьи вы стали относиться к логам немного с недоверием, может быть, не так стопроцентно им доверять, значит, моя статья была не зря.

Техжурнал – это, конечно, штука очень многогранная, местами очень сложная. Далеко не все темные стороны там освещены, особенно в документации.
И по-прежнему это великолепный, замечательный и незаменимый инструмент, потому что без него большинство проблем решить не получится.
Просто очень важно знать его тонкости, знать нюансы и особенности, потому что именно знание таких неочевидных вещей повышает вашу ценность, в том числе как специалиста.
Как говорится, знание – это свет. Так что, коллеги, будьте на светлой стороне.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAM EVENT.


Вступайте в нашу телеграмм-группу Инфостарт