















Когда-то 5 лет назад я написал статью Распознавание текста с помощью нейросетей Google Cloud Vision и 1С
С тех пор многое поменялось, и я решил написать новую статью, используя отечественные технологии Yandex Cloud
Принцип работы получившейся обработки очень простой: нужно сделать POST запрос с картинкой или pdf на сервер Яндекса. Файл нужно закодировать в base64, и получить json-ответ.
И, разобрав ответ, программа может получить распознанный текст. Детальное описание возможностей Yandex Vision API можно посмотреть по ссылке. А про распознавание текста и формат запроса и ответа есть подробная документация
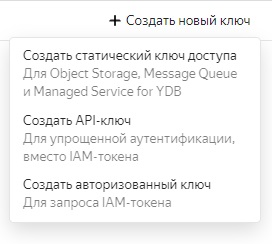
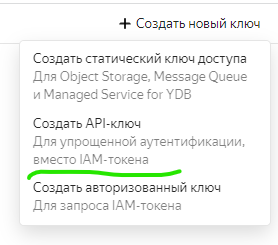
Работу с этим сервисом можно легко реализовать на 1С, используя только некоторые базовые вещи: HTTPЗапрос, ЧтениеJSON, ЗаписьJSON, что я и сделал. Внешнюю обработку можно использовать, только нужно получить в консоли Яндекс.Облака ключ для запросов, вот документация
Далее технические подробности:
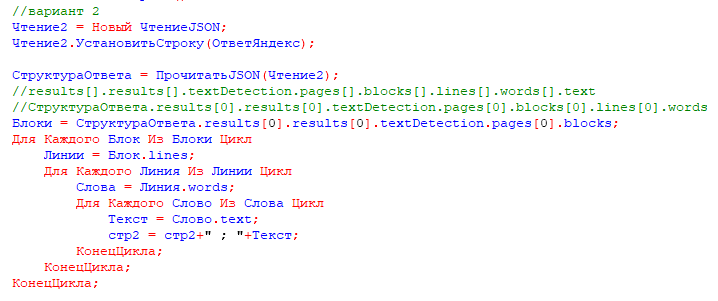
Начнем с правильного формирования JSON запроса. Для этого, пользуясь описанием формата из документации, подготовим Структуру и сериализуем её в JSON.
Кстати обратите внимание что здесь я ставлю в массив language_codes только русский язык, но в этот массив можно добавить еще и "en" строку.

В запрос HTTP вставьте заголовок с ключом АПИ

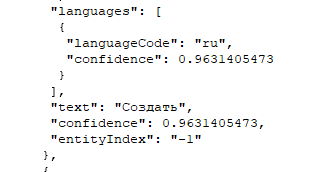
Полученный ответ тоже можно сериализовать в структуру и извлечь из нее все распознанные блоки текста
Запустим обработку, закинем какую-нибудь картинку, полюбуемся полученным ответом.

Для примера распознавания PDF я взял первый попавшийся в поиске образец файла счета, и вот что получилось:
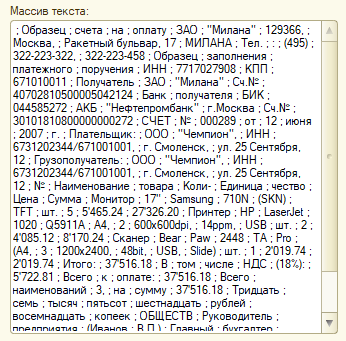
Мы только что заставили огромные сервера Яндекса и их мощные нейросети распознать нам текст, здорово, правда?
У Яндекса есть ограничения: Поддерживаемые форматы файлов: JPEG, PNG, PDF. Максимальный размер файла: 1 МБ.
Тарификация 130 рублей за 1000 изображений
Для распознавания паспорта есть отдельный запрос на стадии Preview но я этим не пользовался.
Тестировал на платформе 8.3.16
В обработке код открыт, можно ее скачать и использовать.
Вступайте в нашу телеграмм-группу Инфостарт