
Область применения
Подсистема реализована в виде Расширения и позволяет:
- Вести список информационных баз (ИБ) в нескольких кластерах и СУБД. Справочник "Информационные базы"
- Для каждой ИБ допустимо указание имени пользователя и пароля, сохраняемые в настройках пользователя.
- Информационные базы представлены в виде иерархического списка, где не первом уровне это исходные (эталонные) ИБ, а остальные уровни это клоны эталонных баз для тестирования функционала разрабатываемой системы.
- Для каждой ИБ возможно исполнение различных командных файлов, из которых четыре предопределены (копирование из родителя, удаление, получение параметров и получения списка ИБ). Остальные могут добавляться по усмотрению. Командные файлы хранятся в виде шаблонов, для каждого шаблона предусмотрены алгоритмы подготовки (заполнения) переменных шаблона и алгоритмы обработки результата на встроенном языке.
- Каждая информационная база может быть связана с некоторым объектом разработки:
- Ветки версий, основная ветка проекта, ветка тестирования.
- Технические проекты
- Ошибки
Объекты сборки связаны непосредственно с ветками в Git и имеют возможность актуализировать конфигурацию связанной с ними информационной базы в соответствии с фиксацией Git посредством запуска сборочных линий.
- Вести справочник "Сборочных линий", представляющих собой динамически формируемый шаблон сборочной линии проекта, подключаемый в конвейере Gitlab одной строкой и не требующих модификации корневого файла проекта .gitlab-ci.yml.
- Поддерживать консистентность ветки версии, в которой содержится только проверенный код, и позволяющий выпустить релиз в любой момент согласно требованиям Разработка плановой версии п. 3.2 за счёт использования ветки тестирования
- Автоматически формировать запросы на слияние в ветку тестирования ошибок, исправляемых в выделенных ветках, не имеющих связи с ИБ и отмеченных как "Исправлено". (Подробнее см. дополнение к справке в справочнике "Ошибки")
- Автоматически формировать запросы на слияние в ветку версии подтверждённых ошибок
- Максимально облегчить подготовку описания релиза. (в том виде, в котором это предусмотрено в БСП)
- Автоматически создавать элементы в справочнике ветки, созданные в при помещении в гит из локального репозитория гит для технических проектов и исправляемых ошибок.
- Создавать и принимать (их при отсутствии конфликтов) запросы на слияние в ветку тестирования при отметке исправления ошибок разработчиком как исправленные.
- Создавать запросы на слияние в ветку версии при подтверждении исправления ошибок и при завершении технических проектов.
- Уведомлять пользователей об окончании сборочного конвейера и функционале, включённом в него через систему взаимодействия, или при её недоступности или отсутствию по электронной почте. Электронная почта используется по умолчанию в качестве резервного канала уведомлений.
- Уведомлять администраторов сборок обо всех событиях сборочного конвейера, не только об успешных.
- Уведомлять разработчика о проблемах при принятии запроса на слияние его кода в ветку тестирования.
- Уведомлять разработчика о создании ветки технического проекта или исправления ошибки в Git и привязывать созданную ветку к техпроекту или ошибке.
- Загружать результаты тестирования VA из артефактов сборочной линии (доработка к загрузке результатов тестирования из CI)
Ограничения:
- Предполагается, что имя базы в кластере и сервере СУБД совпадает.
- Не допускается одновременная работа с двумя и более клонами Gitlab хранилищ, но допускается быстрое переключение между ними изменением настроек. Например, когда в публичное хранилище результаты работы могут выкладываться не сразу, а отладка некоторого функционала проводится в защищённом тестовом контуре, обособленным от публичного. В этом случае будут корректно обрабатываться входящие запросы через API, этого будет достаточно для обработки событий pipeline, push, merge-request, но чтобы заработала исходящая интеграция, необходимо в проекте указать новую строку подключения к хранилищу Git.
- Не поддерживается интеграция по issue Gitlab
- Если с сервера СППР доступа к СУБД нет, скорее всего использовать функционал не получится, либо будут ограничены операции с копированием эталонных баз. Для элемента справочника СУБД, к которым доступа с сервера СППР нет нужно включить флаг "Не опрашивать доступность СУБД"
- Начиная релиза 1.0.4.29 доступна функциональность подключения к тестовому контуру и управления им по протоколу SSH, в том числе и через интернет. В этом случае достаточно организовать доступ всего по одному порту 22. См. описание изменений к релизу 1.0.4.29 в конце раздела.
- Предопределённые и произвольные пакетные задания доступны только пользователю, имеющему "Полные права", либо "Администратору сборок" в будущем планируется снять это ограничение, разрешив разработчикам в некоторых случаях исполнять некоторые пакетные задания.
Детально возможности описаны в разделе "Подробное описание коммерческого продукта"
Программное обеспечение зарегистрировано в ФИПС ЭОД, а так же в реестре Минцифры Управление сборкой GLI. Расширение для конфигурации 1С:СППР.
Демо сервера:
На платформе LINUX / Проект: Демо проект [Версия: 1.0.4.34] (1С:Предприятие)
На платформе WINDOWS / Проект: Демо проект [Версия: 1.0.4.34] (1С:Предприятие)
ВНИМАНИЕ!!! Начиная с 25.11.2024 действует специальное предложение, разработанное совместно с Инфостарт. На срок действия подписки (первоначальная лицензия 12 месяцев или техподдержка 3 месяца) пользователям предоставляется доступ на уровне "Reporter" к хранилищу разработки в формате Git.
Это позволит Вам на время действия лицензии:
- Сделать вилку с проекта на сервисе gitlab.com
- Получать обновления более простым путём, сливая их из основного хранилища к себе в репозиторий
- Вы будете видеть ветки новых фич и исправлений, и ознакомиться с ними до выхода официальной версии.
- Вы так же будете получать штатным образом уведомления с маркетплейса о выходе новых релизов - вне зависимости от действующей подписки, а так же возможность их скачивания при наличии действующей подписки.
Таким образом, Вы не получаете каких либо льгот при получении обновлений, они предоставляются так же как ранее в рамках подписки, но процедура их получения и применения становится значительно прозрачнее, в случае если вы так же дополняете свою функциональность СППР с использованием EDT/Git.
По истечению срока поддержки доступ переходит в режим "По умолчанию" где предоставляется доступ только к issue проекта, где вы можете ознакомиться с планом доработок проекта, а так же известными проблемными ситуациями.
Заявку на доступ можно получить через техподдержку, необходимо предоставить свой логин в формате @UserName в сервисе https://gitlab.com/
Сервис доступен так же тем кто уже приобрёл новую подписку (приобрёл лицензию) оставшийся срок её действия не менее 2R09;х дней.
Техническая поддержка и обновления
Бесплатный период техподдержки составляет 3 месяца со дня покупки
Также после приобретения вы получаете 12 месяцев бесплатных обновлений.
По окончании бесплатного периода вы можете приобрести услугу технической поддержки с доступом к обновлениям на платной основе.
Проверить наличие обновлений можно в личном кабинете. Если обновления недоступны - загрузить новую версию можно после покупки обновлений/технической поддержки.
Задать вопрос по программе можно по кнопке "Техподдержка" на странице описания.
При создании тикета необходимо предоставить:
- Номер заказа
- Описание вопроса. Если это ошибки - напишите порядок ваших действий с программой, которые к ней привели (приложите видео/скриншоты/отчеты об ошибке)
- Точную конфигурацию 1С, и версию платформы, на которой используете купленное решение (наименование и версию 1С можно взять из раздела "О программе"), версию купленной программы.
К созданной заявке подключается специалист. Дальнейшее обсуждение проблемы будет проходить в тикете техподдержки. Стандартный срок реакции - 24 часа в рабочие дни с момента обращения.
Внимание! Техническая поддержка предоставляется исключительно в рамках переписки по обращению. В некоторых случаях для диагностики ошибок и/или вопросов, связанных с особенностями использования продукта в информационных базах покупателя, может потребоваться дополнительная платная диагностика с организацией удаленного доступа к информационной базе. Стоимость уточняется индивидуально.
Причины купить
Эта разработка уникальна в своём роде. Используется и развивается с августе 2020 года.
Основной предпосылкой к её созданию послужило реализация требований, описанных ранее в статье: Технология разветвлённой разработки, использующая git, ci/cd. Т.е. требования были описаны раньше, но реализовать их только с помощью СППР не получалось, либо было неудобно. Не было какой то единой структуры.
В расширении есть много интересных решений и примеров по интеграции с Gitlab API, код присутствующий в ней поможет сэкономить не одну неделю разработчику, который задумал сделать свою собственную интеграцию с Gitlab. Расширение содержит некоторые исправления проблем типового функционала СППР, в частности работа с ошибками, загрузка изменений из Git в технические проекты. Для подсистему управления сборкой есть встроенная справка с примерами использования. Фактически это готовый продукт - бери и работай. 3 месяца бесплатной техподдержки помогут быстрее осуществить запуск подсистемы в эксплуатацию.
Благодарность автору статьи, которая сильно помогла в 2018 году с освоением gitlab'a: Сборка приложения, разработанного на EDT, с помощью gitlab-ci (infostart.ru)
Достоинства
Ключевые моменты реализованные в подсистеме.
Реализация требования ведения эталонных и тестовых информационных баз.
Театр начинается с вешалки, а моделирование процессов предприятия в проекте начинается с создания эталонных тестовых баз. Из которых минимум одна, рано или поздно станет прототипом системы, переживёт миграцию и уйдёт в продуктивный контур проекта. Но от этого, она не перестанет быть эталонной. Количество эталонных баз в разных ситуациях может быть разное, но как правило две создаются всегда - это пустая, в которой проводится начальное заполнение и демонстрационная база, та же конфигурация, но заполненная какими то тестовыми данными типа ООО "Ромашка", на которых можно освоить работу функционала системы и продемонстрировать заказчику. Очень часто используют термин "база моделирования" процессов предприятия. Этот набор баз является исходной точкой для всех остальных тестовых ИБ, которые могут присутствовать в процессе разработки системы. Т.е. все остальные ИБ, по сути являются теми или иными клонами эталонных ИБ.
Меня как архитектора, всегда раздражала ситуация: "Кто в лес, кто по дрова" Когда каждый член проектной команды (методолог, консультант, архитектор, разработчик) присоединяясь в определённый момент времени использует непонятно какие базы для моделирования процессов, непонятно какие платформы. "Что стояло на том и развернул". Очень часто члены команды разворачивают разные релизы исходной системы, что приводит совсем к анекдотичным случаям. Но, в итоге, это ни к чему хорошему, кроме как пустая трата времени на выяснение разницы в релизах не приводит. Так быть не должно.
Тестовый контур должен быть доступен всем членам проектной команды, либо это ВПН, либо непосредственно локальная сеть, и все ИБ должны открываться из одного места. В предлагаемом расширении это справочник "Информационные базы":
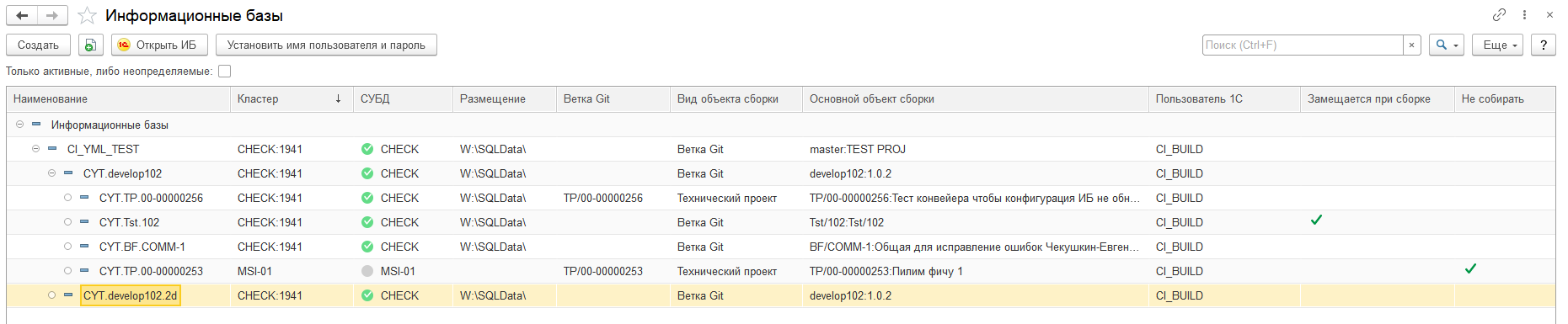
Для режиме толстого клиента доступны ещё несколько информационных колонок, однако на практике получение данных для них требует авторизации и отнимает много времени, если базы большие. Удалять функционал не стали, вдруг в будущем что то изменится? На любителя.

Таким образом есть единое место, откуда производится открытие тестовых и эталонных баз для всей проектной команды. Есть возможность задать свой персональный пароль для ИБ, чтобы не проходить авторизацию каждый раз (на случай отсутствия аутентификации ОС), все остальные настройки доступны администратору сборок. Именно он создаёт или клонирует информационные базы в процессе выдачи в работу технических проектов и исправлений ошибок. Остальные могут их только запускать и работать с ними. При этом список ИБ 1С не используется, и ничто не мешает пользователю "по старинке" зарегистрировать ИБ у себя в списке обычным образом. Предполагается, что клиентская часть платформы должна стоять у члена проектной команды и работает он с тестовыми ИБ по протоколу тонкого клиента.
Реализация требования сборки эталонных и тестовых ИБ.
Если посмотреть на список ИБ то в колонке есть ссылка на "Основной объект сборки", это очень важный момент, так как в предлагаемом решении шаблон сборочной линии создаётся один раз (ну хорошо, буду честен :), добавлю: "и правится в течении проекта постоянно, так как требования могут меняться" у меня так и было, пока не родилось это расширение). Однако с учётом предложенного функционала в действительности так может и быть: один раз создали шаблон и он работает самостоятельно.
Как это работает?
В колонке СУБД (см. картинку выше) есть маленькая зелёная пиктограмма, означающая что ИБ с указанным "Наименованием" присутствует физически на сервере СУБД из колонки. В процессе формирования запроса динамического списка происходит реальное опрашивание доступности баз на СУБД. Текст сборочной линии генерируется только для тех веток, которые связаны с "Основным объектом сборки" у информационных баз, которые реально присутствуют на сервере. Здесь нужно отметить, что GitLab пытается отработать сборочную линию, которая указана в ключевом файле .gitlab-ci.yml при наступлении вариантов событий для определённой ветки или тэга:
- Push (Фиксирование)
- Принятие merge-request (запроса на слияние) (только ветки)
- Запуск сборочного конвейера по расписанию.
- Запуск сборочного конвейера вручную через веб интерфейс
- Запуск сборочного конвейера посредством gitlab API, например:
curl --request POST --header "PRIVATE-TOKEN:" "https://gitlab.example.com/api/v4/projects/1/pipeline?ref=main"
Для каждого из указанных вариантов производится попытка получить версию текста сборочной линии из файла .gitlab-ci.yml для указанной ветки, и при случае, если в нём будут найдены задания для указанной ветки/тэга сборочный конвейер начнёт отработку заданий. Если же ни одного задания для указанной ветки не будет найдено то не произойдёт ничего. Запущенные сборочные линии по 5 представленным выше вариантам будут отличаться лишь в значении одной переменной окружения: "CI_PIPELINE_SOURCE" выставленной в одно из значений: push, merge_request_event, schedule, web, api. (на самом деле вариантов чуть больше, подробнее об этом здесь)
В ключевом файле .gitlab-ci.yml нашего проекта необходимо указать ссылку на публикацию http сервиса СППР GetPipeline (ссылка работает) следующим образом:
include:
- 'http://xn--e1agfaq7azal4a.xn--p1ai/sppr_copy/hs/GetPipeline/CI_YML_TEST/ci-module.yml'
Где "https://xn--e1agfaq7azal4a.xn--p1ai/sppr_copy/hs/GetPipeline/" ваш веб сервер с публикацией СППР, а вот CI_YML_TESTссылка на элемент другого важного справочника "Сборочные линии":
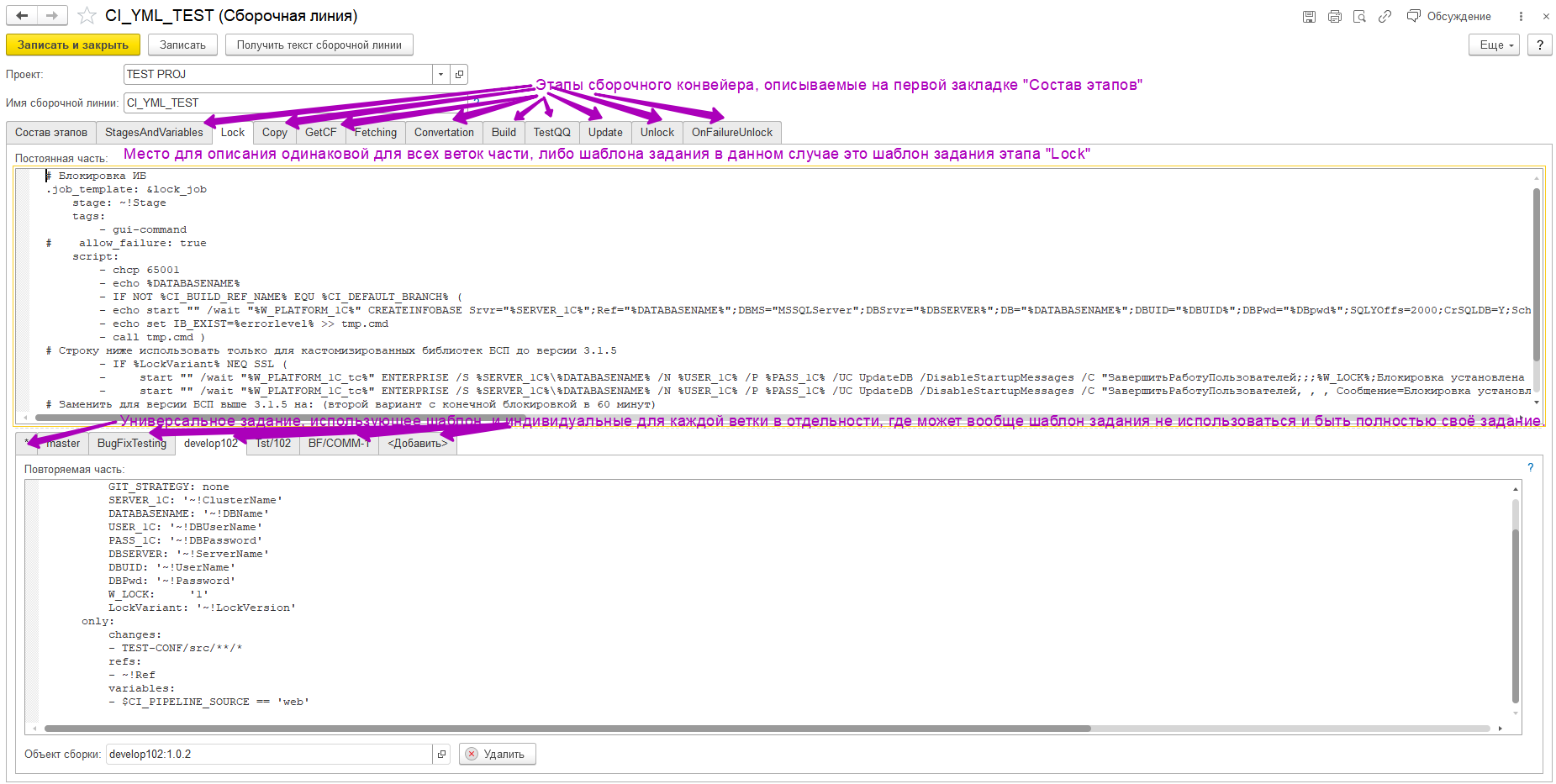
Другими словами, каждый раз когда происходит одно из 5 событий инициирующего запуск сборочного конвейера (pipeline) происходит следующее:
- Gitlab CI считывает файл .gitlab-ci.yml из корня проекта и в нём пытается загрузить вложение директивой include, которая содержит ссылку на внешний ресурс с файлом ci-module.yml
- Происходит попытка получить из веб сервиса СППР подключаемый файл ci-module.yml, по крайней мере gitlab именно так и думает, что он получает этот файл.
- СППР опрашивает доступные ИБ в тестовом контуре и на каждую из них генерирует один общий файл сборочного конвейера (очень жаль, что в подключаемый файл нельзя передать никакие параметры, например имя ветки для которой наступает событие pipeline start, тогда бы механизм мог быть ещё эффективнее)
- Gitlab CI выбирает из этого файла задания, подходящие для ветки, по которой наступило событие сборки, после чего gitlab-runners (бегуны гитлаба) начинают последовательно их исполнять, в том порядке, в котором указаны в списке stages (этапы) при этом для каждого задания проверяются условия указанные в нём, например наличие изменений в определённом каталоге ветки, по отношению к предыдущей фиксации (commit), либо соответствие значения переменных окружения ожидаемым в задании, если все условия выполнены, то задание будет передано бегуну.
- Бегун загружает (при необходимости) артефакты сборки от предыдущих этапов, отрабатывает пакетный файл, указанный в разделе script и результаты, при необходимости сохраняет так же в артефактах сборки. Артефактом сборки может являться, например файл CF или CFU для обновления тестовой или эталонной базы, или лог файл с ошибкой сборки.
- Если последнее задание сборочной линии отрабатывает успешно завершается (success) тогда Gitlab генерирует webhook который отрабатывает СППР, оповещая консультантов, методологов, разработчиков через СВ о том, что проведена успешная сборка:
 В противном случае, если произошла ошибка будут уведомлены только администраторы сборок. Для диагностики нужно будет открыть сборочную линию в веб интерфейсе Gitlab и проанализировать файлы логов заданий и разобраться в причинах.
В противном случае, если произошла ошибка будут уведомлены только администраторы сборок. Для диагностики нужно будет открыть сборочную линию в веб интерфейсе Gitlab и проанализировать файлы логов заданий и разобраться в причинах.
Как это происходит можно посмотреть на видео:
Ещё аналогичное видео с техническим проектомВариант уведомления, для ветки версии, когда собирается ветка в которую было несколько запросов на слияние, СППР отслеживает запросы на слияние в ветку версии и при сборке сообщает, что тот или иной функционал теперь доступен в тестовой ИБ. Круг лиц для уведомлений выбирается по разному. Для справочника "Ошибки" это все кто присутствует на закладке протокол. Если протокол ещё пуст, то автору (кто зарегистрировал) ошибки. Для технических проектов это закладка "Участники". Для элемента справочника "Ветки" дополнительное поле "Получатели уведомлений"
Круг лиц для уведомлений выбирается по разному. Для справочника "Ошибки" это все кто присутствует на закладке протокол. Если протокол ещё пуст, то автору (кто зарегистрировал) ошибки. Для технических проектов это закладка "Участники". Для элемента справочника "Ветки" дополнительное поле "Получатели уведомлений"
У читающего этот текст может сложиться вопрос: если для каждой ветки можно сделать свою сборочную линию, включая вариант её полного отсутствия то зачем всё это (расширение, генерация текста сборочной линии на лету) понадобилось?
Вот на это несколько причин:
- Разработчики 1С, даже перейдя на EDT с конфигуратора далеки от языка пакетных файлов (CMD/PowerShell/Bash), и уж тем более язык YML которым описывается сборочная линия GitLab для них и вовсе как китайская грамота.
- При слиянии веток разработки возникали конфликты, которые EDT в процессе слияния веток не мог разрешить. В итоге это заканчивалось тем, что очень часто после слияния мне приходилось текст конвейера править. Не могу отметить что я был рад этой "балдовой" работе.
- Написать универсальный текст сборочного конвейера тоже не получалось из-за различного количества тестовых баз под фичу. В 90% было достаточно одной эталонной копии для тестирования, но для 10% случаев нужны были дополнительные, либо они должны были при сборке копироваться с эталонной и это приводило к тому, что опять же приходилось тратить время на правку YML текста. Сейчас, конечно же я знаю как можно написать универсальный текст сборочного конвейера, но использовать механизм справочника "Сборочных линий" удобнее.
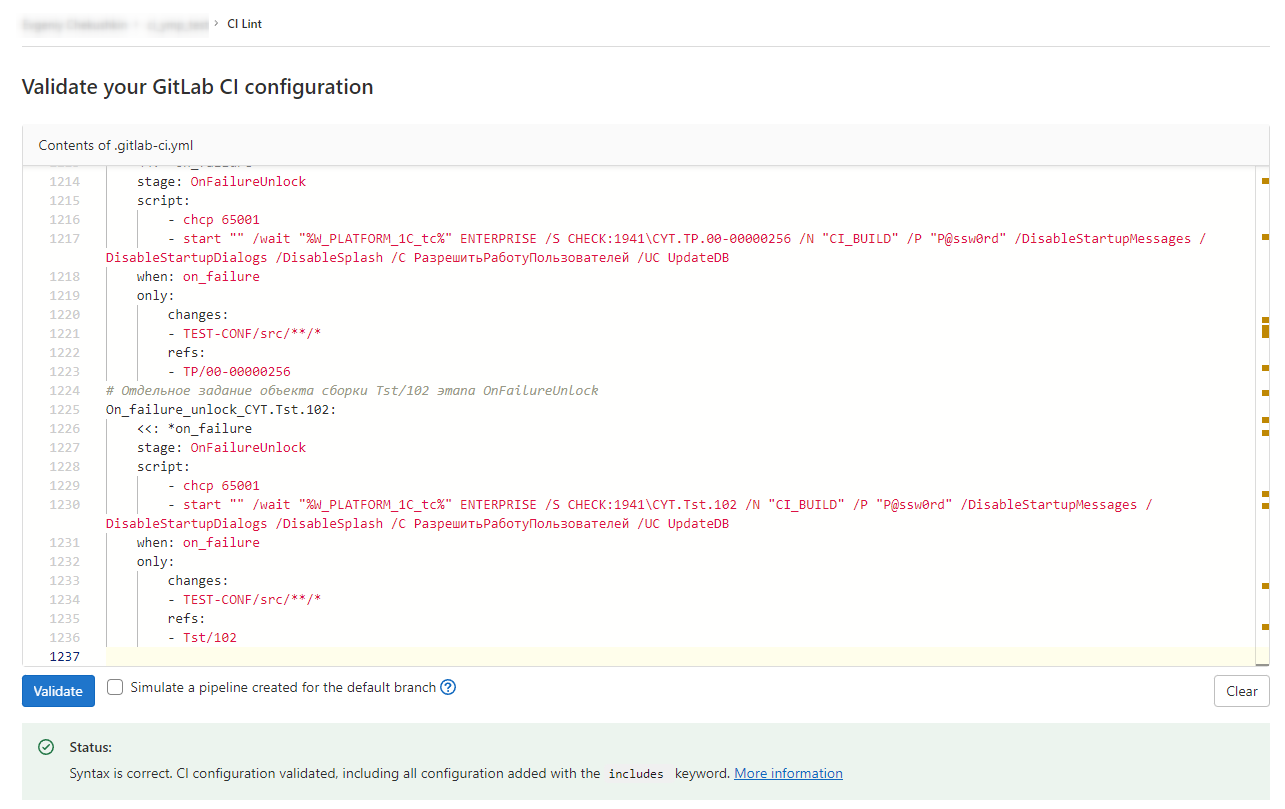
- Хотя бы потому, что при исправлении ошибок в текстах скриптов не нужно ничего пушить в хранилище (знатоки сейчас подумали: "А кто мешал разместить подключаемый файл так же на сервере?"). Да лень, гораздо проще открыть справочник и поправить несколько строк, получить текст сборочной линии по кнопке "Получить текст сборочной линии" и проверить её с CI Lint:
- Есть ещё одна причина, достаточно веская. Gitlab не умеет прерывать ранее запущенные сборочные линии, если линия отрабатывает в этот момент задание, у которого переменная GIT_STRATEGY = none. Из всех вариантов сборочных линий, которые мне удалось построить за несколько лет с учётом различных факторов я пришёл к тому, что этапы должны располагаться примерно так:
- Lock - блокировка и выгонка пользователей информационных баз по таймауту, начиная с 3.1.5 в БСП уже всё включено. До 3.1.5 мы все БСП патчили. Зачем? Подробнее описано здесь.
- GetCF - получение предыдущей конфигурации для получения CFU (зачем нужна CFU и почему без неё - "труба" расскажу чуть позже)
- Fetch&Convert - получение из гит и конвертация в формат XML 1С
- Build - получение CF/CFU новой версии
- Update - обновление тестовых баз новой CF или CFU
- UnLock - отработка обработчиков обновления и разблокировка
Это минимум, на самом деле в силу различных причин их придётся сделать ещё больше, и из всех этапов выше только третий: Fetch&Convert будет прерван автоматически CI/CD если будет запушена новая версия в Git. Во всех остальных случаях задания будут продолжаться исполняться и, естественно будут между собой конфликтовать за ИБ. Чем может закончиться этот конфликт в самом худшем случае: потерей тестовой базы. СППР отслеживает запуск новых линий через pipeline webhook, и, при необходимости, если уже есть для этой ветки запущенные аккуратно их прервёт, вне зависимости от значения GIT_STRATEGY в задании. которое сейчас исполняется. GIT_STRATEGY:none необходим, так как самый простой способ передачи данных от предыдущих этапов хранить их в подкаталогах каталога сборки, чтобы не тратить время на загрузку/выгрузку артефактов. Т.е. есть при регистрации бегун в gitlab CI создаст каталог, например: D:\CI_Runner\builds\5gjGWpxd\0\check300373\ci_ymp_test, где ci_ymp_test это рутовый каталог вашего EDT проекта: в нем же можно создать временные каталоги конвертированных файлов, которые при следующем Fetch будут автоматически удалены.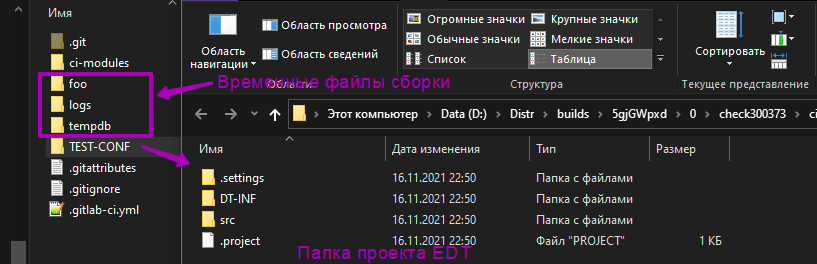
- Есть конечно же соблазн все этапы положить в единый пакетный файл, однако имейте в виду, что если на этапе разблокировки, например, у вас не будет доступна лицензия 1С:Предприятия и эта часть пакетника не отработает (куда пропадают лицензии - это предмет отдельного разговора), при полном перезапуске или будет обидно за потерянное время: мой рекорд сборки и обновления 120 Гб базы по всем этапам выше с 1й минутой ожидания завершения работы пользователей для конфигурации УХ 3.1.16.2 - 32 минуты (при использовании новой утилиты сборки из XML ibcmd и с ней пока не все хорошо), обычным конфигуратором и того медленнее: 58 минут, или Вам придётся завершать сборку вручную, минусы здесь очевидны:
- Пользователи не получат обычного уведомления о сборке, к которому они уже привыкли (см. выше пример), Вам придётся их уведомлять самостоятельно
- Вы потратите своё драгоценнейшее время.
- Есть ещё одно требование - ПАРАЛЛЕЛЬНОСТЬ, т.е. возможность собирать несколько веток практически одновременно на одних и тех же процессорных мощностях. Задача эта, как оказалось, далеко не из простых. Конфигуратор работает в один поток, а утилита ring использует все имеющиеся процессоры. Конфигуратор работает долго, утилиту ring, как оказалось, можно заставить конвертировать целиком проект УХ в формат XML за 4 минуты на 12 процессорах с частотой 4 ГГц. Возможно, для некоторых это не открытие, но надо лишь просто не удалять папку workspace от предыдущей конвертации. Это сократит минимум 20 минут на создание новой папки workspace утилитой ring. Сделать кэш параллельным для нескольких потоков конвертирования можно, но хранить его нужно для каждого процесса бегуна гитлаба отдельно. В демо базе в примере сборочной линии это именно так и делается в папке --workspace-location %CI_BUILDS_DIR%/%CI_RUNNER_SHORT_TOKEN%/workspace%CI_CONCURRENT_ID%, где CI_BUILDS_DIR - папка которая используется бегуном для сборок, CI_RUNNER_SHORT_TOKEN - токен привязки выбранного бегуна к хранилищу(Один бегун может быть привязан, и обслуживать параллельно несколько хранилищ Git), CI_CONCURRENT_ID - номер параллельного процесса бегуна, исполняющего то или иное задание. При этом нужно понимать, что если в одном пайпе на одном бегуне задание начало исполняться с одним значением CI_CONCURRENT_ID, не факт, что следующее из этого же пайпа будет исполняться с тем же значением. Передавать же 20 с лишним гигабайт конвертированных XML через артефакту - полное безумие. Поэтому пришлось помудрить с такими каталогами. На замену "тугодумному" конфигуратору с релиза 1С:Предприятия 8.3.20 подоспела утилита ibcmd, пример её использования есть так же в демо базе, он закоментирован, отмечал её возможность использования чуть ранее. Её фантастичность в том, что она умеет собирать из XML CF в несколько потоков за три минуты, в отличии от конфигуратора, который тратит на это 30 минут... Однако, не знаю, в чем реально проблема, но интерфейс (только интерфейс, остальное всё собирается на ура) она собирает некорректно. Толи дело в том, что версия XML у меня была для платформы 8.3.17, но в интерфейсе отображались все объекты, которые входили в подсистему, включая вложенные подсистемы, даже если флаг отображения у них был сброшен. Возможно, если собирать XML для платформы 8.3.20 такой проблемы не будет, но мне от её использования пришлось отказаться...
Реализация требования консистентной ветки версии, согласно требованиям п 3.2.
Немного пояснений. Начиная с версии 2.0.3.9 в СППР появился функционал веток - справочник ветки. Для меня это было очень неожиданным шагом, что отложило публикацию этой статьи почти на 1,5 года, и возможно, к лучшему. Я долго ждал, когда же описание нового функционала появится на https://its.1c.ru но на момент начала подготовки публикации 26.04.2022 года оно там так и не появилось, в партнёрской конференции тоже все отмолчались на вопросы - когда же будет описание? Т.е. сейчас описание на ИТС соответствует версии 2.0.1.61. Пришлось разбираться с новым функционалом самостоятельно, методом проб и ошибок.
Эмпирическим путём было выяснено, что справочник "Ветки" хоть и отражает иерархическую структуру, но иерархическим не является. Расширением здесь не поможешь, это важно: включить иерархию в справочнике "Ветки" необходимо, на это опирается логика расширения, и это придётся сделать в основной конфигурации.
Каждый элемент справочника "Ветки" должен иметь определённый тип ветки:
- Основная ветка проекта
- Ветка версии
- Ветка технического проекта
- Ветка для исправления ошибок
Для двух последних вариантов предназначение очевидно, на первый взгляд, это ветки где будут разрабатываться технические проекты и будут исправляться ошибки. Однако и в них могут быть различные вариации.
Первые два типа предназначены:
- "Основная ветка проекта" - эта ветка системы, либо её прототипа. Конечный продукт, в Git для неё обычно существует ветка master.
- "Ветки версии". Их может быть несколько, стартуют от "Основная ветка проекта". Очень важные ветки, их аналог в Git - ветка develop или, правильнее отметить подмножество веток c префиксом dev/*. Например так: dev/1.0.1 - ветка разработки версии 1.0.1 может быть сделана в начале проекта на базе типового релиза поставщика, например на базе типового релиза 3.0.1.12. От этой ветки будет старт большинства веток технических проектов и исправлений ошибок, хотя с ошибками могут быть и другие варианты. Со временем, поставщик выпустит новый релиз 3.0.2.7 и вам потребуется обновить вашу систему в проекте до нового релиза. Вот тогда то вам и потребуется создать новую ветку версии, например dev/1.0.2 и в ней вы будете проводить обновление до нового релиза поставщика. При этом вы сможете не прерывать поддержку существующей версии dev/1.0.1 и вести работы параллельно, все зависит от количества ресурсов. Однако, на момент поддержки двух версий масштабные доработки лучше не проводить (заморозить), в особенности тех блоков. которые претерпели изменения у поставщика. В некоторых случаях зарегистрированные ошибки придётся исправлять и в новой и в старой версии дважды, если они критичные, а исходные механизмы поставщиком были изменены. Но чаще такие исправления откладываются и исправляются только в новой версии, в старой версии в лучшем случае "костыль". В большинстве случаев, все критичные исправления старой версии можно будет перенести кумулятивно из ветки старой версии dev/1.0.1 простым слиянием в ветку dev/1.0.2. После чего ветка новой версии обычно сливается в ветку master и выходит уже новый релиз в прототип или продуктивную среду с новой версией поставщика. В обычном случае, ошибки, зарегистрированные в старой версии исправляются уже только в новой версии, механизм справочника ошибок на текущий момент имеет такую возможность, плюсом мы его немного "облагородили". Конечно же Вы можете стартовать новую версию и без перехода на новую версию поставщика. Например, если у вас разработка с нуля на базе БСП. Но ведь и новую БСП, и другие библиотеки тоже нужно периодически в систему встраивать. Создание новой ветки версии, как мне кажется, самое удачное применение для этих целей. Кроме этого, допускается исправлять ошибки и вести разработку технических проектов прямо в ветке версии. Мы так делали только при исправлении ошибок рефакторинга сразу после обновления на новый релиз поставщика, например:
О ветках ошибок и технических проектов:
- "Ветка технического проекта" в большинстве случаев исходная ветка - это ветка текущей версии, возможно новой но только не старой. Изначальная техническая реализация ветки предполагает что в ней может быть несколько технических проектов, мы сочли это слишком запутанным, и ограничили возможность разработки разных технических проектов только для тех случаев, когда предыдущий технический проект завершён, либо полностью отменён. Однако отмечу сразу, в СППР есть загрузка изменений метаданных из Git в технический проект, она не рассчитана на случаи, когда технический проект сливался в ветку разработки более одного раза. Соответственно, если вы вели два техпроекта в одной ветке последовательно (один завершили загрузили изменения ОМД, затем так же со вторым) у Вас возможность извлечь изменения по метаданным будет (нужно будет лишь поменять базовый UID фиксации), а вот если два одновременно - то точно нет. Да, и ошибки, как ни странно. тоже можно исправлять в ветках технических проектов. В этом случае их желательно дополнительно включать в те технические проекты. в рамках которых они исправляются. Естественно "выдернуть" исправление из ветки технического проекта в ветку версии Вы сможете только при условии обособленности изменений и только через "cherry-pick", более того в изменениях ОМД будут изменения по исправлению ошибки тоже.
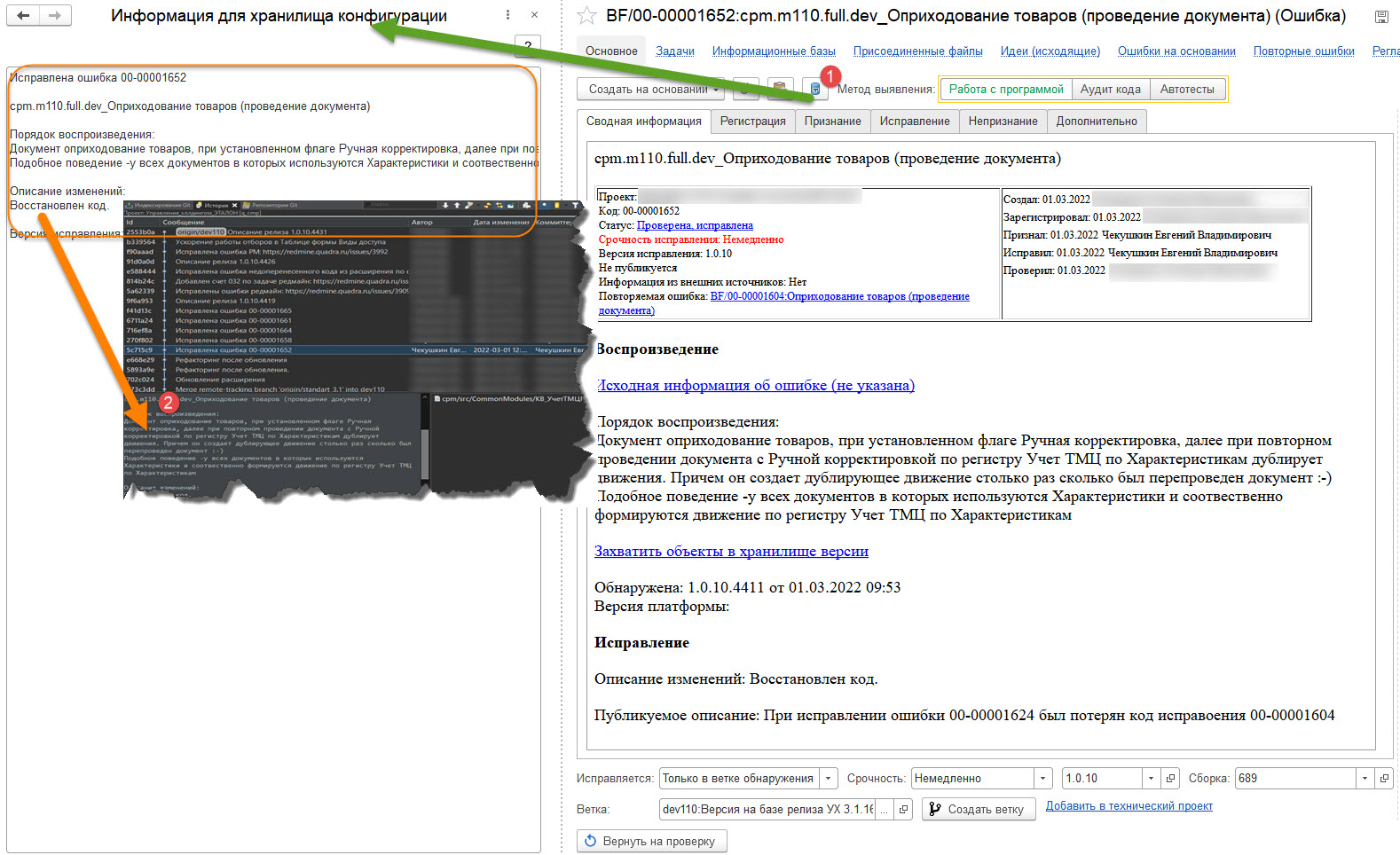
- "Ветка исправления ошибок" техническая реализация в СППР этого типа веток предполагает исправление одной или нескольких ошибок в ветке одновременно, но ветка должна принадлежать одной ветке версии. Исправлять ошибки разных версий в одной ветки будет сложно. В теории это возможно. за счёт последующего слияния в ветку другой версии, но будет очень сложно отделить доработки. Каждую фиксацию в ветке правильно оформлять получая описание изменений как на картинке ниже, пример, когда для исправления ошибки выделена индивидуальная ветка, тестирование которой проводилось в общей ветке тестирования:
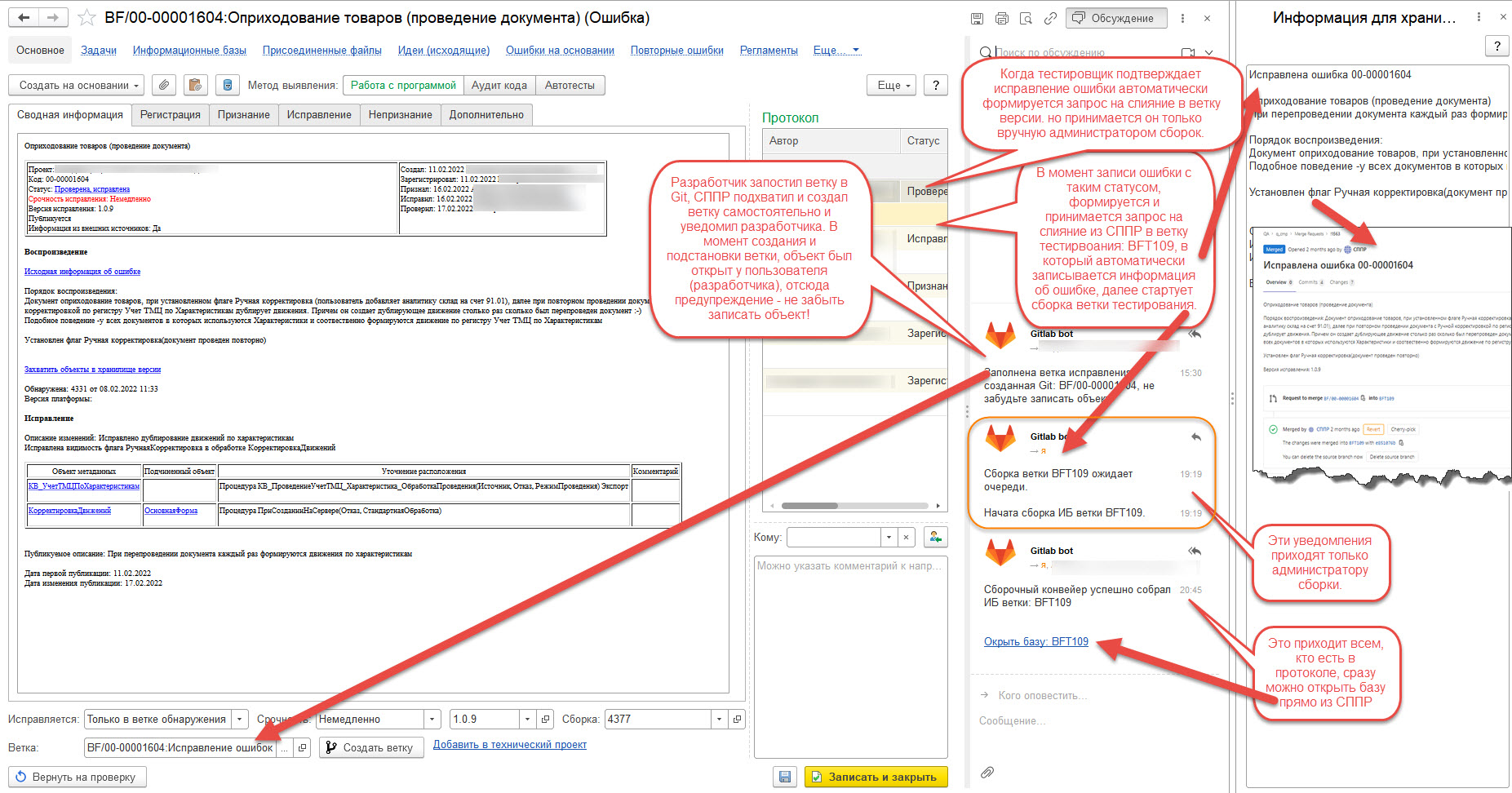 Порядок отражения в ветке версии предыдущего примера, отфильтрованы ветки develop109, master, BF/00-00001604
Порядок отражения в ветке версии предыдущего примера, отфильтрованы ветки develop109, master, BF/00-00001604 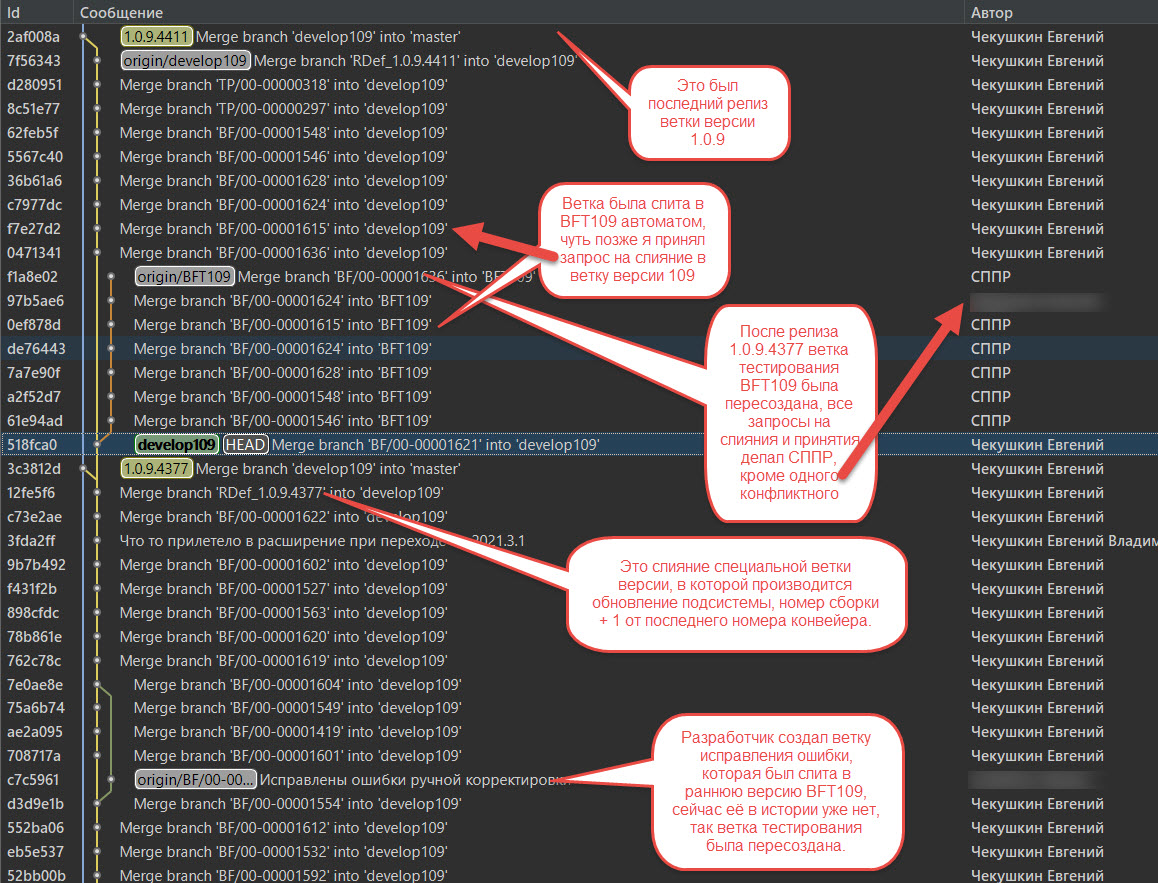
- "Ветка тестирования" - важный элемент, добавленный в расширение для поддержки готовности ветки версии к сборке нового релиза в любой момент времени:
- Может быть создана для каждой ветки версии, и только одна. По сути представляет собой тоже ветку версии, но с особым признаком:
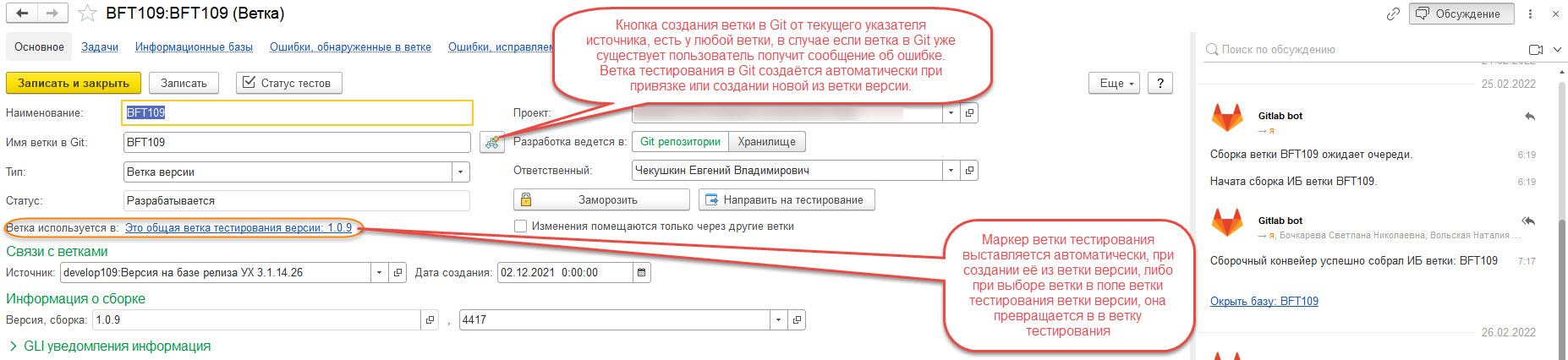
- К ветке тестирования могут быть присоединены несколько баз тестирования, все они как правило при сборке замещаются из ИБ ветки версии, так как ИБ ветки версии постоянно обновляется из прототипа системы или продукционной ИБ, привязанных к ветке master. Таким образом постоянно пополняется список тестовых примеров для воспроизведения ошибок, зарегистрированных в СППР.
- Ветка тестирования должна пересоздаваться после каждого релиза, но можно и пропустить. Пересоздание доступно средствами СППР:
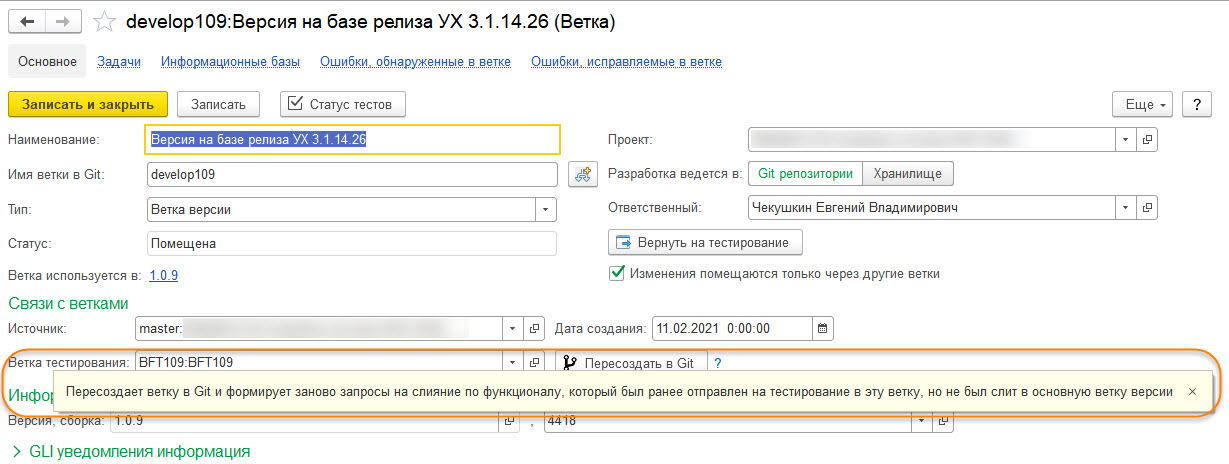
- В ветку тестирования сливаются автоматически все ветки исправления ошибок, отмеченные в СППР как "Исправленные", а запросы на слияние в ветку версии только те, которые были переведены в состояние "Проверена, исправлена". Таким образом, в релиз не подтверждённые ошибки не включаются.
- После релиза ветка тестирования пересоздаётся и туда "реквестятся" повторно все не подтверждённые, но числящиеся как исправленные ошибки. Если они будут подтверждены, то включатся уже в следующий релиз.
- Механизм работает только если каждая ошибка исправляется в отдельной ветке, стартованной от ветки версии, в которой ошибка была обнаружена и для которой была зарегистрирована. В случае, если в одной ветке исправляются несколько ошибок, да и ещё коммиты их будут перепутаны, вытащить в ветку версии реально подтверждённые ошибки очень сложно.
- Иногда, бывает, что регистрируются ошибки на один и тот же блок, и тогда при автоматической попытке слить изменения возникает конфликт, ну например разные ошибки исправили внутри одной процедуры. Git автоматом такое не сольёт. В этом случае, если первую ошибку подтвердят - всё просто, ветка исправления ошибки поднимается до ветки версии и слияние в ветку тестирование проходит без конфликтов. Если ни одна ошибка не подтверждена. тогда придётся со второй немного помучится - в EDT извлечь ветку тестирования и слить ветку исправления в неё вручную. Конфликтный MR будет закрыт автоматически. Однако поверьте за 2 года проекта такое было раз 10, не более. В этом случае, возможно и в ветку версии так же придётся сливать изменение через EDT.
- В целом механизм позволяет сверить перед сборкой количество запросов на слияние в ветку версии в Git с исправленными ошибками, слить завершённые технические проекты и сформировать описание версии прямо из СППР: