В новой версии ряд важных изменений
Выдача результатов поиска теперь максимально компактная
- • только идентификаторы и наименования объектов метаданных (внутреннее наименование и синоним).
- • Результаты возвращаются в двух форматах: и в структурированном json'е и плоским текстом.
- • Первый хорошо понимают современные клиенты типа cursor'а, а обычный текст пока оставлен для обратной совместимости с mcp-клиентами, которые не поддерживают структурированный ответ.
- • На моем опыте - современные llm'ки отлично сами понимают какой из результатов поиска наиболее релевантный, без необходимости подключать реранкер. Такой подход дает лучшую предсказуемость и, самое главное, - не засоряет контекстное окно лишними данными.
Переработан гибридный поиск
- • Теперь семантический поиск по обычным векторам можно смешивать с поиском по разреженным или sparse-векторам, в которые по алгоритму bm25 кодируются ключевые слова всего тела описания объекта метаданных.
- • Для каких-то конфигураций 1С с использованием какой-то особой терминологии в названиях реквизитов - подключение поиска по разреженным векторам даст заметный прирост качества поиска.
- • Для типовых же конфигураций особого улучшения поиска не будет, потому что "специфичные" ключевые слова и так обычно фигурирую в наименовании объекта. Например, если нужно найти документ или справочник связанный с работой с ЕГАИС, то слово ЕГАИС и так присутствует в названии.
Бонусом добавил mcp для проверки синтаксиса и поиска по справке синтакс-помощника
- • Бонусом, потому что эти mcp основаны на чужих решениях (в частности справка по синтаксису от Алексея Корякина), я же оборачиваю это в удобный запуск в docker-контейнерах.
- • Для проверки синтаксиса сделал так, чтобы BSL Language Server запускался в websocket-режиме, чтобы каждое обращение mcp на проверку синтаксиса не переподнимало каждый раз java-приложение (это не мгновенно).
Если детализировать схему до конкретных контейнеров, то получается такая схема:
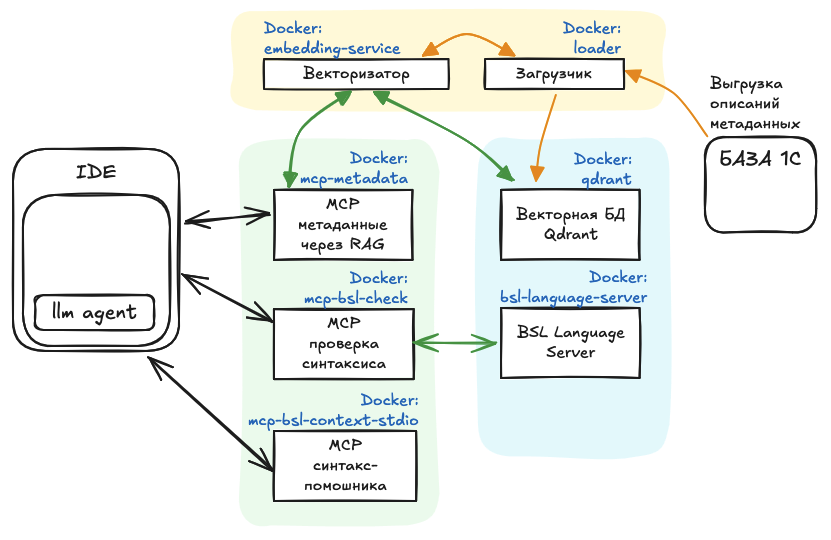

Именно mcp тут три контейнера, остальные вспомогательные.
Вопрос, который может возникнуть: зачем такая фрагментация?
Ответ на него: Потому что микросервисную архитектуру проще разрабатывать, тестировать и, самое главное, эти сервисы можно переиспользовать.
Достоинства и преимущества решения
Компактный вывод результатов
Минимизирует нагрузку на контекстное окно LLM, ускоряя обработку запросов и снижая затраты на API.
Гибридный поиск
Семантический + BM25 повышает точность для нестандартных конфигураций 1С, где ключевые слова в описаниях не совпадают с названиями.
Выбор моделей векторизации
Включая легковесные, обеспечивая быстрый отклик — идеально для локального развертывания без облачных затрат.
Поддержка нескольких конфигураций 1С
В одной БД позволяет работать с разными проектами одновременно, без переключений.
Микросервисная архитектура
Упрощает масштабирование и интеграцию: каждый компонент можно использовать отдельно в других проектах.
Переработанный с нуля MCP для проверки синтаксиса
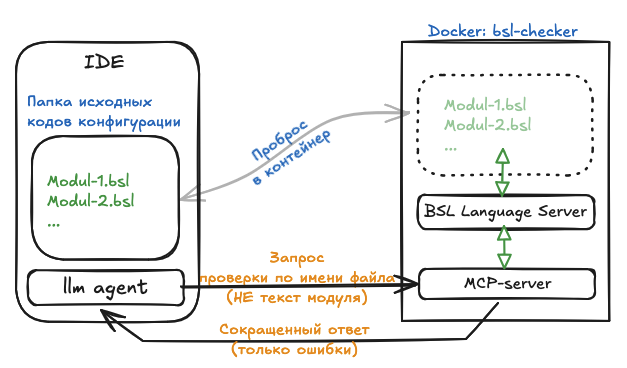
LLM-агенты IDE общаются с MCP только текстом. Из-за этого наивный подход к проверке синтаксиса работает плохо, потому что LLM'ке нужно сформировать для MCP запрос с текстом модуля, а модули в 1С бывают гигантские. Да, LLM-агенты умеют сами понять, что можно проверять только одну процедуру/функцию, но это все равно дорогие выходные (output) токены.
Намного экономнее, быстрее и правильнее передавать для проверки в MCP имя файла. Это потребует сделать для MCP-сервера "видимой" папку с исходниками 1С, но при работе с docker это не проблема. При таком подходе практически не тратятся output токены.
Дополнительные преимущества
Интеграция и производительность
 Для bsl language server можно указать configurationRoot и инициализировать рабочее пространство. Да, первый запуск будет долгим, но последующие проверки быстрыми с более глубокими с анализом (с учетом общих модулей).
Для bsl language server можно указать configurationRoot и инициализировать рабочее пространство. Да, первый запуск будет долгим, но последующие проверки быстрыми с более глубокими с анализом (с учетом общих модулей).- Для больших кодовых баз, типа ERP можно опционально указать параметры памяти Java (Xms/Xmx) для bsl language server.

Оптимизация вывода и контекста
- Включена по умолчанию опция выводить результаты проверки только с ошибками, скрывая предупреждения и рекомендации. Это сильно уменьшает засорение контекста (услышал недавно красивый термин "context poisoning" или отравление контекста).
- Сокращен формат ответа, сохраняя структурность. Опять же - ради экономии окна контекста.
Гибкость и совместимость
- Разные LLM-агенты по разному передают имя файла, некоторые полный путь, некоторые относительный. MCP автоматически понимает оба варианта.
- MCP можно запустить с выбором транспортного протокола: Streamable HTTP или SSE. Ранее казалось, что уже все поддерживают Streamable HTTP, но нет, тот же Gemini CLI работает только по SSE, хотя бы ради него добавлена совместимость с SSE.
Открытый вопрос: Остался для меня открытым вопрос, а кто экранирует текст модулей для JSON-RPC вызова? Не смог найти убедительной информации о логике работы агентов типа Cline, RooCode или Copilot, скорее всего экранирование делает фреймворк агента (не тратя токены).
Примеры использования
Пример работы
Схема работы
Пример результатов проверки
Информация по обновлениям
Английские имена в справке синтакс-помощника
В предыдущем обновлении v1.6.1 добавлялся параметр CONF_LANG, который заменял русскоязычные наименования из справки синтакс-помощника на англоязычные. Это показалось слишком кардинально. Поэтому сделан еще компромиссный вариант — добавление английских наименований в дополнение к русским.
- Добавлена переменная окружения
INCLUDE_EN_NAMES(по умолчаниюfalse) в сервисахloaderиmcp-help. - При
INCLUDE_EN_NAMES=trueзагрузчик (loader) дописывает английские имена (name_en) в тексты справки синтакс-помощника. - MCP-сервер
mcp-helpтеперь возвращаетname_enв ответах для методов и свойств, а при включённом флаге ищет такие элементы и по русскому, и по английскому имени.
Как включить
Для этого у обоих сервисов (контейнеров) нужно задать дополнительную переменную окружения INCLUDE_EN_NAMES=true.
loader:
image: docker.f-pix.ru/mcp/loader:v1.6.2 # ОБНОВЛЕННАЯ ВЕРСИЯ
container_name: loader
ports:
- "8501:8501"
environment:
...
- INCLUDE_EN_NAMES=true # опциональный параметр для включения английских наименований из справки синтакс-помощника
...
mcp-help:
image: docker.f-pix.ru/mcp/mcp-help:v1.6.2 # ОБНОВЛЕННАЯ ВЕРСИЯ
container_name: mcp-help
ports:
- "9092:8000"
- "9002:9002"
environment:
...
INCLUDE_EN_NAMES: true # опциональный параметр для включения английских наименований из справки синтакс-помощника
...
Поддержка английского языка в справке синтакс-помощника
Обновлен парсер и загрузка (loader) справки синтакс-помощника для поддержки англоязычных alias'ов наименований объектов, методов и свойств платформы 1С:Предприятие.
Обновлен MCP-сервер по справке синтакс-помощника (mcp-help) для поддержки англоязычных запросов.
Для этого у обоих сервисов (контейнеров) нужно задать дополнительную переменную окружения CONF_LANG=en.
loader:
image: docker.f-pix.ru/mcp/loader:v1.6.1 # ОБНОВЛЕННАЯ ВЕРСИЯ
container_name: loader
ports:
- "8501:8501"
environment:
...
- CONF_LANG=en # опциональный параметр для поддержки справки синтакс-помощника англоязычных конфигураций 1С
...
mcp-help:
image: docker.f-pix.ru/mcp/mcp-help:v1.6.1 # ОБНОВЛЕННАЯ ВЕРСИЯ
container_name: mcp-help
ports:
- "9092:8000"
- "9002:9002"
environment:
...
- CONF_LANG=en
...
Новая версия выгрузки/загрузки описаний метаданных 1С:Предприятия
У первой версии генерации описаний метаданных через внешнюю обработку две фундаментальные проблемы:
- Не поддерживались расширения конфигурации.
- Не было возможности инкрементального обновления метаданных (актуализации изменений).
Решить эти проблемы получилось через работу с XML-выгрузкой конфигурации 1С:Предприятия.
Как это работает
Новый загрузчик работает следующим образом:
- Берутся XML-файлы описания метаданных основной конфигурации и расширений и преобразуются в более компактное JSON-представление. При этом XML выгрузка позволила записывать в JSON больше видов метаданных, точнее типы и связи, а так же включить поддержку английского написания для англоязычных конфигураций.
- Полученные JSON-файлы основой конфигурации объединяются с JSON-файлами расширений, при этом учитываются правила приоритета (назначения) расширений.
- Затем полученные объединённые JSON-файлы загружаются в векторную базу Qdrant. Используется тот же контейнер векторизации
embedding-service, та же БД Qdrant из первой версии. MCP-сервер же пришлось немного обновить для поддержки новых видов метаданных. - Можно включить отслеживание изменений в XML-файлах выгрузки и инкрементально обновлять JSON и векторную БД.
В парсинге XML предусмотрены настройки ускорения через многопоточность и пакетную обработку разных видов метаданных. Подозреваю, что это потребуется для ERP. На обычной же "Управлении торговлей", на обычном ПК (мобильный AMD Ryzen 7 6850H, 32 ГБ ОЗУ, SSD NVMe) даже с дефолтными настройками работает достаточно быстро:
- секунд 20-30 на генерацию всех итоговых JSON (с учетом расширений);
- 2-3 минуты на векторизацию и загрузку в Qdrant.
Соглашения о структуре проекта (директорий)
Чтобы не сильно усложнять настройки проекта, приняты следующие соглашение:
- В директории для выгрузки xml-файлов 1С должно быть две поддиректории
Configurationдля выгрузки основной конфигурации иExtensionsдля выгрузки расширений. Причем вExtensionsдолжны быть поддиректории по названию расширений. - Поддиректория
Extensions- опциональная, будет работать и без нее.
^92;^72; /1c-src/ # Основная директория для XML-выгрузки 1С
_00;^72;^72; Configuration/ # Поддиректория выгрузки основной конфигурации
^92;^72;^72; Extensions/ # Поддиректория выгрузки расширений конфигурации
_00;^72;^72; Расширение1/
^92;^72;^72; Расширение2/
- Именно в таком виде директория
.../Project/1c-src/должна прокидываться (мапиться) в контейнерmetadata-loaderпо пути/data/src.
Настройки контейнера metadata-loader
В основном те же настройки как в первой версии:
- Адрес векторной БД Qdrant:
QDRANT_HOST,QDRANT_PORT - Адрес сервиса векторизации:
EMBEDDING_SERVICE_URL - Путь к XML-файлами выгрузки 1С:
SRC_DIR(мапится на/data/src) - Размеры батчей: сколько файлов и сколько текстов обрабатывать за раз:
FILES_BATCH_SIZE,EMBEDDING_BATCH_SIZE - Параметр режима отслеживания изменений файлов XML:
WATCHER_POLLING. Для Docker в Windows приходится включать режим опроса (polling), потому что нативные нотификации файловой системы не срабатывают. Но так как отслеживаются не все файлы, а только XML метаданных, то нагрузка минимальная и даже с pollig работает быстро.
Как использовать
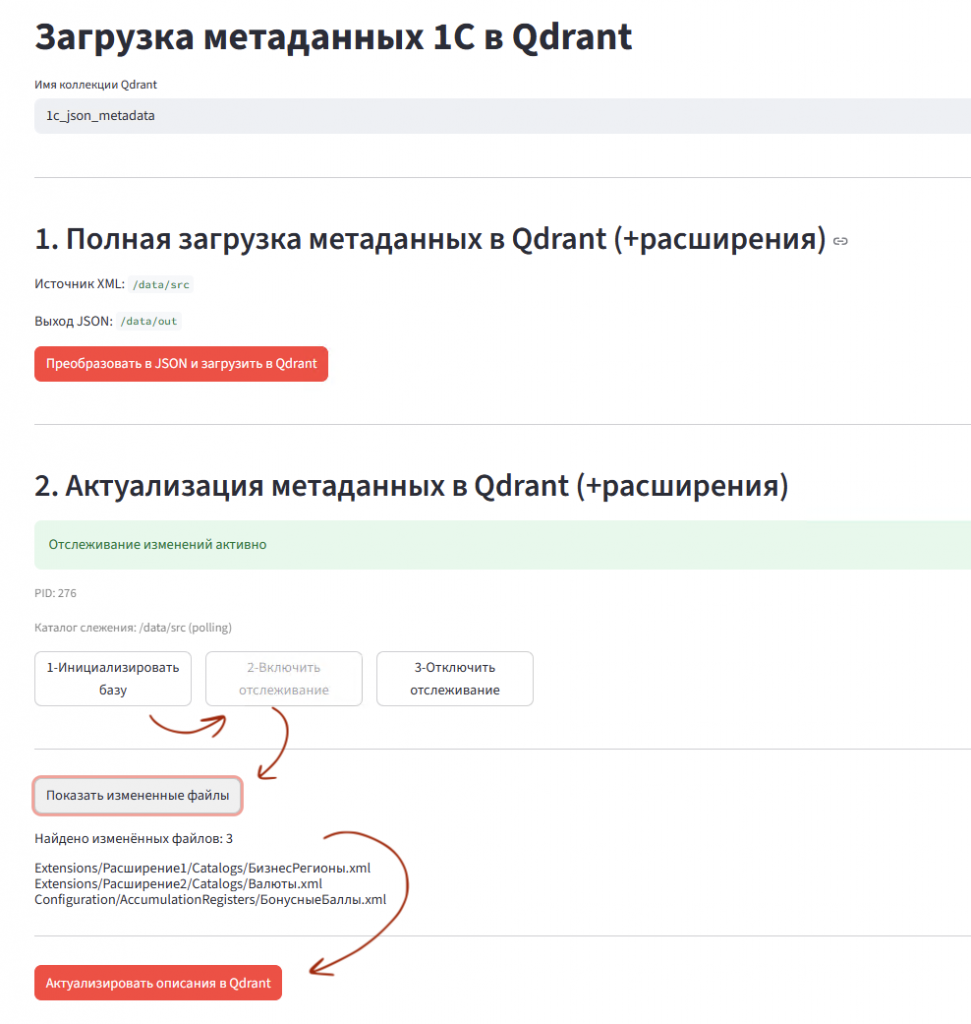
После запуска контейнера metadata-loader (через docker-compose up -d metadata-loader) открываете web-сервис http://localhost:8502

- Указываете наименование коллекции векторной БД Qdrant. Коллекция будет автоматически пересоздана (или создана, если её нет).
- Сначала генерируем полное описание и векторизацию метаданных через кнопку
Преобразовать в json и загрузить в Qdrant. - Затем инициализируем небольшую табличку хешей для отслеживания изменения содержимого xml-файлов метаданных через кнопку
1-Инициализировать базу.
Отслеживаются именно изменения содержимого файлов, а не просто "касание" файлов. Берутся только файлы метаданных 1С, поэтому их получается не так много (относительно всех файлов выгрузки) и поэтому выполняется меньше минуты.
Затем кнопкой 2-Включить отслеживание запускается фоновый процесс, который будет регистрировать изменения файлов метаданных.
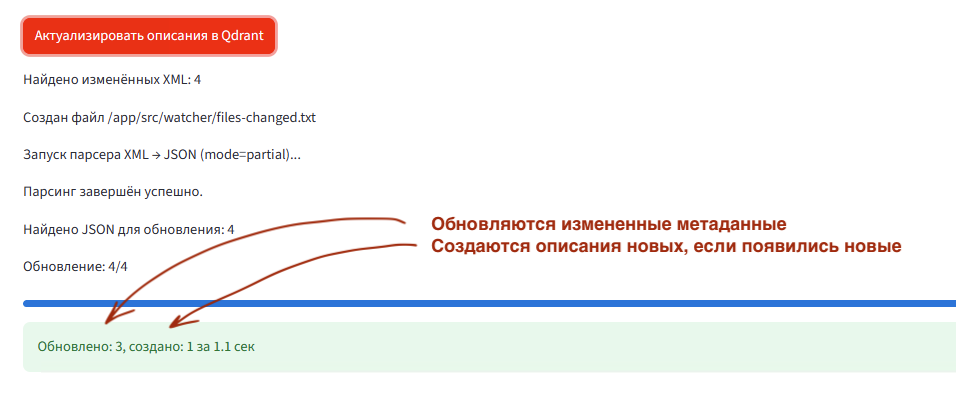
И по кнопке Актуализировать описания в Qdrant можно периодически актуализировать описание метаданных. Измененные объекты метаданных будут обновлены в векторной БД, новые объекты метаданных будут добавлены в векторную БД.

За счет этого обращения к MCP по метаданных от LLM агентов всегда будут отдавать актуальную информацию.
Пример JSON который будет получать LLM агент от MCP
{
"internal_kind": "Document",
"kind": "Документ",
"name": "УстановкаЦенНоменклатуры",
"synonym": "Установка цен номенклатуры",
"numbering": { "type": "String", "length": 9, "allowed_length": "Variable",
"periodicity": "Nonperiodical", "autonumbering": true, "check_unique": true },
"posting": {
"allow": true, "realtime": false,
"registers": {
"writes": [ { "ref": "РегистрСведений.ЦеныНоменклатуры" } ],
"deletion_mode": "AutoDeleteOn",
"writing_on_post": "WriteSelected",
"sequence_filling": "AutoFillOn"
}
},
"attributes": [
{ "name": "Комментарий", "type": "String(0)" },
{ "name": "Ответственный", "type": { "ref": "Справочник.Пользователи" } }
],
"tabular_sections": [
{
"name": "ЦеныНоменклатуры", "synonym": "Цены номенклатуры",
"attributes": [
{ "name": "Номенклатура", "type": { "ref": "Справочник.Номенклатура" } },
{ "name": "Цена", "type": "Number(15, 2)" }
]
}
]
}
Список видов поддерживаемых метаданных
- Catalog / Справочник
- Document/ Документ
- InformationRegister / РегистрСведений
- AccumulationRegister / РегистрНакопления
- AccountingRegister / РегистрБухгалтерии
- Enum / Перечисление
- Constant / Константа
- ChartOfAccounts / ПланСчетов
- ChartOfCharacteristicTypes / ПланВидовХарактеристик
- BusinessProcess / БизнесПроцесс
- DocumentJournal / ЖурналДокументов
- ExchangePlan / ПланОбмена
- FilterCriterion / КритерийОтбора
- HTTPService / HTTPСервис
- WebService / WebСервис
- CommonAttribute / ОбщийРеквизит
- DefinedType / ОпределяемыйТип
Это все те виды метаданных, чьё описание имеет смысл. Единственное, что пока пропущено - это XDTO-пакеты, в силу того, что конкретно пакеты EnterpriseData... очень большие и их не получается одним ответом возвращать LLM агенту. Нужна для них отдельная логика, как их описание отдавать частями.
Изменения в docker-compose.yml
Изменилась версия образа контейнера mcp-metadata:
mcp-metadata:
image: docker.f-pix.ru/mcp/mcp-metadata:v1.6.0 # НОВАЯ ВЕРСИЯ
container_name: mcp-metadata
...
Добавился новый сервис (контейнер) metadata-loader:
metadata-loader:
image: docker.f-pix.ru/mcp/metadata-loader:v1.6.0
container_name: metadata-loader
ports:
- "8502:8501"
environment:
- PYTHONUNBUFFERED=1
- EMBEDDING_SERVICE_URL=http://embedding-service:5000
- QDRANT_HOST=qdrant
- QDRANT_PORT=6333
- SRC_DIR=/data/src
- OUT_DIR=/data/out
- FILES_BATCH_SIZE=50
- EMBEDDING_BATCH_SIZE=25
- WATCHER_POLLING=1
- OMIT_EQUAL_SYNONYM=true # если синоним совпадает с именем, не включать его в JSON
- CONF_LANG=ru
volumes:
- C:/you/project/1c-src:/data/src:ro # Путь к XML-выгрузке 1С (с поддиректориями Configuration и Extensions)
restart: unless-stopped
networks:
- mcp-network
Векторная база данных Qdrant
Была проблема у некоторых пользователей, что не скачивался образ Qdrant с официального репозитория Docker Hub. Из-за этого пересобрал и перенес образ Qdrant в свой docker registry:
docker.f-pix.ru/mcp/qdrant:v1.15
Изменилась строка в docker-compose.yml:
qdrant:
image: docker.f-pix.ru/mcp/qdrant:v1.15 # НОВАЯ ССЫЛКА ОБРАЗА
container_name: qdrant
Сервис векторизации (эмбеддингов)
Изменился базовый образ контейнера для поддержки GPU. По умолчанию он же работает на CPU, как и раньше. Но если есть видеокарта и захочется использовать более тяжелую модель векторизации, например, Qwen/Qwen3-Embedding-0.6B или 4B, то нужно будет сделать следующее:
- установлен и работает
nvidia-smi - установлен и работает nvidia container toolkit
- в
docker-compose.ymlраскомментировать строки блокаdeploy
embedding-service:
image: docker.f-pix.ru/mcp/embedding-service:v1.5 # НОВАЯ ВЕРСИЯ ОБРАЗА
container_name: embedding-service
ports:
- "5000:5000"
volumes:
- ./embeddings/models:/root/.cache/huggingface/hub
# опциональный блок GPU
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
environment:
...
MCP по справке синтакс-помощника
Была исправлена досадная ошибка в наименовании tool'a при запросе детальной справки по идентификатору статьи (help_details_by_id). Из-за этого агент LLM иногда путался и не находил информацию.
mcp-help:
image: docker.f-pix.ru/mcp/mcp-help:v1.5 # НОВАЯ ВЕРСИЯ ОБРАЗА
container_name: mcp-help
Прочее
Добавлен пример настроек MCP для LLM-агента Continue.
По умолчанию отключен (закомментирован) контейнер mcp-inspector. Отключил, потому что почти во всех сервисах и MCP реализован тестовый HTTP API.
# удаление старых контейнеров (векторная БД и модель векторизации сохранятся)
docker compose down
# копируете новый docker-compose.yml
# корректируете настройки под себя:
# sse или http транспорт
# для контейнера проверки синтаксиса свою папку проекта
# запускаете новые контейнеры
docker compose up -d
- MCP по Метаданным: переименованы инструменты и параметры, улучшены описания.
- MCP по справке Синтакс-помощника: переведён на RAG с гибридным поиском.
- Все MCP теперь поддерживают оба транспорта: SSE и HTTP.
- Обновлён загрузчик векторной БД для данных Синтакс-помощника.
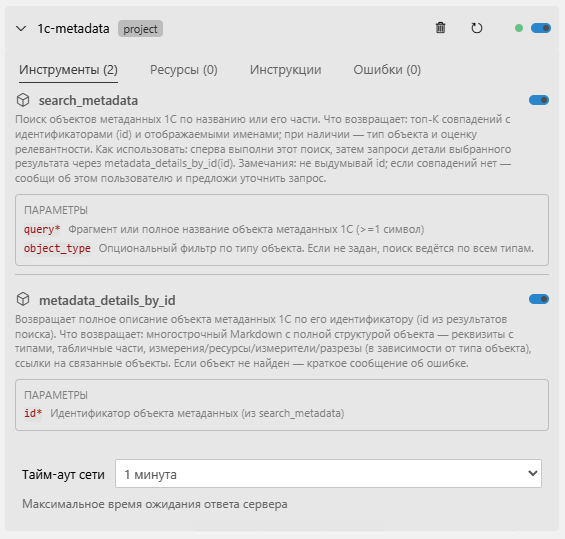
1) MCP по метаданным
Пересмотрены названия инструментов и параметры: убрали неоднозначности, улучшили описания для LLM-агентов.
Пример: search → search_metadata, get_details... → metadata_details_by_id.
В исследовании Microsoft Research описана «интерференция инструментов»: при подключении нескольких MCP часто совпадают имена (особенно search). Claude Code частично решает это префиксами, но у многих агентов этого нет. Новые имена и аннотации уменьшают коллизии и повышают точность выбора инструмента.
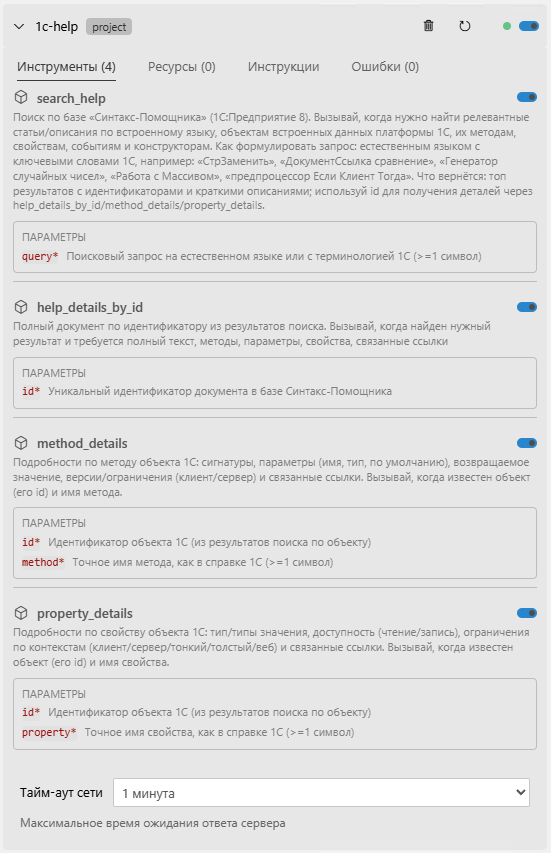
2) MCP по Синтакс-помощнику
Перевели поиск на RAG с гибридным ранжированием: BM25 + векторное сопоставление.
Индексируем название, краткое описание и ключевые слова по документу.
Возвращаем LLM-агенту краткий список кандидатов, а он дозапрашивает детали по выбранному объекту.
Гранулярность ответов
- Для глобальных свойств и методов: текст обычно небольшой — отдаём целиком.
- Для встроенных типов (где описания большие): отдаём гранулярно — по конкретному свойству/методу.
Результат
Быстрее находим релевант и меньше «засоряем» контекст.
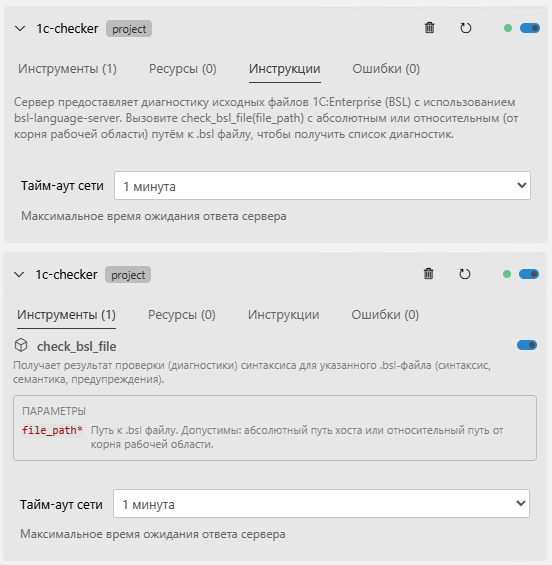
3) Транспортные протоколы (SSE и HTTP)
Оба MCP поддерживают SSE и HTTP. У ряда агентов SSE всё ещё основной — поэтому оставили поддержку.
Примеры
Новый загрузчик в векторную БД:

Новые имена инструментов и подробные аннотации:
Названия и аннотации инструментов и параметров
-
В Microsoft Research вышла интересная публикация про интерференцию агентских инструментов.
Один из поинтов статьи про проблемы с неймспейсами и неоднозначность названий инструментов. -
Можно подключить несколько mcp, и у них могут совпадать названия инструментов, особенно со словом "search".
-
Claude Code обходит эту проблему самостоятельно добавляя префиксы к названиям инструментов, но у других агентов такого нет.
-
Поэтому в новых версиях переработаны и названия и аннотации, чтобы исключить неоднозначности для llm агентов.
Поиск по метаданным

Поиск справки

Проверка синтаксиса

Подробная инструкция по решению
Windows 10/11 x64 или Linux x64
8 Гб RAM
20 Гб HDD
4 ядра CPU (не ARM)
установленный Docker с Docker Compose плагином
Это тот минимум, на котором запустится и будет работать. При первом запуске происходит большая предобработка (индексация), и она будет сильно разной по времени в зависимости от объёма конфигурации (метаданных), мощности ПК (CPU/RAM) и выбранной модели векторизации. По умолчанию выбрана небольшая модель sergeyzh/BERTA, которая быстро отработает даже на минимальных требованиях.
Микросервисная архитектура решения позволяет вспомогательные контейнеры запускать на одном общем мощном ПК/сервере. А на ПК разработчиков запускать только MCP-контейнеры (контейнеры, связанные с взаимодействием с IDE / LLM-агентом).
Как установить и запустить Docker на новой Windows машине:
https://rutube.ru/video/711231ab858d36a3cdca00bc09286b44/
Решение поставляется в виде набора Docker-контейнеров, описанных в файле docker-compose.yml.
Вспомогательные контейнеры:
- Векторная БД Qdrant (контейнер
qdrant) - Сервис векторизации (контейнер
embedding-service) - Сервис загрузки (индексации) данных (контейнер
loader) - Клиент MCP для тестов/проверок (контейнер
mcp-inspector)
Основные контейнеры:
- MCP поиска по метаданным (контейнер
mcp-metadata) - MCP поиска по справке-синтакс-помощника (контейнер
mcp-help) - MCP проверки синтаксиса (контейнер
mcp-bsl-checker)
Дополнительные материалы:
- Примеры настроек MCP для разных IDE
- Пример файла
agents.mdс описанием MCP-инструментов для LLM-агентов
Подготовительная часть:
- Предварительно нужно проиндексировать (векторизовать) описание метаданных конфигурации 1С и файл справки синтакс-помощника.
- Для работы проверки синтаксиса через
bsl-language-serverнеобходимо выгрузить исходники 1С и настроить проброс этой директории в контейнер. - Прописать в настройках IDE / LLM-агента параметры подключения к MCP.
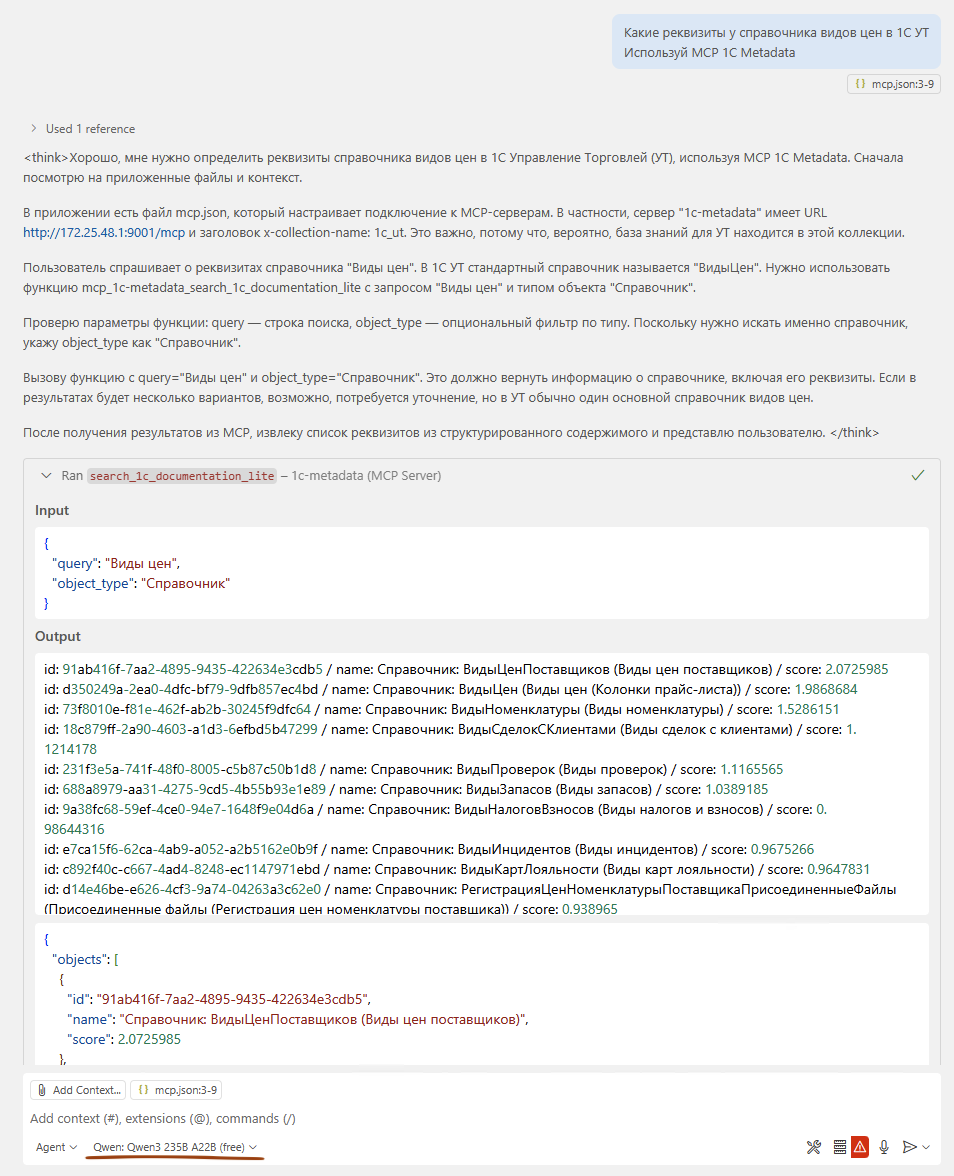
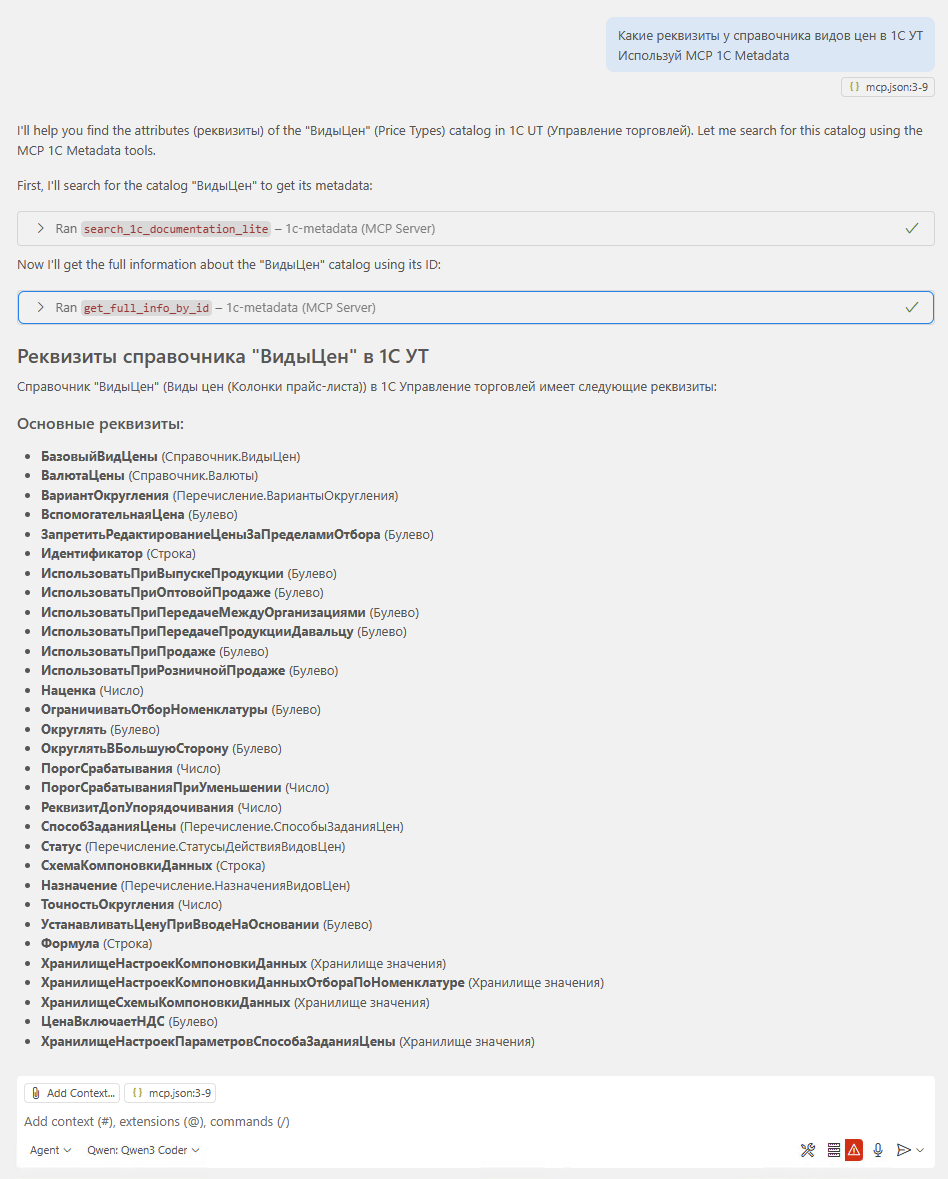
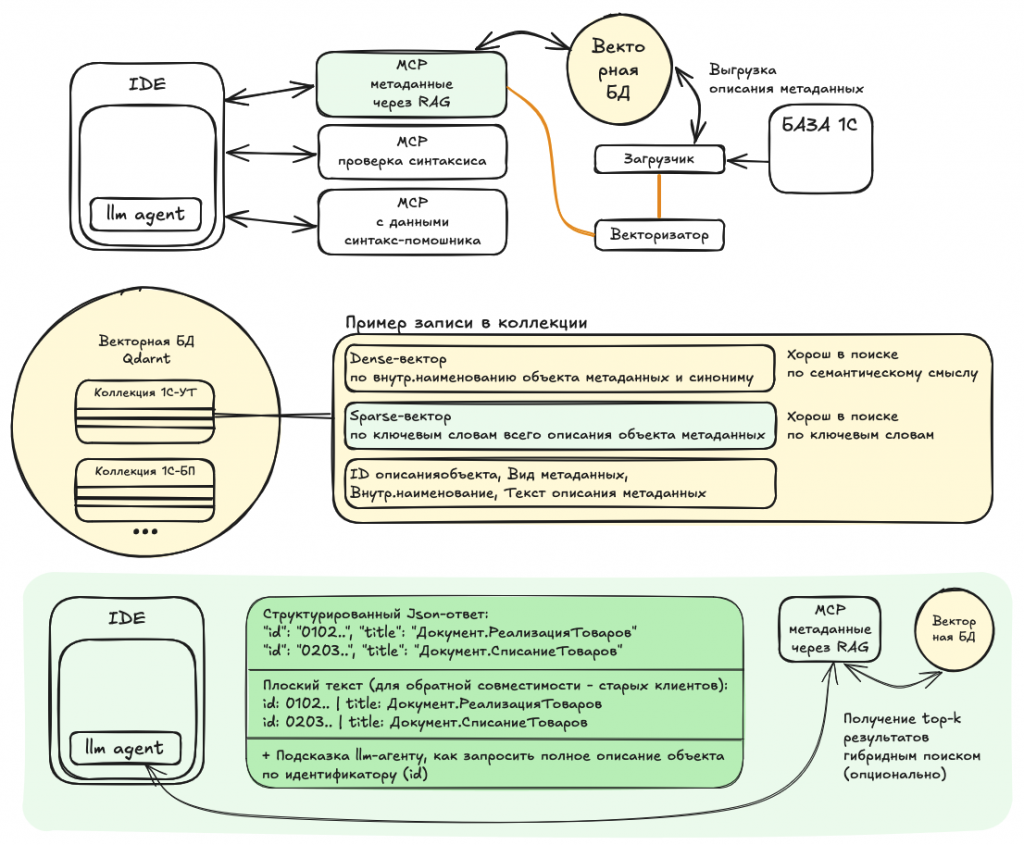
LLM-агент при выполнении задачи принимает решение запросить описание какого-либо объекта метаданных. Агент делает запрос к MCP 1c-metadata, например: «Структура данных документа Заказ клиента» или «регистр запасы на складах». Запрос может включать указание типа объекта (справочник, документ, регистр и т.д.).
MCP векторизует запрос с помощью сервиса embedding-service и выполняет гибридный поиск в векторной БД Qdrant: одновременно семантический (нечёткий) и по ключевым словам. Топ-K результатов возвращается LLM-агенту — это краткий список подходящих метаданных без полных описаний.
LLM-агент выбирает наиболее релевантный объект и делает второй запрос к MCP — уже за полным описанием структуры данных. Обычно хватает одной итерации; в редких случаях агент переформулирует запрос и повторяет поиск.
Таких циклов будет столько, сколько объектов метаданных упомянуто в исходной задаче.
Этот подход называется RAG (Retrieval-Augmented Generation) — генерация, усиленная извлечением данных из внешних систем.
Принцип аналогичен работе с метаданными, но адаптирован под структуру справки 1С.
LLM-агент запрашивает описание глобальных методов или типов данных (например: «Генерация случайного числа» или «запись в регистр сведений») через MCP 1c-help.
Запрос векторизуется и обрабатывается гибридным поиском в Qdrant. В ответе — названия статей + краткое пояснение (описание из справки или список методов/свойств).
Этого достаточно, чтобы LLM-агент выбрал нужную статью и запросил её полное содержимое.
Как и в случае с метаданными, обычно хватает одной итерации.
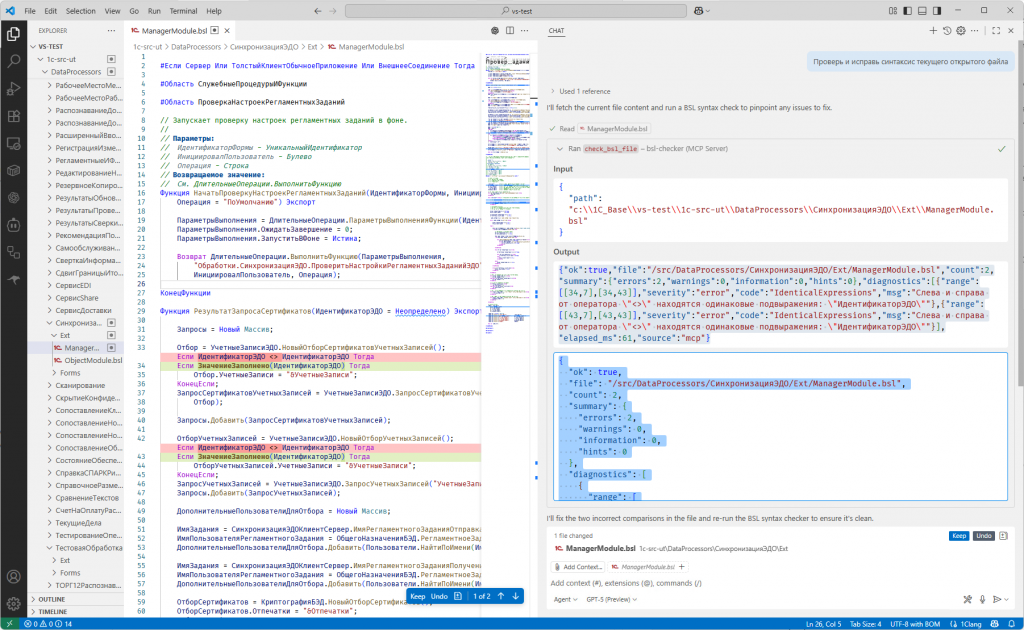
В контейнер mcp-bsl-checker пробрасывается директория с исходниками 1С (конфигурация, расширение, обработка и т.д.).
LLM-агент передаёт путь к файлу (не текст!), например: modul.bsl. MCP преобразует путь к внутреннему расположению в контейнере и запускает проверку через bsl-language-server.
При первом запуске для полной конфигурации можно инициализировать рабочее пространство (улучшает качество проверки). Для расширений и обработок это не поддерживается и отключено по умолчанию.
По умолчанию возвращаются только ошибки (предупреждения скрыты), а результат форматируется в компактный JSON, чтобы не засорять контекст LLM-агента.
Требуются как минимум две директории:
- Для запуска решения (например,
d:\mcp) - Для проектов 1С (например,
d:\projects\proj1)
Подготовка:
В d:\mcp скопируйте:
docker-compose.ymlbsl-ls\.bsl-language-server.json
В d:\projects\proj1 скопируйте:
ВыгрузитьОписаниеСтруктурыКонфигурации.epf- настройки IDE (например, папку
.vscode) - файл
agents.md
Рекомендуемая структура проекта:
proj1/ Выгрузка/ ВыгрузитьОписаниеСтруктурыКонфигурации.epf ОписаниеКонфигурации.zip 1c-build/ # директория сборки бинарников (cf-файлов, epf и т.д.) 1c-src/ # директория xml-выгрузки из конфигуратора 1С (исходники) .vscode/ mcp.json # настройки MCP для VS Code Copilot agents.md # описания MCP-инструментов для LLM-агентов
Разберём настройки всех контейнеров сверху вниз:
qdrant — векторная БД
Можно ничего не менять.
В настройках указывается именованный том для хранения данных на хосте:
volumes: # - ./qdrant_storage:/qdrant/storage - qdrant_storage:/qdrant/storage
Запись в таком формате, а не относительный путь, потому что в Windows иначе получалась битая база после перезапуска контейнера. Под Linux такой проблемы нет.
embedding-service — сервис векторизации
Генерирует обычные (dense) и разрежённые (sparse) векторы.
Переменные:
MODEL_NAME=sergeyzh/BERTA— имя моделиVEC_DIM=768— размерность векторов
Можно использовать любые модели, совместимые с SentenceTransformer (например, ai-sage/Giga-Embeddings-instruct).
Проброс кеша модели:
volumes: - ./embeddings/models:/root/.cache/huggingface/hub
Модели сохраняются в d:\mcp\embeddings\models (от 500 МБ до нескольких ГБ).
API для получения векторов:
curl --request POST \
--url http://127.0.0.1:5000/dense \
--header 'Content-Type: application/json' \
--data '{"texts":["Hello world проверка 1", "Проверка два"]}'
curl --request POST \
--url http://127.0.0.1:5000/sparse \
--header 'Content-Type: application/json' \
--data '{"texts":["Hello world проверка 1", "Проверка два"]}'
loader — сервис загрузки
Выполняет индексацию метаданных и справки.
Основные переменные:
environment: - EMBEDDING_SERVICE_URL=http://embedding-service:5000 - QDRANT_HOST=qdrant - QDRANT_PORT=6333 - ROW_BATCH_SIZE=200 - EMBEDDING_BATCH_SIZE=50
При использовании тяжёлых моделей уменьшайте батчи, при мощном ПК — увеличивайте.
Интерфейс загрузчика: http://127.0.0.1:8501
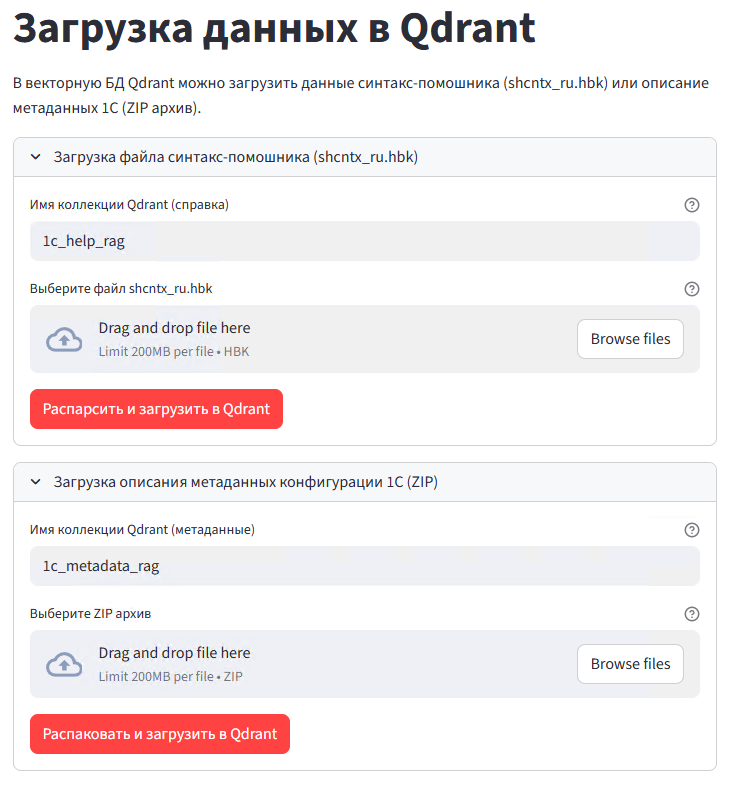
- Для справки укажите коллекцию, например:
1c_help_rag, и выберите файлshcntx_ru.hbk. - Метаданные загружаются из архивов (например,
ОписаниеКонфигурацииУТ.zip) в отдельные коллекции:1c-ut,1c-bpи т.д.
mcp-metadata — поиск по метаданным
Поддерживает несколько проектов через заголовок x-collection-name.
Настройки (по умолчанию закомментированы):
# - MCP_TRANSPORT=sse # - TOPK_LITE_SEARCH_LIMIT=15 # - USE_HYBRID_SEARCH=true
REST API для теста:
curl --request POST \
--url http://127.0.0.1:9001/search \
--header 'Content-Type: application/json' \
--header 'x-collection-name: 1c_ut' \
--data '{"query": "Продажи товаров и услуг","object_type": "Документ"}'
mcp-help — поиск по справке
Гибридный поиск включён по умолчанию.
Переменные:
MCP_TRANSPORT: http COLLECTION_NAME_HELP: 1c_help_rag SEARCH_LIMIT: 10 PREFETCH_LIMIT_MULTIPLIER: 3
Swagger-документация: http://127.0.0.1:9092/docs
curl --request POST \
--url http://127.0.0.1:9092/search \
--header 'Content-Type: application/json' \
--data '{"query": "Число прописью"}'
mcp-bsl-checker — проверка синтаксиса
Пробрасывает директорию с исходниками:
volumes: - C:/Projects/Proj1/1c-src:/src:ro - ./mcp-bsl-checker/bsl-ls/.bsl-language-server.json:/config/.bsl-language-server.json:ro
Важные переменные:
BSL_ONLY_ERRORS=1— только ошибкиHOST_WORKSPACE_DIR="C:/Projects/Proj1/1c-src"— путь к исходникамBSL_SKIP_WORKSPACE_INIT=1— пропустить инициализацию (для расширений)MCP_TRANSPORT="http"
Для нескольких проектов запускайте отдельные контейнеры с разными портами и путями.
REST API для теста:
curl --request POST \
--url http://127.0.0.1:9004/check-file \
--header 'Content-Type: application/json' \
--data '{
"file_path": "C:/1C_Base/vs-test/1c-src-mini/CommonModules/ОбщийМодульТест/Ext/Module.bsl"
}'
Общие настройки для всех MCP
Порты можно менять в секции ports:
ports: - "9005:8000"
Левый порт — хоста, правый — контейнера. Не забудьте обновить порты в файлах mcp.json для IDE.
Комплект поставки и запуск решения
Комплект поставки
Решение поставляется в виде нескольких файлов:
- • Docker-compose файл описывающего запуск всех контейнеров
- - Большинство настроек задаются в нем же. Пояснения к настройкам будут в текстовой версии публикации.
- - В отдельный файлик вынесены настройки сервера, чтобы можно было выключать/выключать опции проверок, например оставить только критичные тем самым сэкономив еще немного контекста.
- • Обработка выгрузки описания метаданных
- • Примеров файлов конфигурации mcp для cursor и vs code (для других IDE конфигурации аналогичны)
Процесс запуска решения
Копируете файлы поставки в любую удобную папку, например: C:\mcp\
В консоли выполняете:
cd C:\mcp
docker compose up -d
Дольше всего будет запускаться контейнер embedding-service, он объемные (4+Гб) и при первом запуске будет скачивать модель векторизации.
Проверить запуск можно в логах контейнера:
docker compose logs embedding-service -f
После запуска можно переходить к выгрузке / загрузке метаданных:
- • Внешней обработкой выгружаем описания из 1С.
- • Открываем веб-страничку сервиса загрузки описаний в векторную БД http://localhost:8501. При загрузке указываем название коллекции в БД. Это позволяет одним mcp одновременно работать с описаниями метаданных нескольких разных конфигураций 1С.
Все. Можем открывать IDE и прописывать параметры подключения mcp.
Пример для Cursor:
"mcpServers": {
"1c-metadata": {
"timeout": 60,
"headers": {
"x-collection-name": "1c_ut"
},
"url": "http://172.25.48.1:9001/mcp",
"disabled": false
},
"1c-check": {
"timeout": 60,
"url": "http://172.25.48.1:9002/mcp",
"disabled": false
},
"bsl-context": {
"command": "docker",
"args": [
"exec",
"-i",
"mcp-bsl-context-stdio",
"java",
"-jar",
"/app/mcp-bsl-context.jar",
"--mode",
"stdio",
"--platform-path",
"/app/1c-platform"
]
}
}
x-collection-name меняете на название коллекции, которое указали при первичной загрузки в векторную БД.
Доступные настройки
Через переменные окружения можно указать модель и размерность ее векторов:
MODEL_NAME=sergeyzh/BERTA- модель по умолчаниюVEC_DIM=768- размерность векторов
По умолчанию указана sergeyzh/BERTA - она маленькая, быстрая и при этом дает хорошие результаты. Контейнер с ней утилизирует буквально 400Мб RAM.
Можно пробовать и другие модели:
intfloat/multilingual-e5-base| 768intfloat/multilingual-e5-small| 384Alibaba-NLP/gte-multilingual-base| 768Qwen/Qwen3-Embedding-0.6B| 1024ai-forever/FRIDA| 1536
Qwen/Qwen3-Embedding-0.6B - дает отличные результаты, но это уже 1,5-2Гб RAM и в несколько раз медленнее.
Доступные настройки:
ROW_BATCH_SIZE- количество объектов метаданных обрабатывать за итерациюEMBEDDING_BATCH_SIZE- размер батча векторизации, сколько одним запросом получать векторов от сервиса векторизации
Доступные настройки:
TOPK_LITE_SEARCH_LIMIT- количество объектов в результатах поискаUSE_HYBRID_SEARCH- использовать ли гибридный поиск (добавлять ли поиск по ключевым словам)
В блоке подключения томов volumes нужно указать путь к папке с платформой 1С, например:
C:/Program Files/1cv8/8.3.27.1644/bin
Остались вопросы?
Для получения дополнительной информации и помощи в настройке модуля под нужды вашего бизнеса — оставьте заявку