Ну, Вы знаете
 Не сомневаюсь, что Вы знаете о назначении индексов и уже использовали их в повседневной работе. Разбираетесь в какой-то мере в принципе их работы, на уровне, достаточном для оптимизации запросов и создания оптимальной структуры базы данных. Прочитали множество материала по этой теме. В общем, говорите с ними на "ты".
Не сомневаюсь, что Вы знаете о назначении индексов и уже использовали их в повседневной работе. Разбираетесь в какой-то мере в принципе их работы, на уровне, достаточном для оптимизации запросов и создания оптимальной структуры базы данных. Прочитали множество материала по этой теме. В общем, говорите с ними на "ты".
Или, возможно, нет? Вероятно, что за потоком проблем из области разработки и решения прикладных задач эта тема просто выпала из Вашего поля зрения. Приоритеты могут быть таковы, что нужно помочь закрыть месяц, сдать отчётность, исправить ошибки в отчетах, починить обмены, сходить в отпуск в конце концов! Список можно бесконечно продолжать. И это абсолютно нормально!
Тема индексов относится больше к теме администрирования базы данных и поддержания стабильности и производительности ее работы. В обычном представлении, разработчик 1С не имеет к их созданию и поддержке прямого отношения. В идеальном мире эта задача ложится на плечи администратора базы данных, но его не часто встретишь в штате. Скорее всего этим занят сисадмин, по крайней мере так многие считают. А у него своих проблем хватает, поэтому он просто копипастом настраивает обслуживание и забывает про 1С.
Когда совсем приспичит, разработчики 1С начинают добавлять индексы через настройки метаданных в конфигураторе. И Вам очень повезет, если индекс будет создан корректно, т.к. часто используется инновационный метод "тыка" при их настройке.
Все это к тому, что часто эта тема проходит мимо разработчиков и администраторов. В проблемах разбираются быстро, принимая "странные" решения и советуя их другим. После этого устоявшиеся подходы становятся "правильными" и "неоспоримыми".
Сегодня мы рассмотрим несколько самых распространённых заблуждений об индексах в контексте 1С, рожденных такими устоявшимися подходами, а также постараемся их объяснить и развеять.
Почему это важно
Ты! Да, ты! Ты разработчик 1С, который в ответе за эффективность работы написанных запросов и всей информационной системы, которую ты обслуживаешь. Сколько угодно можно "клеймить" администраторов, разработчиков платформы 1С и просто жизнь, что база "тормозит", а твой код идеален. Но реальность такова, что чаще всего ты чуть ли не единственный человек, который в силах исправить ситуацию с производительностью, ведь администраторы не в контексте работы БД или не ведают "магию" индексов. А руководство вообще не в курсе дела и считает ответственным именно тебя, 1Сника!
Придется стать героем! Изучить работу СУБД, в частности индексов, и встать на светлую сторону! Жизнь информационной базы в твоих руках! Расширь горизонты познания!
От простого к невероятному
Немного пафосно было сказано, но и правда кто, если не мы?! Вся эта ситуация и создает множество заблуждений про индексы, а в последствии и ошибки при работе с ними. Давайте по порядку рассмотрим самые распространенные из них, передвигаясь от простого к сложному.
Изучение работы индексов, если Вы с ними еще не сталкивались, можно начать с помощью материалов, ссылки на которые добавлены в конце публикации. Сейчас же принципы их работы и что это вообще такое мы рассматривать не будем, тема другая.
И так, поехали!
Индексы не нужны
 Часто приходилось слышать, что об индексах в базе можно не заботиться, т.к. это специфичная тема и мы так уже 15 лет живем. То есть проблем никогда не было, так зачем об этом беспокоиться? Да, у нас система жутко тормозит в периоды закрытия месяца и формирования тяжелых отчетов, но это же 1С! Просто нужно смириться или купить сервер получше. Да и вообще, нет времени с этим копаться.
Часто приходилось слышать, что об индексах в базе можно не заботиться, т.к. это специфичная тема и мы так уже 15 лет живем. То есть проблем никогда не было, так зачем об этом беспокоиться? Да, у нас система жутко тормозит в периоды закрытия месяца и формирования тяжелых отчетов, но это же 1С! Просто нужно смириться или купить сервер получше. Да и вообще, нет времени с этим копаться.
Слышал такое настолько часто, что удивляюсь до сих пор. Самое обидное, что все аргументы проходят всегда мимо и не воспринимаются всерьез. Вот он, дух 1С! То что явно не сказано в инструкциях к платформе и не проверяется на сдаче экзамена "1С:Специалист по платформе", то не должно удостаиваться внимания. К счастью, такое не везде, но удручающе часто. Даже в больших компаниях.
Но индексы конечно же нужны! Это одно из самых эффективных средств повышения скорости поиска данных в базе. Без них большинство запросов выполнялось бы неприемлемое количество времени. Чем больше база, тем больше было бы это время. Если бы индексы были не нужны совсем, то, думаю, разработчики платформы не добавляли штатные кластерные индексы на большинство таблиц, не было бы настроек индексирования в объектах метаданных и многого другого. Нужно ли еще что-то говорить по этому поводу.
Индексы - это сложно
Даже если индексы и нужны, то тема эта настолько сложная, что и браться за нее не стоит! Да, это еще один миф, который довольно часто встречается на просторах разработчиков 1С и системных администраторов. И это тоже заблуждение, т.к. достаточно один раз изучить основы работы и все встанет на свои места. В большинстве случаев, индекс представляет собой некоторый эффективно организованный указатель на значения, с помощью которого поиск осуществляется значительно быстрее по сравнению с полным перебором записей в таблице. Описывать подробно принцип работы индексов здесь смысла нет, да и это уже делали не раз на Инфостарт. Оставлю здесь несколько полезных ссылок:
организованный указатель на значения, с помощью которого поиск осуществляется значительно быстрее по сравнению с полным перебором записей в таблице. Описывать подробно принцип работы индексов здесь смысла нет, да и это уже делали не раз на Инфостарт. Оставлю здесь несколько полезных ссылок:
Прочитав даже одну лишь из перечисленных статей, Вы навсегда поймете, что индексы - это просто. Когда знаешь - все становится просто. Знание - сила!
СУБД создает индексы автоматически
 Помню не одну беседу, когда мне пытались доказать, что СУБД, в т.ч. Microsoft SQL Server, создает все необходимые индексы автоматически и полностью самостоятельно на основе собранной статистики. То есть если мы много много много раз выполним какой-либо запрос и SQL Server поймет, что для его эффективной работы нужен индекс, то она создаст его!
Помню не одну беседу, когда мне пытались доказать, что СУБД, в т.ч. Microsoft SQL Server, создает все необходимые индексы автоматически и полностью самостоятельно на основе собранной статистики. То есть если мы много много много раз выполним какой-либо запрос и SQL Server поймет, что для его эффективной работы нужен индекс, то она создаст его!
Это, конечно же, полностью не так! Создание, изменение и удаление индексов - это обязанность разработчика баз данных или администратора БД. Автоматически СУБД ничего не создает и не удаляет, и это очень хорошо. Вы только представьте ситуацию, когда SQL Server решит создать индекс автоматически во время рабочего дня, породив блокировку данных. Или автоматически создаст пару индексов и полностью займет свободное дисковое пространство, ведь индексы имеют накладные затраты в виде занимаемого места на диске и времени на их поддержание.
Но от части это все же правда. Но не в плане, что СУБД создает индексы автоматически, а в том, что она может подсказать каких индексов сейчас не хватает. Ранее в публикациях были рассмотрены скрипты для SQL Server и PostgreSQL, среди которых были и те, что показывали отсутствующие индексы. Для SQL Server статистика по отсутствующим индексам по умолчанию собирается наиболее подробная по сравнению с данными для PostgreSQL.
Не стоит уповать на СУБД в части создания индексов в автоматическом режиме. Все же думать над этим придется, а SQL Server / PostgreSQL / др. СУБД дадут эффективные инструменты анализа недостающих индексов и средства их создания и поддержки.
Платформа 1С создает все индексы сама
Как Вы уже поняли, СУБД не создает индексы автоматически, адаптируясь под выполняемые запросы. НО! Значит платформа 1С сама создает недостающие индексы для оптимизации производительности!
На самом деле, конечно же, нет. Услышав такое, можно очень удивиться и пойти пить крепкий чай. Но столкнуться с таким до сих пор можно. Тут, на самом деле, возможно, появляется путаница, ведь платформа все же создает индексы в зависимости от типа объекта метаданных и его настроек. Это действительно так и по этой ссылке Вы можете изучить все возможные платформенные индексы.
В остальных же случаях разработчику приходится самостоятельно настраивать индексирование полей, чтобы добиться нужного результата. К сожалению, искусственный интеллект в платформу еще не завезли.
Чем больше индексов, тем лучше
Для быстрого поиска нужен индекс. Так почему же не добавить индекс на каждое поле. Например, есть справочник "Номенклатура" в конфигурации "Управление торговлей" ред. 11. В нем имеется несколько индексов, большинство из которых создается платформой 1С без каких-либо особых настроек. Есть и индексы, созданные специально для тех реквизитов, в которых свойство "Индексировать" установлено в "Индексировать" (извините за тавтологию, но такие уж названия):
- Артикул
- Вид номенклатуры
- Код для поиска
Но что, если нужно выполнить поиск по реквизиту "Код ОКВЭД" или "Код ОКП"? Или любому другому полю? Почему бы не добавить индексы на каждое поле?
 Да, тут сразу можно понять, что что-то не так и добавление индексов на все поля таблицы дело не самое правильное. Как уже говорилось выше, индексы имеют свои накладные расходы для обслуживания. Кроме дополнительного дискового пространства, для их поддержки СУБД тратит дополнительное время при выполнении операций модификации данных. Когда Вы изменяете запись в таблице, СУБД обновляет данные индекса, что требует дополнительного времени и ресурсов. Чем больше индексов на таблице, тем больше времени на поддержку индекса тратится. Это время может быть незначительным относительно общего времени выполнения операции записи, но чем больше индексов, тем сильнее это время будет увеличиваться.
Да, тут сразу можно понять, что что-то не так и добавление индексов на все поля таблицы дело не самое правильное. Как уже говорилось выше, индексы имеют свои накладные расходы для обслуживания. Кроме дополнительного дискового пространства, для их поддержки СУБД тратит дополнительное время при выполнении операций модификации данных. Когда Вы изменяете запись в таблице, СУБД обновляет данные индекса, что требует дополнительного времени и ресурсов. Чем больше индексов на таблице, тем больше времени на поддержку индекса тратится. Это время может быть незначительным относительно общего времени выполнения операции записи, но чем больше индексов, тем сильнее это время будет увеличиваться.
С помощью простого запроса можно проанализировать список индексов, на поддержание которых СУБД тратит значительные ресурсы в части операций ввода / вывода.
К сожалению, такого простого запроса для PostgreSQL нет. Там требуется другой подход.
Плюс ко всему, неизвестно какие индексы для всех полей добавлять, ведь они могут быть составными, покрывающими, а еще для использования индексов значение отбора должно быть селективным. Какой смысл искать в индексе по полю "Пометка удаления" со значением Ложь, если 99% записей в таблице не помечены на удаление? Индекс не будет использоваться, т.к. смысла искать по неселективному значению нет.
Таким образом, смысла создавать индексы для всех полей просто нет, да и для большого числа полей тоже. При создании индекса нужно точно знать для каких целей он создается, иначе он будет висеть мертвым грузом и просто "съедать" ресурсы сервера. Если уж и стоит задача поиска по всем возможным полям, то скорее всего нужен другой подход в виде полнотекстового поиска и т.д.
Главное, чтобы поле входило в индекс
Перейдем к более практическим кейсам. Еще одним частым "фейлом" можно считать ситуацию, когда разработчики считают, что для эффективной работы индекса главное наличие в нем нужно поля. Например, в типовой конфигурации "Управление торговлей" ред. 11 имеется регистр сведений "Календарные графики" со следующей структурой.
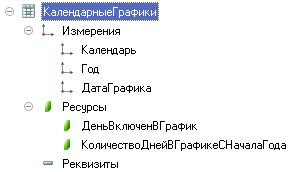
У регистра один единственный кластерный индекс.
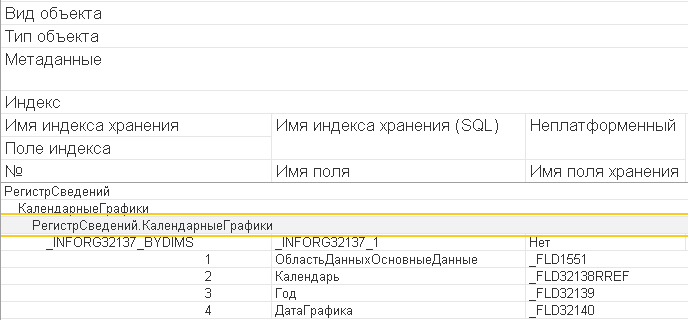
Например, нам понадобилось узнать для определенной даты включена ли она в график. Делаем простейший запрос.
ВЫБРАТЬ
КалендарныеГрафики.Календарь КАК Календарь,
КалендарныеГрафики.Год КАК Год,
КалендарныеГрафики.ДатаГрафика КАК ДатаГрафика,
КалендарныеГрафики.ДеньВключенВГрафик КАК ДеньВключенВГрафик,
КалендарныеГрафики.КоличествоДнейВГрафикеСНачалаГода КАК КоличествоДнейВГрафикеСНачалаГода
ИЗ
РегистрСведений.КалендарныеГрафики КАК КалендарныеГрафики
ГДЕ
КалендарныеГрафики.ДатаГрафика = &ДатаГрафика
В качестве параметров передаем конкретную дату (например, "01.11.2017 0:00:00"). Вроде бы хороший запрос и это поле есть в индексе (см. изображение выше). Но на самом деле, запрос этот написан не самым оптимальным образом, а существующий индекс в запросе практически не используется. Посмотрите, что происходит на стороне СУБД.

По этой информации видно, что индекс не использовался от слова совсем. Но как же так? Индекс же содержит поле "Дата графика", почему бы его не использовать? И да, такие вопросы до сих пор приходится слышать. Узнав ответ, обычно начинают либо отрицать такое поведение, ибо уже по этой логике написали много запросов (да здравствует тех. долг!). Либо начинают возмущаться, что SQL Server не работает корректно и почему Microsoft не создала нормальный механизм индексирования.
Ответ, конечно же, простой - потому что индекс так не работает. Чтобы его использование стало возможным, необходимо накладывать условия в соответствии со структурой индекса, а именно в соответствии с порядком полей индекса. Да, можно не делать отбор по всем полям из состава индекса, но накладывать фильтр нужно от первого поля и так далее по порядку. Иначе его эффективное использование невозможно. Выше были даны ссылки на материалы по работе индексов, изучив их вопросов почему так это работает не останется.
Итого: структура индекса состоит из полей, по которым будет выполняться поиск, но их порядок в не менее важен, чем их наличие.
Платформа 1С позволяет создавать произвольные составные индексы
Еще одна забавная путаница связана с составными индексами. Вот есть у Вас справочник "Номенклатура" и для какой-то задачи понадобилось делать поиск номенклатуры по трем полям: "Качество", "Марка", "Складская группа". Не важно зачем, есть задача и все :)
Что в первую очередь делает разработчик? Вариант, что с индексами ничего не делает - рассматривать не будем. Правильно - устанавливает свойство "Индексирование" у реквизитов в "Индексировать". Установил у всех реквизитов, обновил информационную базу и радуется. А на самом деле среди множества индексов на каждое поле был добавлен собственный индекс.
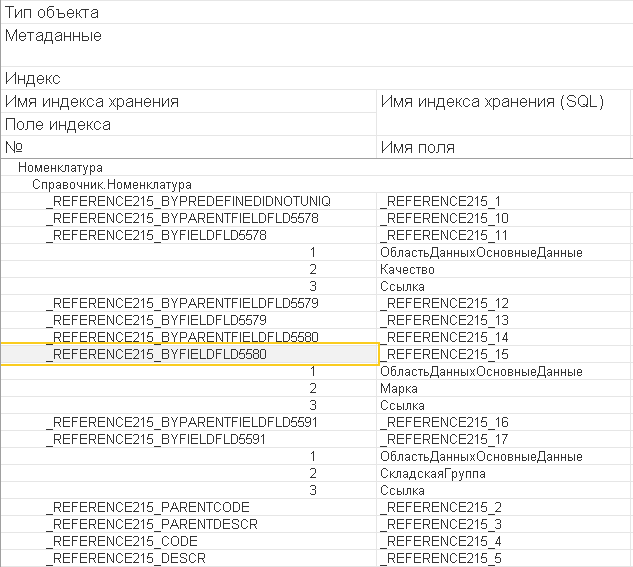
То есть составного индекса с полями "Качество", "Марка" и "Складская группа" платформа 1С не создала. На самом деле это нормально, т.к. настройки индексирования такого сейчас не позволяют. Тем более как платформа по этим настройкам может определить порядок полей в индексе, а без этого делать их настройку бессмысленно.
Любопытные разработчики могли пойти дальше и поставить индексирование с доп. упорядочиванием. Но это не изменит проблему - составного индекса с нужными полями создано не будет. Но мы получим монструозные индексы, которые платформа создает при включенном доп. упорядочивании, которые могут решить только задачу создания покрывающего индекса, но не как не эффективного при поиске данных.
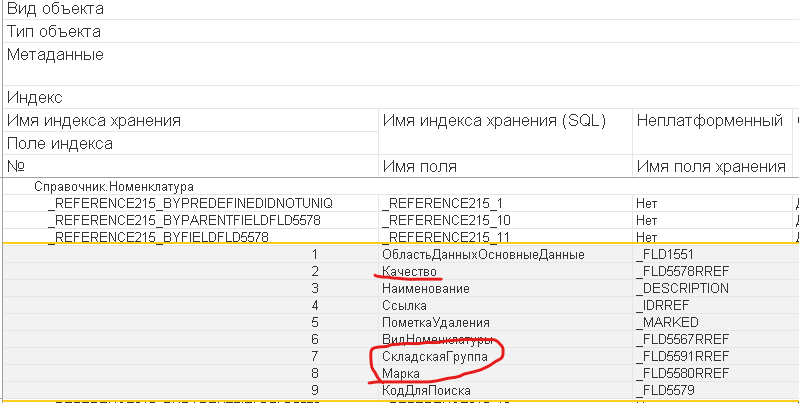
Все это поведение описано в официальной документации и ничего удивительного здесь нет. Но все ли ее читают?
В регистрах всегда есть индекс по измерениям
 По этому поводу где-то даже была ветка на Инфостарт или Мисте, где разработчики спорили так, аж "сопли из замочной скважины летели". Рассмотрим пример. Есть в УТ 11 регистр накопления "Товары на складах". Думаю, что многие с ним знакомы. Так вот, в некоторых ситуациях необходимо делать запрос к основной физической таблице регистра, не используя виртуальную таблицу остатков. Зачем и когда это нужно сейчас обсуждать не будем, просто продолжим. Вот структура этого регистра.
По этому поводу где-то даже была ветка на Инфостарт или Мисте, где разработчики спорили так, аж "сопли из замочной скважины летели". Рассмотрим пример. Есть в УТ 11 регистр накопления "Товары на складах". Думаю, что многие с ним знакомы. Так вот, в некоторых ситуациях необходимо делать запрос к основной физической таблице регистра, не используя виртуальную таблицу остатков. Зачем и когда это нужно сейчас обсуждать не будем, просто продолжим. Вот структура этого регистра.
Как часто пишут в мануалах, отбор в регистре нужно делать в том порядке по измерениям, как они размещены в структуре метаданных регистра. То есть, если нужно получить информацию по конкретному складу в таблице остатков, то обязательно нужно установить фильтр по номенклатуре, характеристике, назначению и непосредственно складу. Объясняется это тем, что порядок полей в основном индексе регистра определяется порядком в объекте метаданных. А как мы уже Выше смотрели, порядок полей в индексе очень важен.
Так вот, очень часто разработчики считают, что в таблице движений регистра всегда есть индекс по измерениям. В нашем случае он должен идеально подойти для выполнения фильтрации по номенклатуре. То есть, если нам нужно получить все записи движений по номенклатуре, то нужно сделать вот так.
ВЫБРАТЬ
ТоварыНаСкладах.Период КАК Период,
ТоварыНаСкладах.ВидДвижения КАК ВидДвижения,
ТоварыНаСкладах.Номенклатура КАК Номенклатура,
ТоварыНаСкладах.Характеристика КАК Характеристика,
ТоварыНаСкладах.Назначение КАК Назначение,
ТоварыНаСкладах.Склад КАК Склад,
ТоварыНаСкладах.Помещение КАК Помещение,
ТоварыНаСкладах.Серия КАК Серия,
ТоварыНаСкладах.ВНаличии КАК ВНаличии,
ТоварыНаСкладах.КОтгрузке КАК КОтгрузке
ИЗ
РегистрНакопления.ТоварыНаСкладах КАК ТоварыНаСкладах
ГДЕ
ТоварыНаСкладах.Номенклатура = &Номенклатура
УПОРЯДОЧИТЬ ПО
Период
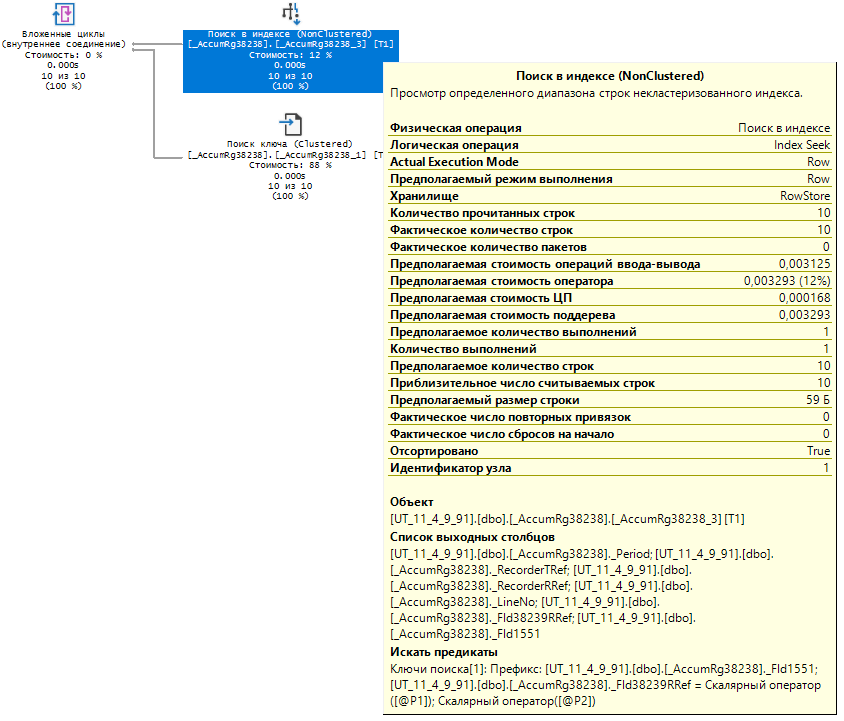
Так как измерение "Номенклатура" первое в предполагаемом индексе по измерениям, то все должно работать отлично. Но, вот так сюрприз! На стороне СУБД с нами не согласны.
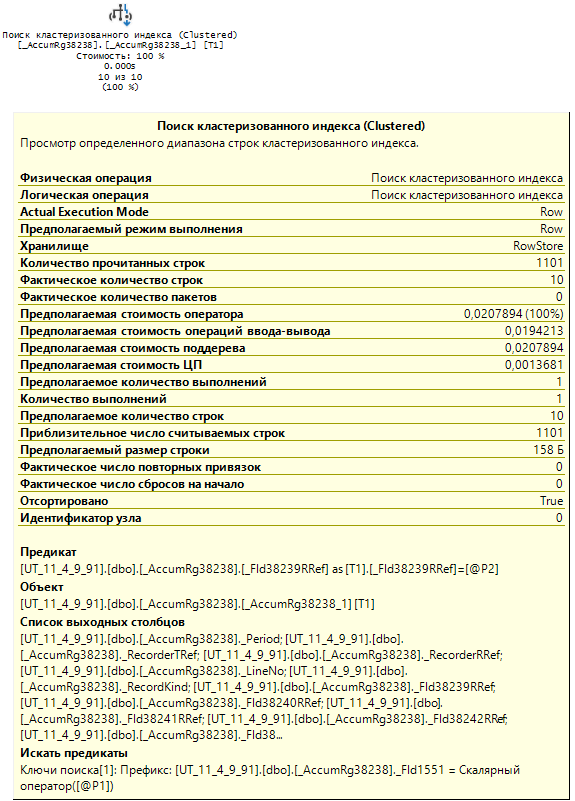
Да, индекс по измерениям в основной таблице регистра не использовался. Почему? Да потому что там нет такого индекса по измерениям, которого мы так ждали. Основная таблица регистра накопления по умолчанию содержит такие индексы:
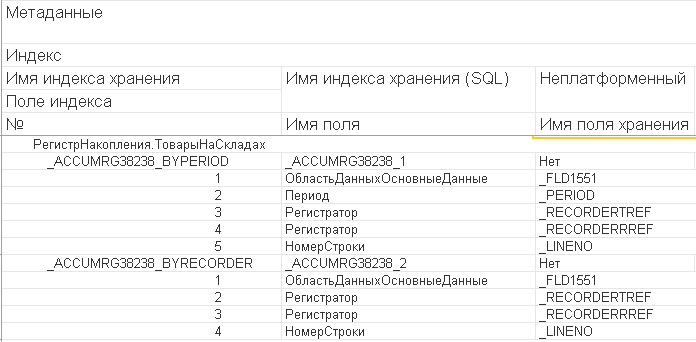
Нет ни одного подходящего, который бы позволил эффективно отобрать записи по первому измерению, то есть по номенклатуре. Для исправления ситуации Вы можете включить индексирование для первого измерения и получите вот такой индекс.
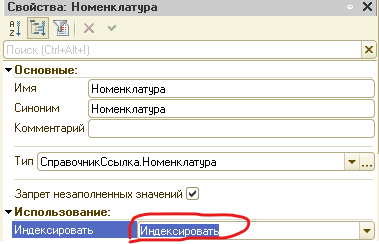 А после обновления информационной базы получаем то что ожидали.
А после обновления информационной базы получаем то что ожидали.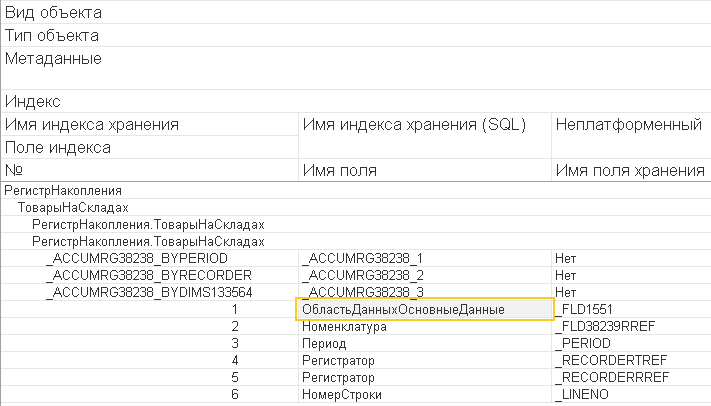 Профит!
Профит!Теперь ситуация на стороне СУБД будет иной.
Но как же так, где же изначально был индекс? На самом деле индекс по измерениям есть, но он находится в таблице итогов регистра. Именно поэтому существуют рекомендации от фирмы "1С" выполнять получение данных из регистра с помощью виртуальным таблиц. Вот какой есть индекс в таблице итогов регистра, где хранятся данные по остаткам.
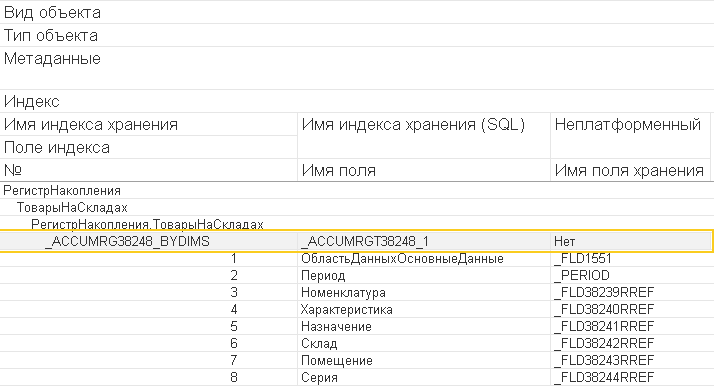
Но и тут есть нюанс - первым измерением идет период. Без указания периода индекс также работал бы неэффективно, то есть вообще бы не использовался. Ранее мы уже рассматривали работу виртуальных таблиц регистров накопления, можете освежить знания:
Но, конечно, не все так однозначно. Бывают ситуации, когда нужны индекс по измерениям уже есть. Например, регистр сведений "Цены номенклатуры", в котором есть множество индексов на основной таблице. Три основных из них создались платформой 1С изначально, т.к. они есть для всех регистров подобного вида (основной кластерный индекс по периоду, индекс по регистратору и индекс по измерениям).
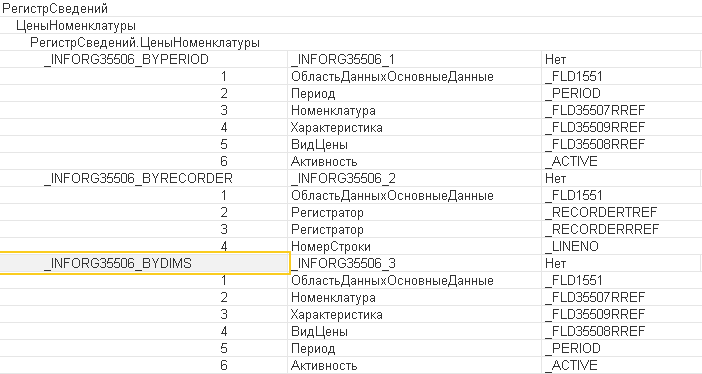
Как мы видим, есть индекс по измерениям у регистра сведений подходящий для запросов, где ставился бы отбор по первому измерению. Ситуация еще может быть изменена тем, что разработчики поставили флаг "Ведущее" у измерения регистра в настройках метаданных.
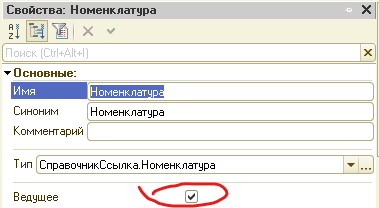
При такой настройке платформа создает индекс по измерению как дополнительный. В регистре "Цены номенклатуры" в УТ 11 для всех измерений установлена эта настройка, поэтому платформа была очень щедрой на создание индексов для этих измерений.
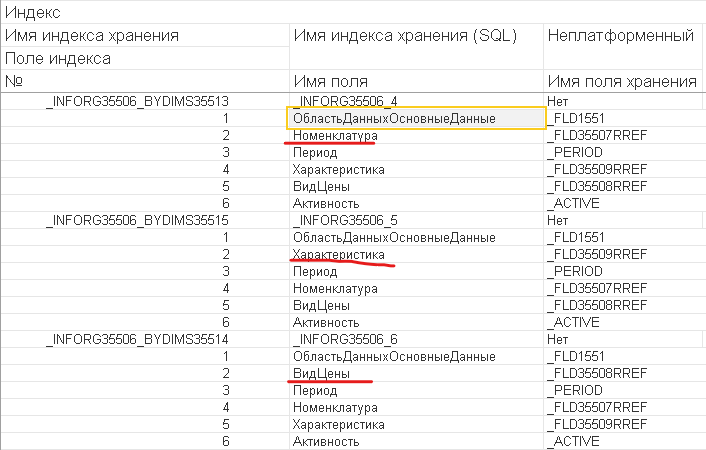
Будут ли два индекса, у которых первое поле "Номенклатура" избыточными? Стоило ли создавать индекс для измерения "Номенклатура", если оно уже было в другом индексе? Сложный вопрос, ведь конечная структура индексов все же отличается. Нужно смотреть по ситуации.
Что же можно сказать в итоге? Не всегда одной только логикой и предположениями можно понять, какие все-таки индексы создает платформа 1С. Как говорится: "доверяй, но проверяй". Если есть хоть малейшие сомнения в том, создала ли платформа необходимый для наших запросов индекс - вперед смотреть что творится на стороне базы данных. Анализировать можно с помощью стандартных средств платформы, вызывая метод "ПолучитьСтруктуруХраненияБазыДанных" или использовать более удобные инструменты с Инфостарт. Например, отчет Просмотр и анализ структуры базы данных (отчет на СКД), с помощью которого и были сделаны изображения и другой материал по структуре индексов в этой публикации.
Оставьте стереотипы позади и проверяйте работу платформы, ведь с каждой новой версией поведение может измениться.
Во все временные таблицы нужно добавлять индекс
При подготовке к экзамену 1С:Специалист по платформе очень часто можно услышать, что при создании временных таблиц обязательно нужно задавать для них индекс. Да и не только для экзамена, просто такая информация не редко проскальзывает в сообществе. Да, да, тот самый индекс в запросе. Например, помещая табличную часть документа во временную таблицу, добавляя для него индекс и в дальнейшем используя для соединения с другими таблицами (виртуальные таблицы регистров и др.).
Но давайте посмотрим, как индекс во временной таблице влияет на производительность. Первым делом проанализируем как платформа выполняет запрос выше.
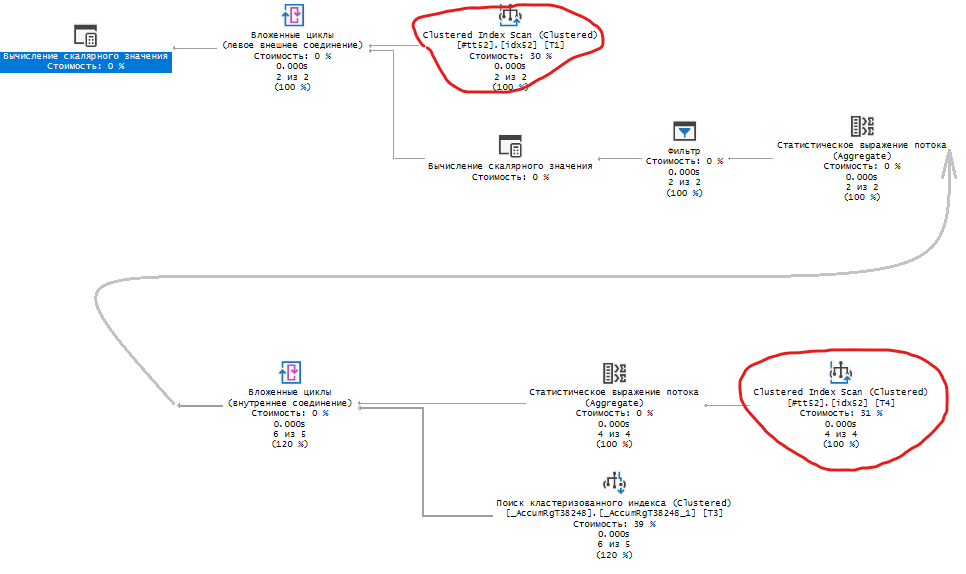
Таким образом, добавлять индексы во временную таблицу не всегда целесообразно. Да, они могут пригодиться на больших объемах данных при выполнении операций соединения и фильтрации. Но бездумно вставлять их в тех случаях, когда во временной таблице не может быть большого количества записей или сложных соединений вообще не предвидится все же неправильно. Это как преждевременная оптимизация, которая может сделать только хуже.
Тут лишь можно посоветовать - проверять работу своих запросов, смотреть планы запроса и изучить контекст работы Вашего кода. Универсального решения нет.
Неплатформенные индексы - зло
Они лишь зло в неумелых руках. Да, они относятся к нестандартным решениям и входят в противоречие с лицензионным соглашением фирмы "1С". Но прежде чем их отбрасывать, то рекомендую все же посмотреть этот материал, т.к. иногда такой подход остается единственным для решения задач производительности и стабильности.
Все в Ваших руках
В рамках одной публикации не раскрыть всех нюансов работы с индексами, но и цель была другой. Надеюсь, что это будет отличным стартом для всех, кто только погружается в тему работы СУБД и индексов в частности. Кто знает, может и опытные разработчики найдут что-то новое здесь для себя.
Краткий итог всего выше сказанного можно подвести такой:
- Индексы в базе нужны и важны.
- Понять работу индексов просто, а вот нюансы уже сложнее и требует усилий для изучения.
- Индексы требуют пристального внимания как со стороны разработчика, так и со стороны администратора базы данных.
- При написании запросов важно понимать принцип работы индексов, чтобы эффективно их использовать.
- Платформенные индексы не всегда работают так, как предполагается. Проверяйте с помощью документации и профилирования запросов.
- Рекомендации 1С для общих ситуаций, иногда все же нужно думать в контексте задачи.
- Выходить за рамки возможностей платформы можно, но нужно четко понимать, что и для чего Вы делаете.
В любом случае, добро пожаловать в комментарии! Всегда интересно послушать другие кейсы и перенять чужой опыт.
Если Вам нравится публикация, то не забывайте ставить лайки и подписываться на канал :).
Другие ссылки
-
Создаем свои индексы для баз 1С. Со своей структурой и настройками!
-
14 вопросов об индексах в SQL Server, которые вы стеснялись задать
-
Инструменты обслуживания и разработки для MS SQL Server, а также другие интересности
-
Инструменты обслуживания и разработки для PostgreSQL, а также другие интересности
Авторские разработки
-
Анализ производительности APDEX - отчет для просмотра и анализа замеров производительности в конфигурациях на базе БСП.
-
Путеводитель по истории релизов - отчет по истории выпуска релизов продуктов фирмы "1С" и анализа информации по обновлениям.
-
Просмотр и анализ структуры базы данных (отчет на СКД) - отчет для просмотра и анализа структуры базы данных с поддержкой файловых баз (ограниченный режим), а также баз на SQL Server и PostgreSQL.
-
Просмотр и анализ журнала регистрации (отчет на СКД) - отчет на базе системы компоновки данных (СКД) для просмотра записей журнала регистрации.
-
Обозреватель криптографии - отчет для просмотра доступных провайдеров и сертификатов криптографии на сервере и клиенте.
-
Пакетная выгрузка / загрузка внешних отчетов и обработок - пакетная выгрузка / загрузка внешних отчетов и обработок для массовый манипуляций с ними.
-
Командный интерпретатор для 1С - инструмент для выполнения команд CMD / PowerShell из 1С.

Вступайте в нашу телеграмм-группу Инфостарт