В SQL Server топ запросов по потреблению ресурсов можно получить из кэша планов запросов или с помощью Query Store.
Первый способ не требует никаких предварительных настроек. DMV sys.dm_exec_query_stats, sys.dm_exec_sql_text и sys.dm_exec_query_plan предоставляют доступ, соответственно, к статистике выполнения, текстам и планам запросов из кэша. К недостаткам этого метода относится то, что в кэше сохраняются не все версии планов запросов, и то, что кэш не предназначен для постоянного хранения и может быть очищен.
Чтобы использовать Query Store его нужно включить, настроить и подождать пока в хранилище накопятся нужные данные.
Коротко рассмотрим оба способа.
Для получения информации о ресурсоемких запросах из кэша планов запросов можно использовать следующий запрос:
SELECT
topq.statement_text,
topq.creation_time,
topq.last_execution_time,
topq.execution_count,
topq.avg_worker_time,
topq.avg_physical_reads,
topq.avg_logical_reads,
topq.max_dop,
topq.plan_handle,
qp.query_plan
FROM
(
SELECT TOP 20
MIN(qstats.statement_text) AS statement_text,
MIN(qstats.plan_handle) AS plan_handle,
MIN(qstats.creation_time) AS creation_time,
MAX(qstats.last_execution_time) AS last_execution_time,
SUM(qstats.execution_count) AS execution_count,
SUM(qstats.total_worker_time) / SUM(qstats.execution_count) AS avg_worker_time,
SUM(qstats.total_physical_reads) / SUM(qstats.execution_count) AS avg_physical_reads,
SUM(qstats.total_logical_reads) / SUM(qstats.execution_count) AS avg_logical_reads,
MAX(qstats.max_dop) AS max_dop
FROM
(SELECT
qs.query_hash,
qs.plan_handle,
qs.creation_time,
qs.last_execution_time,
qs.execution_count,
qs.total_worker_time,
qs.total_physical_reads,
qs.total_logical_reads,
qs.max_dop,
SUBSTRING(st.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(st.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) AS st
WHERE st.dbid = DB_ID('database_1c') ) AS qstats
GROUP BY qstats.query_hash
HAVING MIN(qstats.statement_text) LIKE 'SELECT%'
ORDER BY avg_worker_time DESC
) topq
CROSS APPLY sys.dm_exec_query_plan(topq.plan_handle) qp
Здесь DMV соединяются по идентификатору плана запроса в кэше – plan_handle. Результатом выполнения станет топ запросов по среднему процессорному времени:
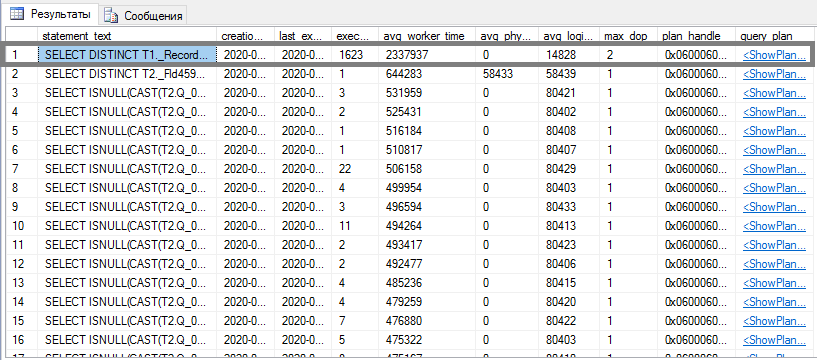
Аналогично запросы можно упорядочить и по другим метрикам производительности, таким как логические или физические чтения.
Второй способ – Query Store, который впервые появился в SQL Server 2016. Включить его можно в окне свойств базы данных или с помощью запроса, например:
ALTER DATABASE database_1c SET QUERY_STORE = ON
GO
ALTER DATABASE database_1c SET QUERY_STORE (OPERATION_MODE = READ_WRITE,
/*Регистрируются только запросы с временем выполнения > 1 сек и выполненные больше 3-х раз*/
QUERY_CAPTURE_MODE = AUTO,
/*Максимальный размер хранилища в Мб (В 2016 по умолчанию - 100 Мб)*/
MAX_STORAGE_SIZE_MB = 1000)
GO
Помимо прочих возможностей Query Store позволяет просматривать отчет «Основные запросы, потребляющие ресурсы» («Top Resource Consuming Queries»). Откроем отчет и выберем метрику «Время ЦП (мс)»:
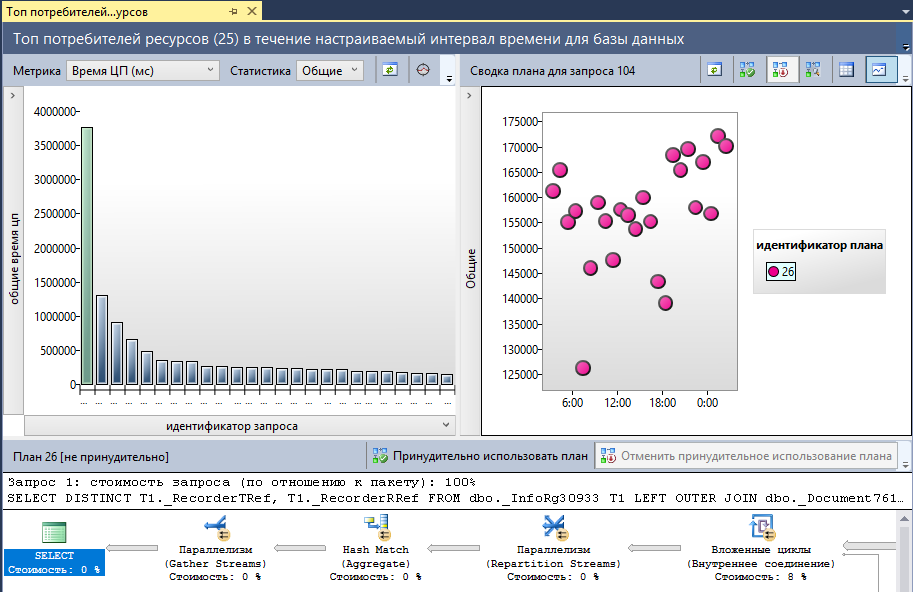
Первым в топе мы видим тот же самый запрос, который ранее мы получили из кэша планов запросов с помощью DMV.
В правой части окна мы видим сводку разных вариантов плана этого запроса. Каждая отметка обозначает не единичное выполнение, а обобщенную информацию по выполнениям за интервал времени. Переключившись в табличный формат сводки можно узнать точные значения метрик, а также значение счетчика выполнения запроса. Наш запрос выполняется с высокой периодичностью.
В нижней части окна отчета выводится текст запроса и план его исполнения.
Теперь, когда запрос для оптимизации выбран, выясним, что это за запрос. Для того чтобы определить место вызова запроса в конфигурации, настроим технологический журнал 1С следующим образом:
<?xml version="1.0" encoding="UTF-8"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<dump create="true" location="D:\Debug\dumps" type="0" prntscrn="false"/>
<log location="D:\Debug\logs_dbmssql" history="600">
<event>
<eq property="name" value="DBMSSQL"/>
<eq property="p:processName" value="ibase_1c"/>
<like property="sql" value="%LEFT OUTER JOIN dbo.\_Document761 T2%"/>
</event>
<property name="all"/>
</log>
</config>
В журнал будут записываться только события DBMSSQL, регистрируемые при исполнении операторов SQL Server. Для этих событий мы установили отбор по имени информационной базы и по соответствию текста запроса заданному шаблону. Шаблон мы построили на основе части запроса, содержащей имя одной из таблиц. В начало и конец части запроса мы поместили «%», а специальный символ «_» экранировали обратной косой чертой.
После того, как запрос в очередной раз выполнится, в технологическом журнале мы найдём следующую запись:
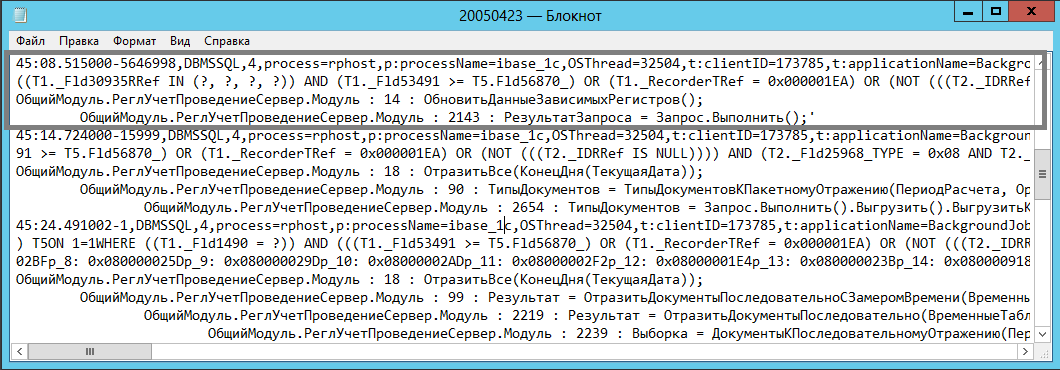
В журнале фиксируется контекст исполнения оператора. В данном случае мы имеем дело с одной из процедур регламентного задания отражения документов в регламентированном учете. Этим и объясняется высокая частота выполнения запроса:
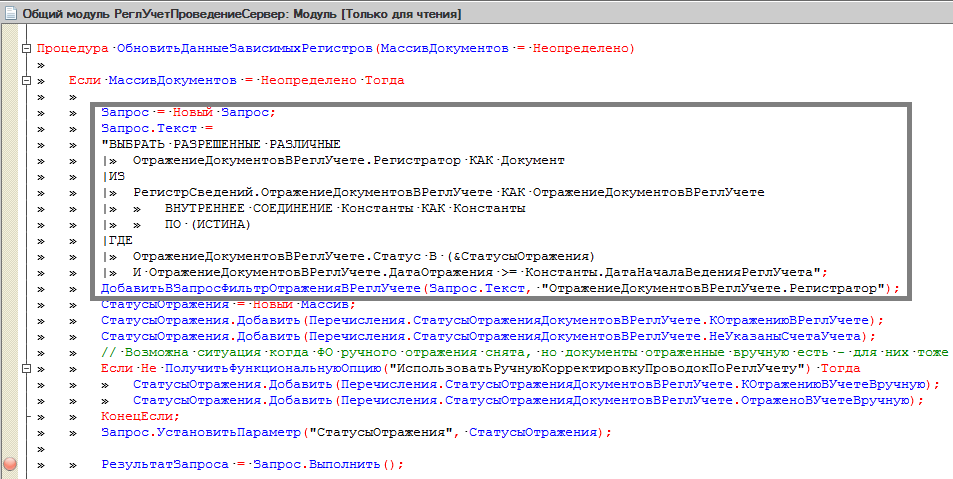
Мы видим, что текст запроса перед выполнением модифицируется. Если посмотреть процедуру ДобавитьВЗапросФильтрОтраженияВРеглУчете(), то можно сказать, что это делается с целью повторного использования кода.
Получим окончательный текст запроса с помощью отладчика:
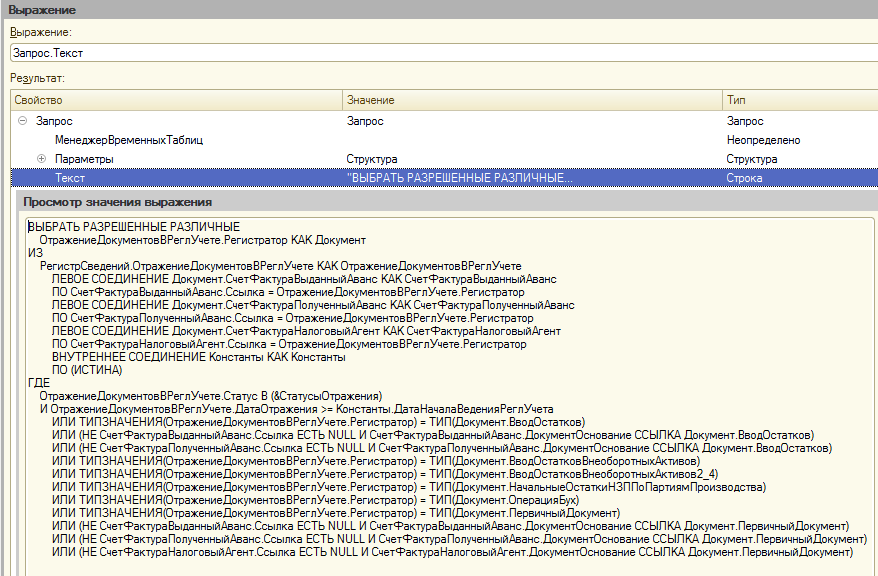
Теперь выясним, как SQL Server выполняет этот запрос, и почему он входит в топ запросов по потреблению ресурсов.
План исполнения запроса, который мы видим в нижней части отчета Query Store – это предполагаемый план (Estimated Plan), сформированный до выполнения запроса. Чтобы дополнить его информацией времени выполнения, т.е. получить фактический план (Actual Plan), воспользуемся Extended Events.
Сеанс Extended Events можно создать с помощью графических средств, но быстрее и проще это сделать с помощью запроса:
CREATE EVENT SESSION [query_post_execution_capture_1] ON SERVER
ADD EVENT sqlserver.query_post_execution_showplan(
ACTION(sqlserver.sql_text)
WHERE ([sqlserver].[equal_i_sql_unicode_string]([sqlserver].[database_name],N'database_1c') AND [sqlserver].[like_i_sql_unicode_string]([sqlserver].[sql_text],N'%LEFT OUTER JOIN dbo._Document761 T2%')))
WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF)
GO
Для события query_post_execution_showplan мы установили отбор по имени базы данных и шаблону текста запроса. В параметрах события мы включили дополнительное поле – sqlserver.sql_text (текст запроса).
Из контекстного меню созданного сеанса запустим сеанс и откроем окно событий – «Наблюдать за данными, передаваемыми в режиме реального времени» («Watch Live Data»).
Когда нужное событие будет зарегистрировано, остановим сеанс и посмотрим информацию о событии:
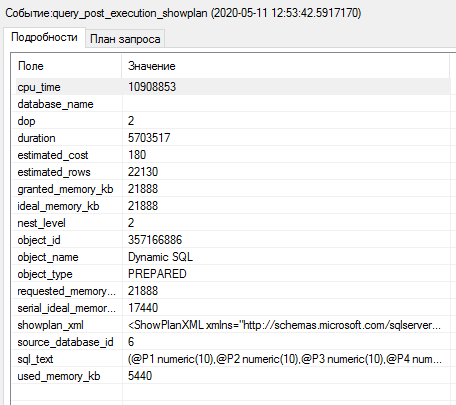
Мы видим, что наш запрос выполняется за 5,7 секунд (поле duration). Оптимизатор запросов оценил его предполагаемую стоимость как 180 (поле estimated_cost) и, в соответствии с настройками параллелизма, для запроса выбрана параллельная версия плана исполнения (поле dop). Для сравнения, порог стоимости плана запроса для использования параллелизма (cost threshold for parallelism) по умолчанию – 5.
Поле sql_text содержит текст запроса. Скопировав его в редактор запросов SSMS можно получить запрос в отформатированном виде:
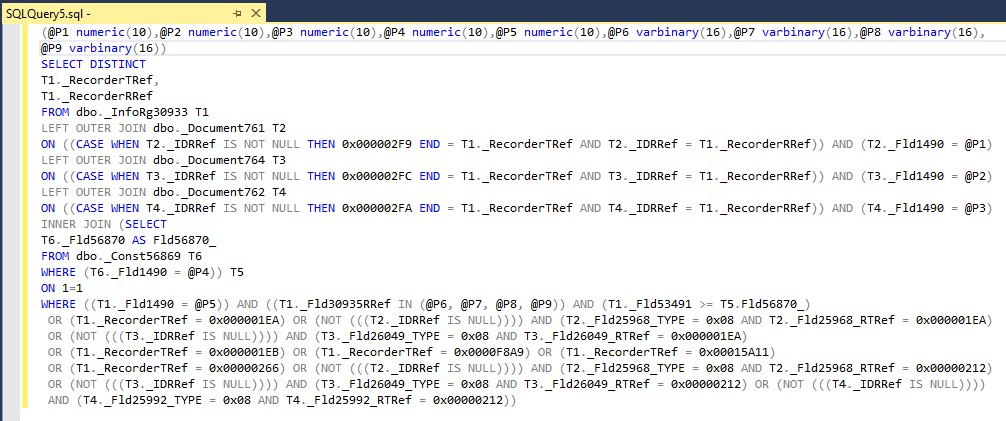
Обратите внимание на условие отбора по полю Fld1490 для каждой таблицы. Это поле разделителя с типом "ОбщийРеквизит.ОбластьДанныхОсновныеДанные". Платформа 1С неявно подставляет такие условия в запросы для конфигураций, в которых заложена возможность разделения данных, независимо от того, включено разделение или нет. Это относится ко всем конфигурациям, основанным на современных версиях БСП.
Для того, чтобы узнать каким объектам конфигурации соответствуют таблицы и поля базы данных, нужно воспользоваться функцией глобального контекста ПолучитьСтруктуруХраненияБазыДанных(). Результат её выполнения можно посмотреть в отладчике:
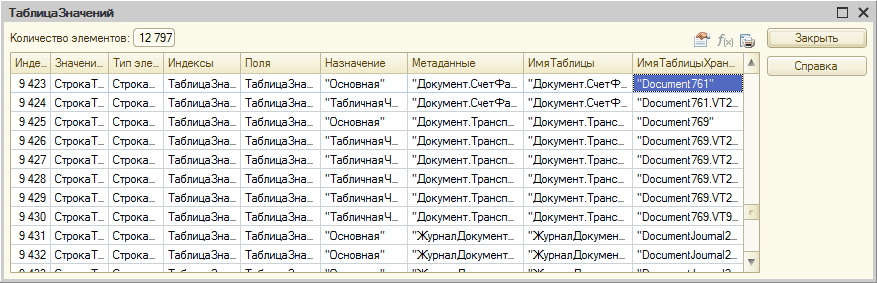
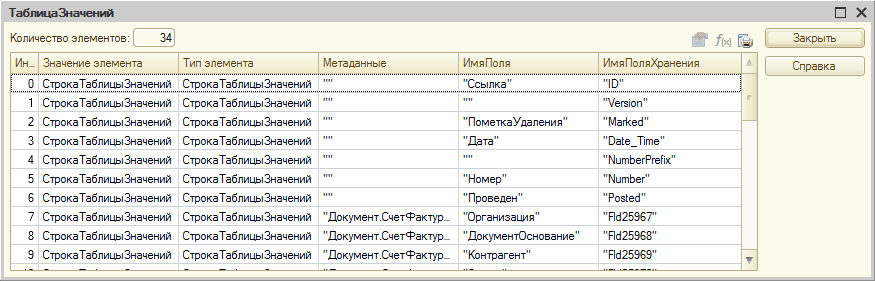
Таким же способом можно получить структуру индексов таблиц базы данных:
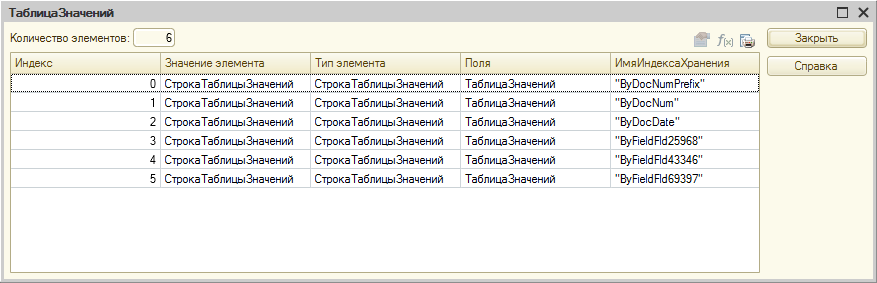
Первое, что бросается в глаза в плане исполнения нашего запроса – это толщина стрелок, изображающих потоки данных. Мы видим, что вся таблица регистра сведений ОтражениеДокументовВРеглУчете (InfoRg30933), в которой более 1,3 миллионов записей, попарно соединяется с каждой из основных таблиц трех документов, участвующих в запросе. Если быть точным, соединяются не таблицы, а результаты поиска по некластеризованным индексам, где предикатом является значение поля разделителя Fld1490, которое уже было упомянуто выше. Т.к. разделение в базе отключено, селективность этого предиката равна единице, т.е. возвращаются все строки таблиц.
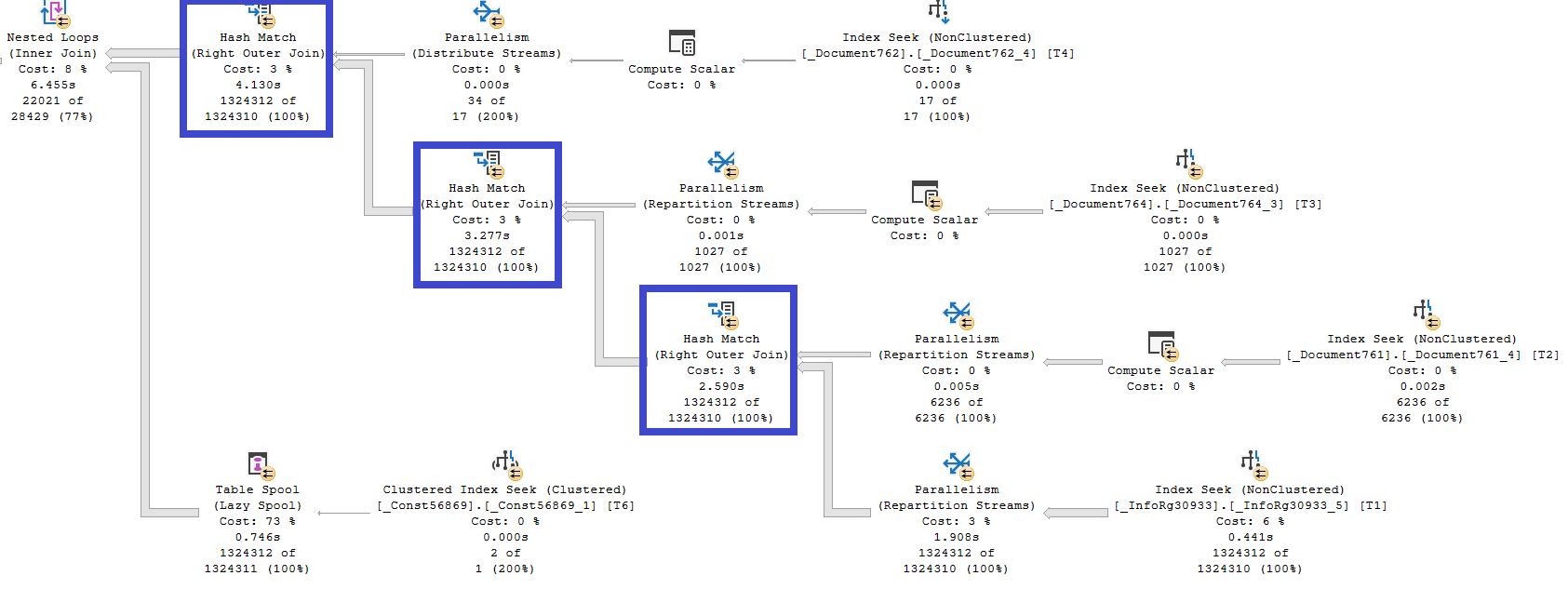
Во всех трех случаях для соединения используется оператор Hash Match. Оптимизатор обычно использует этот оператор для соединения больших входных данных, если они не отсортированы по полям соединения.
При соединении оператором Hash Match вычисляются хеши полей соединения верхних входных данных, называемых «Build». Таблица со значениями полей соединения и их хешами помещается в оперативную память. После этого выполняется построчное чтение нижних входных данных, называемых «Probe». Для каждой строки вычисляется хеш значений полей соединения и сравнивается с хешами в таблице из оперативной памяти. Для эффективного выполнения в качестве «Build» (верхних входных данных) выбирается меньший из двух потоков.
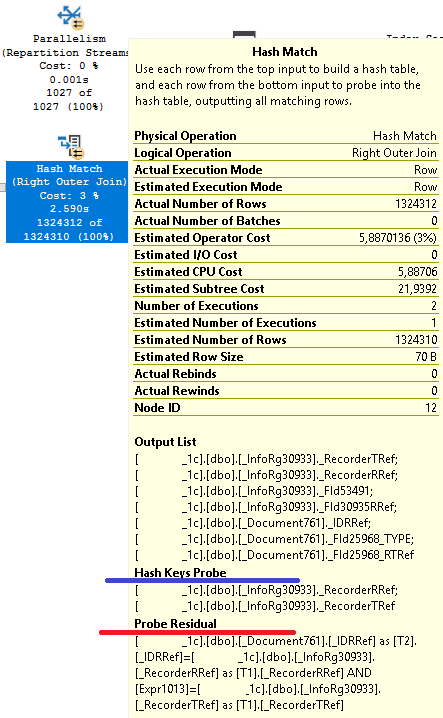
Поля, по которым выполняется соединение, можно увидеть в свойстве «Hash Keys Probe» оператора Hash Match.
В нашем случае стоимость операторам Hash Match увеличивает ещё и дополнительный предикат, соответствие которому должно быть проверено в ходе соединений. Его можно увидеть в свойстве «Probe Residual» операторов:
Из-за объема данных в нижнем потоке эти три оператора Hash Match наиболее затратны по CPU.
Наш запрос входит в топ по процессорному времени и по той причине, что для его исполнения используется параллелизм. Параллелизм уменьшает время выполнения запроса, но увеличивает потребление ресурсов. Если есть необходимость, параллелизм можно отключить не на уровне экземпляра или базы данных, а для конкретного запроса, добавив к запросу «Хинт» (Hint): OPTION (MAXDOP 1). Т.к с помощью средств платформы 1С мы не можем непосредственно изменять sql-запросы, хинт можно добавить в SSMS с помощью т.н. «Структуры планов» (Plan Guide):
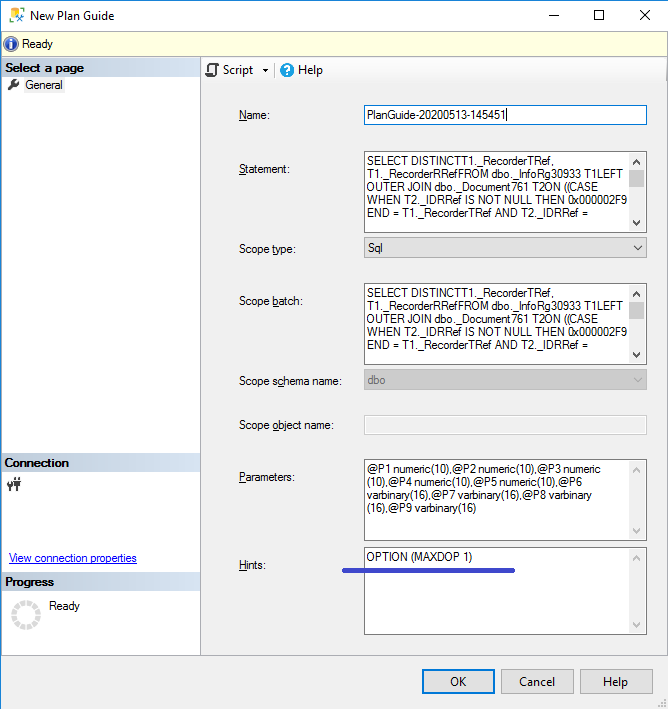
Рассмотрим теперь этот фрагмент плана исполнения:
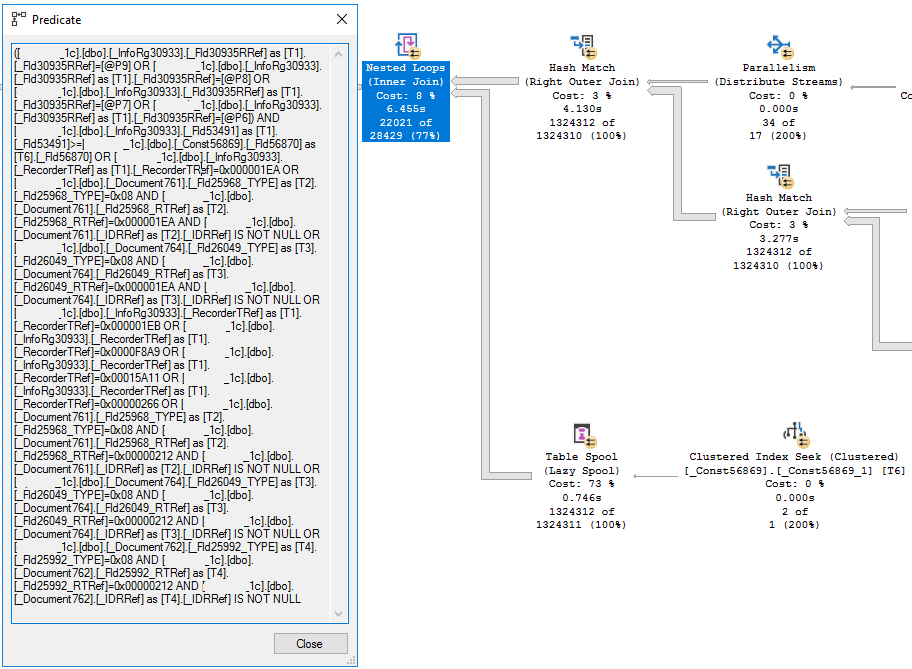
На плане мы видим, что верхний поток, в котором 1,3 млн. записей (результат соединения регистра сведений с документами), соединяется с таблицей константы «ДатаНачалаВеденияРеглУчета» с помощью оператора Nested Loops. В современных версиях платформы 1С каждой константе соответствует своя отдельная таблица базы данных.
Перед соединением на таблицу константы, как и на все другие таблицы, накладывается отбор по значению разделителя. Чтобы не производить поиск по этому значению на каждой итерации Nested Loops, результат поиска в индексе записывается в tempdb c помощью оператора Table Spool.
При выполнении Nested Loops операторы нижней ветки, в данном случае Table Spool, выполняются столько раз, сколько строк содержит верхний входящий поток, в нашем случае более 1,3 млн. раз. Это неоптимальное использование оператора Nested Loops, который эффективен, только если верхний поток содержит сравнительно малое количество строк.
Оператор Nested Loops проверяет условия соединения одним из двух способов. В нашем случае условия соединения находятся в свойстве «Predicate» оператора. Это значит, что оператор Nested Loops отбирает строки, соответствующие условиям, после того как получит значения из внутреннего цикла (нижняя ветка). Значения из верхнего набора строк в нижний не передаются. Нижние входящие данные в нашем случае статичны и возвращают одни и те же значения при каждом выполнении.
Условия соединения могут также проверятся в нижней ветке (во внутренних циклах). В этом случае мы бы увидели условия не в свойстве «Predicate», а в свойстве «Outer References» оператора Nested Loops.
Если мы посмотрим значение свойства «Predicate» оператора Nested Loops в плане исполнения нашего запроса, то мы увидим там все условия из секции «ГДЕ» запроса.
Способ оптимизации этого запроса достаточно прост. Нужно применить отборы как можно раньше, чтобы уменьшить объем соединяемых данных. При этом поиск данных, соответствующих условиям отбора, по возможности должен выполняться с помощью индексов.
Перепишем запрос следующим образом:
ВЫБРАТЬ РАЗРЕШЕННЫЕ
ОтражениеДокументовВРеглУчете.Регистратор КАК Документ
ИЗ
РегистрСведений.ОтражениеДокументовВРеглУчете КАК ОтражениеДокументовВРеглУчете
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Константы КАК Константы
ПО (ИСТИНА)
ГДЕ
ОтражениеДокументовВРеглУчете.Статус В(&СтатусыОтражения)
И ОтражениеДокументовВРеглУчете.ДатаОтражения >= Константы.ДатаНачалаВеденияРеглУчета
ОБЪЕДИНИТЬ
ВЫБРАТЬ
ОтражениеДокументовВРеглУчете.Регистратор
ИЗ
РегистрСведений.ОтражениеДокументовВРеглУчете КАК ОтражениеДокументовВРеглУчете
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.СчетФактураВыданныйАванс КАК СчетФактураВыданныйАванс
ПО (СчетФактураВыданныйАванс.Ссылка = ОтражениеДокументовВРеглУчете.Регистратор)
ГДЕ
(СчетФактураВыданныйАванс.ДокументОснование ССЫЛКА Документ.ВводОстатков
ИЛИ СчетФактураВыданныйАванс.ДокументОснование ССЫЛКА Документ.ПервичныйДокумент)
ОБЪЕДИНИТЬ
ВЫБРАТЬ
ОтражениеДокументовВРеглУчете.Регистратор
ИЗ
РегистрСведений.ОтражениеДокументовВРеглУчете КАК ОтражениеДокументовВРеглУчете
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.СчетФактураПолученныйАванс КАК СчетФактураПолученныйАванс
ПО (СчетФактураПолученныйАванс.Ссылка = ОтражениеДокументовВРеглУчете.Регистратор)
ГДЕ
(СчетФактураПолученныйАванс.ДокументОснование ССЫЛКА Документ.ВводОстатков
ИЛИ СчетФактураПолученныйАванс.ДокументОснование ССЫЛКА Документ.ПервичныйДокумент)
ОБЪЕДИНИТЬ
ВЫБРАТЬ
ОтражениеДокументовВРеглУчете.Регистратор
ИЗ
РегистрСведений.ОтражениеДокументовВРеглУчете КАК ОтражениеДокументовВРеглУчете
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Документ.СчетФактураНалоговыйАгент КАК СчетФактураНалоговыйАгент
ПО (СчетФактураНалоговыйАгент.Ссылка = ОтражениеДокументовВРеглУчете.Регистратор)
ГДЕ
СчетФактураНалоговыйАгент.ДокументОснование ССЫЛКА Документ.ПервичныйДокумент
ОБЪЕДИНИТЬ
ВЫБРАТЬ
ОтражениеДокументовВРеглУчете.Регистратор
ИЗ
РегистрСведений.ОтражениеДокументовВРеглУчете КАК ОтражениеДокументовВРеглУчете
ГДЕ
(ТИПЗНАЧЕНИЯ(ОтражениеДокументовВРеглУчете.Регистратор) = ТИП(Документ.ВводОстатков)
ИЛИ ТИПЗНАЧЕНИЯ(ОтражениеДокументовВРеглУчете.Регистратор) = ТИП(Документ.ВводОстатковВнеоборотныхАктивов)
ИЛИ ТИПЗНАЧЕНИЯ(ОтражениеДокументовВРеглУчете.Регистратор) = ТИП(Документ.ВводОстатковВнеоборотныхАктивов2_4)
ИЛИ ТИПЗНАЧЕНИЯ(ОтражениеДокументовВРеглУчете.Регистратор) = ТИП(Документ.НачальныеОстаткиНЗППоПартиямПроизводства)
ИЛИ ТИПЗНАЧЕНИЯ(ОтражениеДокументовВРеглУчете.Регистратор) = ТИП(Документ.ОперацияБух)
ИЛИ ТИПЗНАЧЕНИЯ(ОтражениеДокументовВРеглУчете.Регистратор) = ТИП(Документ.ПервичныйДокумент))
Выполним запрос и посмотрим метрики его производительности в Extended Events:
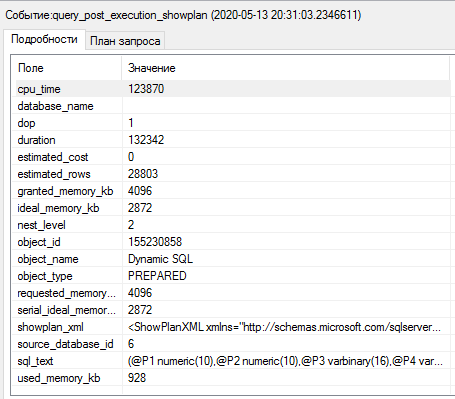
Мы видим, что на этот раз исполнитель запросов счел запрос достаточно простым, чтобы выполнить его на одном логическом процессоре (estimated_cost=0, dop = 1). При этом измененный запрос выполнился за 0.13 секунд, т.е. в 43 раза быстрее оригинального запроса. Процессорное время, затраченное на выполнение (cpu_time), теперь равно 123870 микросекунд, что в 88 раз меньше, чем у оригинального запроса.
Посмотрим теперь на текст sql-запроса и на план его исполнения:
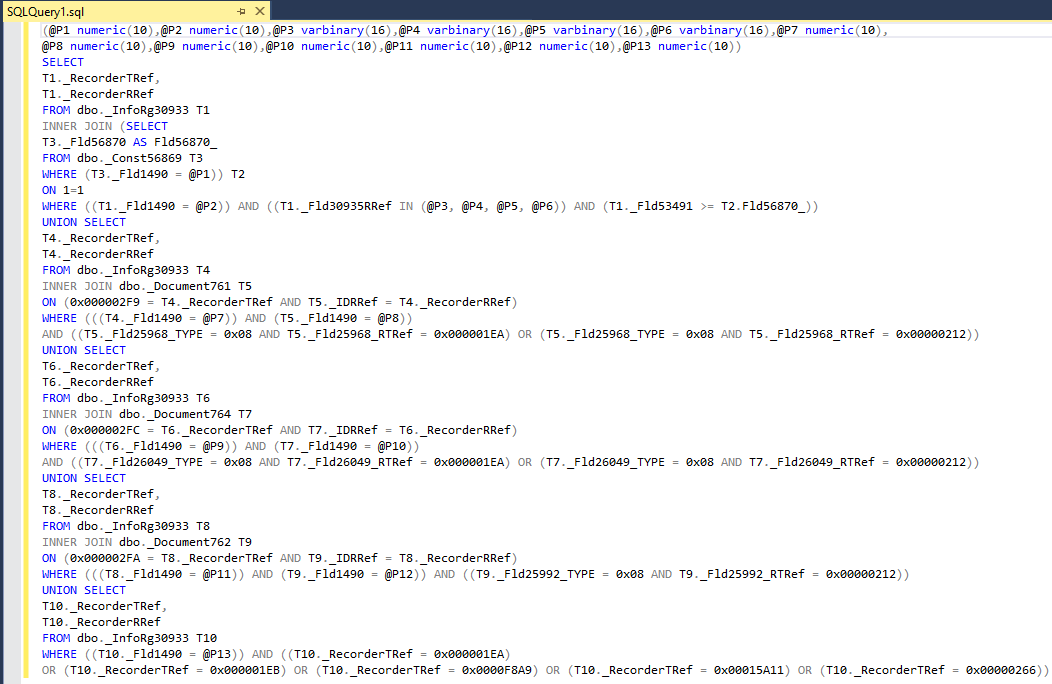
Для реализации логической операции объединения (Union) оптимизитор использовал физический оператор Merge Join, который требует, чтобы входные данные были упорядочены по полям объединения и не содержали дубликатов. Сам оператор Merge Join (Union) исключает из объединения дубликаты строк, которые есть в обоих наборах, но не учитывает дубликаты, которые могут быть в каждом из наборов по отдельности. Поэтому оптимизатор явным образом удаляет из наборов дубликаты либо с помощью оператора Sort (Distinct Sort), либо с помощью оператора Stream Aggregare (если данные в наборе уже упорядочены по нужным полям):
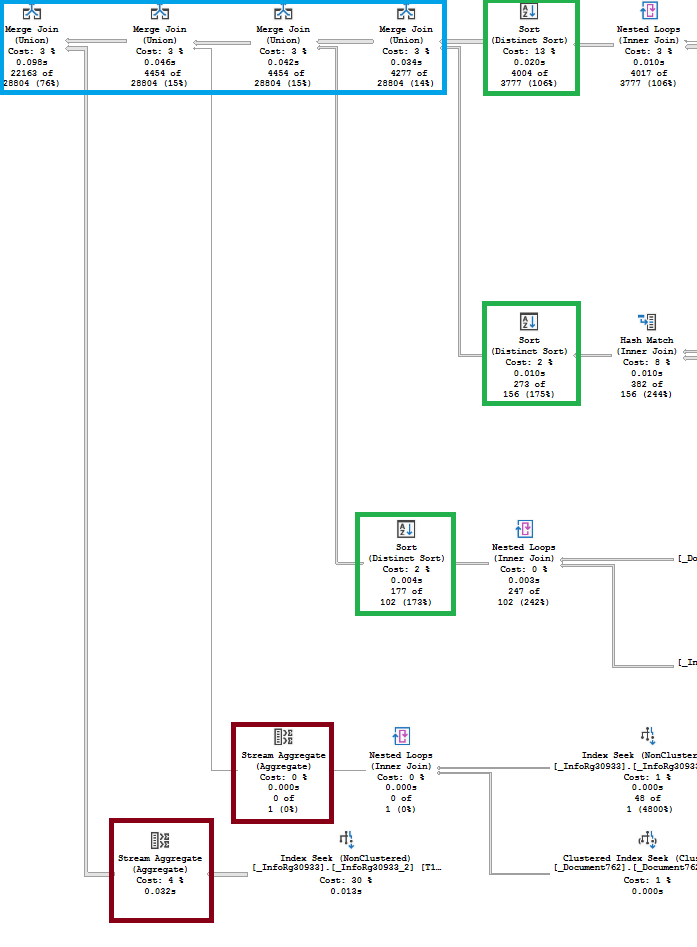
Посмотрим теперь, как оптимизатор формирует каждый из пяти объединяемых наборов данных, начиная с верхнего.
В секции «ГДЕ» верхнего запроса мы видим условия отбора по ресурсу «Статус» и по измерению «ДатаОтражения» регистра «ОтражениеДокументовВРеглУчете». Значения параметра &СтатусыОтражения передаются в запрос и объединяются с помощью оператора Concatenation. Ресурс «Статус» регистра проиндексирован, и поиск значений статусов выполняется в этом индексе.
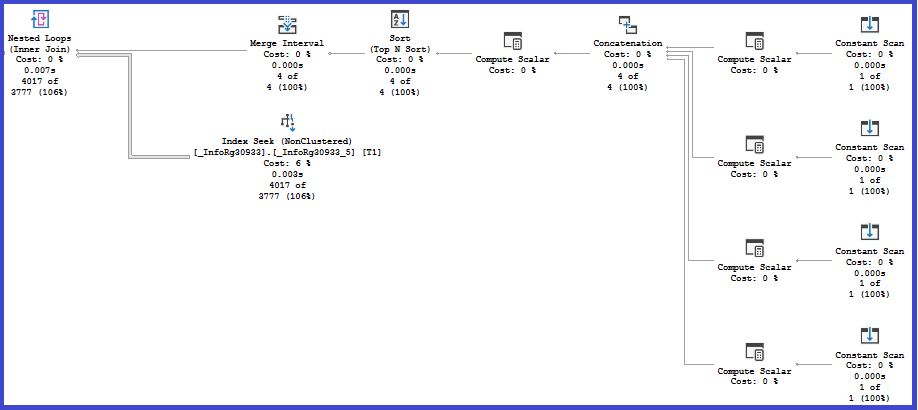
Условие по Статусу высокоселективное: из 1.3 млн. строк выбирается 4 тысячи. Далее эти 4 тысячи строк соединяются с таблицей константы с отбором по Дате отражения, уже без использования индексов:
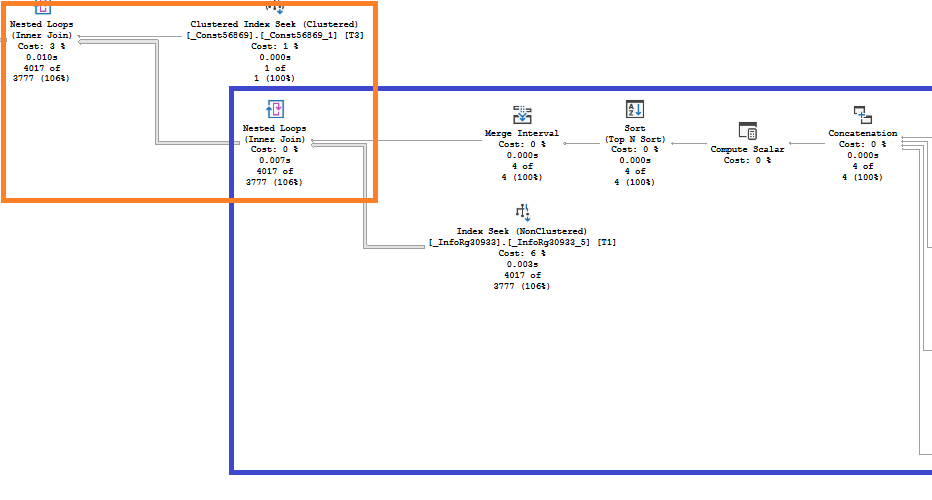
Используя терминологию из Методик разработки конфигураций 1С, условие по Статусу можно назвать «основным», а по Дате отражения – «дополнительным».
Следующие 3 объединяемых запроса по структуре почти не отличаются, но оптимизатор выбрал для них разные способы исполнения. Это объясняется разной оценкой количества элементов (Cardinality estimation), соответствующих условиям отбора. Эту оценку оптимизатор получает на основе статистики.
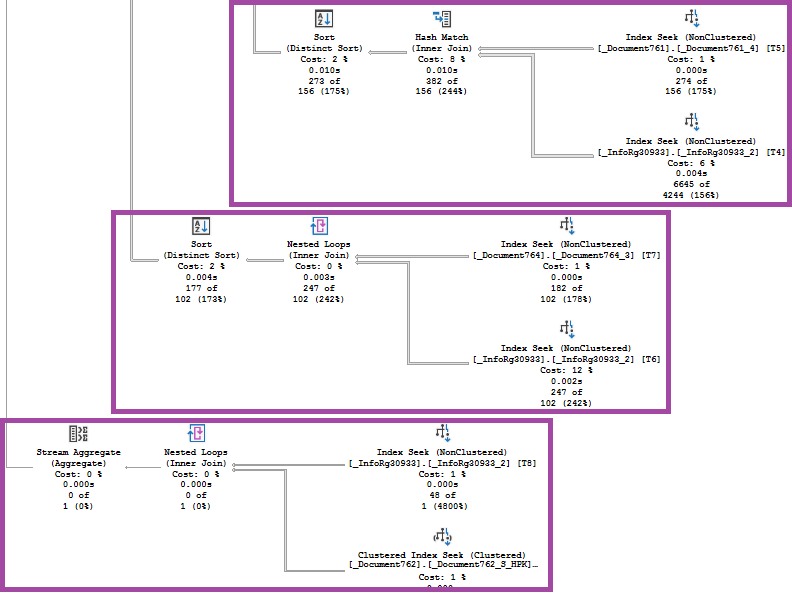
Наконец, для получения результата последнего из пяти запросов, достаточно выполнить поиск по индексу, т.к. все элементы в секции «ГДЕ», несмотря на то, что они объединены оператором «ИЛИ», накладывают отбор по одному и тому же полю – Регистратору.
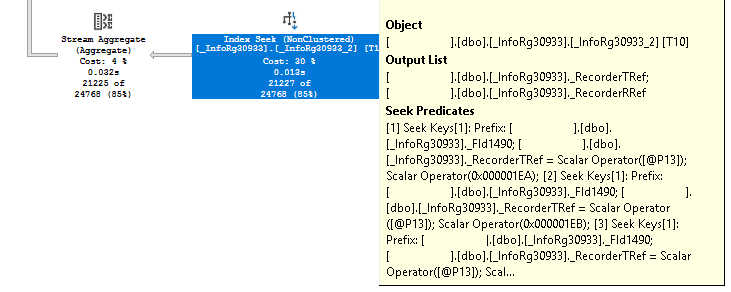
Таким образом, для применения всех основных условий запроса мы использовали индексы, и избежали неэффективных соединений больших объемов данных. Этим и объясняется значительная разница в количестве процессорного времени, используемого для выполнения запросов.
Оригинальный запрос заменим оптимизированным в расширении конфигурации. В данном случае безопасней всего это сделать, расширив метод «ДобавитьВЗапросФильтрОтраженияВРеглУчете()» следующим образом:
Если после обновления конфигурации оригинальный запрос будет изменен, эта замена автоматически перестанет выполняться.
Вступайте в нашу телеграмм-группу Инфостарт