
















1С + MS SQL против Матрицы виртуализации.
Логика Черного лебедя делает то, чего вы не знаете, гораздо более важным, чем то, что вы знаете. Ведь если вдуматься, то многие Черные лебеди явились в мир и потрясли его именно потому, что их никто не ожидал.
Нассим Талеб
«Время всегда против нас».
Весна 2020 года была очень активной на фондовых рынках, количество сделок в некоторые дни вырастало в 2 раза от нормы, закрытие дня в финансовом учете было близко к предельным срокам. Клиенты боролись с Черным Лебедем Covid-19 по всем фронтам. К этому моменту конфигурация уже 7 лет работала на одном и том же оборудовании, которое было заложено с запасом под горизонтальное маштабирование. Даже то горизонтальное масштабирование, которое можно сделать в 1С (см статью //infostart.ru/1c/articles/1683197/ ) позволяет решать проблемы роста объемов оборудованием, и вот настал тот момент когда уже пора расширять оборудование. Случайное совпадение - наши системные администраторы предложили попробовать новый виртуальный кластер, который недавно развернули в компании. Кластер на основе VMWare. Перспективы были заманчивые, вместо покупки новых серверов, отдельных дисковых хранилищ, обоснований бюджета – создаются виртуальные машины с нужными параметрами, а в бюджет аллоцируются расходы из общего пула. Будущее рисует нам картины, когда системный администратор скоро не сможет потрогать сервер рукой, и будет видеть только операционную систему и прайс лист за использование J от провайдера. Однако виртуальная реальность оказалась не такой радужной.
Мне выделили контур с примерно таким же числом ядер, памяти как на рабочем. Версии программ и операционной системы поставили идентичные, настройки тоже. Параметры оборудования по виртуализацию были лучше, но не сильно ведь гонка тактовых частот заканчивается по физическим ограничениям. Запустил перерасчет за месяц с распараллеливанием… и ушел спать.
«Что есть реальность?» В виртуальной среде
Утром первым делом посмотрел на результаты, они были странные – замедление 60% на виртуальном кластере. Даже ФИФО который параллелится только по бумагам и не создает большой нагрузки, посчитался медленней на 30%

Хорошо, что мне есть с чем сравнивать, и я могу просто сказать «А вот на железном кластере с той же конфигурацией гораздо быстрее» или сравнить счетчики MS SQL на быстром и медленном кластере. Но допустим, кому то дали облако под проект с якобы заявленными параметрами, как ему понять что кластер (1С MSSQL Hardware) работает на полную мощность?
Тут можно обратится к принципу непротиворечивости логичной системы аксиом. В логике предикатов http://mathhelpplanet.com/static.php?p=svoystva-aksiomaticheskikh-teoriy это изложено детально, но по простому можно сказать: Вы можете построить любую систему аксиом для своей алгебры, геометрии, теории множеств – важно чтобы она была непротиворечивой при выводе теорем и утверждений. Там, где есть противоречие 2 варианта либо система аксиом плоха, либо вы что-то не знаете и не учитываете и именно там истина. Математика, физические постоянные существуют в мире не просто так любые противоречия разрушили бы вселенную. Напр путешествие во времени назад вызывает кучу противоречий, значит оно невозможно, а вот в будущее без возврата в прошлое вполне возможно.
Значит решено - снимаем показатели и ищем противоречия. ИТ технологии сложны, но это гораздо проще тензорного исчисления J . Производительность какого-то компонента кластера снижается по одной из трех причин.
- Ресурс перегружен, это сразу видно на счетчиках производительности
- Ресурс частично свободен, но ждет снятия какой-то блокировки (Это может быть блокировка строк в СУБД, ресурсов памяти Latch, и т.д.)
- Ресурс частично свободен, но у него скопилась очередь (Это может быть очередь к дисковой системе, минимально необходимые задержки на передачу пакета по сети)
Комбинация этих причин приводит к тому что все утыкается в бутылочное горлышко и остальные ресурсы просто не нагружаются.
Настроил счетчики, я не будут описывать нужные - так как в разных ситуациях нужно искать разные. Принцип простой – из всех счетчиков ищите счетчики очередей, ожиданий, миллисекунд на трансфер. Счетчики на % загрузки как правило не дают сделать выводы напр. Передача по сети множества мелких пакетов не создает 100% траффика, но за счет задержек сети упирается в потолок производительности (см мою старую статью на эту тему http://selis76.narod.ru/matnetw1.html#bookmark1 )
Для оборудования настроил Perfomance Monitor с записью, то что называется Data collection set. Странно, но оно работало только после перезагрузки сервера.
Для SQL Server сбросил счетчики статистики и кэши
DBCC SQLPERF("sys.dm_os_wait_stats",CLEAR);
DBCC FREEPROCCACHE ;
DBCC DROPCLEANBUFFERS;
Анализ перегруженности ресурсов не показал ничего критичного
На кластере 1С за счет горизонтального масштабирования загрузка плотная, больше 50% (что считается с точки зрения Microsoft значительной нагрузкой)
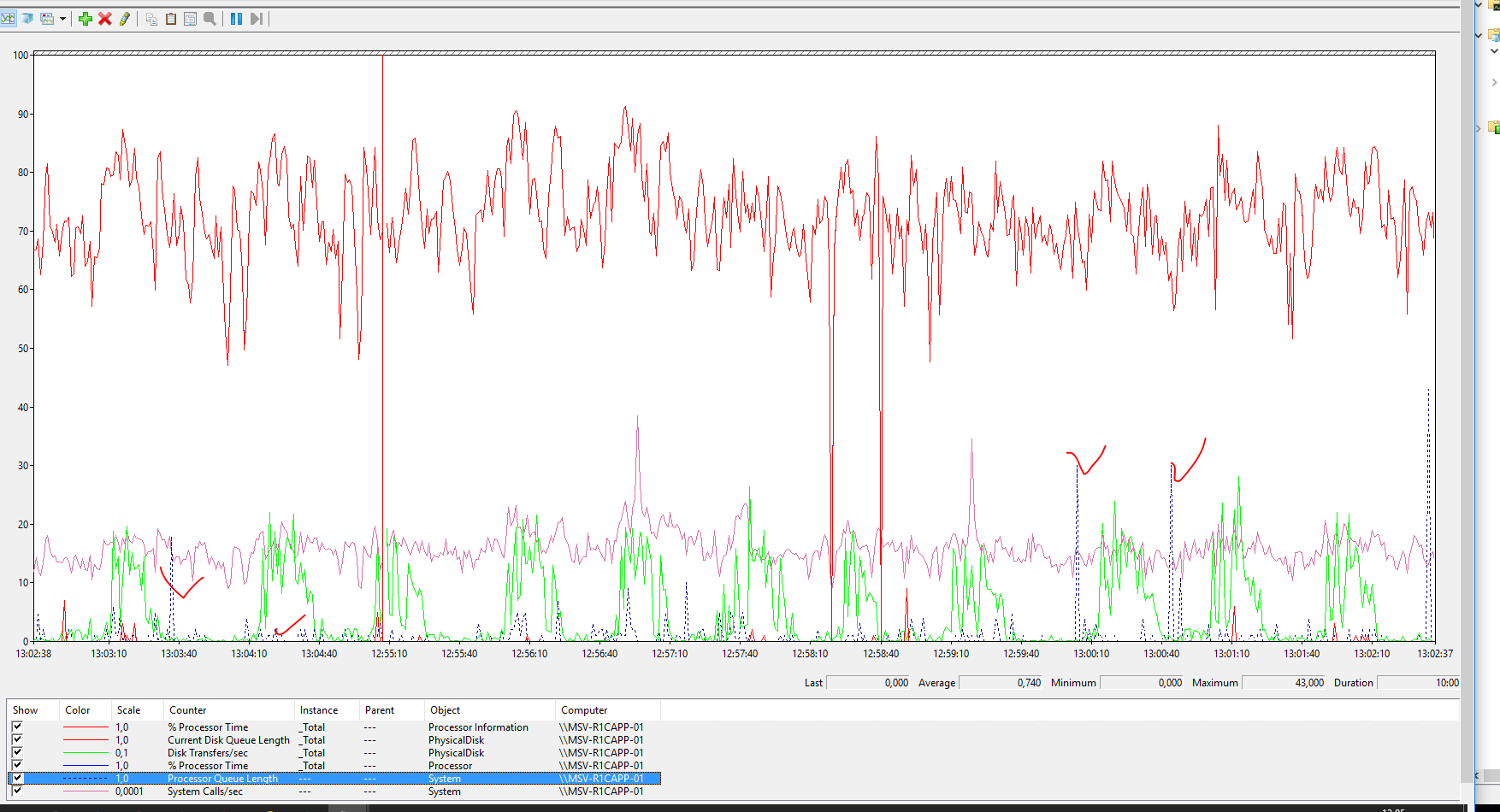
Небольшая странность, бывают очереди на процессор (Processor queue length).
На сервере базы данных нагрузка небольшая, значит можно увеличить еще, но видны противоречия
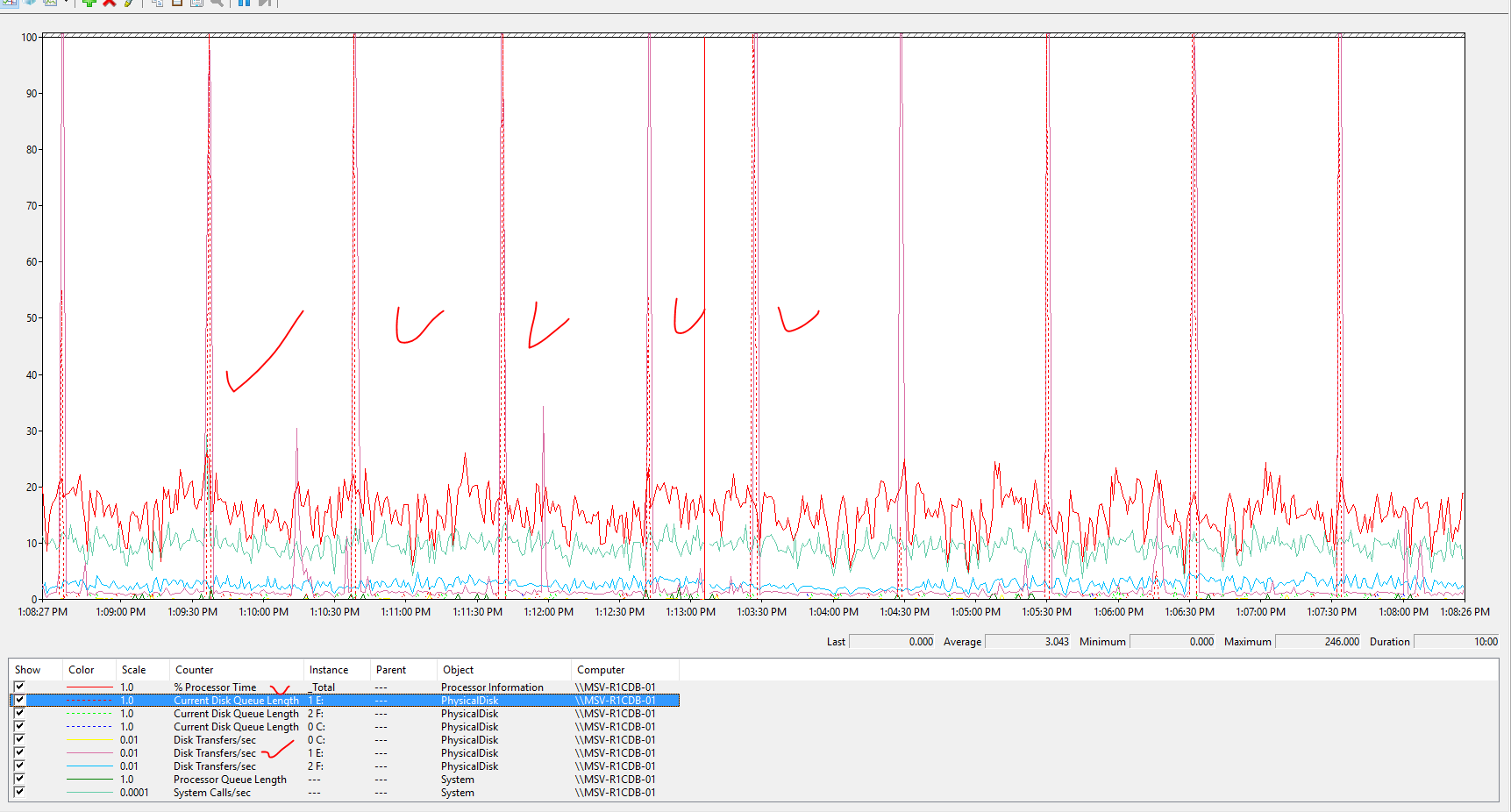
Видны всплески очередей на диск (Current disk queue length больше 100), когда активность превышает 10 тыс IOPS . Причем видно что очередь держится по несколько секунд. Это странно, ведь SSD должен переваривать такой траффик легко.
Попросил администраторов проверить со стороны гипервизора, получил ответ
«В данной конфигурации Ваш виртуальный сервер может спокойно потреблять до 50k iops при минимальном latency. Разумеется, если от него этого требуют.
На Ваших графиках видно, что нагрузка почти нулевая с периодическими кратковременными скачками. Я посмотрел - в эти пиковые моменты сервер потреблял всего до 20k iops. Latency в эти моменты достигала 15-20 мс, что безусловно не мало, но и не катастрофично, учитывая, что эти всплески длятся доли секунды.
Latency растет, т.к. Вы периодически упираетесь в одно единственно ограничение - одновременное количество потоков данных от виртуального сервера к дисковой системе (максимум 64) в текущей конфигурации.
Параметр queue lentgh и все его производные имеет смысл рассматривать только на однодисковых десктопах. На серверах и в виртуализации он не показывает абсолютно ничего. »
Вот первый звоночек оказывается VMWare ограничивает одновременное количество потоков данных от сервера к дисковой подсистеме, неужели придется еще VWWare изучать J чтобы знать ее узкие места. Про очереди не согласен, если они возникают значит что-то не так. А так «Все хорошо прекрасная маркиза, все хорошо, все хорошо»
«Если бы ты не мог проснуться, как бы ты узнал, что сон, а что действительность?»
Очень просто – надо так пошалить в системе, что бы агент Смит мигом прибежал успокаивать прозревающего Нео и попытаться уложить его в кроватку. В ИТ это называется стресс тест , у водопроводчиков опрессовка. Если хотите проверить качество работы сантехника, пригласите опрессовщика, он создаст избыточное давление и все недоработки потоком польются вам на пол.
Горизонтальное масштабирование позволяет легко увеличить количество параллельных процессов обработки и тем самым увеличить нагрузку. Поэтому свой тест я запускал увеличив количество параллельных процессов обработки с 40 до 60, если % загрузки не дают внятного ответа, смотрим анализ ожиданий
Результаты интересные, ожидание на логгирование Transaction log вылезло в топ, да еще Memory waits https://www.sqlskills.com/help/waits/resource_semaphore/ появились .
Еще сетевые задержки между кластером 1С и СУБД великоваты https://www.sqlskills.com/help/waits/async_network_io/ они действительно отличались от продуктивного контура, если применить анализ задержек через hrping. Это исправили, результат улучшился, но не существенно для текущей проблемы
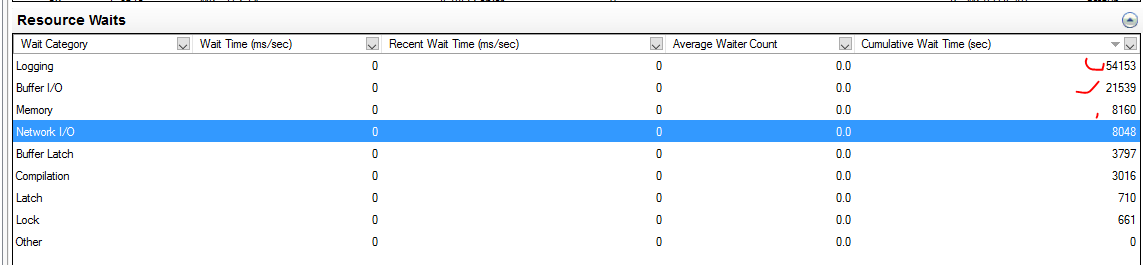
На продуктивном сервере топ ожиданий совсем другой, скажем так логичный – больше ждешь записи\чтения в базу нежели transaction log и памяти
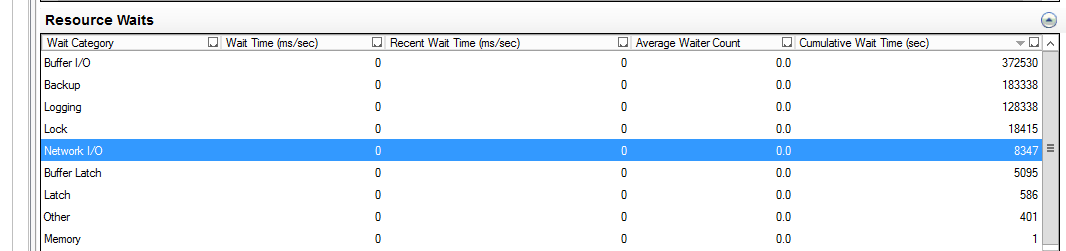
Далее смотрим детально ожидания на Transaction log он находится на отдельном SSD диске, но там нет проблем с производительностью дисковой системы.
Администраторы мне это подтвердили
«На графике ниже 3 параметра: lock wait, log write wait, disk latency.
Хорошо видно, что несмотря на высокий уровень Log write waits, запись данных на диск происходит с приемлемой latency. Следовательно, проблема тут не в дисках.

Решение проблем с задержками сети улучшило результат до 1233 мин против 1492, но это не 937 мин на рабочем.
Анонс. Анализ сетевых задержек это отдельная тема. В устаревшем варианте есть моя статья http://selis76.narod.ru/matnetw1.html#bookmark1 , но ее можно уже обновить, учитывая новые кейсы.

«Часть меня чувствует, будто я всю жизнь ждала тебя.» Ожидания наше все.
Если отбросить диск, то анализ задержек на уровне процессор память наиболее сложная тема, поскольку это уже нужно лезть в анализ процессов операционной системы и с пониманием использовать ProcessExplorer https://docs.microsoft.com/en-us/sysinternals/downloads/process-explorer . Многоядерность, Numa nodes усложняют задачу. Я уже подошел к моменту, когда анализ счетчиков увеличивает глубину НЕ знания, поскольку даже внутри кластера видно, что для tempdb при сопоставимых объемах записи, таких проблем нет, а для базы СУБД есть. Интуитивно было понятно что, что-то не так с виртуальными ядрами, Numa nodes, а не с реальным железом
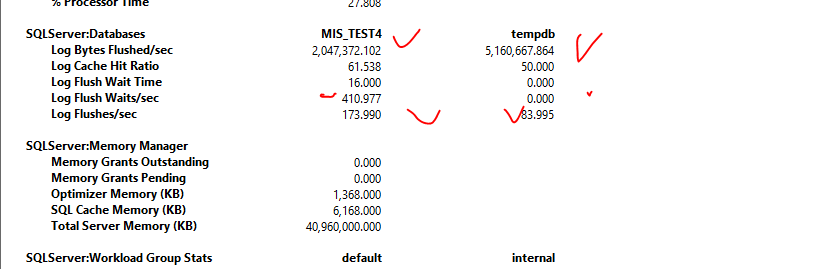
Если есть теория, значит, нужно искать ей подтверждение! Ок Google?
Не помню, какой правильно был сформулированный вопрос, который содержит половину ответа, но я нашел эту статью про spinlock в MS SQL
https://chrisadkin.io/2015/09/09/tuning-the-logcache_access-spinlock-on-a-big-box/
Тема сложная, поскольку это уже системная архитектура СУБД, до которой не каждый SQL администратор доберется, а Эксперт по технологическим вопросам 1С вообще не должен столкнуться с подобным, учитывая проблемы 1С горизонтальным масштабированием, см. тут //infostart.ru/1c/articles/1683197/ . Приведу лишь несколько цитат для понимания

«Spinlocks are lightweight synchronization primitives which are used to protect access to data structures. Spinlocks are not unique to SQL Server. They are generally used when it is expected that access to a given data structure will need to be held for a very short period of time. When a thread attempting to acquire a spinlock is unable to obtain access it executes in a loop periodically checking to determine if the resource is available instead of immediately yielding. After some period of time a thread waiting on a spinlock will yield before it is able to acquire the resource in order to allow other threads running on the same CPU to execute. This is known as a backoff and will be discussed in more depth later in this paper.
SQL Server utilizes spinlocks to protect access to some of its internal data structures. These are used within the engine to serialize access to certain data structures in a similar fashion to latches. The main difference between a latch and a spinlock is the fact that spinlocks will spin (execute a loop) for a period of time checking for availability of a data structure while a thread attempting to acquire access to a structure protected by a latch will immediately yield if the resource is not available. Yielding requires context switching of a thread off the CPU so that another thread can execute. This is a relatively expensive operation and for resources that are held for a very short duration it is more efficient overall to allow a thread to execute in a loop periodically checking for availability of the resource.»
Проще говоря это блокировки для структур памяти, которые работают по принципу циклического ожидания.
«Ты всю жизнь ощущал, что мир не в порядке. Странная мысль, но её не отогнать. Она — как заноза в мозгу. Она сводит с ума, не даёт покоя. Это и привело тебя ко мне...» Морфеус
Предположил, что проблема в физическом распределении по Numa Node потоков MS SQL, которое влечет задержки при доступе к памяти (ведь spinlock это структуры памяти) , видимо на физическом уровне WriteLog висит на тех же ядрах что и другие потоки MS SQL и Numa Nodes фактически не работают. С приходом многоядерности требуется внимательно смотреть на загрузку отдельных ядер, ведь там может висеть процесс или поток, который становится узким местом для всей системы.
Классический пример из 1С – rmanager со всеми сервисами висит на одном ядре, если он управляет 40 рабочими процессами, загрузка этого ядра на 100% уже влияет на всю систему самым отрицательным образом. Поэтому в 8.3 есть флажок «Менеджер под каждый сервис», а в 8.2 нужно сделать несколько менеджеров кластера и распределить по ним сервисы.
Ложки не существует. Что не так с ядрами виртуальной машины?
— Не пытайся согнуть ложку. Это невозможно. Для начала нужно понять главное.
— Что главное?
— Ложки не существует.
— Не существует?
— Знаешь, это не ложка гнётся. Всё — обман. Дело в тебе.
С какими ядрами работает SQL Server можно увидеть в Affinity mask логе SQL Server
Вот что было на виртуальном кластере

А это на рабочем

Почувствовали разницу? SQL сервер по другому видит и Numa node и количество ядер. Хотя там все одинаково с точки зрения количества
Что такое Numa node, хорошо объяснено тут
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms178144(v=sql.105)
«Each group of processors has its own memory and possibly its own I/O channels. However, each CPU can access memory associated with the other groups in a coherent way. Each group is called a NUMA node. The number of CPUs within a NUMA node depends on the hardware vendor. It is faster to access local memory than the memory associated with other NUMA nodes»
Дальше все становится понятным - SQL Server не будет есть виртуальную … . Любая виртуальная … приведет к самым экзотическим эффектам в производительности. Выход один – выровнять виртуальную машину с физической. В VMWare такое возможно, с другой стороны, а зачем она нам вообще тогда нужна J . Все варианты например: дадим половину реальной машины или 2 реальных машины объединенных в одну приведут к непредсказуемым эффектам в производительности
Проверка через CoreInfo показала такое распределение ядер на виртуальном сервере
Logical to Physical Processor Map:
*----------------------- Physical Processor 0
-*---------------------- Physical Processor 1
--*--------------------- Physical Processor 2
---*-------------------- Physical Processor 3
----*------------------- Physical Processor 4
-----*------------------ Physical Processor 5
------*----------------- Physical Processor 6
-------*---------------- Physical Processor 7
--------*--------------- Physical Processor 8
---------*-------------- Physical Processor 9
----------*------------- Physical Processor 10
-----------*------------ Physical Processor 11
------------*----------- Physical Processor 12
-------------*---------- Physical Processor 13
--------------*--------- Physical Processor 14
---------------*-------- Physical Processor 15
----------------*------- Physical Processor 16
-----------------*------ Physical Processor 17
------------------*----- Physical Processor 18
-------------------*---- Physical Processor 19
--------------------*--- Physical Processor 20
---------------------*-- Physical Processor 21
----------------------*- Physical Processor 22
-----------------------* Physical Processor 23
Logical Processor to Socket Map:
*----------------------- Socket 0
-*---------------------- Socket 1
--*--------------------- Socket 2
---*-------------------- Socket 3
----*------------------- Socket 4
-----*------------------ Socket 5
------*----------------- Socket 6
-------*---------------- Socket 7
--------*--------------- Socket 8
---------*-------------- Socket 9
----------*------------- Socket 10
-----------*------------ Socket 11
------------*----------- Socket 12
-------------*---------- Socket 13
--------------*--------- Socket 14
---------------*-------- Socket 15
----------------*------- Socket 16
-----------------*------ Socket 17
------------------*----- Socket 18
-------------------*---- Socket 19
--------------------*--- Socket 20
---------------------*-- Socket 21
----------------------*- Socket 22
-----------------------* Socket 23
Logical Processor to NUMA Node Map:
************------------ NUMA Node 0
------------************ NUMA Node 1
Approximate Cross-NUMA Node Access Cost (relative to fastest):
00 01
00: 1.0 1.2
01: 1.2 1.1
На рабочем сервере
Logical to Physical Processor Map:
**------------------------------ Physical Processor 0 (Hyperthreaded)
--**---------------------------- Physical Processor 1 (Hyperthreaded)
----**-------------------------- Physical Processor 2 (Hyperthreaded)
------**------------------------ Physical Processor 3 (Hyperthreaded)
--------**---------------------- Physical Processor 4 (Hyperthreaded)
----------**-------------------- Physical Processor 5 (Hyperthreaded)
------------**------------------ Physical Processor 6 (Hyperthreaded)
--------------**---------------- Physical Processor 7 (Hyperthreaded)
----------------**-------------- Physical Processor 8 (Hyperthreaded)
------------------**------------ Physical Processor 9 (Hyperthreaded)
--------------------**---------- Physical Processor 10 (Hyperthreaded)
----------------------**-------- Physical Processor 11 (Hyperthreaded)
------------------------**------ Physical Processor 12 (Hyperthreaded)
--------------------------**---- Physical Processor 13 (Hyperthreaded)
----------------------------**-- Physical Processor 14 (Hyperthreaded)
------------------------------** Physical Processor 15 (Hyperthreaded)
Logical Processor to Socket Map:
****************---------------- Socket 0
----------------**************** Socket 1
Logical Processor to NUMA Node Map:
****************---------------- NUMA Node 0
----------------**************** NUMA Node 1
Approximate Cross-NUMA Node Access Cost (relative to fastest):
00 01
00: 1.0 1.3
01: 1.5 1.0
Разница понятна. На виртуальном якобы физические сокеты 24 шт, а на рабочем сервере 2 сокета и 32 ядра Hyperthread
Прошу администраторов выровнять виртуальные машины по физическим на SQL сервере и кластере 1С, запускаю тест повторно. Урааа 1162 минуты против 937 это еще не победа, вообще результат должен быть лучше все-таки оборудование более новое. Но направление борьбы с Матрицей понятно – нужно везде разоблачать виртуальные ресурсы и отображать их на реальные физические один к одному. Зачем на тогда Матрица? Для белых воротничков, которые сидят в браузере и Word, для малого бизнеса которому лишние железки только лишняя нагрузка, а в браузере он выглядит даже средним бизнесом, менеджерам для экономии - кому угодно только не тем кому нужна реальная производительность.
Кто-то скажет: Вы не умеете готовить виртуальную среду?
Я отвечу: Я что - шеф повару должен объяснять как ему готовить? Да ну такой ресторан, лучше сделать свой.
Уже по идеологии виртуализации видно, что вопросы производительности там на последнем месте и все заточено на «эффективное использование ресурсов», никогда не знаешь где и когда тебе подрежут ресурсы. Самое плохое, что никто из специалистов 1С не станет изучать гипервизор и VMWare, а системные администраторы не будут глубоко лезть в архитектуру SQL сервера. В итоге любые проблемы придется решать мозговым штурмом Эксперта по тех вопросам 1С, Администратора SQL , Системного администратора и еще других занятых сотрудников только ради того чтобы убрать ограничения виртуальной среды.
Забегая вперед могу сказать, что равной производительности (и даже большей) на виртуальном кластере мы достигли, в следующей серии Матрицы
Как изменились счетчики после выравнивания виртуальной машины можно посмотреть ниже.
Скрипты для запросов с источниками происхождения я прилагаю.
На тестовом кластере зафиксировано до оптимизаций
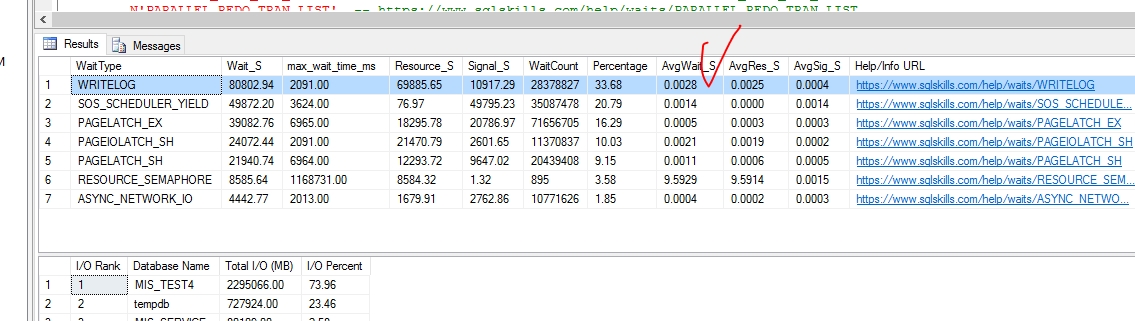
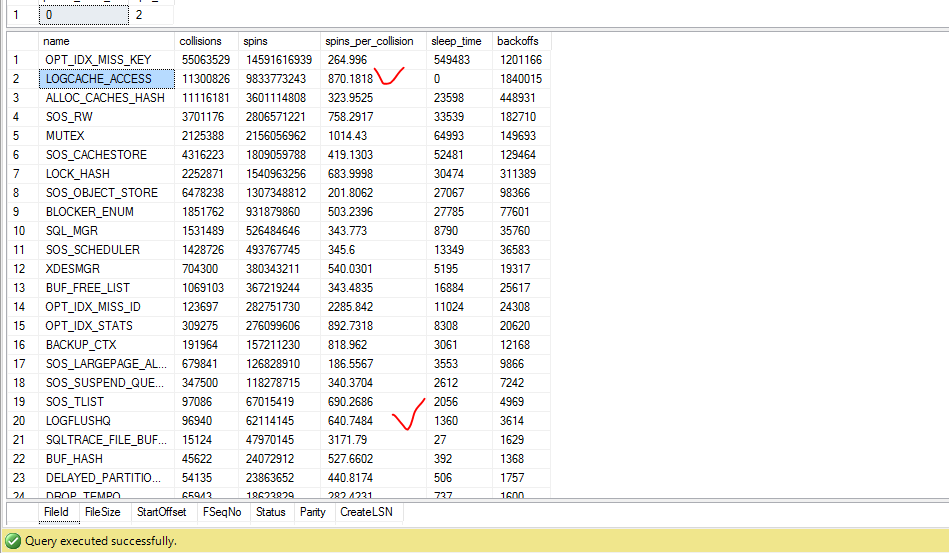
После выравнивания виртуальных машин с физическими сокетами и ядрами картина резко улучшилась
Задержка по Writelog сократилась в два раза.
Как работает spinlock описано выше, но нам сейчас важно понимать, что при коллизии доступа к logbuffer значение spin увеличивается циклически пока другой поток не отпустит ресурс. Т.е чем выше значение spins_per_collision тем хуже работает связка процессор
У нас – они уменьшились на logflushq, но увеличились на logcashe_access – последнее считается признаком более интенсивной работой writelog . Замечу что на рабочем кластере статистика еще лучше, но там повышенную нагрузку не давали при измерениях. О том, что еще влияло на производительность виртуального кластера – в следующей статье. Первыми статьи появляются на нашем канале t.me/Chat1CUnlimited + дополнительная информация


«Я не сказал, что будет легко. Я лишь обещал открыть правду.» Морфеус
Вступайте в нашу телеграмм-группу Инфостарт